
前言:我们先了解一下数据仓库架构的演变过程。
1 、数据仓库定义
数据仓库是一个
面向主题的(Subject Oriented)、
集成的(Integrate)、
相对稳定的(Non-Volatile)、
反映历史变化(Time Variant)的数据集合,用于支持管理决策。
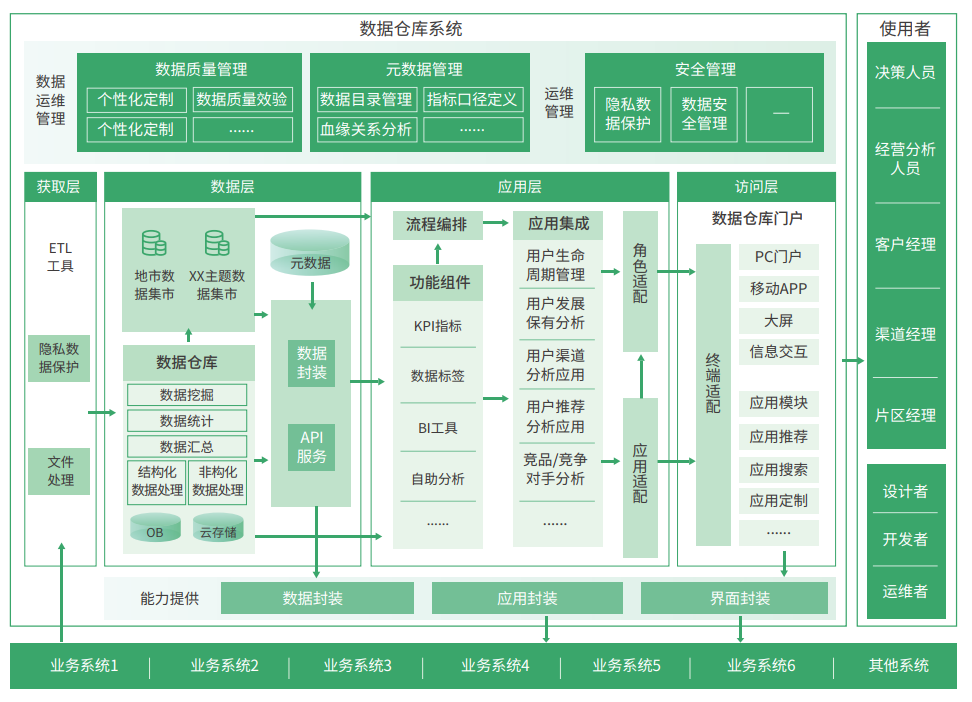
数据仓库概念是 Inmon 于 1990 年提出并给出了完整的建设方法。随着互联网时代来临,数据量暴增,开始使用 大数据工具 来替代经典数仓中的传统工具。此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构
后来随着业务实时性要求的不断提高,人们开始在 离线大数据架构 基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是 Lambda 架构。
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的 Kappa 架构。
2、数据仓库ETL
ETL全称 Extract-Transform-Load,是企业数据应用过程中的一个数据流(pipeline)的控制技术,它是将大量的原始数据经过提取(extract)、转换(transform)、加载(load)到目标存储数据仓库的过程。 ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL负责将分散的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中。ETL 是实施数据仓库的核心和灵魂,ETL规则的设计和实施约占整个数据仓库搭建工作量的 60%~80%。
常见的ETL工具有Kettle,中文名称叫水壶,该项目的概念是把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,无需安装,数据抽取高效稳定。 Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么。Kettle中有两种格式文件,Transformation和Job,Transformation完成针对数据的基础转换,Job则完成整个工作流的控制。
(1)数据提取 extract
抽取(Extract)主要要是针对各个业务系统及不同服务器的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取和缓慢渐变的规则。
在提取阶段,解决的是数据来源问题。主要有以下几种:
- 业务数据 在我们企业运行过程中,会有一些用户的交易数据,如用户的购买订单、退款退货、用户发布的视频、用户的注册信息等等,这些都存在我们的业务数据库里,这些数据库通常是关系型数据库,这是我们获取数据的一个重要来源。
- 文件数据 还有一些数据是有文件的形式存在,比如我们服务器运行的 log,它记录了用户对网站的请求情况,再比如我们通过埋点收集的日志文件,记录了用户的交互。
- 第三方数据 通过第三方购买或者合作形式信用的数据,这些数据可以作为我们业务分析的补充数据。这些数据一般通过和第三方机构的接口(API)形式,对接传输过来。三方的来源、数据形式格式可能有多种多样,就需要我们分别进行对接处理。
数据的格式和形式一般有以下几种:
- 关系型数据库 SQL,RDBMS
- 文件型数据库 NoSQL
- 日志文件
- XML/Html
- JSON
- CSV/TSV(flat files)
Staging Area 为缓存区,在数据加载后进行处理时,将过程中的结果暂时存放起来,有些计算需要一定的硬件资源和时间,设定缓冲区可以对 ETL 有很大有帮助。
提取是把多种多样的原格式数据抽象出来,形成统一的数据格式先放入缓存区,不会直接进入数据仓库,等待下一步转换操作。
(2)数据转换 transform
转换 transform主要为了将数据清洗后的数据转换成数据仓库所需要的数据:来源于不同源系统的同一数据字段的数据字典或者数据格式可能不一样(比如A表中叫id,B表中叫ids),在数据仓库中需要给它们提供统一的数据字典和格式,对数据内容进行归一化;另一方面,数据仓库所需要的某些字段的内容可能是源系统所不具备的,而是需要根据源系统中多个字段的内容共同确定。
这个阶段是ETL的核心环节,也是最复杂的环节。它的主要目标是将抽取到的各种数据,进行数据的清洗、格式的转换、缺失值填补、剔除重复等操作,最终得到一份格式统一、高度结构化、数据质量高、兼容性好的数据,为后续的分析决策提供可靠的数据支持。
根据我们的商业需要,我们用一些规则、方法进行数据处理。一般常见的转换操作有:
- 筛选:筛选部分数据,或者部分字段,提取一部分有用的数据
- 清理:主要是针对源数据库中出现的二义性、重复、不完整、违反业务或逻辑规则等问题的数据进行统一的处理,即清洗掉不符合业务或者没用的的数据。比如通过编写hive或者MR清洗字段中长度不符合要求的数据。缺失值填充、默认值设定、枚举映射等,如将一些编码转为可识别的符号,比如省份代码 sh 转为「上海」
- 合并:将多个属性合并在一起
- 格式转换:,如原数据是一下个时间戳(timestamp),我们为了方便后续分析转换为时间格式,指定时区
- 拆分:将单个属性值拆分为多个属性值,如原为一个邮编,拆分解析成省份、城市等多个字段
- 排序:按期望的数据顺序进行排列
- 计算:如原数据为年龄,用当前年份减去年龄同,取得出生年份
原则:
- 建数仓时尽量保留原始数据,支持多样需求
- 为特定报表时尽量取所需要的数据
(3)数据加载 load
数据加载 load主要是将经过转换的数据装载到数据仓库里面,以方便给数据集市提供。通常的做法是,将处理好的数据写成特定格式(如parquet、csv等)的文件,然后再把文件挂载到指定的表分区上。也有些表的数据量很小,不会采用分区表,而是直接生成最终的数据表。
数据的加载方式一般有以下两种重要类型:
- 全量加载(Full load / Bulk load)
- 增量加载(Incremental load / Refresh load)
全量一般是第一次进行数据加载,这个过程比较长,也有种情况是业务数据存在历史全量数据不停更新的情况,这种情况无论何时都需要全量加载。还有一种情况会追溯一定的时间周期内的数据进行加载,如此业务30天之前的数据不会有再任何变化。
增加加载最为常见,一般一日加载一次,加载上一日数据,也有一周或者一月加载一次的。
加载数据是数据进入数据仓库的最后一步,加载是依赖提取和转换的,因此,加载数据是一个完整的 ETL 过程,这个过程需要大量的数据流转加工时间,而且是周期性重复的工作,所以一般由系统自动完成,执行时间为业务一个最小周期——日(实时数仓会选择更小的时间粒度,如10分钟一次),同时选择业务量小的凌晨进行。
备注:
- 一些小型的数据项目、数据报表也伴随着完整的 etl 过程
- 有时需要实时的 ETL,如推荐、金融反欺诈、反垃圾
3、数据仓库分层模型
数仓分层模式是数据仓库设计中一个十分重要的环节,良好的分层设计能够让整个数据体系更容易被理解和使用。
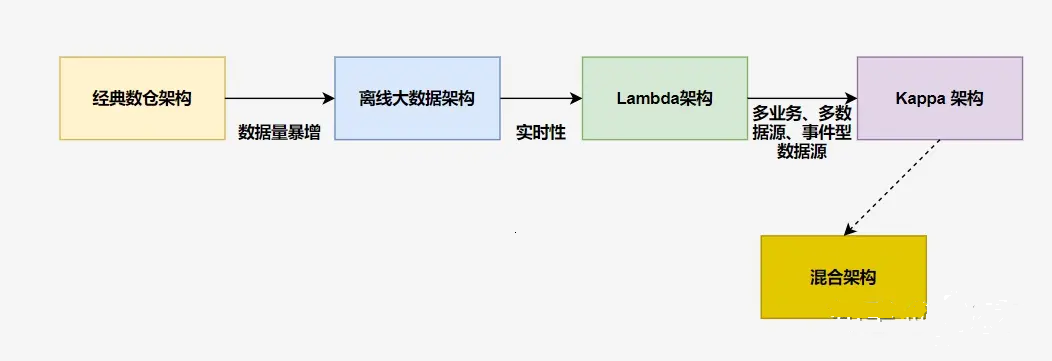
数据仓库从模型层面分为分为4层:

ODS 层: Operation Data Store,数据准备区,贴源层。直接接入源数据的:业务库、埋点日志、消息队列等。DWD 层: Data Warehouse Details, 数据明细层,属于业务层和数据仓库层的隔离层,保持和 ODS 层相同颗粒度。进行数据清洗和规范化操作,去空值/脏数据、离群值等。DWS 层: Data warehouse service,数据服务层,在 DWM 的基础上,整合汇总一个主题的数据服务层。汇总结果一般为宽表,用于 OLAP、数据分发等。ADS 层: Application data service, 数据应用层。其主要功能是保存结果数据,为外部系统提供查询接口,基于数据仓库的数据为企业提供增值应用,并将数据仓库的数据应用于企业决策、报表、分析、控制等领域。ADS层通常采用OLAP(Online Analytical Processing)技术,用于快速访问和查询数据。ADS层一般包括多个宽表,用于支持与企业应用有关的查询、分析、报告、控制、决策等操作。这些宽表一般可以通过BI工具或自定义应用程序查询和访问,以满足企业的各种数据需求。为了提高访问和查询速度,ADS层通常使用数据索引、缓存和预聚合等技术。
有时为了更好地管理和维护数据仓库,可以将ADS层从数据仓库中独立出去,成为一个独立的数据集市层(Data Mart)。数据集市层专门为某一特定业务需求而建立,可以基于某一个特定的主题或者某个业务领域建模,以满足该领域的数据分析和查询需求。
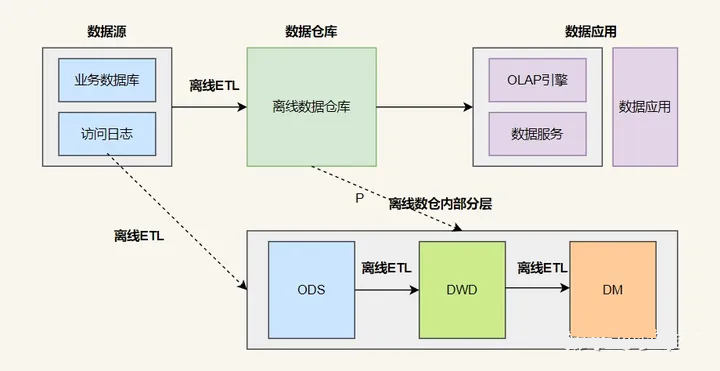
数仓分层模型的优点:
- 划清层次结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:简单来讲可以这样理解,我们最终给下游是直接能使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
- 把复杂问题简单化。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 屏蔽原始数据的异常。屏蔽业务的影响,不必改一次业务就需要重新接入数据。
4、数据中台的内容
数据中台是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。
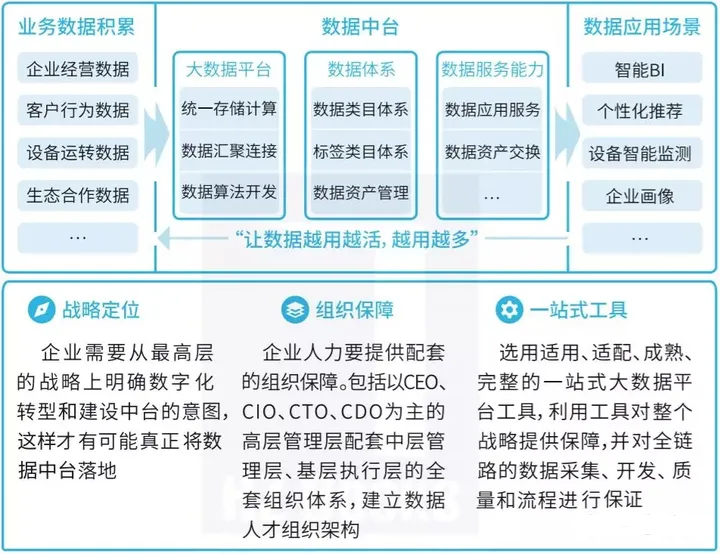
数据中台包含的内容很多,对应到具体工作中的话,它可以包含下面的这些内容:
- 系统架构:以Hadoop、Spark等组件为中心的架构体系
- 数据架构:顶层设计,主题域划分,分层设计,ODS-DW-ADS
- 数据建模:维度建模,业务过程-确定粒度-维度-事实表
- 数据管理:资产管理,元数据管理、质量管理、主数据管理、数据标准、数据安全管理
- 辅助系统:调度系统、ETL系统、监控系统
- 数据服务:数据门户、机器学习数据挖掘、数据查询、分析、报表系统、可视化系统、数据交换分享下载
参考链接:
数据仓库5层 数据仓库的分层架构_mob64ca1417736e的技术博客_51CTO博客
从ODS到ADS,详解数仓分层!
版权归原作者 Java架构何哥 所有, 如有侵权,请联系我们删除。