
一、SparRDD简介
1.RDD 介绍
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
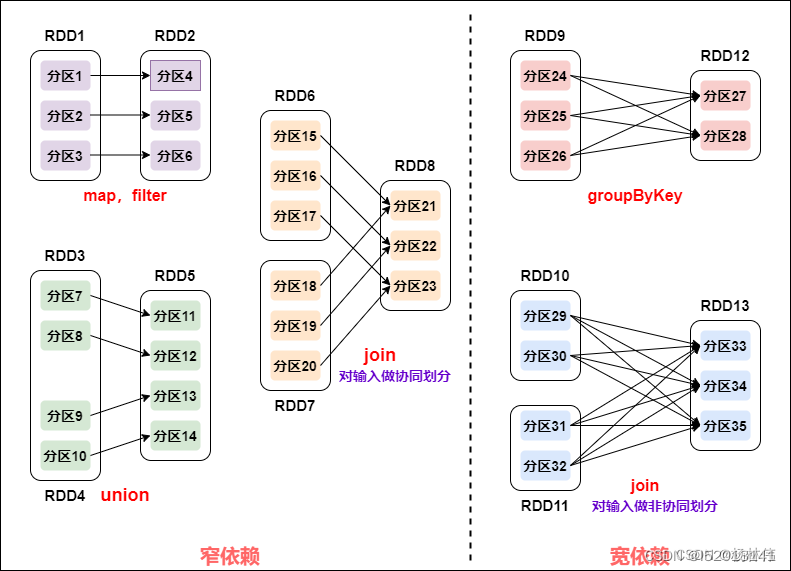
RDD算子分为转换(Transformation)算子和行动( Action)算子,程序运行到转换算子时并不会马上执行转算子,只有碰到行动算子才会真正执行转换算子。
2.RDD 分区
RDD内部的数据集在逻辑上会被划分为多个分区,而在物理上则被分配到多个任务中,以便在分布式计算中进行并行处理。分区的个数决定了计算的并行度,每一个分区内的数据都在一个单独的任务上执行。如果在计算过程中没有指定分区数,那么Spark会采用默认的分区数,默认的分区数为程序运行是分配到的CPU核心数。
3.RDD 创建
创建RDD一般有三种方式:
通过集合创建RDD:使用SparkContext.parallelize方法将集合转成RDD。
通过文件创建RDD:使用SparkContext.textFile方法读取文件内容创建RDD,文件可以是本地文件,也可以是hdfs文件。
通过其他RDD创建RDD,RDD的内容是不可变的,通过RDD算子操作之后会生产新的RDD。
二、SparRDD入门
1、创建 RDD
从集合创建 RDD
val let_data = Array(1, 2, 3, 4, 5)
val let_rdd = sc.parallelize(let_data)

2、从外部文件创建 RDD
val rdd = sc.textFile("file.txt")

1.RDD 常用转换算子
1、map算子
map算子:对输入的每一元素进行处理,生成一对一的结果,有多少条数据进入,就有多少数据出来。
val let_squaredRDD = let_rdd.map(x => x * x)

2、filter算子
根据给定的函数过滤 RDD 中的元素,并返回一个包含满足条件的元素的新 RDD。
val filteredRDD = rdd.filter(x => x % 2 == 0)

3、flatMap算子
类似于 map,但是对每个输入元素生成多个输出元素(返回一个扁平化的结果)。
val let_wordsRDD = let_rdd.flatMap(line => line.split(" "))

4、mapPartitions算子
类似于 map,但是作用于 RDD 的每个分区而不是每个元素,可以减少开销。
val let_rdd = sc.textFile("file.txt")
val let_mappedRDD = let_rdd.mapPartitions(iter => {
iter.map(line => {
val num = line.toInt
num * num
})
})

5、distinct算子
去除 RDD 中的重复元素,并返回一个包含唯一元素的新 RDD。
val let_distinctRDD = let_rdd.distinct()

6、dsortBy算子
根据给定的比较函数对 RDD 中的元素进行排序。
val let_sortedRDD = let_rdd.sortBy(x => x, ascending = false)

2、RDD 常用转换算子
1、collect行动算子
将 RDD 中的所有元素收集到驱动程序节点上,并以数组的形式返回。
val let_result = let_rdd.collect()

2、collect行动算子
将 RDD 中的所有元素收集到驱动程序节点上,并以数组的形式返回。
val let_result = let_rdd.collect()

3、count行动算子
返回 RDD 中元素的数量。
val let_count = let_rdd.count()

4、reduce行动算子
通过一个函数将 RDD 中的元素两两结合,直到将所有元素归约为一个结果。
val let_total = let_rdd.reduce((x, y) => x + y)
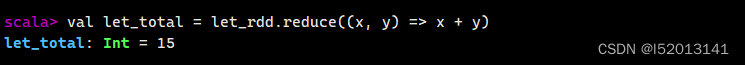
5、take行动算子
val let_firstElements = let_rdd.take(5)

二、SparDataFrame入门
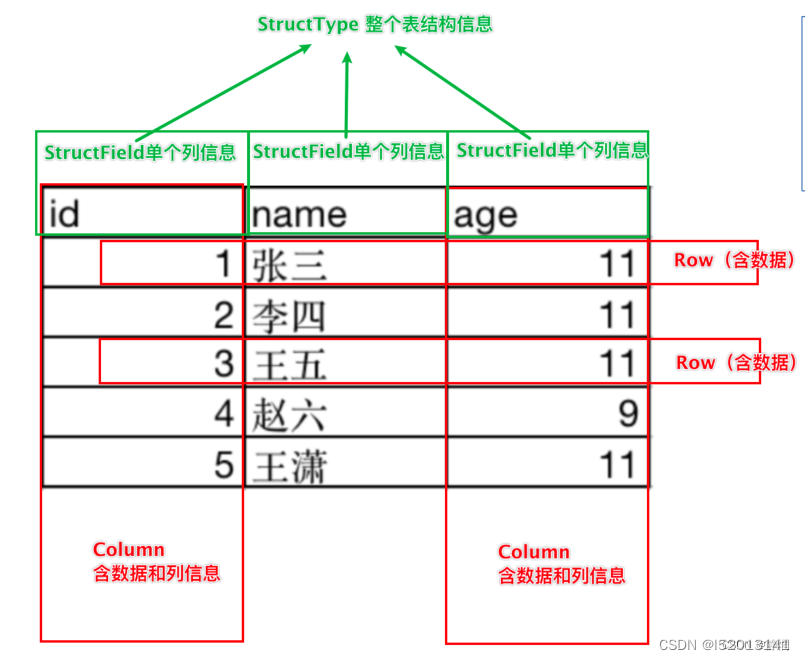
DataFrame是一个二维表结构,那么表格结构就有无法绕开的三个点:
行
列
表结构描述
在MySQL中的一张表:
由许多行组成
数据也被分成多个列
表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提,DataFrame的组成如下:
在结构层面:
StructType对象描述整个DataFrame的表结构
StructField对象描述一个列的信息
在数据层面
Row对象记录一行数据
Column对象记录一列数据并包含列的信息
1、创建SparkDataFrame
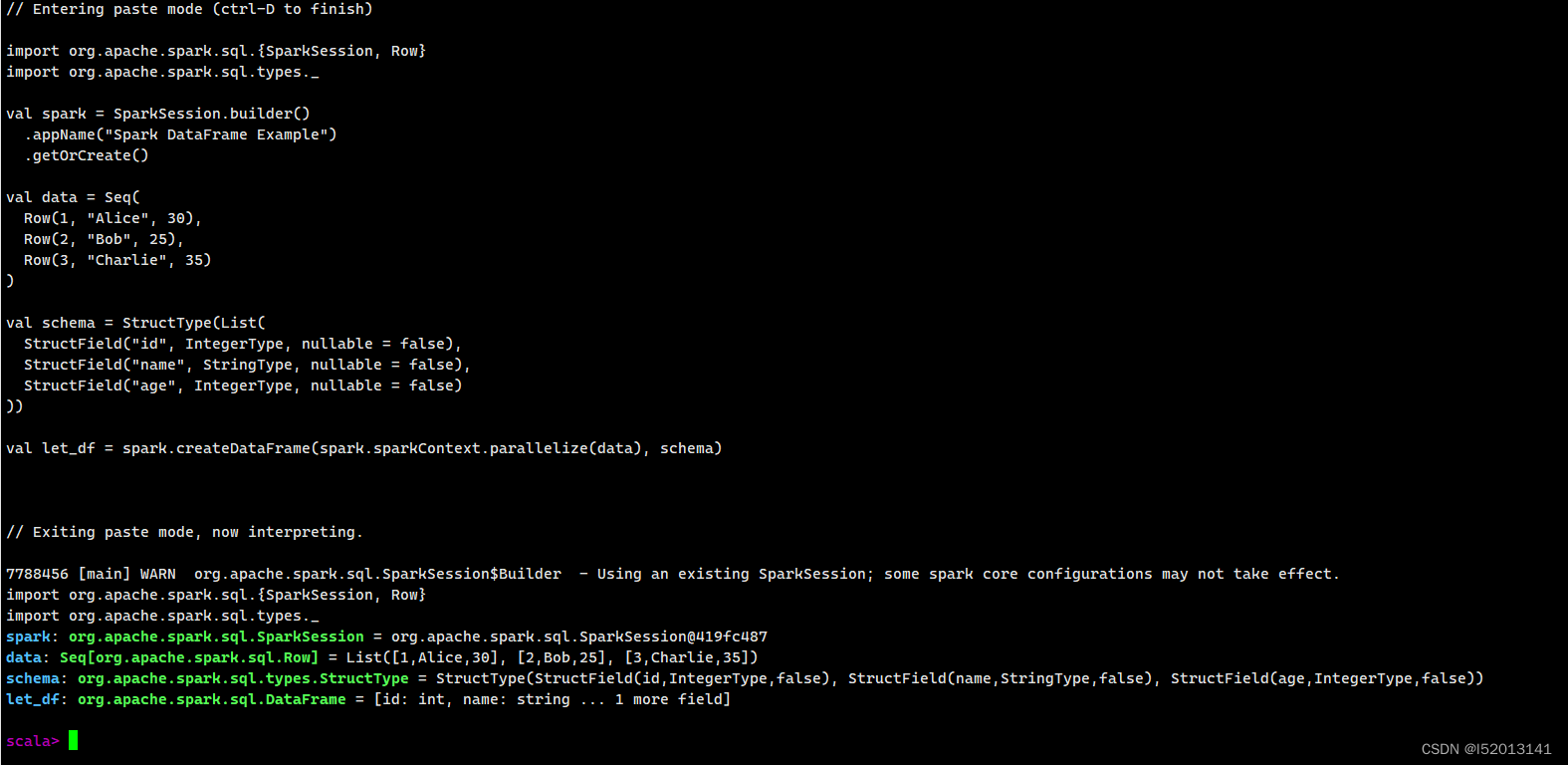
从集合创建 DataFrame
import org.apache.spark.sql.{SparkSession, Row}
import org.apache.spark.sql.types._
val spark = SparkSession.builder()
.appName("Spark DataFrame Example")
.getOrCreate()
val data = Seq(
Row(1, "Alice", 30),
Row(2, "Bob", 25),
Row(3, "Charlie", 35)
)
val schema = StructType(List(
StructField("id", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("age", IntegerType, nullable = false)
))
val let_df = spark.createDataFrame(spark.sparkContext.parallelize(data), schema)
2、从外部数据源创建 DataFrame
val df = spark.read.csv("file.csv")

3、显示 DataFrame 的内容
let_df.show()

3、查看 DataFrame 的结构
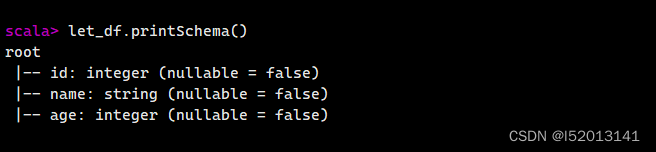
let_df.printSchema()
查询操作
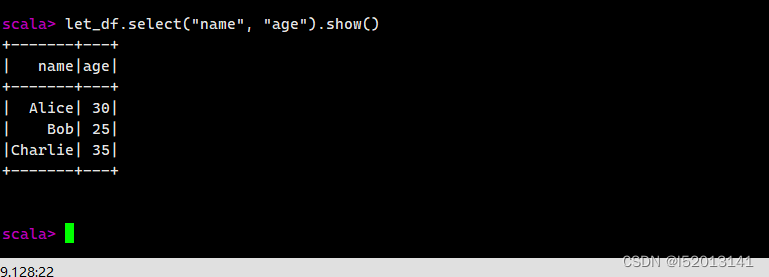
选择列
let_df.select("name", "age").show()
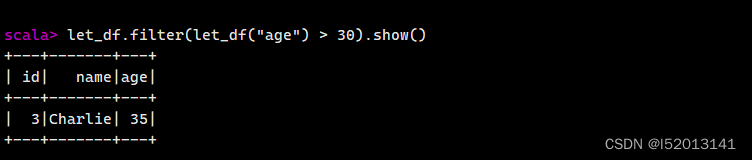
过滤行
let_df.filter(let_df("age") > 30).show()
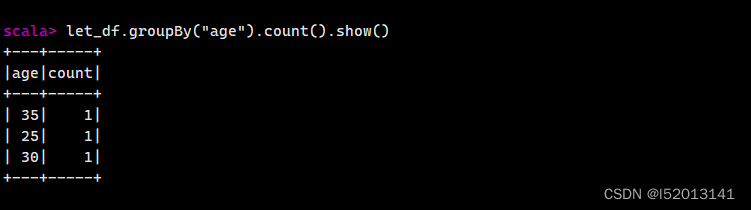
分组聚合
let_df.groupBy("age").count().show()
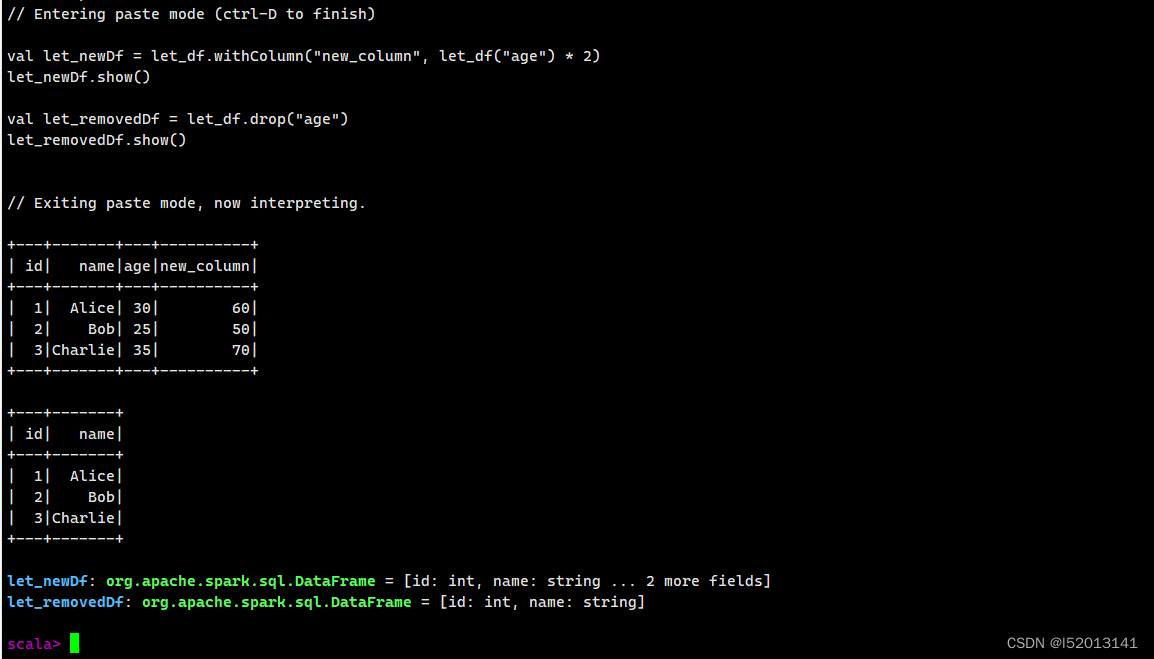
添加和删除列
val let_newDf = let_df.withColumn("new_column", let_df("age") * 2)
let_newDf.show()
val let_removedDf = let_df.drop("age")
let_removedDf.show()
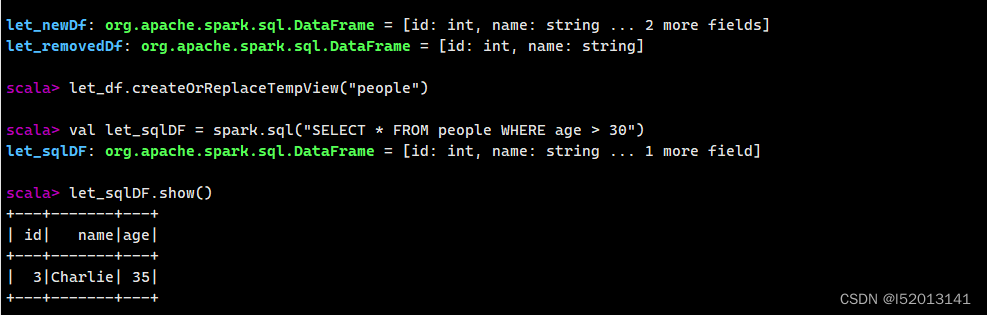
使用 SQL 查询
let_df.createOrReplaceTempView("people")
val let_sqlDF = spark.sql("SELECT * FROM people WHERE age > 30")
let_sqlDF.show()
在本文中,我们探讨了 Spark 中两个重要的数据抽象:Spark RDD 和 Spark DataFrame。Spark RDD 是最初引入的分布式数据集概念,它提供了对数据的低级别控制和操作。它适用于需要对数据进行精细控制的情况,例如复杂的数据处理和算法实现。
与此相比,Spark DataFrame 是在 Spark SQL 中引入的,它提供了更高级别、更方便的 API,使得数据处理更加直观和简单。它更适用于结构化数据和 SQL 操作,以及大规模数据的数据处理和分析。
选择使用哪种数据结构取决于具体的需求和情况。如果你需要对数据进行更复杂的转换和操作,并且对数据的结构不是很了解,那么 Spark DataFrame 可能更适合你。而如果你需要对数据进行更底层的控制,并且更关注性能和灵活性,那么 Spark RDD 可能是更好的选择。
无论你选择使用哪种数据结构,Spark 提供了强大而灵活的工具来处理大规模数据。通过深入了解 Spark RDD 和 Spark DataFrame,你可以更有效地处理和分析数据,并从中获得有价值的见解和洞察。
感谢你阅读本文,希望它能帮助你更好地利用 Spark 进行数据处理和分析!
版权归原作者 l52013141 所有, 如有侵权,请联系我们删除。