
1.初识XML
1.1 定义
XML(EXtensible Markup Language),可扩展标记语言,相比于HTML可以自定义标签,不遵循W3C标准
XML特点:跨平台、跨语言、跨系统。XML与操作系统、编程语言的开发平台无关。
XML作用:①数据交互②使用XML文件配置应用程序和网站
1.2 XML文档结构
**1.文档声明 **包括文档类型:xml 使用的xml版本 使用的字符集
**2.指令 **了解即可,例如CSS
3.标签(元素) 包括标签的属性(属性名=属性值)
**4.文本 **标签之间的内容
示例:
//文档声明
<?xml version=”1.0” encoding=”UTF-8”?>
//引入css指令
<?xml-stylesheet type="text/css" href="t.css"?>
//标签需要成对出现
<books>
<book id=”123”>
//id是属性名,”123”是属性值
《钢铁是怎样练成的》
//成对标签间可以添加文本
</book>
</books>
1.3 XML规范
(1)所有XML元素都必须有结束标签(成对出现或自闭)
(2)XML标签对大小写敏感
(3)XML必须正确的嵌套
(4)同级标签以缩进对齐
(5)元素名称可以包含字母、数字或其他的字符
(6)元素名称不能以数字或者标点符号开始
(7)元素名称中不能含空格
1.4 转义字符
xml中也有一些保留字,常用的有以下内容,可以使用转义符
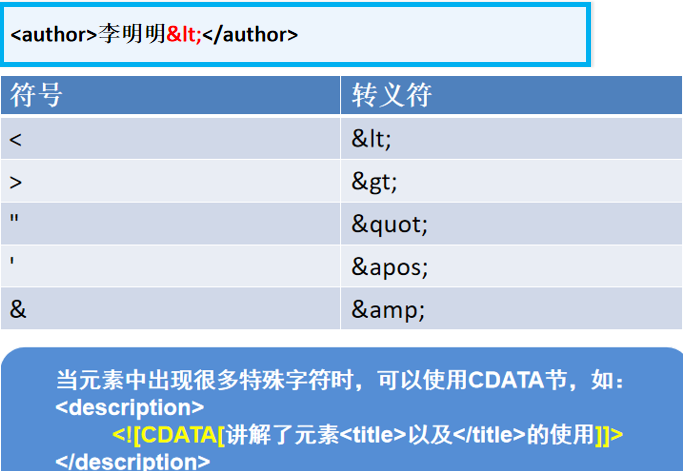
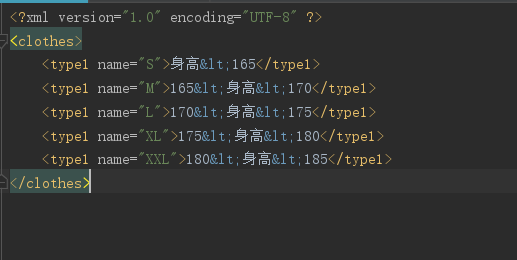
示例:
2.解析XML
2.1 DOM
** **基于XML文档树结构的解析
适用于多次访问的XML文档
特点:比较消耗资源
2.2 SAX
基于事件的解析
适用于大数据量的XML文档
特点:占用资源少,内存消耗小
2.3 Dom4j
基于SAX的依赖库,开源易用,与Java高度兼容,使用广,定义了大量的接口
3.Dom4j实例
3.1 常用接口
Document接口:定义XML文档
Element接口: 定义XML元素
Text接口: 定义XML文本节点
**Attribute接口: ** 定义XML属性
3.2 加载DOM树
测试XML文件
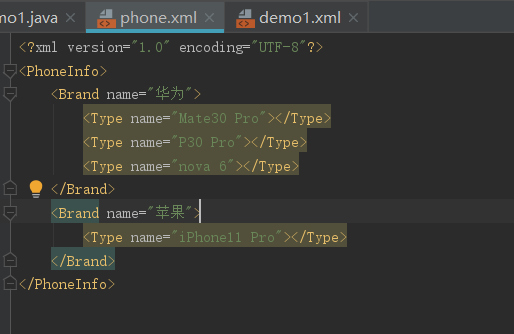
测试类
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
public class Demo1 {
//定义文档对象
Document doc = null;
//创建加载document对象
public void loadXML() throws DocumentException {
//实例化SAXReader对象
SAXReader saxReader = new SAXReader();
//读取phone.xml文件
doc = saxReader.read("src/main/java/phone.xml");
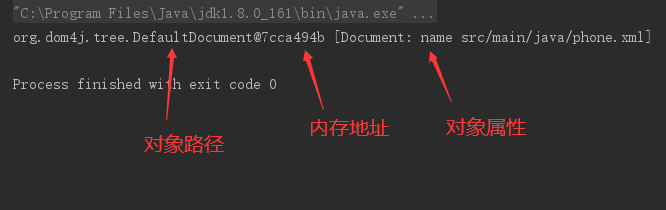
//测试doc对象是否成功
System.out.println(doc);
}
public static void main(String[] args) throws DocumentException {
//测试
Demo1 demo1 = new Demo1();
demo1.loadXML();
}
}
3.3 显示信息
添加findXML()方法
public void findXML(){
//使用Element多态创建实例,获取doc对象中的元素
Element root = doc.getRootElement();
//获取后的对象可以使用迭代器
Iterator brandInfos = root.elementIterator();
while(brandInfos.hasNext()){
Element brandInfo =(Element)brandInfos.next();
System.out.println(brandInfo.attributeValue("name"));
Iterator types = brandInfo.elementIterator();
while(types.hasNext()){
Element type = (Element) types.next();
System.out.println(type.attributeValue("name"));
}
}
}
调用方法后:

3.4 增添新的标签和属性
添加addXML()方法
public void addXML(){
Element root = doc.getRootElement();
//addElement(元素名)添加元素
Element brandInfo = root.addElement("Brand");
//addAttribute(属性名,属性值)添加属性
brandInfo.addAttribute("name","三星");
Element type = brandInfo.addElement("Type");
type.addAttribute("name","Galaxy 11");
}
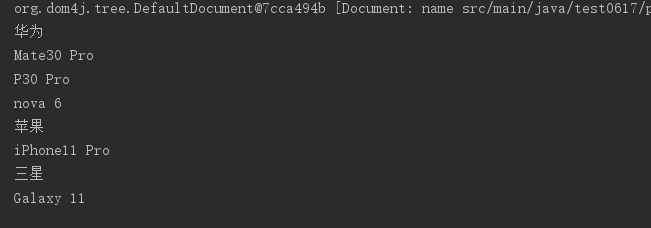
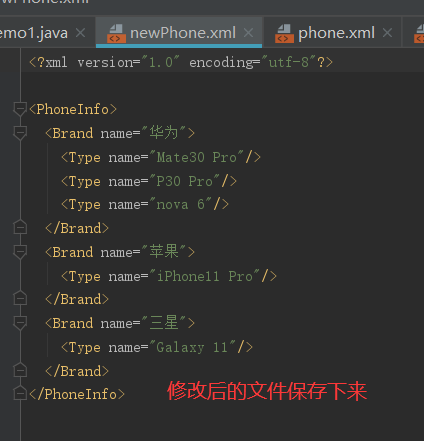
3.5 保存修改后的XML文件
添加saveXML()方法
//保存信息
public void saveXML(String path) throws IOException {
//创建输出流格式对象
OutputFormat format = OutputFormat.createPrettyPrint();
//设置字符集
format.setEncoding("utf-8");
//创建输出流
XMLWriter writer = new XMLWriter(new FileWriter(path),format);
//写出文件
writer.write(doc);
//关闭流
writer.close();
}
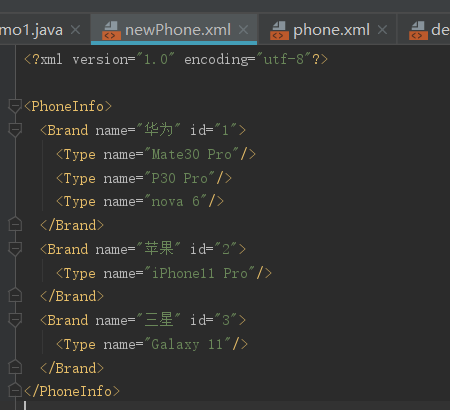
3.6 添加id属性并更新
添加updateXML()方法
//修改信息
public void updateXML() throws IOException {
Element root = doc.getRootElement();
Iterator brands = root.elementIterator();
int id = 0;
while(brands.hasNext()){
Element brand = (Element) brands.next();
id++;
brand.addAttribute("id",id+"");
saveXML("src/main/java/test0617/newPhone.xml");
}
}
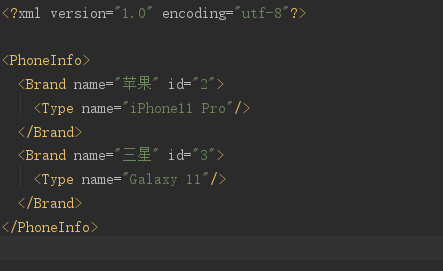
3.7 删除信息
添加delete()方法
//删除元素
public void delete() throws IOException {
Element root = doc.getRootElement();
Iterator brandInfo = root.elementIterator();
while(brandInfo.hasNext()){
Element brand = (Element) brandInfo.next();
//判断当前节点的name值是否为"华为"
if(brand.attributeValue("name").equals("华为")){
//删除父节点下的当前节点
brand.getParent().remove(brand);
break;
}
}
saveXML("src/main/java/test0617/newPhone.xml");
}
标签:
xml
本文转载自: https://blog.csdn.net/weixin_52071901/article/details/131300262
版权归原作者 努力的泽泽 所有, 如有侵权,请联系我们删除。
版权归原作者 努力的泽泽 所有, 如有侵权,请联系我们删除。