
jmeter---- 详解
详解(测试计划Test Plan、线程组、逻辑控制器、取样器、配置元件、前置处理器、定时器、后置处理器、断言、监听器)
1.测试计划Test Plan
它是JMeter测试元件的容器,所有内容都放在测试计划里。
详解:
1)名称(Name)测试计划名字
2)注释(Comments):关于该测试计划的注释
3)用户定义的变量(User Defined Variables):可以定义整个测试中使用的重复值(全局变量:如iP、port,然后再在http请求处用
i
p
,
{ip},
ip,{port}
4)独立运行每个线程组(Run Thread Groups consecutively):默认不勾选,不勾选表示各自运行自己的,两个线程组时不是顺序执行(是并行执行),勾选后,普通线程组之间间按上下排列顺序执行,而非默认的并行。也可用来设置混合场景。
5)主线程结束后运行tearDown线程组(Run tearDownThread Groups after shutdown of main threads),保持默认即可。
6)函数测试模式:压测的时候不选择,否则影响性能,保持默认。
7)添加classpath:添加目录或者jira包到classpath,类路径设置,可以添加jar文件的目录到特定的测试计划(也可以直接把jar包放到jmeter的lib目录(默认的classpath)),添加后需重启jmeter
2.线程组:可以理解为不同的场景,单场景,混合场景、稳定性场景。
1)线程组Thread Group:给服务器发请求的,发送压力。
详解:
A.在取样器错误后要执行的动作:
a.继续,线程出错继续执行(默认)
b. 启动下一线程循环
c.停止线程:3个线程循环2次,如果第二个线程出问题,这个线程就停止,继续运行其余线程
d.停止测试:把线程运行的请求运行完才停止
e.立即停止测试:立刻停止
B.线程属性
a.线程数:线程占用内存资源导致内存溢出、创建线程消耗cpu(线程数设置多少合适?结合目标tps以及rt,如果应用处理快,可以设置少点,目标tps500,一个线程tps50,500/50就是100个线程,100-200个线程)
b.Ramp-Up时间(秒):线程在多少秒内启动.
如果线程数是100,Ramp-Up设置为10,表示10秒内启动100线程,但是不一定是每秒启动10个线程.
c.循环次数:迭代次数(作用于整个线程组)压测时勾选永远,持续运行一段时间。循环控制器
d.Delay Thread creation until needed,延迟创建线程,直到需要创建时创建
e.调度器配置:持续时间(最终的持续时间包含了启动线程数时间),勾选上。
jmeter自带线程组设计阶梯加压:
场景:服务器响应很快时间短,若想一次性多加几个线程,可能得不到完整的tps曲线,这种就建议线程一个递增一个递增。
f.启动延迟:定时启动
2)jp@gc - Stepping Thread Group:场景:一次想着增加多个线程,每个阶梯比较明显的阶梯加压,和自带的比,多了阶梯加压完成后,还可以设置持续运行多少时间,自带的,虽然没有明显的阶梯,但是场景还是有意义。
处理慢可以多加几个线程,可以多线程处理。多跑几个线程,tps增加起来。
3)setUp线程组:执行前执行一次,应用场景初始化数据。
4)tearDown线程组:执行后执行一次,做关闭连接、清除垃圾数据等收尾工作。
3.逻辑控制器Logic Controller
1)事务控制器(场景:把多个请求或一个流程定义为事务,就需要添加一个事务控制器,则需要将事务控器中的generate parent sample勾选上,目的是为了聚合报告只显示一个结果。如:登录、添加商品、查询。
2)吞吐量控制器(比较重要)
模拟生产环境、模拟真实业务
业务模型(生产环境上有不同的业务,跑业务时需要去统计业务比例。
压测的话就需要模拟这个业务模型,根据业务比例设计到压测脚本中)
a.业务之间有关联
单测接口,关联转参数化,先跑被依赖接口,然后把要依赖的数据放获取到,放到文件里,压测的接口通过参数化的方式获取文件的值。
b.业务之间没关联:业务比例统计出后,假设是业务1:业务2:业务3是2:1:1,在吞吐量控制器设计一下比例percent–吞吐量业务1是150,业务2是25.业务3是25
3)仅一次控制器
场景:某一个请求只执行一次,后面的请求反复执行。如:只登录一次,反复添加用户。
4)ForEach控制器
场景:把返回的name全部获取到,然后遍历name的值,作为另一个请求的入参,就需要通过正则把name获取到,看Name的左右边界,左边界好确认,右边界不好确认(有空格),获取多个name:正则表达式name=(.*?)\s+
把这获取多个的值作为下一个请求的入参
forech处
输入变量前缀:name;
开始循环字段:0
结束循环字段:${name_match}
输出变量名称:name,下一个请求通过这个变量来获取。
4.取样器sampler
5.配置元件ConfigElement
1)CSV 数据文件设置:参数化实现,大量数据。
用户定义的变量(全局)这种有局限性。
1)文件名:测试计划下的相对路径或绝对路径、不要放中文路径下、路径不要包含空格、特殊字符。可以参数化(可以动态获取文件名称前的路径就更方便:测试计划–添加–非测试元件–属性显示–system–use.dir启动jmeter所在的目录,file.separtor表示分隔符、属性获取是通过函数获取函数助手–p,user.dir,
window上的文件名:测试计划–添加–非测试元件–属性显示–system–use.dir启动jmeter所在的目录,file.separtor表示分隔符、属性获取是通过函数获取函数助手–p,user.dir,
linux上的文件名:测试计划–添加–非测试元件–属性显示–system–use.dir,file.separtor表示分隔符
windows启动jmeter:jmeter.bat
linux启动jmeter:jmeter.sh
2)文件编码:一般选择UTF-8
3)变量名称(西文逗号间隔):参数文件中每列的名称,如有多列,用英文逗号间隔,如果只有一列,则不加分隔符
4)忽略首行(只在设置了变量名称后才生效):如果参数文件中有很多列,为了区分每列,就在首行把列名写上,此时就要选True
5)分隔符(用’\t’代表制表符):是变量值的分隔符,分隔符就是英文逗号。
6)是否允许带引号?:如果是False,请求中保留引号(默认),如果是True:请求中去掉引号
7)遇到文件结束符再次循环?Recycle on EOF? :True表示循环,False就取值EOF,一般保持默认False。如果数据不能重复利用,尽量造足量数据。Edit,在没有参数的时候会根据定义的内容来调用函数或变量
8)遇到文件结束符结束线程?Stop thread on EOF?:值不够,是否停止线程,一般保持默认False。如果设置为True,那么“Recycle on EOF?”设置的True将失效
9)线程共享模式Sharing mode
a.所有现场All threads【每次迭代,唯一】:默认值
结论:多个线程组取值不一样,每个线程组内的线程取值也不一样
b.当前线程Current thread【每次迭代,顺序】
结论:多个线程组取值一样,每个线程组内的线程取值也一样
c.当前线程组Current thread group
结论:多个线程组取值一样,每个线程组内的线程取值不一样
2)HTTP信息头管理器
比如:传的json数据:名称:content-type 值:application/json(在jmeter中需要显示发送的数据类型)
3)HTTP Cookie管理器:ui端请求,建议加上,比如,登录完了有cookie,重定向时没cookie,就又跳转到登录页面,提示没有登录(前后端不分离的项目)
4)HTTP请求默认值:应用场景(相同的脚本,测试不同的环境):测试、演练、灰度。填写协议、ip、端口、公共参数等
5)JDBC Connection Configuration
5)计数器:主要用来生成指定格式的值,和所有现场取值策略是一样的。计数器只是用它生成的数据用作唯一,csv可以定义很多列。
压测过程中需要知道他的取值策略是什么。
一个线程组时:相同线程、不同线程的取值都是不一样。
两个线程组时:不同线程组的取值不一样。
6.前置处理器Pre Processors
BeanShell 预处理程序
7.定时器Timer【不建议使用】
a.固定定时器
b.高斯随机定时器
不是定时的,而是随机的。
偏差100
固定延迟偏移200
那么取值的时间200-400ms
c.同步定时器(集合点)
模拟用户组数量(集合线程数)、超时时间,模拟用户组数量设为0,超时时间设置为0,意思是集合线程数没有达到200,一直等待。(设置的集合线程数比线程组的线程数大就一直等待,即需要集合线程数小于等于线程组的线程数)
超时时间为0就永远等待
场景:模拟大量的用户同时给服务器发送压力,就用同步定时器,发现客户端发送的时间并不是一致,也没有集合,也是有先后顺序的,不是秒杀和抢购场景建议不用。
8.后置处理器Post Processors
1)正则表达式提取器(较重要)
场景:服务器返回的数据非json用正则表达式,关联。
关联:下一个请求的入参要依赖与上一个请求返回的值(即服务器的合法性校验,做数据的增删改查建立关系)
正则基础:
正则表达式提取器详解:
1)应用Apply to
默认是主请求中取,Main sample and sub-sample and sub-samples
Main sample only 其它子请求,前面的子请求的code一般都是302,响应结果展示到最后一个子请求中,有子请求去子请求中获取。
2)要检查的响应字段:用得最多的是【主体】,其次是【信息头】,其他很少用
主体:header + body,可以从header,也可以从body取值,默认
引用名称:变量名,由用户自定义
正则表达式:用来获取服务器响应值的正则表达式、括起来的部分就是要提取的、写法左边界(.?)右边界(大部分情况有效)name=‘’(.?)“,age=”(.*?)"
模板:填写的是位置变量
N
N
N,
1
1
1
2
2
2获取两个值,
1
1
1-
2
2
2获取到的值就是Anal-18
匹配数字:0代表随机取值,
1表示第一个,
正整数代表提取第几个匹配的内容模板中每个模板都取第一个
-1代表全部取值(此时提取结果是一个数组,一般会和逻辑控器中的foreach并列使用, 哪怕结果只有一个值,如果匹配第一个,除了数字选择1,还可以通过
n
a
m
e
1
的
方
式
来
取
第
1
个
匹
配
的
内
容
,
{name_1}的方式来取第1个匹配的内容,
name1的方式来取第1个匹配的内容,{name_2}来取第2个匹配的内容,name是引用名称)
缺省值:最好是有特征的,方便出错的时候看报错信息,比如:----------
2)调试后置处理程序Debug PostProcessor:用于调试,放在取样器下面。
查看结果树–响应数据,里面的JMeterVariables,要引用,都可以${变量名}的方式获取
3)jp@gc - JSON/YAML Path Extractor(较重要,自动化也会用到)
场景:服务器返回json格式数据,关联。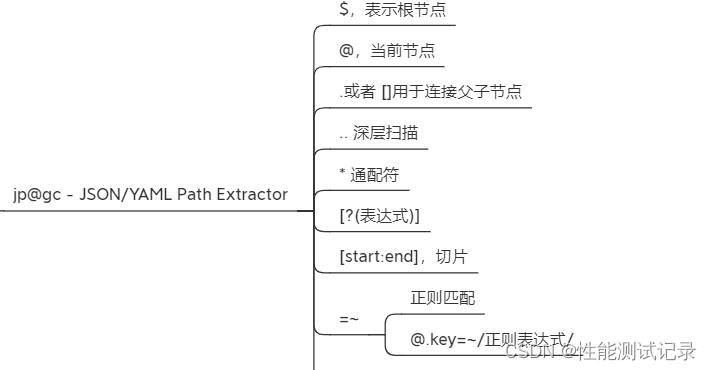
首先安装这个插件,jmeterGUi界面上最后一个图标。
Input Format:JSON
变量名
取所有uuid
.
d
a
t
a
.
r
e
s
u
t
s
[
∗
]
.
u
u
i
d
或
者
.data.resuts[*].uuid或者
.data.resuts[∗].uuid或者…uuid
取第一个uuid
.
d
a
t
a
.
r
e
s
u
t
s
[
0
]
.
u
u
i
d
或
者
.data.resuts[0].uuid或者
.data.resuts[0].uuid或者…resuts[0].uuid
取前三个uuid
$…results[1,3].uuid
同时获取两个字段值uuid,showname
$…results[1,3].[“uuid”,“showname”]
获取带条件的
获取showname为测试01的
$…results[?(@.showname==‘测试01’)]
获取正则表达式的,获取showname包含测试的uuid
$…results[?(@.showname=~/.测试./)].uuid
4)BeanShell 后置处理程序
9.断言Assertions
请求成功(返回200),不代表业务成功,业务的成功,只能靠业务来判断。
检查点不要检查中文(检查元素)
jmeter最佳实践说少加
加不加?根据实际情况
官网说是:单场景(比如非查询单接口,可以不加),可以通过统计数据库方式看成功率;监控过程中,就tail -f统计错误日志,或者通过日志平台查询接口,建议加,也可以统计日志方式看成功率为了方便(压力机性能好的情况下):单场景:建议查询加,非查询不加 混合场景:建议每个请求接口都加。
1)响应断言:
详解:
应用:一般勾选“main sample only” 就足够了,默认
重定向的请求(勾选了“跟随重定向”)那么就有main sample和sub-sample之分
测试字段:
模式匹配规则:
2)断言持续时间:响应时间大于这个值,就报错 ,会忽略思考时间
http请求–高级–超时、响应比较
3)BeanShell断言
10.监听器Listener
调试脚本用,调试成功后禁用,否则影响性能
1)查看结果树:或者只显示错误的,默认是接收返回数据但是不保存,要保存什么数据就勾选配置,默认情况下,不保存响应结果Save Response Data (XML)
2)聚合报告
非要用Gui的方式压测的话,聚合报告还是可以看的,适用于快速把所有现场启动起来,要跑长一点时间,此时才接近于阶梯加压的tps,这个聚合报告对阶梯加压方式来说是没有意义的。
一般看90%
3)用表格察看结果
GUI方式,不建议压测。
jp@gc - Transactions per Second(tps)
jp@gc - Response Times Over Time(RT)
jp@gc - Active Threads Over Time
说明:运行的时候,监听器用得越少越好,尽可能只用一种监听器作结果记录,否则会十分影响性能
插件都放在lib目录下,重启一下Jmeter
非Gui其实很少用,一般只是少量线程验证。
真正压测要跑目标值,最大值一般都是通过非GUI模式把脚本传到linux服务器上跑。
压测过程中还需要看响应时间,响应时间蹭蹭往上涨就开始出现就已经开始出现瓶颈,偶尔有相应时间比较高,有可能是网络波动、资源竞争、tps如果是频繁的话,就需要关注。
版权归原作者 叮当!* 所有, 如有侵权,请联系我们删除。