
程序员面试题库分享
1、前端面试题库 (面试必备)** 推荐:★★★★★**
地址:前端面试题库
2、前端技术导航大全 推荐:★★★★★
地址:前端技术导航大全
3、开发者颜色值转换工具 推荐:★★★★★
地址 :开发者颜色值转换工具
1、为什么typeof null 是object?
不同的数据类型在底层都是通过二进制表示的,二进制前三位为
000
则会被判断为
object
类型,
而null底层的二进制全都是0,那前三位肯定也是
000
,所以被判断为
object
2、0.1 + 0.2 === 0.3,对吗?不对
JavaScript的计算存在精度丢失问题
- 原因:JavaScript中小数是浮点数,需转二进制进行运算,有些小数无法用二进制表示,所以只能取近似值,所以造成误差
- 解决方法: - 先变成整数运算,然后再变回小数- toFixed() 性能不好,不推荐
3、addEventListence的第三个参数是干嘛的?
xxx.addEventListence('click', function(){}, false)
第三个变量传一个布尔值,需不需要阻止冒泡,默认是false,不阻止冒泡
4、Ajax、Axios、Fetch有啥区别?
- Ajax:是对XMLHttpRequest对象(XHR)的封装
- Axios:是基于Promise对XHR对象的封装
- Fetch:是window的一个方法,也是基于Promise,但是与XHR无关,不支持IE
5、load、$(document).ready、DOMContentLoaded的区别?
DOM文档加载的步骤为:
- 1、解析HTML结构。
- 2、加载外部脚本和样式表文件。
- 3、解析并执行脚本代码。
- 4、DOM树构建完成。//
DOMContentLoaded触发、$(document).ready触发 - 5、加载图片等外部文件。
- 6、页面加载完毕。//
load触发
6、如何实现数组去重?

// 使用 Map 去重
function quchong1(arr) {
const newArr = []
arr.reduce((pre, next) => {
if (!pre.get(next)) {
pre.set(next, 1)
newArr.push(next)
}
return pre
}, new Map())
return newArr
}
// 使用 Set 去重
function quchong (arr) {
return [...new Set(arr)]
}

7、call、apply、bind改变this
const obj1 = {
name: '林三心',
sayName: function() {
console.log(this.name)
}
}
const obj2 = {
name: 'Sunshin_Lin'
}
// 改变sayName的this指向obj2
obj1.sayName.call(obj2) // Sunshin_Lin
// 改变sayName的this指向obj2
obj1.sayName.apply(obj2) // Sunshin_Lin
// 改变sayName的this指向obj2
const fn = obj1.sayName.bind(obj2)
fn() // Sunshin_Lin

8、BOM 和 DOM 的关系
BOM全称Browser Object Model,即浏览器对象模型,主要处理浏览器窗口和框架。
DOM全称Document Object Model,即文档对象模型,是 HTML 和XML 的应用程序接口(API),遵循W3C 的标准,所有浏览器公共遵守的标准。
JS是通过访问BOM(Browser Object Model)对象来访问、控制、修改客户端(浏览器),由于BOM的window包含了document,window对象的属性和方法是直接可以使用而且被感知的,
因此可以直接使用window对象的document属性,通过document属性就可以访问、检索、修改XHTML文档内容与结构。因为document对象又是DOM的根节点。
可以说,BOM包含了DOM(对象),浏览器提供出来给予访问的是BOM对象,从BOM对象再访问到DOM对象,从而js可以操作浏览器以及浏览器读取到的文档。
9、JS中的substr()和substring()函数有什么区别
substr() 函数的形式为substr(startIndex,length)。 它从startIndex返回子字符串并返回'length'个字符数。
var s = "hello";
( s.substr(1,4) == "ello" ) // true
substring() 函数的形式为substring(startIndex,endIndex)。 它返回从startIndex到endIndex - 1的子字符串。
var s = "hello";
( s.substring(1,4) == "ell" ) // true
10、Object和Map的区别
JavaScript 的对象(Object),本质上是键值对的集合(Hash 结构),但是传统上只能用字符串当作键。这给它的使用带来了很大的限制。

const m = new Map();
const o = {p: 'Hello World'};
m.set(o, 'content')
m.get(o) // "content"
m.has(o) // true
m.delete(o) // true
m.has(o) // false
将对象
o
当作
m
的一个键,然后又使用
get
方法读取这个键,接着使用
delete
方法删除了这个键。

const map = new Map([
['name', '张三'],
['title', 'Author']
]);
map.size // 2
map.has('name') // true
map.get('name') // "张三"
map.has('title') // true
map.get('title') // "Author"

Map 也可以接受一个数组作为参数。该数组的成员是一个个表示键值对的数组。
const map = new Map();
map.set(['a'], 555);
map.get(['a']) // undefined
上面代码的
set
和
get
方法,表面是针对同一个键,但实际上这是两个不同的数组实例,内存地址是不一样的,因此
get
方法无法读取该键,返回
undefined
。

const map = new Map();
const k1 = ['a'];
const k2 = ['a'];
map
.set(k1, 111)
.set(k2, 222);
map.get(k1) // 111
map.get(k2) // 222

Map 的键实际上是跟内存地址绑定的,只要内存地址不一样,就视为两个键。
这就解决了同名属性碰撞(clash)的问题,我们扩展别人的库的时候,如果使用对象作为键名,就不用担心自己的属性与原作者的属性同名。
let map = new Map()
.set(1, 'a')
.set(2, 'b')
.set(3, 'c');
set
方法返回的是当前的
Map
对象,因此可以采用链式写法。
11、weakMap
WeakMap
只接受对象作为键名(
null
除外),不接受其他类型的值作为键名
用途:

let myWeakmap = new WeakMap();
myWeakmap.set(
document.getElementById('logo'),
{timesClicked: 0})
;
document.getElementById('logo').addEventListener('click', function() {
let logoData = myWeakmap.get(document.getElementById('logo'));
logoData.timesClicked++;
}, false);
上面代码中,
document.getElementById('logo')
是一个 DOM 节点,每当发生
click
事件,就更新一下状态。
我们将这个状态作为键值放在 WeakMap 里,对应的键名就是这个节点对象。一旦这个 DOM 节点删除,该状态就会自动消失,不存在内存泄漏风险。
12、(a == 1 && a == 2 && a ==3) 有可能是 true 吗?
当两个类型不同时进行==比较时,会将一个类型转为另一个类型,然后再进行比较。
比如
Object
类型与
Number
类型进行比较时,
Object
类型会转换为
Number
类型。
Object
转换为
Number
时,会尝试调用
Object.valueOf()
和
Object.toString()
来获取对应的数字基本类型。
var a = {
i: 1,
toString: function () {
return a.i++;
}
}
console.log(a == 1 && a == 2 && a == 3) // true
13、函数的length是多少?
可以看出,
function
有多少个形参,
length
就是多少;
但是如果有默认参数,就是
第一个具有默认值之前的参数个数;剩余参数是不算进
length
的计算之中的
function fn1 (name) {}
function fn2 (name = '仙人掌') {}
function fn3 (name, age = 22) {}
function fn4 (name, age = 22, gender) {}
function fn5(name = '仙人掌', age, gender) { }
console.log(fn1.length) // 1
console.log(fn2.length) // 0
console.log(fn3.length) // 1
console.log(fn4.length) // 1
console.log(fn5.length) // 0
//剩余参数
function fn6(name, ...args) {}
console.log(fn6.length) // 1
14、includes 比 indexOf好在哪?
includes可以检测
NaN
,indexOf不能检测
NaN
,includes内部使用了
Number.isNaN
对
NaN
进行了匹配
15、map、object和set的区别
map:对象保存键值对。任何值(对象或者原始值) 都可以作为一个键或一个值。构造函数
Map
可以接受一个数组作为参数。
object:
- 一个
Object的键只能是字符串或者Symbols,但一个Map的键可以是任意值。 Map中的键值是有序的(FIFO 原则),而添加到对象中的键则不是。Map的键值对个数可以从 size 属性获取,而Object的键值对个数只能手动计算。Object都有自己的原型,原型链上的键名有可能和你自己在对象上的设置的键名产生冲突。
set:对象允许你存储任何类型的值,无论是原始值或者是对象引用。它类似于数组,但是成员的值都是唯一的,没有重复的值。
总结:
- 初始化需要的值不一样,Map需要的是一个二维数组,而Set 需要的是一维 Array 数组
- Map 和 Set 都不允许键重复
- Map的键是不能修改,但是键对应的值是可以修改的;Set不能通过迭代器来改变Set的值,因为Set的值就是键。
- Map 是键值对的存在,值也不作为健;而 Set 没有 value 只有 key,value 就是 key;
16、vue和react的diff算法的区别
vue和react的diff算法,都是忽略跨级比较,只做同级比较。vue diff时调动patch函数,参数是vnode和oldVnode,分别代表新旧节点。
vue比对节点,当节点元素类型相同,但是className不同,认为是不同类型元素,删除重建,而react会认为是同类型节点,只是修改节点属性
vue的列表比对,采用从两端到中间的比对方式,而react则采用从左到右依次比对的方式。当一个集合,只是把最后一个节点移动到了第一个,react会把前面的节点依次移动,而vue只会把最后一个节点移动到第一个。总体上,vue的对比方式更高效。
虚拟dom:一个用来标识真实DOM的对象
<ul id="list">
<li class="item">哈哈</li>
<li class="item">呵呵</li>
<li class="item">嘿嘿</li>
</ul>
对应的虚拟dom为:
let oldVDOM = { // 旧虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: ['哈哈']
},
{
tagName: 'li', props: { class: 'item' }, children: ['呵呵']
},
{
tagName: 'li', props: { class: 'item' }, children: ['嘿嘿']
},
]
}
这时候,我修改一个
li标签
的文本:
<ul id="list">
<li class="item">哈哈</li>
<li class="item">呵呵</li>
<li class="item">哈哈哈哈</li> // 修改
</ul>
这就是咱们平常说的
新旧两个虚拟DOM
,这个时候的
新虚拟DOM
是数据的最新状态,那么我们直接拿
新虚拟DOM
去渲染成
真实DOM
的话,效率真的会比直接操作真实DOM高吗?那肯定是不会的,看下图:
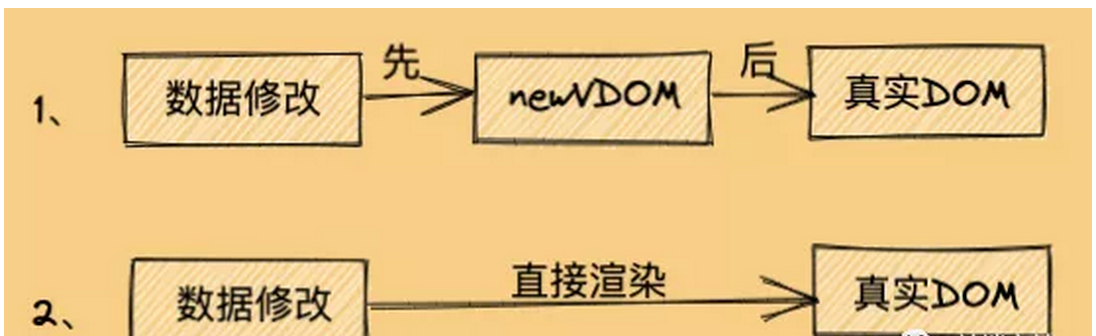
由上图,一看便知,肯定是第2种方式比较快,因为第1种方式中间还夹着一个
虚拟DOM
的步骤,所以虚拟DOM比真实DOM快这句话其实是错的,或者说是不严谨的。那正确的说法是什么呢?虚拟DOM算法操作真实DOM,性能高于直接操作真实DOM,
虚拟DOM
和
虚拟DOM算法
是两种概念。
虚拟DOM算法 = 虚拟DOM + Diff算法
什么是Diff算法
上面说了
虚拟DOM
,也知道了只有
虚拟DOM + Diff算法
才能真正的提高性能,那讲完
虚拟DOM
,我们再来讲讲
Diff算法
吧,还是上面的例子

上图中,其实只有一个li标签修改了文本,其他都是不变的,所以没必要所有的节点都要更新,只更新这个li标签就行,Diff算法就是查出这个li标签的算法。
总结:Diff算法是一种对比算法。对比两者是
旧虚拟DOM和新虚拟DOM
,对比出是哪个
虚拟节点
更改了,找出这个
虚拟节点
,并只更新这个虚拟节点所对应的
真实节点
,而不用更新其他数据没发生改变的节点,实现
精准
地更新真实DOM,进而
提高效率
。
使用虚拟DOM算法的损耗计算
:总损耗 = 虚拟DOM增删改+(与Diff算法效率有关)真实DOM差异增删改+(较少的节点)排版与重绘
直接操作真实DOM的损耗计算
:总损耗 = 真实DOM完全增删改+(可能较多的节点)排版与重绘
Diff算法的原理
Diff同层对比
新旧虚拟DOM对比的时候,Diff算法比较只会在同层级进行, 不会跨层级比较。所以Diff算法是:
广度优先算法
。 时间复杂度:
O(n)
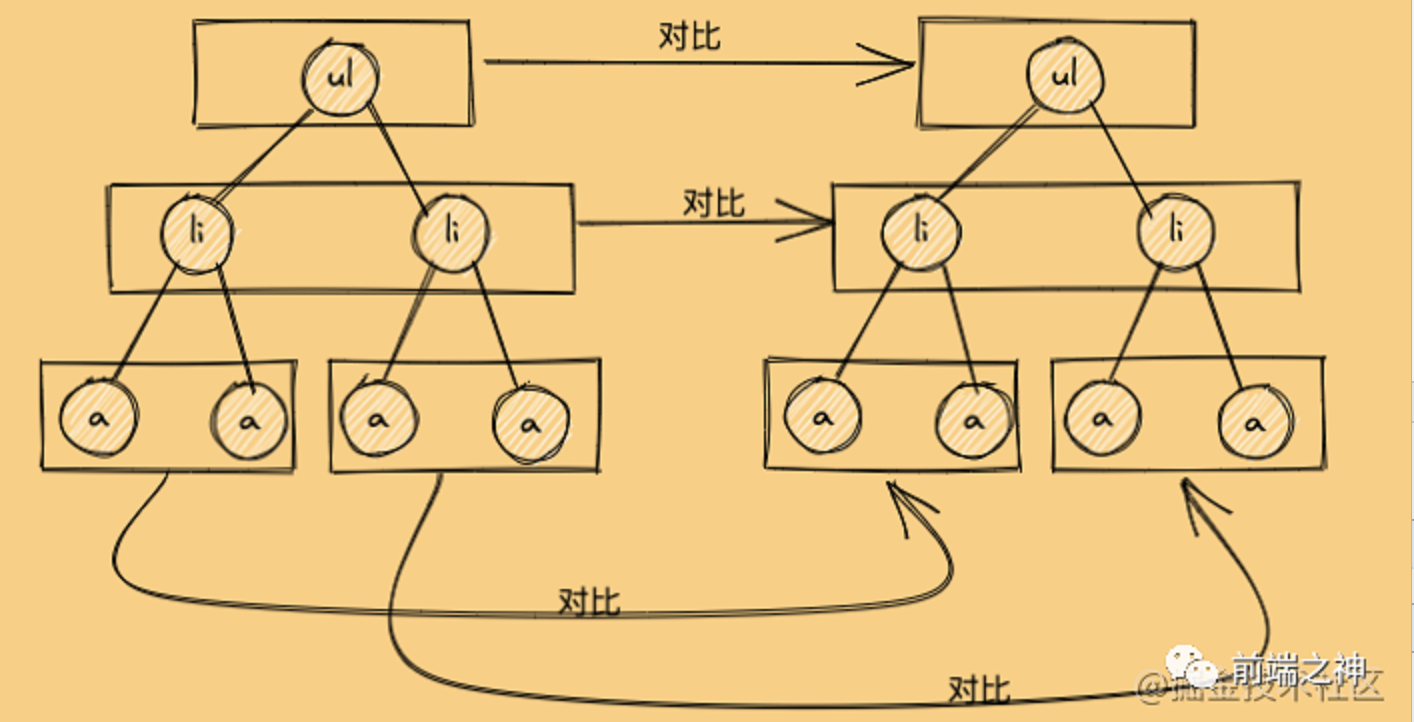
** Diff对比流程**
当数据改变时,会触发
setter
,并且通过
Dep.notify
去通知所有
订阅者Watcher
,订阅者们就会调用
patch方法
,给真实DOM打补丁,更新相应的视图
17、如何遍历输出页面上的所有元素
使用createNodeIterator
const body = document.getElementByTagName("body")[0]
const it = document.createNodeIterator(body)
let root = it.nextNode()
while(root){
console.log(root)
root = it.nextNode()
}
18、判断元素是否在可视区域内
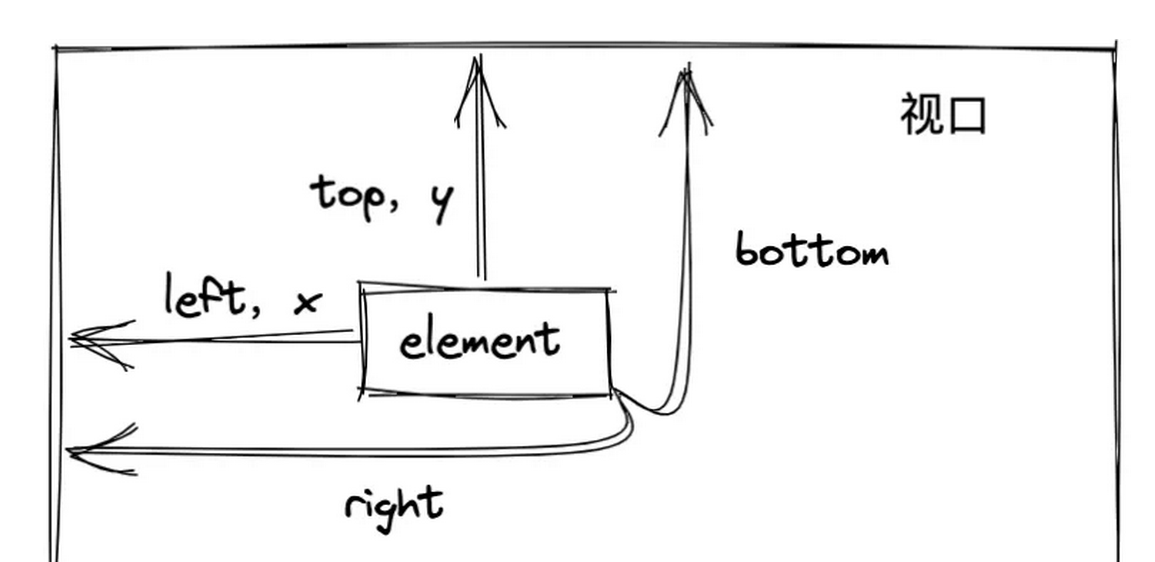
使用getBoundingClientRect
Element.getBoundingClientRect()
方法返回元素的大小及其相对于视口的位置。返回的是一个对象,
对象里有这8个属性:
left,right,top,bottom,width,height,x,y
根据这个用处,咱们可以实现:懒加载和无限滚动

<div id="box"></div>
body {
height: 3000px;
width: 3000px;
}
#box {
width: 300px;
height: 300px;
background-color: red;
margin-top: 300px;
margin-left: 300px;
}
// js
const box = document.getElementById('box')
window.onscroll = function () {
// box完整出现在视口里才会输出true,否则为false
console.log(checkInView(box))
}
function checkInView(dom) {
const { top, left, bottom, right } = dom.getBoundingClientRect()
console.log(top, left, bottom, right)
console.log(window.innerHeight, window.innerWidth)
return top >= 0 &&
left >= 0 &&
bottom <= (window.innerHeight || document.documentElement.clientHeight) &&
right <= (window.innerWidth || document.documentElement.clientWidth)
}

19、getComputedStyle
Window.getComputedStyle()
方法返回一个对象,该对象在应用活动样式表并解析这些值可能包含的任何基本计算后报告元素的所有CSS属性的值。私有的CSS属性值可以通过对象提供的API或通过简单地使用CSS属性名称进行索引来访问。
window.getComputedStyle(element, pseudoElement)
element: 必需,要获取样式的元素。pseudoElement: 可选,伪类元素,当不查询伪类元素的时候可以忽略或者传入 null。
搭配
getPropertyValue
可以获取到具体样式

// html
#box {
width: 300px;
height: 300px;
background-color: yellow;
}
<div id="box"></div>
const box = document.getElementById('box')
const styles = window.getComputedStyle(box)
// 搭配getPropertyValue可以获取到具体样式
const height = styles.getPropertyValue("height")
const width = styles.getPropertyValue("width")
console.log(height, width) // ’300px‘ '300px'

20、DOMContentLoaded
是什么:
当初始的 HTML 文档被完全加载和解析完成之后,**
DOMContentLoaded
** 事件被触发,而无需等待样式表、图像和子框架的完全加载。
这时问题又来了,“HTML 文档被加载和解析完成”是什么意思呢?或者说,HTML 文档被加载和解析完成之前,浏览器做了哪些事情呢?那我们需要从浏览器渲染原理来谈谈。
浏览器向服务器请求到了 HTML 文档后便开始解析,产物是 DOM(文档对象模型),到这里 HTML 文档就被加载和解析完成了。如果有 CSS 的会根据 CSS 生成 CSSOM(CSS 对象模型),然后再由 DOM 和 CSSOM 合并产生渲染树。有了渲染树,知道了所有节点的样式,下面便根据这些节点以及样式计算它们在浏览器中确切的大小和位置,这就是布局阶段。有了以上这些信息,下面就把节点绘制到浏览器上。所有的过程如下图所示:

现在你可能了解 HTML 文档被加载和解析完成前浏览器大概做了哪些工作,但还没完,因为我们还没有考虑现在前端的主角之一 JavaScript。
JavaScript 可以阻塞 DOM 的生成,也就是说当浏览器在解析 HTML 文档时,如果遇到
当 HTML 文档被解析时如果遇见(同步)脚本,则停止解析,先去加载脚本,然后执行,执行结束后继续解析 HTML 文档。过程如下图

defer 脚本:
当 HTML 文档被解析时如果遇见 defer 脚本,则在后台加载脚本,文档解析过程不中断,而等文档解析结束之后,defer 脚本执行。另外,defer 脚本的执行顺序与定义时的位置有关。过程如下图:

async 脚本:
当 HTML 文档被解析时如果遇见 async 脚本,则在后台加载脚本,文档解析过程不中断。脚本加载完成后,文档停止解析,脚本执行,执行结束后文档继续解析。过程如下图:

async 和 defer 对 DOMContentLoaded 事件触发的影响:
defer 与 DOMContentLoaded
如果 script 标签中包含 defer,那么这一块脚本将不会影响 HTML 文档的解析,而是等到 HTML 解析完成后才会执行。而 DOMContentLoaded 只有在 defer 脚本执行结束后才会被触发。所以这意味着什么呢?HTML 文档解析不受影响,等 DOM 构建完成之后 defer 脚本执行,但脚本执行之前需要等待 CSSOM 构建完成。在 DOM、CSSOM 构建完毕,defer 脚本执行完成之后,DOMContentLoaded 事件触发。
async 与 DOMContentLoaded
如果 script 标签中包含 async,则 HTML 文档构建不受影响,解析完毕后,DOMContentLoaded 触发,而不需要等待 async 脚本执行、样式表加载等等。
DOMContentLoaded和load
当 HTML 文档解析完成就会触发 DOMContentLoaded,而所有资源加载完成之后,load 事件才会被触发。
另外需要提一下的是,我们在 jQuery 中经常使用的
(document).ready(function()//...代码...);其实监听的就是DOMContentLoaded事件
而 ((document).load(function() { // ...代码... }); 监听的是 load 事件。
** 使用:**
document.addEventListener("DOMContentLoaded", function(event) {
console.log("DOM fully loaded and parsed");
});
21、 webpack配置中的3种hash值
事先准备3个文件(main.js、main.css、console.js)
在main.js中引入main.css
import './main.css'
console.log('我是main.js')
webpack.config.js

// 多入口打包
entry: {
main: './src/main.js',
console: './src/console.js'
},
// 输出配置
output: {
path: path.resolve(__dirname, './dist'),
// 这里预设为hash
filename: 'js/[name].[hash].js',
clean: true
},
plugins: [
// 打包css文件的配置
new MiniCssExtractPlugin({
// 这里预设为hash
filename: 'styles/[name].[hash].css'
})
]

1、全局hash
打包后,所有文件的文件名hash值都是一致的,修改一下
main.css
这个文件,重新打包,所有文件的hash值跟着变
结论:整个项目文件是一致的,修改其中一个会导致所有跟着一起改。
2、chunkhash
consfig中把输出文件名规则修改为
chunkhash
hash值会根据入口文件的不同而分出两个阵营:
main.js、main.css一个阵营,都属于main.js入口文件console.js一个阵营,属于console.js入口文件

** 3、contenthash**
每个文件hash值都不一样,每个文件的hash值都是根据自身的内容去生成的
当某个文件内容修改时,打包只会修改其本身的hash值,不会影响其他文件的hash值
22、package.lock.json的作用
锁定安装模块的版本
比如在package.json中,vue的版本是^2.6.14
^的意思是,加入过几天vue在大版本2下更新了小版本2.6.15,那么当npm install的时候vue会自动升级为2.16.5
引起的问题:
比如有A\B两个开发者
- 程序员A:接手项目时vue版本时2.16.4,并一直使用这个版本
- 程序员B:一个月后加入项目,这时vue已经升级到了2.9.14,npm install的时候会自动升级
这时候会导致两个开发时vue版本不一致,从而导致合作中产生一些问题和错误
package.lock.json解决该问题
比如现在有A、B两个开发者
A:接手项目时vue的版本时2.6.14,此版本被所在了package-lock.json中
B:一个月后加入该项目,这时vue已经升级到了2.9.14,npm install的时候,按理说会自动升级,但是由于package-lock.json中锁着2.6.14这个版本,所以阻止了自动升级,保证版本还是2.6.14
23、MutationObserver
作用:监控DOM元素的变化
例子:添加水印,使用MutationObserver阻止用户恶意破坏水印,因为在控制台修改水印的background-image或者将水印的div删掉,都会引起MutationObserver的监控触发
- observer:开启监控DOM的变化
- disconnect:停止检测DOM的变化
代码:
1、定义画水印的函数
import type { Directive, App } from 'vue'
interface Value {
font?: string
textColor?: string
text?: string
}
const waterMarkId = 'waterMark'
const canvasId = 'can'
const drawWatermark = (el, value: Value) => {
const {
font = '16px Microsoft JhengHei',
textColor = 'rgba(180, 180, 180, 0.3)',
text = 'nlf大菜鸟',
} = value
// 创建一个canvas标签
const canvas = document.getElementById(canvasId) as HTMLCanvasElement
// 如果已有则不再创建
const can = canvas || document.createElement('canvas')
can.id = canvasId
el.appendChild(can)
// 设置宽高
can.width = 400
can.height = 200
// 不可见
can.style.display = 'none'
const ctx = can.getContext('2d')!
// 设置画布的样式
ctx.rotate((-20 * Math.PI) / 180)
ctx.font = font
ctx.fillStyle = textColor
ctx.textAlign = 'left'
ctx.textBaseline = 'middle'
ctx.fillText(text, can.width / 3, can.height / 2)
// 水印容器
const waterMaskDiv = document.createElement('div')
waterMaskDiv.id = waterMarkId
// 设置容器的属性样式
// 将刚刚生成的canvas内容转成图片,并赋值给容器的 background-image 样式
const styleStr = `
width: 100%;
height: 100%;
position: fixed;
z-index: -1;
top: 0;
left: 0;
pointer-events: none;
background-image: url(${can.toDataURL('image/png')})
`
waterMaskDiv.setAttribute('style', styleStr)
// 将水印容器放到目标元素下
el.appendChild(waterMaskDiv)
return styleStr
}
//不使用监测
const watermarkDirective: Directive = {
mounted(el, { value }) {
// 接收styleStr,后面可以用来对比
el.waterMarkStylestr = drawWatermark(el, value)
}
}
使用的时候直接以
v-watermark
来使用:

<div
v-watermark="
{
text: '水印名称',
textColor: 'rgba(180, 180, 180, 0.3)'
}
"
>
</div>

2、使用监控

const watermarkDirective: Directive = {
mounted(el, { value }) {
// 接收styleStr,后面可以用来对比
el.waterMarkStylestr = drawWatermark(el, value)
// 先定义一个MutationObserver
el.observer = new MutationObserver(() => {
const instance = document.getElementById(waterMarkId)
const style = instance?.getAttribute('style')
const { waterMarkStylestr } = el
// 修改样式 || 删除div
if ((instance && style !== waterMarkStylestr) || !instance) {
if (instance) {
// div还在,说明只是修改style
instance.setAttribute('style', waterMarkStylestr)
} else {
// div不在,说明删除了div
drawWatermark(el, value)
}
}
})
// 启动监控
el.observer.observe(document.body, {
childList: true,
attributes: true,
subtree: true,
})
},
unmounted(el) {
// 指定元素销毁时,记得停止监控
el.observer.disconnect()
el.observer = null
},
}

现在,控制台修改
style
或者
删除容器div
,都会重新生成水印,这样恶意用户就无法得逞
24、HTTPS加密的过程
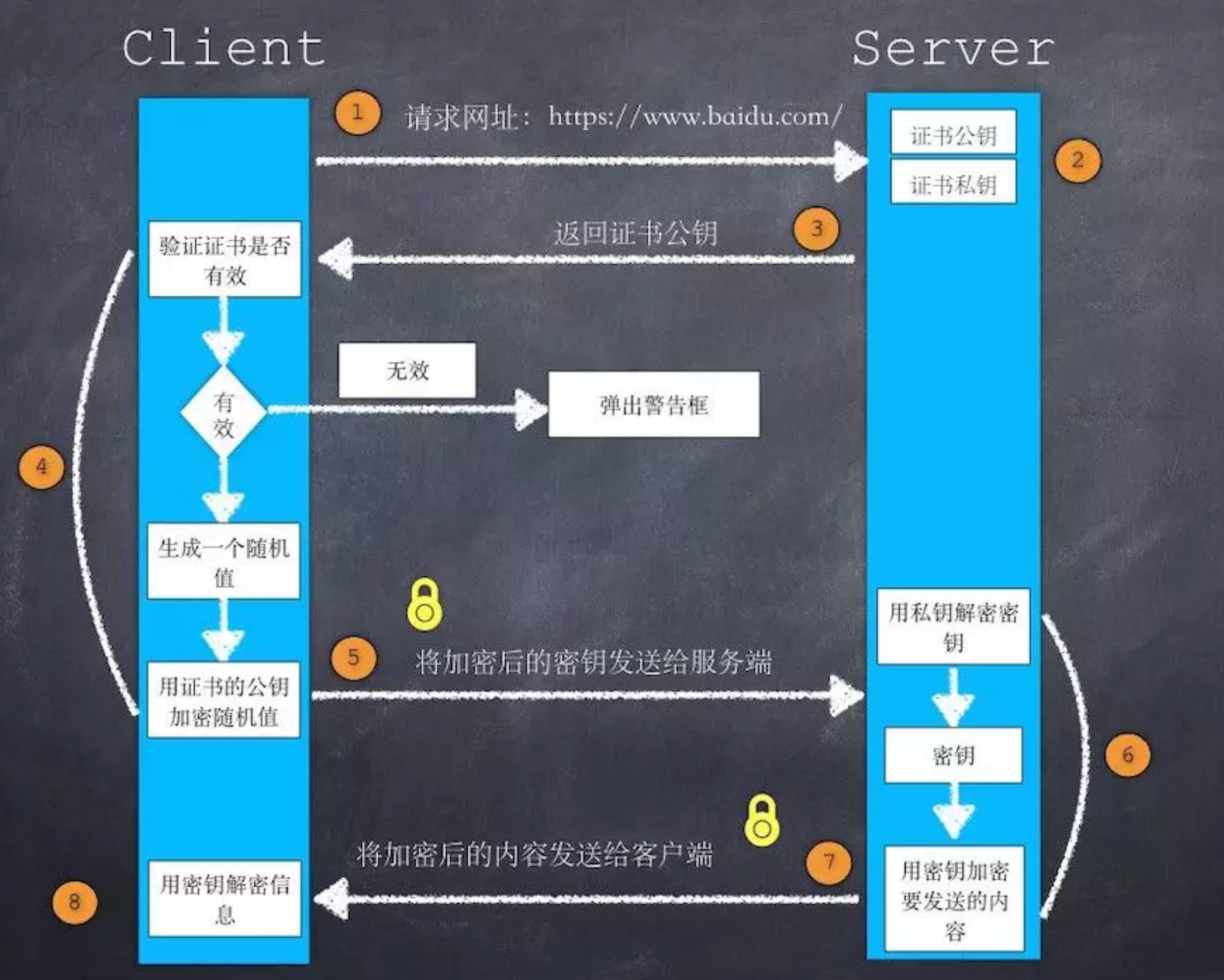
1、首先,客户端发起握手请求,以明文传输请求信息
2、服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。
这套证书其实就是一对公钥和私钥。
如果对公钥不太理解,可以想象成一把钥匙和一个锁头,只是世界上只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3、服务端返回证书、加密算法等信息给客服端
4、客户端验证证书的合法性,包括可信性,是否吊销,过期时间和域名,如果异常,弹框提示,没有异常则生成一串随机数
5、客户端使用公匙对对称密匙加密,发送给服务端。
6、服务器用私钥解密,拿到对称加密的密匙
25、性能优化
代码层面:
- 防抖和节流(resize,scroll,input)。
- 减少回流(重排)和重绘。
- 事件委托。
- css 放 ,js 脚本放 最底部。
- 使用字体图标iconfont代替图片
- 降低css选择器的复杂性
- 减少 DOM 操作。
- 尽量使用css而不是强制加载和卸载组件
- 按需加载,比如 React 中使用
React.lazy和React.Suspense,通常需要与 webpack 中的splitChunks配合。
构建方面:
- 压缩代码文件,在 webpack 中使用
terser-webpack-plugin压缩 Javascript 代码;使用css-minimizer-webpack-plugin压缩 CSS 代码;使用html-webpack-plugin压缩 html 代码。 - 开启 gzip 压缩,webpack 中使用
compression-webpack-plugin,node 作为服务器也要开启,使用compression。 - 常用的第三方库使用 CDN 服务,在 webpack 中我们要配置 externals,将比如 React, Vue 这种包不打倒最终生成的文件中。而是采用 CDN 服务。
webpack性能优化:
- 优化构建速度:
- 缩小文件搜索范围:resolve字段告诉webpack怎么去搜索文件,所以首先要重视resolve字段的配置(设置 resolve.modules:[path.resolve(__dirname, 'node_modules')] 避免层层查找)
- 配置oneOf(每个不同类型的文件在load转换时,会遍历module中rules所有的loader,即使匹配到某个规则后也会继续向下匹配。如果将规则放在oneOf中,一旦匹配到某个规则后就停止匹配)
- 使用DllPlugin减少基础模块编译次数(原理是把网页依赖的基础模块抽离出来打包到dll文件中,当需要导入的模块存在于某个dll中时,这个模块不再被打包,而是去dll中获取。为什么会提升构建速度呢?原因在于dll中大多包含的是常用的第三方模块,如react、react-dom,所以只要这些模块版本不升级,就只需被编译一次)
- 使用HappyPack或者thread-load开启多进程Loader转换(在整个构建流程中,最耗时的就是Loader对文件的转换操作了,而运行在Node.js之上的Webpack是单线程模型的,也就是只能一个一个文件进行处理,不能并行处理。HappyPack可以将任务分解给多个子进程,最后将结果发给主进程。JS是单线程模型,只能通过这种多进程的方式提高性能)
- 使用ParallelUglifyPlugin开启多进程压缩JS文件(使用UglifyJS插件压缩JS代码时,需要先将代码解析成Object表示的AST(抽象语法树),再去应用各种规则去分析和处理AST,所以这个过程计算量大耗时较多。ParallelUglifyPlugin可以开启多个子进程,每个子进程使用UglifyJS压缩代码,可以并行执行,能显著缩短压缩时间)
- 优化输出质量-压缩文件体积
- 区分环境-减少生产环境代码体积(代码运行环境分为开发环境和生产环境,代码需要根据不同环境做不同的操作,许多第三方库中也有大量的根据开发环境判断的if else代码,构建也需要根据不同环境输出不同的代码,所以需要一套机制可以在源码中区分环境,区分环境之后可以使输出的生产环境的代码体积减小。Webpack中使用DefinePlugin插件来定义配置文件适用的环境,用来支持process.env.NODE_ENV === 'production' 语句)
- 压缩js、es、css
- 使用tree-shaking剔除js死代码
- 优化输出质量-加速网络请求
- 使用CDN加速静态资源的加载
- 多页面应用提取页面间公共代码,以利用缓存(把公共文件提取出一个文件,那么当用户访问了一个网页,加载了这个公共文件,再访问其他依赖公共文件的网页时,就直接使用文件在浏览器的缓存,这样公共文件就只用被传输一次。)
- 分割代码按需加载 例如:一个最简单的例子:网页首次只加载main.js,网页展示一个按钮,点击按钮时加载分割出去的show.js,加载成功后执行show.js里的函数

//main.jsdocument.getElementById('btn').addEventListener('click',function(){ import(/* webpackChunkName:"show" */ './show').then((show)=>{ show('Webpack'); })})//show.jsmodule.exports = function (content) { window.alert('Hello ' + content);}import(/* webpackChunkName:show */ './show').then() 是实现按需加载的关键
其它:
- 使用 http2。因为解析速度快,头部压缩,多路复用,服务器推送静态资源。
- 使用服务端渲染。
- 图片压缩。
- 使用 http 缓存,比如服务端的响应中添加
Cache-Control / Expires
26、loader和plugin的区别
- 两者都是扩展webpack的功能,loader只专注于转化文件,完成压缩、打包和语言翻译;而plugin只局限在打包,资源加载上,还可以打包优化和压缩,重新定义环境变量等
- loader是运行在打包文件之前,plugins在整个编译周期都起作用
- 一个loader的职责是单一的,只需要完成一种转换,一个loader其实就是一个node.js模块。当需要多个loader去转换一个文件时,每个loader会链式的顺序执行
- webpack运行的生命周期中广播出许多事件,plugins会监听这些事件,在合适的时机通过webpack提供的API改变输出结果
** 原理:**
** loader** loader 的作用是用来处理
非js文件
,它是一个函数,实现原理是:将所需处理的文件内容使用相应的转换插件转成
AST(抽象语法树)
,然后按照loader规则对于这个 AST 进行处理,处理之后再转成原本的内容格式,然后输出,达到了处理内容的效果
** plugin** plugin 的作用是拓展webpack的打包功能。它是一个类,使用方式是new Plugin(option),这个类内部有一个
apply
方法,打包时会执行这个方法,且这个
apply
方法接收的参数中有一个
plugin
方法,此方法中有许多钩子函数,使用这些钩子函数可以在不同的打包阶段做一些事,例如修改文件,新增文件,删除文件等等
27、vue中不需要响应式的数据如何处理
vue中,会有一些数据,从始至终都未曾改变,这种死数据,既然不会改变,也不需要对其做响应式处理了,不然会消耗性能。
比如一些写死的下拉框

//方法1:将数据定义在data之外
data(){
this.list = {xxxx}
return {}
}
//方法2、Object.freeze()
data(){
return {
list:Object.freeze({xxxx})
}
}
28、父子组件生命周期的顺序
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
29、computed和watch的区别
computed是依赖已有的变量来计算一个目标变量,大多数情况都是多个变量凑在一起计算出一个变量,并且computed具有缓存机制,依赖值不变的情况下其会直接读取缓存进行复用,computed不能进行异步操作watch是监听某一个变量的变化,并执行相应的回调函数,通常是一个变量的变化决定多个变量的变化,watch可以进行异步操作- 简单记就是:一般情况下
computed是多对一,watch是一对多
30、 vue的修饰符
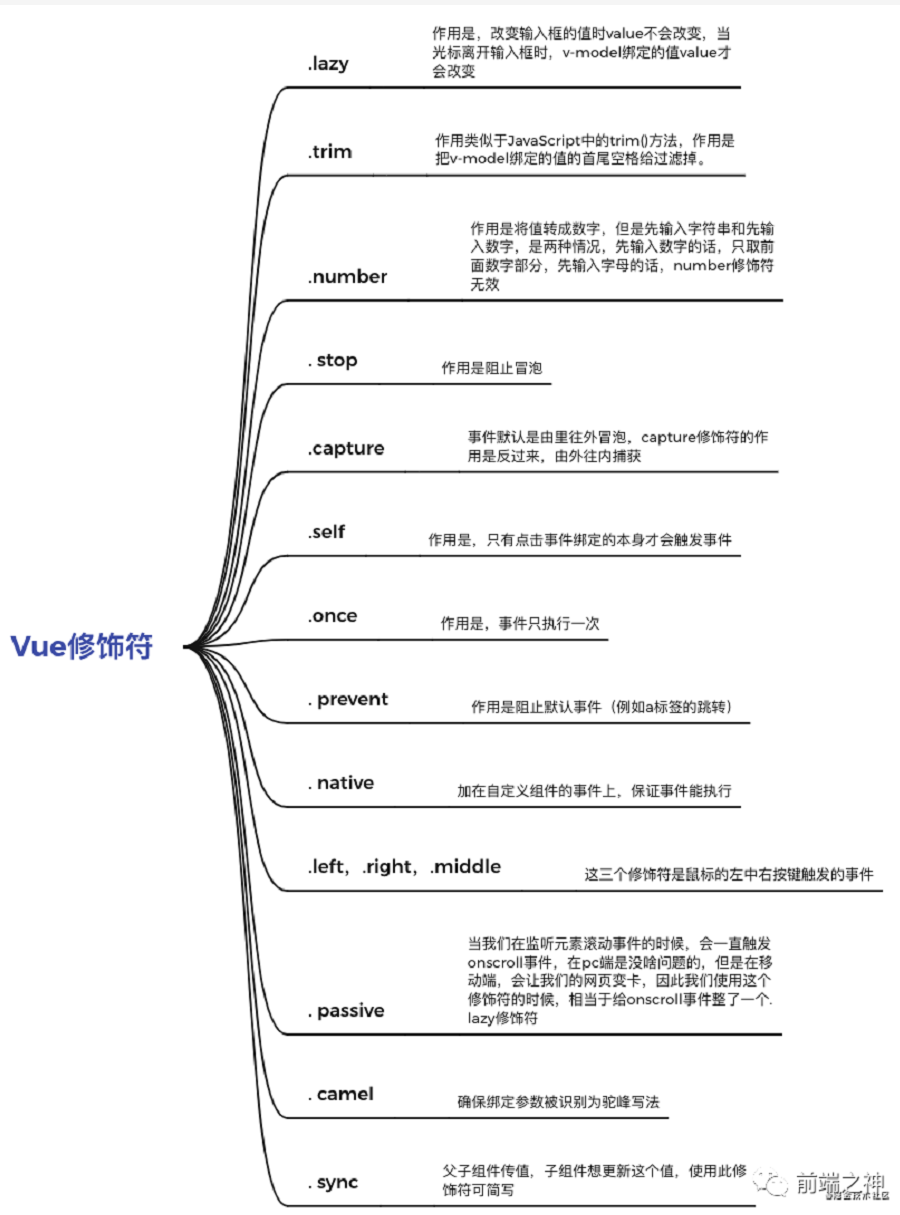
31、使用vite为什么会变快
- 1、esbuild预构建依赖:代码分为
依赖和源码,依赖就是那些npm包,一般不会变,缓存起来;源码是会频繁更改的那一部分代码 - 2、利用浏览器可以运行
ES Module,将代码转成ES Module后交给浏览器,把压力放在浏览器那边,从而提高项目启动速度 - 3、按需加载:浏览器根据
ES Module去使用http请求,按需加载所需页面 - 4、利用协商缓存,缓存文件,无变化的文件不需要重新加载
32、webpack babel vue都用到了AST,对抽象语法树的理解
现在的很多工具,例如webpack、vite、eslint、babel等等都离不开一个东西——AST。
AST是正常代码,使用工具,根据不用的代码节点类型,转化成的一个JSON格式的数据
const a = 5;
// 转换成AST
[{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...]
33、TCP/UDP的区别
都属于TCP/IP协议族
- TCP是面向连接的,UDP是面向无连接的
- TCP是可靠的,UDP是不可靠的
- TCP是面向字节流,UDP是面向报文的
- TCP只有一对一的传输方式,而UDP不仅可以一对一,还可以一对多,多对多
TCP拥塞控制:若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就会变坏,这种情况叫做网络拥塞
TCP的4种拥塞控制算法:慢开始、拥塞控制、快重传、快恢复
TCP和http的区别
http:超文本传输协议,是运行TCP之上的
TCP:传输控制协议,用来控制传输的,为了在不可靠的互联网上提供可靠的端到端字节流,作用范围比HTTP大
34、跨域
意思:协议、域名和端口不一致均会导致跨域
产生的原因:
1、基于浏览器的同源策略限制
2、同源策略是一种约定,它是浏览器核心也是最基本的安全功能,它会组织一个域的js脚本和另外一个域的内容进行交互。如果缺少了同源策略,浏览器很容易受到XSS、CSRF的攻击。
3、同源就是两个页面具有相同的协议、域名和端口
35、get和post的区别
相同:都是http协议请求,tcp连接
不同:
get:
- get不安全,参数在url中
- 参数有长度限制
- 能被缓存,可以收藏为书签,参数保留在浏览器历史中
- 只发送1个tcp数据包,即http header和data共同发送给服务器
post:
- 安全,参数在request body
- 参数没有长度限制
- 不会被缓存
- 发送2个tcp数据包,第一次发送http header,如果服务器响应100,则发送第二个数据包data
36、requestAnimationFrame
requestAnimationFrame 比起 setTimeout、setInterval的优势主要有两点:
1、requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率,一般来说,这个频率为每秒60帧。
2、在隐藏或不可见的元素中,requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的的cpu,gpu和内存使用量。
requestAnimationFrame 动画原理:
假设某图像正在以每秒60次的频率刷新,由于刷新频率很高,因此你感觉不到它在刷新。而动画本质就是要让人眼看到图像被刷新而引起变化的视觉效果,这个变化要以连贯的、平滑的方式进行过渡。 那怎么样才能做到这种效果呢?
刷新频率为60Hz的屏幕每16.7ms刷新一次,我们在屏幕每次刷新前,将图像的位置向左移动一个像素,即1px。这样一来,屏幕每次刷出来的图像位置都比前一个要差1px,因此你会看到图像在移动;由于我们人眼的视觉停留效应,当前位置的图像停留在大脑的印象还没消失,紧接着图像又被移到了下一个位置,因此你才会看到图像在流畅的移动,这就是视觉效果上形成的动画。
setTimeOut卡顿的原因:
1、setTimeout的执行时间并不是确定的。在Javascript中, setTimeout 任务被放进了异步队列中,只有当主线程上的任务执行完以后,才会去检查该队列里的任务是否需要开始执行,因此 setTimeout 的实际执行时间一般要比其设定的时间晚一些。
2、刷新频率受屏幕分辨率和屏幕尺寸的影响,因此不同设备的屏幕刷新频率可能会不同,而 setTimeout只能设置一个固定的时间间隔,这个时间不一定和屏幕的刷新时间相同。
以上两种情况都会导致setTimeout的执行步调和屏幕的刷新步调不一致,从而引起丢帧现象。 那为什么步调不一致就会引起丢帧呢?
原因:setTimeout的执行只是在内存中对图像属性进行改变,这个变化必须要等到屏幕下次刷新时才会被更新到屏幕上。如果两者的步调不一致,就可能会导致中间某一帧的操作被跨越过去,而直接更新下一帧的图像。
37、Cookies中的SameSite
SameSite可以让Cookie在跨站请求时不会被发送,从而组织跨站请求伪造攻击CSRF
设置:
- 客户端发送 HTTP 请求到服务器
- 当服务器收到 HTTP 请求时,在响应头里面添加一个 Set-Cookie 字段
- 浏览器收到响应后保存下 Cookie
- 之后对该服务器每一次请求中都通过 Cookie 字段将 Cookie 信息发送给服务器。
SameSite 可以有下面三种值:
- Strict 仅允许一方请求携带 Cookie,即浏览器将只发送相同站点请求的 Cookie,即当前网页 URL 与请求目标 URL 完全一致。
- Lax 允许部分第三方请求携带 Cookie
- None 无论是否跨站都会发送 Cookie
之前默认是 None 的,Chrome80 后默认是 Lax。
主要用于3个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
38、事件冒泡和事件捕获
事件冒泡可以形象地比喻为把一颗石头投入水中,泡泡会一直从水底冒出水面。也就是说,事件会从最内层的元素开始发生,一直向上传播,直到document对象。
因此上面的例子在事件冒泡的概念下发生click事件的顺序应该是
p -> div -> body -> html -> document
另一种事件流名为事件捕获(event capturing)。与事件冒泡相反,事件会从最外层开始发生,直到最具体的元素。
上面的例子在事件捕获的概念下发生click事件的顺序应该是
document -> html -> body -> div -> p
39、BFC:块级格式化上下文
触发的条件:
·body根元素
·设置浮动,不包括none
·设置定位,absoulte或者fixed
·行内块显示模式,inline-block
·设置overflow,即hidden,auto,scroll
·表格单元格,table-cell
·弹性布局,flex
一个BFC区域只包含其子元素,不包括其子元素的子元素。
并不是所有的元素都能成为一块BFC区域,只有当这个元素满足上面条件之一的时候才会成为一块BFC区域。
不同的BFC区域之间是相互独立的,互不影响的。利用这个特性我们可以让不同BFC区域之间的布局不产生影响。
40、箭头函数的this
this:表示当前对象的一个引用
箭头函数没有自己的this,所以内部的this就是外层代码块的this,它的this是继承而来的,默认指向在定义时所处的宿主对象
程序员面试题库分享
1、前端面试题库 (面试必备)** 推荐:★★★★★**
地址:前端面试题库
2、前端技术导航大全 推荐:★★★★★
地址:前端技术导航大全
3、开发者颜色值转换工具 推荐:★★★★★
地址 :开发者颜色值转换工具
版权归原作者 前端技术栈 所有, 如有侵权,请联系我们删除。