

Flink On Yarn任务提交
一、Flink On Yarn运行原理
Flink On Yarn即Flink任务运行在Yarn集群中,Flink On Yarn的内部实现原理如下图:
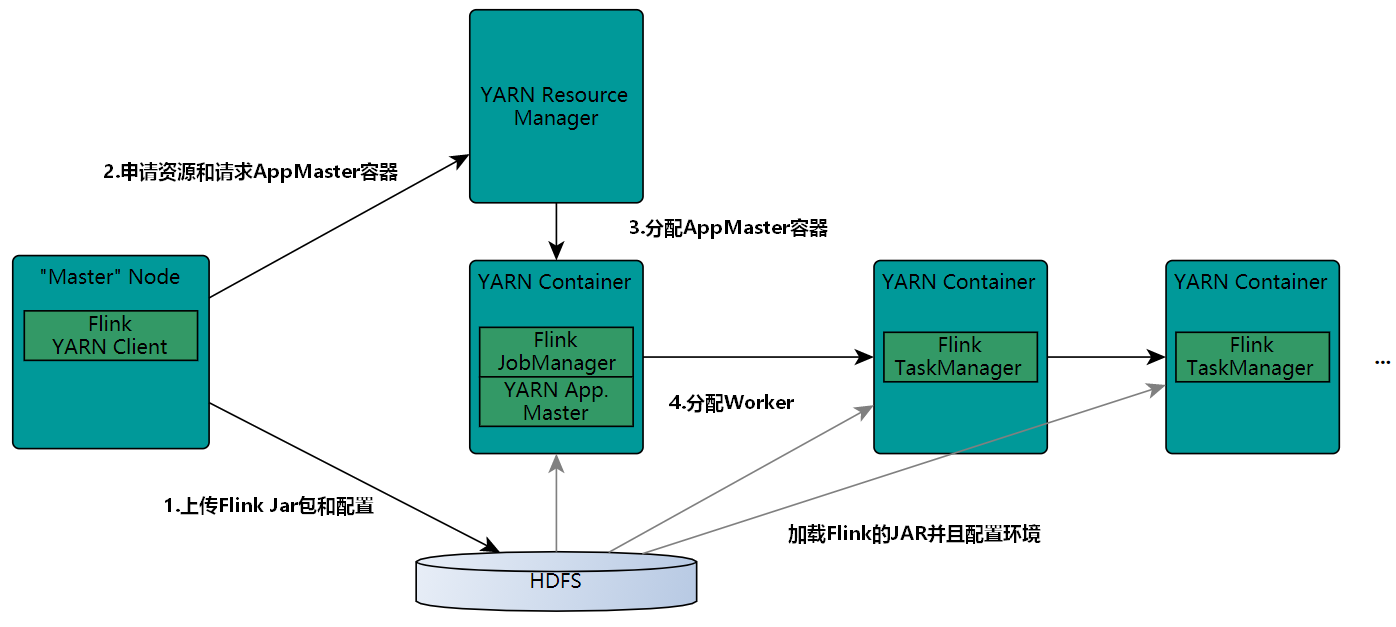
- 当启动一个新的Flink YARN Client会话时,客户端首先会检查所请求的资源(容器和内存)是否可用,之后,它会上传Flink配置和JAR文件到HDFS。
- 客户端的下一步是向ResourceManager请求一个YARN容器启动ApplicationMaster。JobManager和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM就能够知道JobManager的地址,它会为TaskManager生成一个新的Flink配置文件(这样它才能连上JobManager),该文件也同样会被上传到HDFS。另外,AM容器还提供了Flink的Web界面服务。Flink用来提供服务的端口是由用户和应用程序ID作为偏移配置的,这使得用户能够并行执行多个YARN会话。
- 之后,AM开始为Flink的TaskManager分配容器(Container),从HDFS下载JAR文件和修改过的配置文件,一旦这些步骤完成了,Flink就可以基于Yarn运行任务了。
Flink On Yarn任务提交支持Session会话模式、Per-Job单作业模式、Application应用模式。下面分别介绍这三种模式的任务提交命令和原理。
二、代码及Yarn环境准备
1、准备代码
为了能演示出不同模式的效果,这里我们编写准备Flink代码形成一个Flink Application,该代码中包含有2个job。Flink允许在一个main方法中提交多个job任务,多Job执行的顺序不受部署模式影响,但受启动Job的调用影响,每次调用execute()或者executeAsyc()方法都会触发job执行,我们可以在一个Flink Application中执行多次execute()或者executeAsyc()方法来触发多个job执行,两者区别如下:
- **execute()**:该方法为阻塞方法,当一个Flink Application中执行多次execute()方法触发多个job时,下一个job的执行会被推迟到该job执行完成后再执行。
- **executeAsyc()**:该方法为非阻塞方法,一旦调用该方法触发job后,后续还有job也会立即提交执行。
当一个Flink Application中有多个job时,这些job之间没有直接通信的机制,所以建议编写Flink代码时一个Application中包含一个job即可,目前只有非HA的Application模式可以支持多job运行。后续打包运行包含多个job的Flink代码如下:
//1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取Socket数据 ,获取ds1和ds2
DataStreamSource<String> ds1 = env.socketTextStream("node3", 8888);
DataStreamSource<String> ds2 = env.socketTextStream("node3", 9999);
//3.1 对ds1 直接输出原始数据
SingleOutputStreamOperator<Tuple2<String, Integer>> transDs1 = ds1.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
transDs1.print();
env.executeAsync("first job");
//3.2 对ds2准备K,V格式数据 ,统计实时WordCount
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = ds2.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
tupleDS.keyBy(tp -> tp.f0).sum(1).print();
//5.execute触发执行
env.execute("second job");
将以上代码进行打包,名称为"FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar",并在node3节点上启动多个socket服务
[root@node3 ~]# nc -lk 8888
[root@node3 ~]# nc -lk 9999
2、yarn 环境准备
在Per-Job模式中,Flink每个job任务都会启动一个对应的Flink集群,基于Yarn提交后会在Yarn中同时运行多个实时Flink任务,在HDFS中$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml中有"yarn.scheduler.capacity.maximum-am-resource-percent"配置项,该项默认值为0.1,表示Yarn集群中运行的所有ApplicationMaster的资源比例上限,默认0.1表示10%,这个参数变相控制了处于活动状态的Application个数,所以这里我们修改该值为0.5,否则后续在Yarn中运行多个Flink Application时只有一个Application处于活动运行状态,其他处于Accepted状态。
所有HDFS节点配置$HADOOP_HOME/etc/hadoop/capacity-scheduler.xml文件,修改如下配置项为0.5:
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value>
<description>
Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications.
</description>
</property>
至此,Flink On Yarn运行环境准备完毕。
三、Yarn Session模式
1、任务提交命令
Yarn Session模式首先需要在Yarn中初始化一个Flink集群(称为Flink Yarn Session 集群),开辟指定的资源,以后的Flink任务都提交到这里。这个Flink集群会常驻在YARN集群中,除非手工停止(yarn application -kill id),当手动停止yarn application对应的id时,运行在当前application上的所有flink任务都会被kill。这种方式创建的Flink集群会独占资源,不管有没有Flink任务在执行,YARN上面的其他任务都无法使用这些资源。
1.1、启动Yarn Session 集群
启动Yarn Session 集群前首先保证HDFS和Yarn正常启动,这里在node5节点上来使用名称创建Yarn Session集群,命令如下:
[root@node3 ~]# cd /software/flink-1.16.0/bin/
#启动Yarn Session集群,名称为lansonjy,每个TM有3个slot
[root@node3 bin]# ./yarn-session.sh -s 3 -nm lansonjy -d
以上启动Yarn Session集群命令的参数解释如下:
参数****解释-d--detached,Yarn Session集群启动后在后台独立运行,退出客户端,也可不指定,则客户端不退出。-nm--name,自定义在YARN上运行Application应用的名字。-jm--jobManagerMemory,指定JobManager所需内存,单位MB。-tm--taskManagerMemory,指定每个TaskManager所需的内存,单位MB。-s--slots,指定每个TaskManager上Slot的个数。-id--applicationId,指定YARN集群上的任务ID,附着到一个后台独立运行的yarn session中。-qu--queue,指定Yarn的资源队列。
以上命令执行完成后,可以在Yarn WebUI(https://node1:8088)中看到启动的Flink Yarn Session集群:
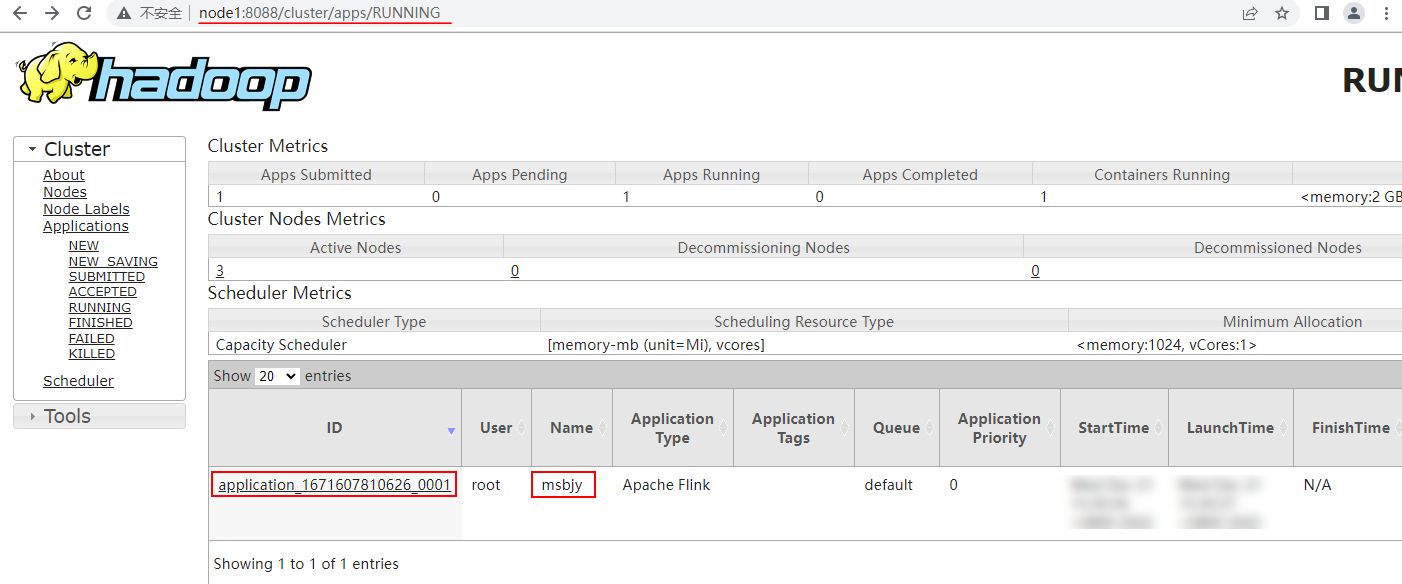
点击Tracking UI"ApplicationMaster"可以跳转到Flink Yarn Session集群 WebUI页面中:
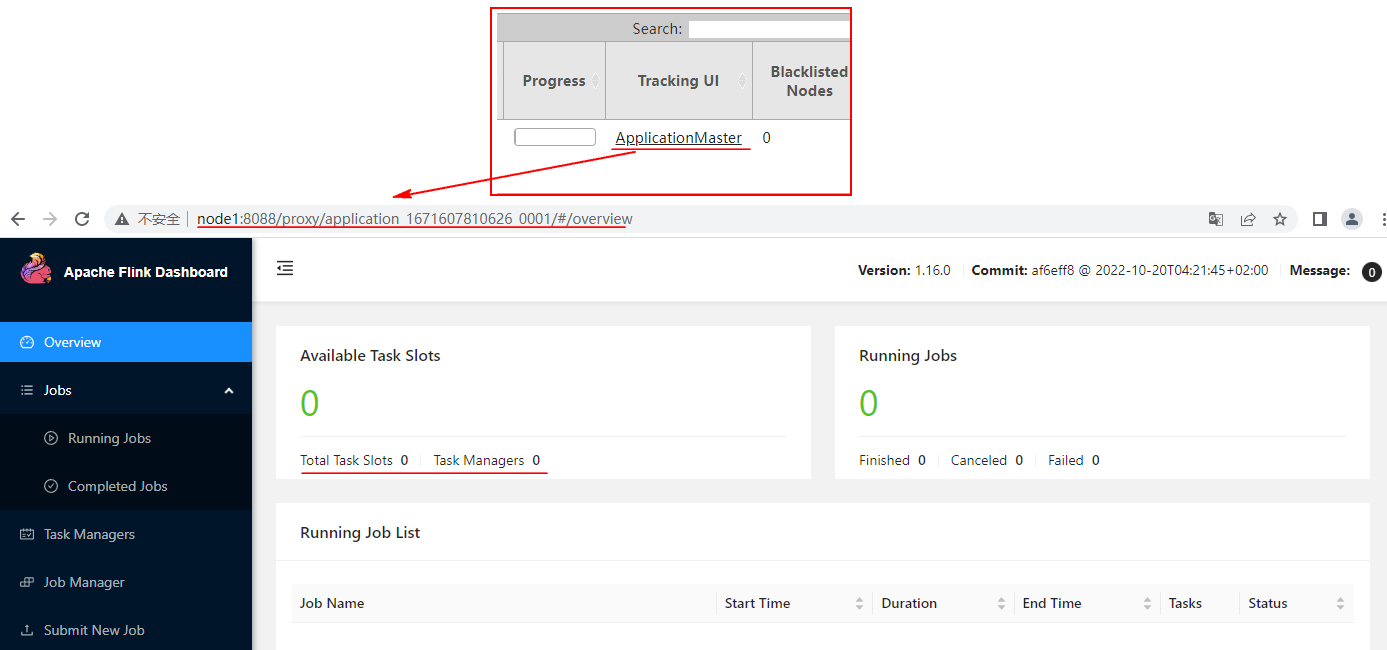
目前在Yarn Session集群WebUI中看不到启动的TaskManager ,这是因为Yarn会按照提交任务的需求动态分配TaskManager数量,所以Flink 基于Yarn Session运行任务资源是动态分配的。
此外,创建出Yarn Session集群后会在node5节点/tmp/下创建一个隐藏的".yarn-properties-<用户名>" Yarn属性文件,有了该文件后,在当前节点提交Flink任务时会自动发现Yarn Session集群并进行任务提交。
1.2、向Yarn Session集群中提交作业
[root@node3 ~]# cd /software/flink-1.16.0/bin/
#执行如下命令,会根据.yarn-properties-<用户名>文件,自动发现yarn session 集群
[root@node3 bin]# ./flink run -c com.lanson.flinkjava.code.chapter3.FlinkAppWithMultiJob /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
#也可以使用如下命令指定Yarn Session集群提交任务,-t 指定运行的模式
[root@node3 bin]# ./flink run -t yarn-session -Dyarn.application.id=application_1671607810626_0001 -c com.lanson.flinkjava.code.chapter3.FlinkAppWithMultiJob /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
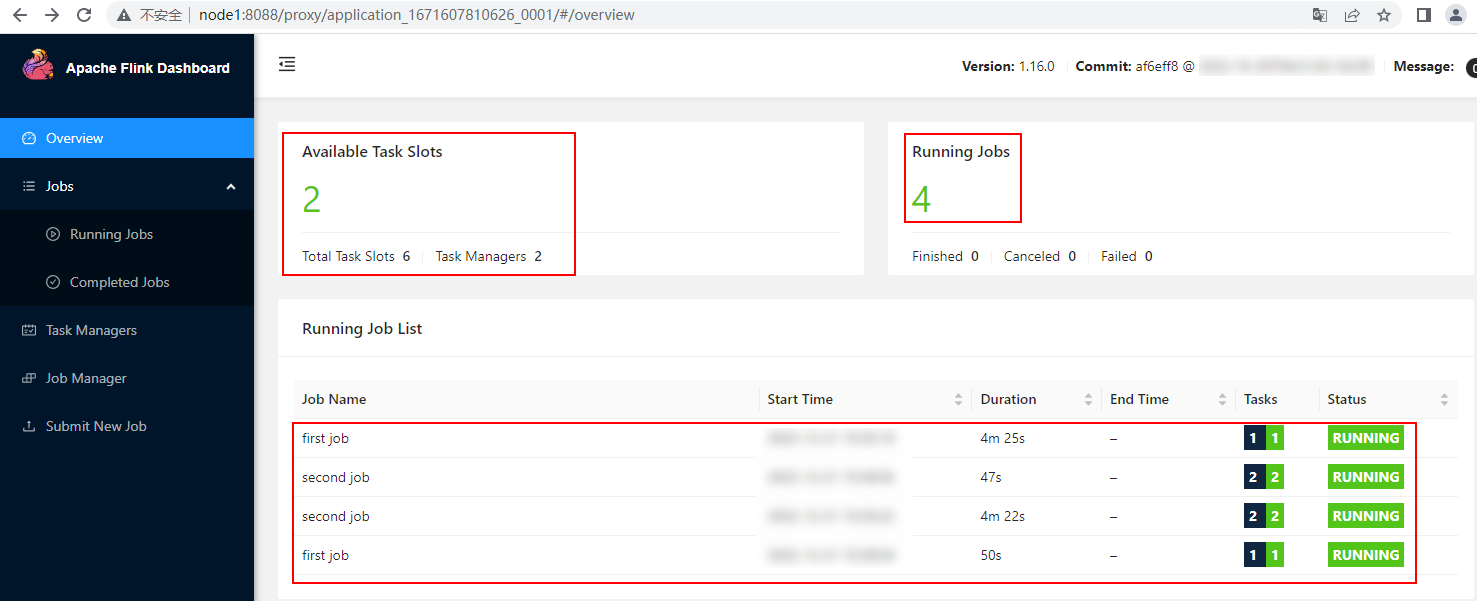
以上命令执行之后,可以查看对应的Yarn Session 对应的Flink集群,可以看到启动了2个Flink Job任务、启动1个TaskManager,分配了3个Slot。

1.3、任务资源测试
按照以上方式继续提交一次Flink Application,可以看到会申请新的TaskManager:
查看集群中任务列表并取消各个任务,命令如下:
#查看Yarn Session集群中任务列表 后面跟上Yarn Application ID
[root@node3 bin]# ./flink list
------------------ Running/Restarting Jobs -------------------
87f6f9a45fd9a9533e93a94dff455b66 : first job (RUNNING)
0d5cd72d8f59ed0eb51d2d64124d4859 : second job (RUNNING)
cff599a2d43a33195702ca7e7512feb4 : first job (RUNNING)
6498d664a8e141ed7503046c5fb9fa9a : second job (RUNNING)
--------------------------------------------------------------
#取消任务命令,也可以在WebUI中“cancel”取消任务
[root@node3 bin]# ./flink cancel 87f6f9a45fd9a9533e93a94dff455b66
[root@node3 bin]# ./flink cancel 0d5cd72d8f59ed0eb51d2d64124d4859
[root@node3 bin]# ./flink cancel cff599a2d43a33195702ca7e7512feb4
[root@node3 bin]# ./flink cancel 6498d664a8e141ed7503046c5fb9fa9a
当任务取消后,等待30s后(resourcemanager.taskmanager-timeout=30000ms)可以看到TaskManager数量为0,说明Flink基于Yarn Session模式提交任务会动态进行资源分配。
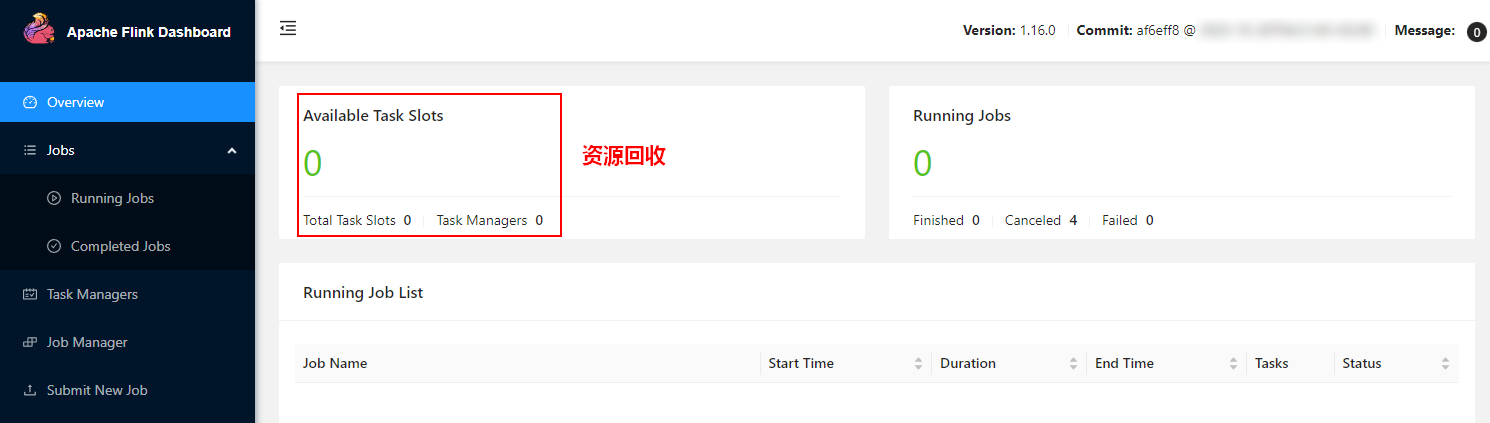
1.4、集群停止
停止Yarn Session集群可以在Yarn WebUI中找到对应的ApplicationId,执行如下命令关闭任务即可。
[root@node3 bin]# yarn application -kill application_1671607810626_0001
2、任务提交流程
Yarn Session 模式下提交任务首先创建Yarn Session 集群,创建该集群实际上就是启动了JobManager,启动JobManager同时会启动Dispatcher和ResourceManager,当客户端提交任务时,才会启动JobMaster以及根据提交的任务需求资源情况来动态分配启动TaskManager。
Yarn Session模式下提交任务流程如下:
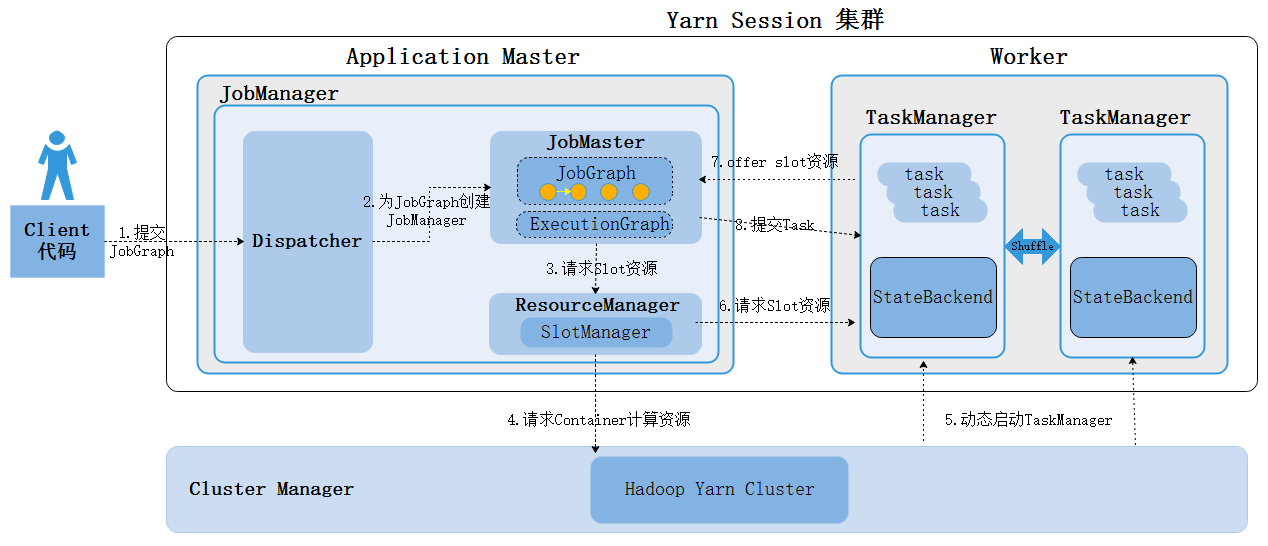
- 客户端向Yarn Session集群提交任务,客户端会将任务转换成JobGraph提交给JobManager。
- Dispatcher启动JobMaster并将JobGraph提交给JobMaster。
- JobMaster向ResourceManager请求Slot资源。
- ResourceManager向Yarn的资源管理器请求Container计算资源。
- Yarn动态启动TaskManager,启动的TaskManager会注册给Resourcemanager
- ResourceManager会在对应的TaskManager上划分Slot资源。
- TaskManager向JobMaster offer Slot资源。
- JobMaster将任务对应的task发送到TaskManager上执行。
四、Yarn Per-Job模式
Per-Job 模式目前只有yarn支持,Per-job模式在Flink1.15中已经被弃用,后续版本可能会完全剔除。Per-Job模式就是直接由客户端向Yarn中提交Flink作业,每个作业形成一个单独的Flink集群。
1、任务提交命令
Flink On Yarn Per-Job模式提交命令如下:
[root@node5 bin]# ./flink run -t yarn-per-job -d -c com.lanson.flinkjava.code.chapter3.FlinkAppWithMultiJob /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
以上提交任务命令的参数解释如下:
参数****解释-t--target,指定运行模式,可以跟在flink run 命令后,可以指定"remote", "local", "kubernetes-session", "yarn-per-job"(deprecated), "yarn-session";也可以跟在 flink run-application 命令后,可以指定"kubernetes-application", "yarn-application"。-c--class,指定运行的class主类。-d--detached,任务提交后在后台独立运行,退出客户端,也可不指定。-p--parallelism,执行应用程序的并行度。
以上命令提交后,我们可以通过Yarn WebUI看到有2个Application 启动,对应2个Flink的集群,进入对应的Flink集群WebUI可以看到运行提交的Flink Application中的不同Job任务:
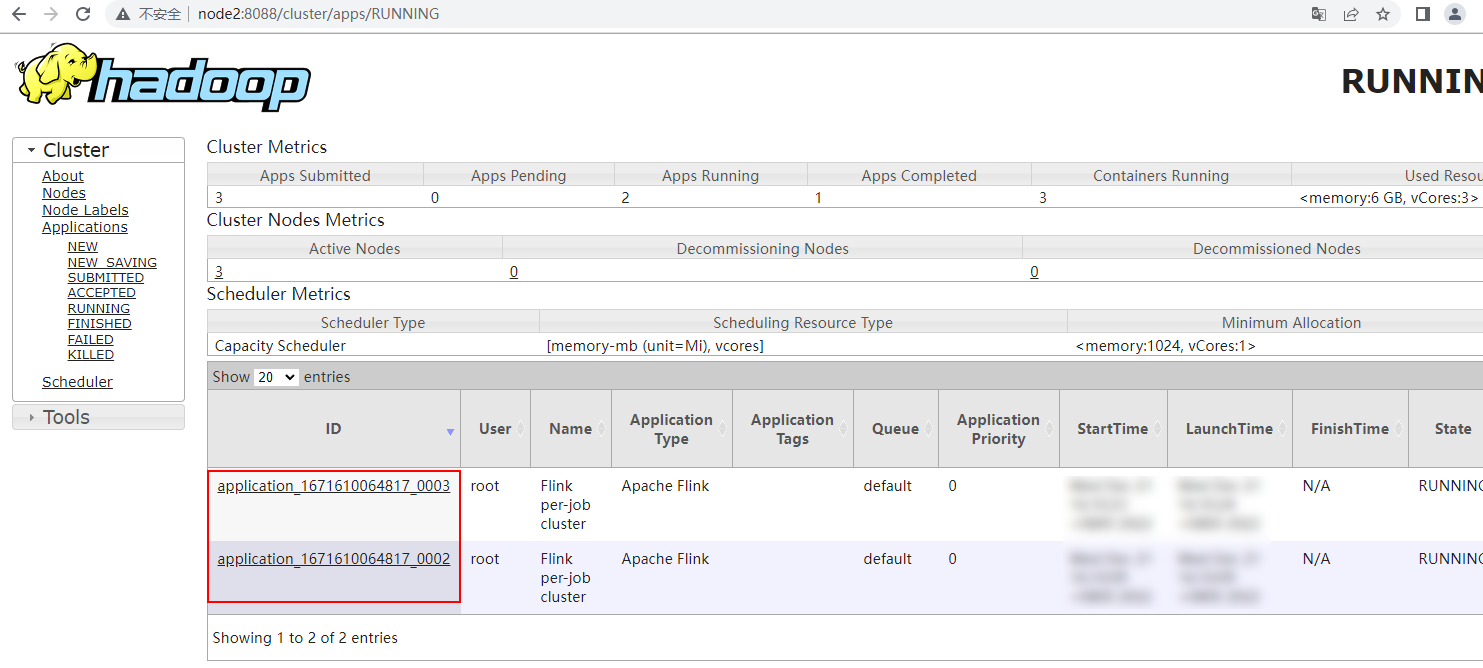
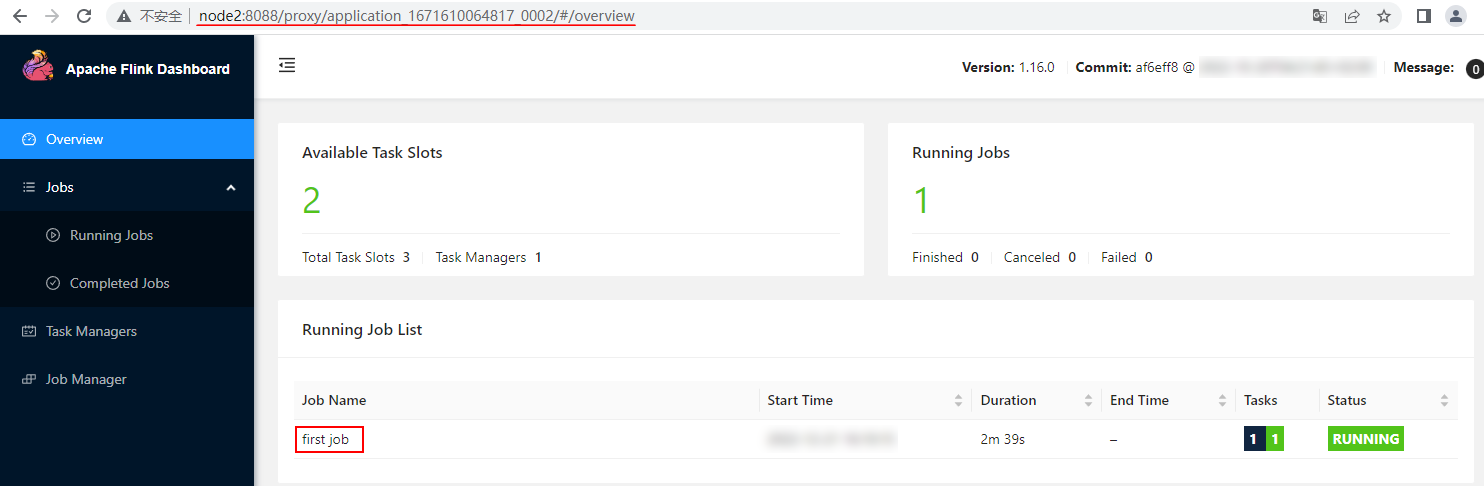
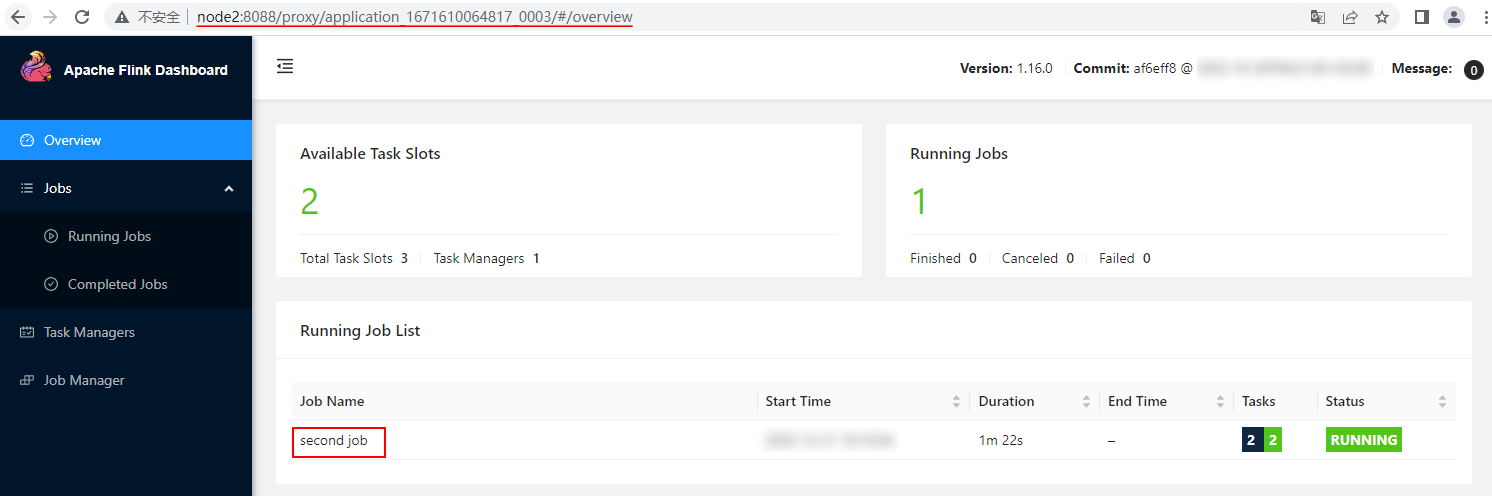
这说明Per-Job模式针对每个Flink Job会启动一个Flink集群。
注意:在基于Yarn Per-Job模式提交任务后,会打印以下错误:
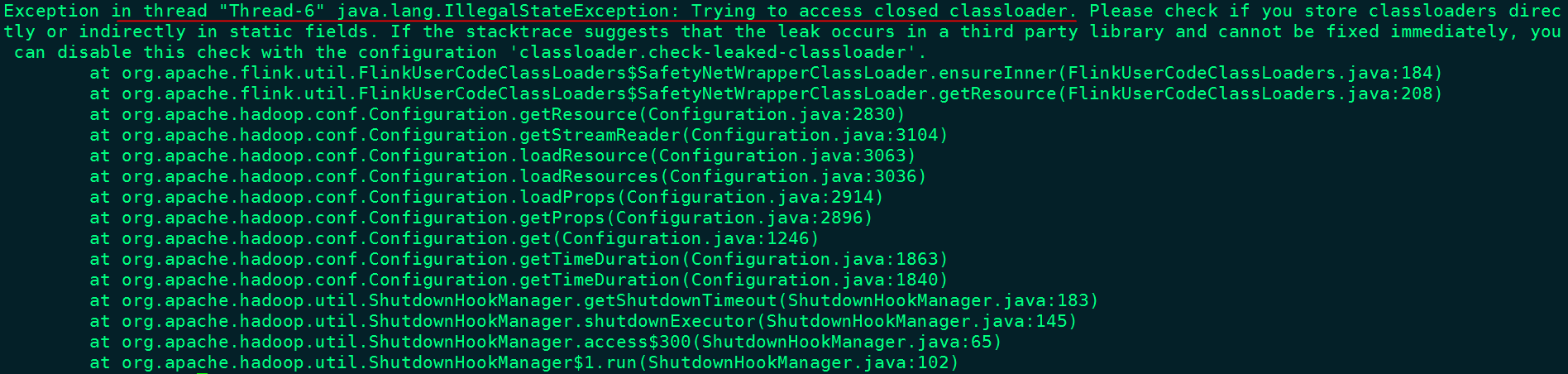
该异常是Hadoop3与Flink整合的bug(https://issues.apache.org/jira/browse/FLINK-19916),不会影响Flink任务基于Yarn提交。错误的原因是Hadoop3启动异步线程来执行一些shutdown钩子,当任务提交后对应的类加载器被释放,这些钩子在作业执行之后执行仍然持有释放的类加载器,因此抛出异常。
取消任务可以使用yarn application -kill ApplicationId也可以执行如下命令:
#取消任务命令执行后对应的 Flink集群也会停止 :flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
[root@node5 bin]# ./flink cancel -t yarn-per-job -Dyarn.application.id=application_1671610064817_0002 805542d84c9944480196ef73911d1b59
[root@node5 bin]# ./flink cancel -t yarn-per-job -Dyarn.application.id=application_1671610064817_0003 56365ae67b8e93b1184d22fa567d7ddf
2、任务提交流程
Flink基于Yarn Per-Job 提交任务时,在提交Flink Job作业的同时启动JobManager并启动Flink的集群,根据提交任务所需资源的情况会动态申请启动TaskManager给当前提交的job任务提供资源。
Yarn Per-Job模式下提交任务流程如下:
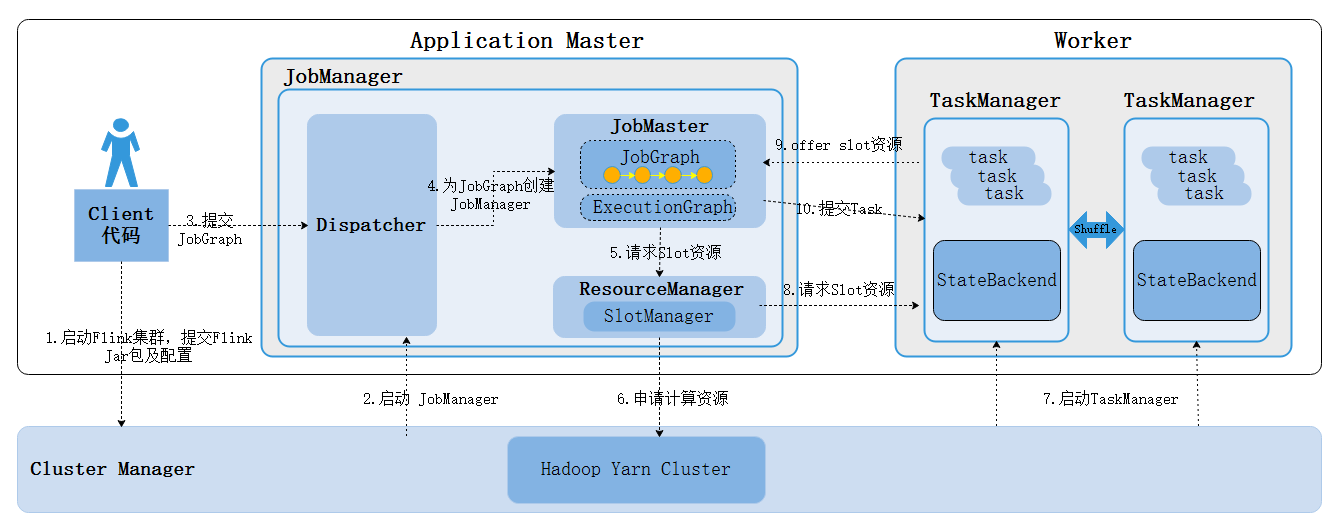
- 客户端提交Flink任务,Flink会将jar包和配置上传HDFS并向Yarn请求Container启动JobManager
- Yarn资源管理器分配Container资源,启动JobManager,并启动Dispatcher、ResourceManager对象。
- 客户端会将任务转换成JobGraph提交给JobManager。
- Dispatcher启动JobMaster并将JobGraph提交给JobMaster。
- JobMaster向ResourceManager申请Slot资源。
- ResourceManager会向Yarn请求Container计算资源
- Yarn分配Container启动TaskManager,TaskManager启动后会向ResourceManager注册Slot
- ResourceManager会在对应的TaskManager上划分Slot资源。
- TaskManager向JobMaster offer Slot资源。
- JobMaster将任务对应的task发送到TaskManager上执行。
Yarn Per-job模式在客户端提交任务,如果在客户端提交大量的Flink任务会对客户端节点性能又非常大的压力,所以在Flink1.15中已经被弃用,后续版本可能会完全剔除,使用Yarn Application模式来替代。
五、Yarn Application模式
Yarn Application 与Per-Job 模式类似,只是提交任务不需要客户端进行提交,直接由JobManager来进行任务提交,每个Flink Application对应一个Flink集群,如果该Flink Application有多个job任务,所有job任务共享该集群资源,TaskManager也是根据提交的Application所需资源情况动态进行申请。
1、任务提交命令
#Yarn Application模式提交任务命令
[root@node5 bin]# ./flink run-application -t yarn-application -c com.lanson.flinkjava.code.chapter3.FlinkAppWithMultiJob /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
以上参数解释同Per-Job模式,命令提交后,查看对应Yarn Application,进入到Flink Application的WebUI,可以看到2个Flink 任务共享该集群资源。

查看集群任务、取消集群任务及停止集群命令如下:
#查看Flink 集群中的Job作业:flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[root@node3 bin]# flink list -t yarn-application -Dyarn.application.id=application_1671610064817_0004
------------------ Running/Restarting Jobs -------------------
108a7b91cf6b797d4b61a81156cd4863 : first job (RUNNING)
5adacb416f99852408224234d9027cc7 : second job (RUNNING)
--------------------------------------------------------------
#取消Flink集群中的Job作业:flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
[root@node3 bin]# flink cancel -t yarn-application -Dyarn.application.id=application_1671610064817_0004 108a7b91cf6b797d4b61a81156cd4863
#停止集群,当取消Flink集群中所有任务后,Flink集群停止,也可以使用yarn application -kill ApplicationID 停止集群
[root@node3 bin]# yarn application -kill application_1671610064817_0004
2/任务提交流程
Flink Yarn Application模式提交任务与Per-Job模式任务提交非常类似,只是客户端不再提交一个个的Flink Job ,而是运行任务后,一次性将Application信息提交给JobManager,JobManager根据每个Flink Job作业由Dispatcher启动对应的JobMaster进行资源申请和任务提交。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。