
- 1.spark****是什么
spark官网地址:https://spark.apache.org/
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
- 2.Spark****的特点
运行速度快:
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中
易用性好:
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法
通用性强:
Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本
高兼容性:
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力
- 3.Spark和mapreduce****对比
1>spark处理数据是基于内存的,而MapReduce****是基于磁盘处理数据的
2>Spark在处理数据时构建了DAG有向无环图,减少了shuffle****和数据落地磁盘的次数
3>Spark是粗粒度资源申请,而MapReduce****是细粒度资源申请
4>lspark只能计算,mapreduce既能计算也能存储
- 4.Spark****的运行及架构
1.基本概念
① RDD:是弹性分布式数据集的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
② DAG:是有向无环图的英文缩写,反映RDD之间的依赖关系。
③ Executor:是运行在工作节点上的一个进程,负责运行任务,并为应用程序存储数据。
④ 应用:用户编写的Spark应用程序。
⑤ 任务:运行在Executor上的工作单元。
⑥ 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
⑦ 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
2.spark运行架构

- 5.什么是宽依赖、窄依赖
窄依赖指的是子RDD的一个分区只依赖于某个父RDD中的一个分区
宽依赖指的是子RDD的每一个分区都依赖于某个父RDD中一个以上的分区
 窄依赖 · · 宽依赖
窄依赖 · · 宽依赖
- 6.什么是****RDD
<1>RDD的概念
a.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
b.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
<2>RDD特性
a.高效的容错性
现有容错机制:数据复制或者记录日志RDD具有天生的容错性:血缘关系,重新计算丢失分区,无需回滚系统,重算过程在不同节点之间并行,只记录粗粒度的操作
b.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
c.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
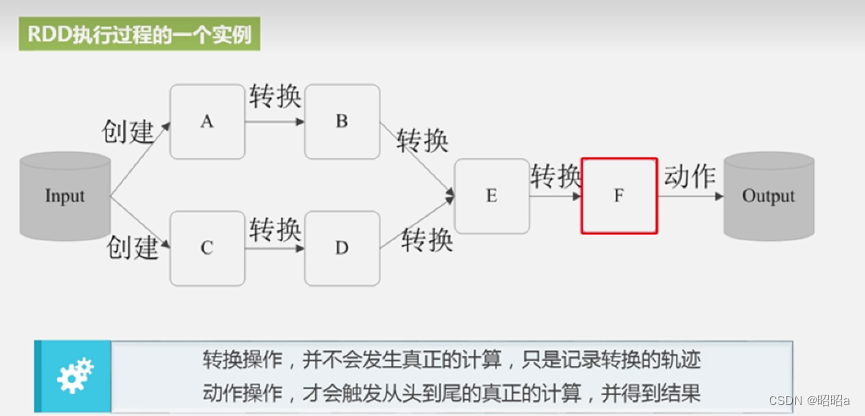
- 7.RDD运行过程
创建RDD对象;
SparkContext负责计算RDD之间的依赖关系,构建DAG;
DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。

- 8.什么是****Scala
Scala是一门现代的多范式编程语言,运行于IAVA平台(JVM,JAVA虚拟机)并兼容现有的JAVA程序
Scala的特点
a. Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
b. Scala语法简洁,能提供优雅的API。
c. Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
版权归原作者 昭昭a 所有, 如有侵权,请联系我们删除。