
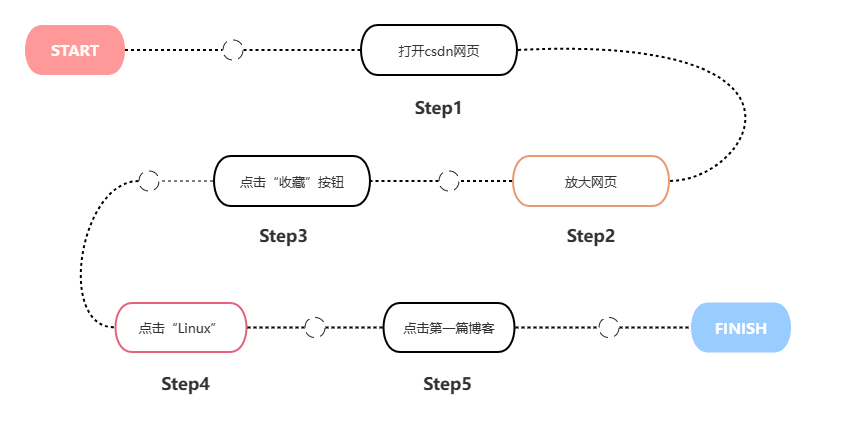
前提 准备好流程
第一步 导包
这里需要提前下载好第三方库:selenium,time。代码及selenium第三方库的下载流程如下:
代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from time import sleep
第三方库的下载流程
1.1右下角点击“Python xx”,选择“Interpreter Settings”
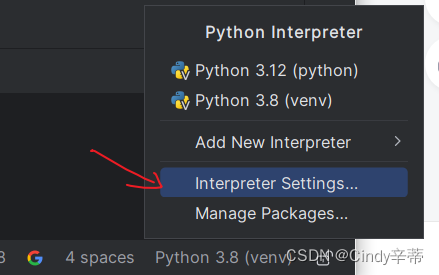
1.2如果下方没有selenium库,点击“+”号

1.3输入“selenium”,选择第一个,点击“Install Package”就可以下载

第二步 设置谷歌浏览器及要打开的网页
这里需要安装好与chrome浏览器版本匹配的chromedriver驱动。全局等待20秒的意思是:定位后面的每一个元素都会等待20秒,20秒内定位到了就直接继续运行后面的代码;20秒后还是定位不到会报no such element: Unable to locate element:xx。代码如下:
option=webdriver.ChromeOptions()
option.add_experimental_option("detach",True)
driver=webdriver.Chrome(options=option)
url="https://blog.csdn.net/2301_76297780?spm=1010.2135.3001.5343"
driver.get(url)
driver.implicitly_wait(20) # 全局等待20秒
driver.maximize_window() #放大网页,全屏
第三步 定位元素
在元素与元素之间加上sleep(2)强制等待,可以避免定位不到情况。代码及定位方法如下:
代码
# 点击收藏夹
driver.find_element(By.CSS_SELECTOR,"#userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.navList > ul > li:nth-child(9)").click()
# 点击Linux
sleep(2)
driver.find_element(By.CSS_SELECTOR,"#userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.mainContent > div > div:nth-child(1) > div > div.collect-list-header").click()
# 点击第一篇文章
sleep(2)
driver.find_element(By.CSS_SELECTOR,"#userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.mainContent > div > div:nth-child(1) > div > div.collect-second-list > div:nth-child(1) > a > div").click()
元素定位方法
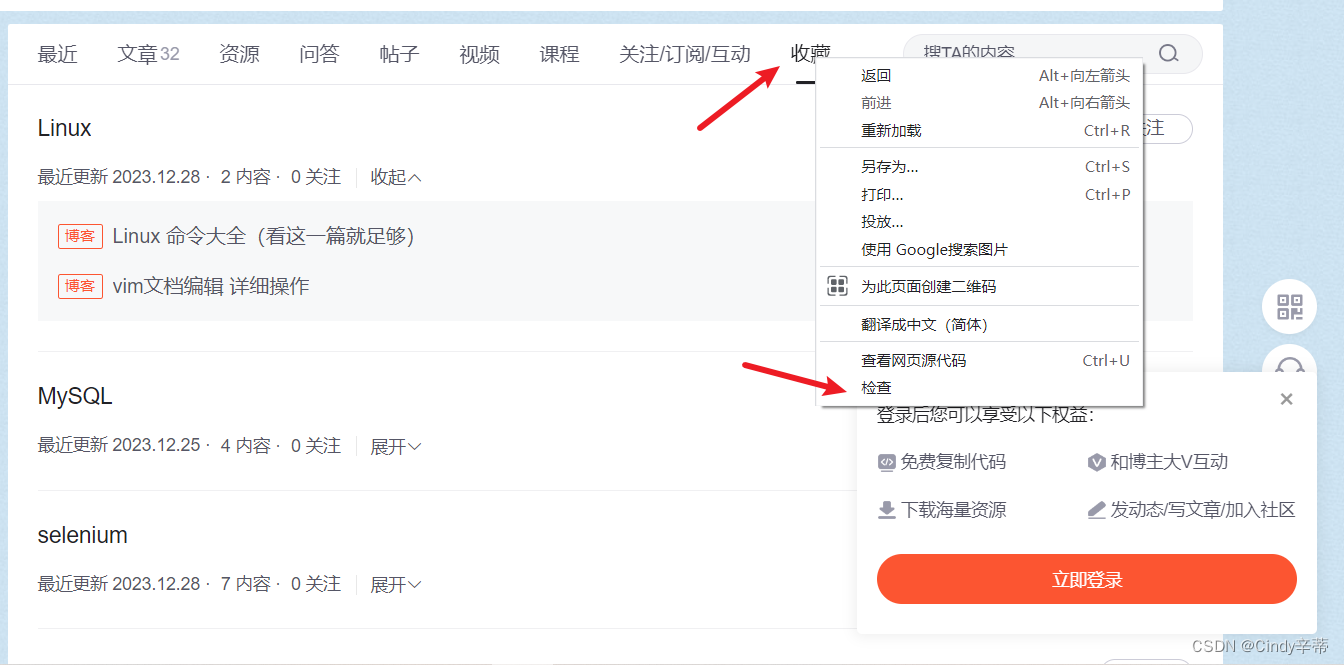
3.1鼠标停留在你想要定位的元素上,右键点击后选择“检查”
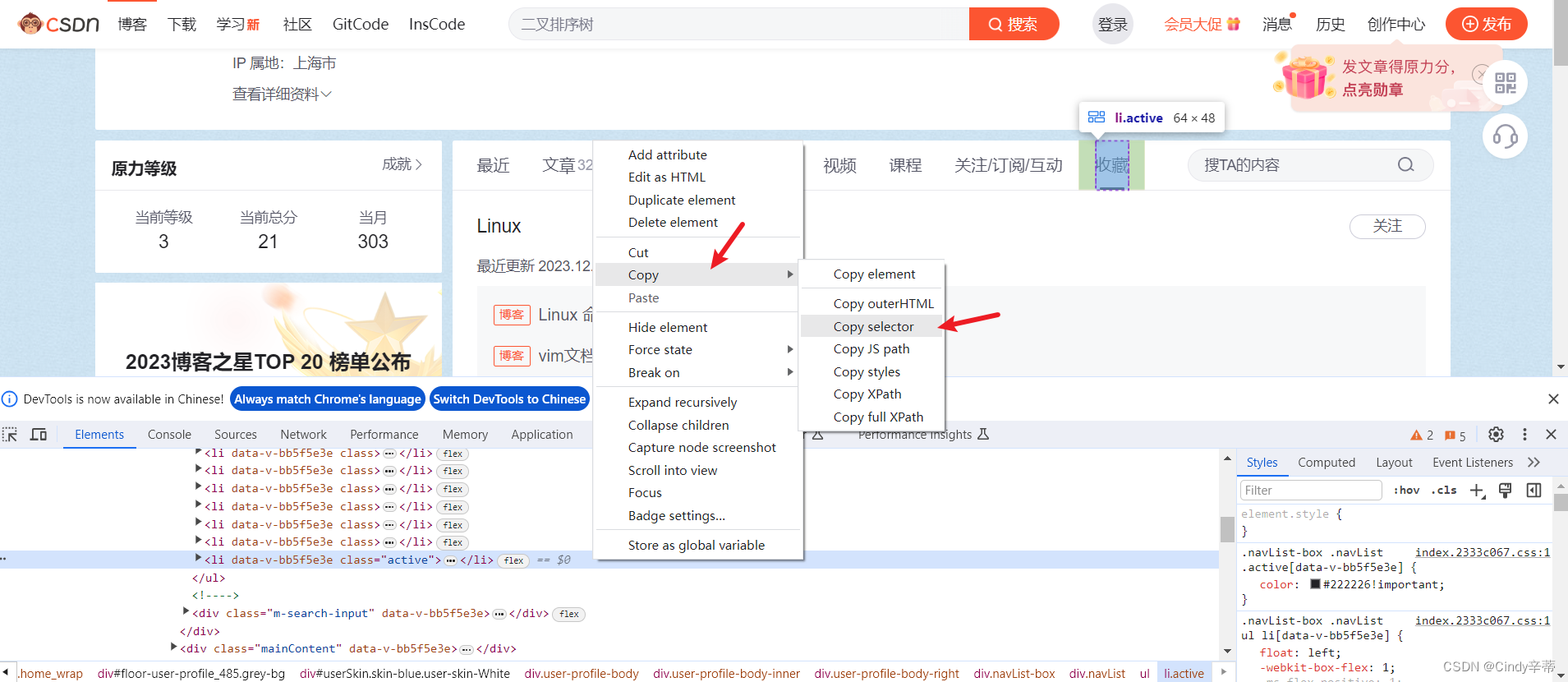
3.2根据箭头指示,选择“dock to bottom”

3.3如图右键点击高亮的行,选择“Copy”,再选“Copy selector” 。如果这里没有出现高亮,右键再点一次“收藏”按钮,选择“检查”。 定位其他元素也是一样的操作方法
运行结果(介意左上角和右下角弹窗的,可以再追加代码点掉“x”按钮)
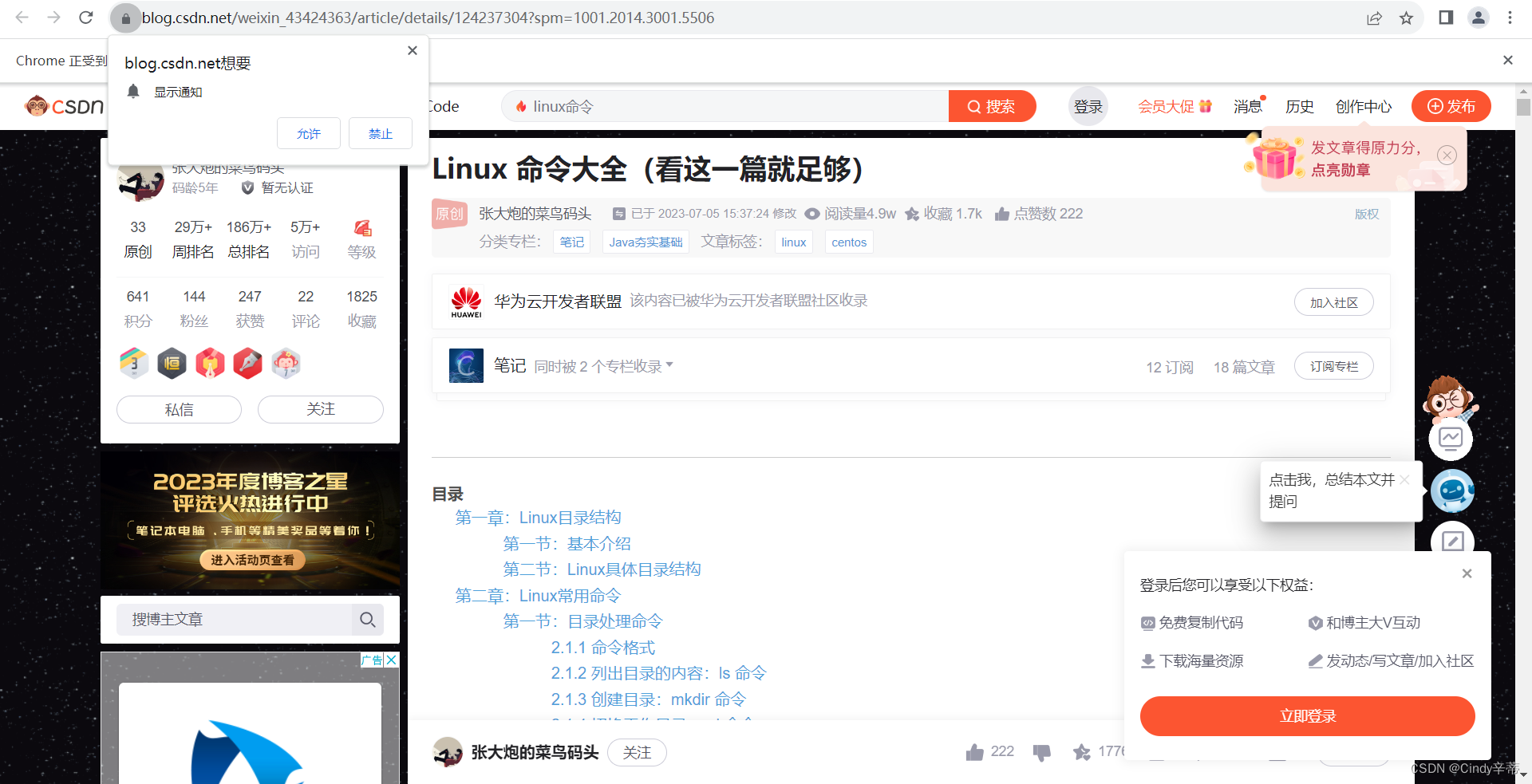
本文转载自: https://blog.csdn.net/2301_76297780/article/details/135310841
版权归原作者 Cindy辛蒂 所有, 如有侵权,请联系我们删除。
版权归原作者 Cindy辛蒂 所有, 如有侵权,请联系我们删除。