
数据存储底层分布
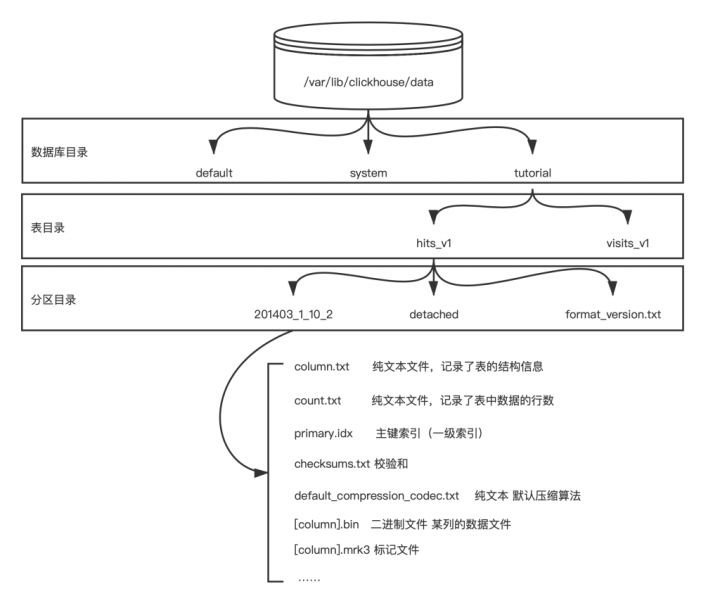
目录名类型说明202103_1_10_2目录分区目录一个或多个,由于分区+LSM生成的detached目录通过DETACH语句卸载后的表分区存放位置format_version.txt文本文件纯文本,记录存储的格式
columns.txt:该文件是一个文本文件,存储了表结构信息,可以用文本编辑打开。
count.txt:该文件也是一个文本文件,存储了该分区下的行数。可以用文本文件打开。在用户执行select count() from xxx时本质上就是直接返回了该文件的内容,而不需要遍历数据。因此clickhouse的**count()的速度非常快**。
[column].bin:真正存储数据的数据文件。每一列都会生成一个单独的bin文件。
skp_idx_[column].idx:跳数索引,在使用了二级索引时会生成,否则这不生成。
数据分区目录命名规则
比如20221115_2_2_0,其中 20221115是分区ID ,2_2对应的是最小的数据块编号和最大的数据块编号,最后的 **_0 **表示目前分区合并的层级。这么命名是为了数据目录合并算法。
分区ID:该值由 insert 数据时分区键的值来决定。分区键支持使用任何一个或者多个字段组合表达式,针对取值数据类型的不同,分区ID的生成逻辑目前有四种规则:
- 不指定分区键:如果建表时未指定分区键,则分区ID默认使用all,所有数据都被写入all分区中。
- 整型字段:如果分区键取值是整型字段,并且无法转换为YYYYMMDD的格式,则会按照该整型字段的字符形式输出,作为分区ID取值。
- 日期类型:如果分区键属于日期格式,或可以转换为YYYYMMDD格式的整型,则按照YYYYMMDD格式化后的字符形式输出,作为分区ID取值。
- 其他类型:如果使用其他类似Float、String等类型作为分区键,会通过对其插入数据的128位Hash值作为分区ID的取值。
MinBlockNum 和 MaxBlockNum: BlockNum 是一个整型的自增长型编号,该编号在单张MergeTree表中从1开始全局累加,当有新的分区目录创建后,该值就加1,对新的分区目录来讲,MinBlockNum 和 MaxBlockNum 取值相同。
Level: 表示合并的层级。相当于某个分区被合并的次数,它不是以表全局累加,而是以分区为单位,初始创建的分区,初始值为0,相同分区ID发生合并动作时,在相应分区内累计加1。
分区目录的合并过程
MergeTree的分区目录和传统意义上其他数据库有所不同。MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。也就是说如果一张数据表没有任何数据,那么也不会有任何分区目录存在。MergeTree的分区目录伴**随着每一批数据的写入**(一次INSERT语句),**MergeTree都会生成一批新的分区目录**。**即便不同批次写入的数据属于相同分区,也会生成不同的分区目录**。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize查询语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)。
但是有些特殊场景下,用户希望立刻删除老的数据目录,这种需求可以在创建MergeTree表的时候通过Settings属性来设置。如下所示
CREATE TABLE partition_directory_merge
(
partition_key Int32,
orderBy_key String,
data String
)
ENGINE = MergeTree()
PARTITION BY partition_key
ORDER BY orderBy_key
SETTINGS old_parts_lifetime = 1
- old_parts_lifetime 这个属性的含义是多久删除老的分区数据目录。单位是秒
版权归原作者 大大大大肉包 所有, 如有侵权,请联系我们删除。