
Kafka基本讲解
一:Kafka介绍
Kafka是分布式消息队列,主要设计用于高吞吐量的数据处理和消息传输,适用于日志处理、实时数据管道等场景。Kafka作为实时数仓架构的核心组件,用于收集、缓存和分发实时数据流,支持复杂的实时数据处理,实时需求分析,实时报表等应用。
二:Kafka基本架构图
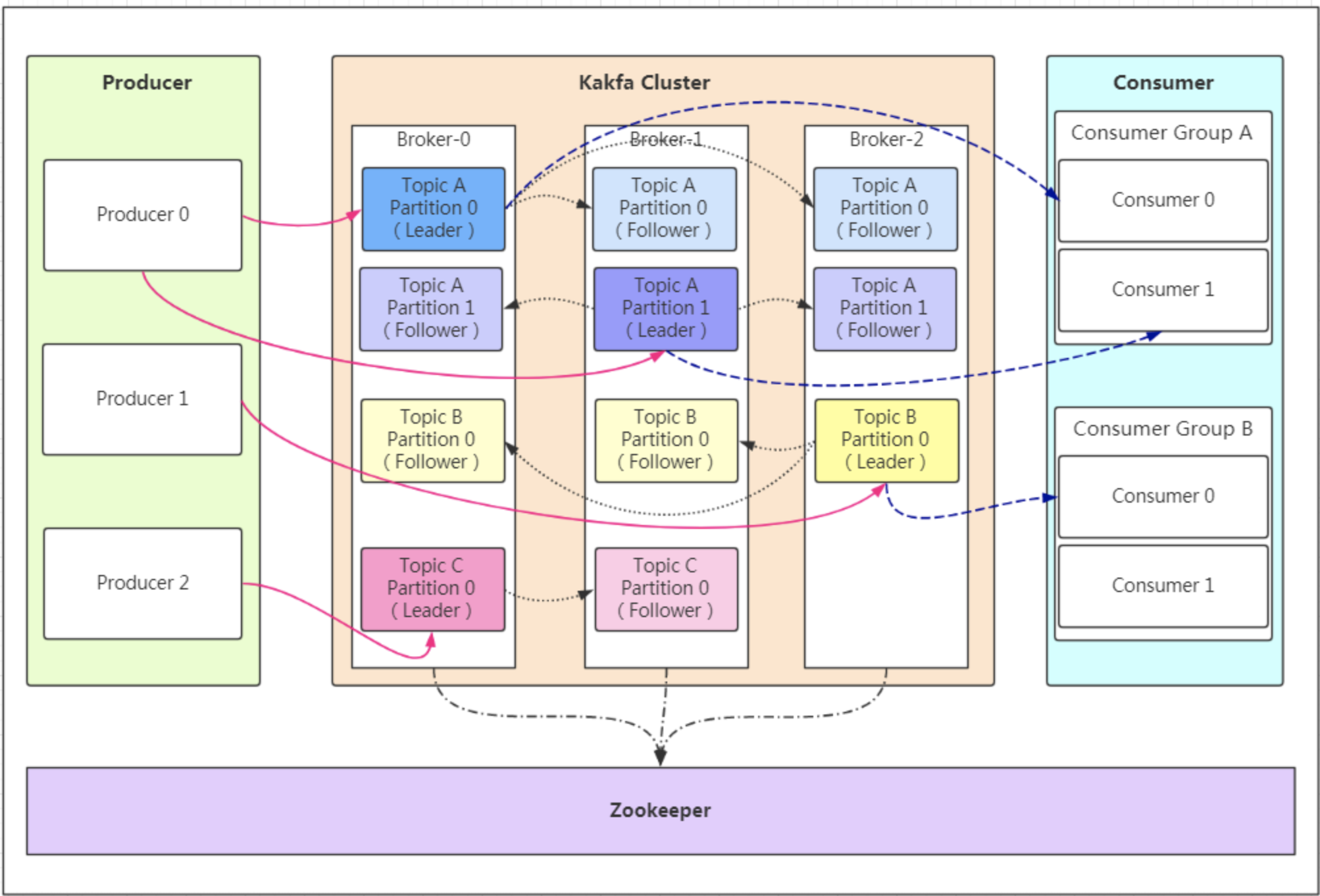
基本讲解:
- zookeeper:统一管理kafka集群> (1)保存kafka相关的元数据> > (2)负责Kafka集群的整体协调和管理> > (3)在Kafka集群中,当某个节点(如Broker或分区领导者Leader)出现故障时,ZooKeeper能够协助进行故障检测和恢复
- Producer:生产者向kafka发送消息,通过【轮询写入】方式,使得消息数据均匀分布,即:传数据给kafka。
- Consumer:消费者从kafka中获取消息(数据)进行消费,一般有三种策略可选(订阅模式,正则模式,指定模式)。
- Kafka集群:> 1. Broker:一台Kafka服务器一般是一个Broker【主要由该机器的核数来决定】,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。> 2. Topic(主题):是数据的逻辑分类单位,用于管理和组织消息流,Topic类似于mysql数据库中的库。Topic分为多个partition存放于不同的kafka服务器上。> 3. partition(分区):每个Partition(分区)是一个有序的队列(分区有序,不能保证全局有序)- Leader:每个partition(分区)都有一个leader(领导者),负责处理该分区的所有读取和写入数据操作(生产者和消费者都面对leader对象进行操作)。- Replica:特殊的Follower。- Follower:每个partition(分区)含有多个follower(跟随者),主要用于与leader(领导者)同步数据,保持数据的一致性。当leader失效时,会从中选一个follower成为新的leader。
三:Kafka特点
1、多副本机制
1.1.容错性(In-Sync Replicas,同步副本集)

讲解:
- 在每个partition(分区)内部中,都含有一个leader(领导者)和多个follower(跟随者)。
- 其中可将其分为ISR队列(此处为三个)和Followers两部分。
- 正常状态(消息数据写入队列):- 1、消息数据写到ISR队列中的每一个节点上(Leader和replica),当写入所有的ISR队列后,才可以进行下一个消息的写入。- 2、Followers中节点可以同步Leader数据,且并无时间限制(时间可长可短)。
- Leader失效场景:- 当Leader失效时,会在ISR队列中选取一个作为新的Leader继续工作,同时会在Followers中选取一个进入ISR队列中。
1.2.读写分离
- Leader 负责写操作
- I S R 中任何一个 replica 都可以读操作
2、多分区(MP,multiple partitions)
每个Topic(主题)可以被划分成多个分区(partition),每个分区在物理上可以存储在不同的Broker节点上。
主要优势:
- 低延时
- 负载均衡:Kafka集群可以在多个Broker节点上均匀地分布分区,使得每个Broker负责处理的分区数量相对均衡【Topic(主题)分区数量最优设计:节点数*物理核数】
- 方便在集群中集成和扩展:Kafka提供了丰富的客户端API,支持多种编程语言,如Java、Python、Go、Scala等。同时,每个partition通过调整以适应它所在的机器(水平扩展),而一个Topic又可以有多个partition组成,因此整个集群可以适应适合的数据,从而达到扩缩容效果。
3、零拷贝
数据可以直接从磁盘传输到网络接口,避免了传统I/O操作中的多次内存拷贝和上下文切换,提高数据传输效率。
4、产销解耦
基本讲解:
- Kafka作为一种分布式消息中间件。生产者只需要将数据发送到Kafka的特定主题(Topic)中,无需知道数据的具体消费者是谁;消费者只需要从Kafka订阅特定的主题,并拉取数据进行处理,无需知道数据的来源是从何而来【生产者 —> Kafka <— 消费者】
- 生产者数量:分区数 个生产者【轮询写入】,均匀分布。
- 消费者数量:分区数 个消费者一对一读取,并行消费。=> 分布式最佳效果:spark处理的算子分区数(spark并行度) = kafka的分区数(有多少个队列)【分区上限主要由"核数"决定】。
四:消费者策略(读取数据方式)
Kafka为消费者提供了三种类型的订阅消费模式:subscribe(订阅模式)、SubscribePattern(正则订阅模式)、assign(指定模式)。
subscribe与SubscribePattern讲解
基本认知:
- subscribe(订阅模式)与SubscribePattern(正则订阅模式)原理基本一致。
- 区别:subscribe(订阅模式)适用于【单主题】,SubscribePattern(正则订阅模式)适用于【多主题】。
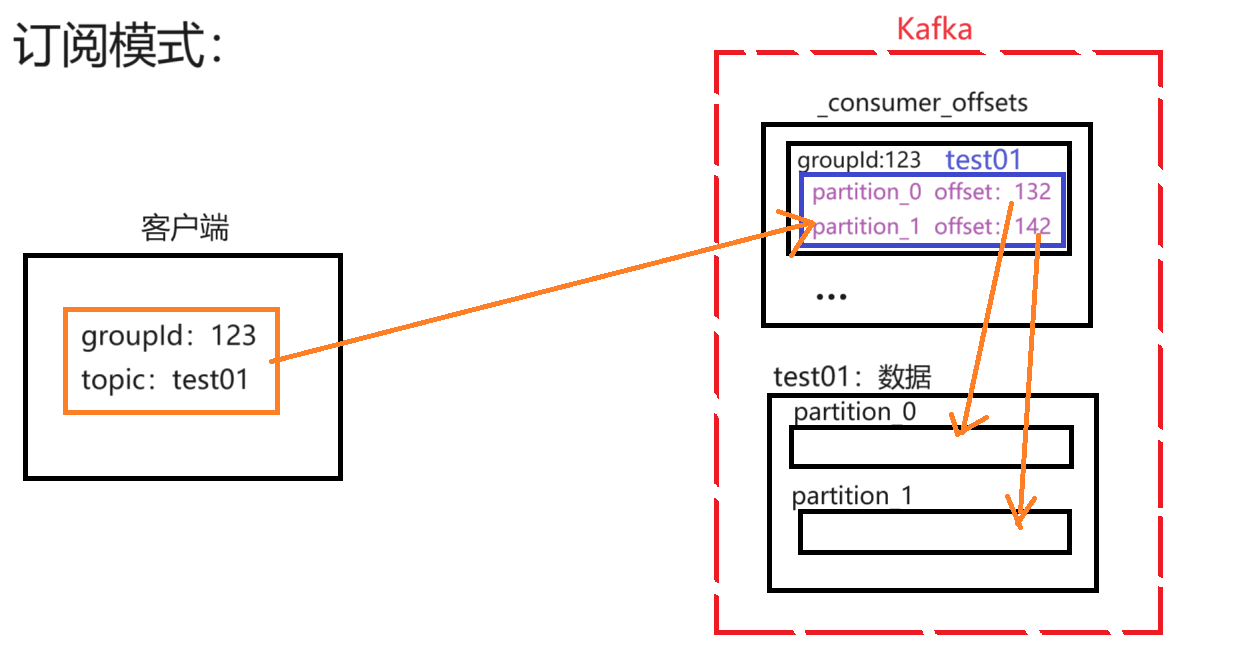
讲解:
- 客户端提供groupId和订阅的主题(topic),会先找到这个groupId为123所对应的主题(topic),其中会有记录其offset(偏移量),然后通过这个这个offset(偏移量)继续从test01中进行数据的读取操作。
assign讲解

讲解:
- Redis与客户端之间进行数据交互,会将offset(偏移量)存储于Redis中。客户端提供topic(主题)给Redis,与offset形成键值对的形式,进而可以从test01中进行数据的读取操作。
五:Kafka命令讲解(shell 控制台处理)
1、查看主题
# --bootstrap-server kafka的地址:端口号
kafka-topics.sh --list --bootstrap-server single:9092

2、创建主题
# --topic 主题名称# --partitions 分区数# --replication-factor 每个分区的副本数# --bootstrap-server kafka的地址:端口号
kafka-topics.sh --create--topic test01 --partitions1 --replication-factor 1 --bootstrap-server single:9092

3、查看主题详情
# --topic 主题名称# --bootstrap-server kafka的地址:端口号
kafka-topics.sh --describe--topic test01 --bootstrap-server single:9092

4、创建控制台【生产者】
# --topic 主题名称# --broker-list single:9092 => 指定主题
kafka-console-producer.sh --broker-list single:9092 --topic test01 < /root/ebs_act_log/transaction_log/part-00001
在Kafka客户端工具中
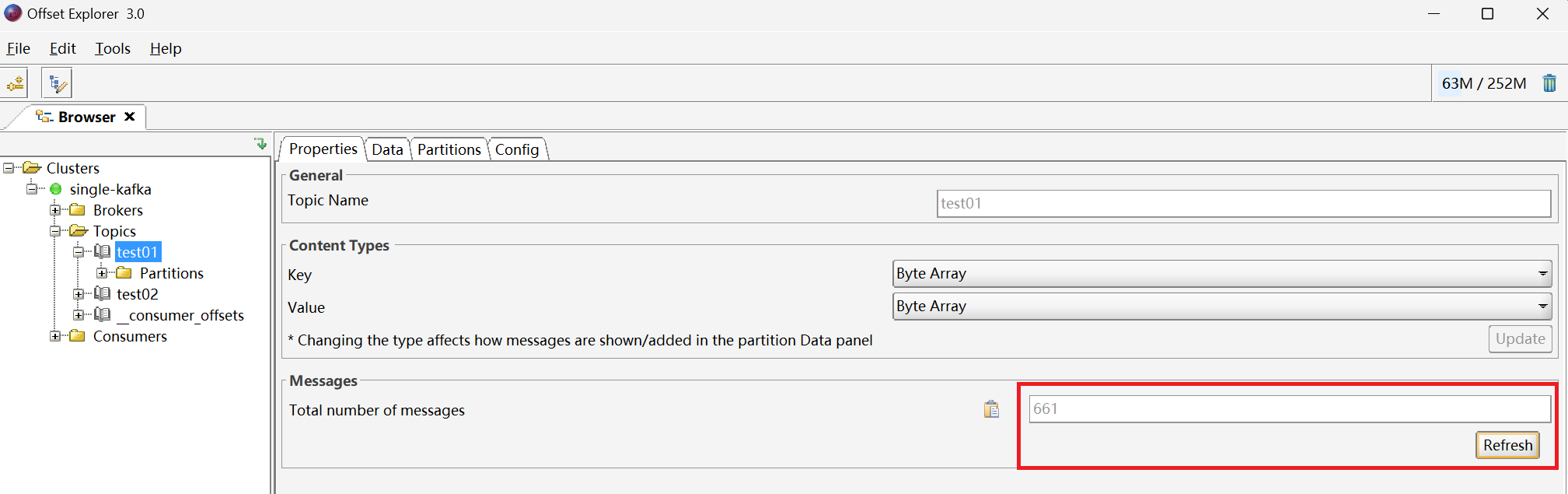
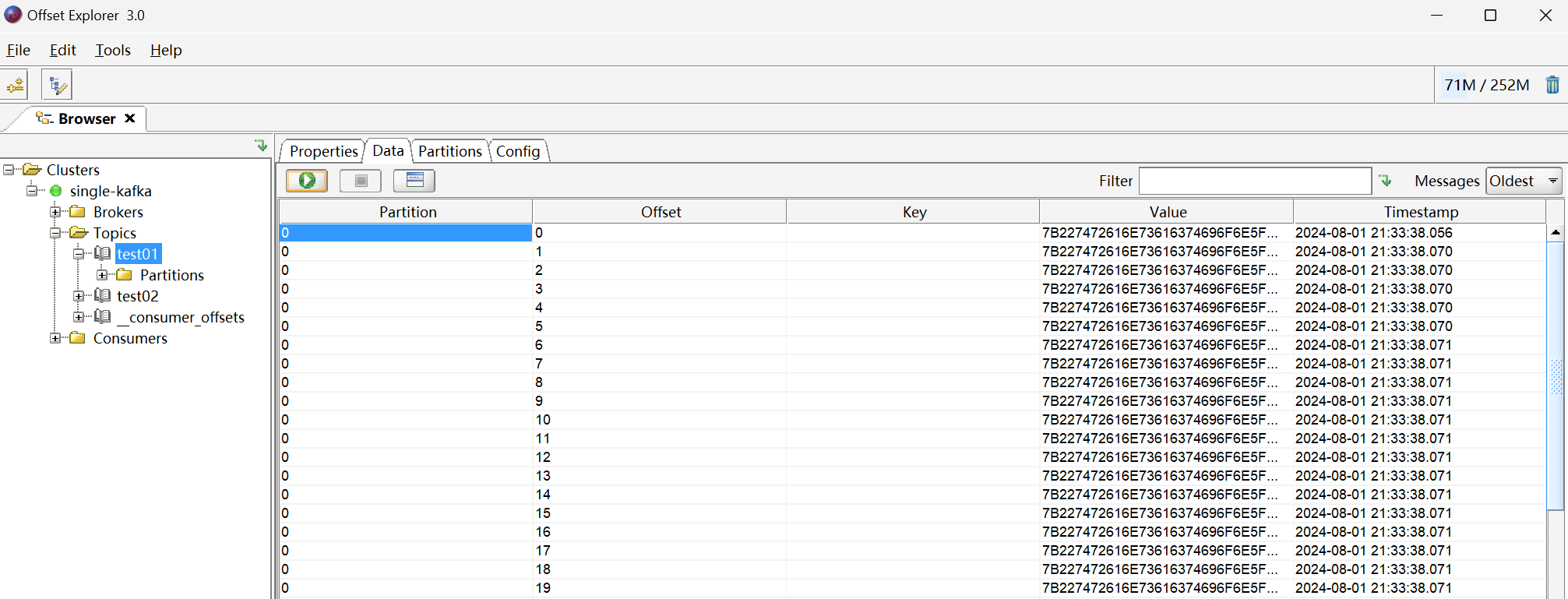
5、创建控制台【消费者】
# --bootstrap-server kafka的地址:端口号# --topic 主题# --property print.key=true
kafka-console-consumer.sh --bootstrap-server single:9092 --topic test01 --propertyprint.key=true --from-beginning
6、删除主题和数据(不能被正在生产或消费)
kafka-topics.sh --bootstrap-server single:9092 --delete--topic test01

Kafka实战(Scala操作)
Kafka实战(Scala操作)
本文转载自: https://blog.csdn.net/qq_73339471/article/details/140867481
版权归原作者 frimiku 所有, 如有侵权,请联系我们删除。
版权归原作者 frimiku 所有, 如有侵权,请联系我们删除。