
你好呀!
这里是小易同学的博客,一名大二在校生。
写博客是为了记录自己的学习过程,同时也希望能帮助到需要帮助的人。
如果我的博客可以帮助到你,不妨给我一个关注🥰
前言
对字符串截取,这里主要有两种方法:
一是用split截取字符串

二是用substr截取字符串

提示:以下是本篇文章正文内容
一、目标
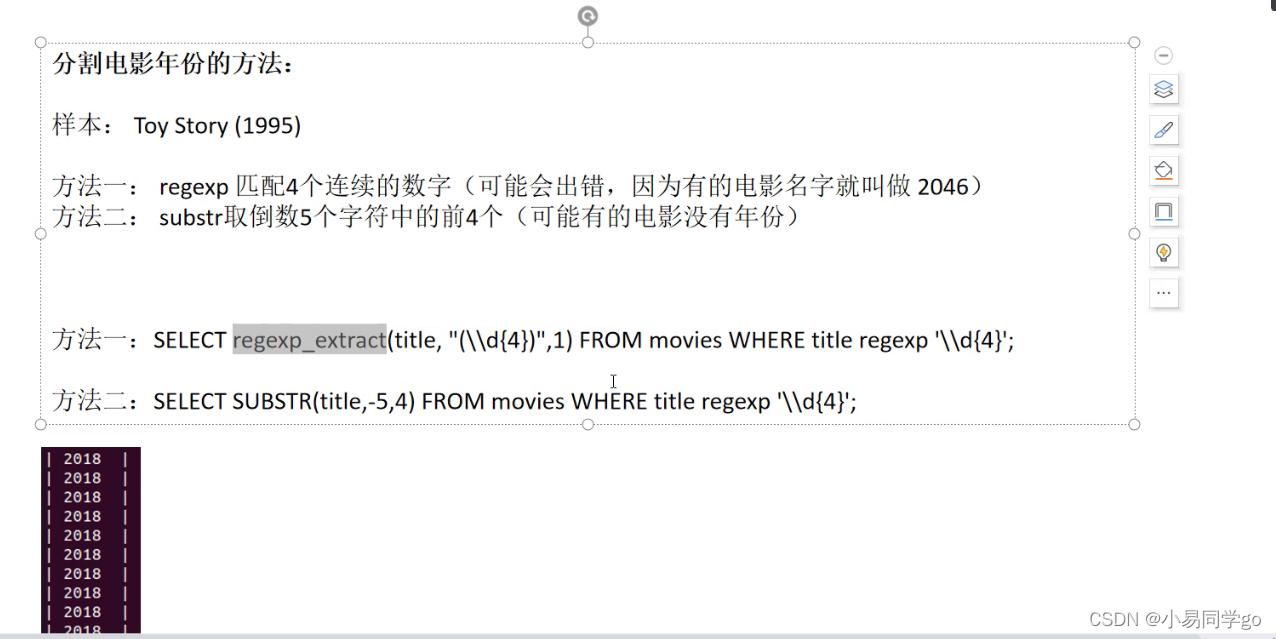
将hive中movie表的年份数字取出来,并统计每一年有多少部电影
二、截取字符串,取出年份数字
1.split
注:在分割时加“\”是因为()是特殊字符,需要加\才能让hive识别
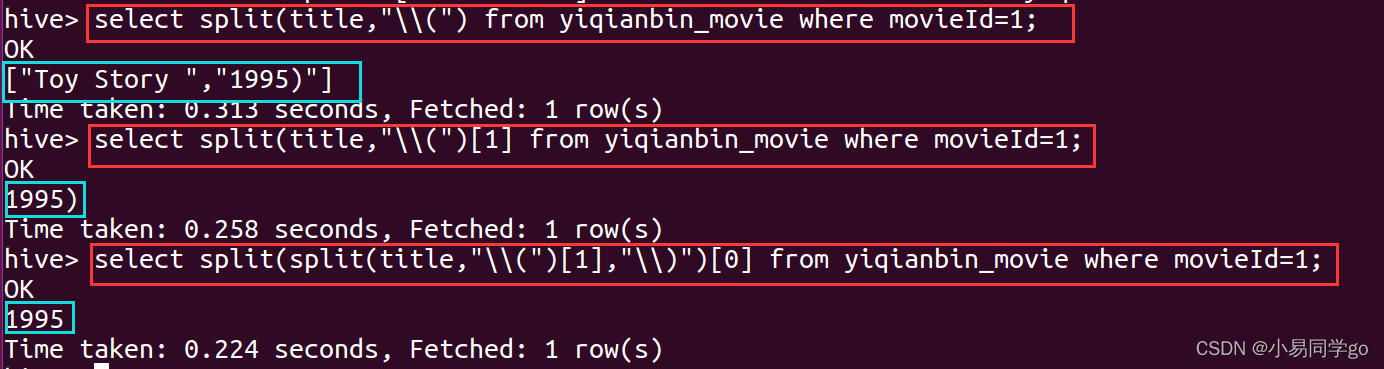
(1)因为数据太多,先用一条数据来测试,也就是movieId=1这条数据
select split(title,"\(") from yiqianbin_movie where movieId=1;
select split(title,"\(")[1] from yiqianbin_movie where movieId=1;
select split(split(title,"\(")[1],"\)")[0] from yiqianbin_movie where movieId=1;
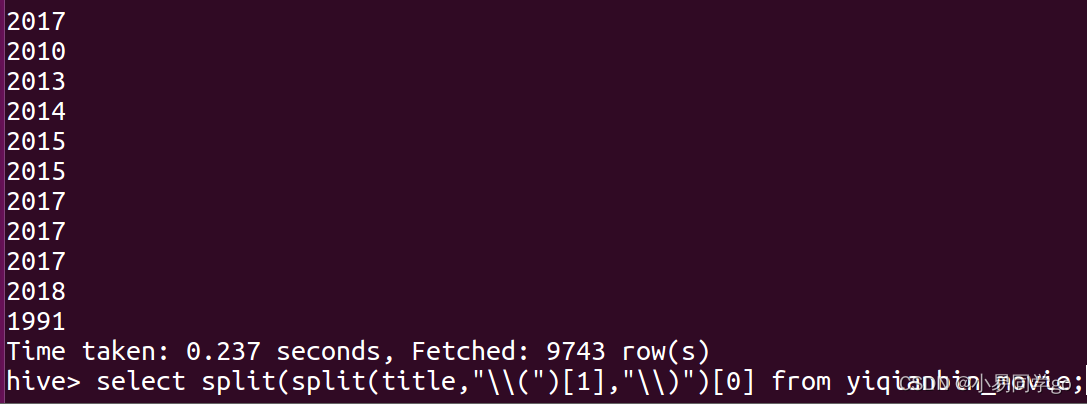
(2)取出了1995,那么就可以直接去掉后面where的条件,查出全部的年份
select split(split(title,"\(")[1],"\)")[0] from yiqianbin_movie;
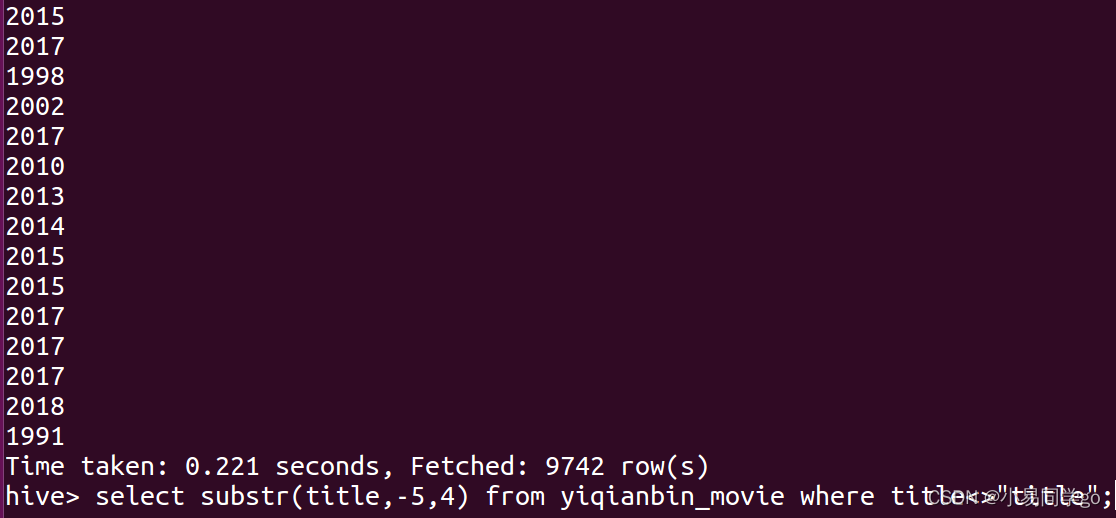
2.substr
注:这里加 where title<>"title" 是为了去掉表头“title”
三、统计每个数字出现了多少次

实例:创建临时表,一步完成计数
select year,count(1) from
(select regexp_extract(title, "(\d{4})",1)as year from yiqianbin_movie where title regexp '\d{4}') temp
group by year;

补充
杂七杂八
select * from yiqianbin_movie where title not regexp '\d{4}';
create table movie_year as select *,substr(title,-5,4) as year from yiqianbin_movie;
create table movies_year as select *,regexp_extract(title, "(\d{4})",1)as year from yiqianbin_movie where title regexp '\d{4}';
select substr(title,-5,4)from yiqianbin_movie where title regexp '\d{4}';
select year,count(1) from movies_year group by year;
查出括号中的四个数字
select regexp_extract(title,"\((\d{4})\)") from yiqianbin_movie;
查出哪一年出的电影最多,即年份出现最多的数字对应的电影名
select year,count(1) as year1 from movies_year group by year order by year1 desc limit 1;
将多个电影类型分开
先分开
select explode(split(genres,'\|')) as type from yiqianbin_movie;
之后将分开的导入一个新表
create table movies_type as select explode(split(genres,'\|')) as type from yiqianbin_movie;
将类型的多少按降序排下来
select type,count(1) as count from movies_type group by type order by count desc;
临时表(一步完成)
select type,count(1) as count from (select explode(split(genres,'\|')) as type from yiqianbin_movie)temp group by type order by count desc;
查出评分次数最高的电影
select movieId,count(1) as count from yiqianbin_ratings group by movieId order by count desc limit 1;
select * from(select movieId,count(1) as count from yiqianbin_ratings group by movieId order by count desc limit 1)t left join yiqianbin_movie m on t.movieId = m.movieId;
什么类型的电影评分最高 第四行是一个视图查询
1.先连接查询,每部电影的评分+分类
2.分类 行专列
3.按类型分组统计
select type,avg(rating) as avgrating from
(select t1.rating,type.col as type from(select r.rating,m.genres from yiqianbin_ratings r
left join yiqianbin_movie m on r.movieId = m.movieId)t1
lateral view explode(split(t1.genres,'\|')) type)t2
group by type order by avgrating desc
limit 10;
按年份统计电影数量
create table movies_year_result(year string,num string);
insert into movies_year_result
select year,count(1) from
(select substr(title,-5,4) as year from yiqianbin_movie where title regexp '\d{4}')t group by year;
什么类型电影最多
create table genres_top10_result(type string,num string);
insert into genres_top10_result
select type,count(1) as total from
(select explode(split(genres,'\|')) as type from yiqianbin_movie)t group by type
order by total desc limit 10;
评分人气最高电影top10
create table hot_top10_result(title string,rating string);
insert into hot_top10_result
select m.title,t.total from (
select movieId,count(1) as total
from yiqianbin_ratings group by movieId
order by total desc limit 10)t
left join yiqianbin_movie m on t.movieId = m.movieId;
高频词top10
create table tag_top10_result(tag string,num string);
insert into tag_top10_result
select tag,count(1) as total from
(select explode(split(tag,'\s')) as tag from yiqianbin_tags)t
group by tag
order by total desc limit 10;
评分最高电影top10
create table rating_top10_result(title string,rating string);
insert into rating_top10_result
select m.title,t.avgrating from(
select movieId,avg(rating) as avgrating
from yiqianbin_ratings
group by movieId
order by avgrating desc limit 10)t
left join yiqianbin_movie m on t.movieId = m.movieId;
版权归原作者 小易同学go 所有, 如有侵权,请联系我们删除。