
描述:
想知道两个表或两个视图里是否有相同的数据(行数和值)。考虑如下所示的视图。
create view V
as
select * from emp where deptno != 10
union all
select * from emp where ename = 'WARD'
select * from V
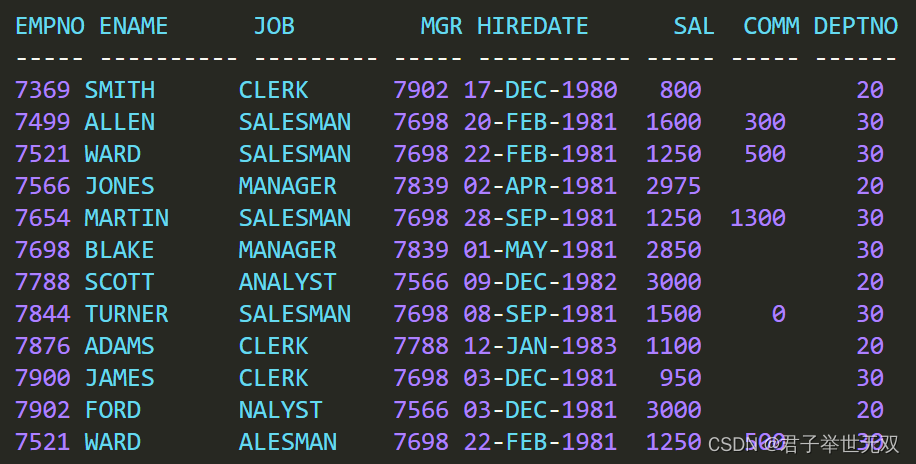
我希望确定该视图是否和
EMP
表有完全相同的数据。与员工 WARD 相关的数据有两行,这表明相应的解决方案不仅要找出来不同的数据,还要找到重复的数据。根据
EMP
表的数据,二者的不同之处包括 3 行部门编号为
10
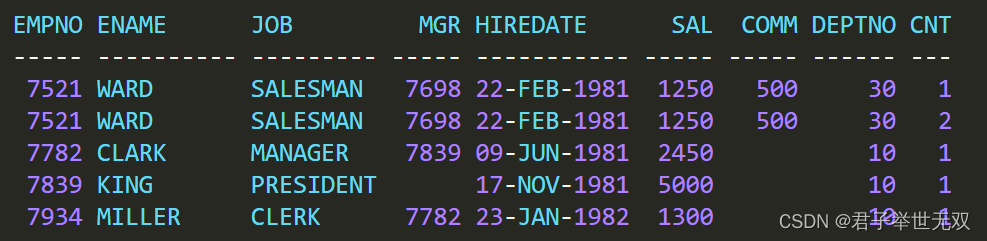
的数据以及两行员工 WARD 的数据。我希望返回如下所示的结果集。
方法:
使用求差集的函数(
MINUS
或
EXCEPT
,这取决于你使用的数据库管理系统)可以很容易地比较表中的数据。如果你所使用的数据库管理系统没有提供类似功能,则可以使用关联子查询。
DB2 和 PostgreSQL
使用集合运算
EXCEPT
和
UNION ALL
找出视图
V
和
EMP
表的不同之处。
1 (
2 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
3 count(*) as cnt
4 from V
5 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
6 except
7 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
8 count(*) as cnt
9 from emp
10 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
11 )
12 union all
13 (
14 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
15 count(*) as cnt
16 from emp
17 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
18 except
19 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
20 count(*) as cnt
21 from V
22 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
23 )
Oracle
使用集合运算
MINUS
和
UNION ALL
找出视图
V
和
EMP
表的不同之处。
1 (
2 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
3 count(*) as cnt
4 from V
5 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
6 minus
7 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
8 count(*) as cnt
9 from emp
10 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
11 )
12 union all
13 (
14 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
15 count(*) as cnt
16 from emp
17 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
18 minus
19 select empno,ename,job,mgr,hiredate,sal,comm,deptno,
20 count(*) as cnt
21 from v
22 group by empno,ename,job,mgr,hiredate,sal,comm,deptno
23 )
MySQL 和 SQL Server
使用关联子查询和
UNION ALL
找出那些存在于视图
V
而不存在于
EMP
表的数据,以及存在于
EMP
表而不存在于视图
V
的数据,并将它们合并起来。
1 select *
2 from (
3 select e.empno,e.ename,e.job,e.mgr,e.hiredate,
4 e.sal,e.comm,e.deptno, count(*) as cnt
5 from emp e
6 group by empno,ename,job,mgr,hiredate,
7 sal,comm,deptno
8 )e
9 where not exists (
10 select null
11 from (
12 select v.empno,v.ename,v.job,v.mgr,v.hiredate,
13 v.sal,v.comm,v.deptno, count(*) as cnt
14 from v
15 group by empno,ename,job,mgr,hiredate,
16 sal,comm,deptno
17 )v
18 where v.empno = e.empno
19 and v.ename = e.ename
20 and v.job = e.job
21 and v.mgr = e.mgr
22 and v.hiredate = e.hiredate
23 and v.sal = e.sal
24 and v.deptno = e.deptno
25 and v.cnt = e.cnt
26 and coalesce(v.comm,0) = coalesce(e.comm,0)
27 )
28 union all
29 select *
30 from (
31 select v.empno,v.ename,v.job,v.mgr,v.hiredate,
32 v.sal,v.comm,v.deptno, count(*) as cnt
33 from v
34 group by empno,ename,job,mgr,hiredate,
35 sal,comm,deptno
36 )v
37 where not exists (
38 select null
39 from (
40 select e.empno,e.ename,e.job,e.mgr,e.hiredate,
41 e.sal,e.comm,e.deptno, count(*) as cnt
42 from emp e
43 group by empno,ename,job,mgr,hiredate,
44 sal,comm,deptno
45 )e
46 where v.empno = e.empno
47 and v.ename = e.ename
48 and v.job = e.job
49 and v.mgr = e.mgr
50 and v.hiredate = e.hiredate
51 and v.sal = e.sal
52 and v.deptno = e.deptno
53 and v.cnt = e.cnt
54 and coalesce(v.comm,0) = coalesce(e.comm,0)
55 )
扩展知识:
尽管使用了不同的方法,但上述解决方案的原理并无差别。
(1) 首先,找出存在于
EMP
表而不存在于视图
V
的行;
(2) 然后与存在于视图
V
而不存在于
EMP
表的行合并(
UNION ALL
)。
如果两个表完全相同,则不会返回任何数据。如果两个表有不同之处,那么将返回那些不同的行。在比较两个表的时候,比较容易的做法是,在比较数据之前先单独比较行数。下面是一个行数比较的简单示例,适用于所有数据库管理系统。
select count(*)
from emp
union
select count(*)
from dept

因为
UNION
子句会过滤掉重复项,所以如果两个表的行数相同,则只会返回一行数据。本例中返回了两行数据,这说明两个表中没有完全相同的数据。
DB2、Oracle 和 PostgreSQL
MINUS
和
EXCEPT
的作用相同,所以这里只讨论
EXCEPT
。
UNION ALL
前后的两个查询语句非常相似。因此,为了说明这个解决方案的原理,我们将直接执行位于
UNION ALL
前面的那个查询。执行第 1 行至第 11 行后产生的结果集如下所示。
(
select empno,ename,job,mgr,hiredate,sal,comm,deptno,
count(*) as cnt
from V
group by empno,ename,job,mgr,hiredate,sal,comm,deptno
except
select empno,ename,job,mgr,hiredate,sal,comm,deptno,
count(*) as cnt
from emp
group by empno,ename,job,mgr,hiredate,sal,comm,deptno
)

上述结果集显示从视图
V
中查询到了一行数据,该行数据要么不存在于
EMP
表,要么它在视图
V
中出现的次数与
EMP
表中的不一致。对于本例而言,查询找到了员工 WARD 的重复行。如果你仍然不理解该结果集是如何产生的,可以分别执行位于
EXCEPT
前后的两个查询。你会发现,两个结果集的不同之处仅仅在于视图
V
中员工 WARD 相关行的
CNT
值。
位于
UNION ALL
后面的查询语句执行了和
UNION ALL
前面的查询相反的操作。该查询找出了那些存在于
EMP
表而不存在于视图
V
的行。
(
select empno,ename,job,mgr,hiredate,sal,comm,deptno,
count(*) as cnt
from emp
group by empno,ename,job,mgr,hiredate,sal,comm,deptno
minus
select empno,ename,job,mgr,hiredate,sal,comm,deptno,
count(*) as cnt
from v
group by empno,ename,job,mgr,hiredate,sal,comm,deptno
)

上述两个结果集通过
UNION ALL
合并后即可得到最终的结果集。
MySQL 和 SQL Server
位于
UNION ALL
前后的两个查询语句非常相似。为了理解基于子查询的解决方案,我们直接执行
UNION ALL
前面的查询。下面的查询是第 1 行至第 27 行的内容。
select *
from (
select e.empno,e.ename,e.job,e.mgr,e.hiredate,
e.sal,e.comm,e.deptno, count(*) as cnt
from emp e
group by empno,ename,job,mgr,hiredate,
sal,comm,deptno
) e
where not exists (
select null
from (
select v.empno,v.ename,v.job,v.mgr,v.hiredate,
v.sal,v.comm,v.deptno, count(*) as cnt
from v
group by empno,ename,job,mgr,hiredate,
sal,comm,deptno
) v
where v.empno = e.empno
and v.ename = e.ename
and v.job = e.job
and v.mgr = e.mgr
and v.hiredate = e.hiredate
and v.sal = e.sal
and v.deptno = e.deptno
and v.cnt = e.cnt
and coalesce(v.comm,0) = coalesce(e.comm,0)
)

注意,这里比较的不是
EMP
表和视图
V
,而是内嵌视图
E
和内嵌视图
V
。计算出每一行数据出现的次数,并作为查询结果的一列返回。我们要比较每一行的数据及其出现的次数。如果你还是不理解比较操作是如何执行的,不妨单独执行两个子查询。下一步是找出存在于内嵌视图
E
而不存在于内嵌视图
V
的所有行(包括
CNT
)。该操作使用了关联子查询和
NOT EXISTS
。连接查询将确定哪些行是相同的,
NOT EXISTS
则筛选出内嵌视图
E
中与连接查询结果不匹配的行。
UNION ALL
后面的查询语句做了相反的操作,它找出了所有存在于内嵌视图
V
而不存在于内嵌视图
E
的行。
select *
from (
select v.empno,v.ename,v.job,v.mgr,v.hiredate,
v.sal,v.comm,v.deptno, count(*) as cnt
from v
group by empno,ename,job,mgr,hiredate,
sal,comm,deptno
) v
where not exists (
select null
from (
select e.empno,e.ename,e.job,e.mgr,e.hiredate,
e.sal,e.comm,e.deptno, count(*) as cnt
from emp e
group by empno,ename,job,mgr,hiredate,
sal,comm,deptno
) e
where v.empno = e.empno
and v.ename = e.ename
and v.job = e.job
and v.mgr = e.mgr
and v.hiredate = e.hiredate
and v.sal = e.sal
and v.deptno = e.deptno
and v.cnt = e.cnt
and coalesce(v.comm,0) = coalesce(e.comm,0)
)

版权归原作者 君子举世无双 所有, 如有侵权,请联系我们删除。