
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序
Kafka 官网:https://kafka.apache.org/
Kafka 在2.8版本之后,移除了对Zookeeper的依赖,将依赖于ZooKeeper的控制器改造成了基于Kafka Raft的Quorm控制器,因此可以在不使用ZooKeeper的情况下实现集群
本文讲解 Kafka KRaft 模式集群搭建
笔者使用3台服务器,它们的 ip 分别是 192.168.3.232、192.168.2.90、192.168.2.11
1、官网下载 Kafka
这里笔者下载最新版3.6.0

下载完成

将kafka分别上传到3台linux

在3台服务器上分别创建 kafka 安装目录
mkdir /usr/local/kafka
在3台服务器上分别将 kafka 安装包解压到新创建的 kafka 目录
tar -xzf kafka_2.13-3.6.0.tgz -C /usr/local/kafka

2、配置 Kafka
进入配置目录
cd /usr/local/kafka/kafka_2.13-3.6.0/config/kraft

编辑配置文件
vi server.properties
server.properties 配置说明
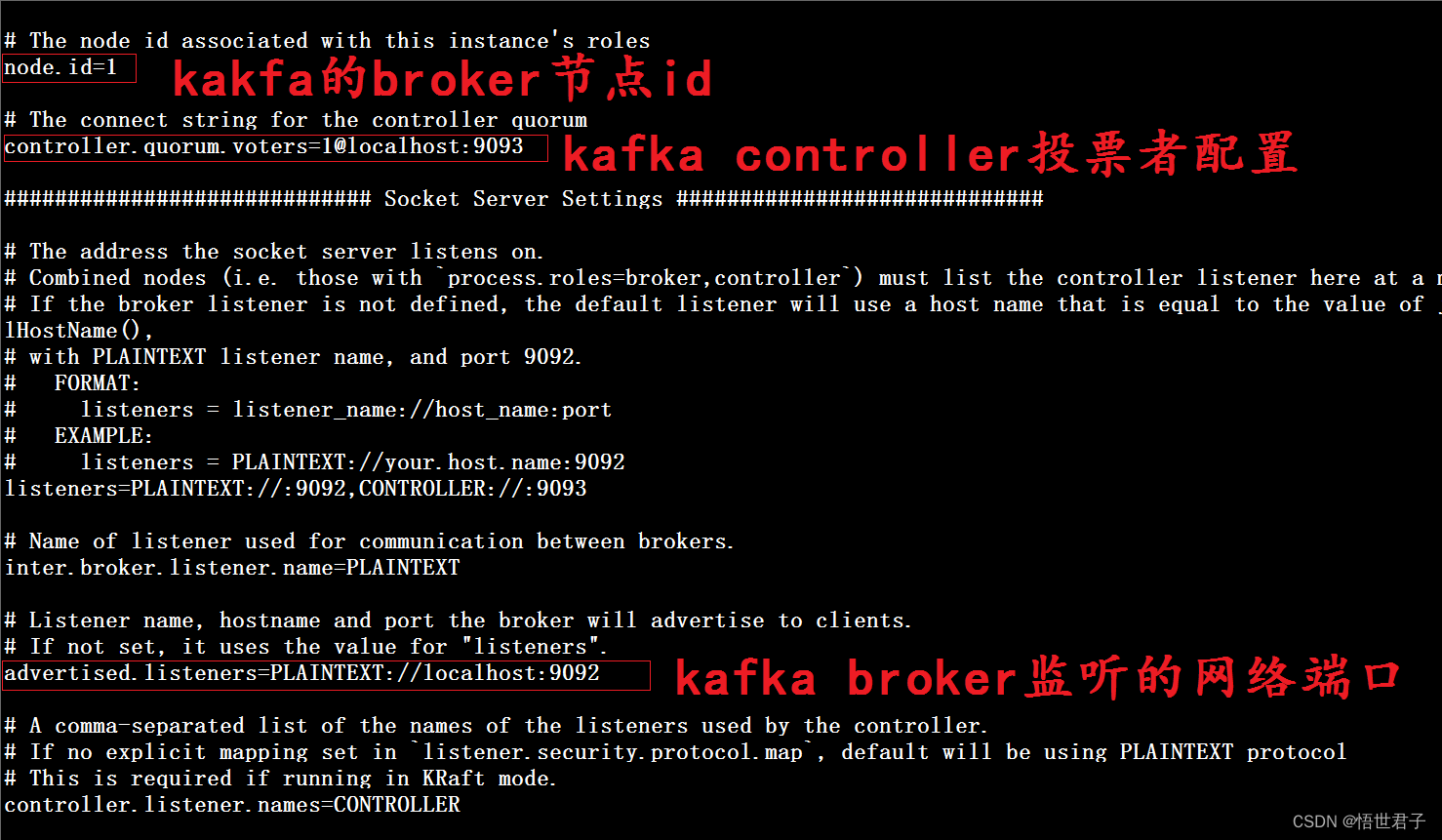
node.id 是kafka的broker节点id
controller.quorum.voters 配置的是 kafka 集群中的其他节点,kafka Controller的投票者配置,定义了一组Controller节点,其中包括它们各自的 id 和网络地址
**advertised.listeners **是节点自己的监听地址
192.168.3.232 节点配置
node.id = 1

192.168.2.90 节点配置
node.id = 2

192.168.2.11节点配置
node.id = 3

3、创建 KRaft 集群
生成集群id
在任意一个节点上执行就行,笔者使用 192.168.3.232 节点
进入bin 目录
cd /usr/local/kafka/kafka_2.13-3.6.0/bin
执行生成集群 id 命令
./kafka-storage.sh random-uuid
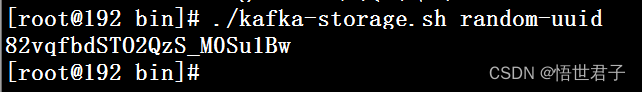
生成后保存生成的字符串 ** 82vqfbdSTO2QzS_M0Su1Bw**
然后分别在3台机器上执行下面命令
为方便执行命令,先回到 kafka安装目录
cd /usr/local/kafka/kafka_2.13-3.6.0
再执行命令,完成集群元数据配置
bin/kafka-storage.sh format -t 82vqfbdSTO2QzS_M0Su1Bw -c config/kraft/server.properties
192.168.3.232 节点

192.168.2.90 节点

192.168.2.11节点

上面命令执行完成后,开放防火墙端口
kafka 需要开放 9092 端口和 9093 端口
3台机器上分别开放 9092 和 9093 端口
查看开放端口
firewall-cmd --zone=public --list-ports
开放9092 端口
firewall-cmd --zone=public --add-port=9092/tcp --permanent
开放9093 端口
firewall-cmd --zone=public --add-port=9093/tcp --permanent
更新防火墙规则(无需断开连接,动态添加规则)
firewall-cmd --reload
4、启动 Kafka KRaft 集群
在3台机器上分别启动
下面2个命令均可启动
bin/kafka-server-start.sh -daemon config/kraft/server.properties
或
bin/kafka-server-start.sh config/kraft/server.properties
笔者使用第二个启动命令 启动,效果看下图
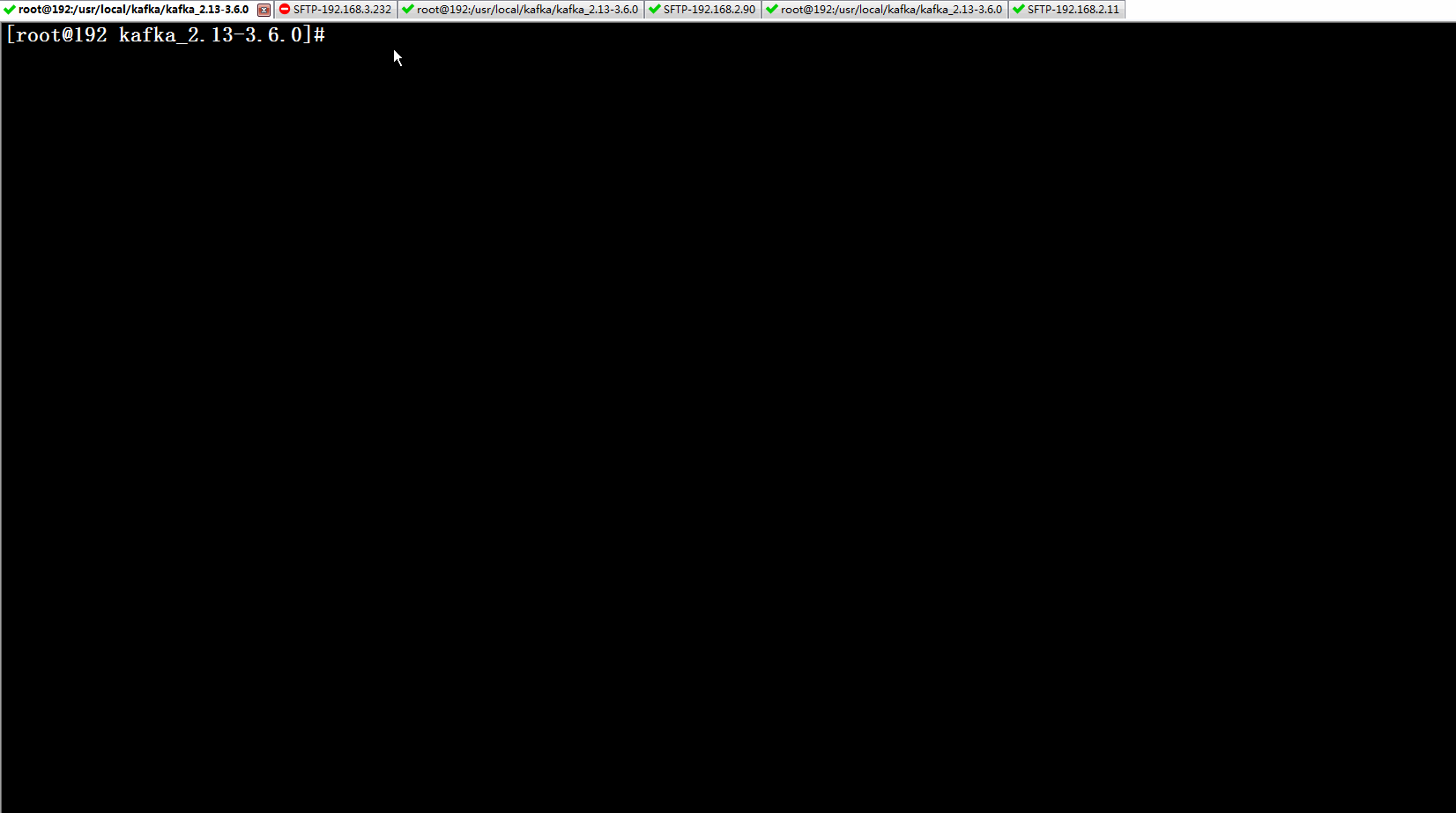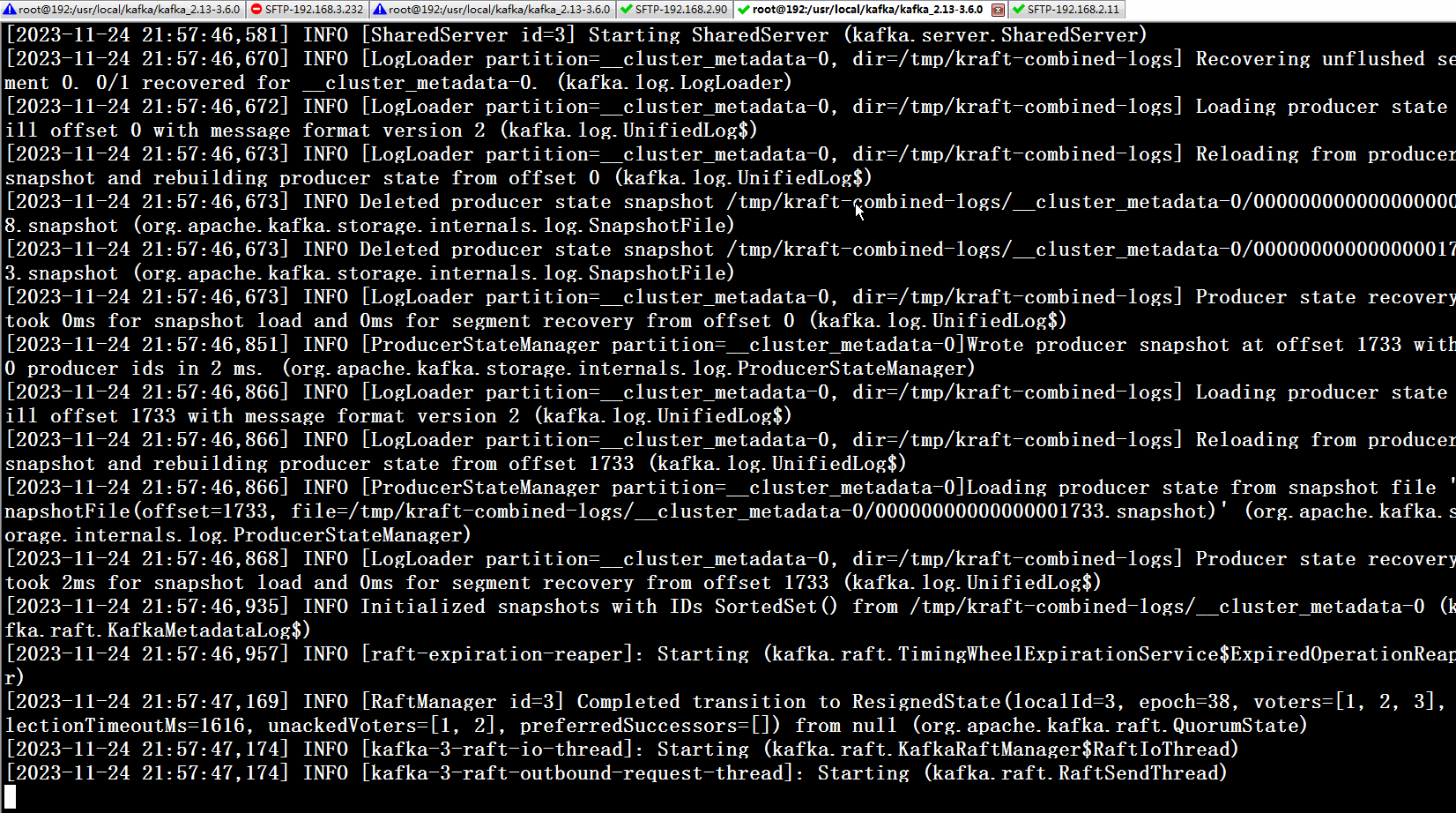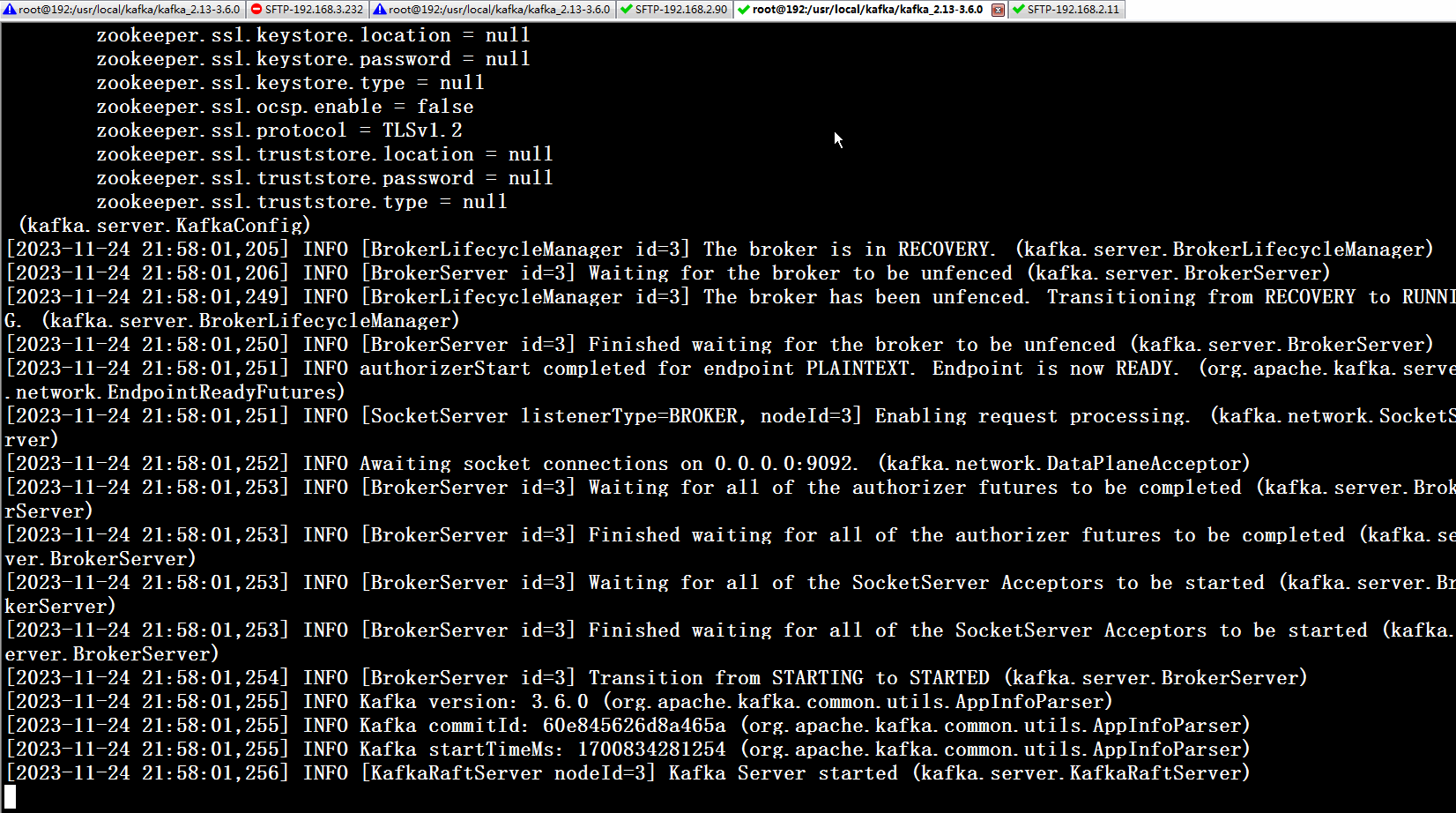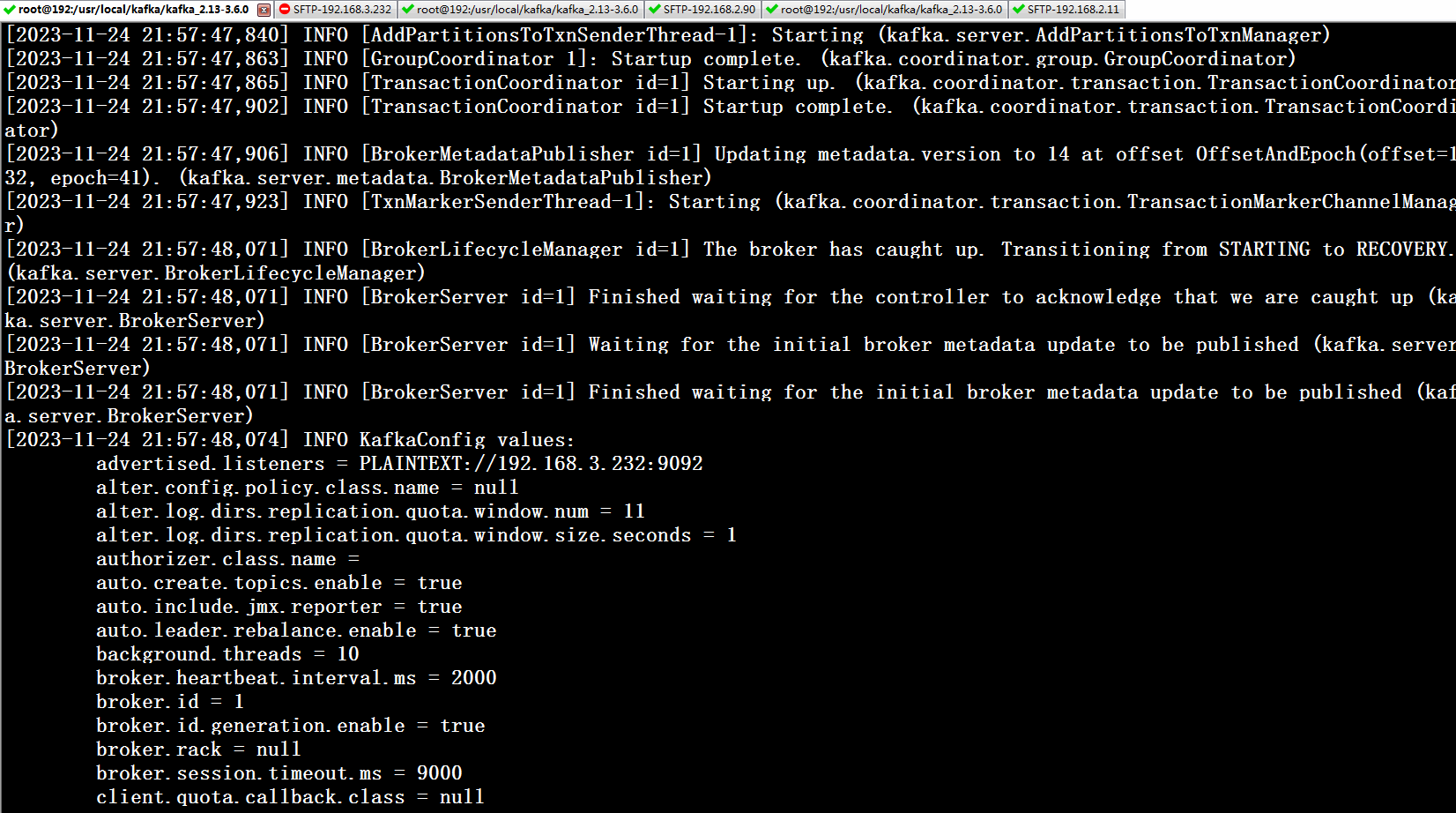
当 3 个节点都出现 Kafka Server started,集群启动成功
5、关闭 Kafka KRaft 集群
关闭命令
bin/kafka-server-stop.sh
在 3 个节点上分别执行关闭命令
6、测试 KRaft 集群
新建 maven 项目,添加 Kafka 依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>
笔者新建 maven项目 kafka-learn
kafka-learn 项目 pom 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wsjzzcbq</groupId>
<artifactId>kafka-learn</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
新建生产者 ProducerDemo
package com.wsjzzcbq;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* Demo
*
* @author wsjz
* @date 2023/11/24
*/
public class ProducerDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
//配置集群节点信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");
//配置序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(properties);
//topic 名称是demo_topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("demo_topic", "明月别枝惊鹊");
RecordMetadata recordMetadata = producer.send(producerRecord).get();
System.out.println(recordMetadata.topic());
System.out.println(recordMetadata.partition());
System.out.println(recordMetadata.offset());
}
}
新建消费者 ConsumerDemo
package com.wsjzzcbq;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* ConsumerDemo
*
* @author wsjz
* @date 2023/11/24
*/
public class ConsumerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
// 配置集群节点信息
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.3.232:9092,192.168.2.90:9092,192.168.2.11:9092");
// 消费分组名
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "demo_group");
// 序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 消费者订阅主题
consumer.subscribe(Arrays.asList("demo_topic"));
while (true) {
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String,String> record:records) {
System.out.printf("收到消息:partition=%d, offset=%d, key=%s, value=%s%n",record.partition(),
record.offset(),record.key(),record.value());
}
}
}
}
运行测试
效果图
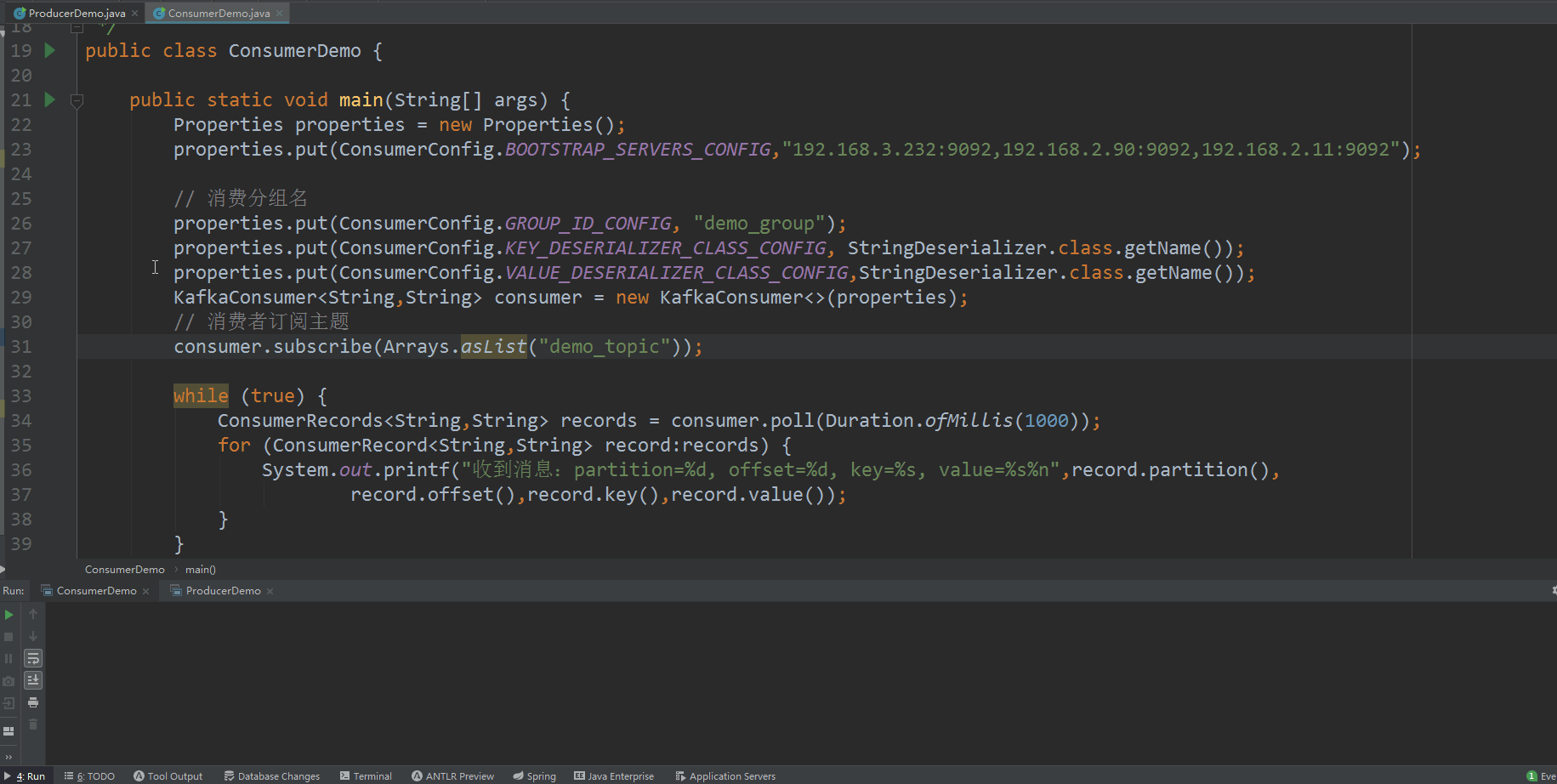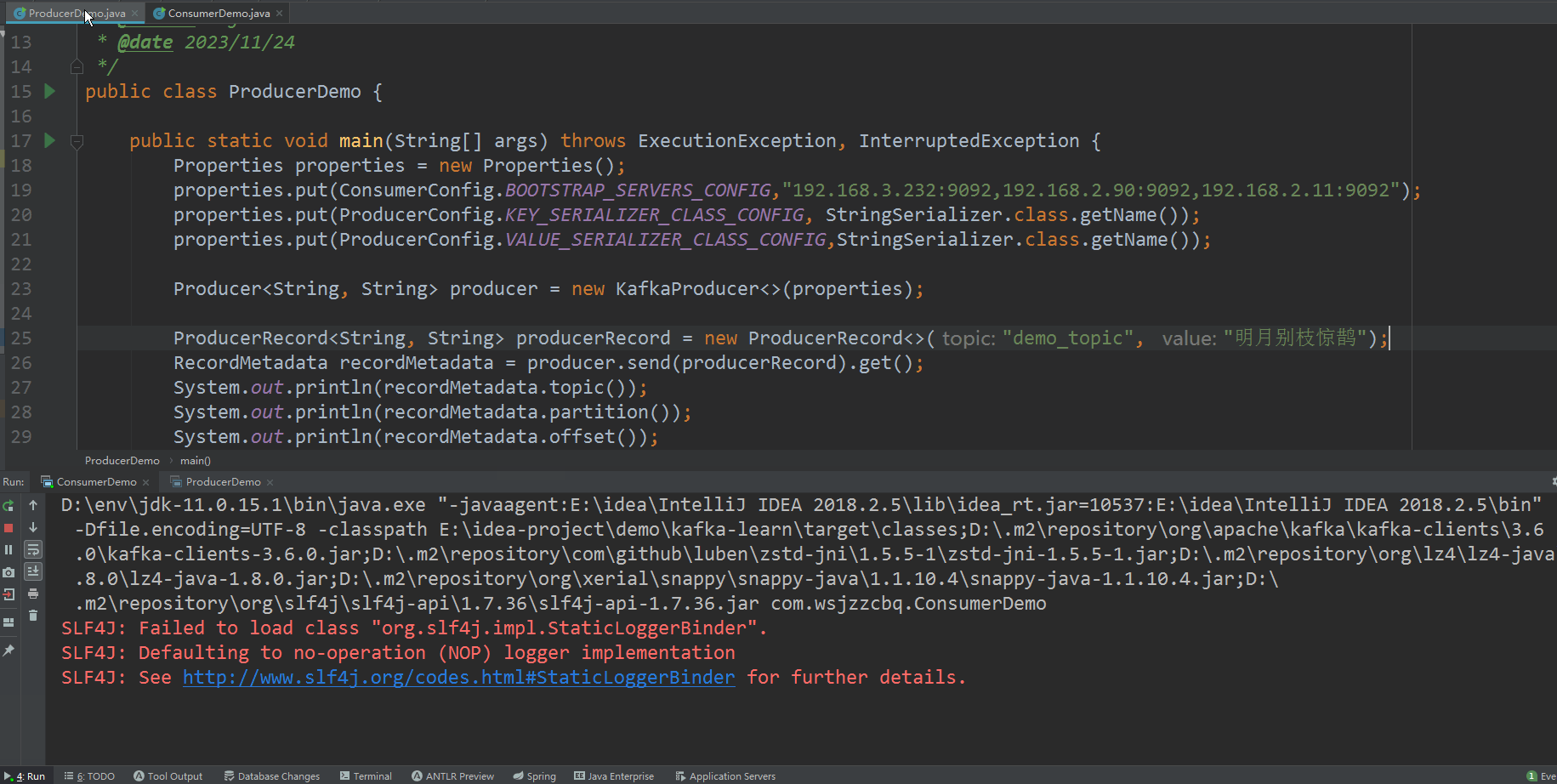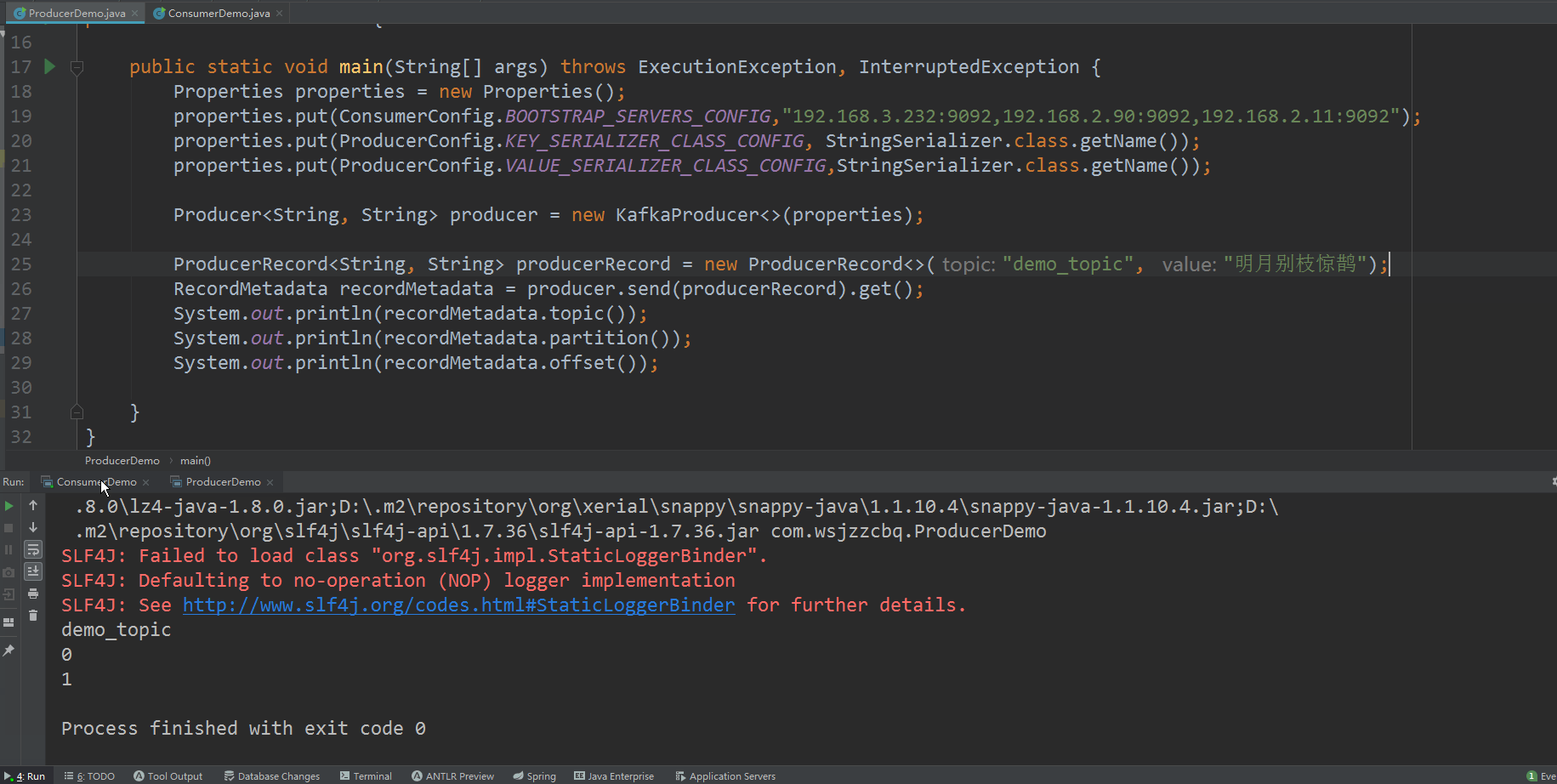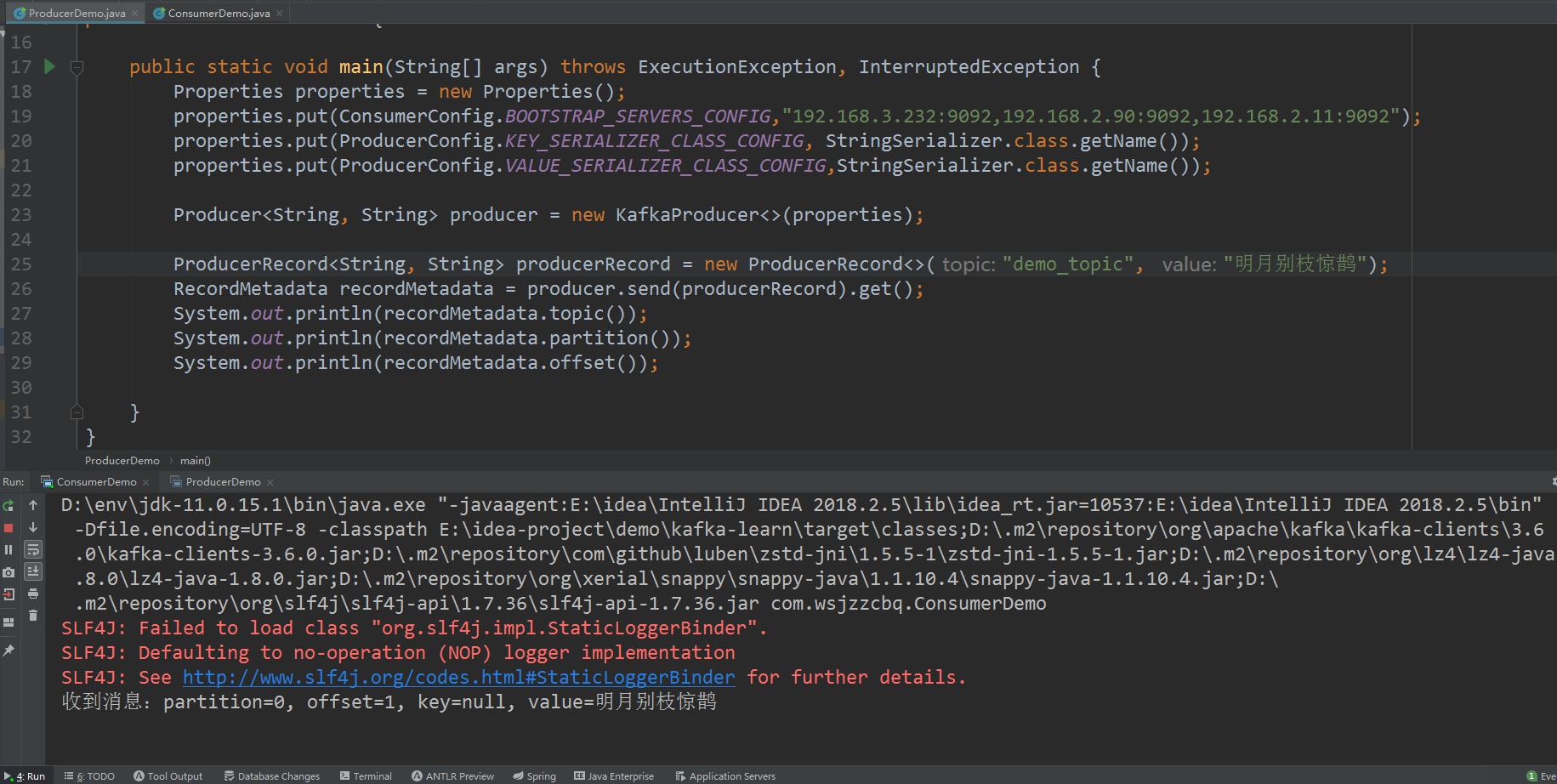
消息成功发送并成功消费
至此完
版权归原作者 悟世君子 所有, 如有侵权,请联系我们删除。