
一、内存配置
1、NameNode内存计算
假设,每个文件块大概占用
150byte
,一台服务器
128G内存
为例,能存储多少文件块呢?
128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1亿
G MB KB Byte
2、Hadoop3.x系列,配置NameNode内存
我的虚拟机内存是2G内存。
查看
NameNode
和
DataNode
占用内存
[atguigu@hadoop102 ~]$ jps 查看所有进程ID
2241 Jps
2163 JobHistoryServer
2004 NodeManager
1685 DataNode
1561 NameNode
[atguigu@hadoop102 ~]$ jmap -heap1561 查看NameNode的内存情况
MaxHeapSize =520093696(496.0MB)[atguigu@hadoop102 ~]$ jmap -heap1685
MaxHeapSize =520093696(496.0MB)
3、官方建议

4、修改配置调优内存
hadoop-env.sh
exportHDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"exportHDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
修改完毕后,分发文件到集群其他节点,重启Hadoop。
5、验证配置结果
发现,内存已经变成1G了。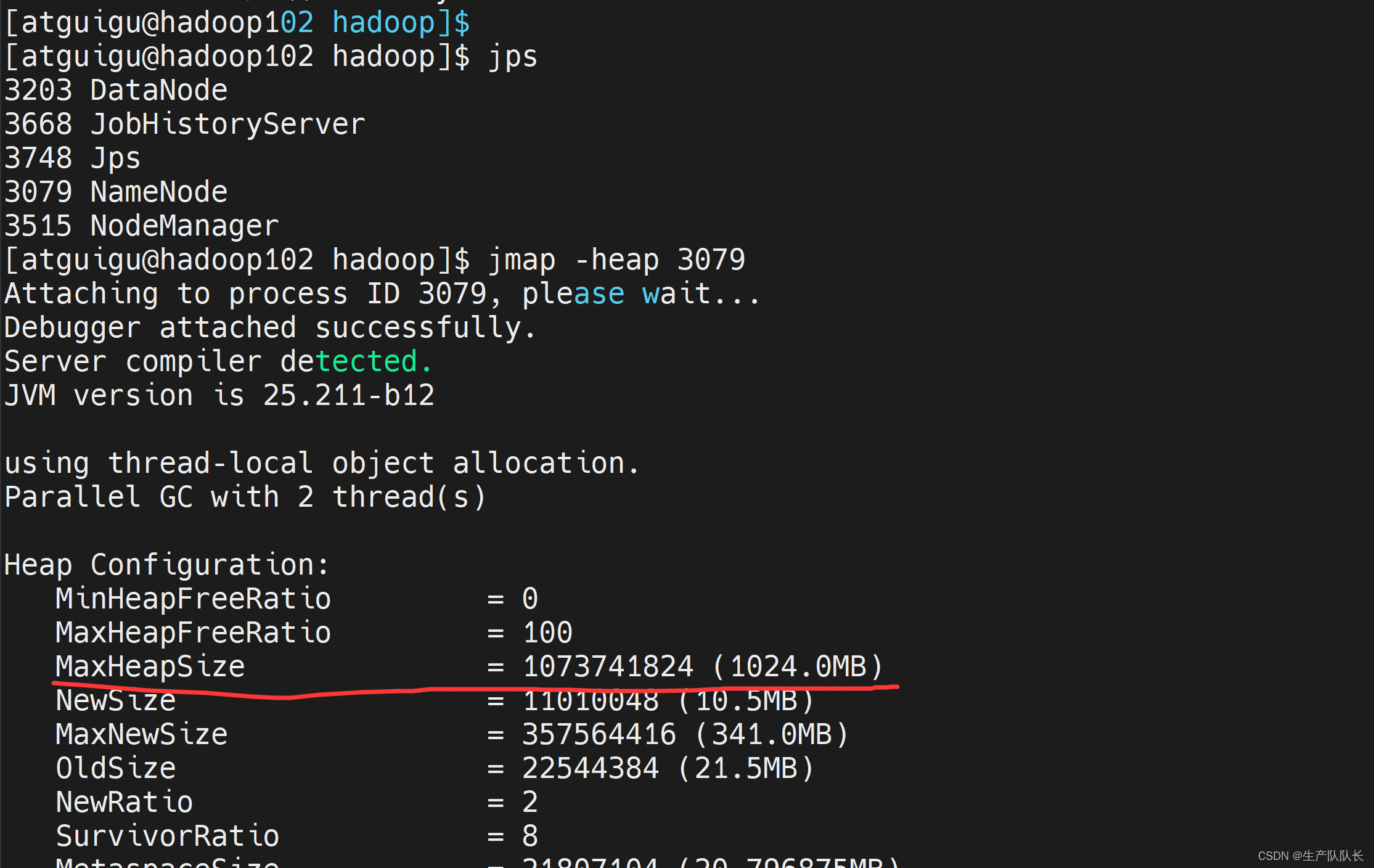
二、并发数配置
1、概述
NameNode
需要处理客户端的请求,同时也要接受
DatanNode
的心跳通知。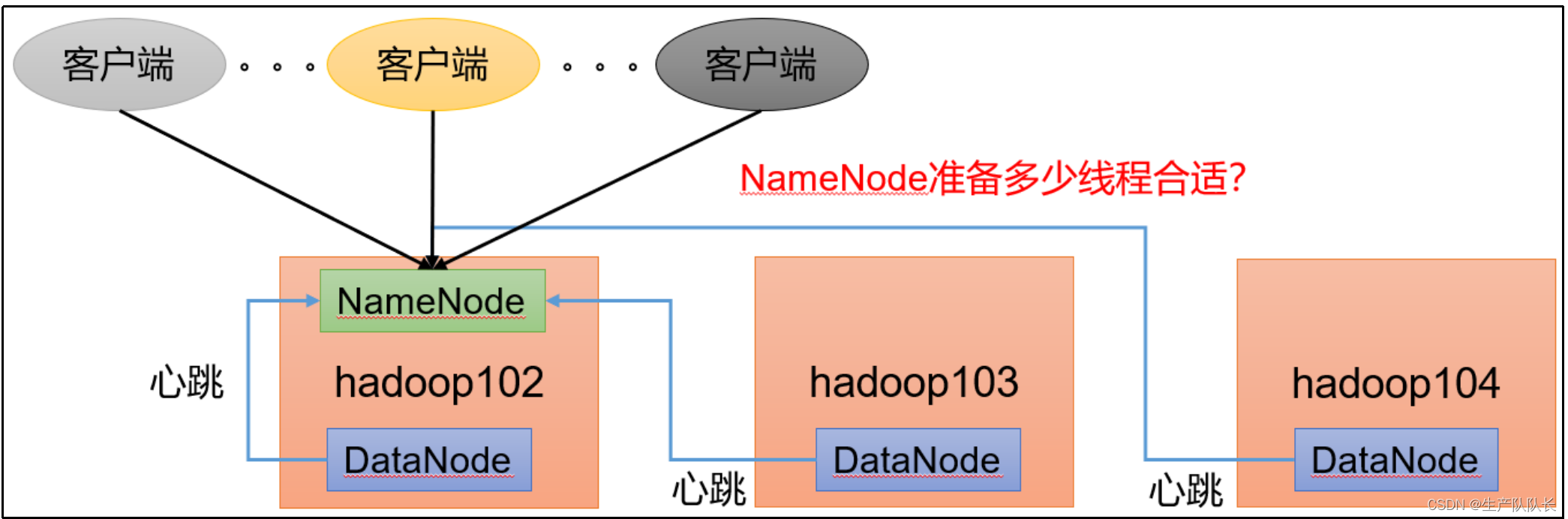
2、计算
那么,并发数配置多少合适?怎么计算?怎么配置?
这个并发数,主要影响根据集群节点数,进行计算。
公式:
d
f
s
.
n
a
m
e
n
o
d
e
.
h
a
n
d
l
e
r
.
c
o
u
n
t
=
20
∗
l
o
g
e
C
l
u
s
t
e
r
S
i
z
e
dfs.namenode.handler.count=20*log_e^{ClusterSize}
dfs.namenode.handler.count=20∗logeClusterSize
用
Python
计算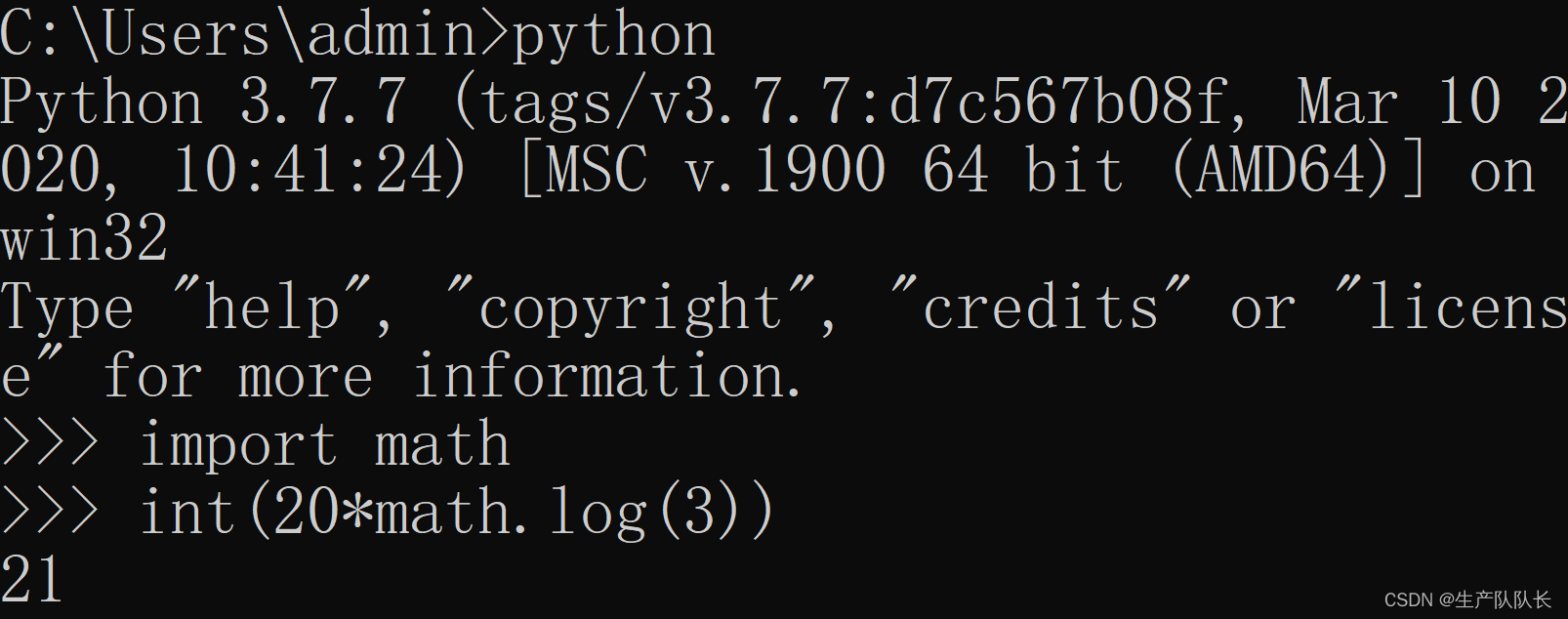
我的是3个节点,经过计算,并发数配置为21比较合适。
3、修改配置
hdfs-site.xml
<!--
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
--><property><name>dfs.namenode.handler.count</name><value>21</value></property>
分发配置,并重启
Hadoop
。
三、回收站配置
1、概述
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
2、原理说明
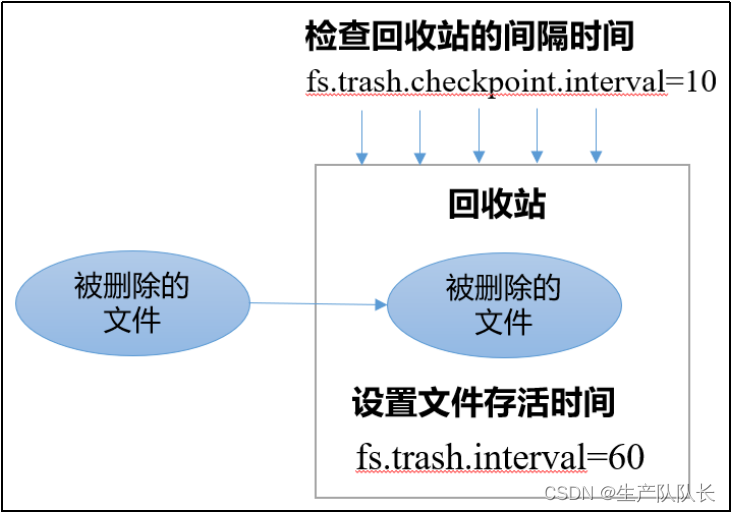
(1)默认值
fs.trash.interval = 0
,0表示禁用回收站;其他值表示设置文件的存活时间。
(2)默认值
fs.trash.checkpoint.interval
= 0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
(3)要求
fs.trash.checkpoint.interval <= fs.trash.interval
。
3、开启回收站配置
core-site.xml
<property><name>fs.trash.interval</name><value>1</value></property>
保存,分发并重启Hadoop。
4、测试
命令行删除文件
hadoop fs -rm /cls.txt

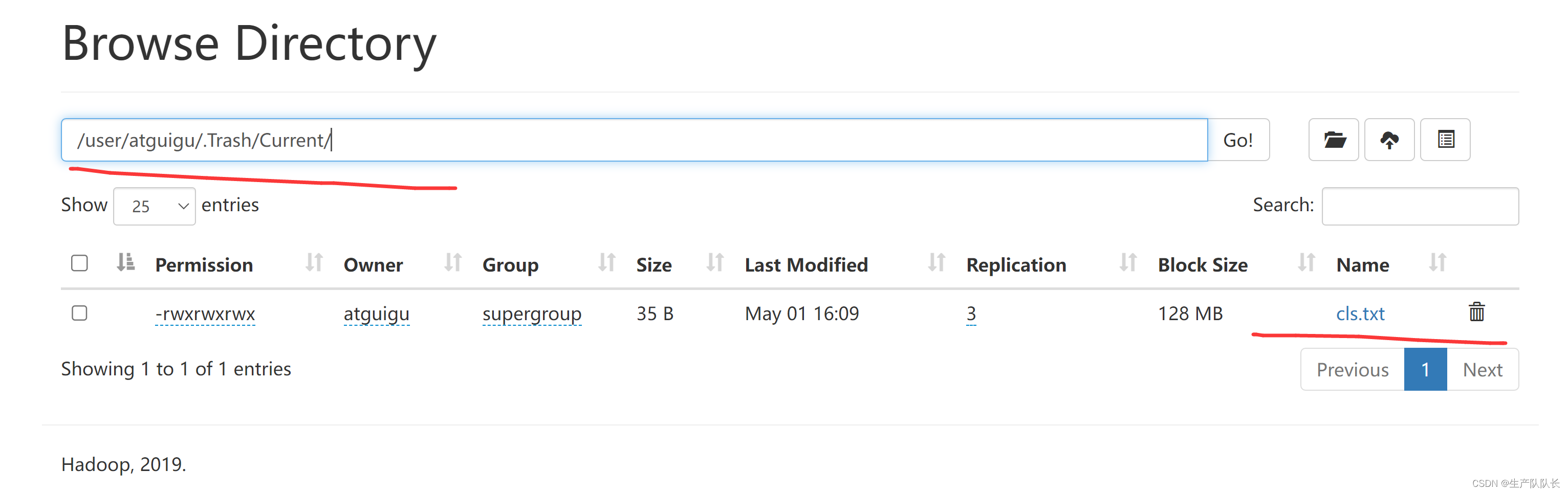
1分钟后,回收站清空,因为我们设置的保存时间就是1分钟。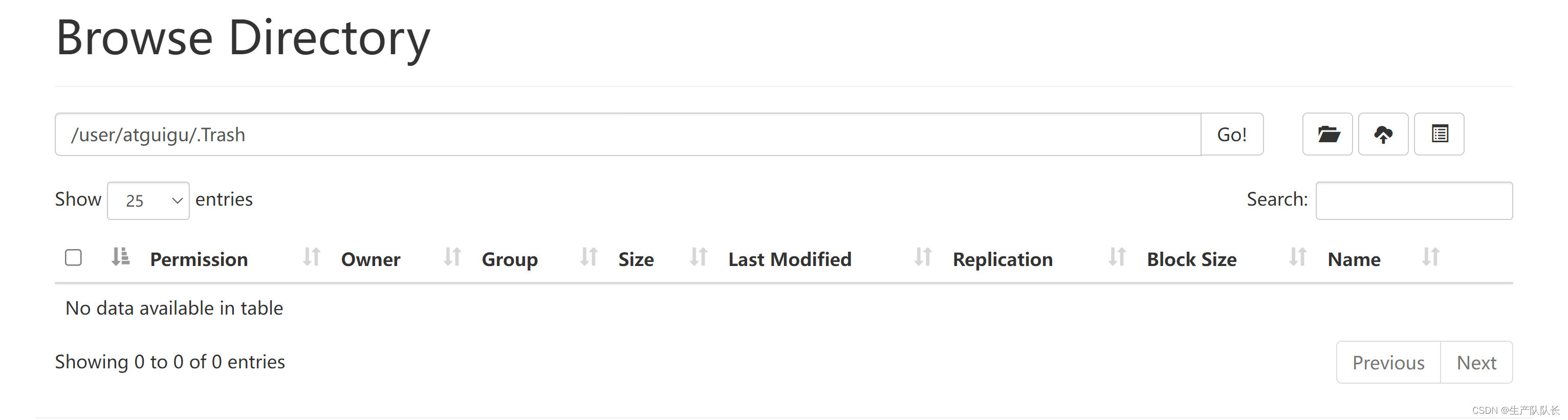
命令行恢复回收站数据
hadoop fs -mv /user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input
注意
1、通过网页上直接删除的文件也不会走回收站。
2、通过
Java
程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站。
Trash trash =NewTrash(conf);
trash.moveToTrash(path);
标签:
hadoop
本文转载自: https://blog.csdn.net/Brave_heart4pzj/article/details/140145356
版权归原作者 生产队队长 所有, 如有侵权,请联系我们删除。
版权归原作者 生产队队长 所有, 如有侵权,请联系我们删除。