
一、spark ui 中的入口
 左上角的 2.4.0 表当前执行任务的spark版本为 spark 2.4.0
左上角的 2.4.0 表当前执行任务的spark版本为 spark 2.4.0
序号
入口页
包含
1
Jobs
Jobs详情页
2
Stages
Stage详情页
3
Storege
Cache缓存详情页
4
Environment
配置项、环境变量详情(如设置的参数)
5
Executors
每个excutors执行情况、计算详情
6
SQL
任务的执行计划详情
二、各入口详情
2.1 Jobs
In Apache Spark execution terminology, operations that physically move data in order to produce some result are called “jobs”.
spark任务中,每遇到一个action算子会提交一个job。job之间一般是有依赖的,为串行执行的,从job0开始执行,执行完1个job才会执行下一个job。如图
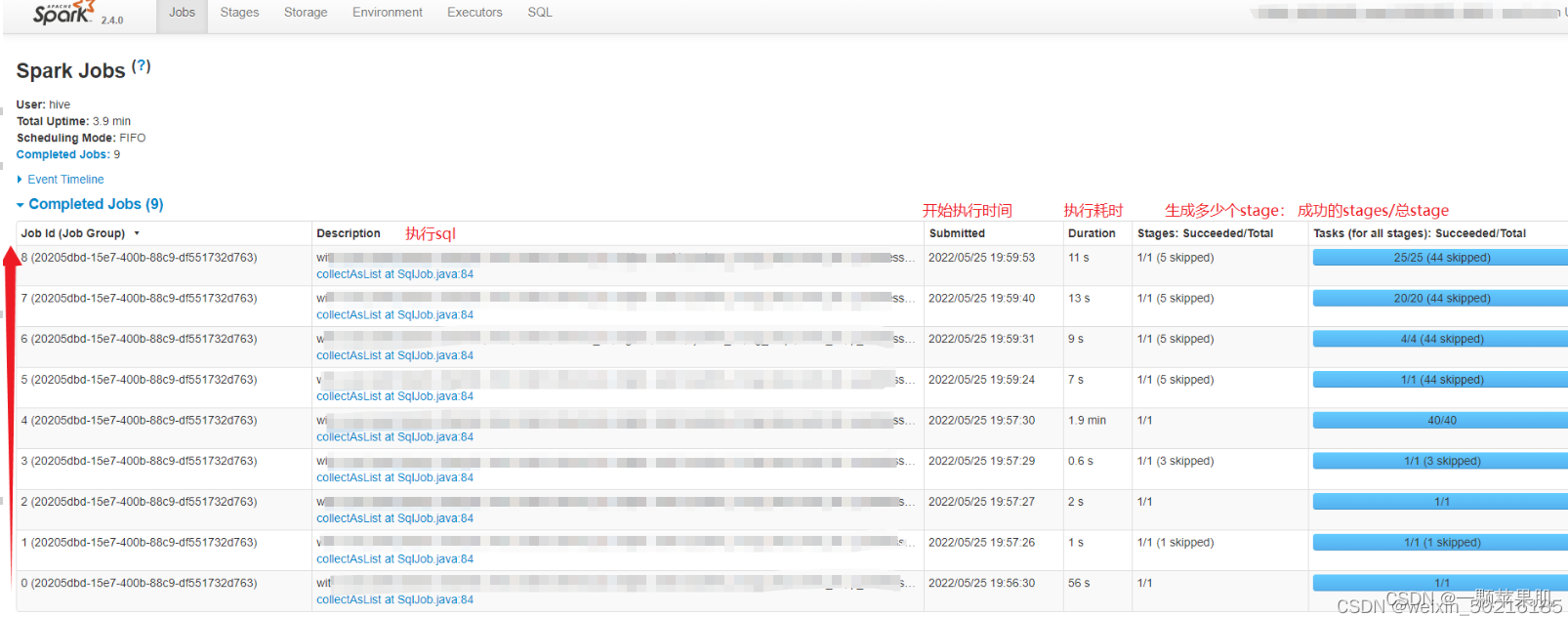
- Total Uptime:总的运行时间,从master开始运行到结束的整体时间。
- Scheduling Mode:application中task任务的调度策略,由参数spark.scheduler.mode来设置,可选的参数有FAIR和FIFO,默认是FIFO。
- Completed Jobs:已完成的Job。
- Active Jobs:正在运行的Job。
- Event Timeline:在application应用运行期间,Job和Exector的增加和删除事件进行图形化的展现。这个就是用来表示调度job何时启动何时结束,以及Excutor何时加入何时移除。
图中,每个job Description中的蓝色链接,点击后都可进入Job的详细信息页面
2.2 Stages
Jobs are decomposed into “stages” by separating where a shuffle is required.
job中stage的划分就是根据shuffle依赖进行的。shuffle依赖是两个stage的分界点。


Stages中的一些关键词:
broadcast exchange:表示这个stage是广播阶段
CompactFilesCommitProtocol:表示合并小文件
图中,点击每个stage Description中的蓝色链接后都可进入stage的详细信息页面
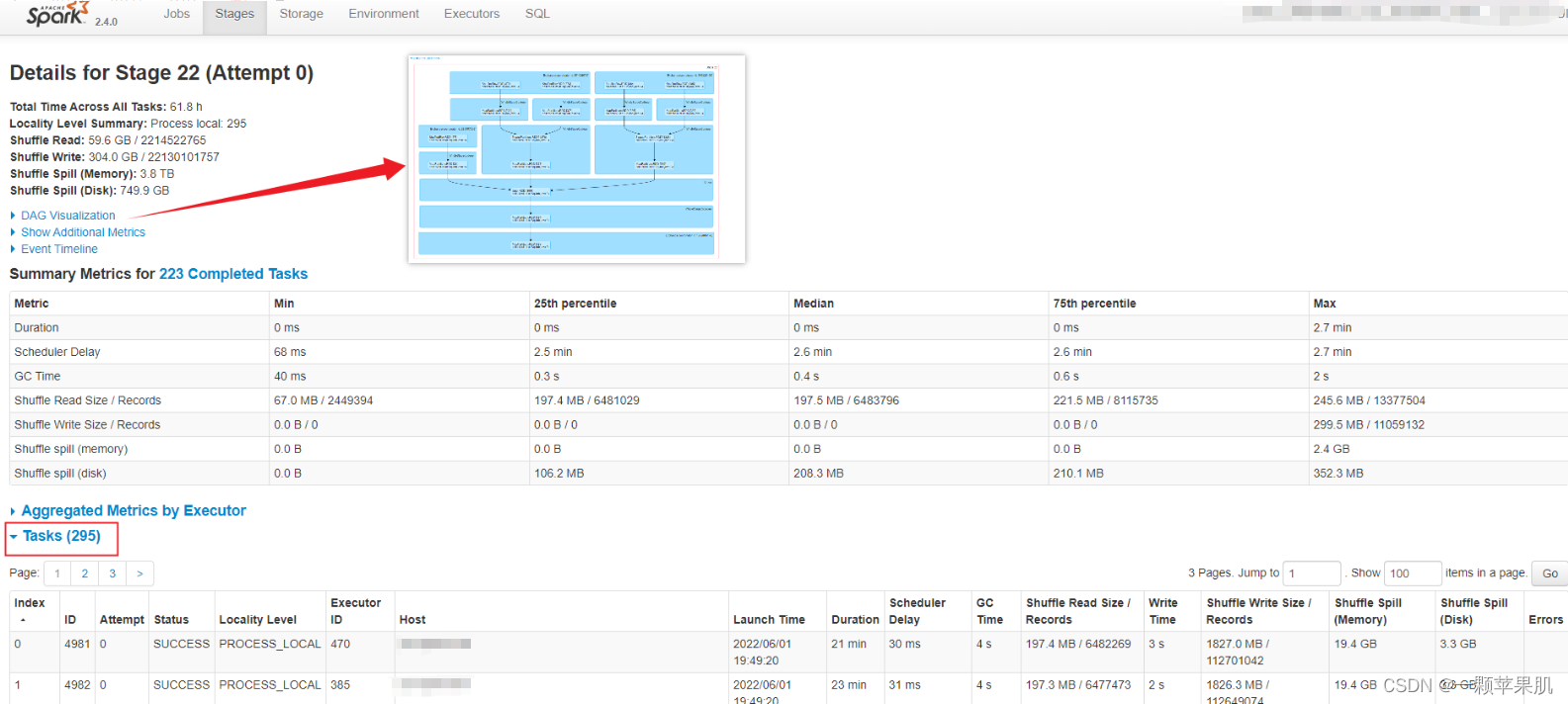
- Total time across all tasks:当前stage中所有task花费的时间和。
- Locality Level Summary:不同本地化级别下的任务数。
- Input Size/Records:输入的数据字节数大小/记录条数。
- Shuffle Write:为下一个依赖的stage提供输入数据,shuffle过程中通过网络传输的数据字节数/记录条数。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的一条基本原则。
- DAG Visualization:当前stage的操作流程图。但这个部分不会显示读的哪张表,关联字段是什么,我们可以通过完整的sql执行计划图查看详细信息。(详见2.6.2)
- Show Additional Metrics:当前stage中所有task的一些指标(每一指标项鼠标移动上去后会有对应解释信息)统计信息。
- Event Timeline:清楚地展示在每个Executor上各个task的各个阶段的时间统计信息,可以清楚地看到task任务时间是否有明显倾斜,以及倾斜的时间主要是属于哪个阶段,从而有针对性的进行优化。
- Aggregated Metrics by Executor:将task运行的指标信息按excutor做聚合后的统计信息,并可查看某个Excutor上任务运行的日志信息。
- Tasks:当前stage中所有任务运行的明细信息,是与Event Timeline中的信息对应的文字展示(可以点击某个task的stderr/stdout查看具体的任务executor日志)。
2.3 Storage
Storage页面能看出application当前使用的缓存情况,可以看到有哪些RDD被缓存了,以及占用的内存资源。如果job在执行时持久化(persist)/缓存(cache)了一个RDD,那么RDD的信息可以在这个选项卡中查看。
注:一般任务中有缓存,且是还在执行的过程中,这个页面才有对应的信息,任务执行时缓存结束了,这个页面的信息就会释放,就看不到什么内容了。

- Cached Partitions:已缓存的分区数
- Fraction Cached:缓存进度
- Size in Memory:缓存在内存中的大小
- Size on Disk:缓存在磁盘中的大小
2.4 Enviroment
该页面记录了环境变量与配置项信息,如我们经常给任务添加的参数是否生效,以及任务的参数设置可以在该页面查看,包括java版本,scala版本信息,引用的jar包等等

2.5 Executor
Executors Tab 的主要内容如下,主要包含“Summary”和“Executors”两部分。这两部分所记录的度量指标是一致的,其中“Executors”以更细的粒度记录着每一个 Executor 的详情,而第一部分“Summary”是下面所有 Executors 度量指标的简单加和。
Summary:是所有Executors度量指标的累加。
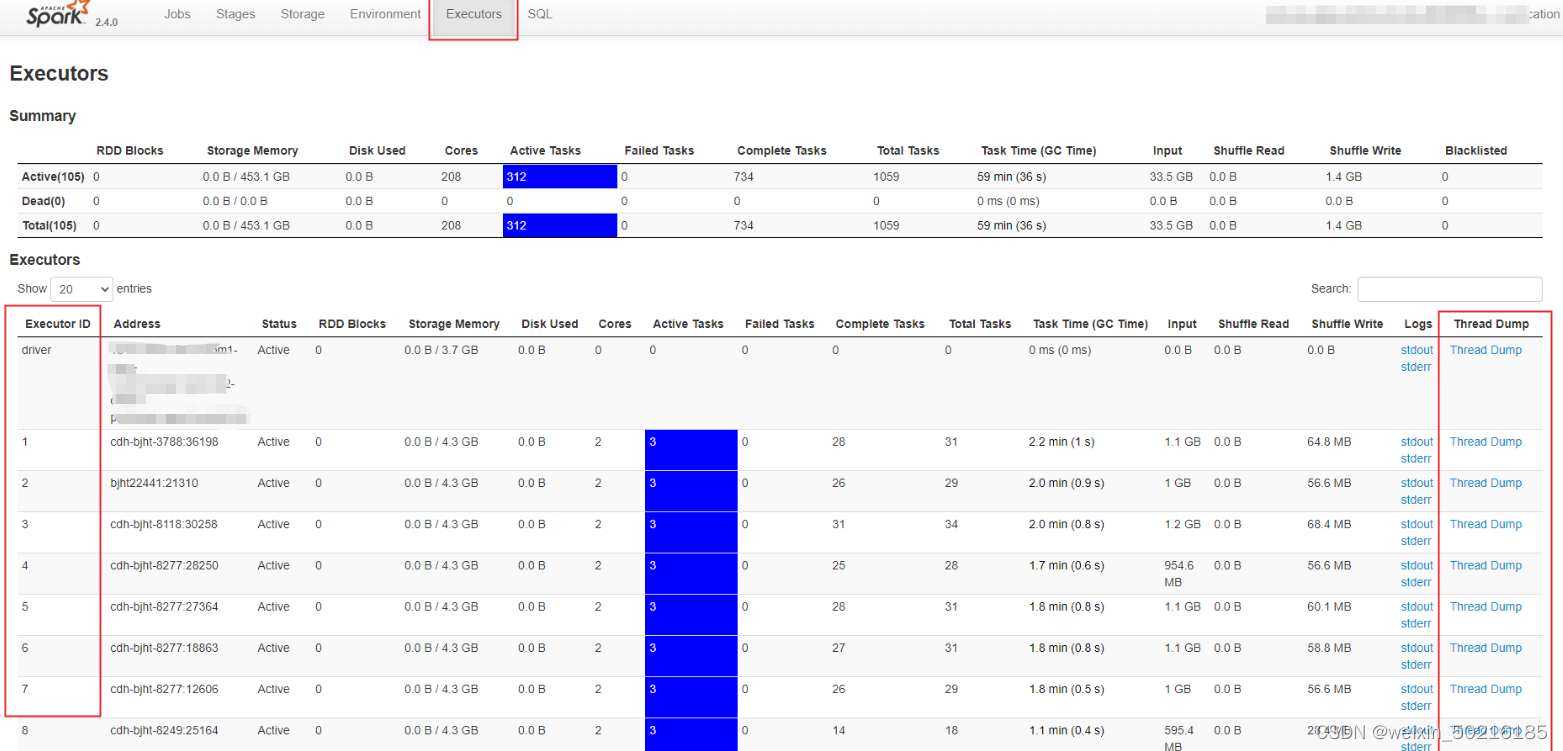
Executors:每一个Executor的详情。其中第一行为driver,对应的logs为driver日志;Execuotor ID对应每个stage中的executor id(如图2.5.2)

(图2.5.1)
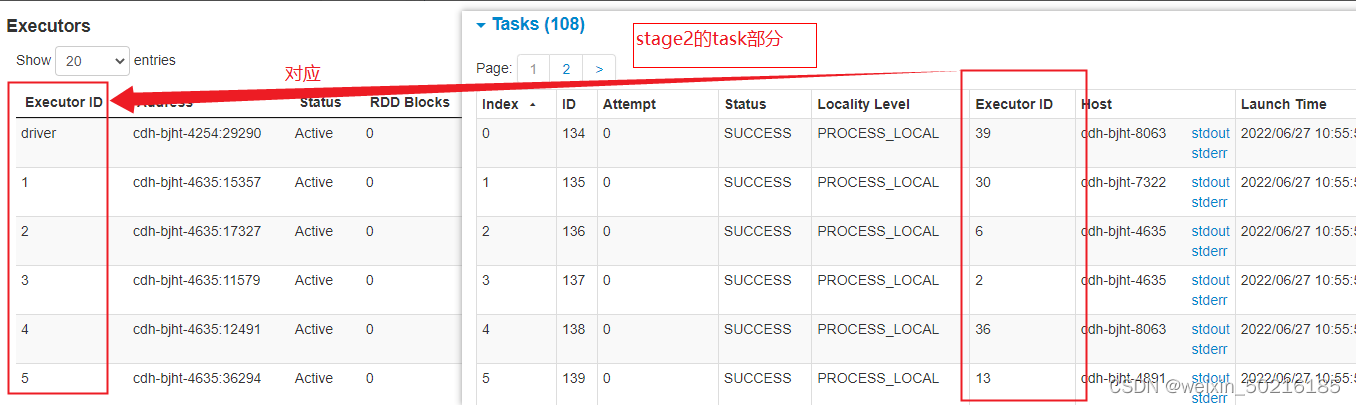
(图2.5.2)
executor日志无法查看的情况:复制这个executor的host,在driver stderr日志中,查看前1M的日志,搜索这个host,就能找到对应的container_id, 随便打开一个可以打开的executor日志,替换网址中的executor host和container_id,有多个container_id的则需要一个一个实验
executor日志怎么看?


以上截图例子中这个stage生成了9个task,则task(TID)的索引是从0开始计数的,即task是0-8,共9个task
每个task(TID)中下会打印读了哪些RDD,每个RDD后面会有这个rdd的,如range: 268435456-298702760(从range可判断文件是否分片)
关键字:FileScanRDD
2.6 SQL
2.6.1 SQL页面介绍
当我们的应用包含 DataFrame、Dataset 或是 SQL 的时候,Spark UI 的 SQL 页面,就会展示相应的内容,如下图所示。


Job IDs 中的数字表示哪些job串行完成了这段sql,点击那行的Description中的蓝色超链接可进入二级页面查看这一段sql的完整执行计划。
有些appid中可能执行几段sql,如上图,执行了两段SQL,故在SQL页面Job IDs中会有两段完整的job id记录。选择我们要查看的那段sql的链接。以下为点击超链接后的页面。

在这个页面最后还有 Details,展开Details 可以看到这段SQL的执行计划
注意:像创建函数,建表、删表是没有完整计划可以看的

2.6.2 执行计划-DAG Visualization
spark中对SQL的解析,是将SQL字符串切分成一个一个的Token,再根据一定语义规则解析成一颗语法树。如下图:

那么在执行计划中我们可以看到:
执行计划中的每个蓝色方块都有非常多的信息可以查看,如肉眼直接可以看到的Scan orc table_name ,number of output rows: 说明扫描了哪个表,这个表有多少行,我们把鼠标放在对应的信息上也会显示详细的信息,扫描的表的hdfs路径,分区,表存在的字段,等等,如下图
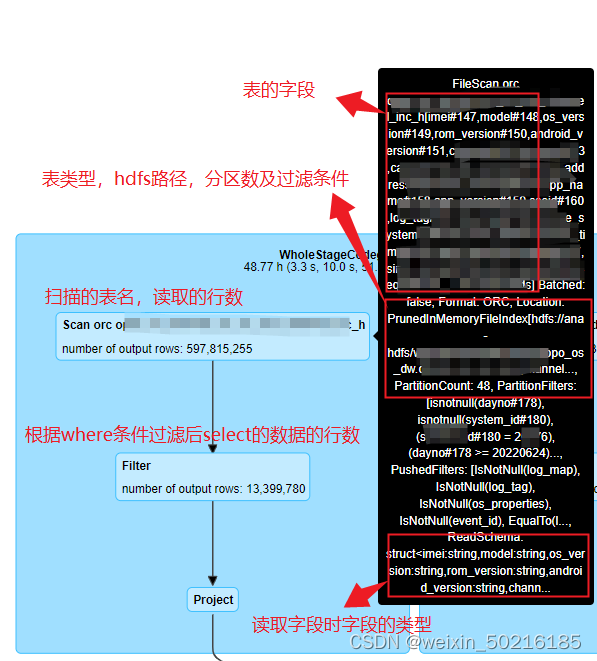


从上面的几个图片示例中,我们大概了解了一个sql的执行计划是怎么样的,我们能获取到什么信息,下面列举一些关键词:
- Scan :扫描表,并显示表名
- Filter:过滤条件,一般是扫描这张表那部分的where条件
- Project:为select的字段
- Sort:排序
- shuffle hash join、broadcast hash join、sort merge join:join的常见算法
- Window:一般是存在窗口函数
- Exchange:Exchange一般为group by ,join on 或者partition 的操作,这个过程会有shuffle。spark2.4.0中这里的id(coordinator id: xxxxxxxxxx)和stage中的dag计划图中的exchange阶段的id对应,spark3.1.2中是WholeStageCodegen(id)。举例:这个sql,stage23为shuffle阶段,dag图中没有的exchangeid=38650596,则在sql中,完整的执行计划中能搜索到对应的exchangeid=38650596的部分,就可以找到是什么表之间关联,关联字段是哪个。如下图
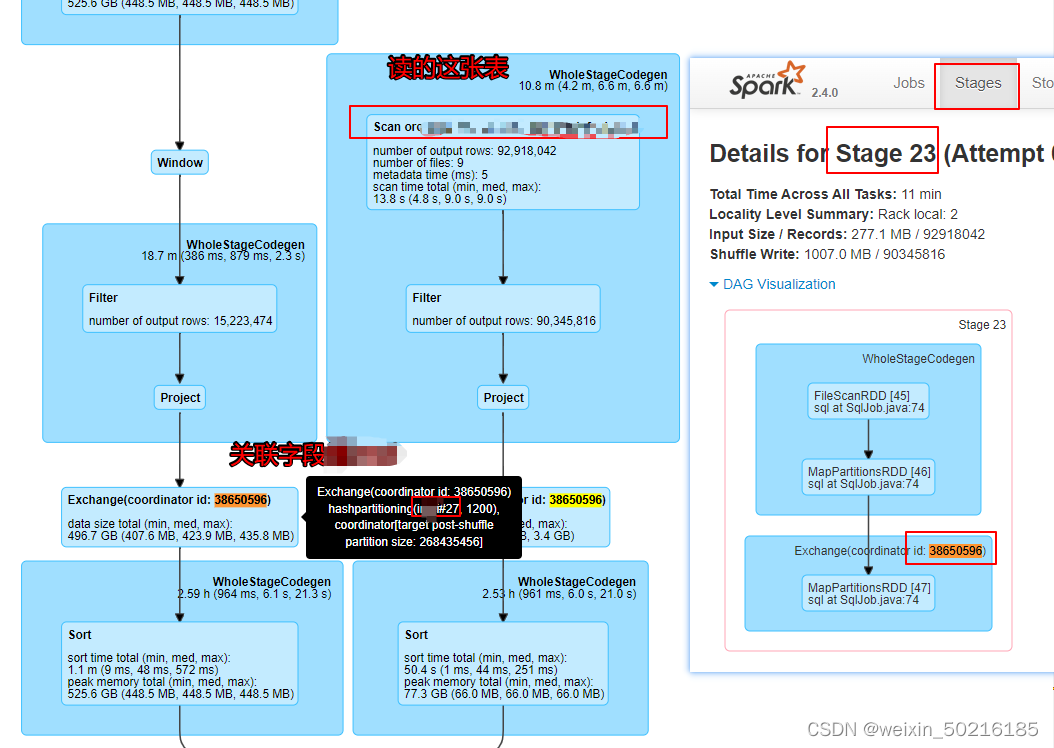
spark3.1.2的stage中则是根据WholeStageCodegen(id)这个信息去找

2.6.3 执行计划-Details
2.7 Streaming(待完善)

streaming页面中的参数
Porcessing Time:用来统计每个batch内处理数据所消费的时间
Scheduling Delay:用来统计在等待被处理所消费的时间
三、Executors中的Thread dump
正在运行的任务,想看任务现在在做什么,可以通过查看executor中的Thread dump;如果是任务卡在某一个stage,需要先在stage中找到这个stage目前运行的Executor ID,再在Executors页面中找到对应的executor 的Thread dump,这样就能去查看这个executor目前在做什么。(这个部分是需要查看executor的堆栈,根据栈信息(也可能需要查看源码)去做分析)

版权归原作者 一颗苹果肌 所有, 如有侵权,请联系我们删除。