
在输入jps命令后,可能会出现无法启动DataNode的情况,如图。
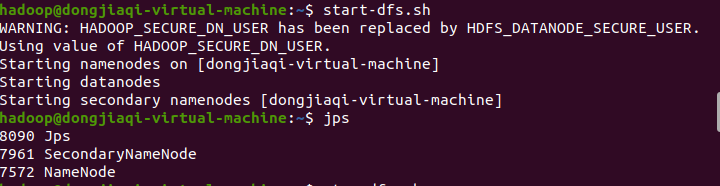
可能原因1:
可能因为多次格式化NameNode会重新生成新的ClusterId(集群ID),而原来的DataNode内data文件下的VERSION文件内的ClusterId还是原来的ClusterId,所以就会出现与NameNode的ClusterId不匹配。
解决方法:
找到存放VERSION的路径
我的是:
data/hadoop/hdfs/name/current/
和
data/hadoop/hdfs/data/current/
查看namenode和datanode的ClusterId

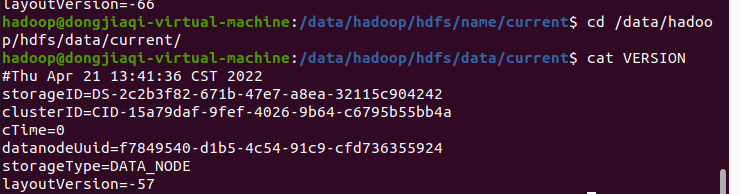
发现从机(datanode)和主机(namenode)的集群不同
所以要将从机的集群id改为主机的集群id
然后启动hadoop
start-dfs.sh
jps

可能原因2:
可能是因为权限设置错误。导致无法调用。
sudo chown 你自己的user名 -R data
修改data的权限即可。
可能原因3:
DataNode内data文件下没有VERSION文件,具体原因未知
单独开启datanode。
hadoop-daemon.sh start datanode
本文转载自: https://blog.csdn.net/Drajor/article/details/124320283
版权归原作者 Drajor 所有, 如有侵权,请联系我们删除。
版权归原作者 Drajor 所有, 如有侵权,请联系我们删除。