
MySQL表的增删改查 - 进阶2
大家好,已经好久没更新了 , 学校的学业有点忙 , 没有额外的精力去进行更新了 , 假期开始了 , 我们也要开始努力了
数据库相对来说难度不是那么高,大家只要勤加练习、熟记语法,我相信学好数据库不是什么问题,博主会从0剖析,逐步讲解数据库的知识点,并且会举很多实例。最重要的是,博主不会采用软件,使用最原始的方式 -> 命令行来讲解,这样讲解的好处是逐个语句进行书写,不会造成读者思路跟不上的问题!

3、新增(plus)
这里面的新增是和查询结合在一起的新增操作,就是把从上一个中得到的查询结果,作为下一个表要插入的数据
3.1 语法
insertinto 表名1select 列名 from 表名2;-- 从表2中查询出来的结果的列数和类型要与表1匹配,但是不要求列名匹配
在这个语句中,就会先执行查找。针对查找到的每个结果,都执行插入操作,插入到
B
中,我们需要保证:从
A
中查询到的结果列数和类型和
B
表匹配,才能正常插入
3.2 实例
我们先来做一些准备工作:
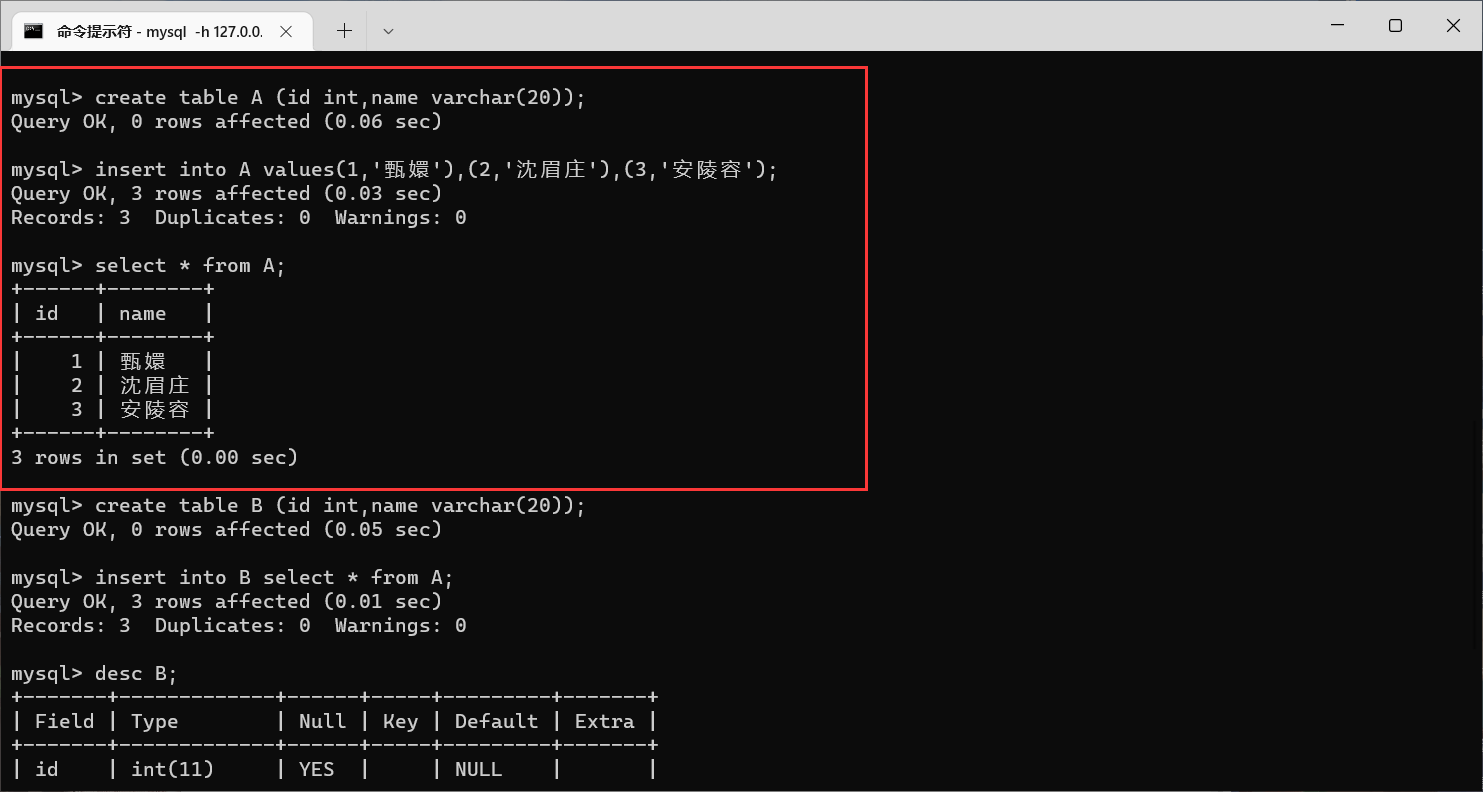
接下来,我们创建一个表
B
,第一列也是
id
,第二列也是
name
(注意"也"字)
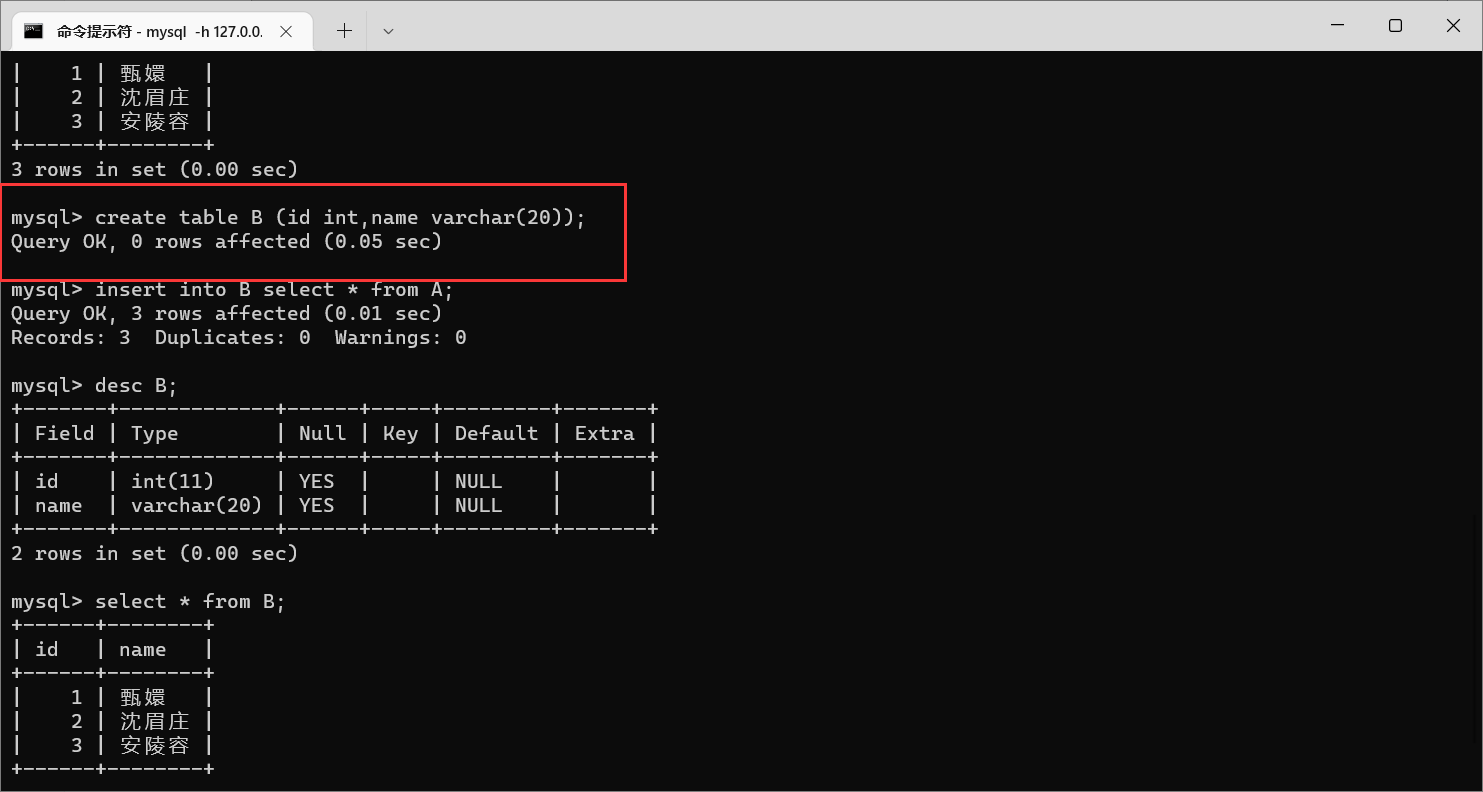
然后,我们就可以把表
A
查询到的数据插入到表
B
了

看一下
B
里面的数据
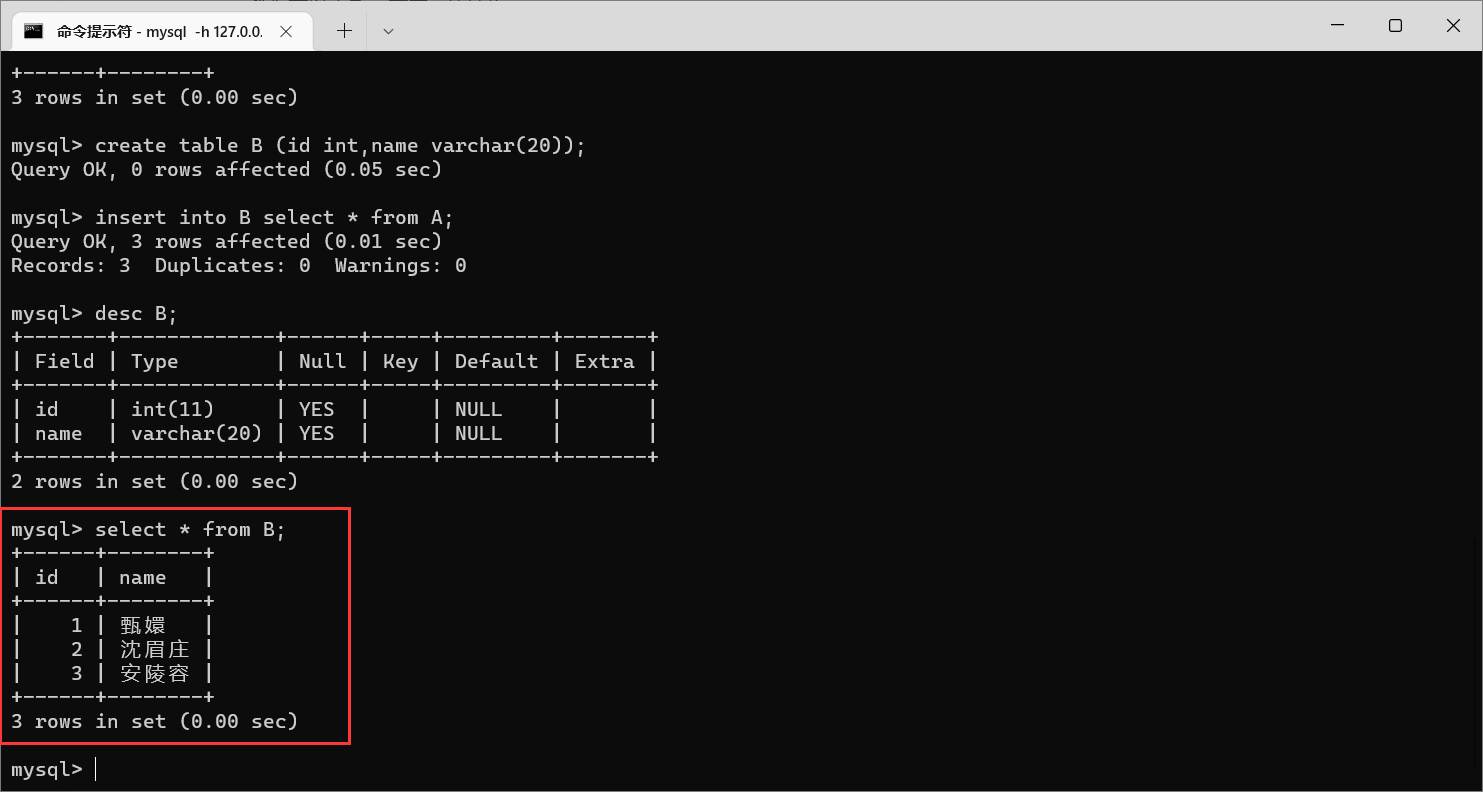
跟查询到的
A
的数据一样。
3.3 注意事项
那么接下来,我们把姓名和 id 列顺序调换一下(用调换的结果创建一个新表
C
),此时能否把
A
的数据插入到
B
呢?
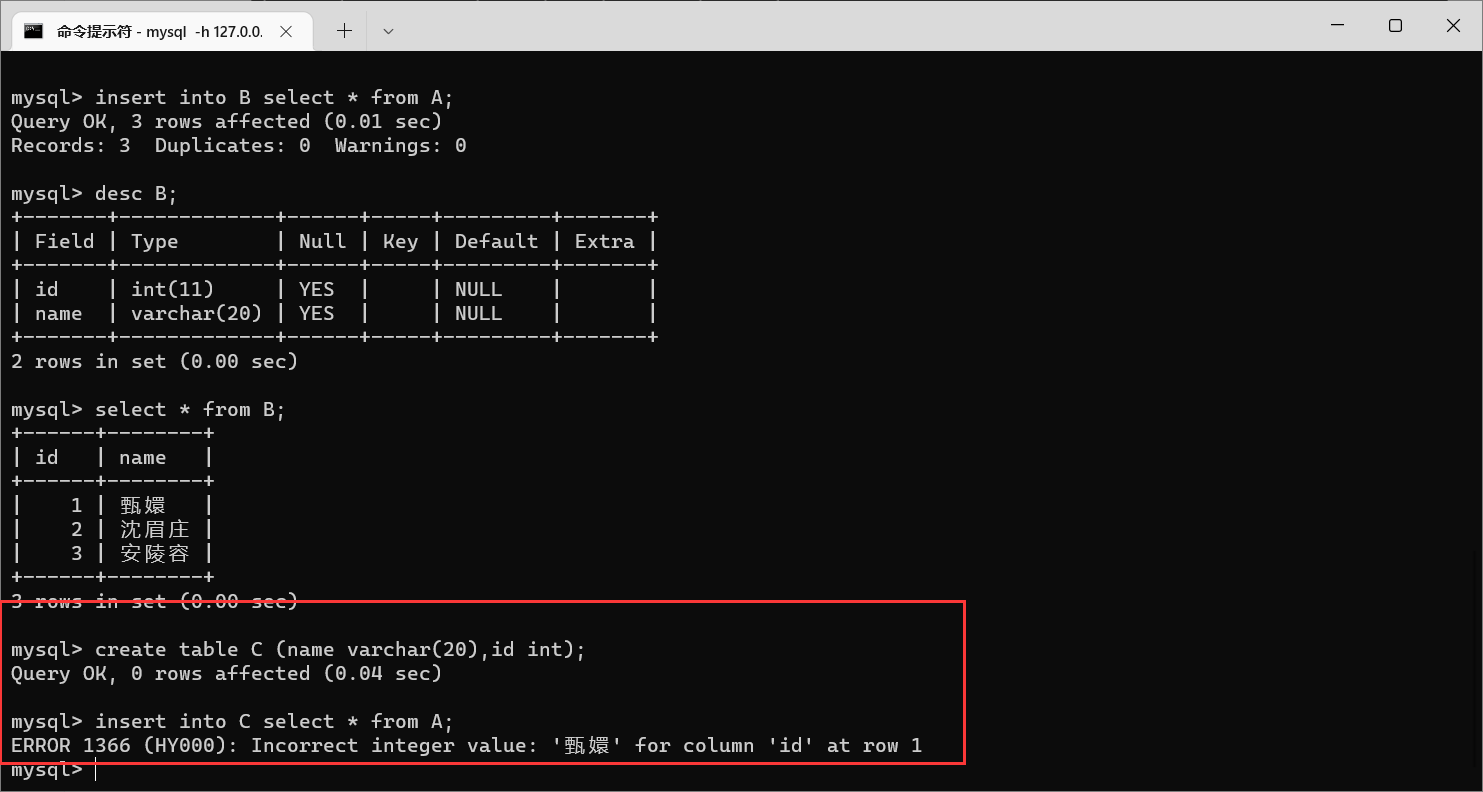
是插入不进去的
我们需要保证:从
A中查询到的结果列数和类型和
B表匹配,才能正常插入。
图片里面就不是匹配的,表
A第一列是学号(
int类型),第二列是名字(
varchar类型)。
而表
C第一列是名字(
varchar类型),第二列是学号(
int类型),二者对应列之间不匹配
那么我们可以这样操作:只需要保证
A
的查询结果的列的顺序和
B
对应即可,我们再创建一个表
D
来演示
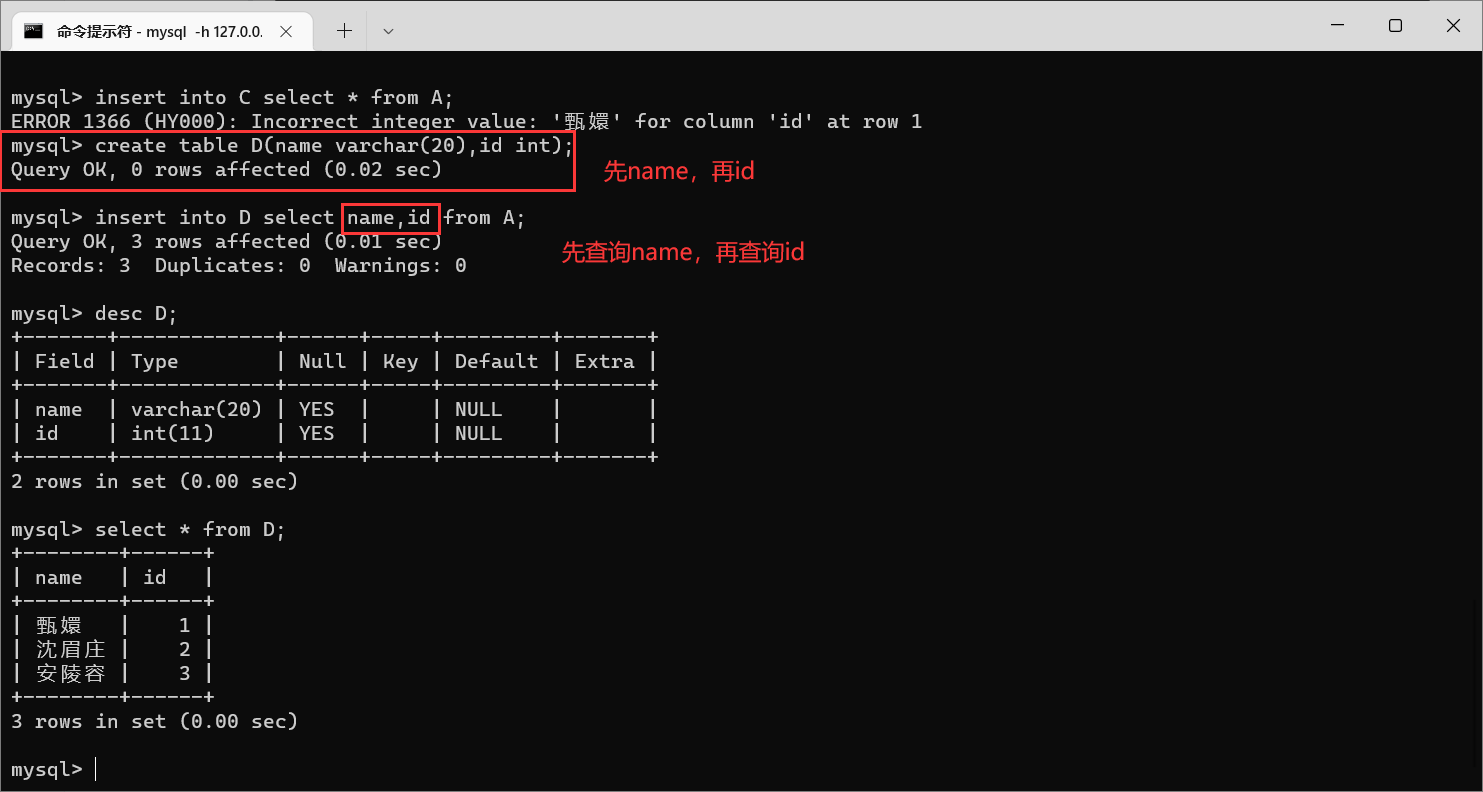
已经创建成功!
4、查询(plus)
4.1 聚合查询
聚合查询就是把多个行的数据给进行了关联操作,“行和行之间的数据加工”
之前我们讲过的查询带表达式的操作,是属于"列和列之间的关联运算"
4.1.1 聚合函数
MySQL
内置了一些聚合函数,我们可以直接使用
函数说明count([distinct] expr)返回查询到的数据的数量sum([distinct] expr)返回查询到的数据的总和(不是数字的话就没有意义)avg([distinct] expr)返回查询到的数据的平均值(不是数字的话就没有意义)max([distinct] expr)返回查询到的数据的最大值(不是数字的话就没有意义)min([distinct] expr)返回查询到的数据的最小值(不是数字的话就没有意义)
其中,
distinct
表示去重,
expr
代表条件,括号中写的是列名或者表达式
举栗子啦!
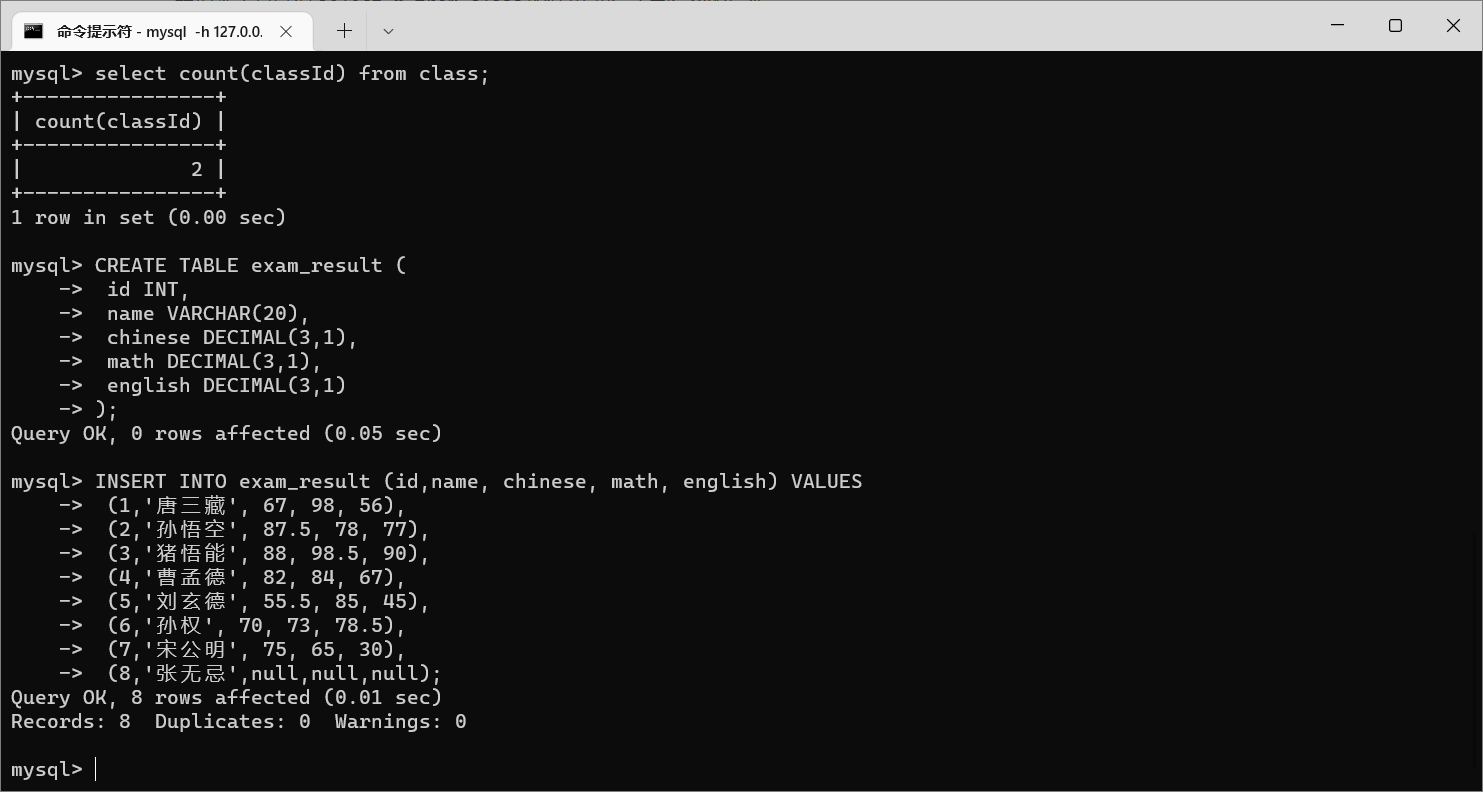
我们先创建这样的数据:
CREATETABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1));
INSERTINTO exam_result (id,name, chinese, math, english)VALUES(1,'唐三藏',67,98,56),(2,'孙悟空',87.5,78,77),(3,'猪悟能',88,98.5,90),(4,'曹孟德',82,84,67),(5,'刘玄德',55.5,85,45),(6,'孙权',70,73,78.5),(7,'宋公明',75,65,30),(8,'张无忌',null,null,null);
栗子1:
count
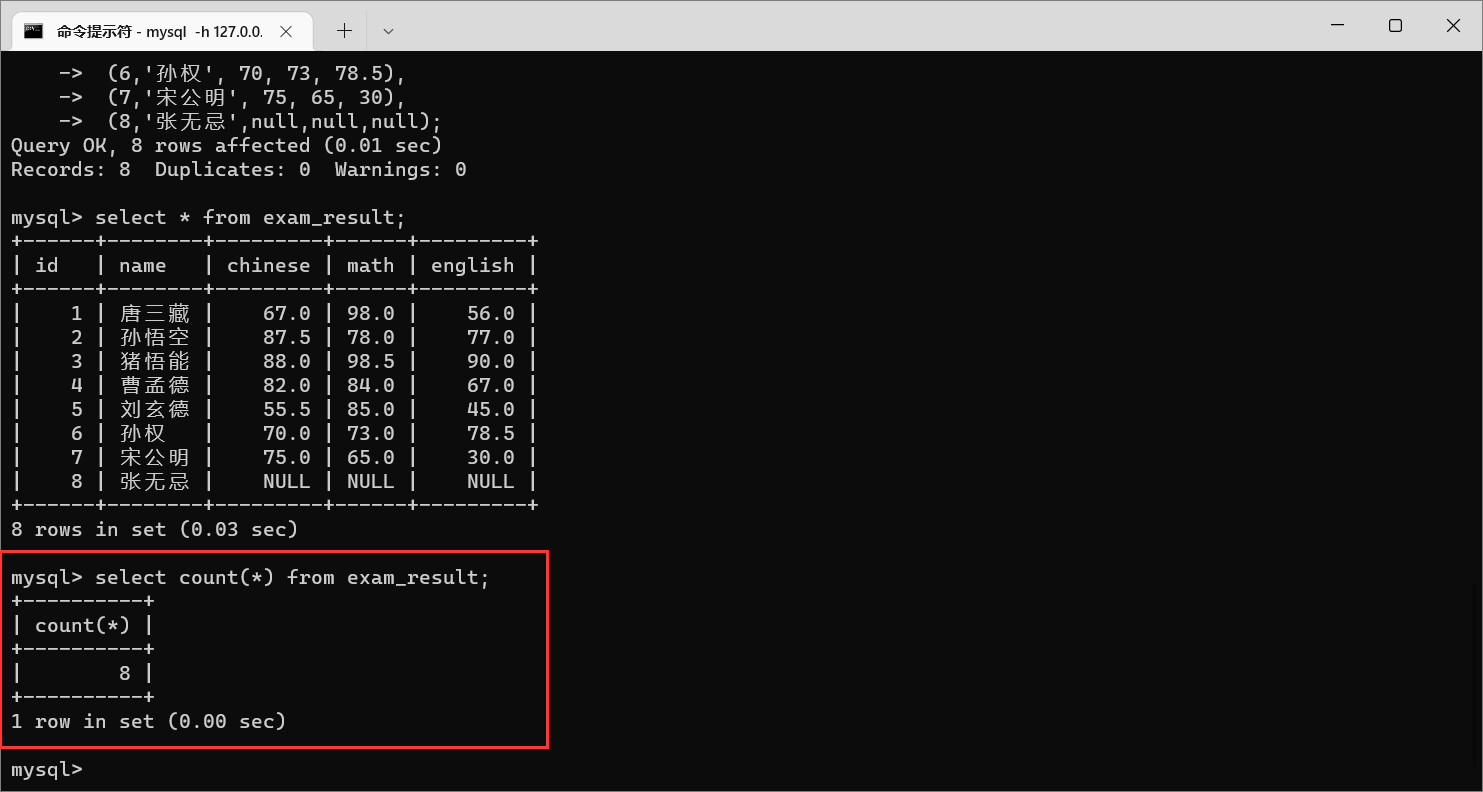
这个例子就相当于针对
select * from exam_result;
的结果集合进行计算行数
这种情况下 , null值是算进去的
count
这里面的参数可以是指定某个列,不一定是
(*)
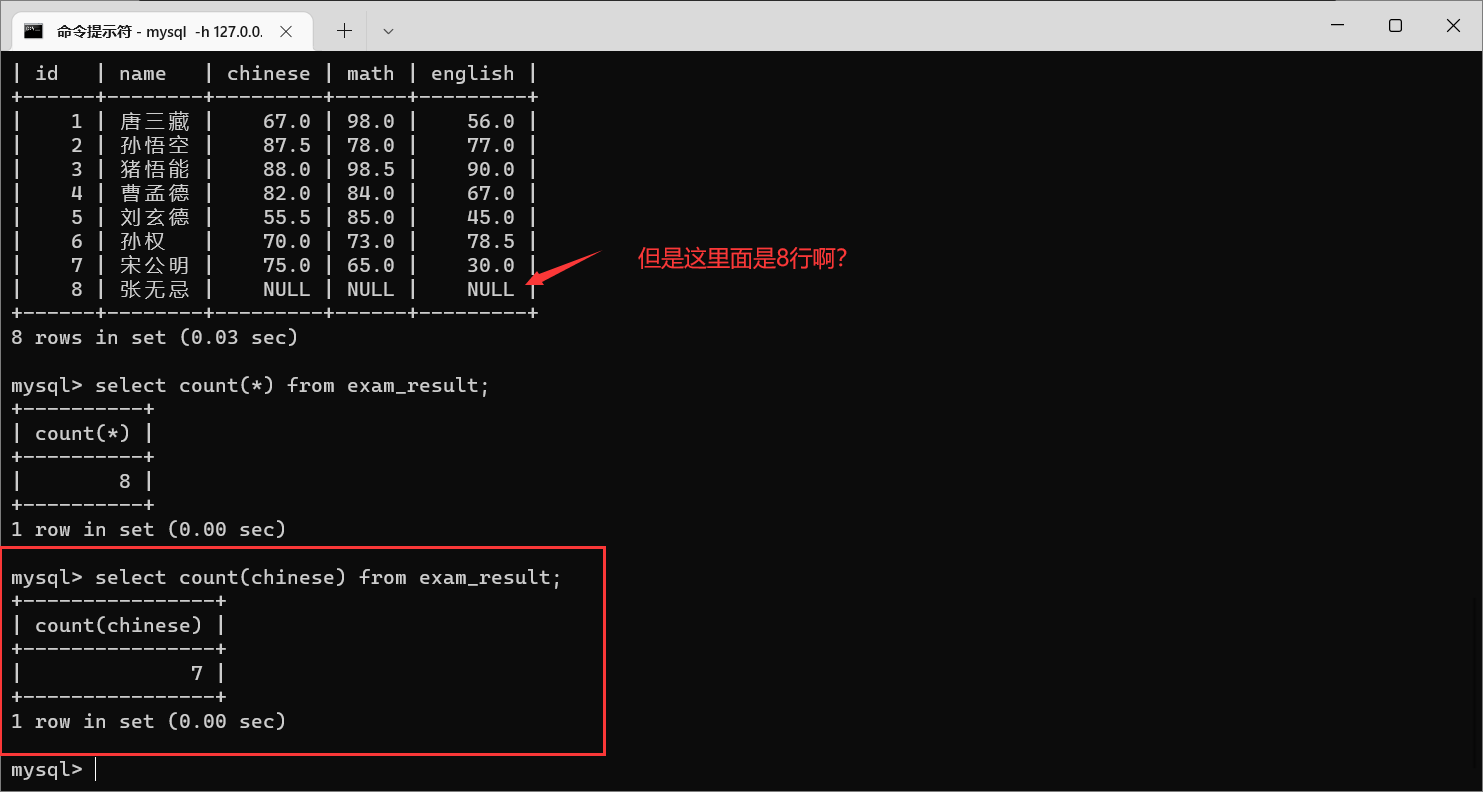
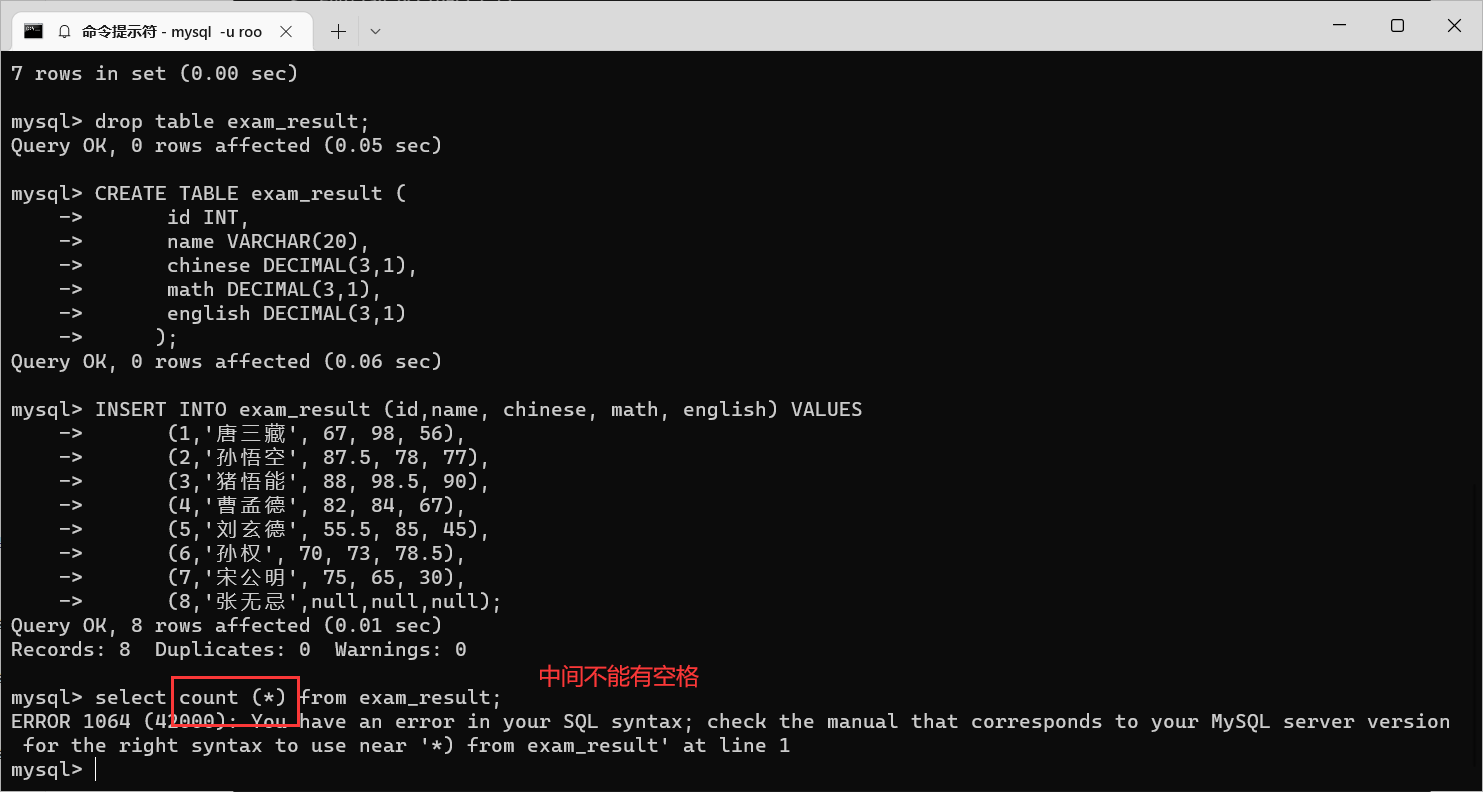
我们看到,其实是有8行数据的,但是为什么只统计出来了7行?
null不会被记录到
count中
还要注意的是 , count 和后面的括号是紧密相连的 , 不能分开 , 不然就会报错
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uUovNNaV-1670856662345)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E7%AC%91%E8%84%B8.png)]](https://img-blog.csdnimg.cn/64dcf874c5434e368122dda2e2efb0a4.png)
栗子2:
sum
相当于
excel
里面的求和,把这一列的若干行进行相加
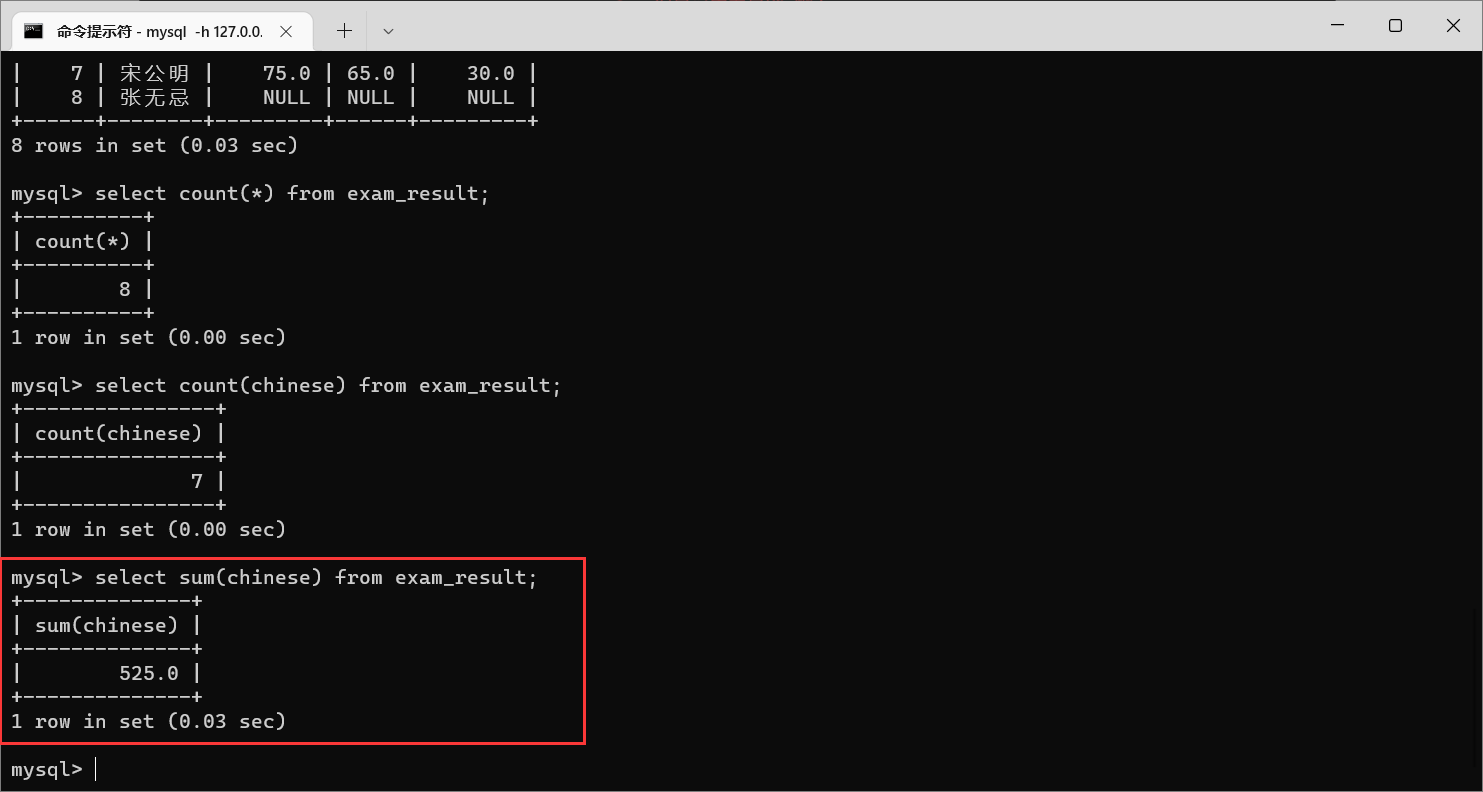
这个操作就是把所有人的语文成绩相加了
但是这个操作只能针对数字进行运算,不能针对字符串来进行
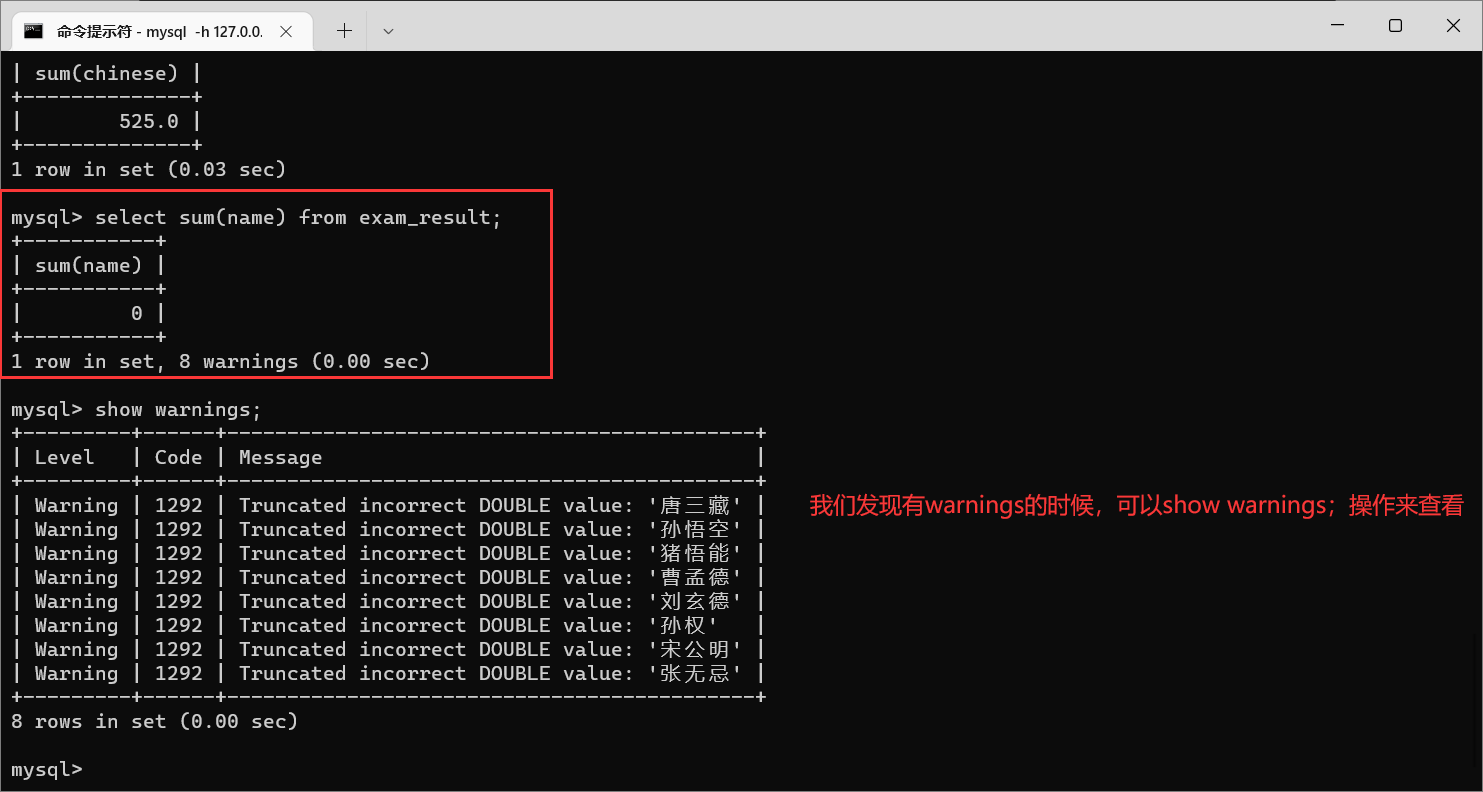
我们还可以把数学总成绩和语文总成绩进行求和
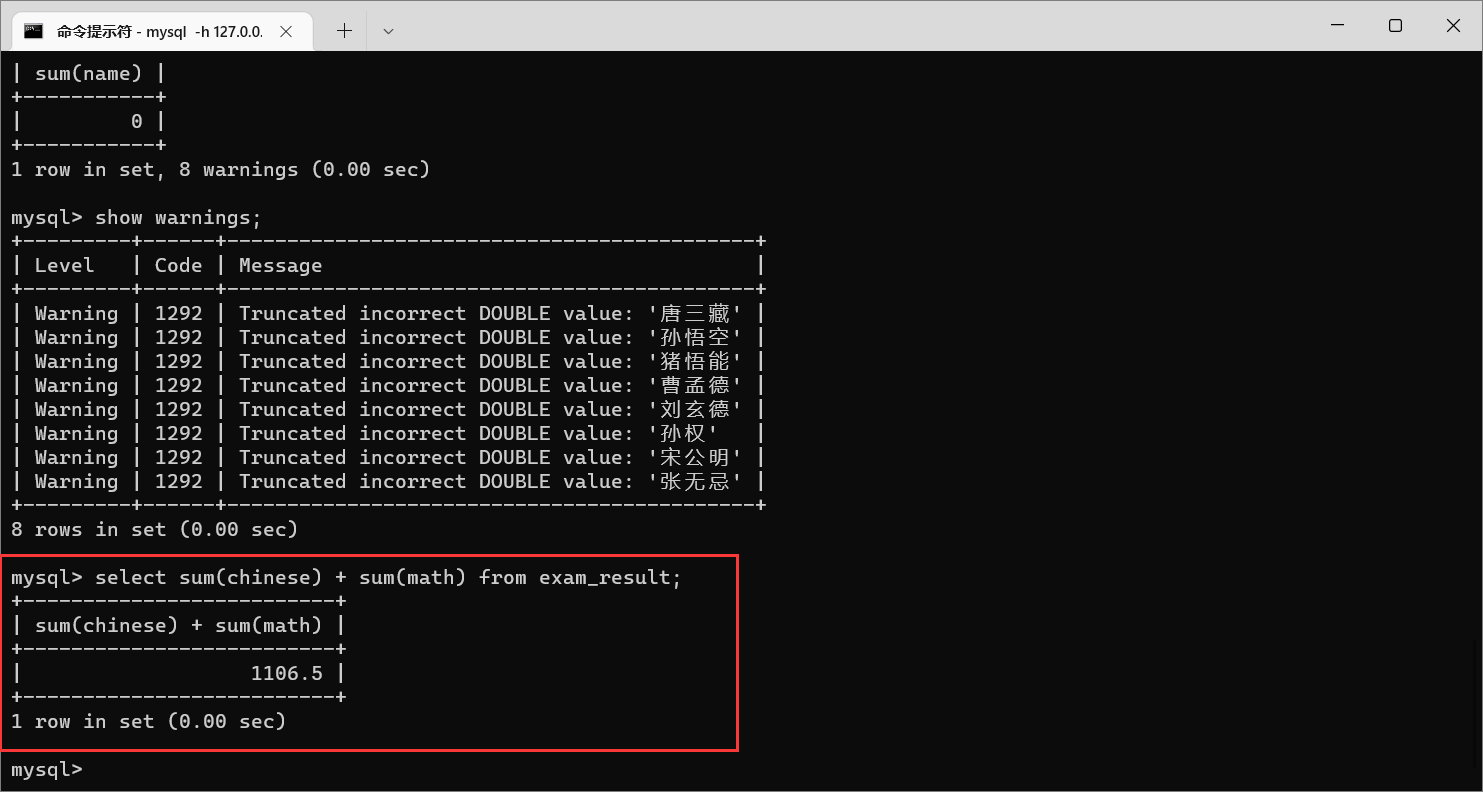
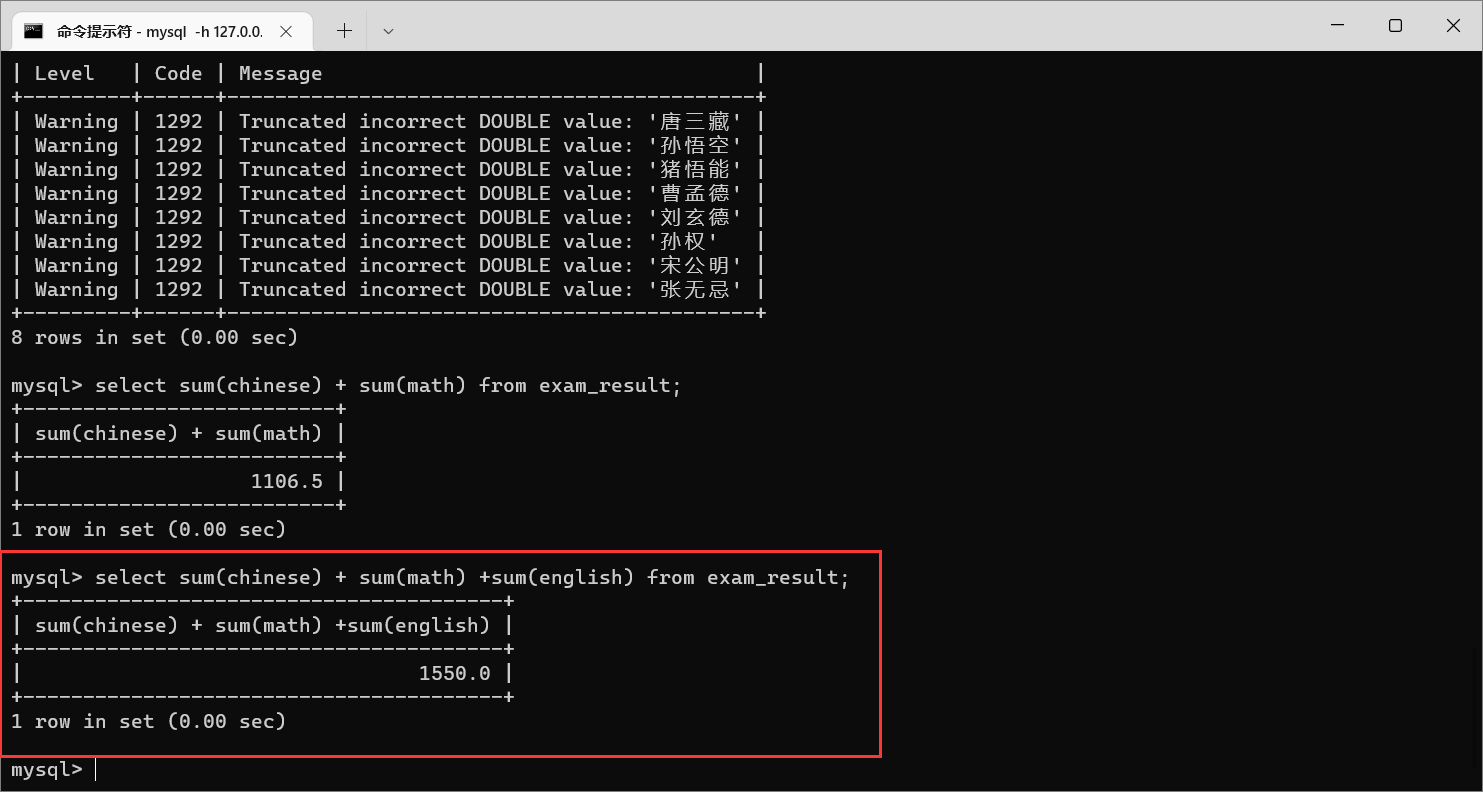
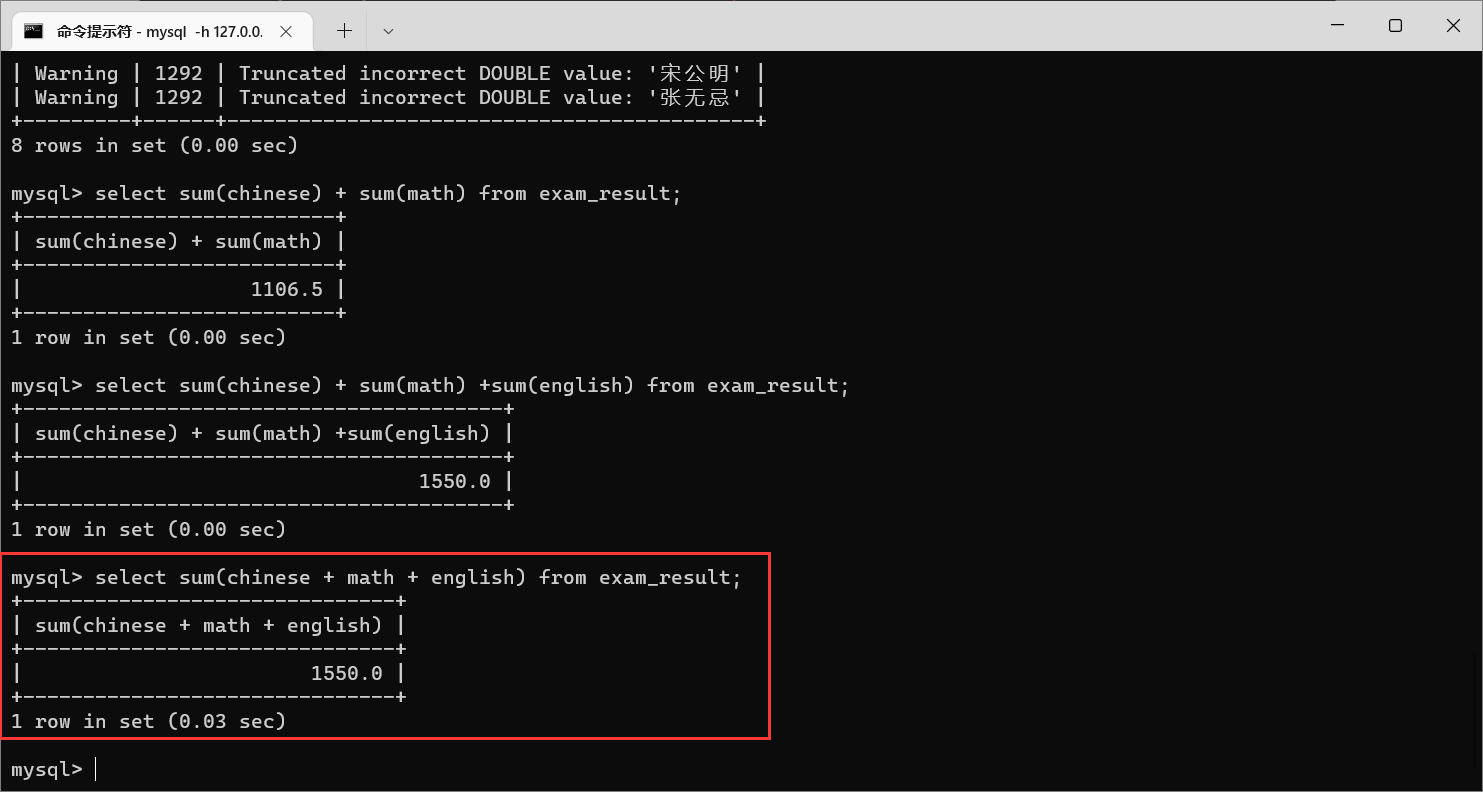
聚合函数里面的参数,也可以是表达式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YlipupBh-1670856561056)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E6%9C%88%E4%BA%AE.png)]](https://img-blog.csdnimg.cn/abbd8719801242babeb9283e3b39990c.png)
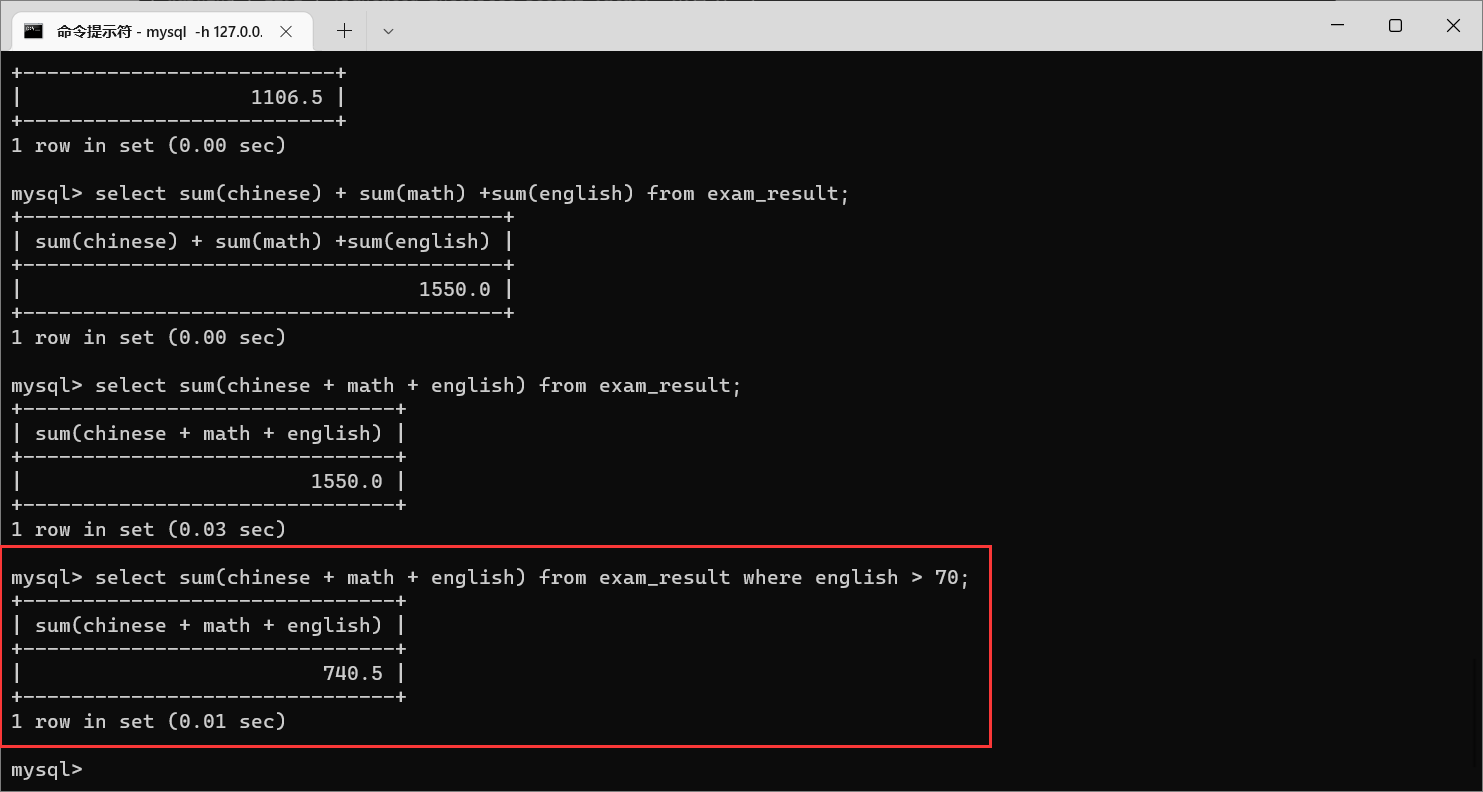
栗子3:聚合函数,也可以搭配
where
子句来使用,先基于条件进行筛选,再针对筛选结果进行聚合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BtaieOdp-1670856561057)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E7%AC%91%E8%84%B8.png)]](https://img-blog.csdnimg.cn/843cc36696534271adf89066996b8c1b.png)
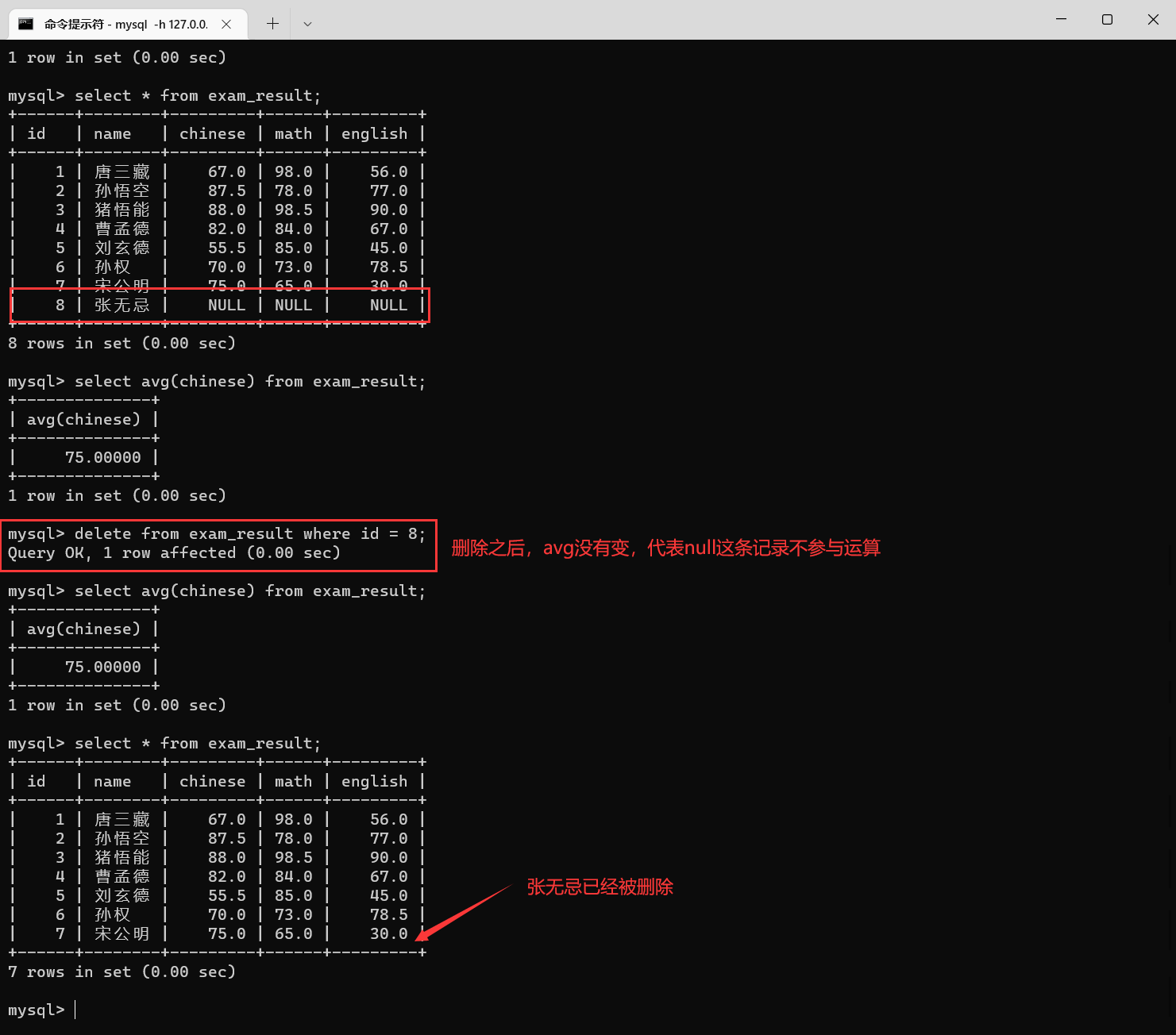
栗子4:
avg
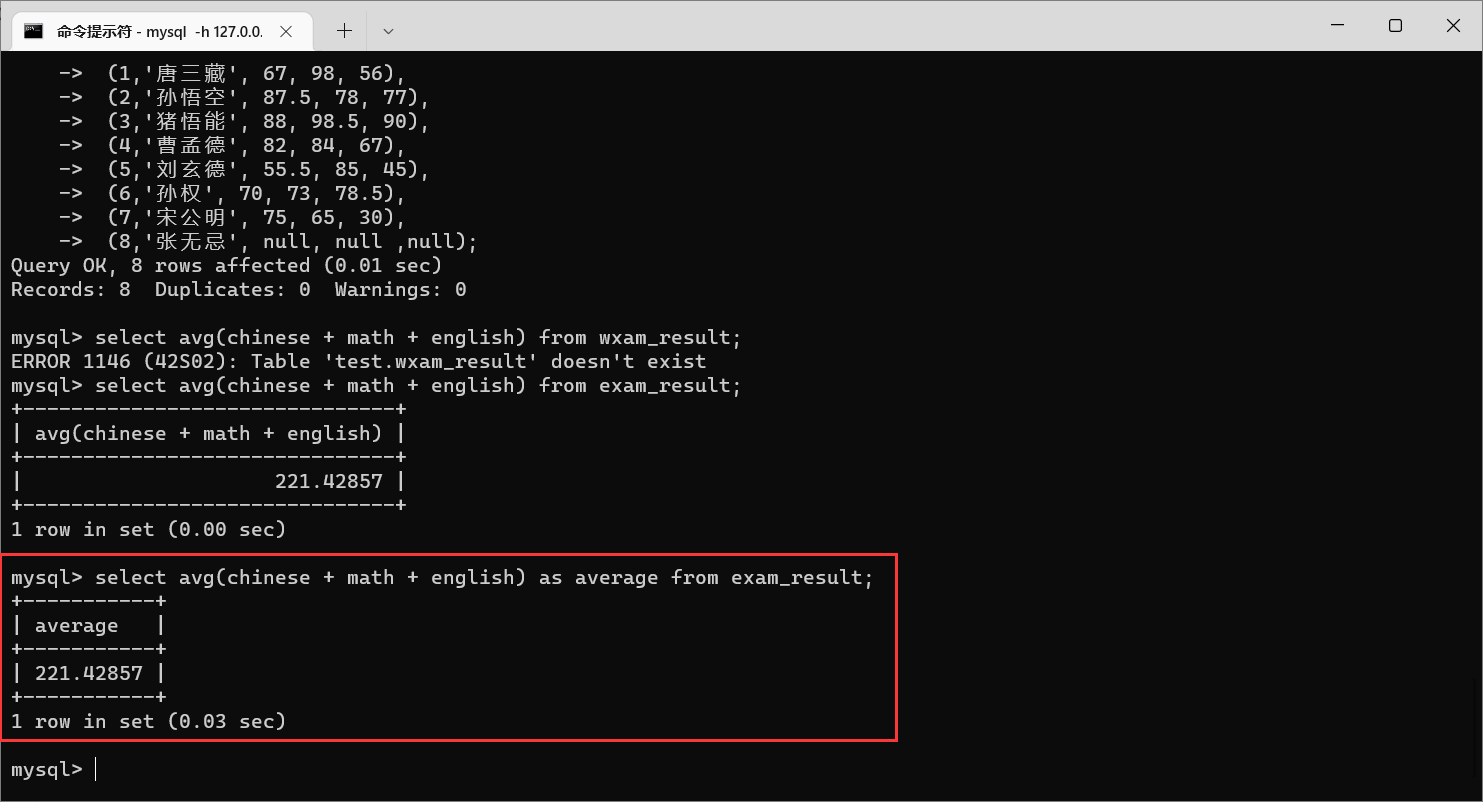
这个操作依然可以指定别名。
avg
操作是不统计
null
的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fB2FIIAA-1670856561057)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E6%9C%88%E4%BA%AE.png)]](https://img-blog.csdnimg.cn/ee4219f90dff48e299821d4e9ffa8b47.png)
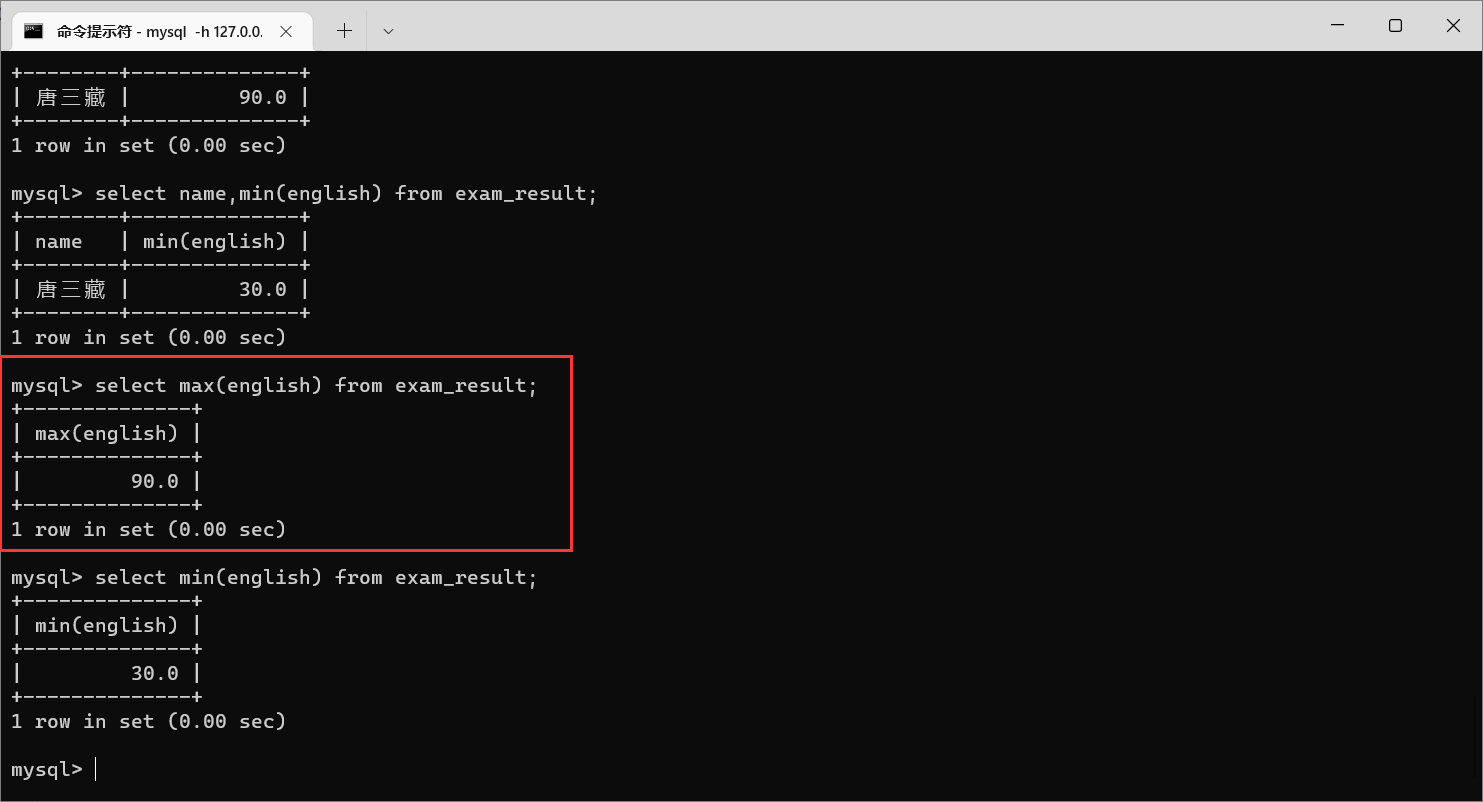
栗子5:
max
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zjy71tyA-1670856561058)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%B0%8F%E7%8C%AB%E5%88%86%E9%9A%94%E7%AC%A6.png)]](https://img-blog.csdnimg.cn/8e8b4c4a1421426f90286743c54d7707.png)
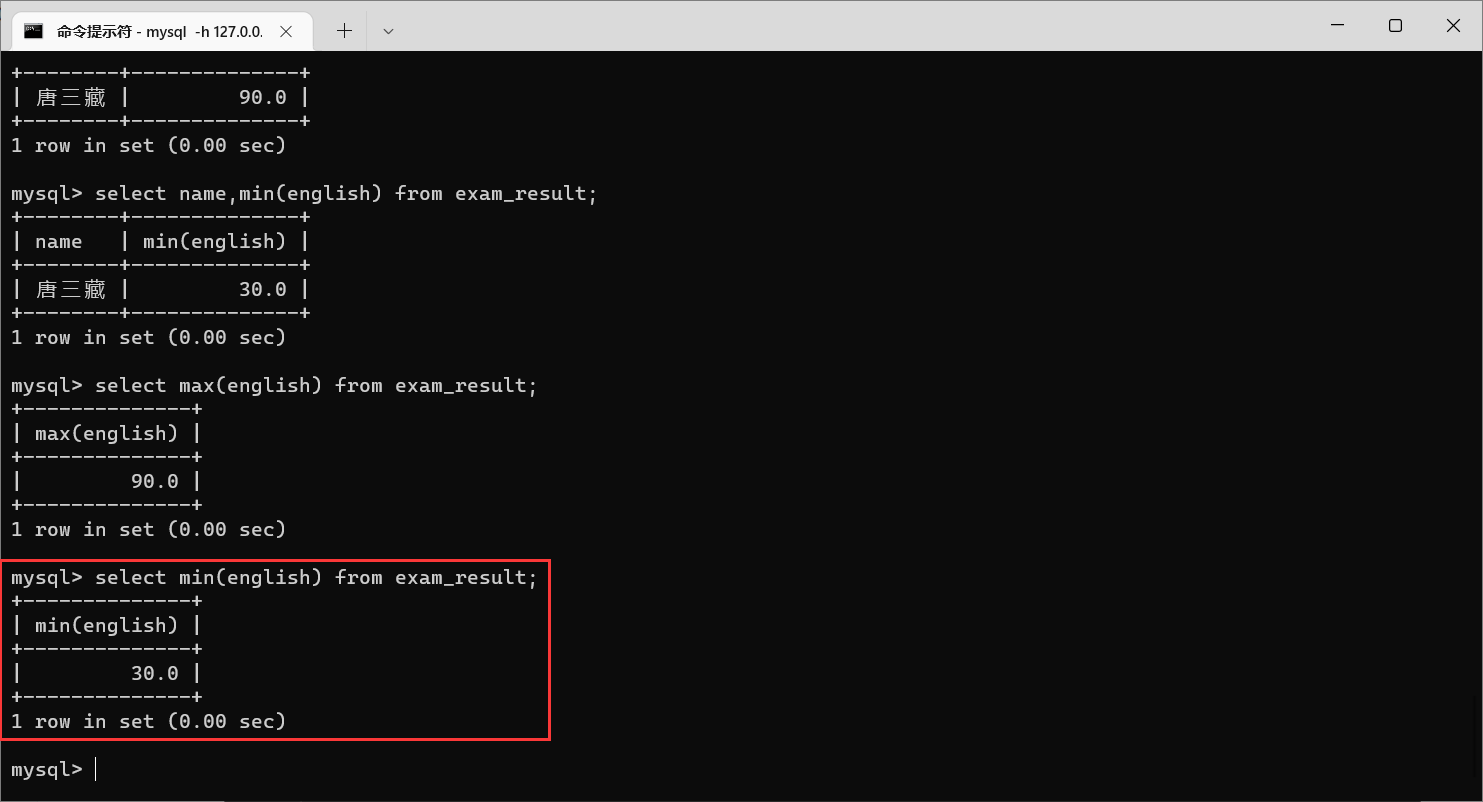
栗子6:
min
4.1.2 分组操作
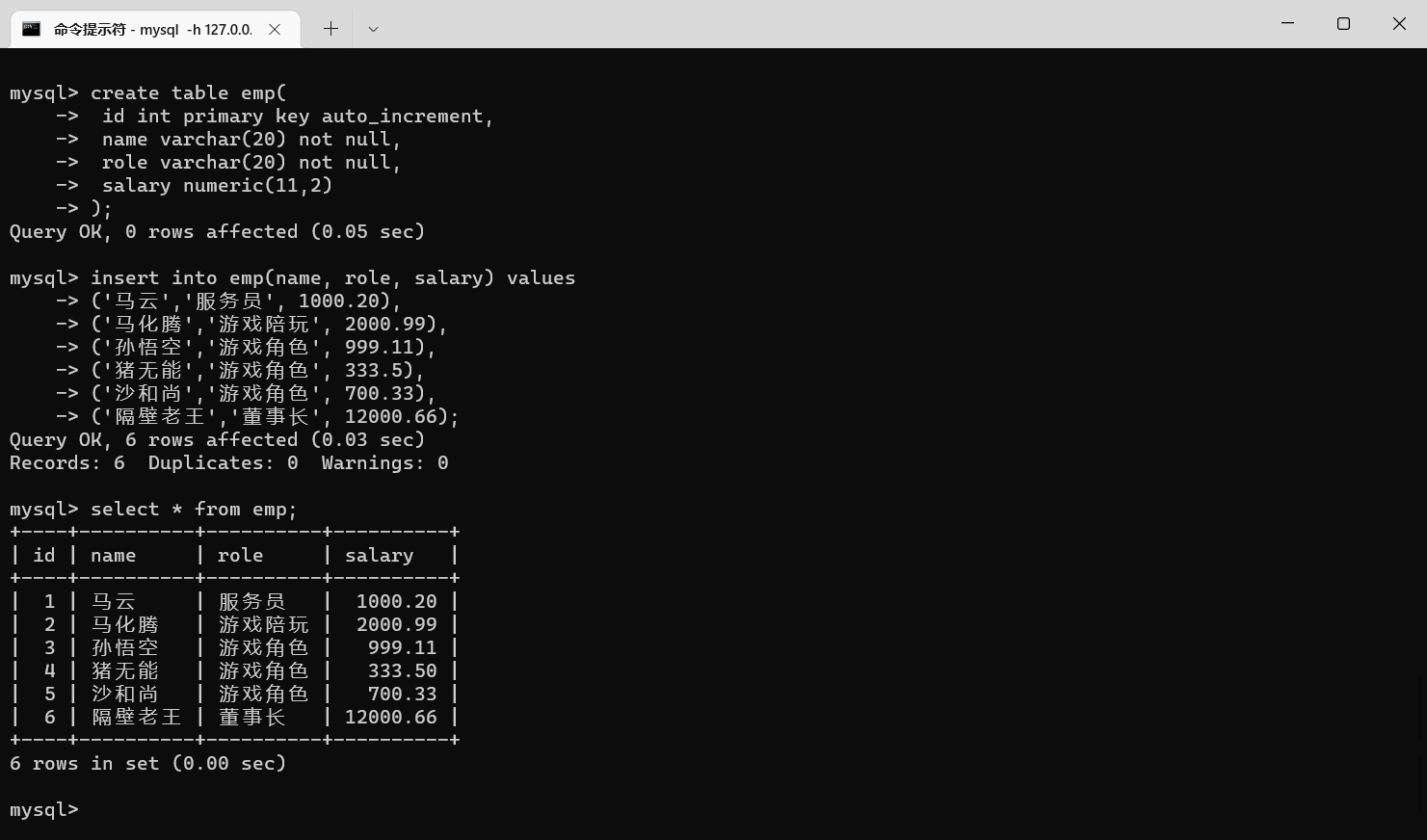
分组操作就是根据行的值,对数据进行分组,把值相同的都归为一组
我们先准备一些数据
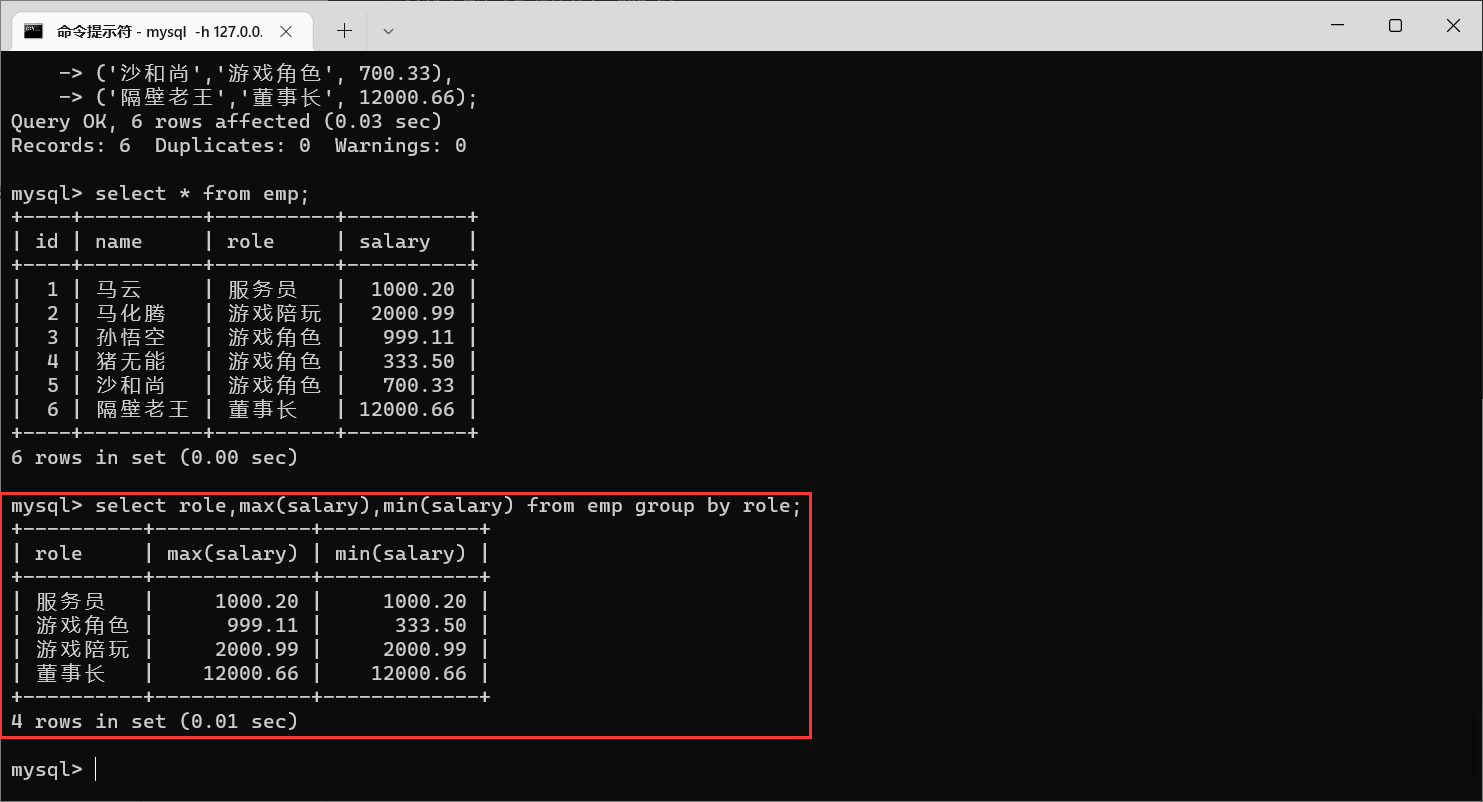
createtable emp(-> id intprimarykeyauto_increment,-> name varchar(20)notnull,-> role varchar(20)notnull,-> salary numeric(11,2)->);insertinto emp(name, role, salary)values->('马云','服务员',1000.20),->('马化腾','游戏陪玩',2000.99),->('孙悟空','游戏角色',999.11),->('猪无能','游戏角色',333.5),->('沙和尚','游戏角色',700.33),->('隔壁老王','董事长',12000.66);
举栗子来讲解:查询每个角色的最高工资、最低工资和平均工资
那么这种操作就是需要按照岗位进行分组(即
group by role
,根据
role
这一列进行分组)
我们可以发现,这个例子里面有4种角色
服务员
,
游戏陪玩
,
游戏角色
,
董事长
,分成四组之后,就可以针对每个组来使用聚合函数
执行流程:先根据
group by
,把这里面的查询结果进行分组,再根据分组完成的结果,针对每个组使用聚集函数
那么我们就可以知道:一个
sql
具体执行流程,跟代码书写顺序并不完全一致。
group by进行分组,是指定列的值,相同的记录合并到一个组里面,每个组又可以分别进行聚合查询。
分组还可以指定条件筛选,如果是分组之前指定条件,使用
where,如果是分组之后指定条件,使用
having
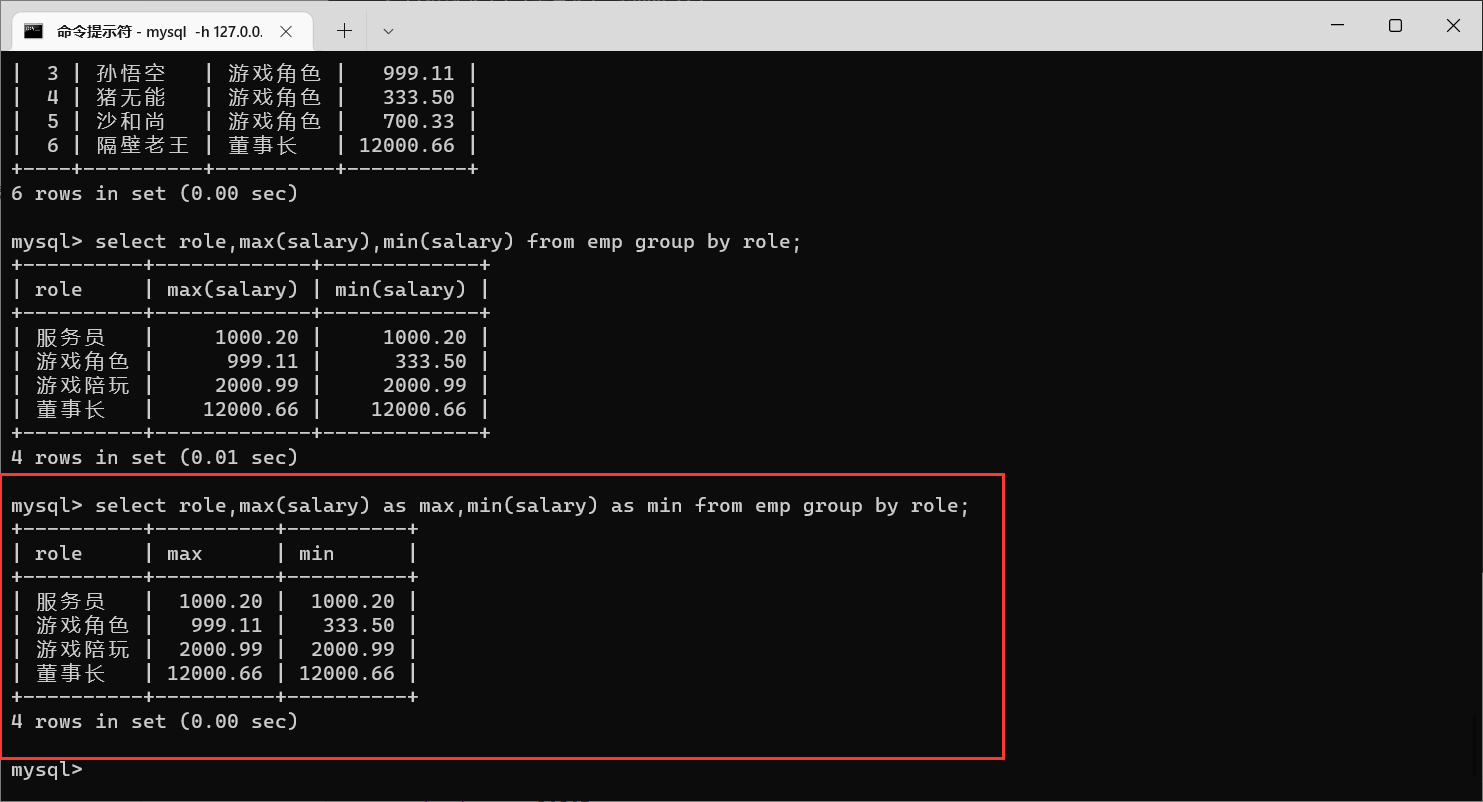
这个操作,我们还可以起别名
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aSjCHK3Z-1670856561059)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E7%AC%91%E8%84%B8.png)]](https://img-blog.csdnimg.cn/f3c9a101a4e44b06be31c6bc98833810.png)
针对分组之后,得到的结果,我们还可以通过
having
来进行指定条件
group by子句可以使用
where,不过
where是在分组之前执行。如果要对分组之后的结果进行条件筛选,就需要使用
havinghaving搭配
group by来使用,跟多对多啥的没关系
那么我们举例子吧:
分组之前:求每种角色的平均薪资(但是要去掉马云)
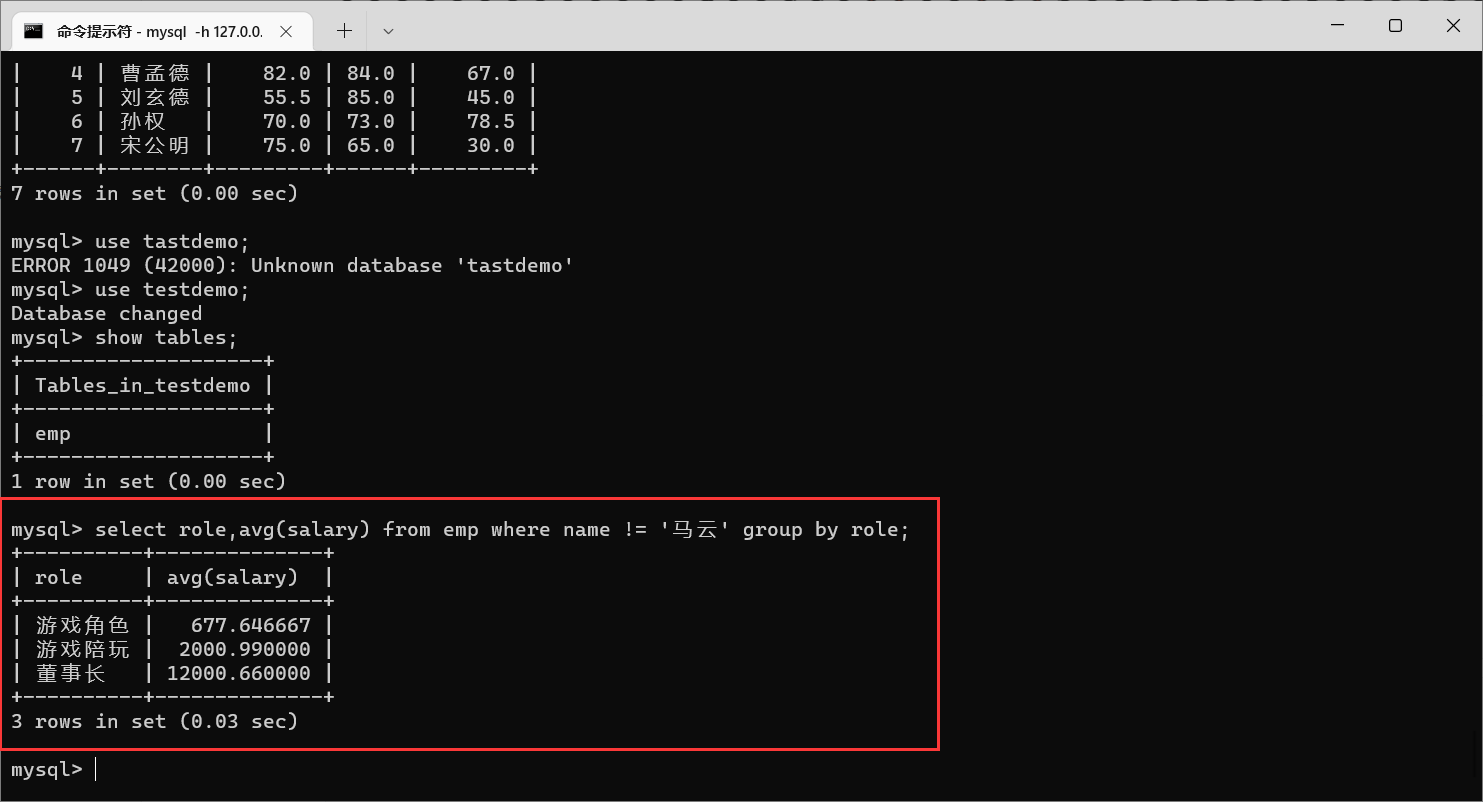
我们看一下,之前的记录里面马云是服务员的角色,现在没有服务员的角色了,代表
where name != '马云'是在
group by role之前执行的
另外,
where是写在
group之前的
分组之后:指定条件筛选
求平均薪资1w一下的角色的平均薪资
这里就需要先分组求平均薪资,再去筛选1w以下的(分组之后指定条件就需要用
having
)
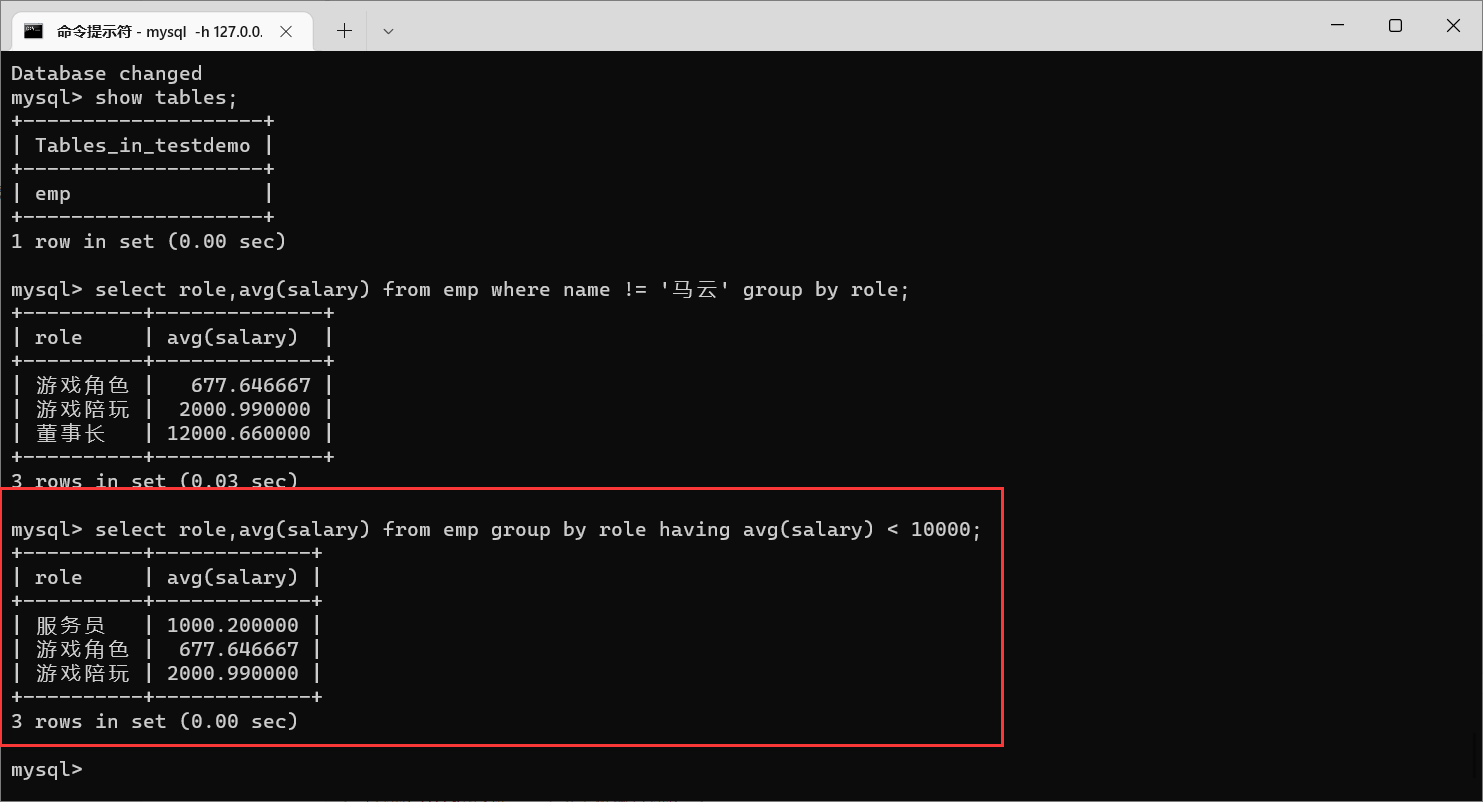
我们可以发现,董事长的薪资是大于1w的,现在已经没有了
另外,
having是写在
group之后的
4.2 联合查询
联合查询(多表查询)就是把多个表的记录往一起合并,一起进行查询
多表查询是整个
SQL
里面最复杂的部分了,也是笔试最常见的出题位置,但是在实际工作一般禁止使用多表查询,原因一会解释。那么在学习多表查询之前,我们要先了解一下笛卡尔积这个东西
4.2.1 笛卡尔积
笛卡尔积是多表查询中的核心操作,是针对于任意两张表之间的计算
笛卡尔积的计算过程:先拿出第一张表里面的第一条记录,去和第二张表里面的每个记录,分别组合,得到一组新的纪录,再去拿第一张表的第二条记录重复刚才的操作
举个栗子:
这是我们创建出来的两个有关联的表

那么我们来进行笛卡尔积计算

针对
A
B
两张表,计算笛卡尔积,此时笛卡尔积的列数,就是
A
的列数+
B
的列数,笛卡尔积的行数,就是
A
的行数*
B
的行数
那么我们之前提到,在公司中一般禁止多表查询,这是因为多表查询涉及笛卡尔积操作,如果两个表都非常大,此时如果贸然执行笛卡尔积,就很有可能把数据库给弄坏。
那么在数据库当中怎么进行笛卡尔积操作呢?
4.2.2 数据库当中的笛卡尔积操作
最简单的做法,就是直接在
select
语句的
from
后面跟上多个表名,表名与表名之间用逗号隔开
我们来创建一组数据:
createtable student(studentId int,name varchar(20),classId int);createtable class(id int,name varchar(20));
insertinto student values(1,'张三',1);insertinto student values(2,'李四',1);insertinto student values(3,'王五',2);insertinto student values(4,'赵六',3);
insertinto class values(1,'0301');insertinto class values(2,'0302');insertinto class values(3,'0303');
那我们就可以进行笛卡尔积了
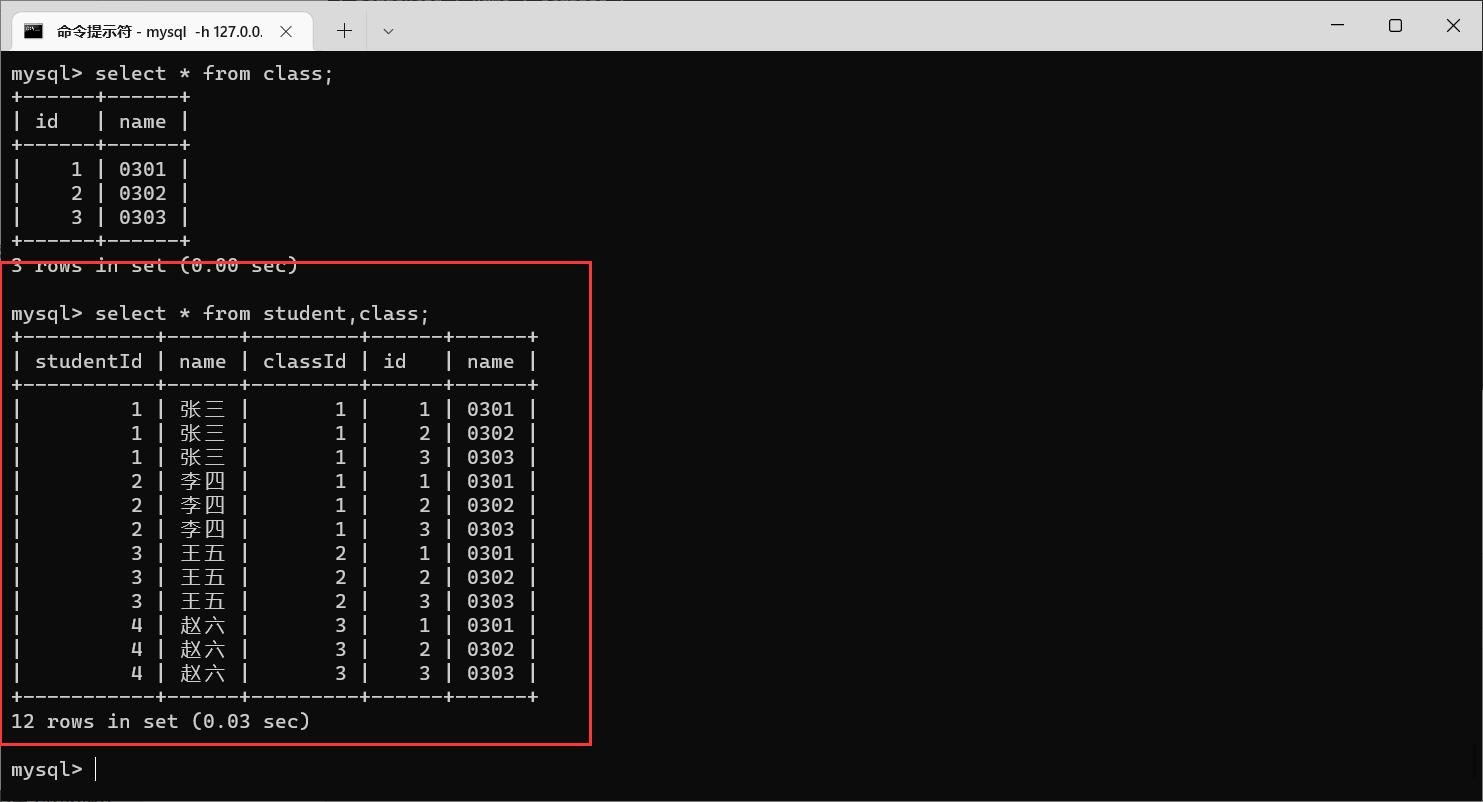
笛卡尔积是两张表中数据尽可能的排列组合得到的,在这些排列组合当中,有我们需要的数据,也有很多没有意义的数据。
对于这个例子来说,都有
classId
这一列,那么
classId
相等的记录,我们就需要保留,像这样的情况就称为"连接条件"
带有连接条件的笛卡尔积,就是多表查询
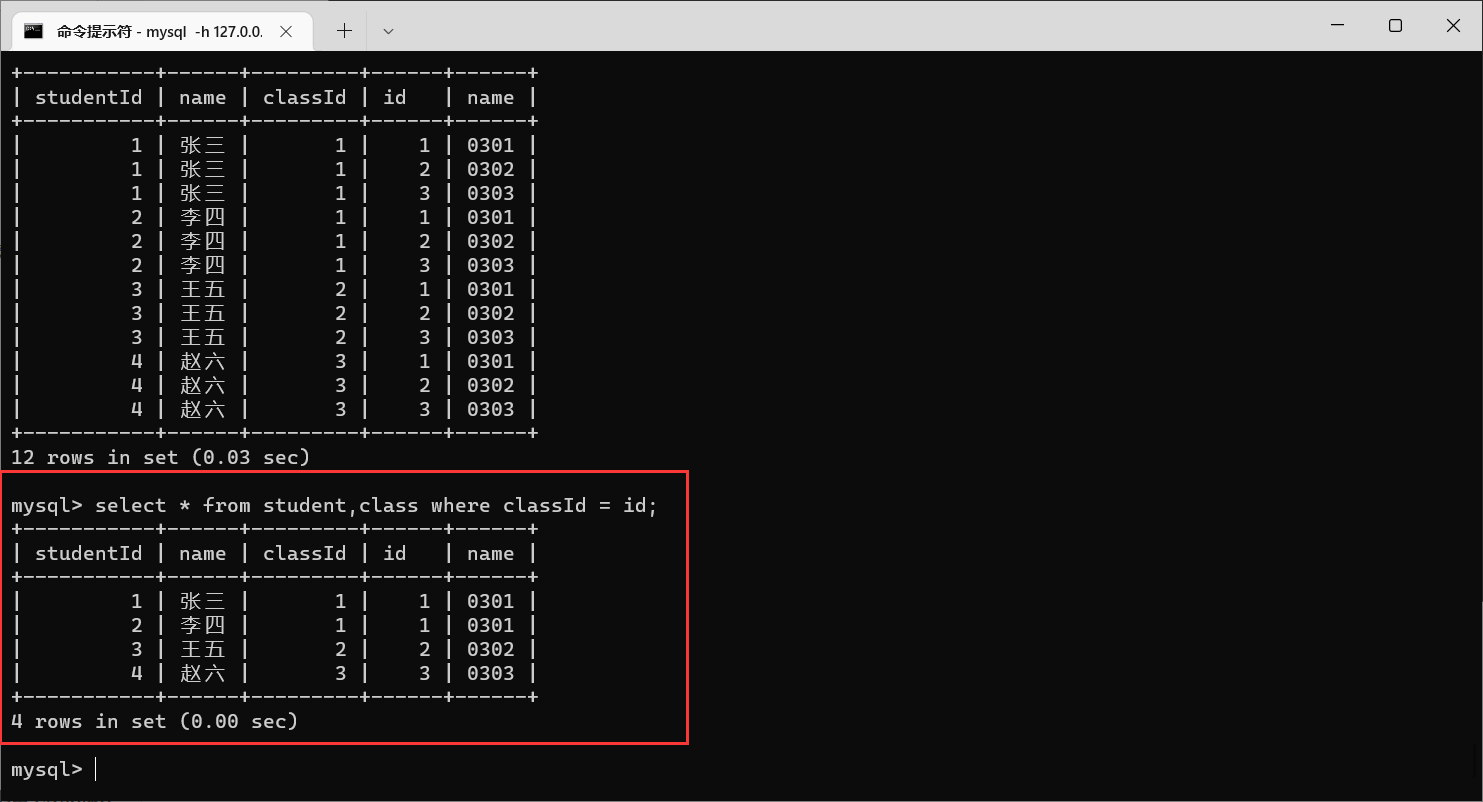
那么我们还有这种情况,我们把
class
表里面的
id
改成
classId
(跟
student
表里面的
classId
重名)
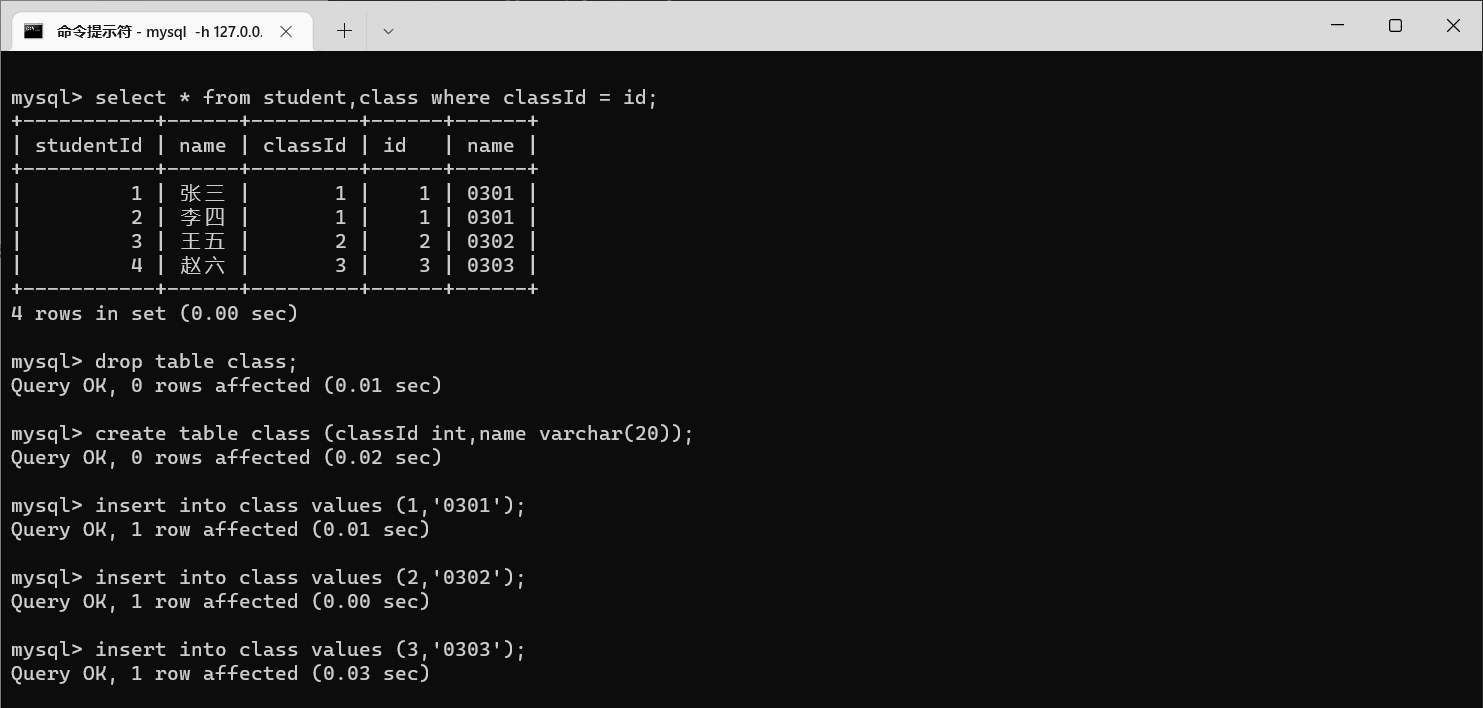
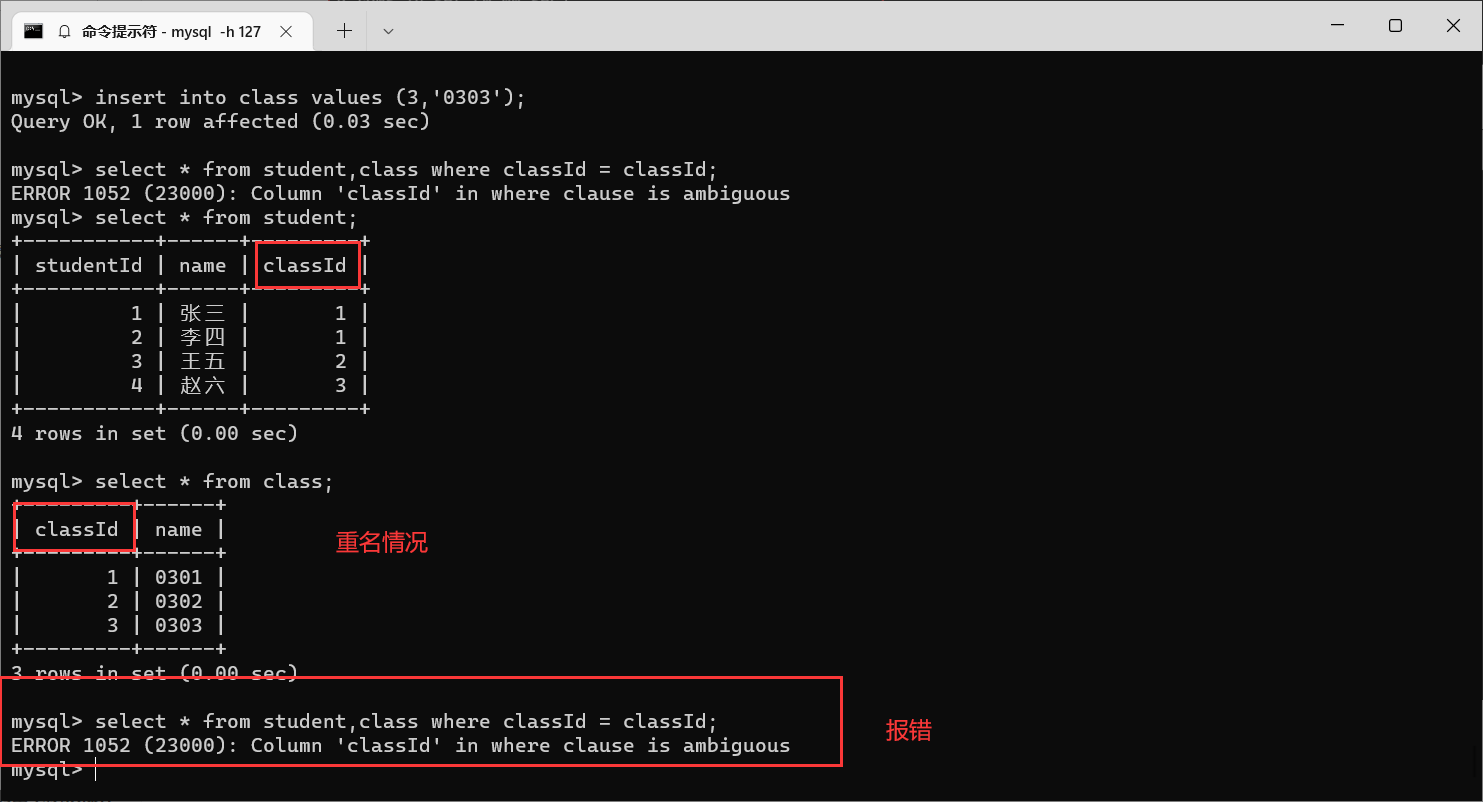
当两个表的列名相同的时候,需要通过
表名.列名
的方式
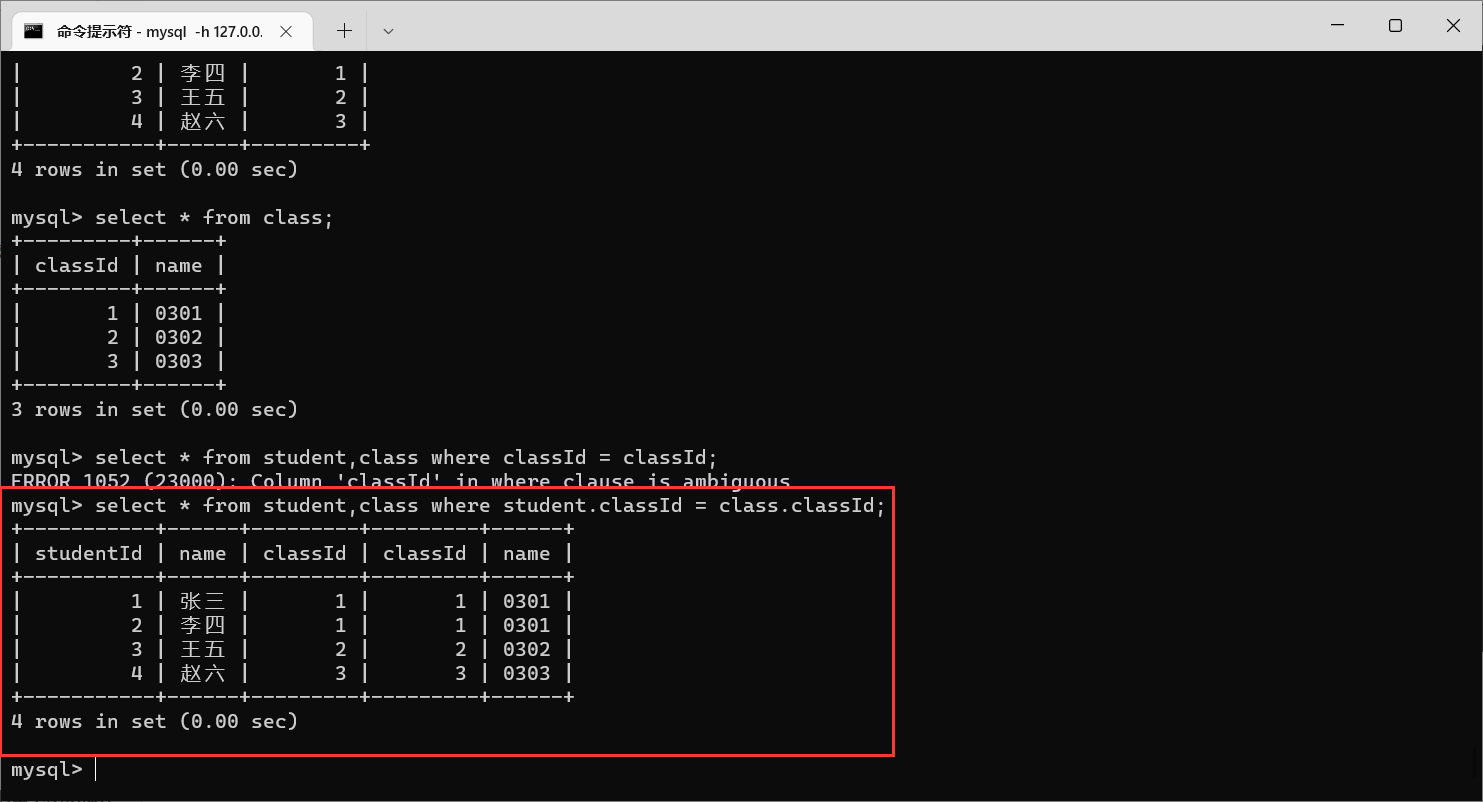
如果列明不会混淆(不是同名的),也可以用
表名.列名
,也可以省略表名
那么有的同学可能有问题了,创建表的时候不是不能有同名项的吗?
同一个表里面确实不能有两个同名的列,但是这是两个表啊。
那么在最终的查询结果中,一般只是需要展示部分列,需要展示哪个列展示哪个列就行了
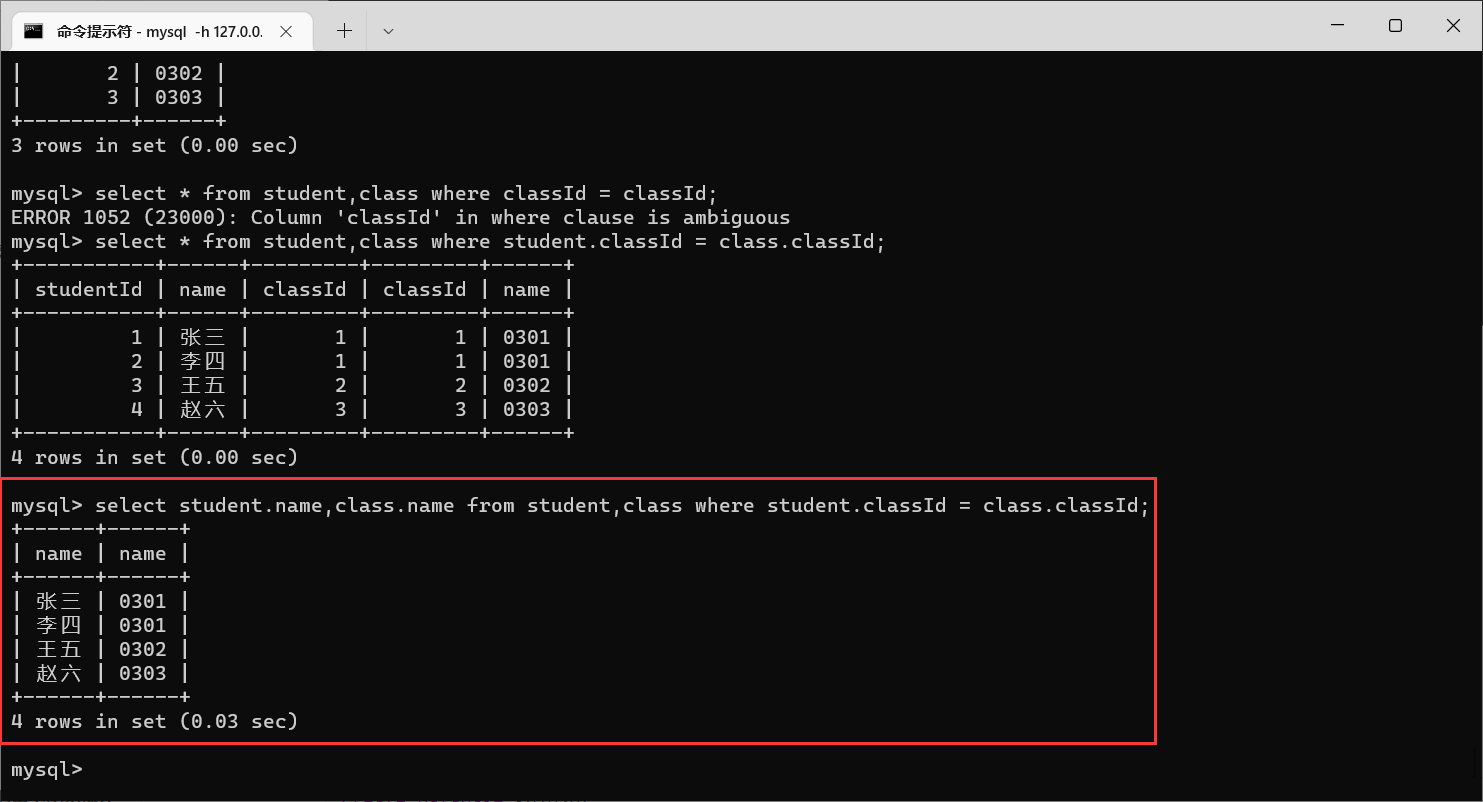
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pjRADY2w-1670856561061)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E6%9C%88%E4%BA%AE.png)]](https://img-blog.csdnimg.cn/17fdd2aff81b4651a8658197c32f1458.png)
那么我们再举一个难一点的栗子
4.2.3 栗子(内连接、外连接)
创建数据:
createdatabase sql0507;use sql0507;
createtable classes (id intprimarykeyauto_increment, name varchar(20),`desc`varchar(100));createtable student (id intprimarykeyauto_increment,sn varchar(20),name varchar(20),qq_mail varchar(20),classes_id int);createtable course(id intprimarykeyauto_increment, name varchar(20));createtable score(score decimal(3,1), student_id int, course_id int);
insertinto classes(name,`desc`)values('计算机系2019级1班','学习了计算机原理、C和Java语言、数据结构和算法'),('中文系2019级3班','学习了中国传统文学'),('自动化2019级5班','学习了机械自动化');insertinto student(sn, name, qq_mail, classes_id)values('09982','黑旋风李逵','[email protected]',1),('00835','菩提老祖',null,1),('00391','白素贞',null,1),('00031','许仙','[email protected]',1),('00054','不想毕业',null,1),('51234','好好说话','[email protected]',2),('83223','tellme',null,2),('09527','老外学中文','[email protected]',2);insertinto course(name)values('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insertinto score(score, student_id, course_id)values-- 黑旋风李逵(70.5,1,1),(98.5,1,3),(33,1,5),(98,1,6),-- 菩提老祖(60,2,1),(59.5,2,5),-- 白素贞(33,3,1),(68,3,3),(99,3,5),-- 许仙(67,4,1),(23,4,3),(56,4,5),(72,4,6),-- 不想毕业(81,5,1),(37,5,5),-- 好好说话(56,6,2),(43,6,4),(79,6,6),-- tellme(80,7,2),(92,7,6);
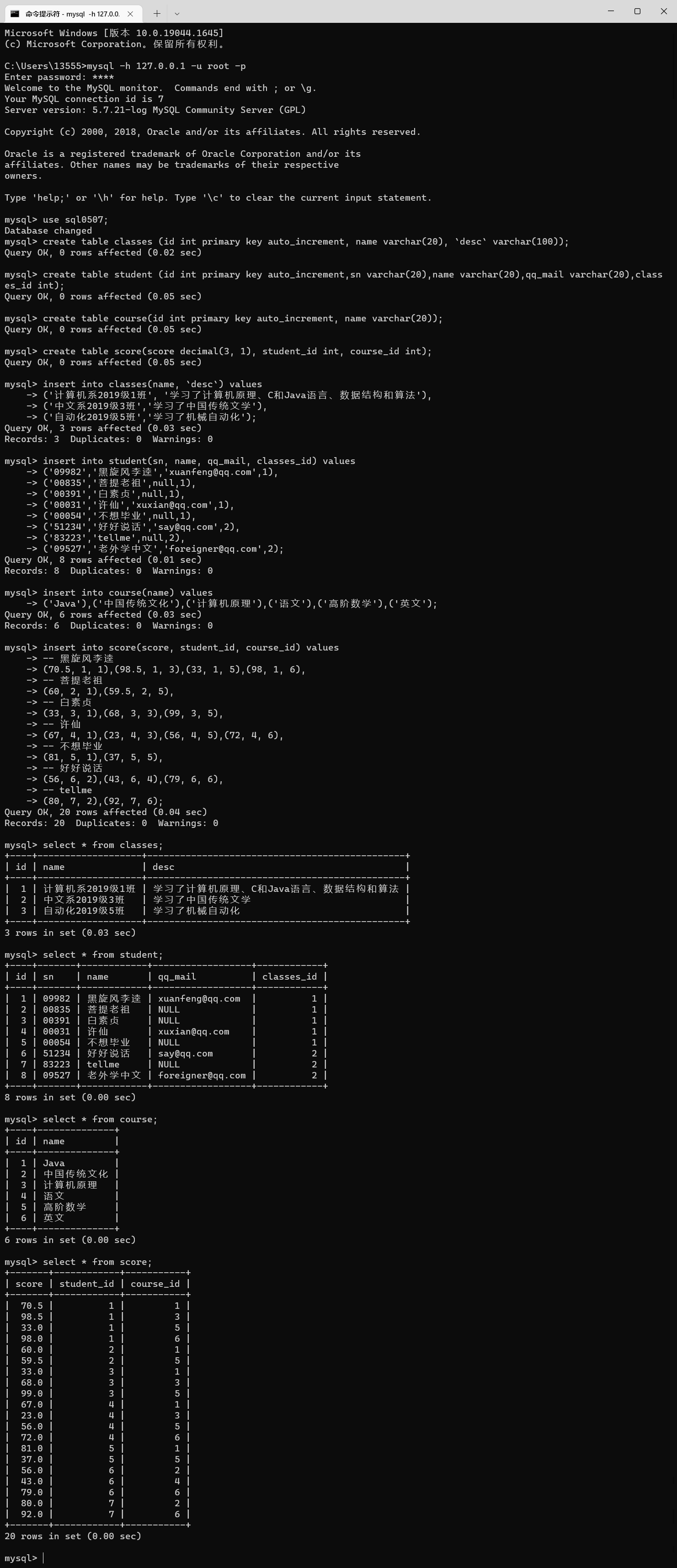
在这个场景中,涉及到的实体有三个:学生 班级 课程
学生和班级是一对多的关系
学生和课程是多对多的课程(分数表其实就是学生和课程之间的关联表)
做多表查询的题目时候,我们需要先想清楚要查询的数据都来自于哪些表中
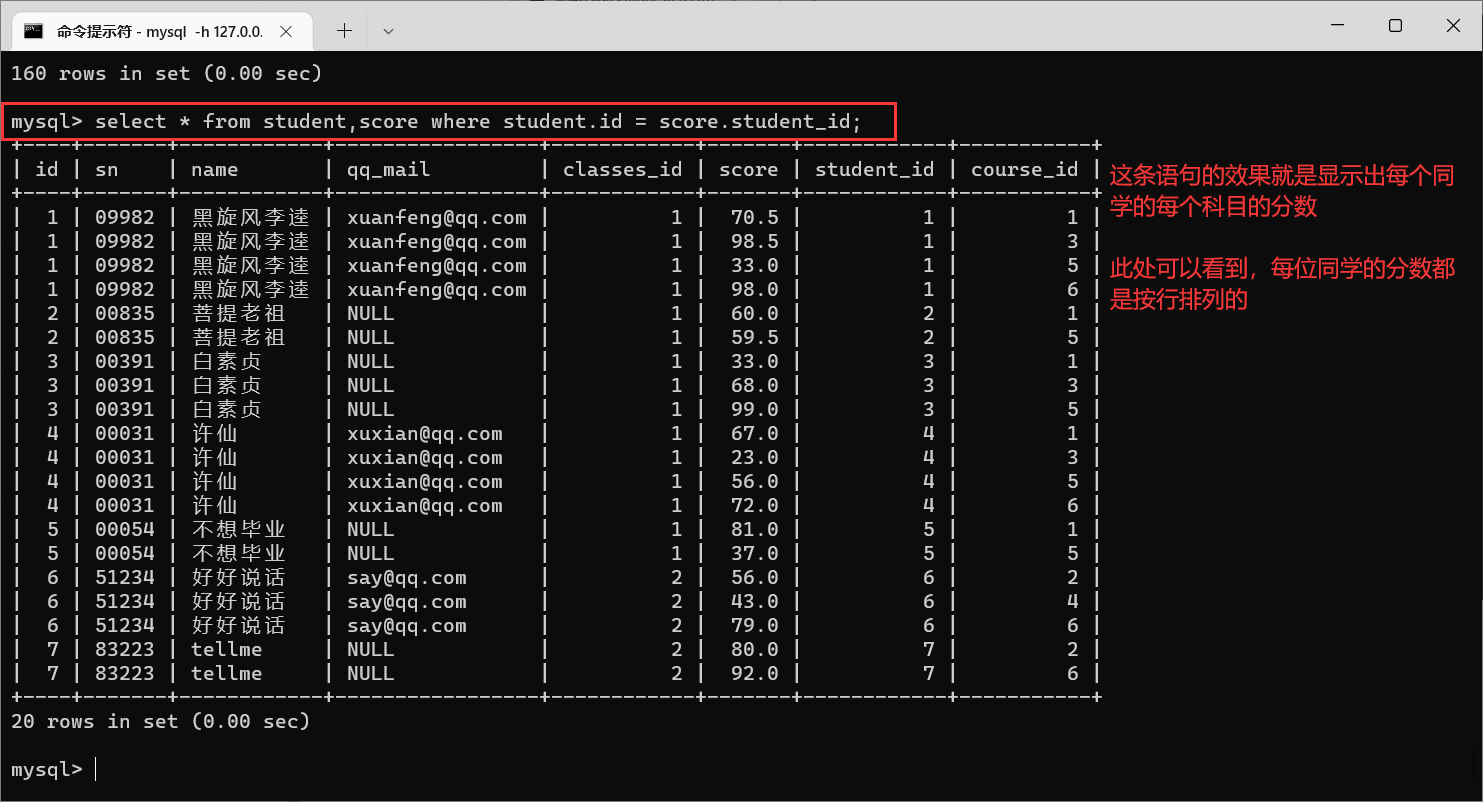
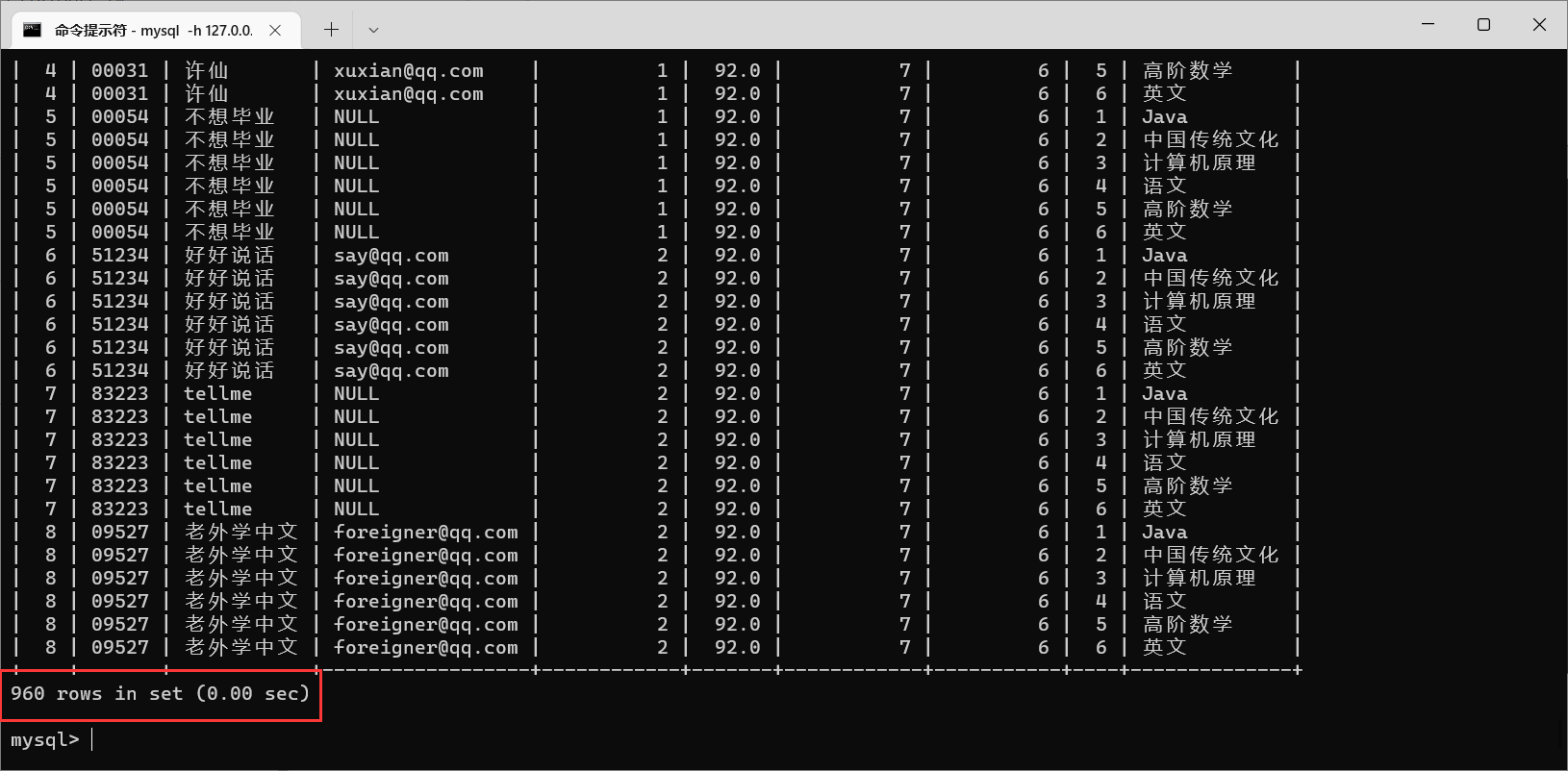
4.2.3.1 栗子1:查询许仙同学的成绩
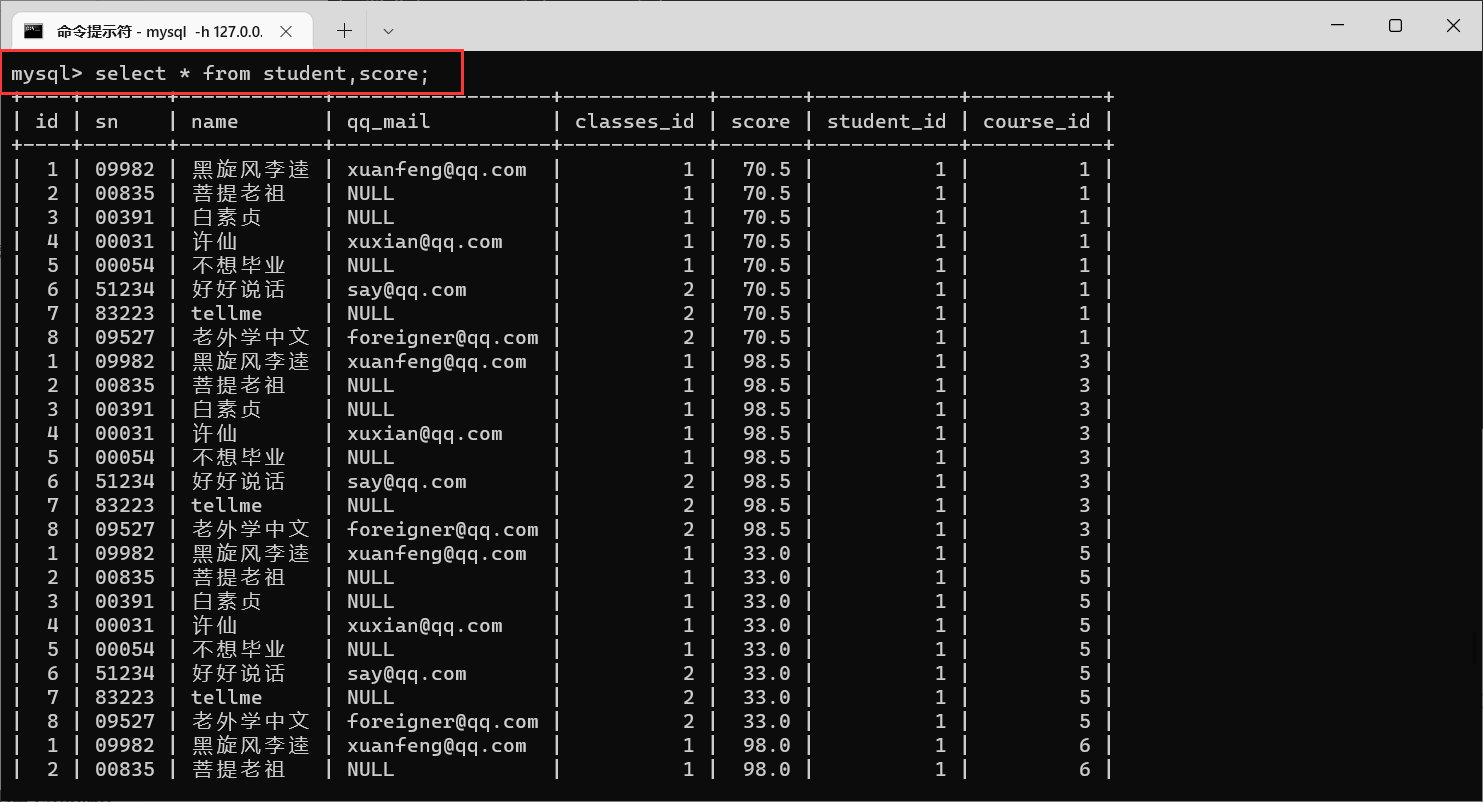
许仙同学选了很多课,那么我们就需要在学生表当中获取到学生信息,在分数表当中获取到分数信息,那么我们就需要对学生表和分数表进行笛卡尔积
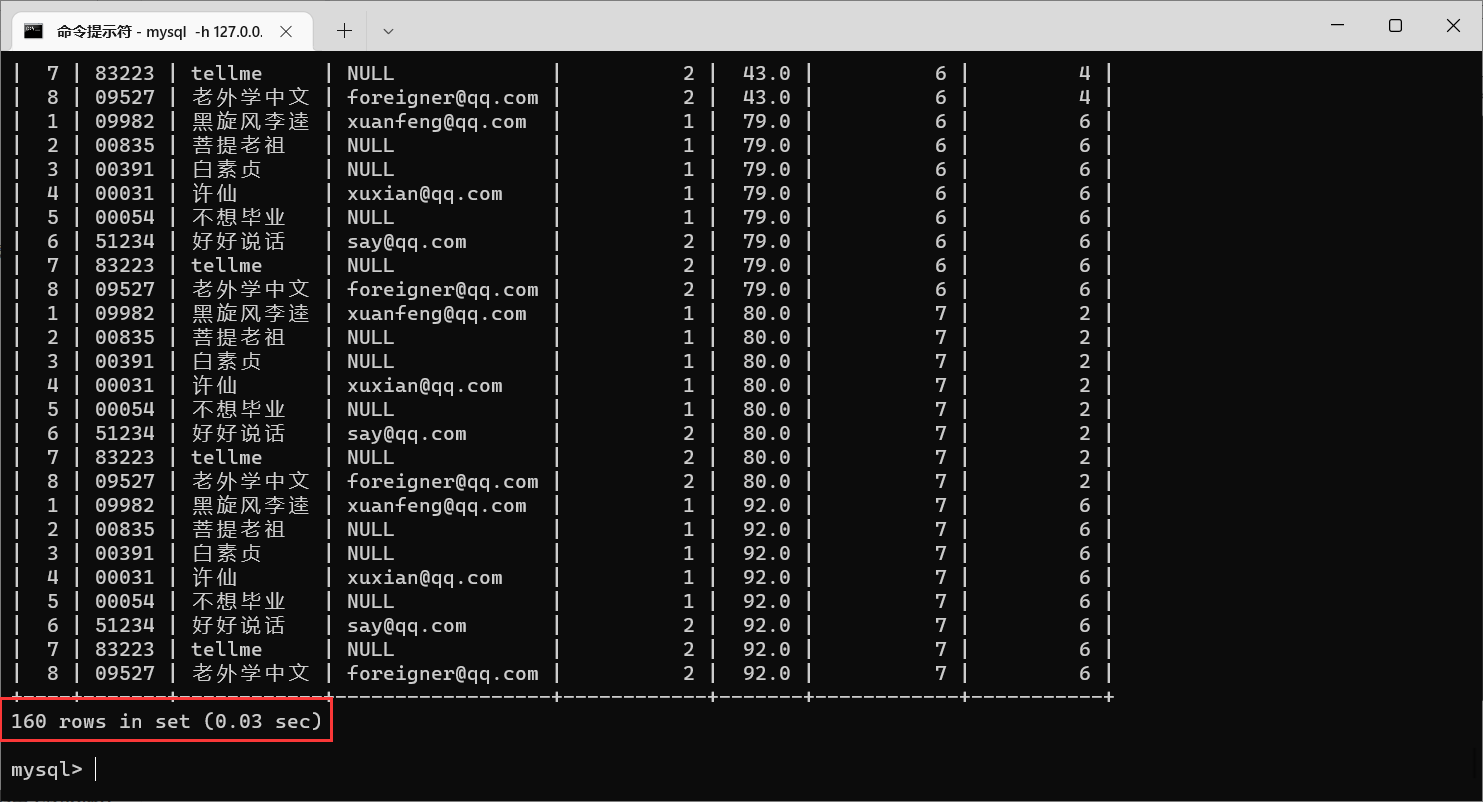
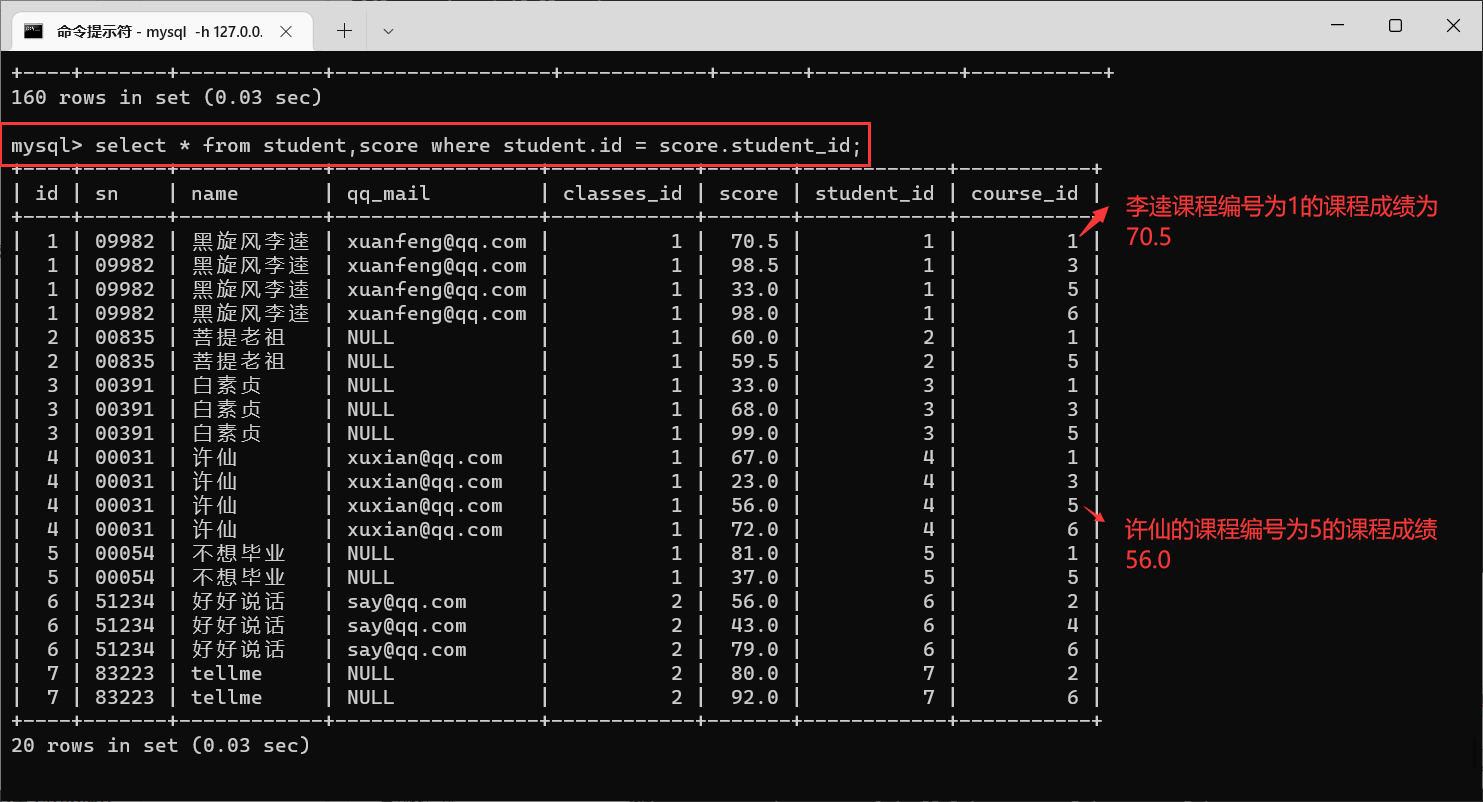
我们可以看到,产生了160行数据,观察之后,可以发现,这两张表里面,都存在
学生Id这一列,那么我们就需要让这两个
id匹配,不匹配的就是排列组合之后生成的无效数据
筛选之后,出现的就是每个人每科的成绩
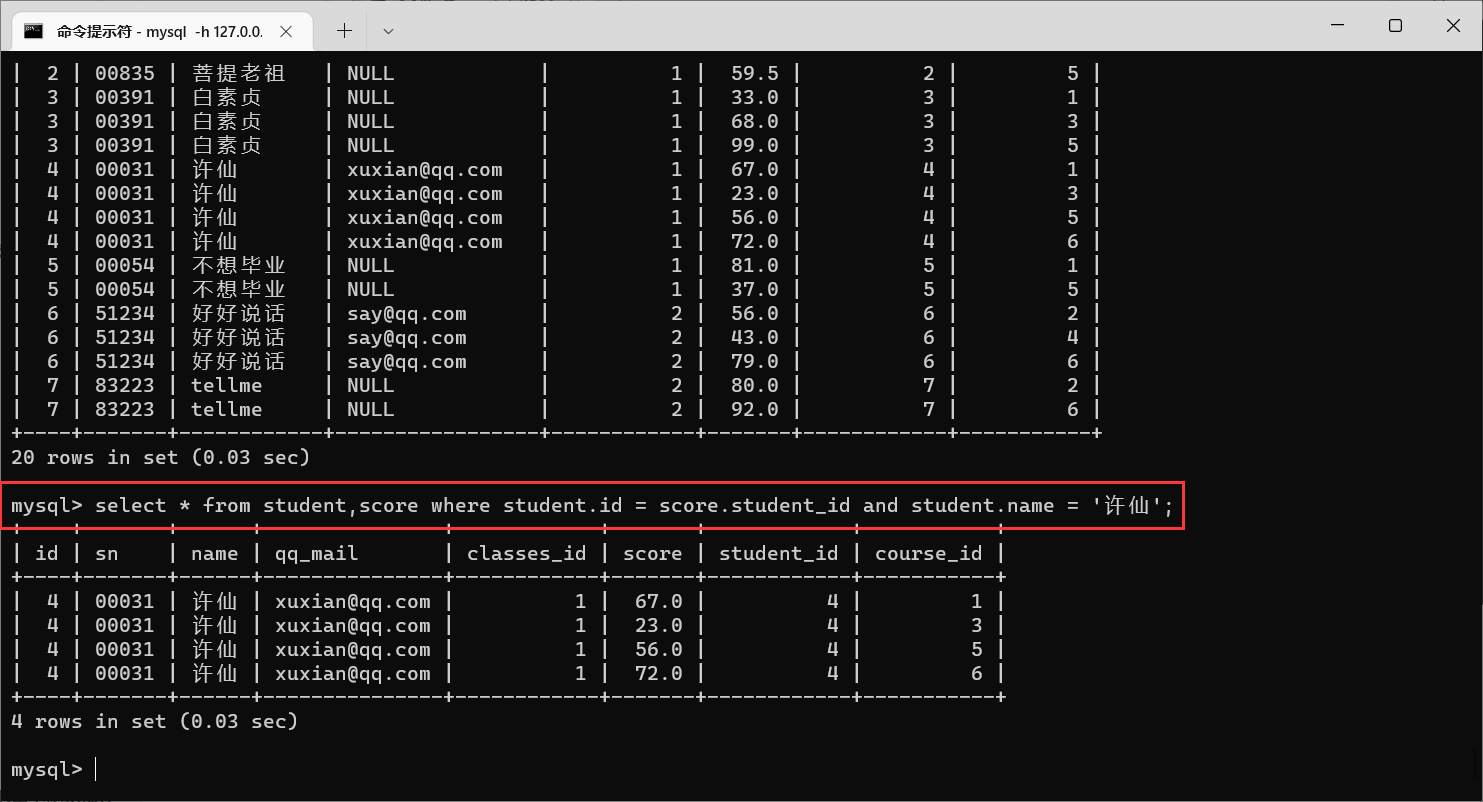
接下来,我们需要找到许仙的成绩,其他人的成绩就可以筛选掉了
那么,我们只需要许仙的名字以及成绩即可
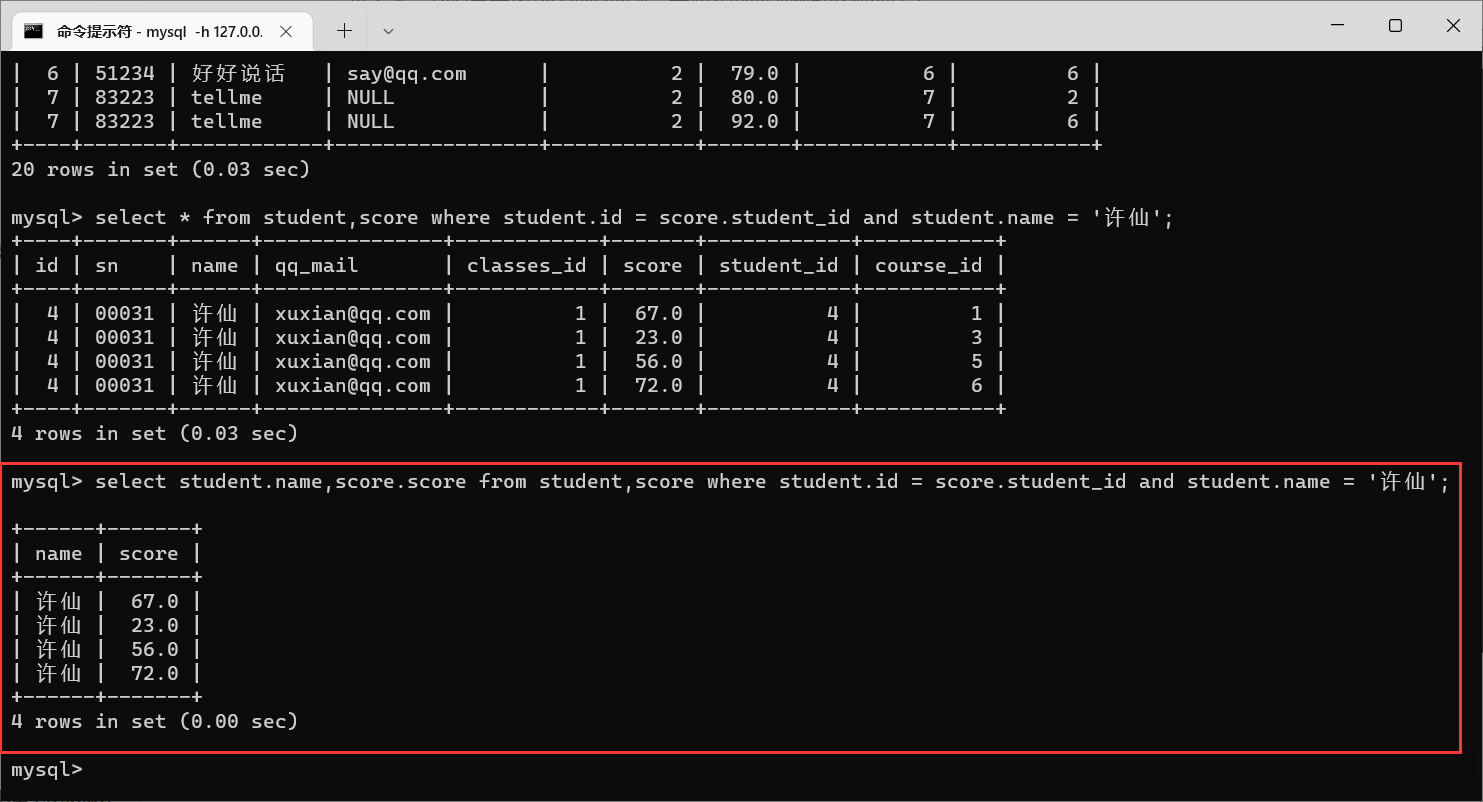
像这样,我们就一步一步把语句写出来了
多表查询不是一蹴而就的过程,我们要一步一步写,先分析需要的数据是来源于哪个表,然后进行笛卡尔积,观察笛卡尔积的结果,找到相同的数据列,筛选出合法数据,再逐步根据需求,添加新的要求,让数据逐步趋近于要求
实现这个多表查询,我们刚才使用的是
from
多张表,我们还可以通过
join
这个关键字实现多表查询
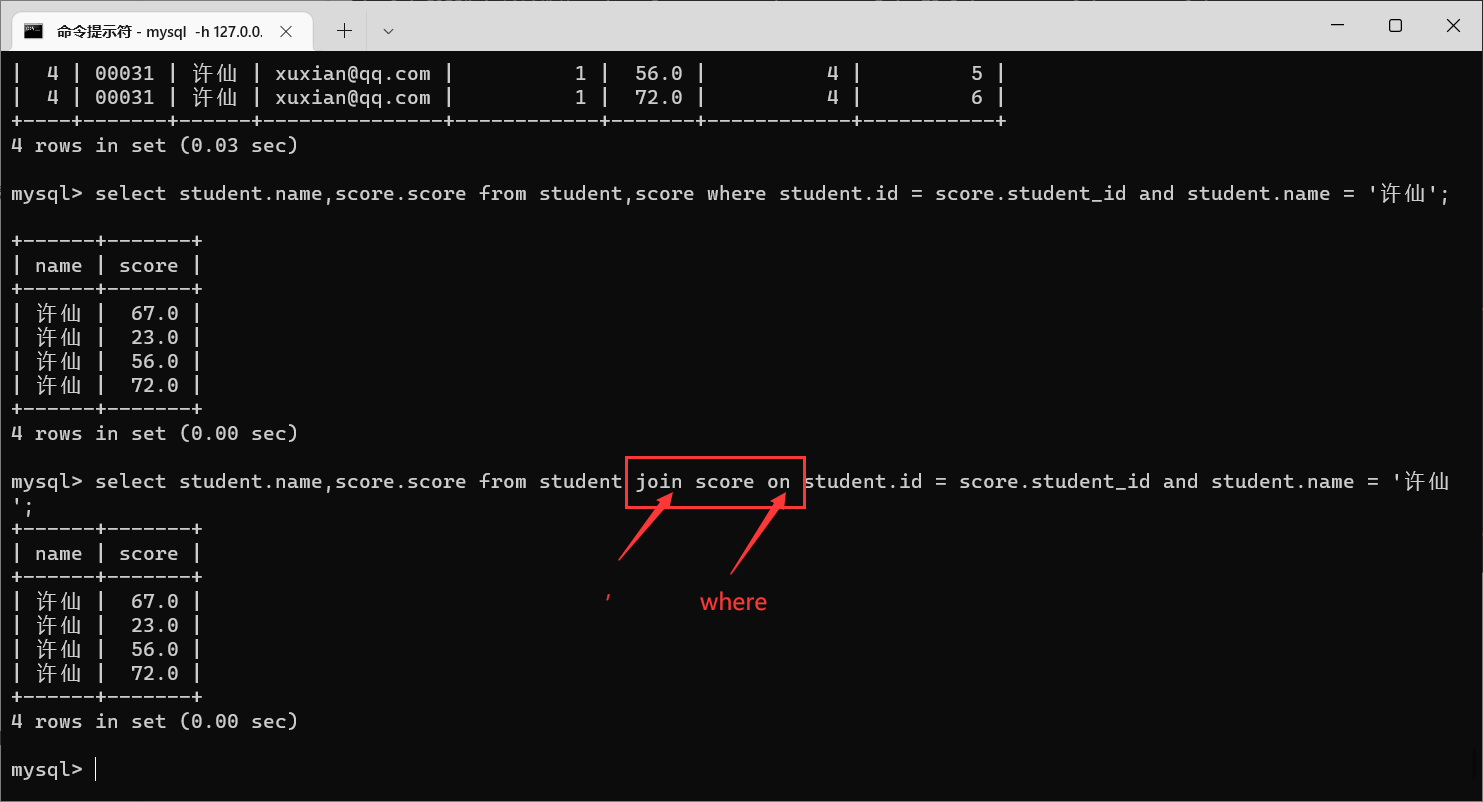
from 表1join 表2on 条件;//from 表1,表2 where 条件;
这两种写法都可以,更推荐下面那个(简单)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0M1RPH5Z-1670856561063)(https://jialebihaitao.oss-cn-beijing.aliyuncs.com/%E5%8D%9A%E5%AE%A2%E5%88%86%E9%9A%94%E7%AC%A6-%E7%AC%91%E8%84%B8.png)]](https://img-blog.csdnimg.cn/25af1f0c110b42c69a442439667b9a7c.png)
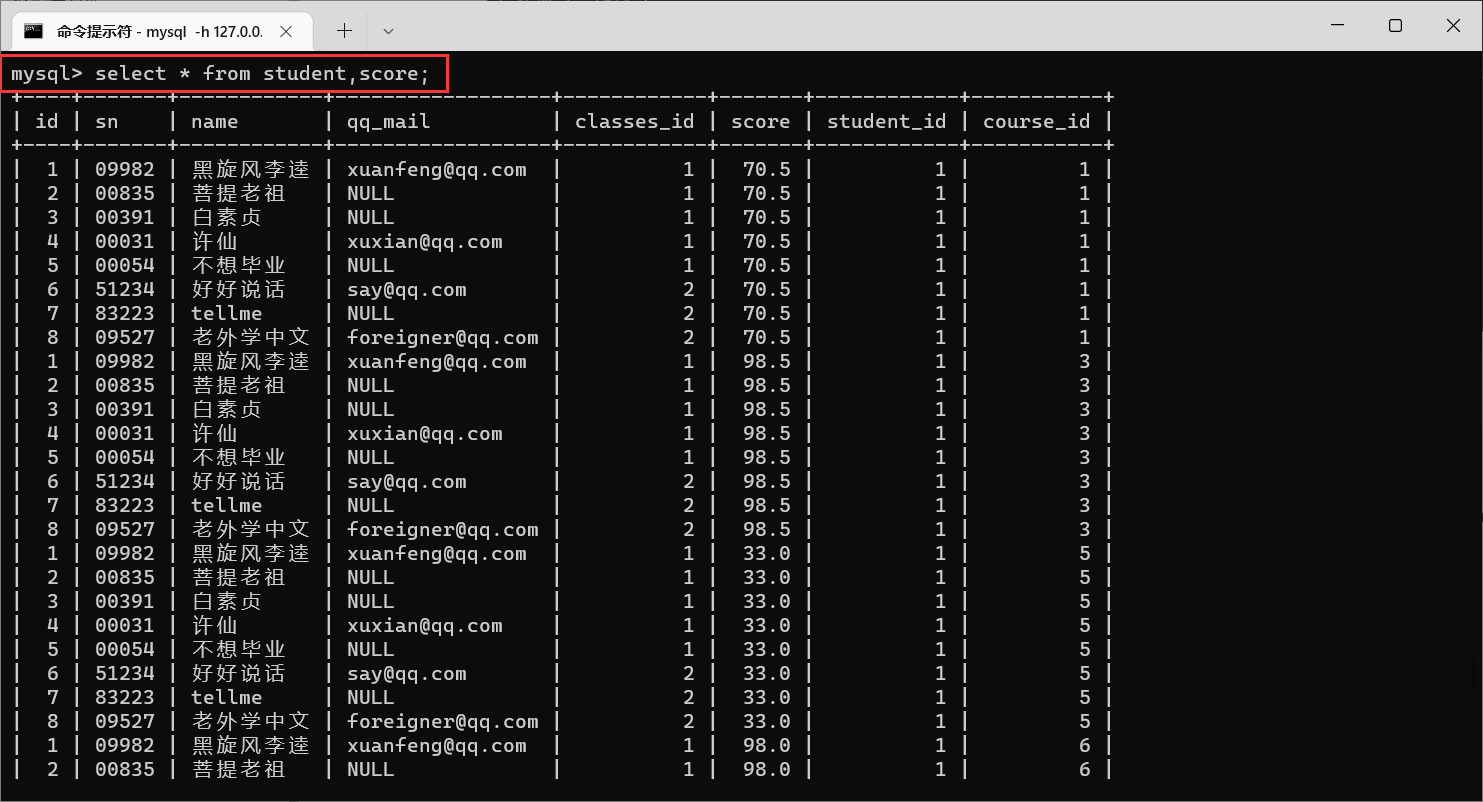
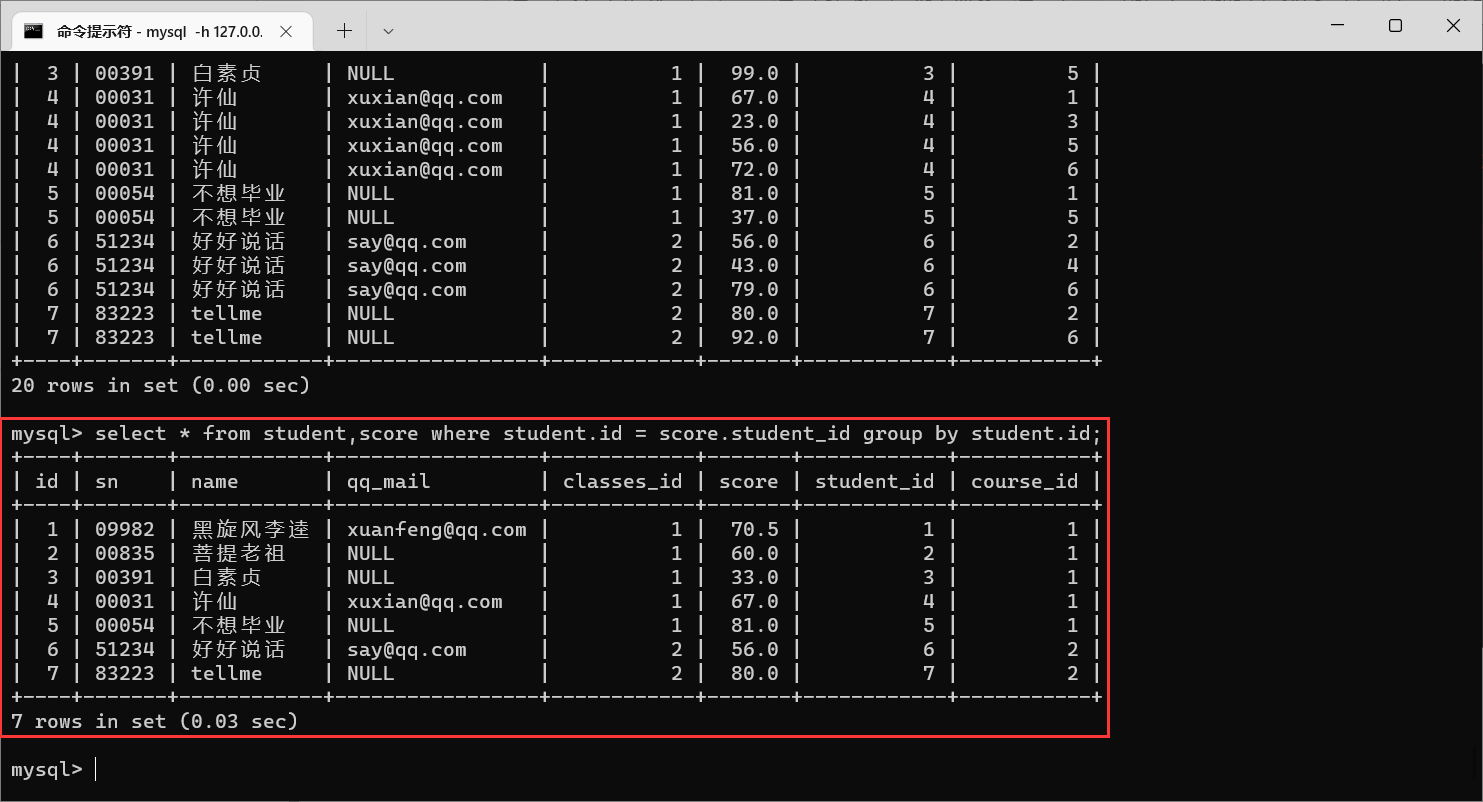
4.2.3.2 栗子2:查询所有同学的总成绩,以及同学的个人信息
这个案例要在多表查询的基础上,再加上一个聚合查询
还是先分析需要的数据是来源于哪个表:成绩来自于
score,个人信息来自于
student
足足有120条记录,那么我们再观察笛卡尔积的结果,找到相同的数据列,筛选出合法数据
这两张表里面,都存在
学生Id这一列,那么我们就需要让这两个
id匹配,不匹配的就是排列组合之后生成的无效数据
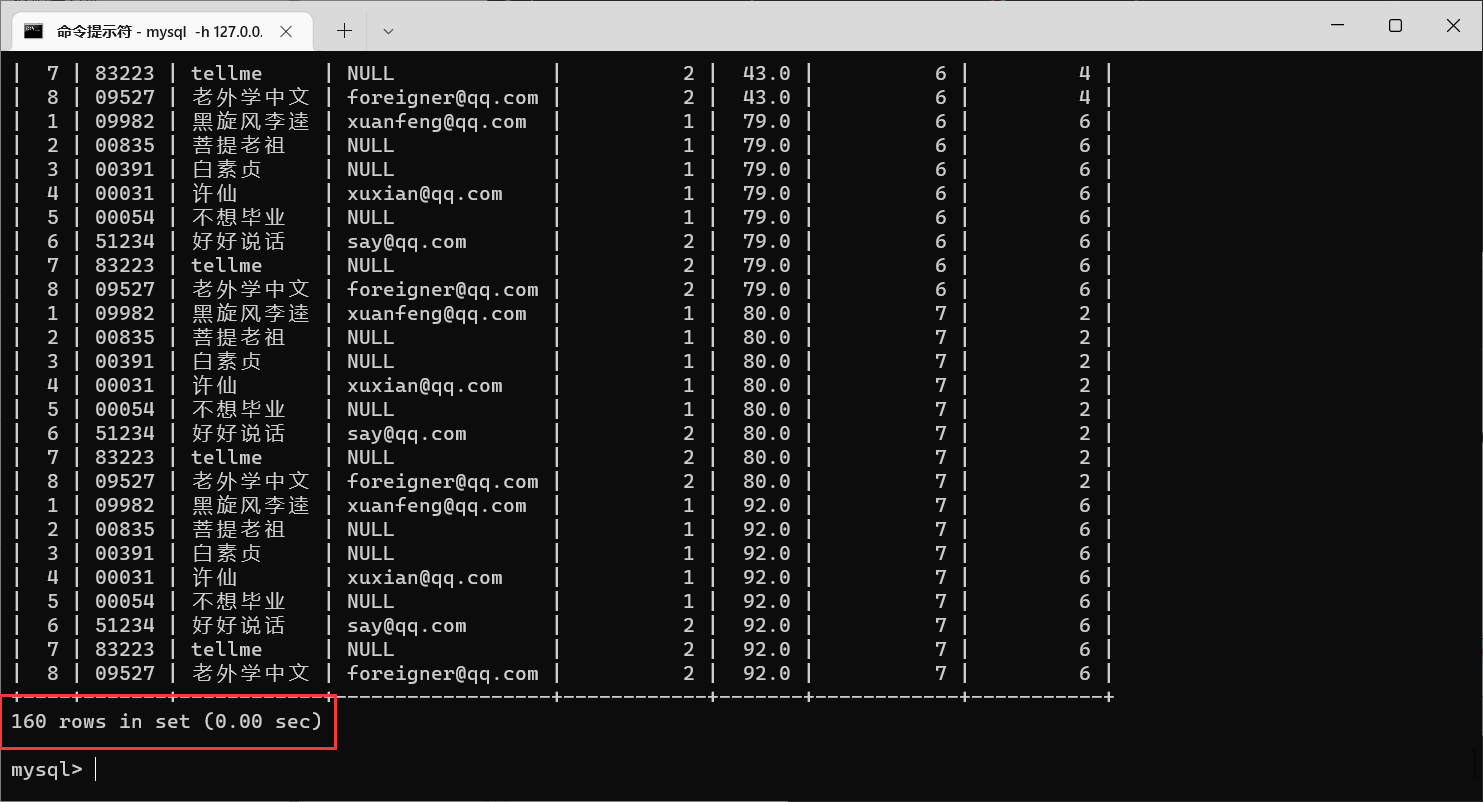
要查询同学的个人信息,我们就需要对学号进行分组
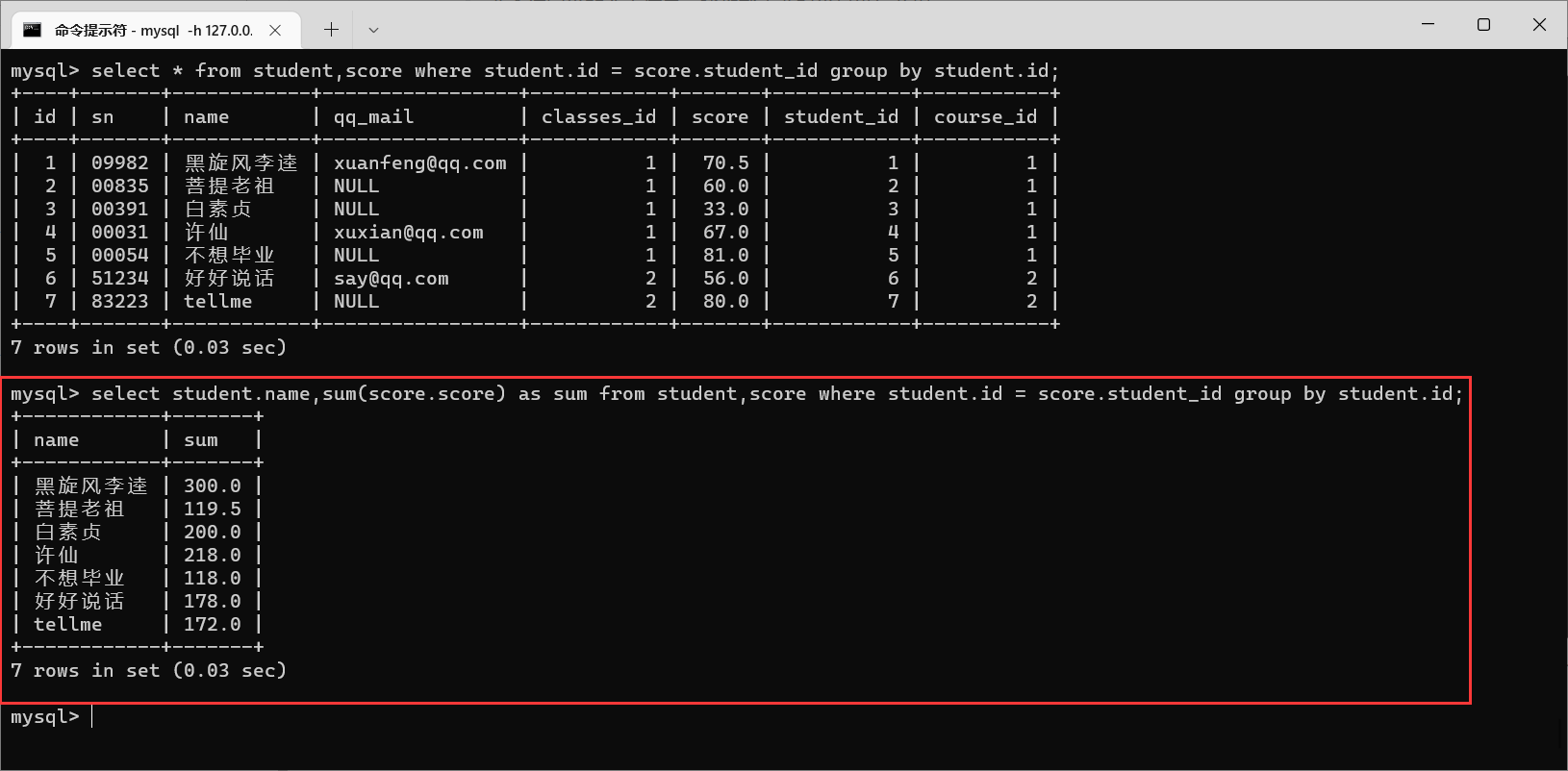
加上
group by之后,记录又变少了,每个同学只有一条数据了。而且
score列表示的也不是总成绩,而是每个分组当中的第一个记录,我们如果想要得到总成绩,就需要进行
sum操作
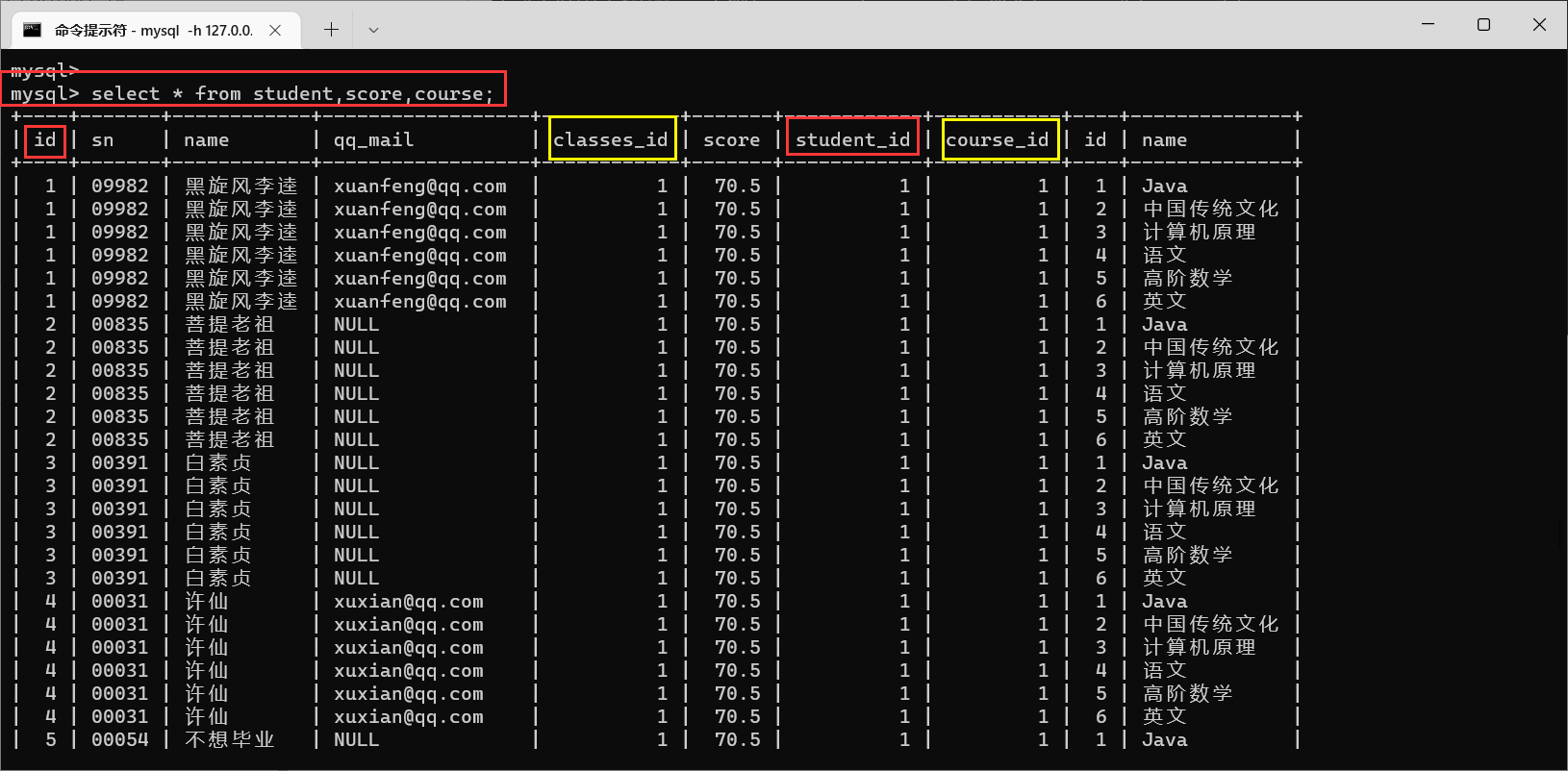
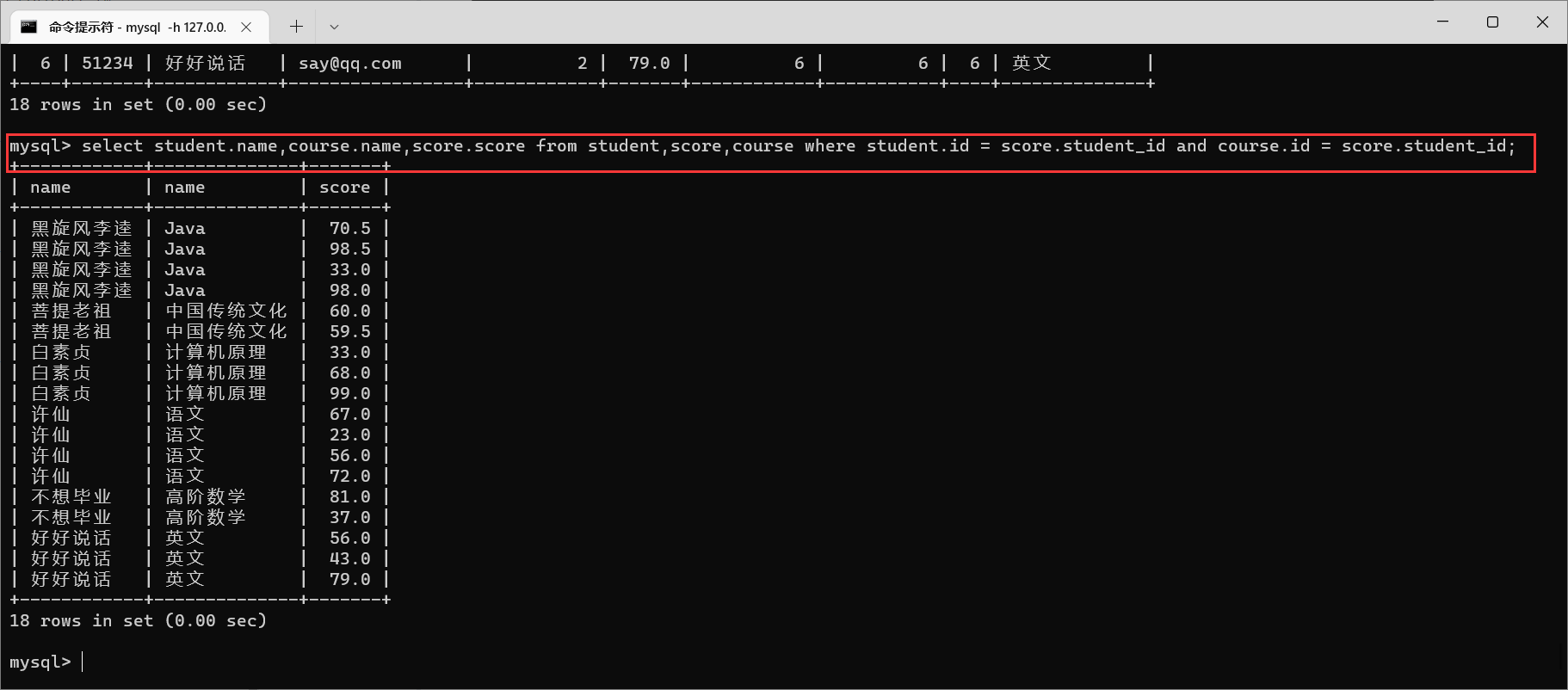
4.2.3.3 栗子3:查询所有同学的成绩,同学的个人信息以及课程信息
- 先分析需要的数据是来源于哪个表,然后进行笛卡尔积,观察笛卡尔积的结果> 成绩,同学信息,课程信息,这明显就是要三张表进行联合查询了> > > 同学名字->> >
> > student> >> > 表> > > > 成绩->> >> > score> >> > 表> > > > 课程信息->> >> > class> >> > 表- 找到相同的数据列,筛选出合法数据
当前这个表就列出来了每个同学的每个课程拿到的分数,同时带有课程名
- 根据需求,添加新的要求,让数据逐步趋近于要求
join的写法:from 表1join 表2on 条件 join 表3on 条件;日常推荐使用
where的写法,那我们学join on还有啥用?>> join on>> 既可以表示内连接,也可以表示外连接> > > 我们说的> >> > from 多个表 where> >> > 的写法,是表示内连接> > > > 虽然说我们常用内连接,但是外连接还是偶尔会碰到> > > > 内连接:> > > >> > select 列 from 表1innerjoin 表2on 条件;//inner可以省略> >> > > > 外连接:> > > > > 左外连接:> > > > > >> > > select 列 from 表1leftjoin 表2on 条件;> > >> > > > > > 右外连接:> > > > > >> > > select 列 from 表1rightjoin 表2on 条件;> > >> > > > > > 我们再来构造一些数据:> > > > > >> > > createtable student (id int,name varchar(20),classId int);createtable class (id int,name varchar(20));> > >> > > > > >> > > insertinto student values(1,'张三',1);insertinto student values(2,'李四',1);insertinto student values(3,'王五',2);insertinto student values(4,'赵六',3);insertinto class values(1,'0301');insertinto class values(2,'0302');> > >> > > > > >> > > > > > 我们看> > >
> > > student> > >> > > 表里面的赵六,他选修的3号课程在> > >> > > class> > >> > > 表里面没有,针对这样的数据,我们进行联合查询的话,可能会出一些问题> > > > > >> > > > > >
> > > > > > 那么我们使用一下左外连接:> > > > > >
> > > > > > 我们可以发现> > >
> > > inner join> > >> > > 和> > >> > > left join> > >> > > 之间的区别:> > > > > > >> > > > left join> > > >> > > > 是以左侧的表为主,会尽可能的把左侧的表的记录都列出来,大不了把后面的列填成> > > >> > > > null> > > >> > > > > > > > > > > > > > > >> > > > inner join> > > >> > > > 是要求这两个表里面同时有的数据> > > > > > > > 那么> > > >> > > > right join> > > >> > > > 就是以右侧的表为主,尽可能把右侧的记录都列出来,大不了左侧的列填成> > > >> > > > null> > > >> > > > > > > > > 那么我们再使用一下右外连接:> > > > > > > 我们再来构造一些数据:> > > > > > > >> > > > createtable student (id int,name varchar(20),classId int);createtable class (id int,name varchar(20));> > > >> > > > > > > >> > > > insertinto student values(1,'张三',1);insertinto student values(2,'李四',1);insertinto student values(3,'王五',2);insertinto class values(1,'0301');insertinto class values(2,'0302');insertinto class values(3,'0303');> > > >> > > > > > > >> > > > > > > > 我们可以发现,> > > >
> > > > class> > > >> > > > 表里面有3号0303班级,但是> > > >> > > > student> > > >> > > > 表里没有选修3号课程的学生> > > > > > > >内连接 左外连接 右外连接图示讲解
那么是否存在一种连接,能够达到这种效果呢?
可以,这叫"全外连接",但是
MySQL不支持


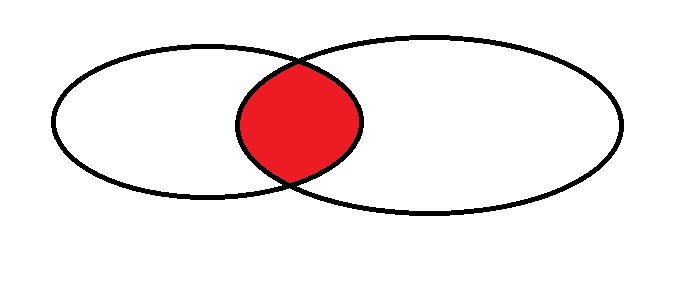
以上就是内连接的知识点
4.2.3 自连接
自连接,就是自己把自己进行笛卡尔积,属于
SQL
当中小妙招,用得不多,只能用来处理一些特殊场景的问题
自连接的本质就是把 行与行 之间的比较操作,转换成 列与列
exam_result表:
id,
name,
chinese,
math,
english如果要找
chinese > english的同学信息,非常好找
举个栗子:显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
那么在这个问题下的表,科目之间已经不是列了,而是变成行了
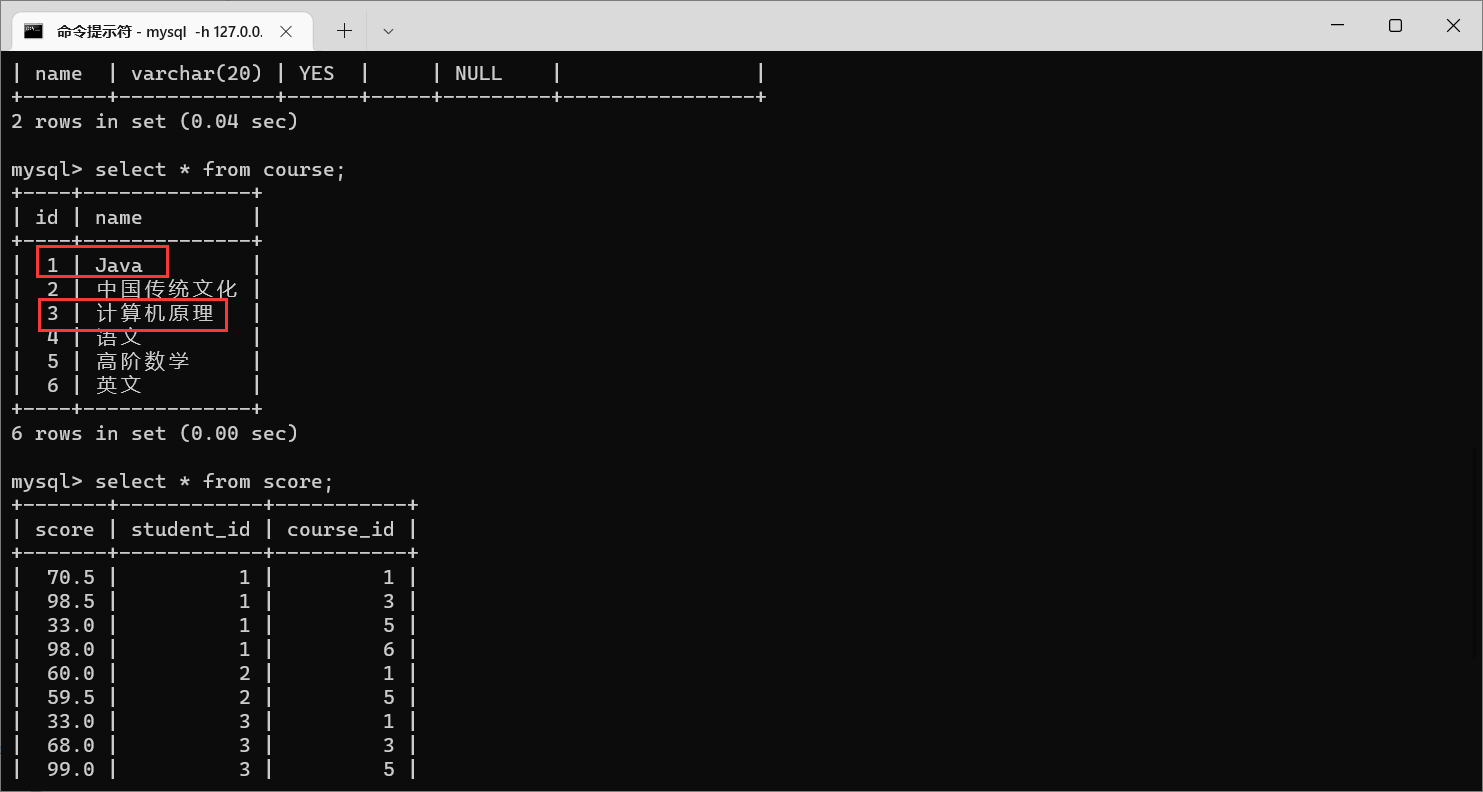
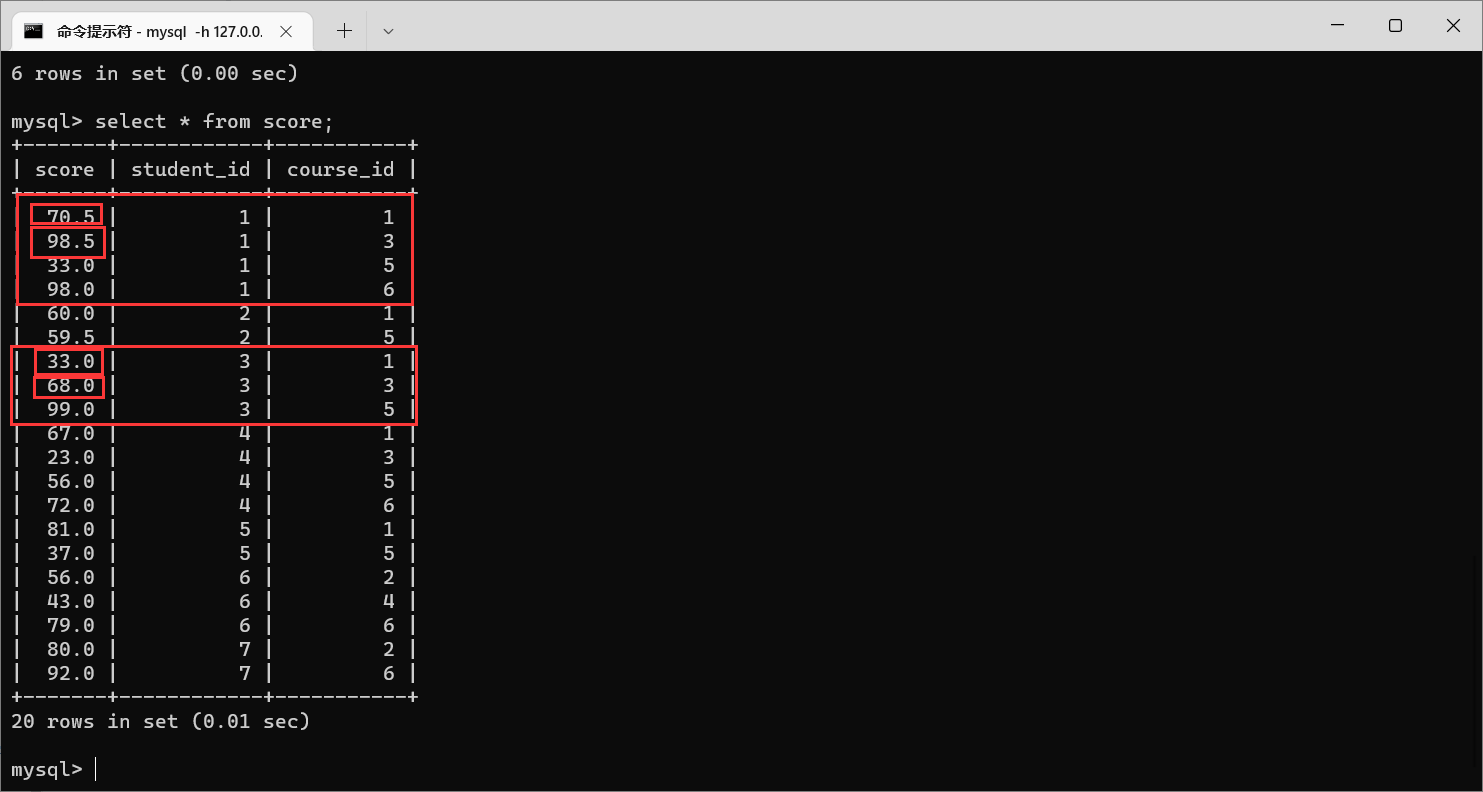
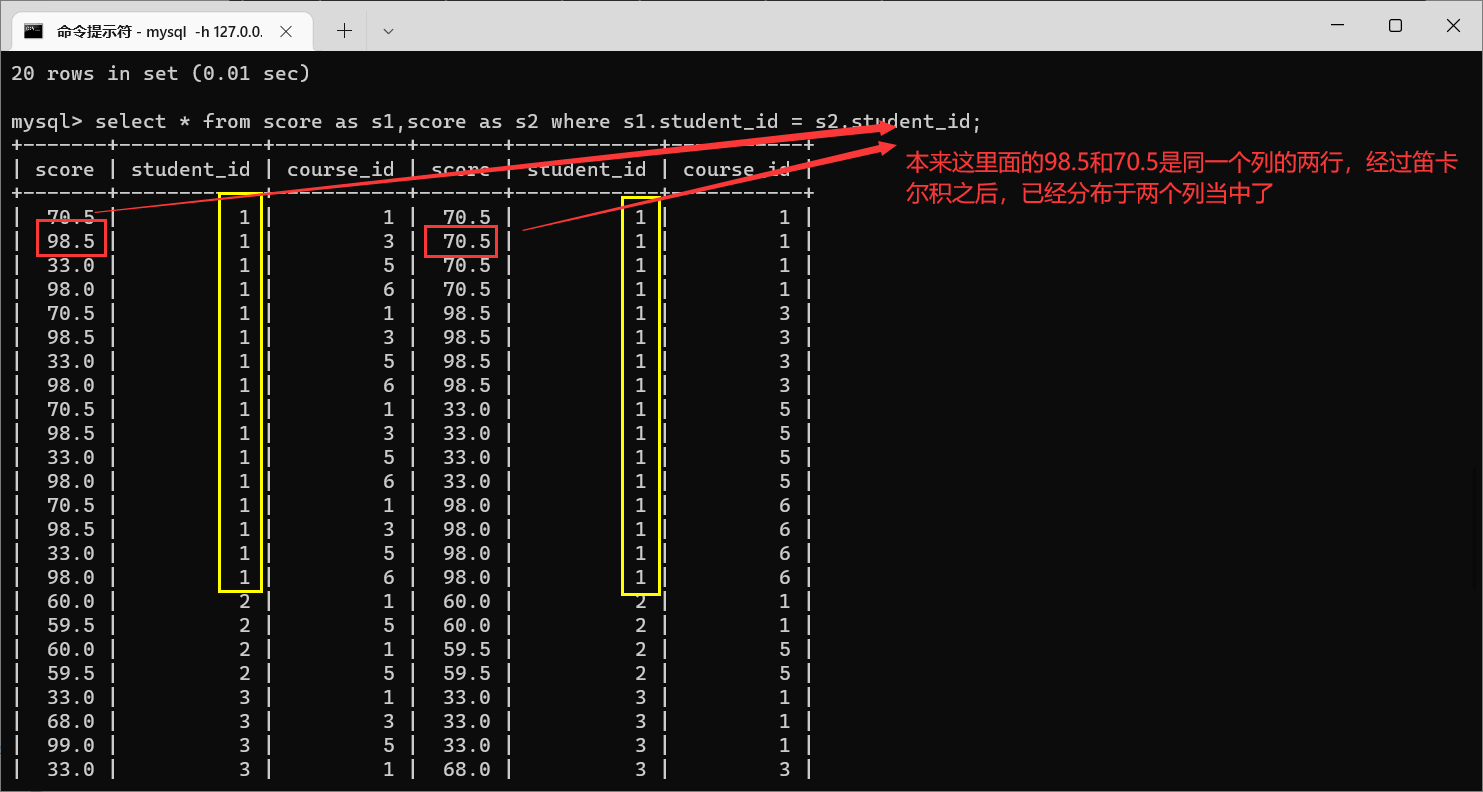
在这个问题当中,可以看到,这里面的条件是按照行的方式来排列的。那么为了解决这个问题,就需要把行转换成列,那么我们就可以使用自连接。
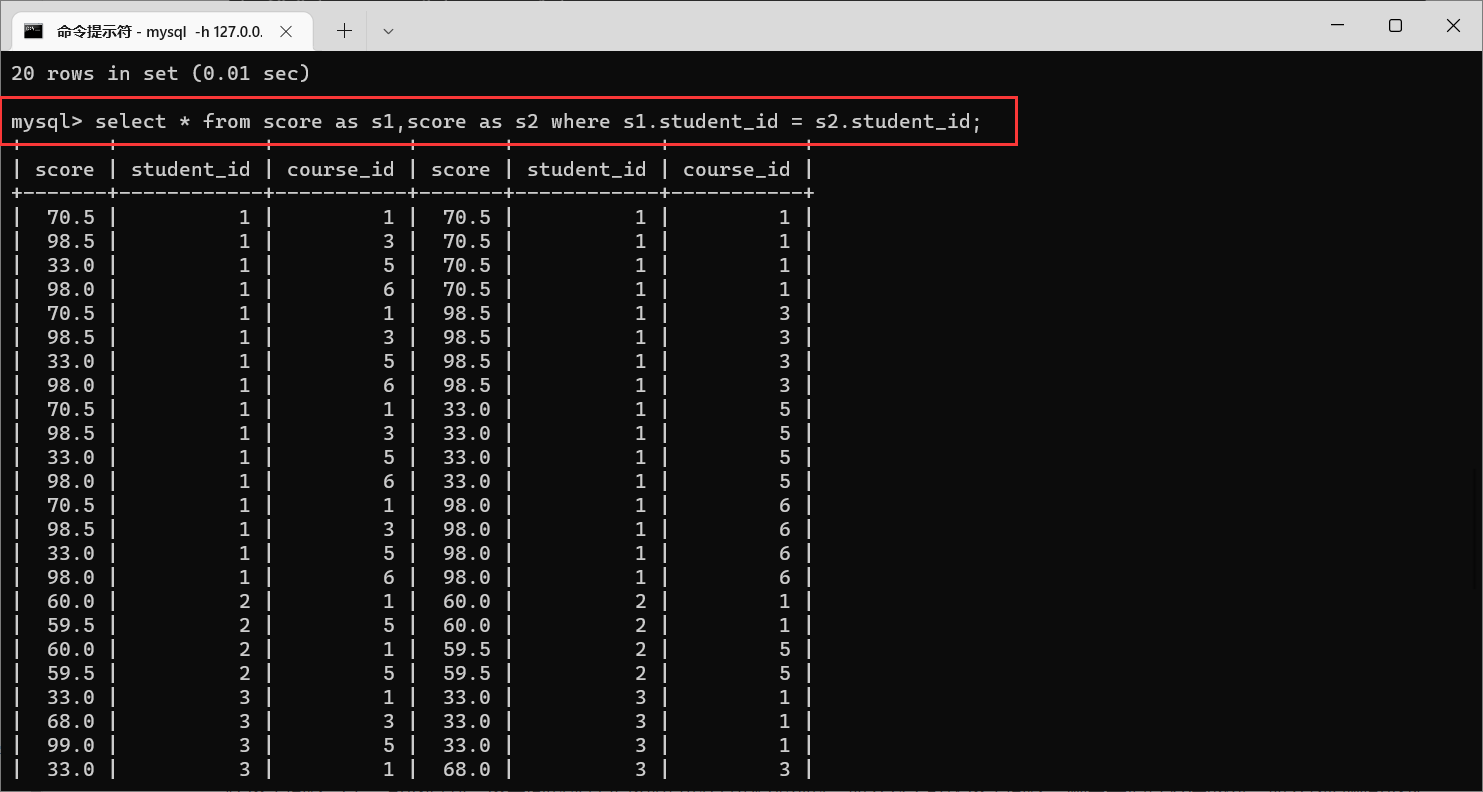
那么我们看到,这就是按照
student_id
进行连接条件之后产生的笛卡尔积
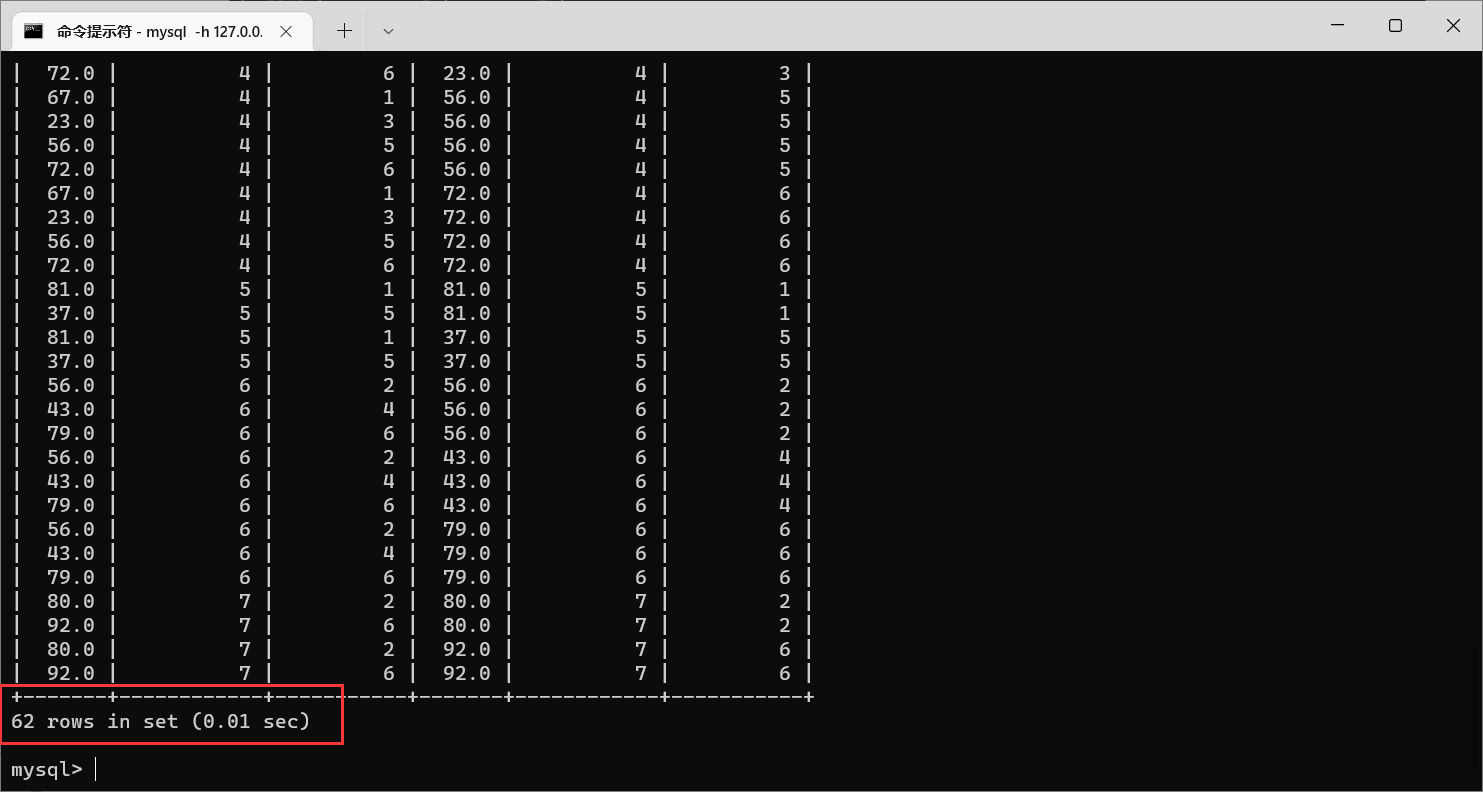
但是这样查询出来的结果,里面还是有不少的无效数据的,我们可以加上一些限制条件
比如:让
s1
的课程
id
只保留3的记录
让
s2
的课程
id
只保留1的记录
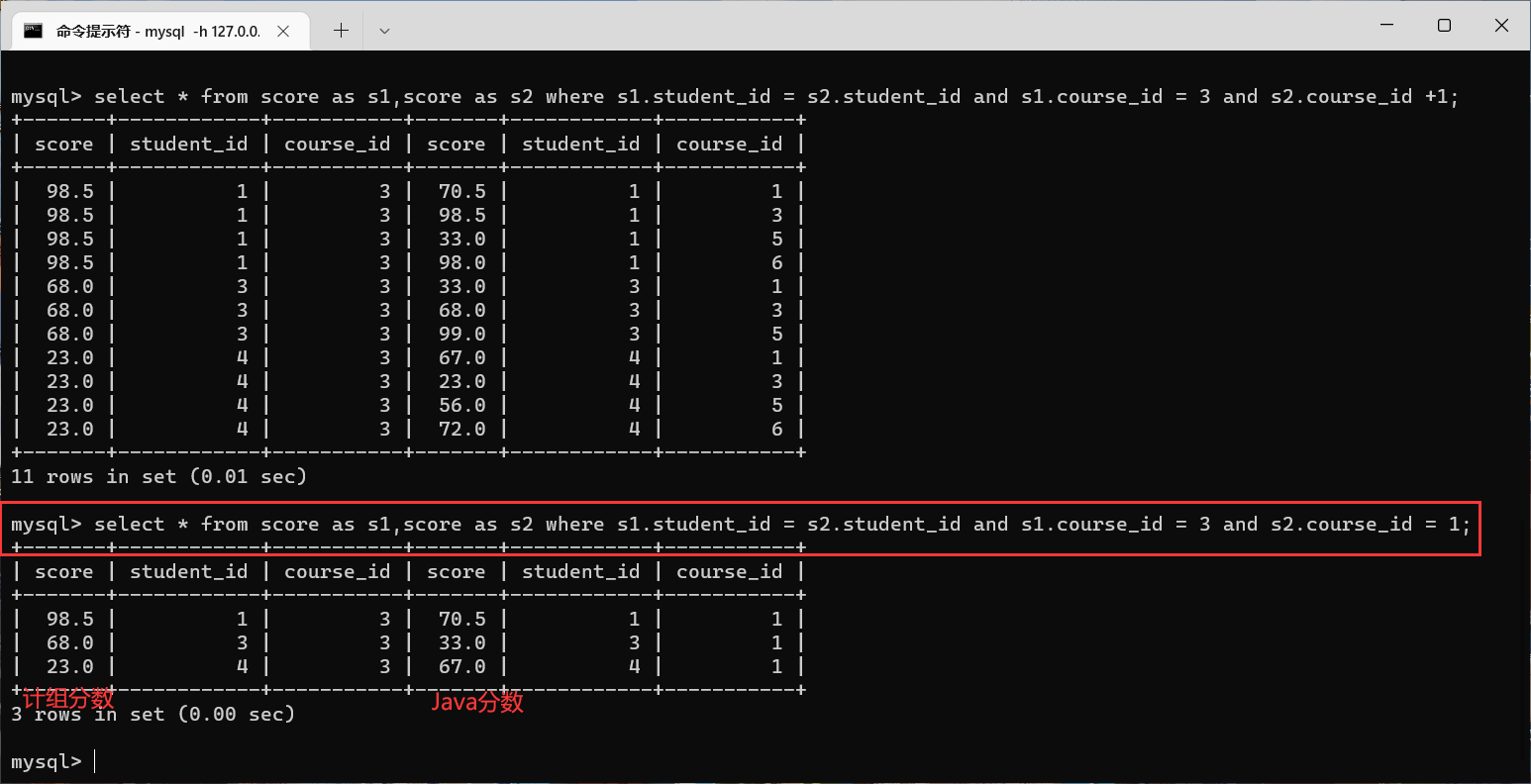
让
s1
的课程
id
只保留3的记录
让
s2
的课程
id
只保留1的记录
且
s1
课程的成绩大于
s2
课程的成绩
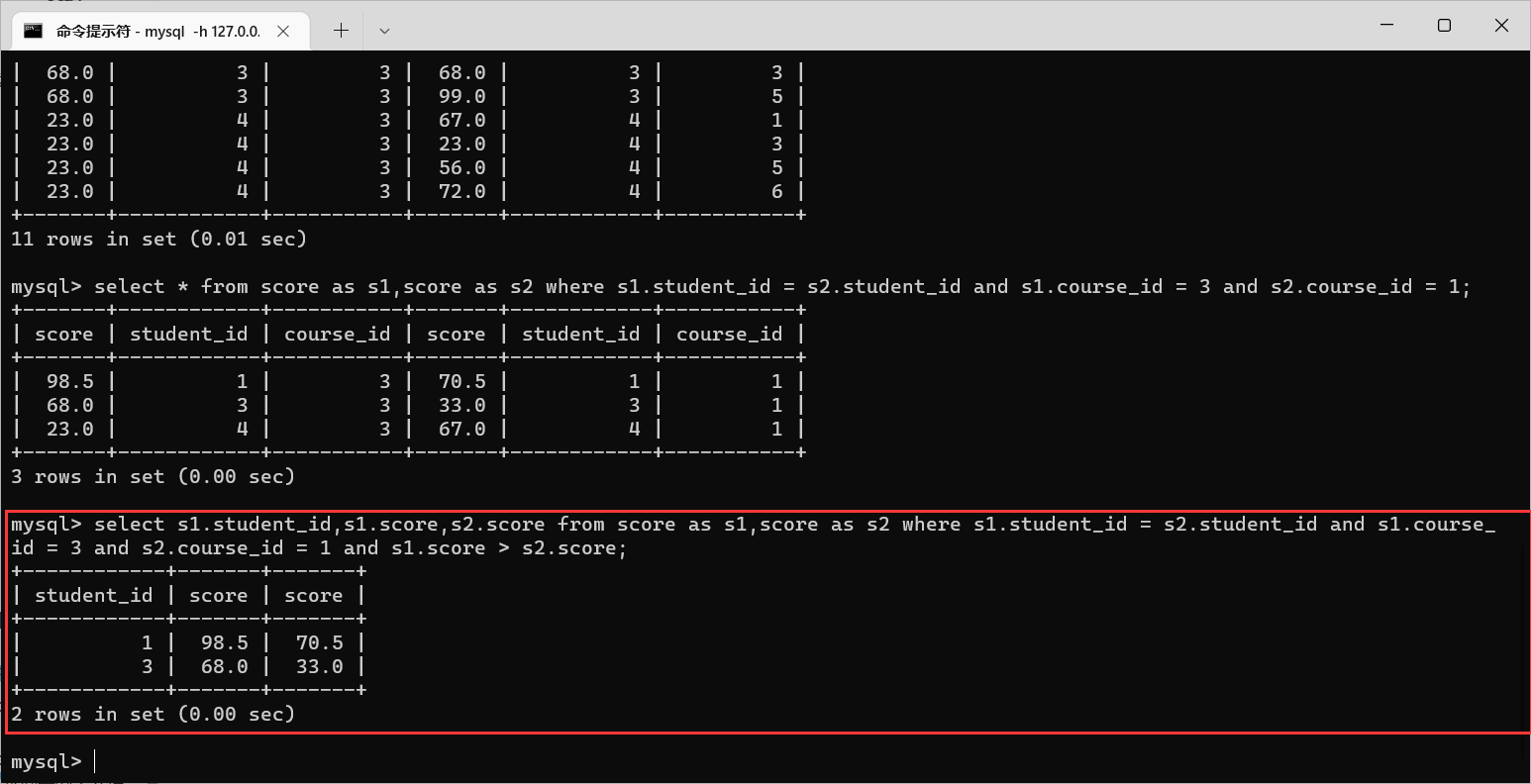
4.2.4 子查询
子查询就是套娃的过程,把多个
select
合并成一个(也就是把拆好的代码给合并成一个)
4.2.4.1 单行子查询
查询与“不想毕业” 同学的同班同学:
先查询不想毕业这个同学的班级
id,然后根据班级
id在学生表中筛选出同
id的同学
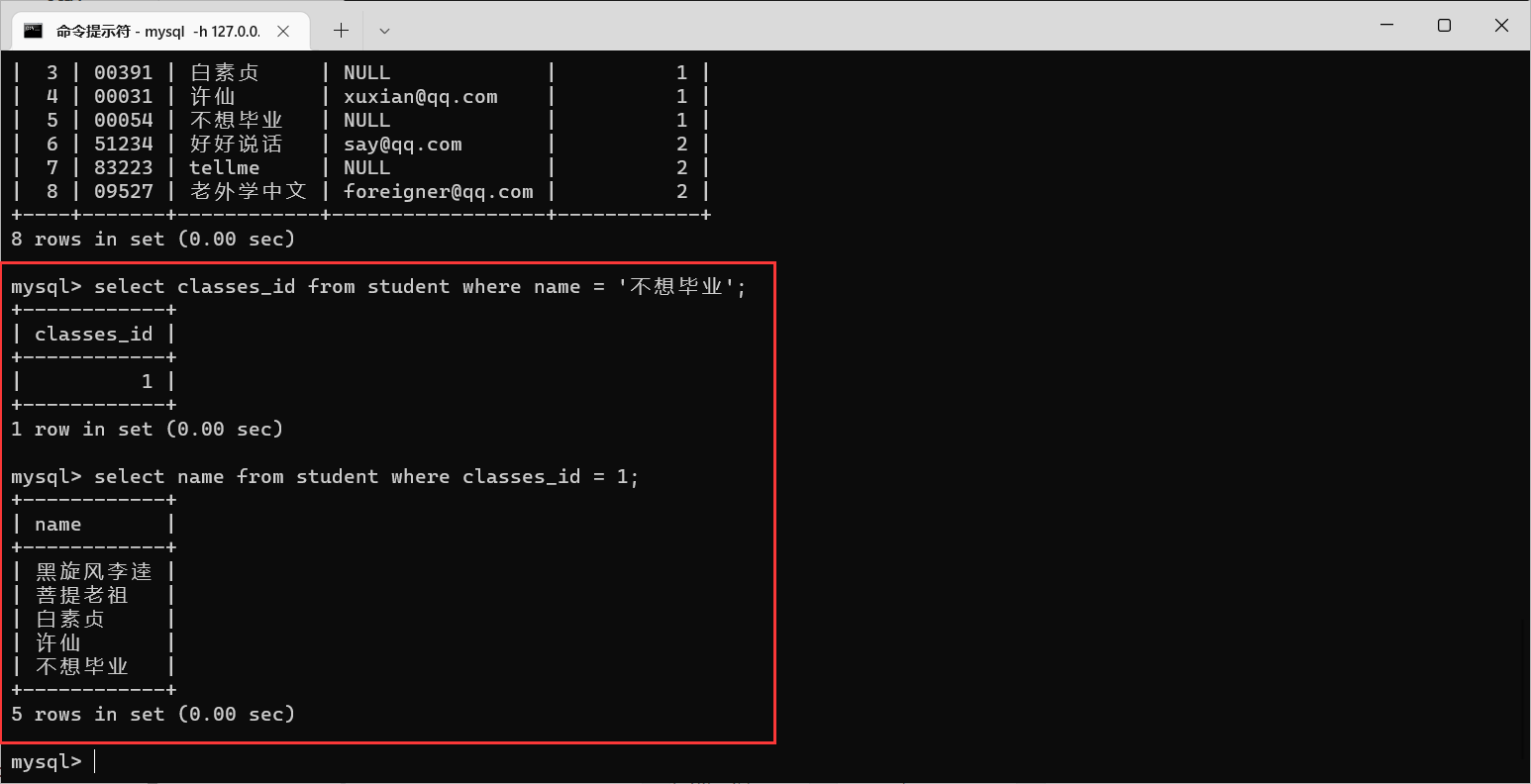
我们通过单行子查询,就是这个样子的
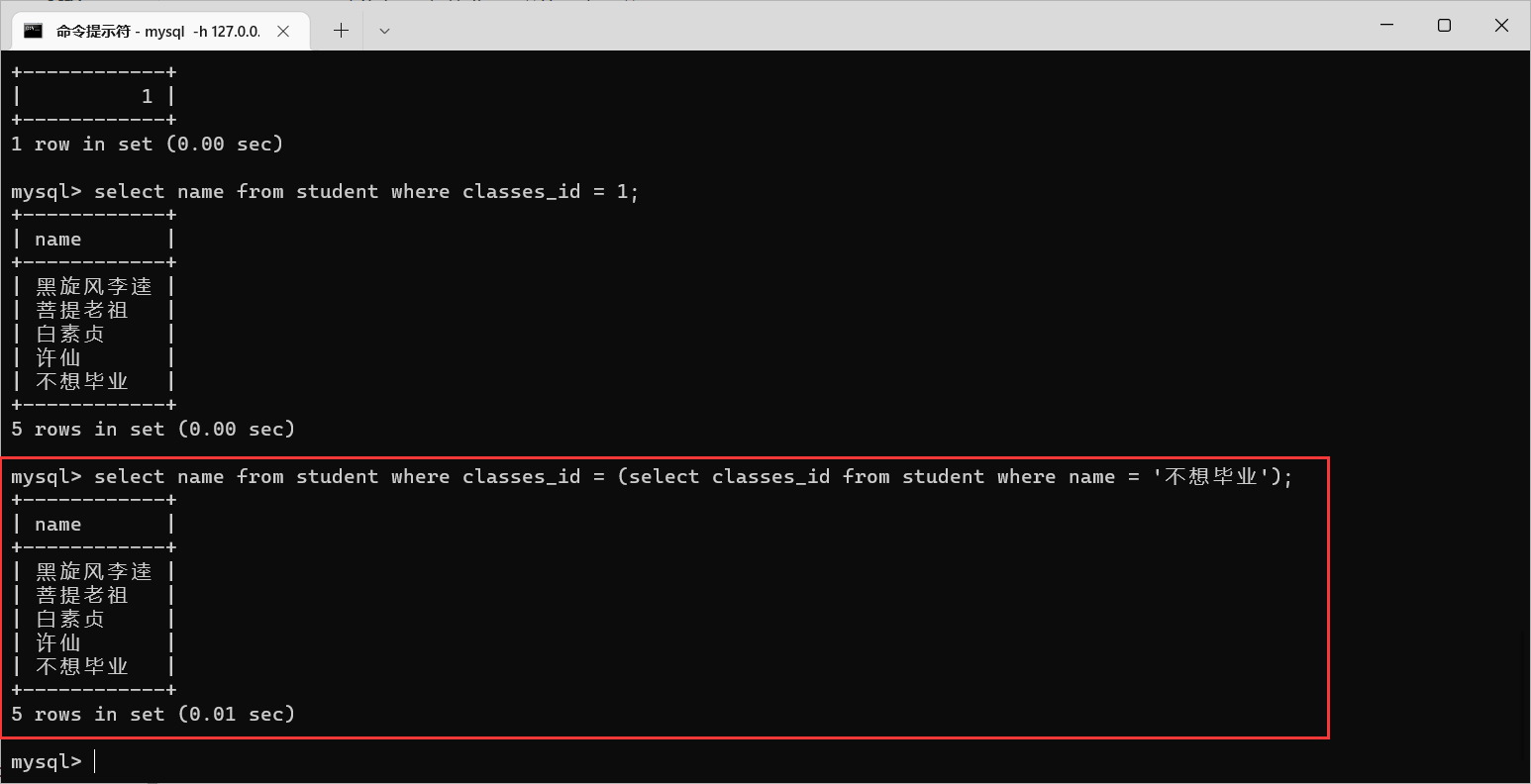
那么有时候,子查询可能会查询出多条记录,这时候就不能直接使用
=
,需要使用
in
这样的操作
4.2.4.2 多行子查询
多行子查询:返回多行记录的子查询
案例:查询“语文”或“英文”课程的成绩信息
先查询 语文 和 英文 的课程
id,再根据课程
id找到对应的成绩信息
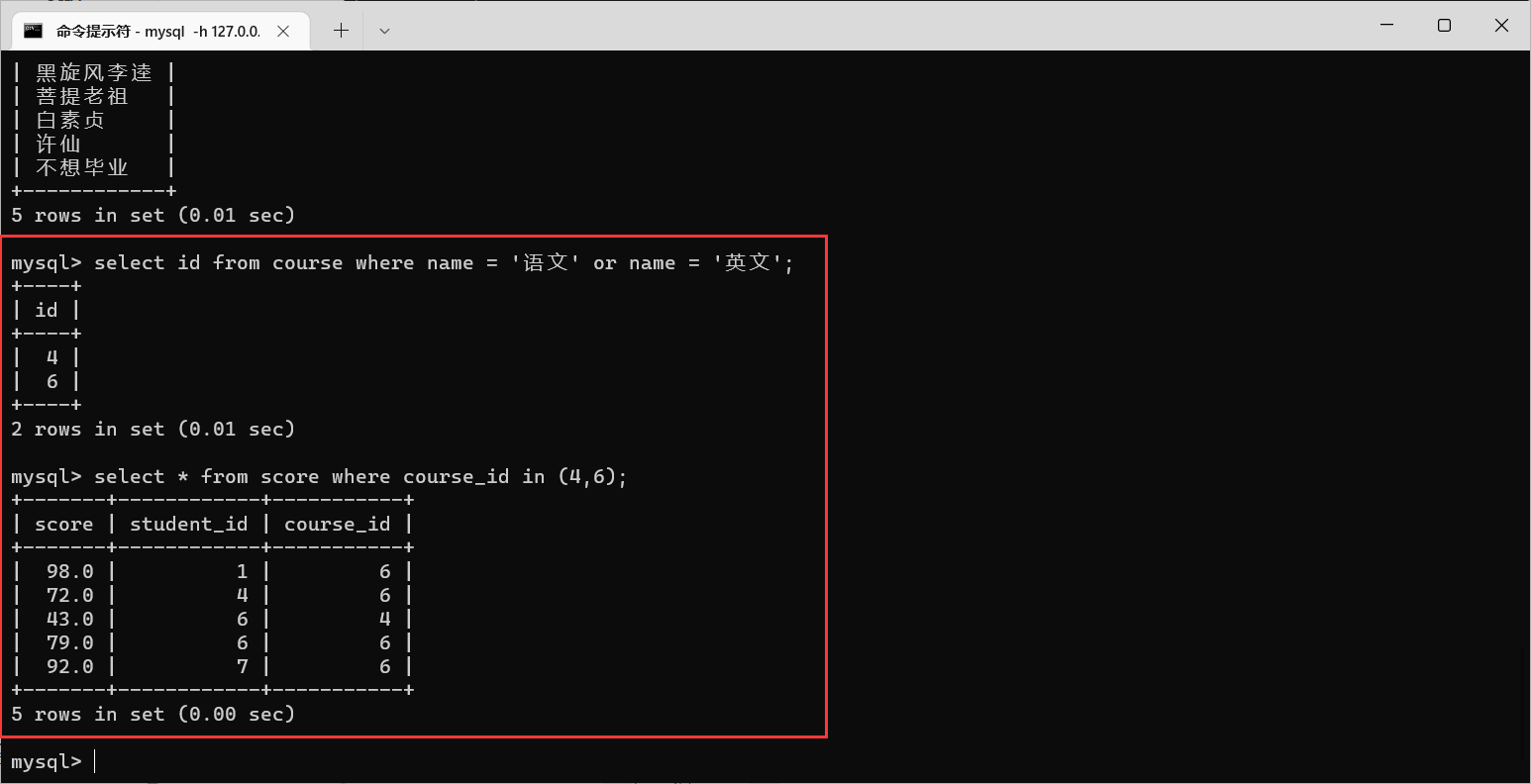
使用多行子查询就是这样
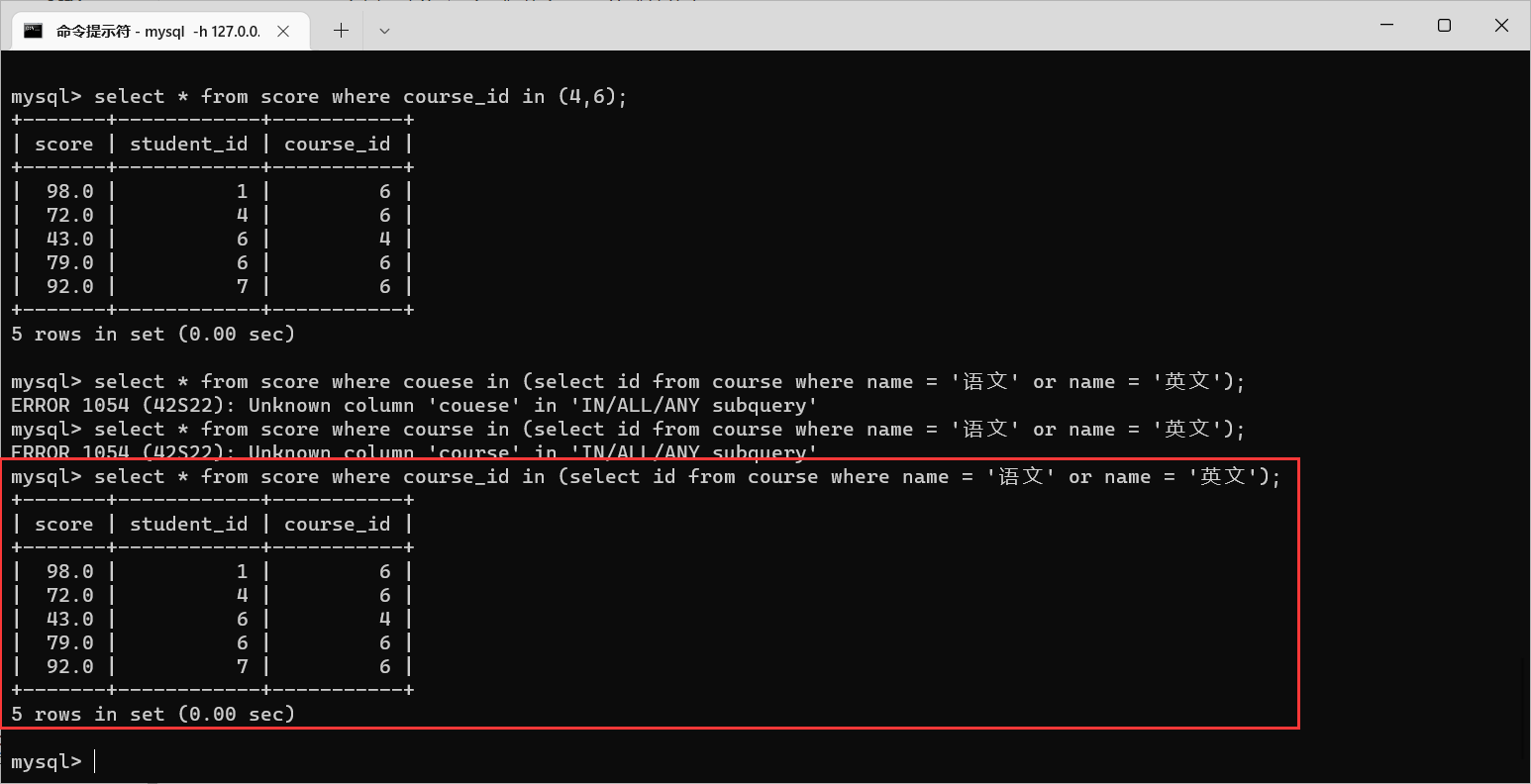
4.2.5 合并查询
合并查询就是把多个查询语句的结果给合并到一起了
使用关键字
union
、
union all
(
C
语言里面我们见过嗷),通过
union
把两个
sql
的查询结果给合并到一起了,合并的前提必须是两个
sql
查询的列必须是对应的
举个栗子:查询
id
小于3,或者名字为“英文”的课程:
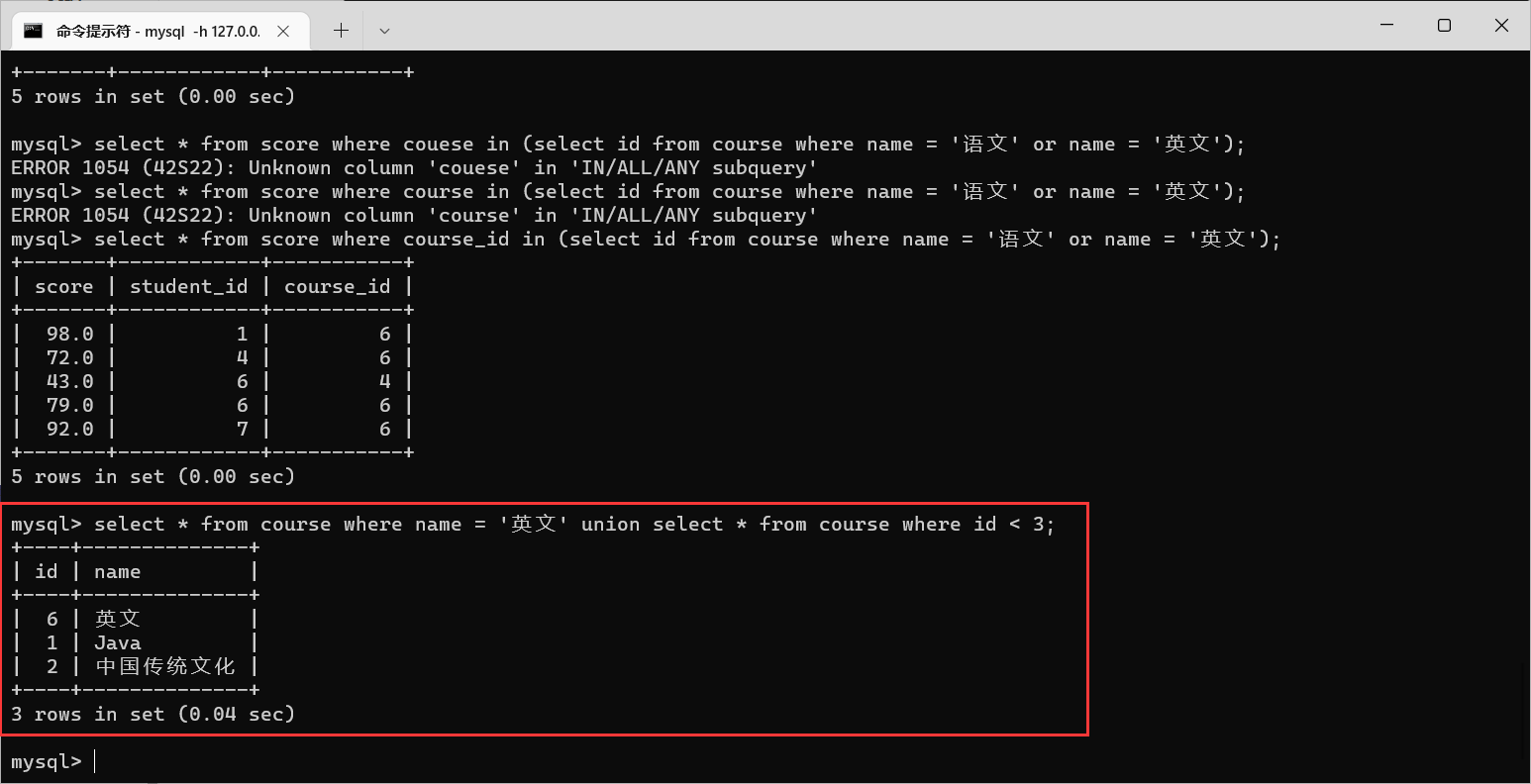
注意:
union
不一定是要针对一张表
这个写法也可以通过
or
来替换(必须是针对同一个表来指定的多个条件查询)
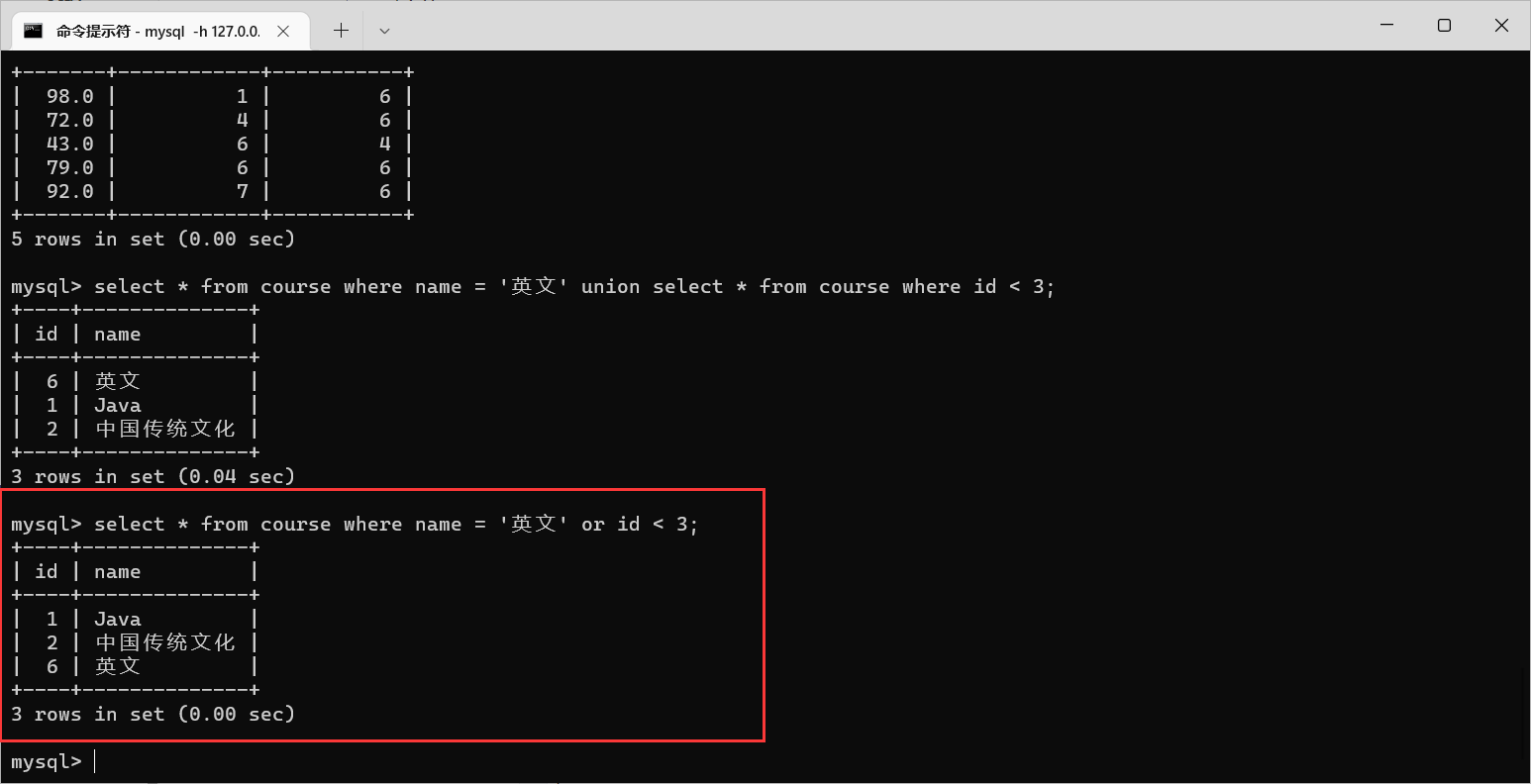
那么,
union
操作是会自动去重的,
union all
操作是不会去重的
版权归原作者 加勒比海涛 所有, 如有侵权,请联系我们删除。