
前言
在上一章《Canal实现Mysql和Redis数据同步》我们使用Canal对Mysql和Redis进行数据同步,这一章我们学习使用Canal对Mysql和ElasticSearch进行数据同步,需要具备的基础知识有:ElasticSearch ; MySql ;
工作原理分析
我不知道你是否了解Mysql主从,根据2/8原则,80%的性能问题都在读上面,当我们数据库的读并发较大的时候,我们可以使用Mysql主从来分担读的压力。它的原理是所有的写操作在主库上,读操作在从库上,当然主库也可以承担读请求,而从库的数据则通过主库复制而来,Mysql自带主从复制的功能。如下图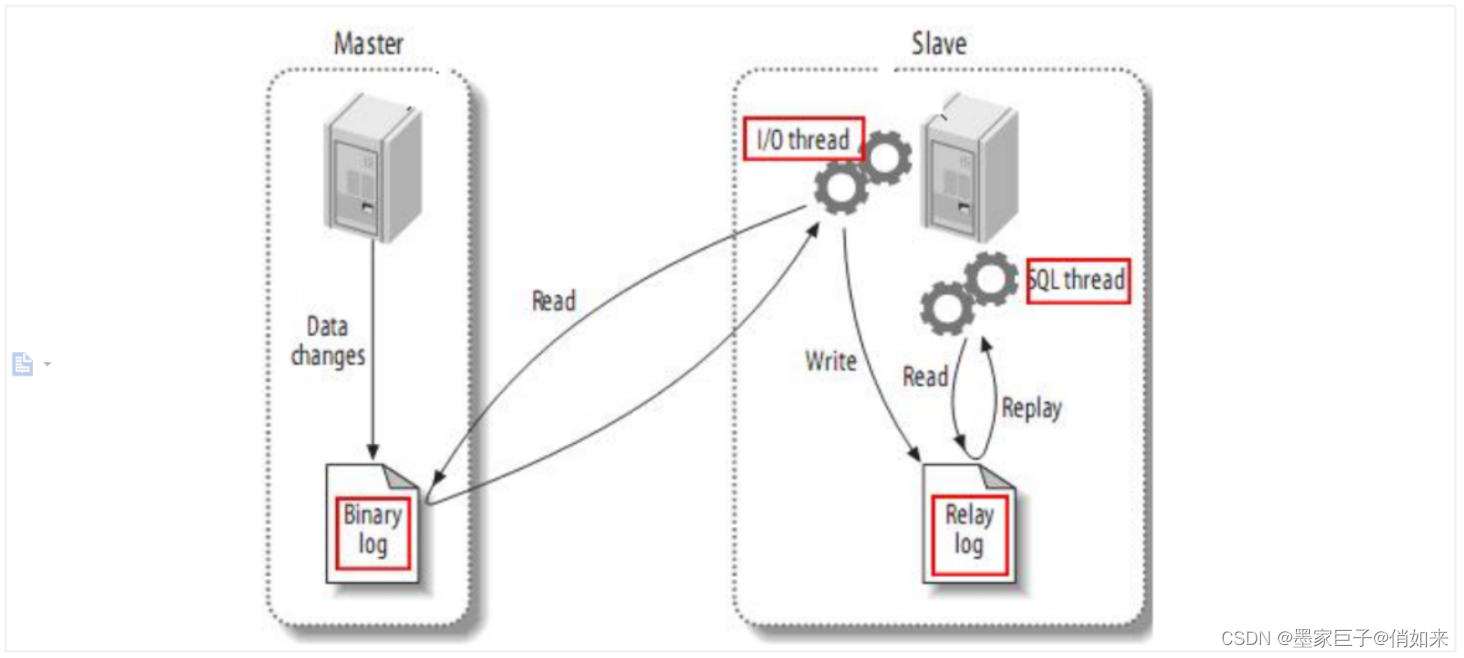
主从复制步骤:
- 将Master的binary-log日志文件打开,mysql会把所有的DDL,DML,TCL写入BinaryLog日志文件中
- Master会生成一个 log dump 线程,用来给从库的 i/o线程传binlog
- 从库的i/o线程去请求主库的binlog,并将得到的binlog日志写到中继日志(relaylog)中
- 从库的sql线程,会读取relaylog文件中的日志,并解析成具体操作,通过主从的操作一致,而达到最终数据一致
而Canal的原理就是伪装成Slave从Binlog中复制SQL语句或者数据。
Mysql和ElasticSearch数据同步方案
根据上面所说,我们就可以通过Canal去自动同步数据库的binlog数据日志文件,然后再把数据同步到ElasticSearch。Canal支持把数据同步到的组件有 : mysql、Kafka、ElasticSearch、Hbase、RocketMQ等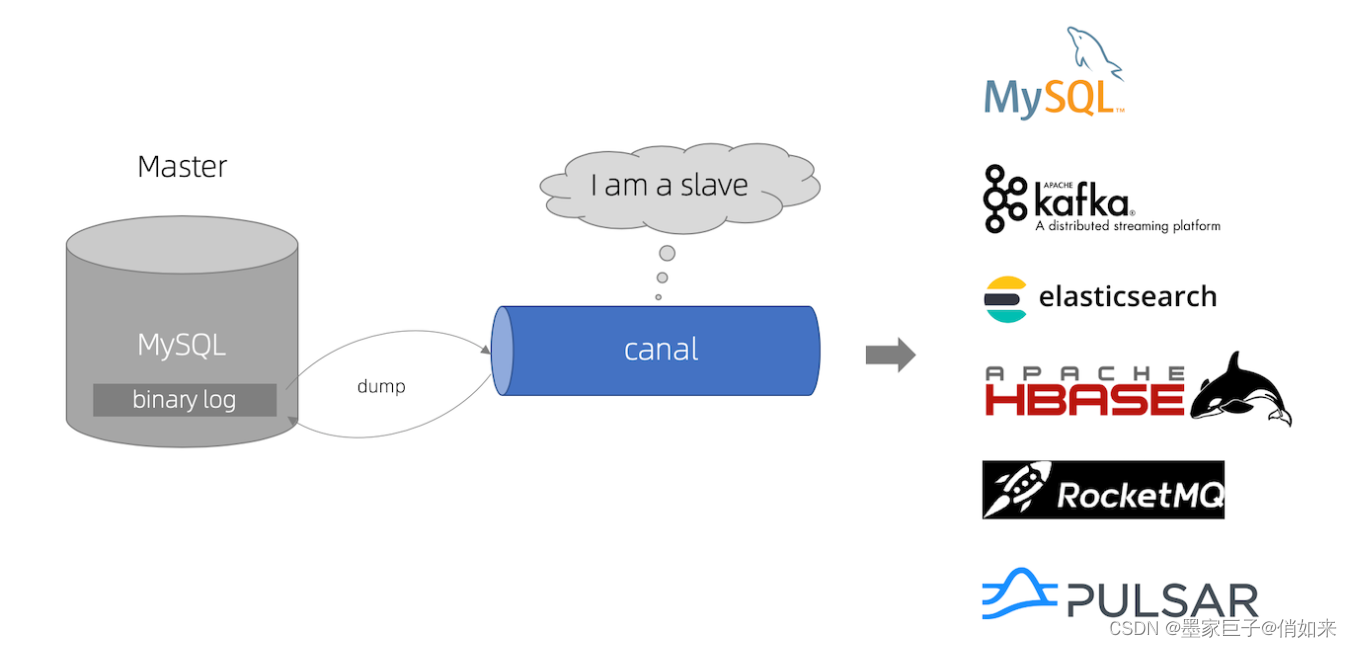
和上一章节讲的Redis的同步流程不一样,因为Canal可以直接同步到ElasticSearch,只不过需要安装CanalAdapter来实现,流程如下
开启Mysql bin-log日志
找到Mysql安装目录中的my.ini 配置文件,我以mysql 5.5为例,在 mysqld 下做如下配置
[mysqld]
#开启bInlog
log-bin=mysql-bin
#给mysql服务指定一个唯一的ID
server-id=1
#以数据的方式写binlog日志 :statement 是记录SQL,row是记录数据
binlog-format=ROW
#同步的数据库名
binlog-do-db=canaldb
#忽略的表
binlog-ignore-db=mysql
# 启动mysql时不启动grant-tables授权表
skip-grant-tables
修改好之后,重启Mysql服务。注意:我这里指定了需要同步的数据库为canaldb,所以需要创建一个数据库,同时创建了一个employee表作为演示
然后创建一个用户提供给canal来链接Mysql做数据同步
flush privileges;#创建用户cannalCREATEUSER canal IDENTIFIED BY'canal';#把所有权限赋予canal,密码也是canalGRANTALLPRIVILEGESON canaldb.userTO'canal'@'%' identified by "canal";
//GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' identified by"canal";#刷新权限
flush privileges;
到这,Mysql部分就搞定了
安装Canal
去官网下载 Canal : https://github.com/alibaba/canal/releases ,我使用的是canal.deployer-1.1.5.tar.gz版本
下载好之后解压,目录结构如下
接下来修改instance 配置文件 : conf/example/instance.properties
# 按需修改成自己的数据库信息#################################################...#我的端口是3307
canal.instance.master.address=192.168.1.20:3307# username/password,数据库的用户名和密码...#刚才开通的mysql的账户密码
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
...################################################## mq config 数据同步到MQ中的topic名字
canal.mq.topic=example
# 针对库名或者表名发送动态topic#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*
canal.mq.partition=0# hash partition config#canal.mq.partitionsNum=3#库名.表名: 唯一主键,多个表之间用逗号分隔#canal.mq.partitionHash=mytest.person:id,mytest.role:id
这里注意如下几个东西,其他的不用管
- master.address :Mysql的地址,我的端口是3307,默认是3306
- dbUsername :上面开通的Mysql用户
- dbPassword : 密码
- canal.mq.topic=example : 数据同步到MQ中的topic名字
接着修改canal 配置文件 conf/canal.properties
# ...# 可选项: tcp(默认), kafka, RocketMQ# 这里使用tcp
canal.serverMode = tcp
# ...########################################################### RocketMQ ###############################################################
rocketmq.producer.group= test
rocketmq.enable.message.trace =false
rocketmq.customized.trace.topic =
rocketmq.namespace =# RocketMQ的地址
rocketmq.namesrv.addr =127.0.0.1:9876
rocketmq.retry.times.when.send.failed =0
rocketmq.vip.channel.enabled =false
rocketmq.tag =
这里需要注意:canal.serverMode = tcp : 注意这里是tcp,tcp指的是直接同步到客户端。和上一章节Redis同步还是有点区别,上一章节我们是同步到RocketMQ
配置好之后,找到 canal 安装目录下 bin目录下的
bin/startup.bat
双击启动,linux上启动:bin/startup.sh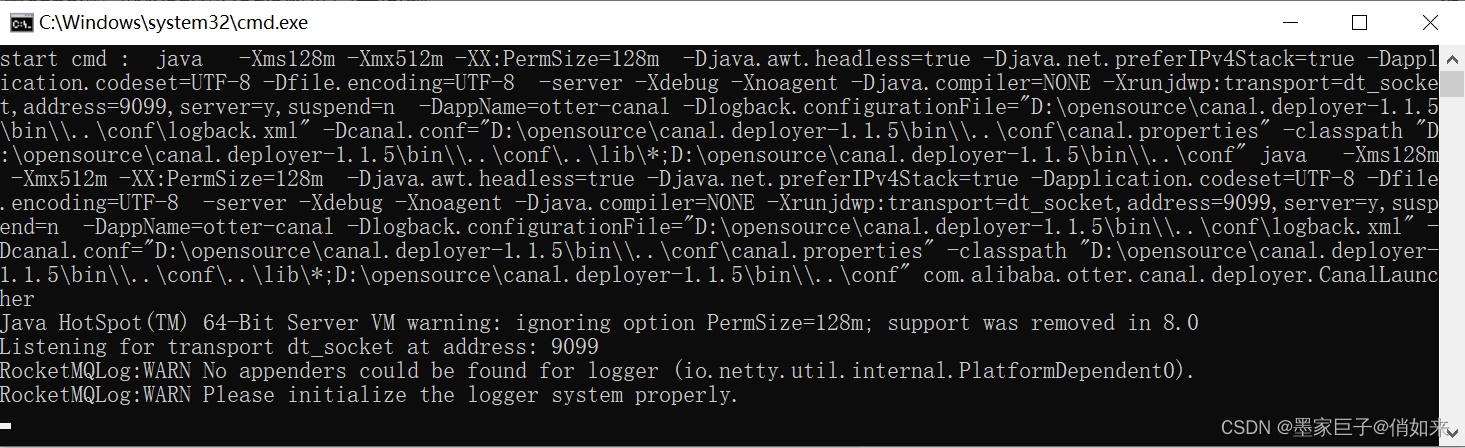
安装 canal-adapter
去官网下载 Canal-adapter : https://github.com/alibaba/canal/releases ,我使用的是canal.adapter-1.1.5.tar.gz 版本
下载好之后解压,目录如下
进入到config目录,修改 config/application.yml 文件
修改内容如下
...省略...canal.conf:mode: tcp #tcp kafka rocketMQ rabbitMQ...省略...consumerProperties:# canal tcp consumercanal.tcp.server.host: 127.0.0.1:11111 #canal的地址...省略...srcDataSources:defaultDS:#同步的数据库,账号,密码,修改为自己的数据库信息url: jdbc:mysql://127.0.0.1:3307/canaldb?useUnicode=true
username: root
password: admin
canalAdapters:#adapter配置-instance: example # canal instance Name or mq topic namegroups:-groupId: g1
outerAdapters:-name: logger
-name: es6 #es配置,这里使用9200通信 也就是rest模式hosts:"http://127.0.0.1:9200"properties:mode: rest # or rest# # security.auth: test:123456 # only used for rest modecluster.name: elasticsearch #集群名字
上面把要修改的内容展示出来了,其他的不用管,具体要修改的如下
- canal.tcp.server.host: 127.0.0.1:11111 :这个需要指向canal地址
- srcDataSources.defaultDS : 这个跟的是要同步的数据库,包括用户名密码要修改为自己的
- outerAdapters :代表数据向哪儿输出,我们配置的是ES6,- name :es6因为我使用的是es6 , hosts使用的是es的9200端口,mode使用rest方式。也可以使用9300,transport模式
然后进入es6目录,基于mytest_user.yml拷贝重命名一个employee.yml(对应要同步的数据库表),然后删除其他的yml文件

employee.yml内容如下
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:_index: employee #索引库名字_type: _doc #es的type_id: _id #id作为文档IDupsert:true#pk: id # 如果不需要_id, 则需要指定一个属性为主键属性#sql映射 ,把列名和es进行一一映射 _id 会作为文档IDsql:"select id _id,username from employee"# objFields:# _labels: array:;etlCondition:"where a.c_time>={}"commitBatch:3000
几个需要修改的参数
- _index: employee #索引库名字
- _type: _doc #es的type
- _id: _id #id作为文档ID
- sql : sql映射 ,根据查询的列名和es的field进行一一映射 , 支持join连表查询
到这Canal的配置完成了,启动 canal-adapapter :
bin/startup.bat
但是我在启动的时候出现了一个问题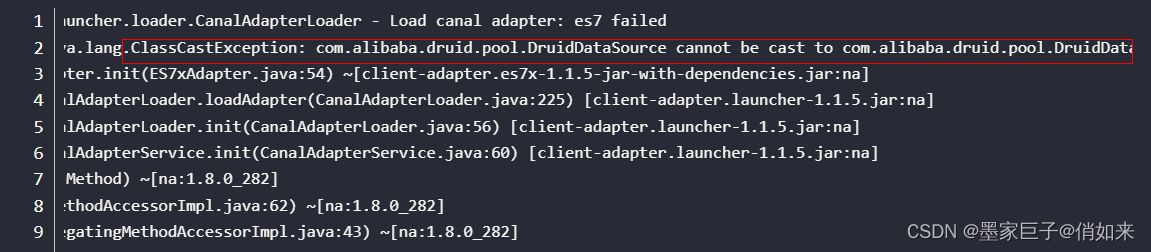
这个是因为Canal中的druid包和 canal.adapter\plugin\client-adapter.es6x-1.1.5-jar-with-dependencies.jar 包中的druid冲突了,我的做法是这样的
1.下载canal源码:https://github.com/alibaba/canal/tree/canal-1.1.5
2.使用IDEA打开项目,找到 escore模块,修改pom.xml中druid增加scope如下
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><scope>provided</scope></dependency>
3.使用mvn install 重新打包 es6x 模块,然后再target中得到 client-adapter.es6x-1.1.5-jar-with-dependencies.jar
4.把 client-adapter.es6x-1.1.5-jar-with-dependencies.jar 拷贝到canal-adapter安装目录的plugin目录中,覆盖原本的client-adapter.es6x-1.1.5-jar-with-dependencies.jar。
下面我提供一份打包好的 client-adapter.es6x-1.1.5-jar-with-dependencies.jar ,您直接下载即可
5.依次启动canal ,canal-adpater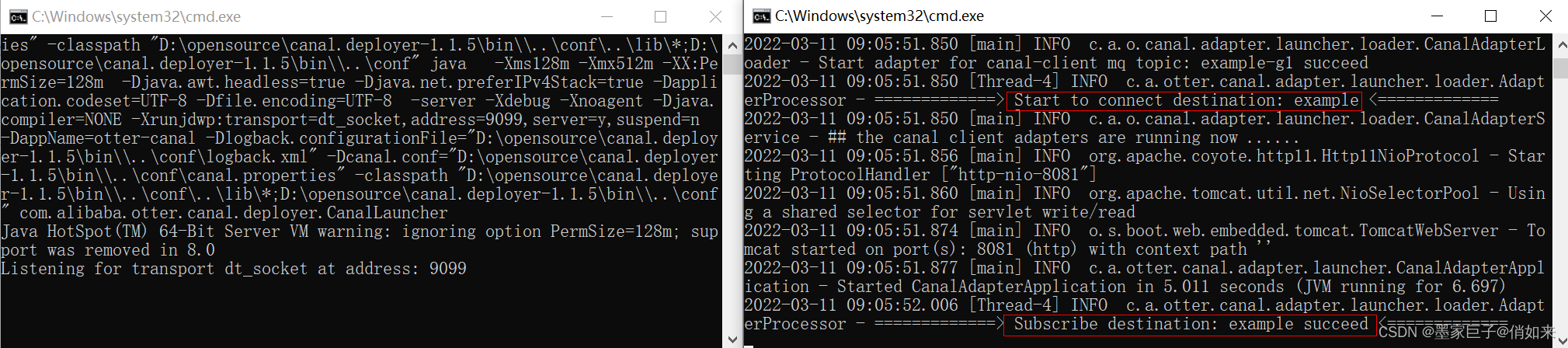
ES创建索引库和映射
启动ES6,启动kibana , 创建索引库和映射,注意:需要对应 canal-adapter配置的索引库
PUT employee
#创建映射
PUT employee/_doc/_mapping
{"_doc":{"properties":{"id":{"type":"long"},"username":{"type":"text","analyzer":"ik_smart"}}}}
最后修改数据库employee表中的数据,然后使用
GET employee/_search
观察ES中是否有数据同步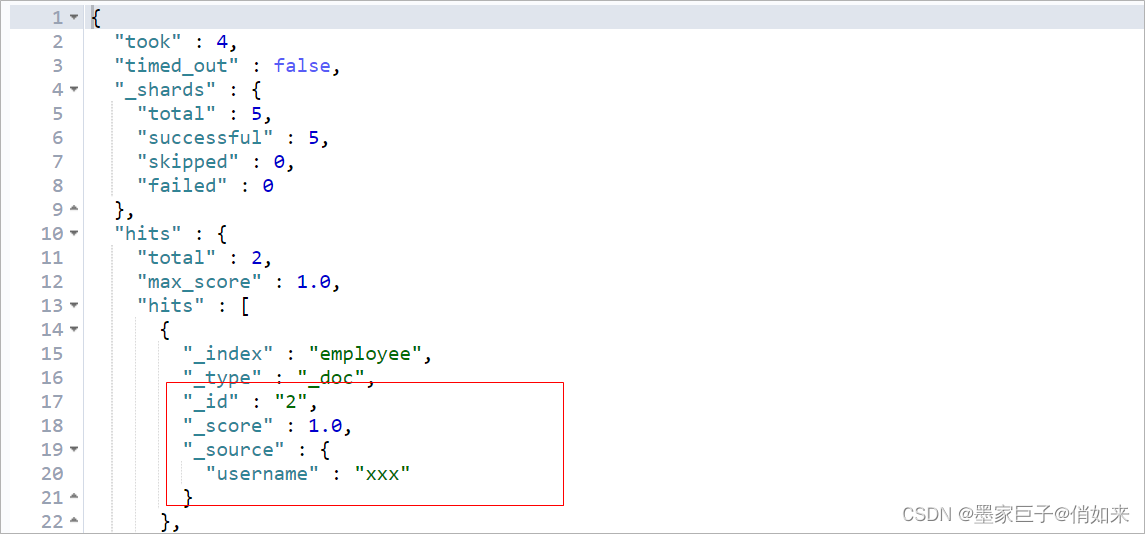
文章到这就结束了,喜欢的话请给个好评,你的鼓励是我最大的动力,谢谢。
版权归原作者 墨家巨子@俏如来 所有, 如有侵权,请联系我们删除。