
RabbitMq消息队列
首先,了解下什么是
同步和异步,这很重要,有些流程使用同步很合理,但是使用异步就会违反需求,就比如下单
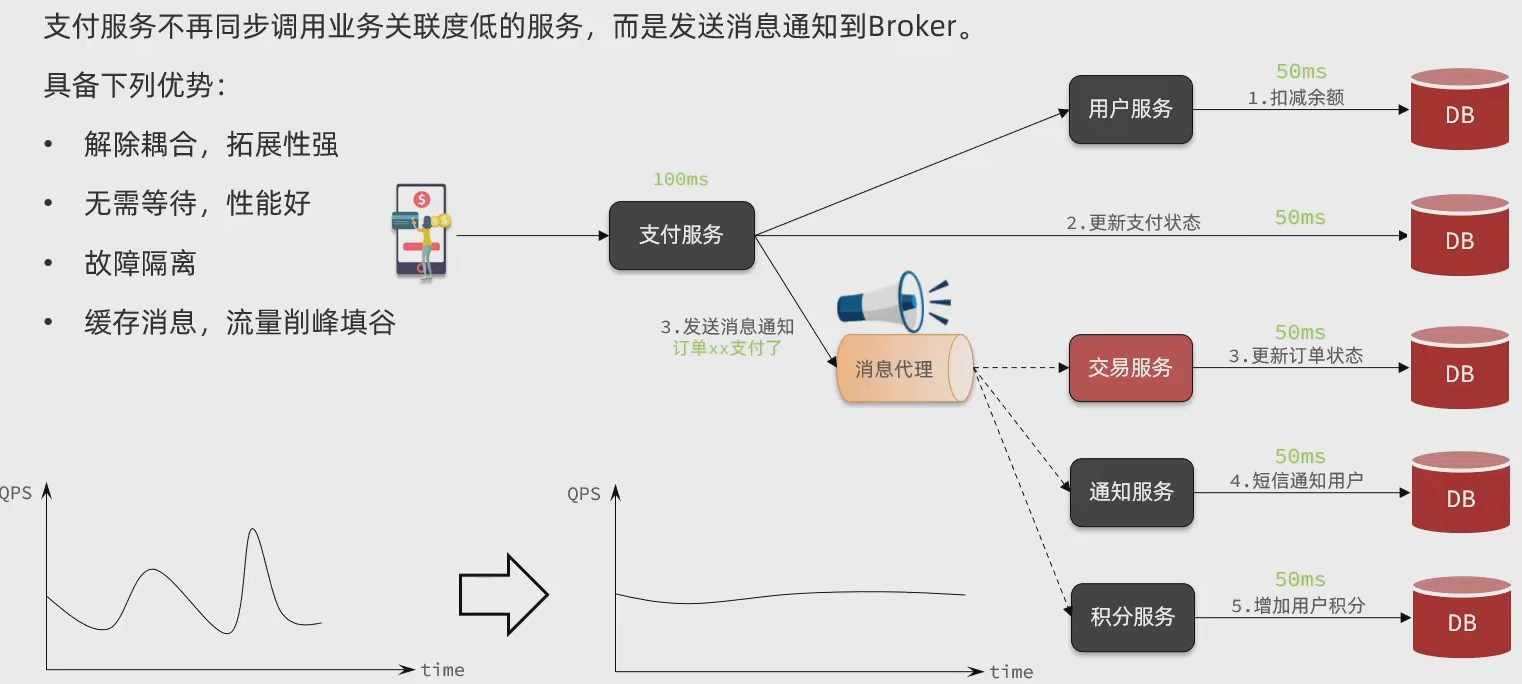
支付业务,用户下单后要先扣减余额,才能更新订单的支付状态,这两步操作只能是同步操作,因为第二步是否成功紧密关联第一步返回的结果。
而修改完订单状态后的一系列不重要操作,则是可以进行异步处理,就比如更新订单状态、增加用户积分等等,就可以使用异步操作。而如果使用同步,每次更新需求都是一次折磨,而且流程越长,接口响应时间越长,用户的体验感就越差,每次添加业务时,都要在原来代码的位置上重新添加,不利于解耦,拓展性很差(违反开闭原则),而且如果一处服务出现bug,会影响整个流程,级联失败。
异步调用
异步调用方式就是基于消息通知的方式,一般包含了三个角色。
消息的发送者:就是投递消息的人,就是调用放,现在不直接调接受者而是发送一条消息给代理。
消息的代理者(mq):管理、缓存、转发消息,可以理解为微信服务器。
消息的接受者:接受和处理消息的人,就是原来的服务提供方(客户)
有了异步调用,发送者和接受者之间就解耦了,双方不必知道对方的存在,也不必等待支付的结果。
就比如外卖柜,外卖小哥把外卖放到外卖柜,然后他就可以走了,他不必知道谁来取,而我也不知道谁送的,只是取走外卖就行,这就是解耦。
但是异步调用也会存在以下问题
- 不能立即得到调用结果,时效性差
- 不确定下游业务是否执行成功
- 业务安全完全依赖消息代理(Broker)的可靠性
所以异步调用不能乱用,只有对对方的执行结果不关心的流程,才可以使用异步。就比如查询就不能使用异步,点击查询按钮是要立刻查出内容的。
RabbitMq
1.安装
上篇文章讲过docker,直接在docker里安装,几条条命令搞定(docker是真方便)
首先,直接拉包,
docker pull rabbitmq:3-management
,然后run。
docker run \
-e RABBIT_DEFAULT_USER=wangmq \ (环境变量,默认用户名)
-e RABBIT_DEFAULT_PASS=123456 \ (设置密码)
-v mq-plugins:/plugins \ (挂载mq-plugins数据卷,对应mq里的插件目录)
--name mq \ (容器名)
--hostname mq \ (主机名)
-p 15672:15672 \ (端口映射)
-p 5672:5672 \
--network wang \ (网络)
-d \ (后台加载)
rabbitmq:3.8-management
然后
docker ps
查看,启动成功,其中15672是它提供的控制台端口(图形化界面),5672是消息通知端口,发送消息用的,所以访问5672端口。
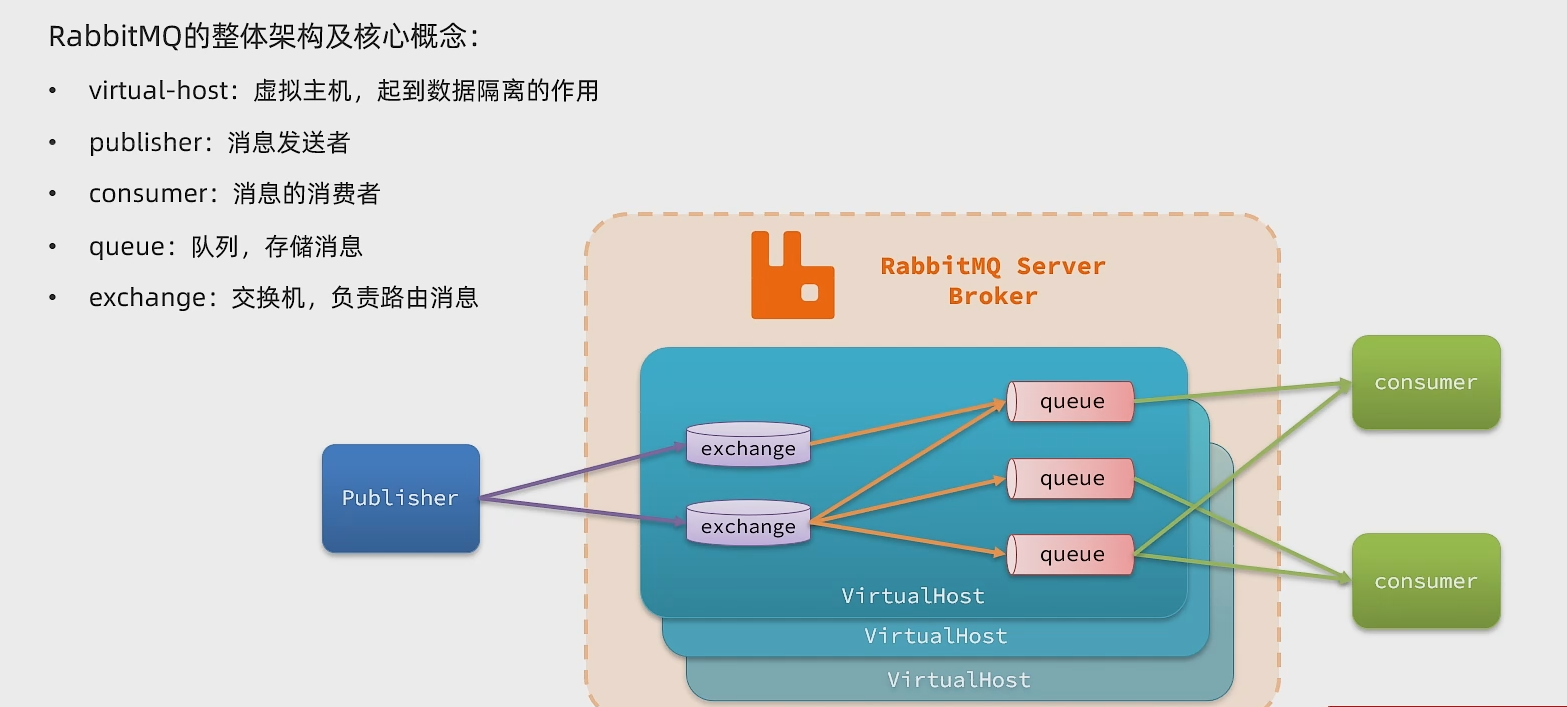
2.RabbitMq的整体架构和核心概念
publisher:消息发送者
consumer:消息接受者
queue:队列,存储消息
exchange:交换机,负责路由消息
virtual-host:虚拟主机,起到数据隔离作用
一般的流程为,消息发送到mq,mq转给consumer,但是中间是有层队列的,consumer是肯定要跟queue绑定,而消息也不是直接发到队列,先发到交换机,然后交换机负责把消息路由给队列。所以整个消息发送的模型为==生产者发送消息到交换机,交换机把消息路由给队列,消费者监听队列,拿到消息。==除去publisher和consumer,中间的部门就是Broker(消息代理)。一个Broker是可以创建多个VirtualHost,起到数据隔离作用,交换机和队列都有属于自己的VirtualHost。
RabbitMq入门
首先,要在Java中使用Mq,我们要使用Spring提供的AMQP,AMQP是用于在应用程序之间传递业务的开放标准。该协议与语言、平台无关,更符合微服务中的独立性要求。
Spring AMQP是基于AMQP的一套API规范,提供了模板来发送和接收信息。包含了两部分,spring-amqp是基础抽象,spring-rabbit是底层默认实现
代码
- 先导入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
- 在控制台创建队列simple.queue
- 配置RabbitMq服务端信息
spring:
rabbitmq:
host: 192.168.150.101 #主机
port: 5672 #端口
virtual-host: /mq
username: wangmq
password: 123456
- 发送消息
@AutowiredprivateRabbitTemplate rabbitTemplate;@TestpublicvoidtestSimplequeue(){//队列名称String queueName ="simple.queue";//消息String message ="hello,mq";//发送消息
rabbitTemplate.converAndSend(queueName,message);}
- 然后通过控制台查看,Queue的Get Message,会看到消息发送成功(消费者和发送者都要配相同的mq配置)
- 接收消息(指定消息队列即可 )
@Slf4j@ComponentpublicclassTestMq{@RabbitListener(queue ="simple.queue")publicvoidlisten(String msg){System.out.println("消费者收到了simple.queue的消息:"+ msg);}}
消费者消息推送限制
默认情况下,RabbitMq会将消息一次轮询投递给绑定在队列上的每一个消费者。但是这没有考虑到消费者是否已经处理完消息,可能会出现消息堆积。
因此需要修改配置,将preFetch值改为1,确保同一时刻最多投递给消费者一条消息
spring:rabbitmq:listener:simple:prefetch:1#每次只能获取一条消息,处理完才能获取下一条消息
Work模型的使用
- 多个消费者绑定一个队列,可以加快消息处理速度(如何解决消息堆积问题)
- 同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预获取的消息数量,处理完一条再处理下一条
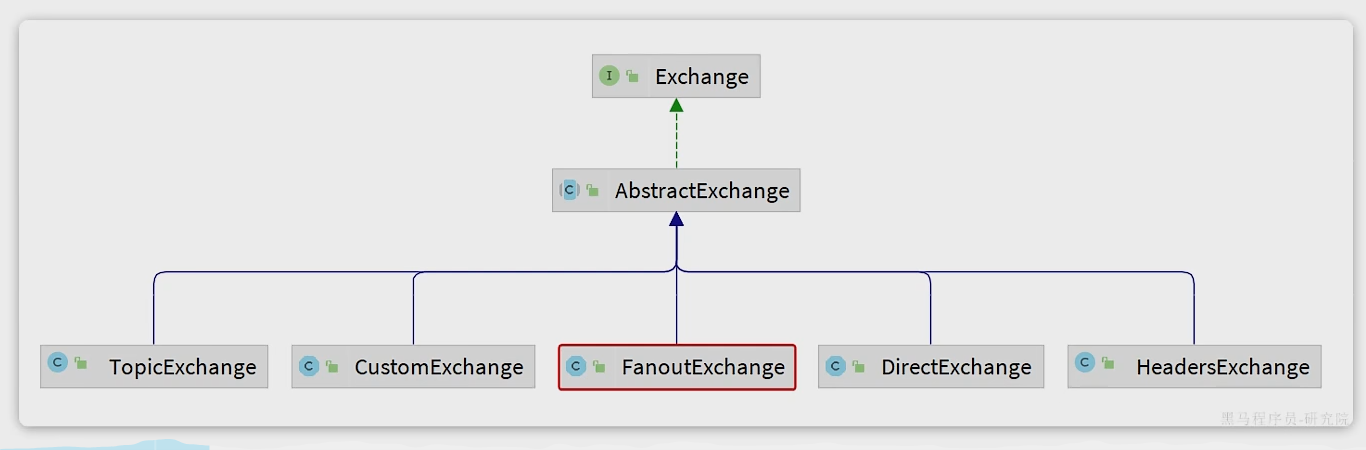
Fanout交换机
生产环境都是会通过交换机(exchange)来发送消息,而不是直接发送到队列,交换机的类型有三种
Fanout:广播
Direct:定向
Topic:话题
Fanout exchange会将接收到的消息广播到每一个跟它绑定的消息队列,所以也叫广播模式。
Direct交换机
Direct Exchange会将接收到的信息根据规则路由到指定的Queue,因此成为定向路由。
- 每一个Queue都与Exchange设置一个BindingKey
- 发送者发送消息时,指定消息的RoutingKey
- Exchange将消息路由到BindingKey与消息RoutingKey一致的Queue
Topic交换机
Topic Exchange与Direct Exchange类似,区别在于Routing Key可以是多个单词的列表,并且以
.
分割
Queue与Exchange指定Bindging Key时可以使用通配符:
#
:代指0个或多个单词
*
:代指一个单词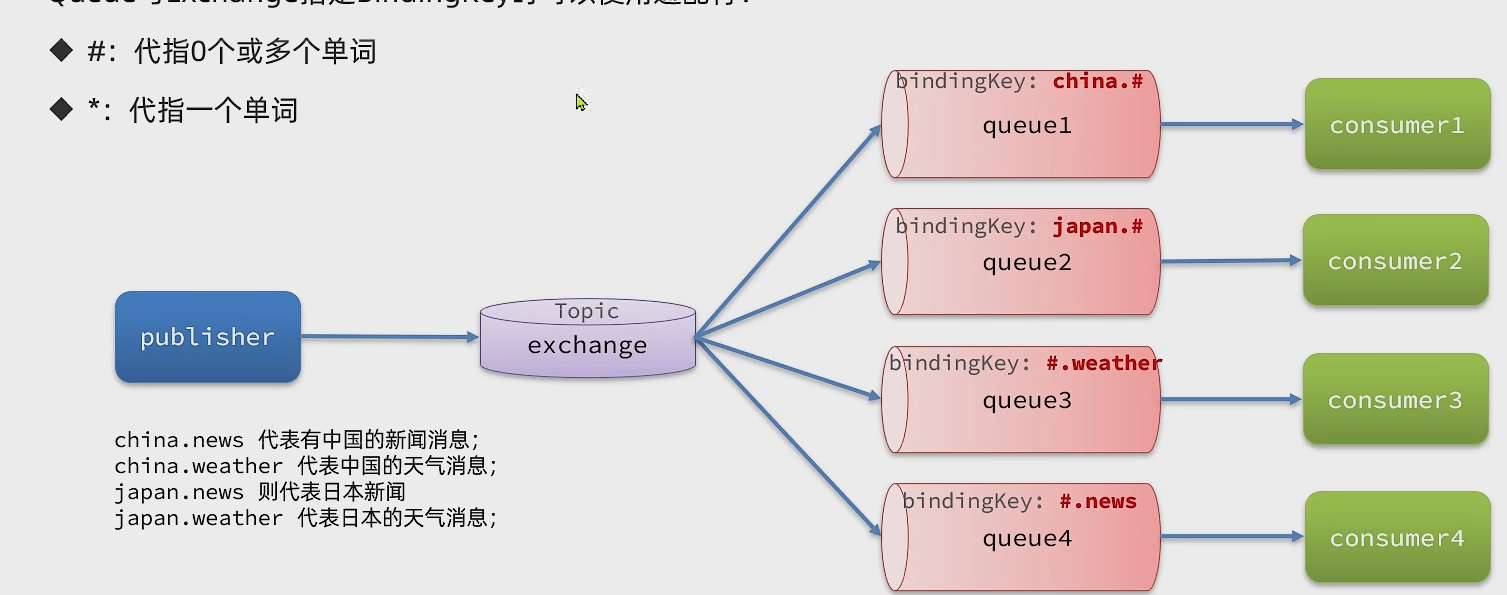
声明队列和交换机
SpringAMQP提供了几个类,用于声明队列、交换机及其绑定关系:
- Queue:用于声明队列,可以用工厂类QueueBuilder构建
- Exchange:用于声明交换机,可以用工厂类ExchangeBuilder构建
- Binding:用于声明队列和交换机的绑定关系,可以用工厂类BindingBuilder构建
 其中SpringAMQP提供了@RabbitListener注解来声明队列和交换机的方式
其中SpringAMQP提供了@RabbitListener注解来声明队列和交换机的方式
消息转换器
mq如果发送的消息不是message类型,那么会对消息进行序列化处理,Spring对消息的处理是由
org.springframrwork.amqp.support.converter.MessageConverter
处理的。而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。
会有安全问题隐患
- JDK序列化有安全风险
- JDK序列化的消息太大
- JDK序列化的消息可读性差
所以建议 采用JSON序列化,在生产者和消费者的pom都要引入jackson依赖
<!-- jackson序列化依赖 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency>
然后在启动类声明序列化方式
@BeanpublicMessageConverterjacksonMessageConverter(){returnnewJackson2JsonMessageConverter();}
RabbitMq高级(消息可靠性问题)
消息可靠性问题
拿订单流程举例,用户下单后调用订单业务代码,同步执行余额扣减和支付状态更新操作,然后使用mq异步处理更新订单状态流程,期间会先调用消息代理(mq),然后进行交易服务,最后更新订单状态。这期间每一步都有可能因为mq的宕机而出bug,所以mq的可靠性是一个注意点。消息丢失的可能性主要有:
- 消息发送的时候丢了
- mq宕机弄丢了消息
- 消费者异常弄丢了消息
生产者的可靠性问题
生产者重连
有时候由于网络的波动,可能会出现客户端连接MQ失败的情况,这时候可以通过配置开启失败后的重连机制。
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled:true# 开启超时重连机制initial-interval: 1000ms # 失败后的初始等待时间multiplier:1# 失败后的下次等待时长倍数,=initial-interval * multipliermax-attempts:3#最大重试次数
生产者确认
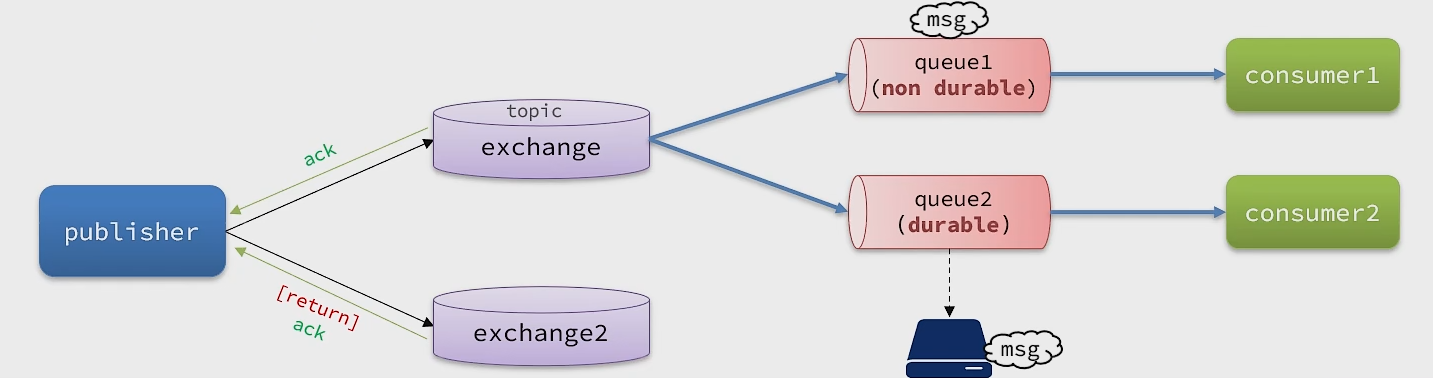
Mq有两种确认机制,分别是publisher Confirm和publisher Return。开启确认机制后,在MQ成功收到消息后会返回确认消息给生产者。返回的结果如下:
- 消息投递到了MQ,但是路由失败,此时会通过Return机制返回路由异常原因,然后返回
ACK,告知投递成功(路由失败几乎不可能是MQ自己的原因,只有一种可能行,交换机没有绑定队列) - 临时消息投递到了MQ,并且入队完成,返回
ACK,告知投递成功 - 持久消息投递到了MQ,并且入队完成持久化,返回
ACK,告知投递成功 - 其他情况都会返回
NACK,告知投递失败
这里生产者发送消息过去,肯定是不可能等着MQ返回的消息时ACK还是NACK吧,这里要异步去接收MQ的返回值,然后处理,然后这就需要加条配置
rabbitmq:publisher-confirm-type: correlated #开启confirm机制,并设置类型publisher-returns:true#开启publisher return机制
这里的
publisher-confirm-type
类型有三种,分别为none:关闭confirm机制;simple:同步阻塞等待MQ回执消息;correlated:MQ异步调用方式返回回执消息。
代码的实现分为两种方式,第一种为配置公共回调,第二种为每次发消息都单独配置一个回调。
第二种
SpringAMQP中生产者消息确认的几种返回值情况
- 消息成功到达交换机,但是没有被路由,返回ACK,并带上Return的消息。
- 消息成功到达交换机,也路由到了队列,返回ACK。
- 持久化的消息到达交换机,也路由到了队列并且持久化,返回ACK。
- 其他情况都是NACK。
如何处理生产者的消息确认
- 生产者确认需要额外的网络和系统资源,尽量不要使用。
- 如果一定要使用,无需开启Publisher-Return机制,因为一般的路由失败都是代码问题。
- 对于NACK消息可以做有限次数的重试,依然失败则记录异常信息。
如何保证生产者发送信息可靠?
- 首先,在mq中配置生产者的重连机制,在连接MQ时有网络波动他会重新连接,避免网络波动而导致发消息失败。
- 如果是其他原因导致的失败,RabbitMq还支持生产者的确认机制,只要开启了生产者确认,生产者发送的消息到 MQ,MQ会给一个ACK回执,如果发送失败则会返回NACK回执。当然这也是通过代码配置的。
- 但是,以上手段都会增加系统的负担和额外的资源开销,因此大多数场景下,尽量不开启消息确认机制,除非对于消息的可靠性有较高的要求。
MQ的可靠性问题
数据持久换
在默认情况下,RabbitMq会将接收到的消息保存在内存中,来降低消息收发的延迟。但是这样会导致两个问题:
一旦MQ宕机,内存中的消息会全部丢失
内存空间有限,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞。
RabbitMq实现持久化包括3个方面
第一个是持久换交换机,在控制台新增Exchange时选择Durable属性
第二个是持久换队列,在控制台新增Queue时选择Durable属性
在Java代码中新增交换机、队列默认都是持久的
第三个是消息持久换,在控制台页面发消息时,需要将propertier改成2
数据如果不是持久化的,MQ会在内存即将堆满的时候,将老的一部分消息持久换到硬盘中,这段时间是阻塞的,线程只做IO,处理消息的速度会出现短暂的为0。
而如果选择持久化,它一边在内存处理的同时,一边写入磁盘。线程不阻塞,但是相比处理不持久化的速度要满一点,而且如果内存即将堆满的时候,它是直接执行删除操作,删除较老的数据,速度会短暂的降低一点,不会阻塞。
Lazy Queue
lazy queue是在RabbitMq3.6版本之后新增的概念,是惰性队列。他的特征如下:
- 接收到的消息直接存入磁盘,而非内存(内存中只保留最近的消息,默认2048条)
- 消费者要消费消息时才会从磁盘中读取并加载到内存,所以响应速度会变慢一旦,但是内存默认是有最新的数据,如果不是数据太多的情况下,速度是不会有什么影响的。
- 支持百万条的消息存储
在3.12版本后,所有的队列都是Lazy Queue模式,无法更改。要设置一个队列为惰性队列,只需在声明绑定的注解里加上
value=“lazy”
即可
Lazy Queue的效率是非常高的,处理消息的速度可以达到60k/s,它虽然是写入磁盘,然后从磁盘读入,但是它对IO进行了优化的。
总结
RabbitMq如何保证消息的可靠性
- 首先通过配置可以让交换机、队列及其发送的消息都持久化。这样队列都会持久化到硬盘,即使MQ宕机,重启后消息依然存在。
- RabbitMq3.6后引入了Lazy Queue。它会将所有消息都持久化,但是性能大大增加。
- 开启持久化和生产者确认时,Mq只有在持久化后才会返回ACK。(真不建议开生产者确认,对性能影响太大)
消费者的可靠性问题
消费者确认机制
**如果把消息投递给消费者,但是消费者处理异常,那么就等于这条消息消失**,所以要处处理这种情况。所以需要有一种确认机制,当消费者处理消息结束后,应该想Mq返回一个回执,告知自己处理消息的状态,回执有三种可选
ack:成功处理消息,Mq从队列中删除改消息nack:处理消息失败,Mq需要再次投递消息reject:消息处理失败并拒绝该消息,Mq从队列中删除该消息(格式有问题的消息,导致代码报错的情况)
spring底层会代理消息监听器,当接收到消息的时候,它会调用消息处理的逻辑。如果执行成功,它会自动回执ACK;如果抛出异常则会NACK或REJECT,取决于异常的类型。
SpringAMQP已经实现了消息确认功能,并且允许我们通过配置文件选择ACK处理方式,主要有:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送ask或者reject,存在业务入侵,但是更灵活
- auto:自动模式。就是刚才说的spring动态代理,对我们 消息处理逻辑做了环绕通知,当业务正常执行时自动返回ack,业务出现异常时,根据异常返回不同结果: 如果是业务异常,则返回nack 如果是消息处理异常或检验异常,则返回reject
rabbitmq:listener:simple:prefetch:1#能者多劳,每次取一条acknowledge-mode: auto #none关闭ack,manual手动ack,auto自动ack。
消费失败处理
如果说,业务代码执行有异常,但是如果在消费者确认机制配置了auto的acknowledge-mode,那么他会一直重试、一直报错…无限循环,导致mq 消息处理飙升。
所以这里一定要加配置,利用spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
rabbitmq:
listener:
simple:
prefetch: 1 #能者多劳
retry:
enabled: true #开启消费者失败重试
initial-interval: 1000ms #初始等待时间为1s
multiplier: 1 #下次等待的时长倍数,下次等待时长 = multiplier * initial-interval
max-attempts: 3 #最大重试次数
stateless: false #true无状态,false有状态,业务中包含事物为false
在三次消息重试失败后,它还是会将消息从队列里删掉,是因为在开启重试模式后,如果重试次数耗尽但依然失败,则有MessageRecover接口来处理,它包含了三种不同的实现模式:
RejectAndDontReqeueRecover:重试耗尽后,直接reject,丢弃消息。默认就是这种处理ImmediateRequeueRecoverer:重试耗尽后,返回nack,消息重新入队RepublishMessageRecover:重试耗尽后,将失败消息投递到指定交换机,这个交换机可以绑定队列,进行一些兜底操作,比如给开发人员发邮件,警告生产环境出错,提示人工处理。
代码实现,首先定义接收失败消息的交换机、队列和binding key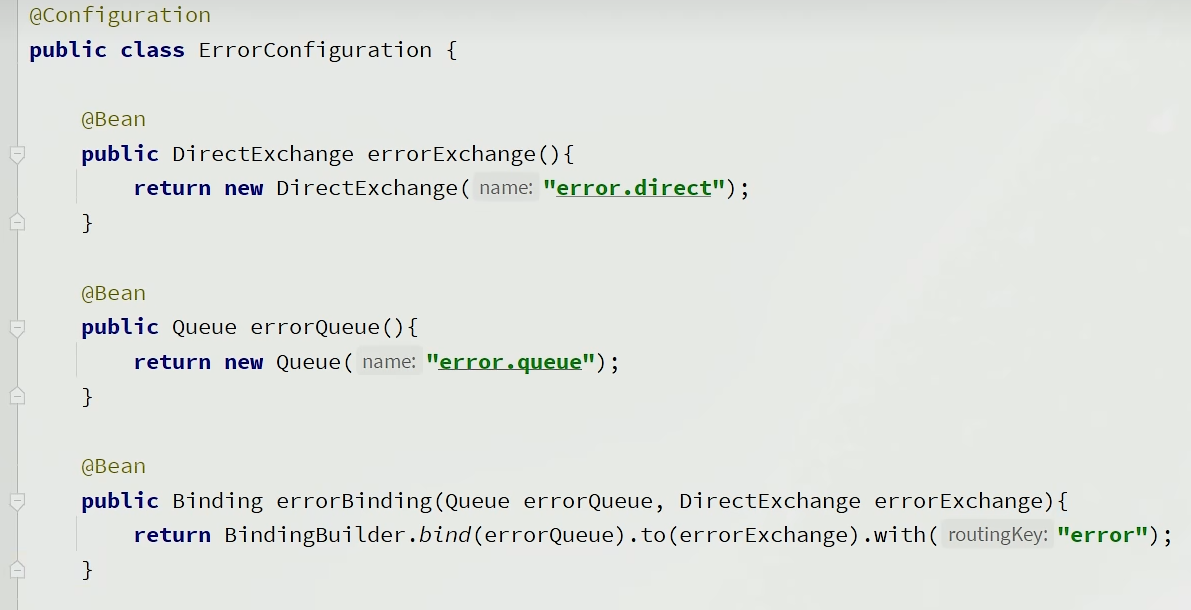
其次定义RepublishMessageRecover
这里需要注意下,这个配置类需要在消费者开启失败重试后才生效,所以需要在类前加注解,当配置了消费者失败重试后,才会生效,重试失败走指定交换机。
@ConditionalOnProperty(prefix ="spring.rabbitmq.listener.simple.retry",name ="enabled", havingValue ="true")
消费者如何确保消息一定被消费
开启消费者确定机制为auto,由spring确认消息处理成功后返回ack,异常时返回nack
开启消费者失败重试机制,并设置MessageRecover,多次重试还是失败后将消息投递到指定的交换机,交由人工处理
业务幂等性
前面所述的方案,可以确保消息至少被消费一次,但是不确保被消费几次。因为中间更有重试机制,假如因为网络波动,消费者消费成功了,由于某种原因代码认为它没有消费成功,一个消息就可能被消费多次。就是消息投递成功了,但是因为一直没有收到ack,所有认为消息超时了,要重发。等等很多因素都会产生一个消息被投递多次,在业务上时不严谨的,所以业务必须要保证**幂等**
什么是幂等?它是一个数学概念,用函数表示就是
f(x) = f(f(x))
(绝对值函数等等)。在程序开发中,指同一个业务,执行一次或执行多次对业务的影响是一样的
有些业务天生就是幂等的,比如查询、根据ID删除。
但有的业务就不是幂等,比如用户下单业务,需要扣减库存、用户退款业务,需要恢复余额、提交表单等等。
如何确保业务幂等性?
对于表单来说,每次进入表单之前,生成一个唯一标识,存储在redis中,发送到前端,然后点击提交时携带标识,通过
set nx
操作,如果可以获取到,则是第一次提交。如果消息提交了多次,获取锁肯定是失败的(一定要设置过期时间)。这就是第一种解决方案,唯一消息ID
第二种方案就是**结合业务逻辑进行判断**。比如在订单支付业务中,应该首先判断订单是否已支付,如果已支付,则直接跳出,只有未支付的订单才需要修改,其他不做处理。但是如果有两个线程进入修改订单的流程代码中,也是会有线程安全问题,在查询订单状态时,确定订单未未支付,但是现在执行另外一个线程,这就是JUC安全问题。这时候可以通过一种乐观锁的方式实现,订单的状态假设为1(未支付),2(已支付),在修改订单状态时执行的语句修改为“update order set status = 2 where id = ?
and status = 1
”,只对未支付的订单进行操作,所以就不用之前的判断订单是否支付的操作。
如何保证支付服务和交易服务之间的订单状态一致性?
首先,支付服务会在用户支付完成后利用MQ消息通知交易服务,完成订单状态同步。
其次,为了保证MQ消息的可靠性,我们采用生产者确认机制和消费者确认机制、消费者失败重试策略,来确保消息投递和处理的可靠性。同时也开启MQ的持久化,避免因服务宕机而导致数据丢失。
最后。我们还在交易服务更新订单状态时做业务幂等判断,避免因消费者重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方案?
如果消息还是投递失败,我们可以配置消费者失败重试失败的交换机,在这里进行兜底操作,比如保存消息,然后发邮箱或短信通知技术人员。
我们可以在交易服务设置定时任务,定期查询订单状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的一致性。
延迟消息
延迟消息:生产者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间后才收到消息。
延迟任务:设置在一定时间之后才执行的任务。
如果有类似这样的需求,那么则需要定时任务:比如在下单后,库存的数量会进行-1操作,但如果用户迟迟不付款,而且库存的数量已经为0,那么对于商家和其他客户来说都是损失。这时候则需要开启一个定时任务,在用户下单的那一刻,监听10分钟后的订单信息,如果10分钟后订单还是没有支付,则取消订单,并且回复库存。
延迟消息的实现方式主要有三种实现方式:死信交换机、延迟消息插件、取消超时订单
死信交换机
当一个队列中的消息满足下列情况之一时,就会成为死信:
消费者使用basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false。
消息是一个过期消息(达到了队列或消息设置的过期时间),超时无人消费。
要投递的队列消息堆积满了,最早的消息可能成为死信。
如果队列通过
dead-letter-exchange
属性指定了一个交换机,那么该队列中的死信就会投递到这个交换机中。这个交换机成为死信交换机

生产者发送了一个消息,设置30秒过期,然后通过交换机路由到指定队列。但是这个队列是不设置消费者的,所以30秒后这条消息就过期了,这条消息就变成了死信,就自动投递到了死信交换机,然后路由到死信队列,最终投递到消费者。
抛开过程不谈,最终的结果就是消费者发送一条消息,30秒后执行。
代码实现:(不给这条消息绑定队列,过期后就会进入死信队列)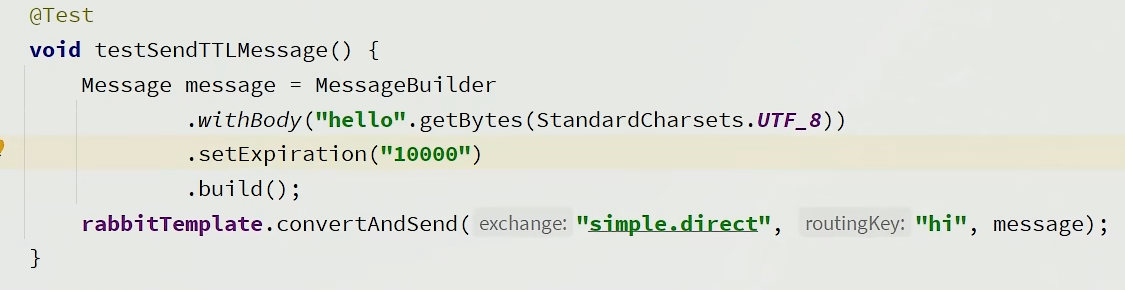
延迟消息插件
RabbitMq官方也推出了一个插件,原生支持延时消息功能。原理是设计了一种支持延迟消息功能的交换机,当消息投递到交换机后可以暂存一段时间(取决于发消息时配的参数),到期后再投递到队列。
发送者
消费者
版权归原作者 我也曾把你举过头顶 所有, 如有侵权,请联系我们删除。