
猫狗识别
- 实验背景1. 数据集介绍
我们使用CIFAR10数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为验证集。这次我们只对其中的猫和狗两类进行预测。

图 1 CIFAR10 数据集图像示例
- ******实验环境 ******
本次实验,在跑完老师提供的 PaddlePaddle 代码的基础上,采用PaddlePaddle环境进一步训练模型,利用PaddlePaddle的可视化插件VisualDL进行训练模型过程的可视化。
另附代码见附录和.ipynb 文件。
- 实验设置
本次实验,我主要比较了几种不同的经典神经网络在 CIFAR10数据集上的表现,包括经典模型如*VGGNet,ResNet和GoogleNet 。VGGNet,ResNet和GoogleNet 三个模型使用332*32**图像
- VGGNet
VGGNet是一种深度卷积神经网络,由牛津大学的研究团队于2014年提出。它在ImageNet图像分类挑战赛中取得了出色的成绩,并成为卷积神经网络设计中的重要里程碑之一。VGGNet的主要贡献在于通过增加网络的深度来提高模型性能,并将深度和宽度作为关键设计元素。
其网络结构如下:
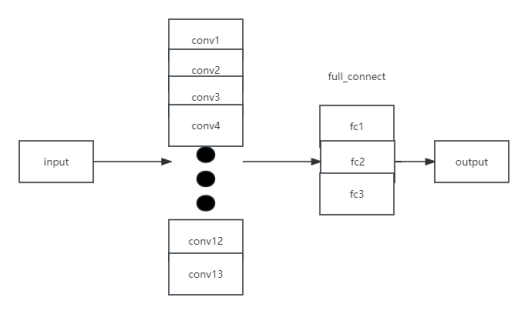
图 2 VGGNet 网络结构
以下是VGGNet的主要特点和设计原理:
网络结构:VGGNet的整体结构非常简单和规整,它由多个卷积层和池化层交替堆叠而成,最后是几个全连接层。VGGNet的核心是使用了非常小的3x3卷积核,以较小的步幅进行卷积操作。通过堆叠多个卷积层,VGGNet可以达到比较大的感受野,从而能够捕捉到更全局的图像特征。
深度和宽度:VGGNet以其深度和宽度的设计而闻名。它引入了不同层数和参数量的变体,其中最著名的是VGG16和VGG19。VGG16具有16个卷积层(包括13个卷积层和3个全连接层),VGG19更进一步,具有19个卷积层(包括16个卷积层和3个全连接层)。这种深度和宽度的设计使得VGGNet能够更好地捕捉图像中的细节和抽象特征。
小卷积核:VGGNet采用了较小的3x3卷积核,这是一项重要的设计选择。通过使用小卷积核,VGGNet可以增加网络的深度,减少参数数量,并且具有更强的非线性表达能力。多个3x3卷积层的堆叠等效于一个更大感受野的卷积层,但参数量更少。
池化层:VGGNet使用了最大池化层来减小特征图的空间大小。池化层有助于减少特征图的空间维度,提取更为鲁棒的特征,并且在一定程度上具有平移不变性。
VGGNet具有多个卷积层和池化层。它的简单结构和小卷积核大小有助于防止过拟合。本次采用VGG16。
- ResNet
ResNet(Residual Network)是一种深度卷积神经网络架构,由微软研究院的研究团队于2015年提出。它在深度学习领域取得了巨大的成功,并成为许多计算机视觉任务的标准模型之一。ResNet的关键创新是引入了残差连接(residual connections),允许网络在训练过程中更轻松地学习到非常深的层次。
其网络结构如下:

图 3 Resnet-18网络结构
以下是ResNet的主要特点和设计原理:
残差连接:残差连接是ResNet的核心概念。传统的卷积神经网络是通过堆叠多个卷积层构建深层网络,但随着网络层数的增加,出现了梯度消失和梯度爆炸等问题。为了解决这些问题,ResNet引入了跳跃连接(skip connections)或快捷连接(shortcut connections)。残差连接允许网络直接将输入信号绕过一个或多个卷积层,并将其与后续层的输出相加。这样,网络可以更轻松地学习到残差(Residual)信息,从而使得深层网络的训练更加容易。
深度和宽度:ResNet的设计思想是通过增加网络的深度来提高性能。它以层的数量作为网络的关键指标。ResNet的变体包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,其中数字表示网络的层数。较深的ResNet模型通常具有更好的性能,但也需要更多的计算资源和训练时间。
卷积层堆叠:ResNet在每个卷积层堆叠中使用了相同的基本模块,称为残差块(Residual Block)。每个残差块由两个或三个卷积层组成,其中包括一个1x1卷积层用于降维和恢复维度,以及一个3x3卷积层用于特征提取。在ResNet-50及更深的模型中,还引入了一个额外的1x1卷积层用于进一步减少特征图的维度。
全局平均池化和全连接层:在ResNet的最后,通常使用全局平均池化层将特征图转换为向量表示,然后使用全连接层进行分类或回归。全局平均池化层有助于减少特征图的空间维度,并保留最重要的特征。
ResNet以其深度、残差连接和优秀的性能在计算机视觉任务中获得了广泛的应用。它在图像分类、目标检测、语义分割等任务上取得了许多优秀的结果,并为后续深度神经网络的设计和发展提供了重要的启示。因restnet变体数字越大,网络层数越多,本次实验采用ResNet-18进行一个简单尝试,后续使用更深网络层进行探究。
- GoogleNet
GoogleNet,也称为Inception v1,是由Google团队于2014年提出的深度神经网络架构。它是为了解决在深度神经网络中存在的计算复杂度和参数数量过大的问题而设计的。

图 4 GoogleNet网络结构
以下是GoogleNet的一些主要特点和创新:
Inception模块: GoogleNet引入了称为“Inception模块”的新型网络结构。该模块使用不同大小的卷积核(1x1、3x3、5x5)和最大池化层,并将它们的输出连接在一起。这种多尺度的卷积操作使网络能够同时捕捉不同尺度的特征。
1x1卷积: GoogleNet广泛使用了1x1的卷积操作,这有助于减少网络的参数数量和计算复杂度。1x1卷积还可以用来学习通道之间的特征组合,增强网络的表达能力。
全局平均池化: 在传统的卷积神经网络中,通常使用全连接层来进行分类。而GoogleNet采用了全局平均池化层,将每个特征图的平均值作为输入,减少了参数数量,同时避免了过拟合。
辅助分类器: GoogleNet在中间层添加了两个辅助分类器。这些辅助分类器有助于梯度的传播,缓解了梯度消失的问题,并且在训练过程中提供了额外的梯度信号,有助于更快地收敛。
网络结构: GoogleNet整体上是一个22层的深度神经网络。它在ILSVRC 2014图像分类竞赛中取得了第一名,证明了其在图像分类任务上的有效性。
- 项目流程
2.1 准备数据
直接下载PaddlePaddle内部的Cifar10数据集,再次体会到了PaddlePaddle的方便。

2.2 搭建网络
本次实验基于 PaddlePaddle搭建了**** VGGNet,ResNet****和GoogleNet,其设计和改良如 1.3 所介绍,其详细代码如下:





2.3 训练配置
接下来,定义训练函数,为防止过拟合,达到更好效果,使用学习率衰减策略。
初始参数如下:
Epochs
Batch_size
verbose
Learning_rate
Shuffle
40
256
1
0.001
True
训练函数:
- 损失函数和优化器: 使用交叉熵损失和Adam优化器。
- 学习率衰减策略: 使用StepDecay策略,每经过10个epoch,学习率乘以0.6。
- 模型准备: 设置模型的优化器、损失函数和评价指标(准确率)。
- 训练模型: 使用model.fit方法进行模型训练,包括40个epoch,批次大小为256,采用shuffle方式,并应用学习率衰减和VisualDL回调。
- 保存模型: 使用model.save方法保存训练好的模型。
- VisualDL回调:代码中使用了VisualDL的LogWriter来记录训练过程的信息,确保在其他地方实例化了log_writer对象。
训练方式如下:
综合来看,使用模型对CIFAR-10数据集进行训练,使用Adam优化器和交叉熵损失函数进行模型优化,同时通过VisualDL工具对训练过程进行可视化。训练过程中会保存分阶段的模型参数,并最终保存整个训练好的模型。
2.4 超参调节
为进一步得到更好的模型结果,且由于本数据集没有设置验证集,因此利用给定参数空间搜索在测试集上进行超参数的调节,其中,参数调节范围如下表所示:
因搜索最优参数耗时较长,且通过初次训练结果发现,在epoch>10以后的acc增幅较小, VGGNet,ResNet****和GoogleNet 三个模型都固定epochs=10,超参数范围如下所示:
'learning_rate': [0.0001, 0.0005, 0.001, 0.005]
'batch_size': [ 128, 256]
搜索代码如下:

对于每个模型搜索得到的最优参数为:
模型
learning_rate
batch_size
VGGNet
0.0005
256
ResNet
0.001
256
GoogleNet
0.001
256
- 实验结果
3.1 模型准确率比较
接下来,我比较了各模型在 echos=40 时的模型的表现
模型
Loss
Train_acc_top1
Train_acc_top5
Test_acc_top1
Test_acc_top5
VGGNet
0.6014
0.9147
0.9942
0.8536
0.9878
ResNet
0.3567
0.8994
0.9987
0.8242
0.99
GoogleNet
0.4580
0.8293
0.9914
0.7932
0.9829
同时,可视化模型表现如以下图:
左列颜色区分下面可视化图:
图 7 训练过程图
横坐标为epoch
从表格上的这些指标来看,不同模型在测试集上的表现相对较好。总体来说,每个模型都有其优势和劣势。VGGNet和ResNet在训练准确率上表现较好,但可能存在过拟合的问题。GoogleNet则在训练和测试准确率上都相对较低,可能需要更多的调整来提高性能。综合考虑训练和测试准确率以及损失值,可以根据具体应用需求来选择最适合的模型或者进一步优化训练过程。从训练过程图看,在epoch<10,acc增长急剧,但epoch>10以后,acc渐趋于平缓,loss一直都有所波动,但整体趋势呈下降趋势。
3.2 泛化能力测试
为了进一步测试模型的泛化能力,我测试了新添加的网络猫狗图片经过模型验证的结果。新测试图片 resize 到 32*32 的大小并归一化为张量便于测试,通过已训练好的模型进行测试。经验证,模型可以正确输出结果。
图 8 测试用图片
识别准确

- 实验感想
在本次实验中,我完整的实现了 VGGNet,ResNet和GoogleNet 的训练过程,并使用了自己制作的新手写数字图片进行测试。这让我对于深度学习高层 Api 的使用有了更深入的理解。同时,在本次实验中我经过了很久的调参和反复的验证,这让我更加深入的理解了过拟合、正 则化等概念和参数增多在深度学习中的影响。
中途有发生过拟合情况如下所示: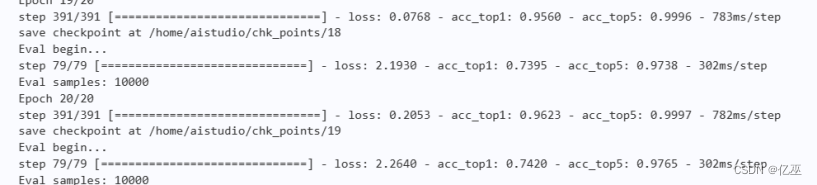
由上图可以看到训练top1准确率已达到96%以上,但测试准确率一直在74%左右,增加处理数据集得随机水平旋转进行数据增强,并使用学习率衰减策略,以此防止过拟合。
最终,也通过自己写的代码在测试集上达到了 0.9935 的准确率。总得来说,本次实验让我收获颇多。
五、 附录:python 代码
完整代码参见所交版本和.ipynb
版权归原作者 亿巫 所有, 如有侵权,请联系我们删除。