
安装visual studio 2019
进入官方的下载页面,可能需要登录,登录后选取社区版下载。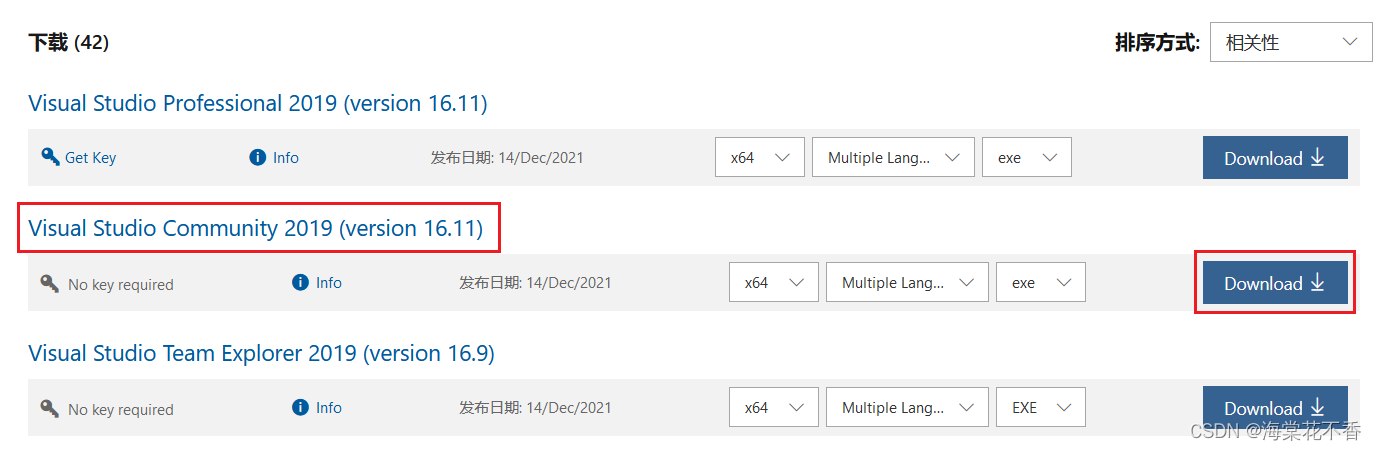
注意,这里只是下载安装器,真正的安装会在后续执行文件,配置安装目录后,联网下载安装包文件。整个过程比较简单,这里不作详细叙述。仅提供一份备用的安装器下载链接。
链接:https://pan.baidu.com/s/1l7IZBIXw7qiGZC9upCylgg
提取码:62dn
由于最新的visual studio版本已经来到了vs2022,但相应的cuda版本肯定也需要是最新的。这里选取vs2019和cuda11的搭配,如果选择安装vs2022,在下载cuda版本后,需要查看cuda版本中是否有相匹配的visual studio integration文件,否则不能配置成功。
安装英伟达驱动
进入驱动下载界面,根据自己的显卡型号,选择合适的显卡驱动。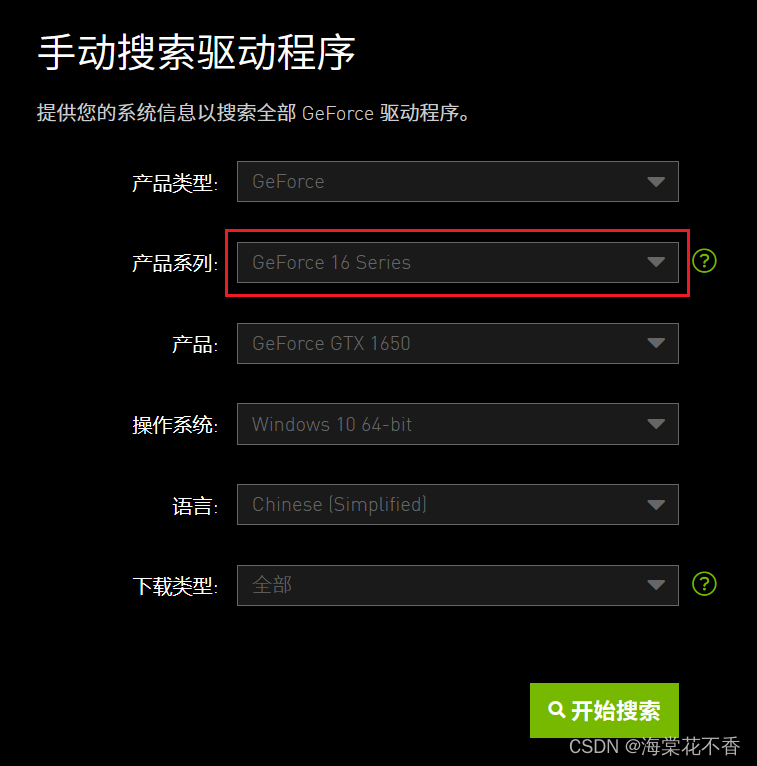
注意,这里我电脑是gtx1650的显卡,产品系列选择Geforce16 Series,而不是GeForce GTX 16 Series [Notebook]。
查看驱动支持的cuda最高版本
有两种方式可以查看驱动与cuda的兼容版本。
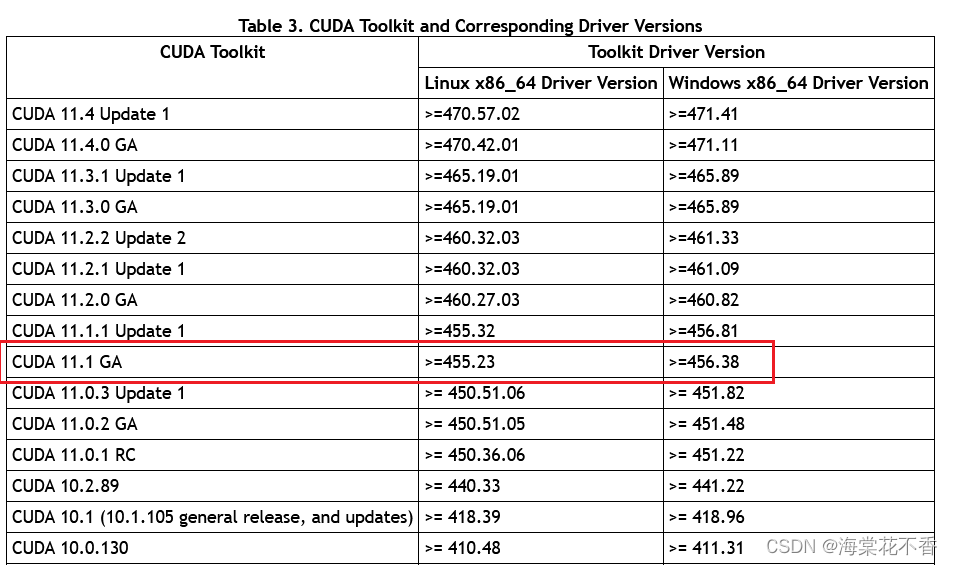
- 进入官方网站查看不同的cuda版本所需要的最低的驱动版本。由于我选择安装的驱动版本为457,因此最高能选择到11.1.1版本。
- 成功安装英伟达驱动后,win+R,输入cmd,进入命令行界面,输入nvdia-smi,即可查看nvidia驱动版本,以及最高支持的cuda版本。
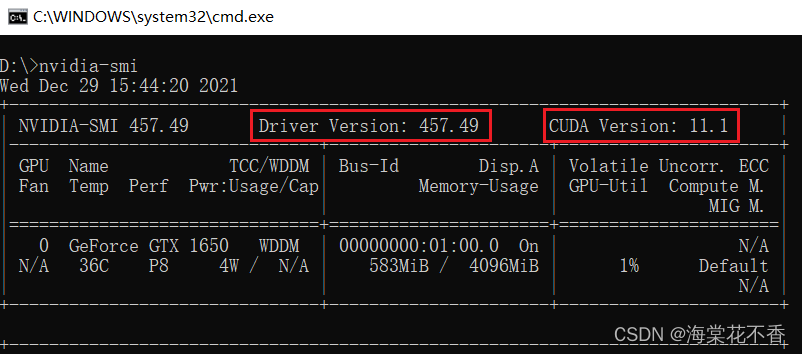
可以得知,英伟达驱动版本为457.49,最高支持的cuda版本为11.1。
安装cuda v11.1及cudnn8.0
下载文件
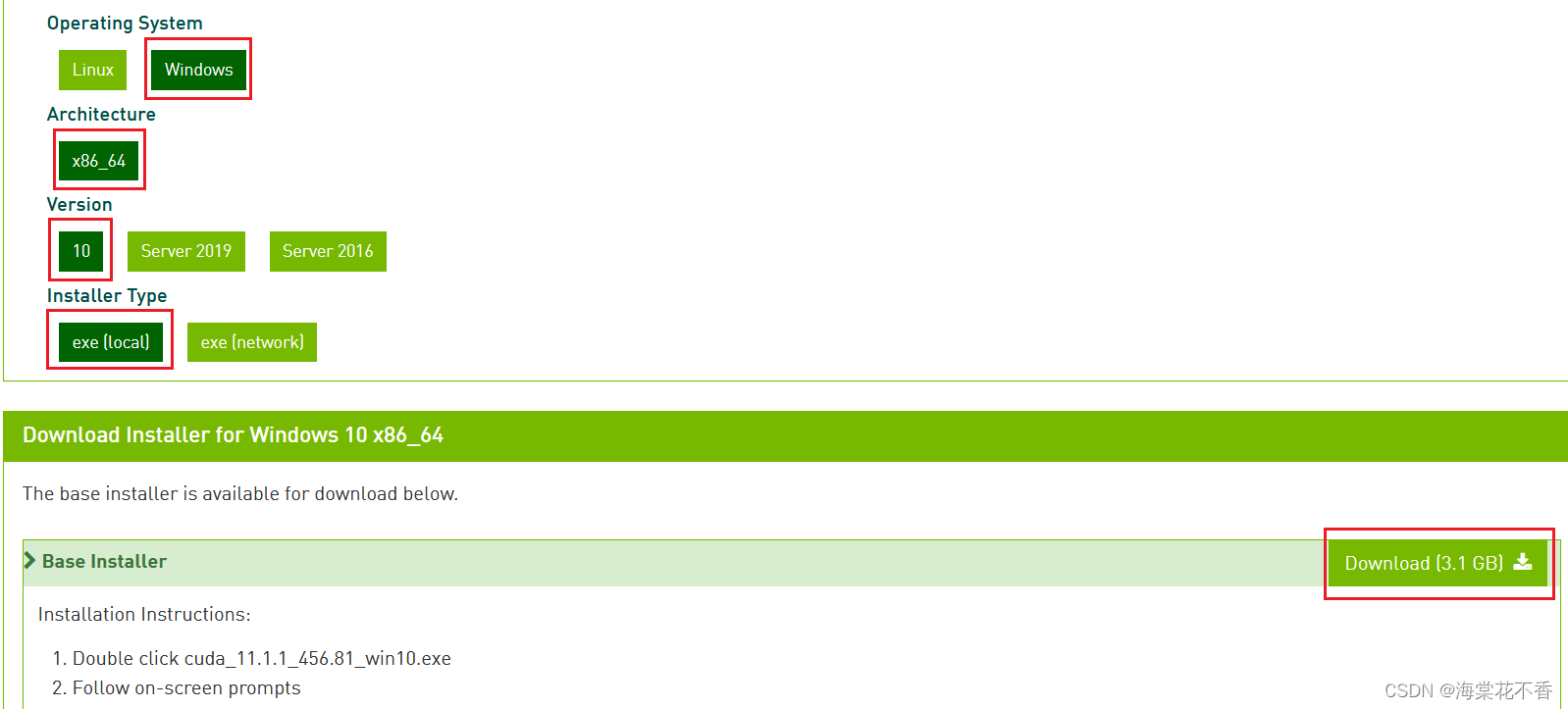
进入cuda的官方下载页面,下载cuda11的windows版本。

由于安装的英伟达驱动限制,最高支持到cuda11.1,因此选择该版本下载。
进入cudnn的主页面,输入账号密码,各种点击,最终会进入到真正的下载界面下载与cuda相匹配的cudnn版本。


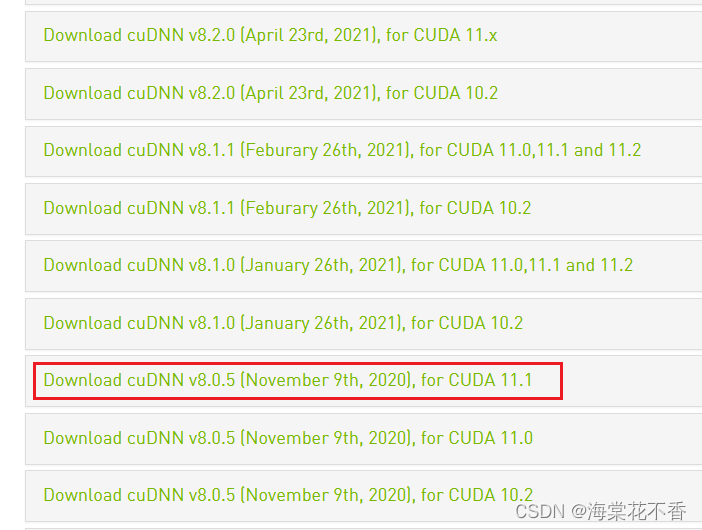

由于cuda可以随意下载,而cudnn下载需要登录账号,而最麻烦的就是注册账号的过程,故提供一份cudnn8.0的备用的下载链接。
链接:https://pan.baidu.com/s/17ViL407xNT0pjfMj80T5kg
提取码:509a
安装配置
双击cuda安装包开始,输入一个临时的解压目录。
开始解压文件。
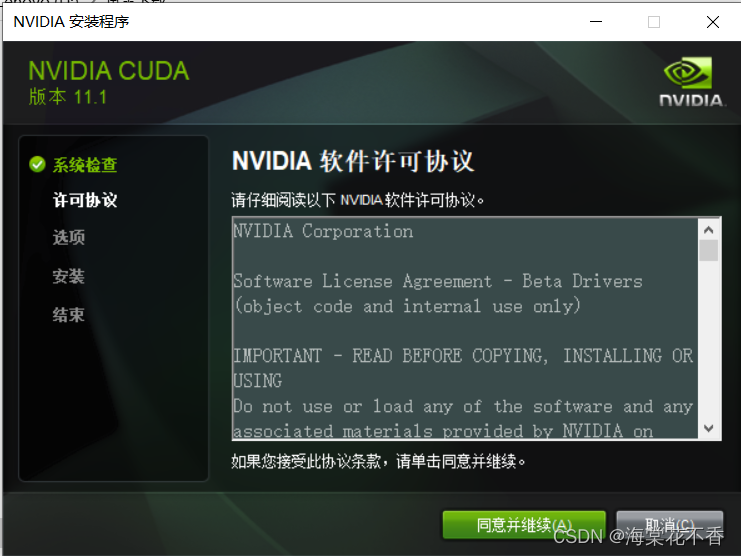
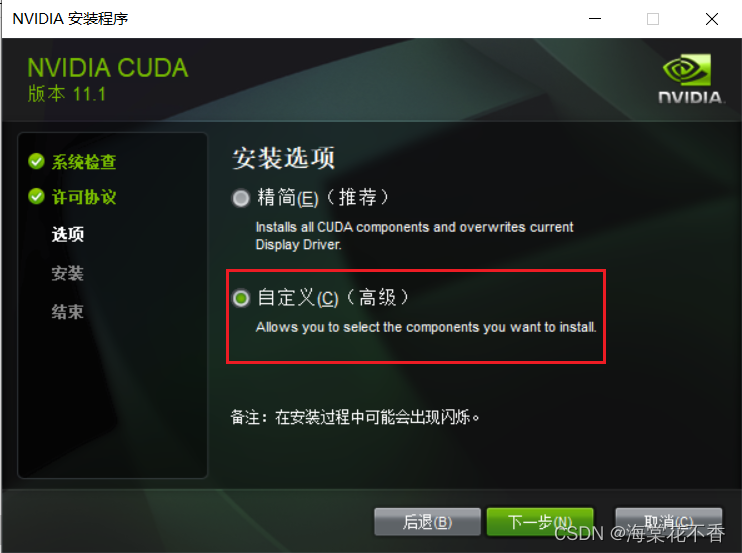
这里需要取消驱动的安装,因为我们之前安装的驱动版本,比cuda自带的驱动版本要高。不取消会安装失败。
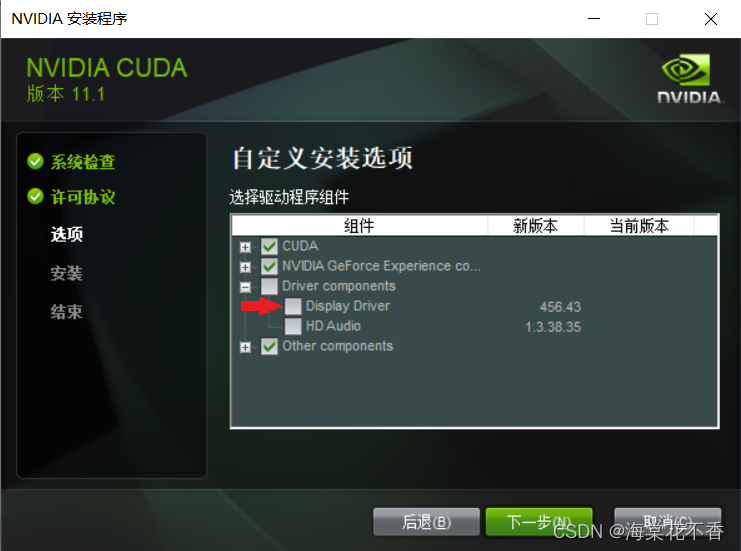
最好将这些文件安装在D盘。如果系统盘够大的话,可以无视这条建议。
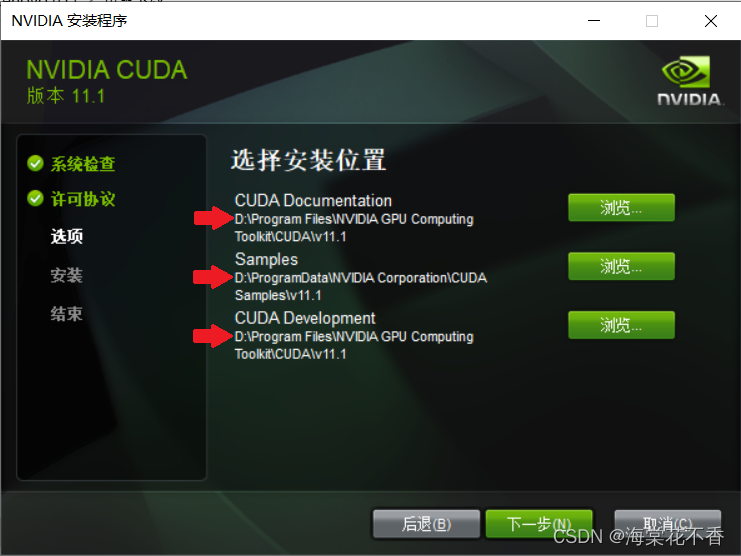
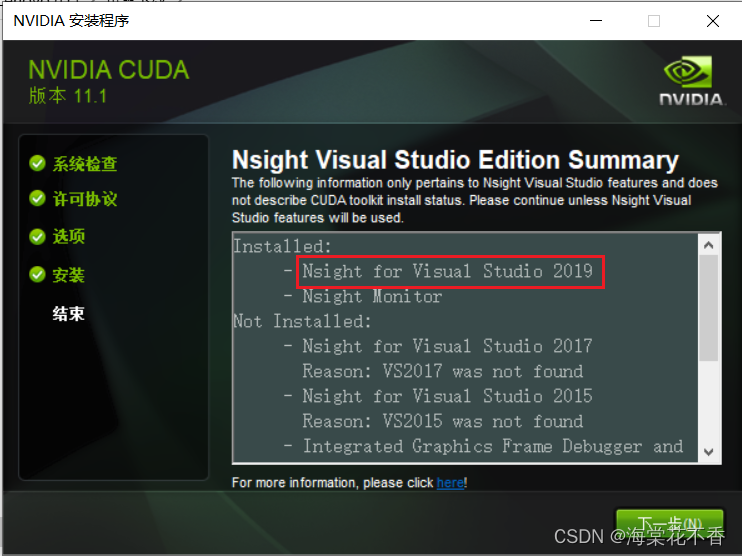
这里检查是否会安装visual studio 2019的配置选项,如果没有,则无法配置成功。
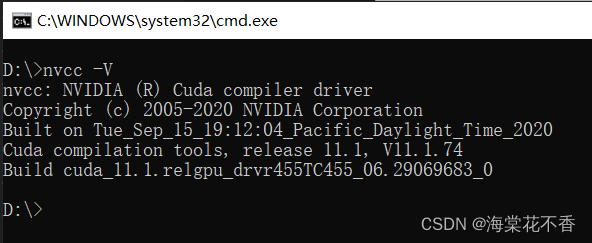
此步骤安装成功,在命令行输入nvcc -V可以显示cuda的版本信息。
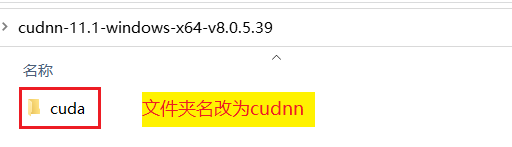
对于cudnn的安装配置则较为简单,将文件下载,解压,改名,复制到指定目录即可。
将改名后的cudnn文件夹拷贝至cuda的安装目录即可。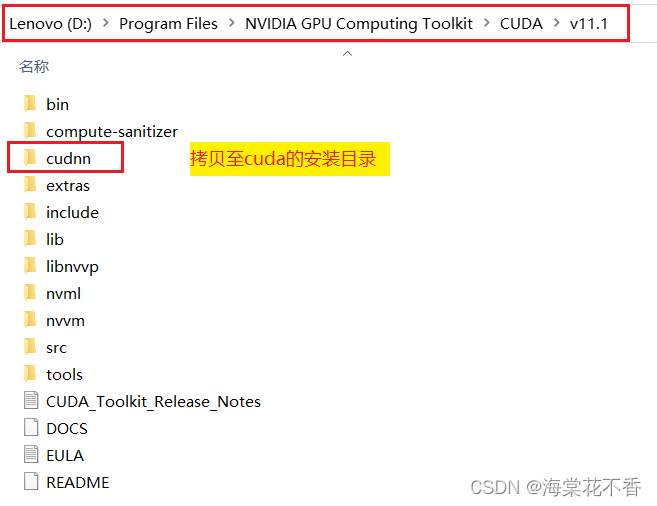
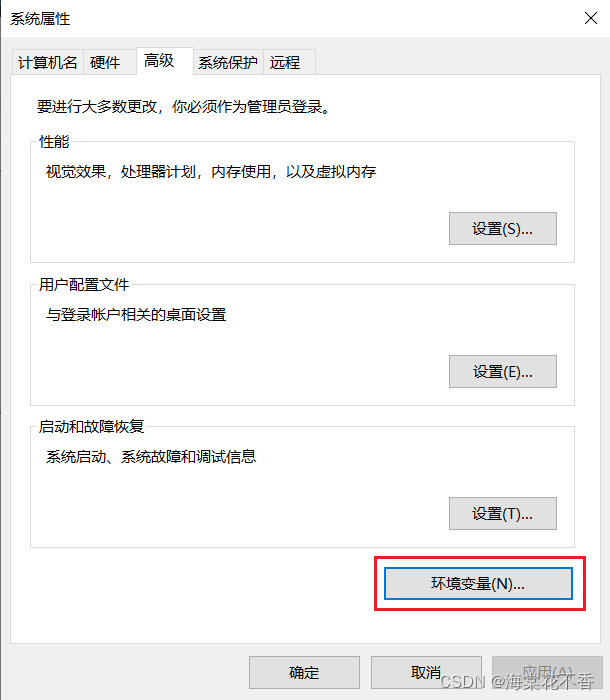
环境变量添加
cuda装完,cuda的安装目录就已经添加到环境变量了。
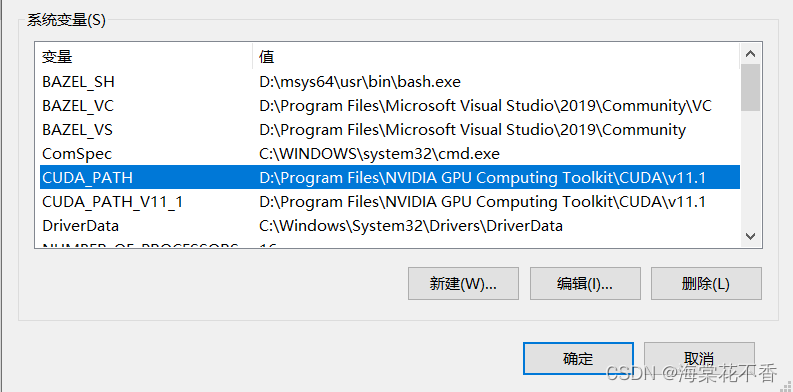
仅需再将cudnn的动态库添加到Path即可。
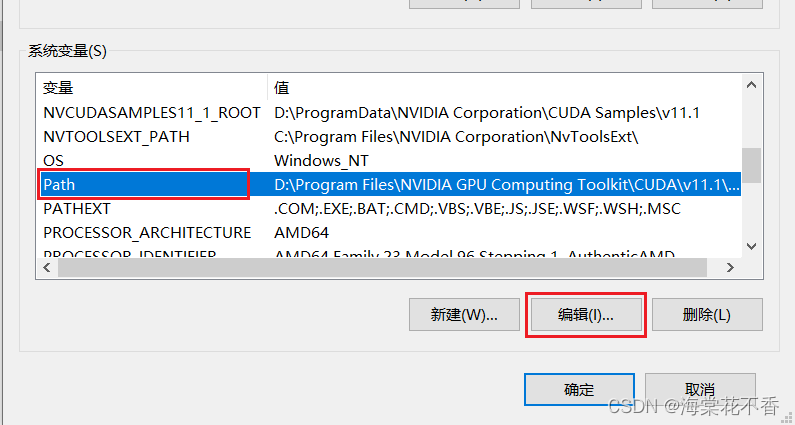
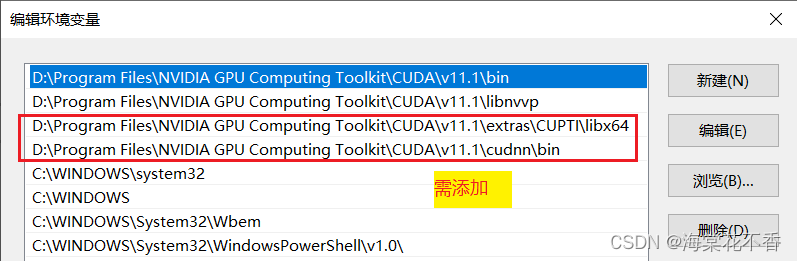
至此,cuda和cudnn的配置过程结束。
配置visual studio的cuda环境
最后一步,也是比较麻烦的一步,配置visual studio的cuda环境。
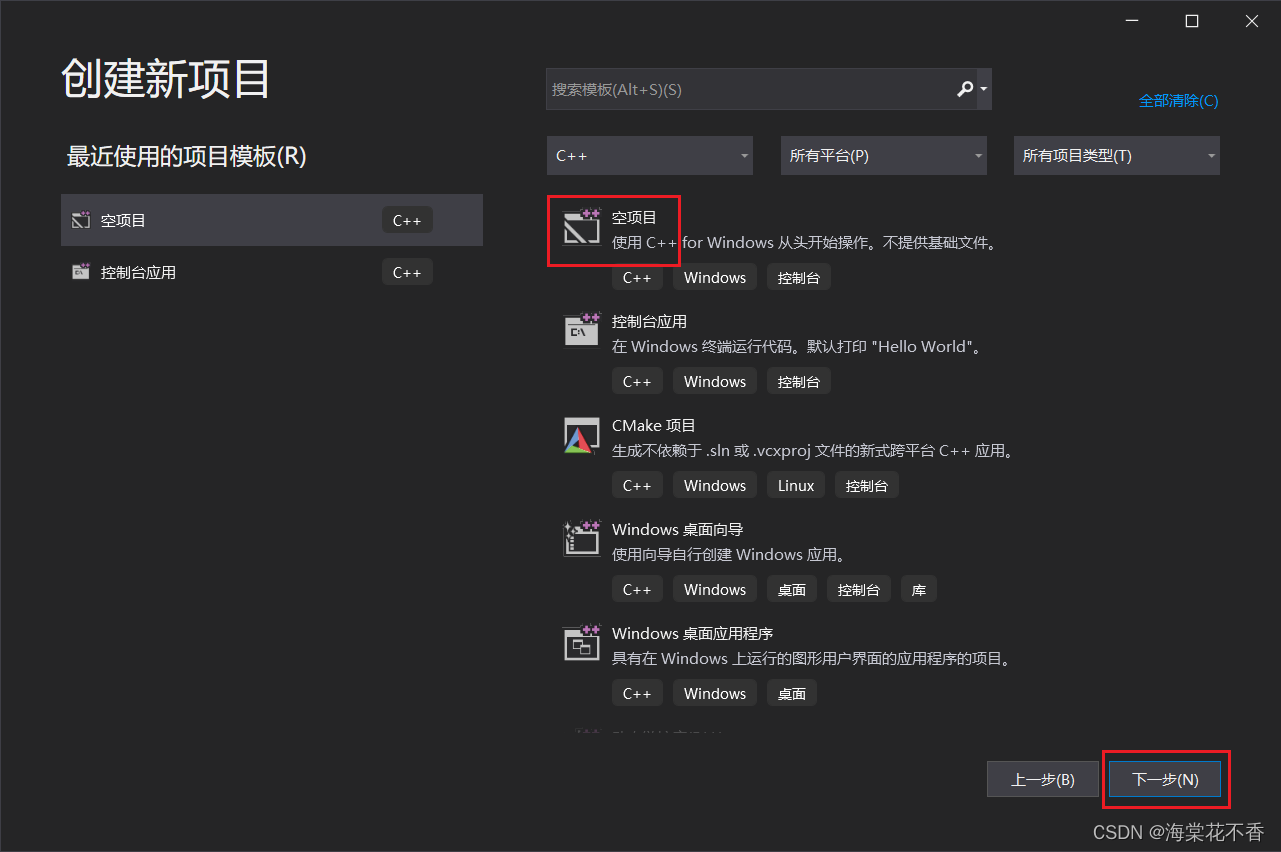
双击visual studio图标,进入软件界面,创建空项目。
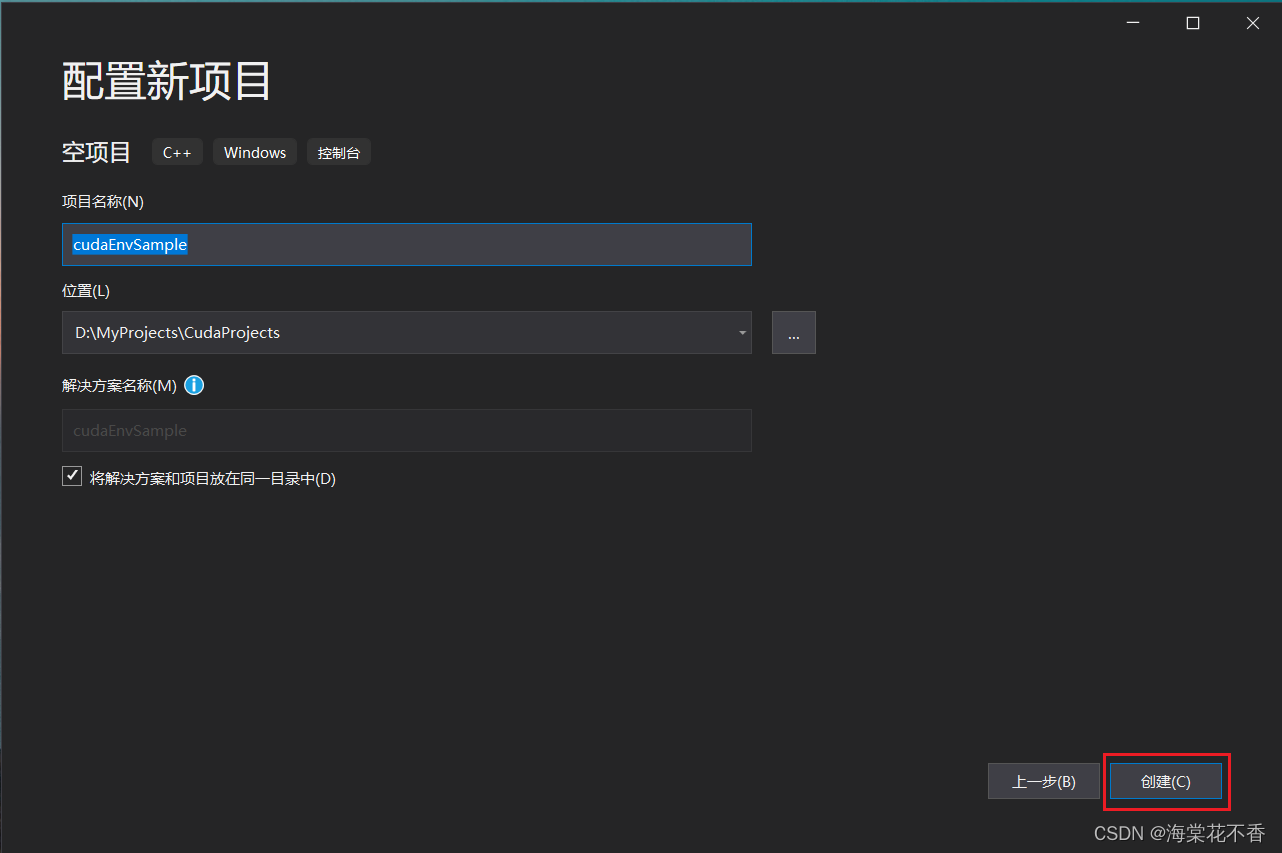
将x86改为x64。
cudaEnvSampleSample的属性列表中选择生成依赖项-生成自定义。
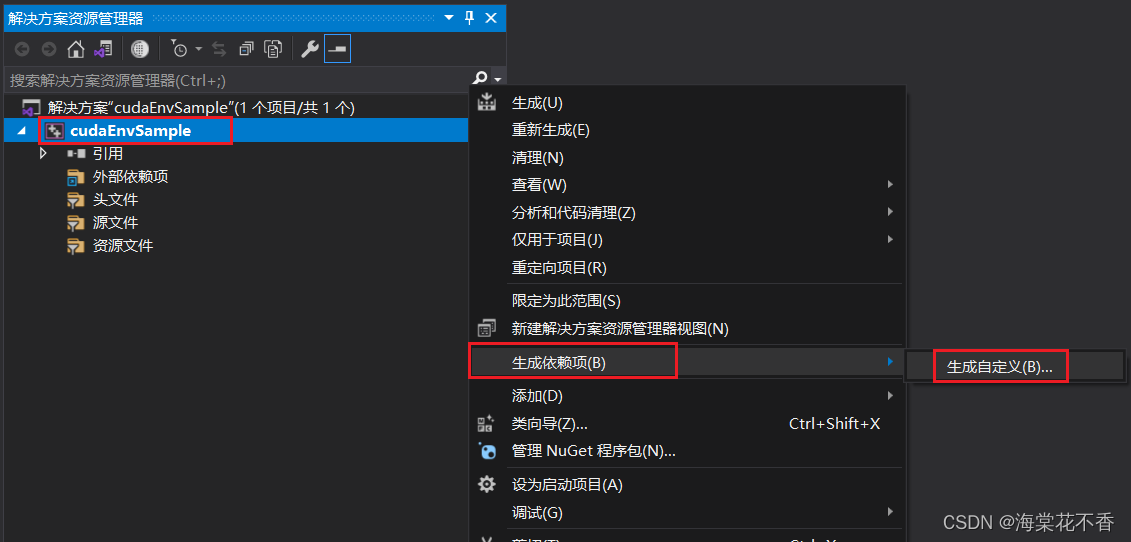
在弹出的Visual C++生成自定义文件中选择第一项,确定。
注:很多同学说这里没找到CUDA11.1(.targets,…)这一项,别着急,先跳过这一部分,新建下面的属性文件,再回来完成这一步。(正确步骤应该是这样的,排版时有一点疏漏)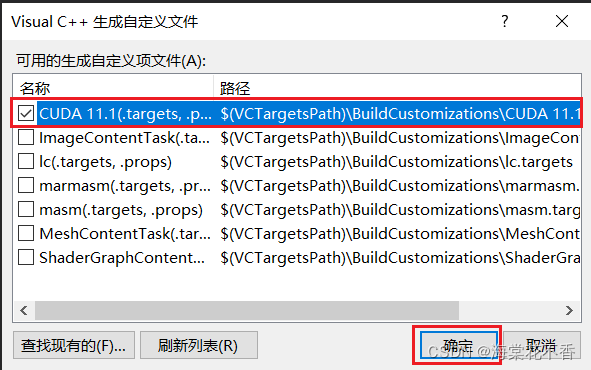
点击视图-属性管理页,进入属性管理器。
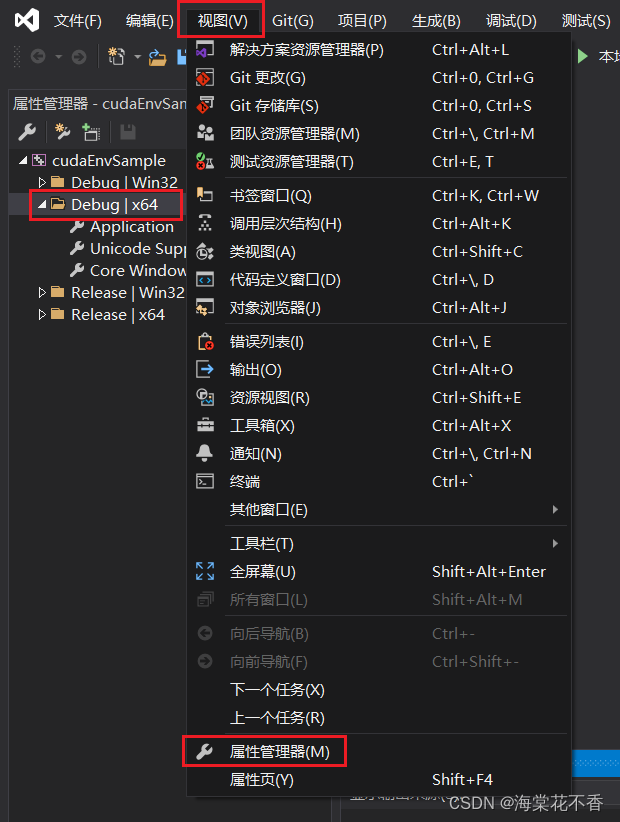
在Debug|x64下添加属性表,表名可以用默认,也可以修改为CudaEnvPropertySheet.props。这个属性表在以后创建其他cuda项目的时候可以复用。到时候只需要添加现有属性表即可。
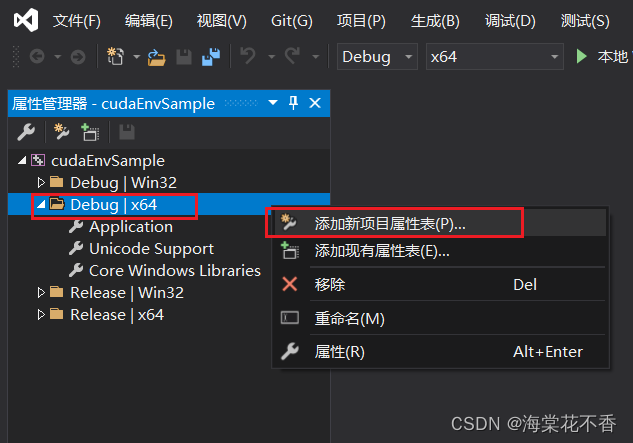
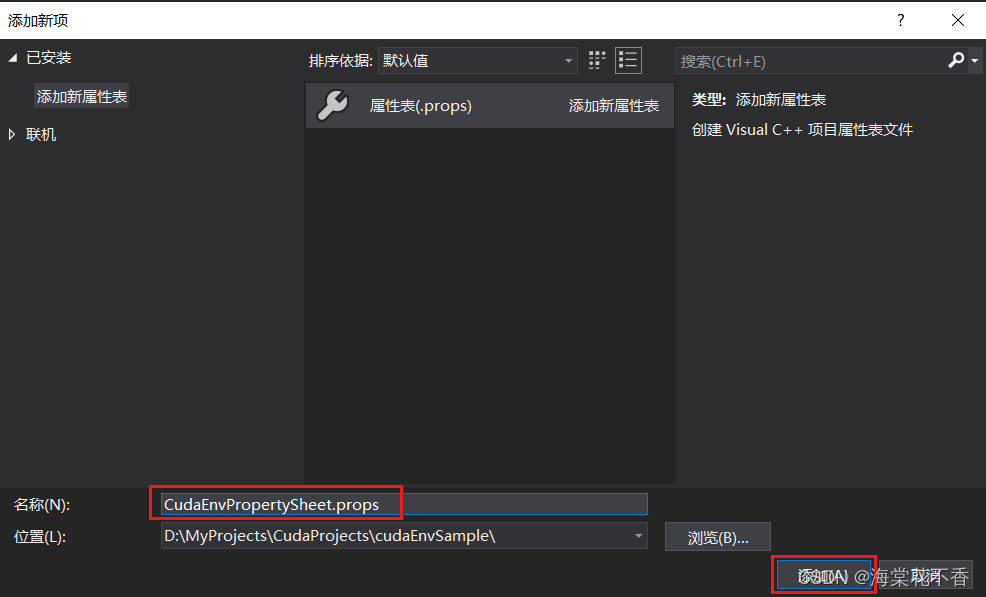
添加后,双击CudaEnvPropertySheet.props文件,出现属性页详细信息。点击通用属性-VC++目录-包含目录,点击编辑,添加所需的头文件路径。
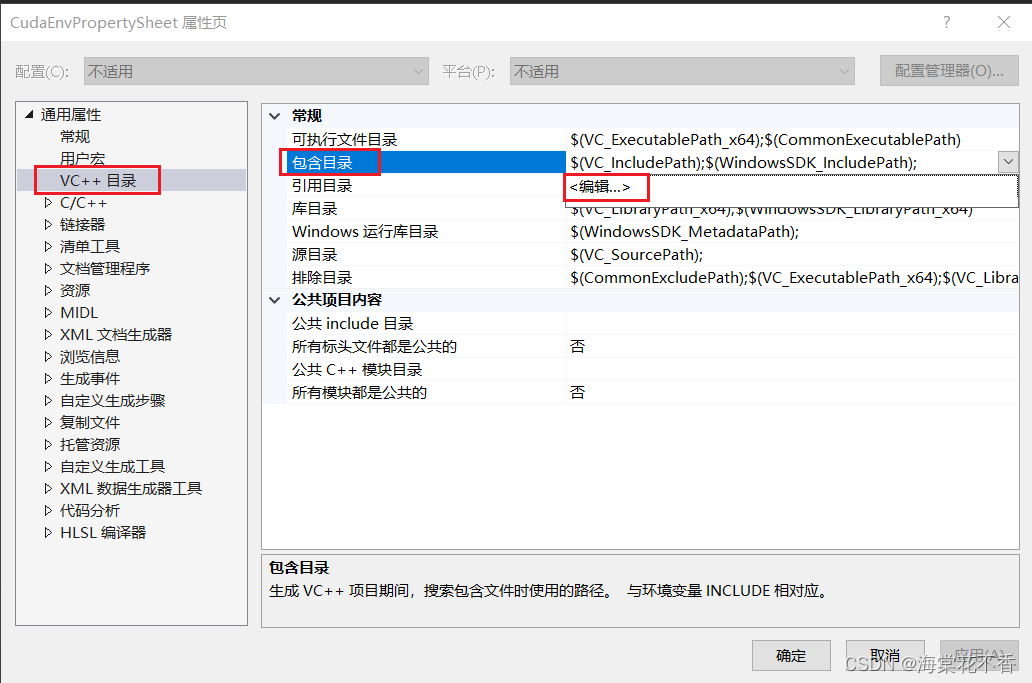
点击添加图标,输入$(CUDA_PATH)\include,确定。
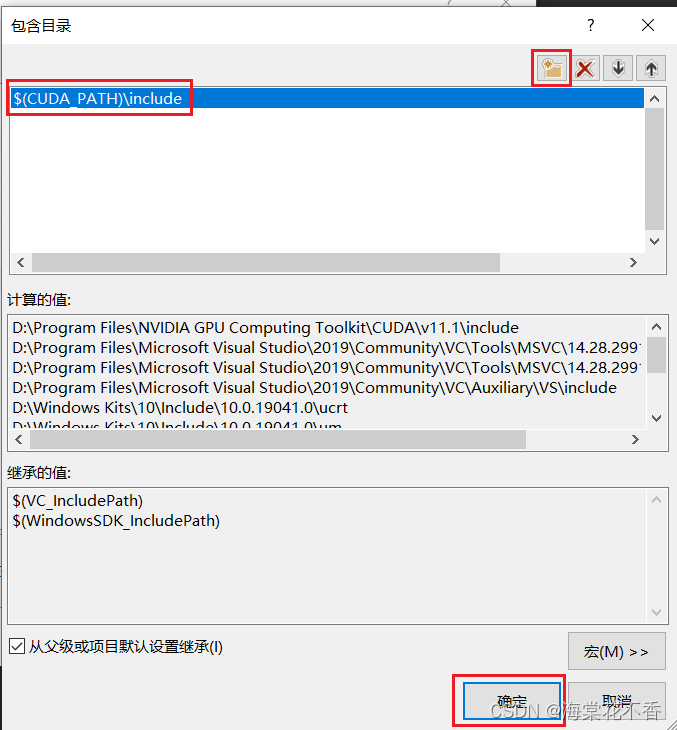
由于测试例程采用的是Samples中的文件,这里需将Samples\common中的头文件一并包含进来。
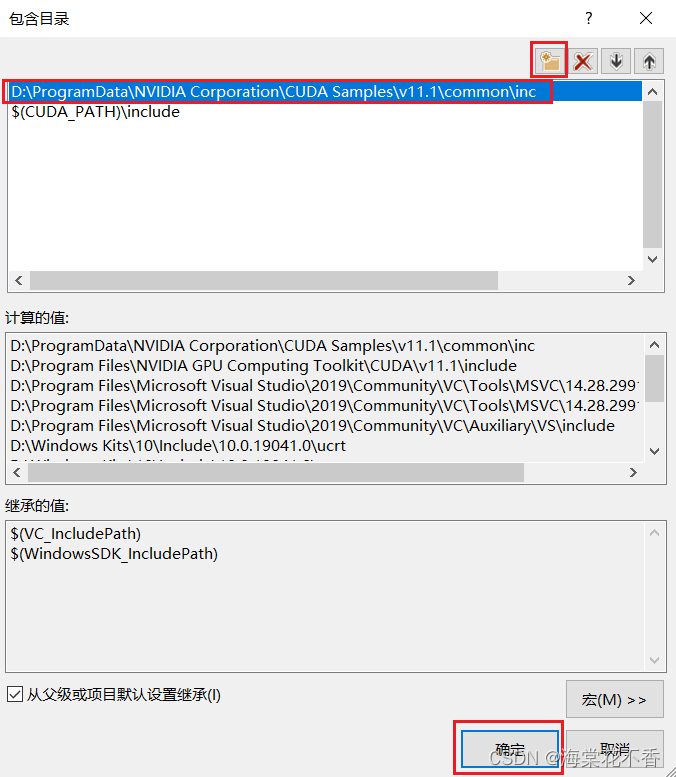
返回属性页,在通用属性-VC++目录-库目录下找到编辑,点击进入,添加库文件(.lib)所在路径。
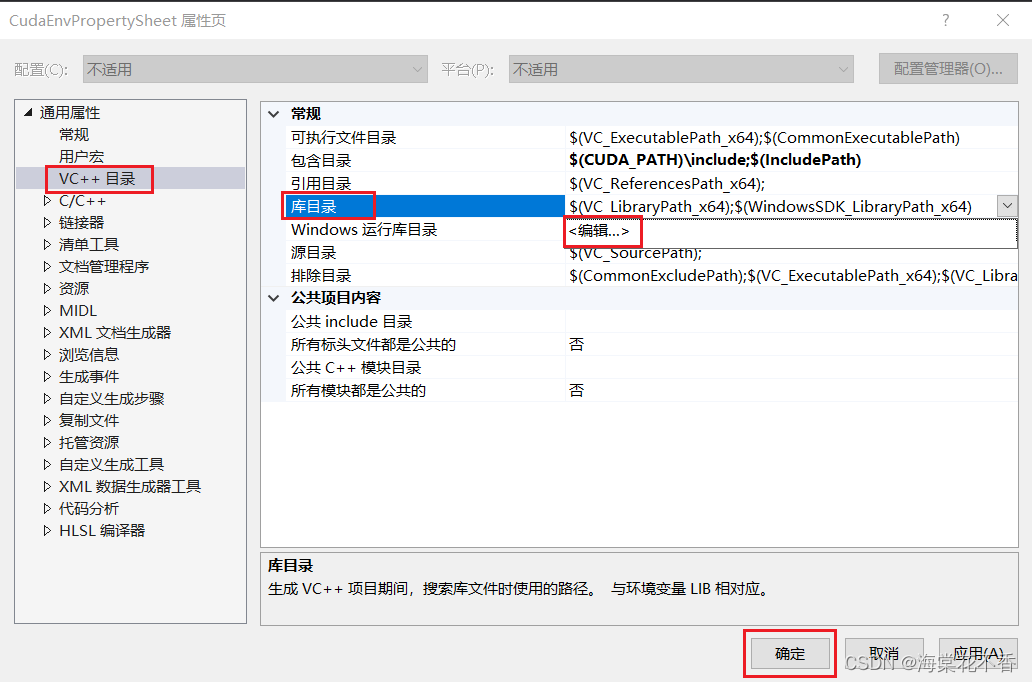
点击添加图标,输入$(CUDA_PATH)\lib\x64,确定。
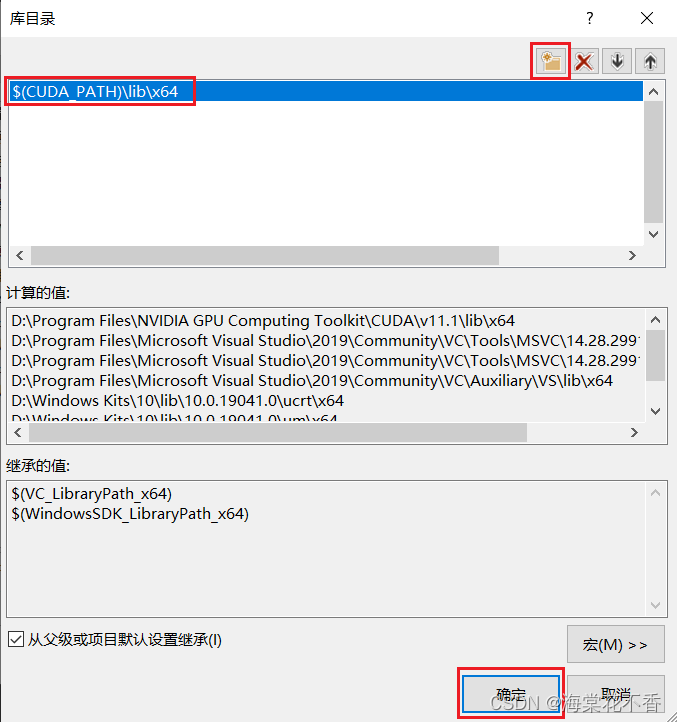

同理,测试例程采用了Sample中的文件,将例程所需的库文件路径一并添加。
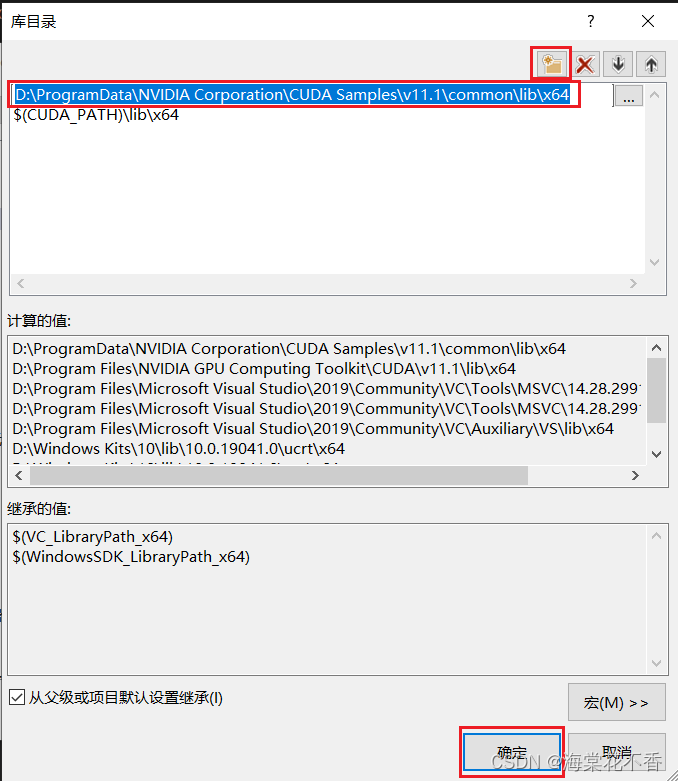
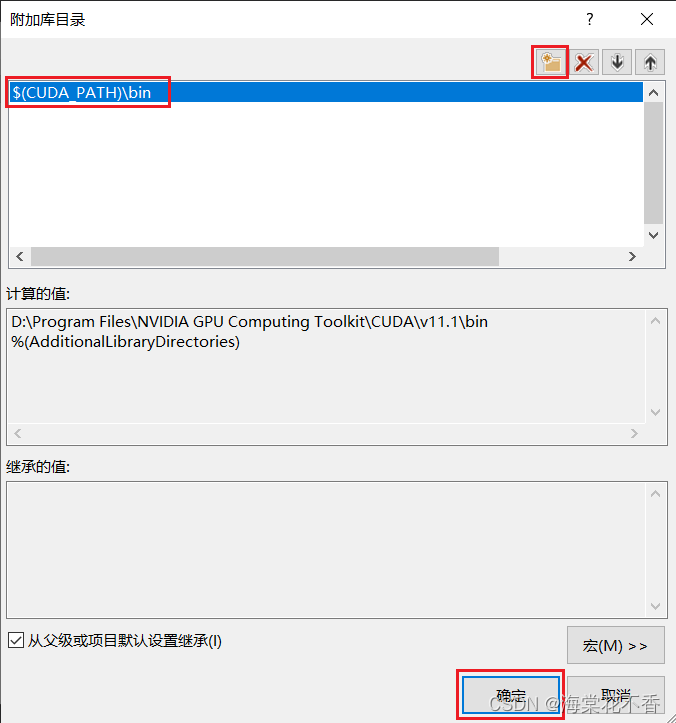
返回属性页,点击链接器-常规-附加库目录,点击编辑,添加动态库所在路径。
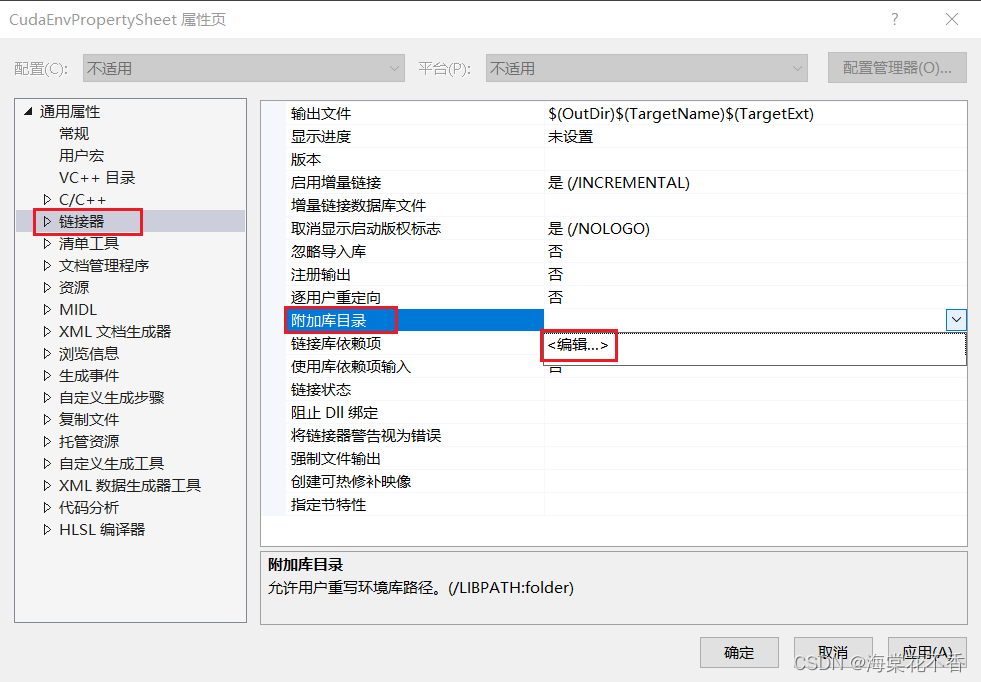
点击添加图标,输入$(CUDA_PATH)\bin,确定。
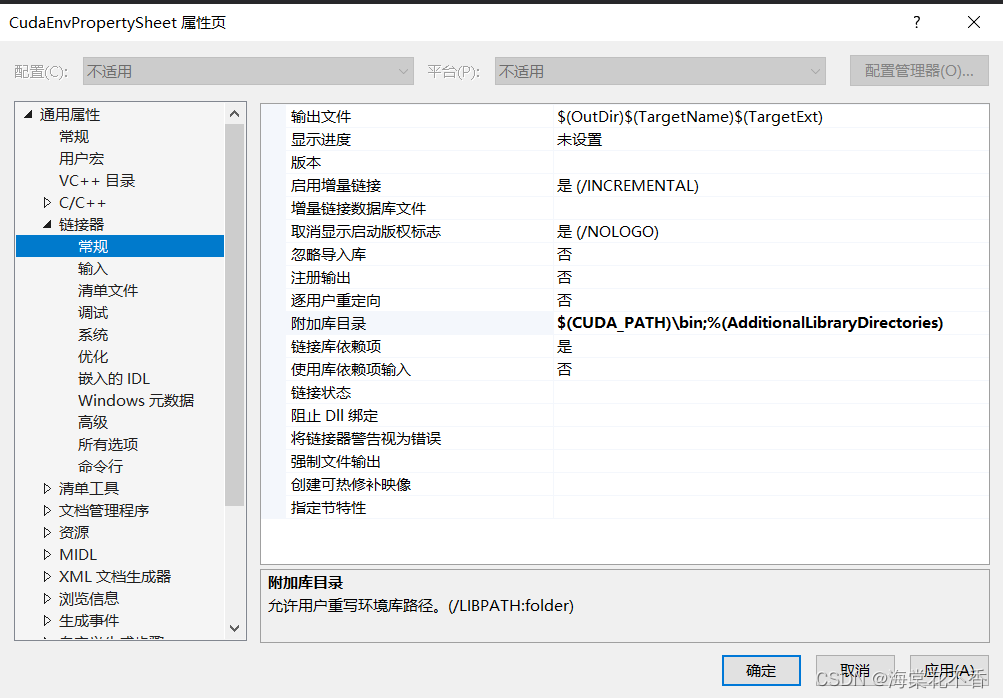
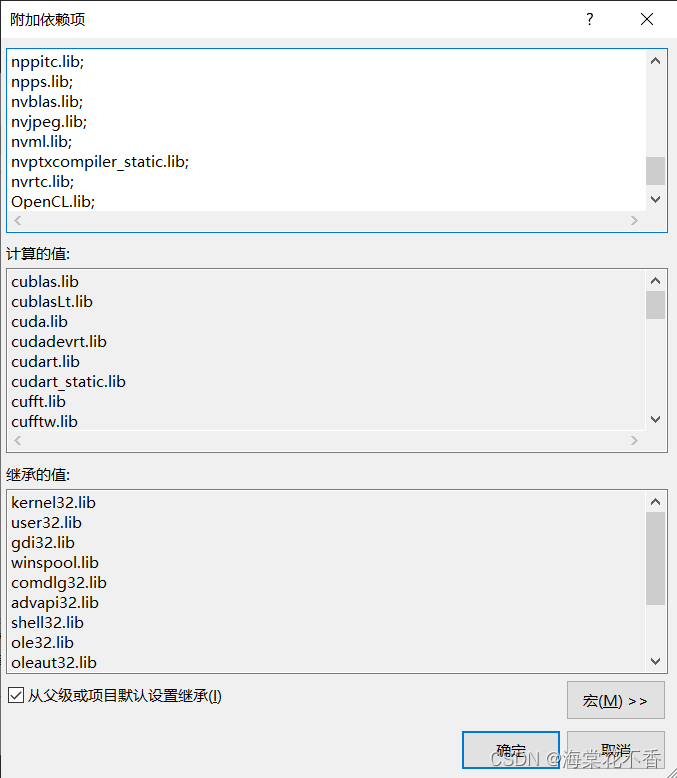
在链接器-输入-附加依赖项中,将所有.lib文件名加入此项中,确定。

具体做法是命令行进入到.lib所在目录,dir /B >res.txt,再打开res.txt,将内容复制到目标框内。
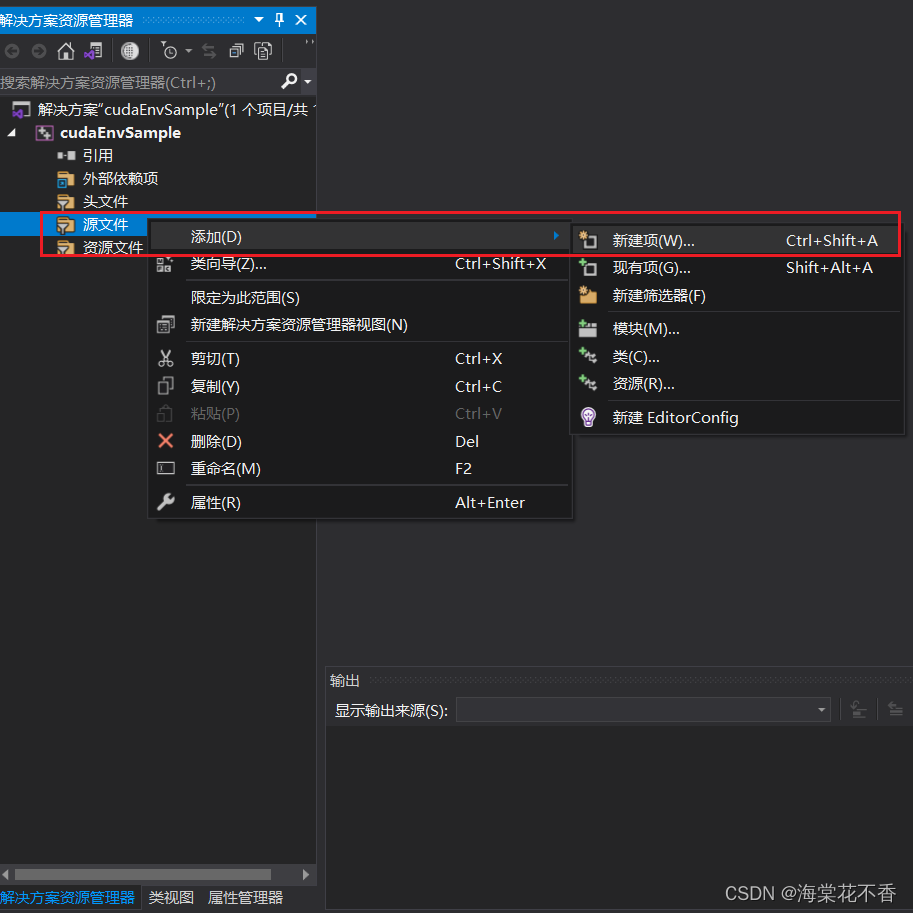
至此,所有基本配置完成。添加一个测试文件。由左下的属性管理器切换至解决方案资源管理器。在cudaEnvSample项目-源文件-添加-新建项中,点击NVIDIA CUDA 11.1中的Code,选择CUDA C/C++ File,点击添加。
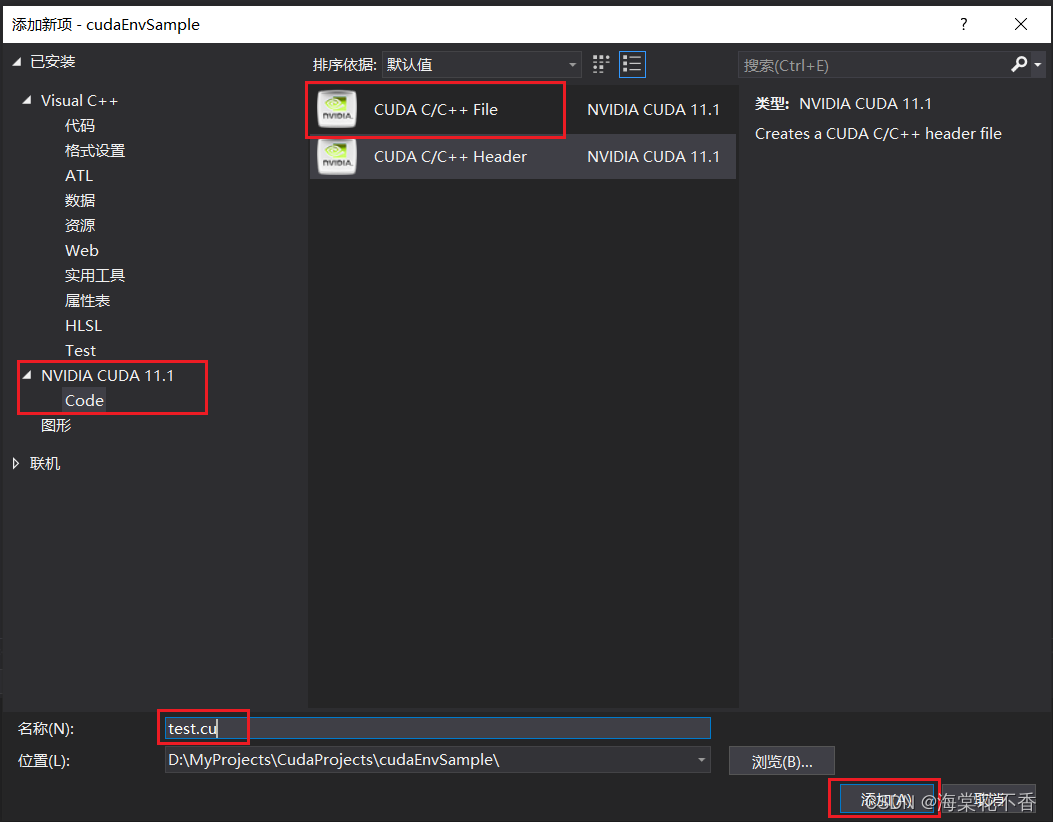
名称中输入test.cu,添加。这里选择Samples中的一个例子来运行,可以自行选择,这里附一个VectorAdd的代码。
#include <stdio.h>
// For the CUDA runtime routines (prefixed with "cuda_")
#include <cuda_runtime.h>
#include <helper_cuda.h>
/**
* CUDA Kernel Device code
*
* Computes the vector addition of A and B into C. The 3 vectors have the same
* number of elements numElements.
*/
__global__ void
vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
/**
* Host main routine
*/
int
main(void)
{
// Error code to check return values for CUDA calls
cudaError_t err = cudaSuccess;
// Print the vector length to be used, and compute its size
int numElements = 50000;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
// Allocate the host input vector A
float *h_A = (float *)malloc(size);
// Allocate the host input vector B
float *h_B = (float *)malloc(size);
// Allocate the host output vector C
float *h_C = (float *)malloc(size);
// Verify that allocations succeeded
if (h_A == NULL || h_B == NULL || h_C == NULL)
{
fprintf(stderr, "Failed to allocate host vectors!\n");
exit(EXIT_FAILURE);
}
// Initialize the host input vectors
for (int i = 0; i < numElements; ++i)
{
h_A[i] = rand()/(float)RAND_MAX;
h_B[i] = rand()/(float)RAND_MAX;
}
// Allocate the device input vector A
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device input vector B
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device output vector C
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the host input vectors A and B in host memory to the device input vectors in
// device memory
printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector A from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector B from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Launch the Vector Add CUDA Kernel
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
err = cudaGetLastError();
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the device result vector in device memory to the host result vector
// in host memory.
printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector C from device to host (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Verify that the result vector is correct
for (int i = 0; i < numElements; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
// Free device global memory
err = cudaFree(d_A);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_B);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_C);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Free host memory
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
}
当添加完成后,便可以点击生成解决方案,窗口会显示调用nvcc编译源文件,生成成功-开始调试,得到以下类似输出即表示配置成功!
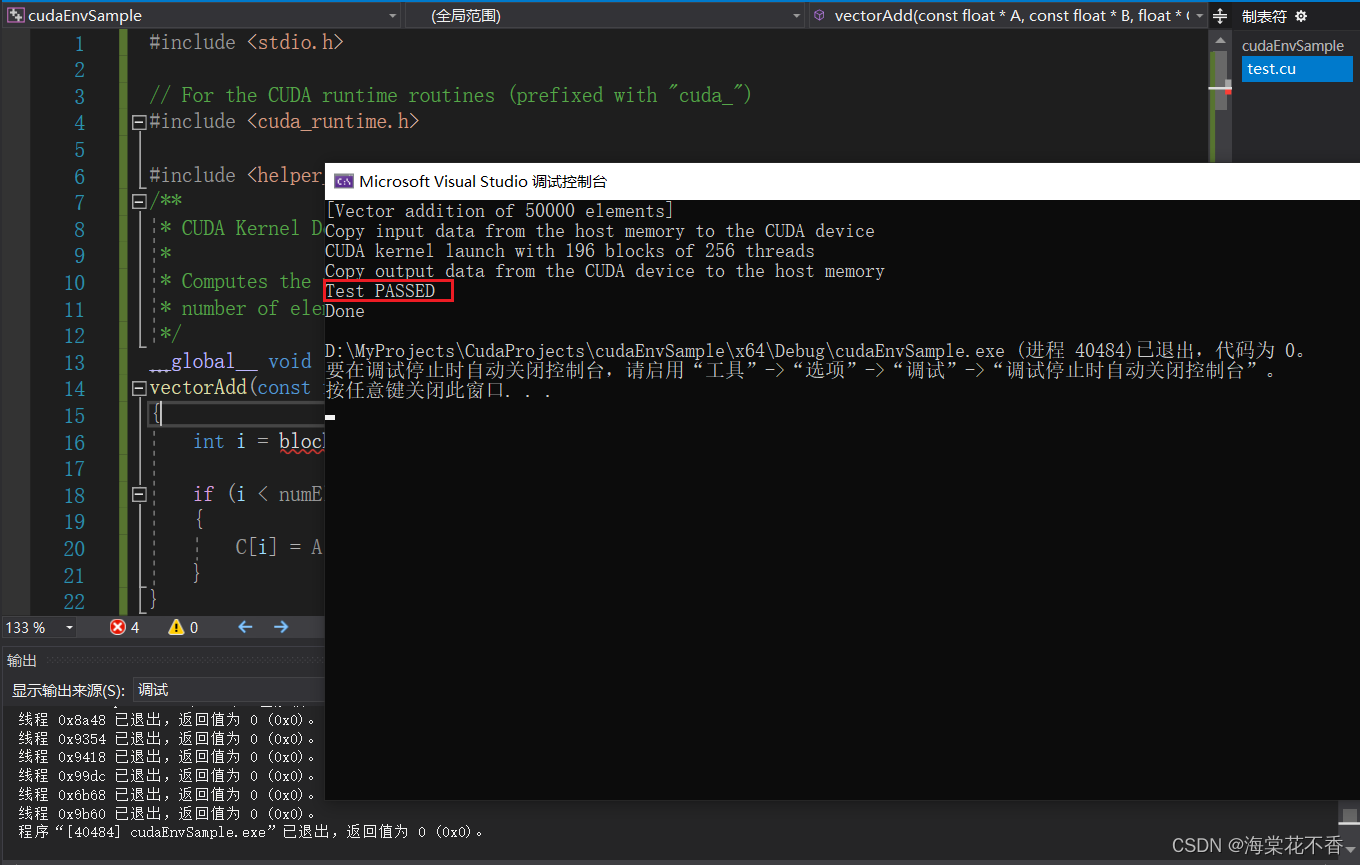
最后再强调一句,CudaEnvProperty.props是可以复用的,以后再新建cuda项目,只需要在新项目中采用该配置文件即可。
版权归原作者 海棠花不香 所有, 如有侵权,请联系我们删除。