
0.知识回顾
1.数据库约束
在认识索引之前,我们有必要回顾一下数据库约束的知识,这对我们之后学习索引有一定的帮助
**约束类型 **
**说明 **
示例
NULL约束
使用NOT NULL指定列不为
空
name varchar(20) not null,
UNIQUE唯一约束
指定列为唯一的、不重复的 name varchar(20) unique,
DEFAULT默认值约
束
指定列为空时的默认值 age int default 20,
主键约束
NOT NULL 和 UNIQUE 的
结合
id int primary key
外键约束
关联其他表的主键或**唯一键 **
foreign key (字段名) references 主
表(列)
CHECK约束(了
解)
保证列中的值符合指定的条件
check (sex ='男' or sex='女')
一.索引
1.什么是索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
可以把索引理解在**书的目录或字典的检索表(拼音检索)**,可以通过目录快还的找到目标记录,这样大大提高了查找的效率

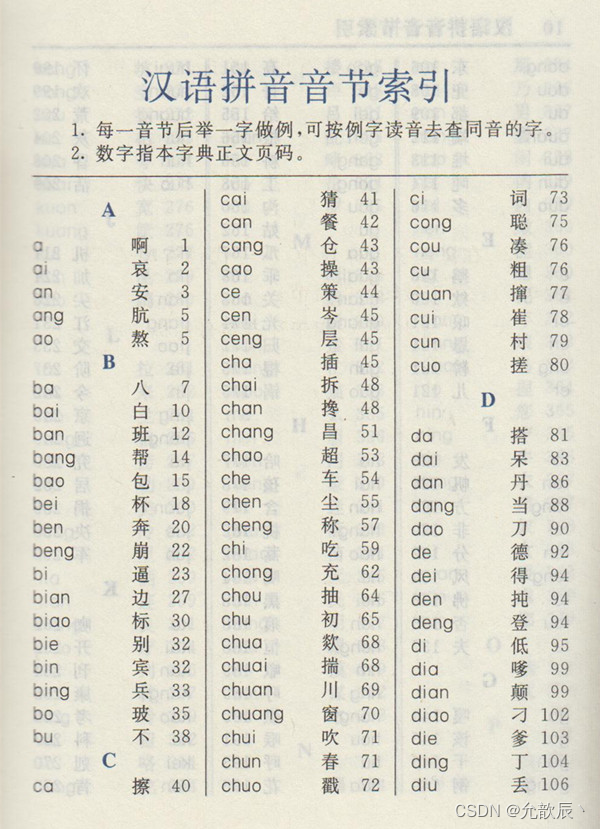
有了索引之后,就可以通过页码,快速定位一个范围,然后再这个小范围内去找,这时的时间复杂度就大大降低了。
那么保存索引也是需要空间的,类似于书的目录,他总是要占那么几页书的厚度,数据库的索引是一个**单独的文件 **
在InnoDB中他和数据文件属于同⼀个⽂件,每个行都会默认给⼀个索引
2.为什么要使用索引(作用)
在前边我们介绍过了使用索引的主要作用就是提高查询效率
我们也提及了保存索引是需要空间的,所以这是一个典型的以空间换时间的操作(类似于数据结构里面的哈希表,但是索引的实现可不是哈希实现的,具体见下文),索引的主要目的就是提高查找的效率(select),但是对于更新(update),删除(delete),插入(insert)的时间开销还是相对较大的,因为不仅要更新表中的数据信息,相应的索引也要进行更新操作.
比如字典中我们要新增和删除一些字的时候,我们在原来的基础上新增了数据,后面内容对应的页码也会发生改变,所以我们对索引也要进行对应的更新
3.索引的使用场景
在上一条中我们分析了索引使用的好处,以及索引使用的一些弊端,这样我们可以来总结一下索引使用的场景.
- 数据量庞大,且经常对这些数据进行查询操作
- 对这些数据很少使用插入,删除和修改操作
- 索引会占用额外的内存空间,内存条件允许
知道这些条件之后,我们在开发中会更好的使用索引进行相应的操作.
4.如何使用索引
在讲述这个之前我们先来创建两张表classes和student
** 创建classes表**
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
`desc` VARCHAR(100)
);
创建student表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY AUTO_INCREMENT,
sn INT UNIQUE,
NAME VARCHAR(20) DEFAULT 'unknown',
qq_mail VARCHAR(20),
classes_id INT,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
同时一张表里至少会有一个索引,当我们我们创建索引的时候,mysql会为每一行生成一个唯一的字段,并将这个字段作为索引
1.查看索引
show index from 表名;
案例:查看student表的索引
show index from student;

之前我们说过了创建的主键约束,唯一约束,外键约束会自动创建对应的索引,这个就可以很好的展现出来
1.Table
表的名称。
2.Non_unique
如果索引不能包括重复词,则为0。如果可以,则为1。
3.Key_name
索引的名称。
4.Seq_in_index
索引中的列序列号,从1开始。
5.Column_name
列名称。
6.Collation
列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)'D'(降序)或NULL(无分类)。
7.Cardinality
索引中唯一值的数目的估计值。通过运行analyze table或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
8.Sub_part
如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则NULL。
9.Packed
指示关键字如何被压缩。如果没有被压缩,则为NULL。
10.Null
如果列含有NULL,则含有YES。如果没有,则该列含有NO。即是否为not null
11.Index_type
使用的索引方法(BTREE(B树), FULLTEXT(全文索引), HASH(哈希), RTREE(R树))。
12.Comment
多种评注。
2.创建索引
create index 索引名 on
表名(字段名 ASC,字段名 DESC......);
可以同时创建多个字段的索引.可以指定是升序还是降序进行创建索引
3.修改索引
alter index 旧索引名 rename to 新索引名
4.删除索引
drop
index 索引名 on
表名;
5.索引的分类
1.使用场景不同
**1.普通索引 **
**普通索引是最基本的索引类型,对数据类型没有限制,主要的作用就是增加访问速度 **
**create index 索引名 on 表名(字段名); **** **
例如给sn字段创建索引名为index_id的索引
create index index_sn on student(sn);
2.唯一索引
唯一索引与普通索引类似,不同的是创建唯一性索引的目的不是为了提高访问速度,而是为了避免数据出现重复。
create unique index index_id on student(id);
3.主键索引
主键索引是一种特殊的唯一索引,不允许值重复或者值为空。
创建主键索引通常使用 primary key 关键字。不能使用 create index 语句创建主键索引。
4.空间索引
**空间索引主要用于地理空间数据类型 GEOMETRY,并且要求声明的数据类型是NOT NULL,**空间索引只能在存储引擎为 MyISAM 的表中创建。初学者很少使用
CREATE SPATIAL INDEX index_line ON tb_student(line);
5. 全文索引
全文索引主要用来查找文本中的关键字,只能在 char、varchar或 text类型的列上创建。在 MySQL 中只有 MyISAM 存储引擎支持全文索引。全文索引允许为null和重复值.
create fulltext index index_name on student(name);
2.按列区分
1.单列索引
单列索引:创建的索引只包含一个原表中的字段,在表中的一个字段建立索引.
单列索引可以使普通索引,唯一索引和主键索引
例如
create (unique) index index_id on student(id (ASC or DESC));
2.组合索引
组合索引也叫做多列索引和复合索引.多列索引在一个表的多个字段建立一个索引.该索引指向表中的多个字段,可以通过多个字段组合进行查询,但是,只有当查询条件中包含了这些字段的第一个字段的时候,组合索引才会生效.
例如,对student表中的name和qq_mail字段建立组合索引
create index index_name_qqmail on student(name,qq_mail);
该索引创建好了以后,查询条件中必须有 name 字段才能使用索引。 比如我们查询name='张三'的人的信息,这个时候组合索引会生效,但是我们仅仅查询age=18的人,这个组合索引便不会生效
3.按数据组织方式
1.聚簇索引
如果⼀张表里有主键,那么主键必然是索引,主键索引也叫聚簇索引, 而且一直存在这也是我
们绝大部分情况下的使用场景.
2.非聚簇索引
如果自己手动创建索引,那会会为这个列或是列的组合(多个列)创建单独的索引,非聚簇索
引
二.索引的数据结构
对于数据库来说,索引使用什么数据结构可以做到时间复杂度最低呢?
1.HASH
索引主要针对的就是查找操作,在数据结构中我们学习过哈希这种数据结构,查找的时间复杂度O(1),这看起来十分符合索引的目的(也就是查找),但是仔细思考就可以发现,哈希主要针对的是查找某一条的数据,而数据库查找中,我们需要查找的是符合条件的一组数据(范围查找),比如我们查找student表中id在10到20之间的学生信息,这个时候hash明显是不支持的
2.二叉搜索树和红黑树
那么二叉搜树是否可以作为索引的数据结构呢?仔细想想是不可以的,平均时间复杂度O(logn),但是最差的时间复杂度为O(n)(插入有序的一组元素),和全表搜索一样了.
这时候我们是否可以考虑平衡二叉搜索树或者红黑树呢?这种数据结构可以很好的解决二叉搜索树的缺点同时利用其优点.
其实也是不合适的.为什么呢? 因为当数据量很大的时候,树的高度会很高,增大了磁盘的IO次数
我们先这样理解:树的高度决定了磁盘的IO次数.每向孩子结点访问一级,就会发生磁盘IO,而在一个系统中,对性能影响最大的就是磁盘IO,所以我们需要一种能控制树的高度的树结构
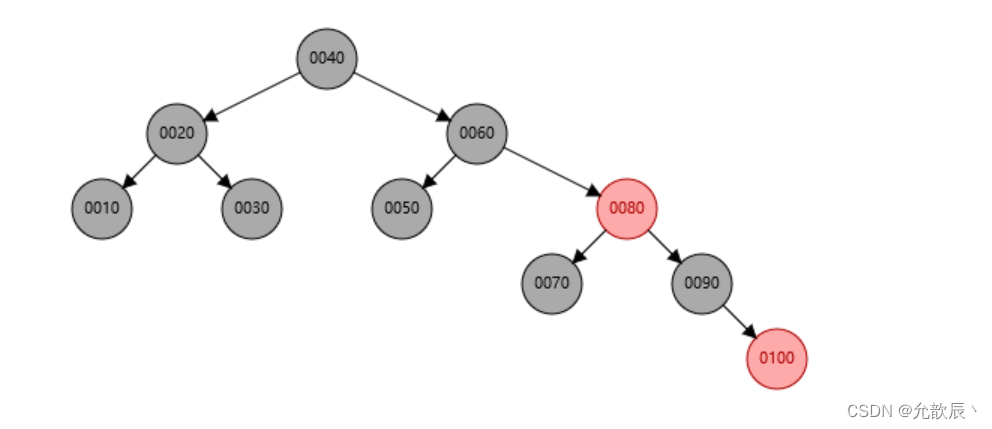
3.N叉搜索树---B 树
B树是一颗多叉搜索树,因此可以很大程度上减少树的高度.我们可以自主的规定一个结点保存多少个值,当结点大于这个值的时候才可能去增加树的高度
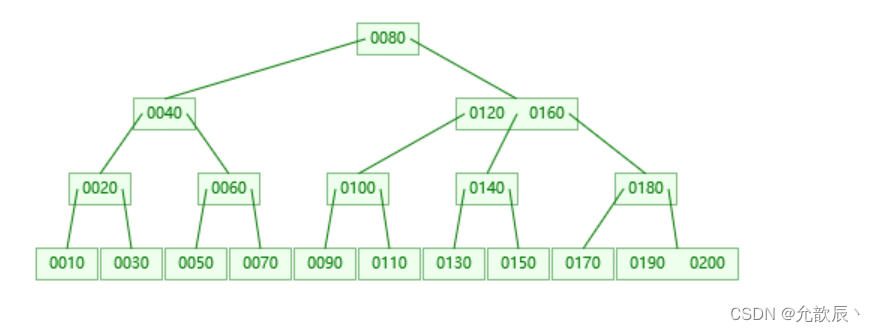
但是数据库默认使用的不是B树这种数据结构来实现索引,使用的却是B+树,B+树其实是在B树的基础上进行了优化
4.B+树

观察B+树我们可以发现
非叶子节点中的每个数据都存在于叶⼦节点中,并且都是对应所在叶子节点中的第⼀条数据
Mysql中的B+树是⼀个循环双向链表,相邻节点是通过双向链表连接的,这样组织数据更有利⽤范****围查找
最重要的是,叶子节点中的数据是有序的
N叉搜索树,有效的降低了树的高度,从而减少了磁盘IO次数
对于B+树而言,在相同树高的情况下,查找任一元素的时间复杂度都⼀样,中间比较次数也差不多,也就是说性能均衡,只要控制树高,就可以达到性能可控的效果
只有叶子结点存储了真实完整的数据,非叶子结点,只保存了主键(索引)的值和子节点的引用
三.explain的使用
1.explain的使用
我们可以使用explain来查看SQL语句的执行
explain select * from student;

2.explain查询的属性含义

以下全部详细解析explain各个属性含义:
id: 查询的序列号
select_type: 查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询
SIMPLE:查询中不包含子查询或者UNION查询中若包含任何复杂的子部分,最外层查询则被标记为:
PRIMARY在
SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERYtable: 输出的行所引用的表
type: 访问类型
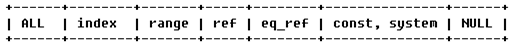
**从左至右,性能由差到好**
ALL: 扫描全表
index: 扫描全部索引树
range: 扫描部分索引,索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
ref: 使用非唯一索引或非唯一索引前缀进行的查找(
eq_ref和const的区别:)eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
const, system: 单表中最多有一个匹配行,查询起来非常迅速,例如根据主键或唯一索引查询。system是const类型的特例,当查询的表只有一行的情况下, 使用system。
NULL: 不用访问表或者索引,直接就能得到结果,如
select 1 from test where 1**possible_keys: **表示查询时可能使用的索引。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引
**key: **显示MySQL实际决定使用的索引。如果没有索引被选择,是NULL
**key_len: **使用到索引字段的长度
注:key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
**ref: **显示哪个字段或常数与key一起被使用
**rows: **这个数表示mysql要遍历多少数据才能找到,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,在innodb上可能是不准确的
**Extra: **执行情况的说明和描述。包含不适合在其他列中显示但十分重要的额外信息。
Using index:表示使用索引,如果只有 Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。
Using where:表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where。
内容来源:explain属性
四.索引覆盖
1.索引覆盖
索引覆盖是指在查询过程中,所需的所有数据都可以从索引中获取,而不必读取数据表的实际数据页。因为索引只包含表中的部分列数据,而且索引存储在内存或磁盘中,所以在使用索引进行查询时可以大大降低磁盘I/O操作的次数,提高查询效率。同时,由于不必读取数据表的实际数据页,索引覆盖可以减少查询所需的内存空间,降低内存压力。通常情况下,如果一个查询只需要从索引中获取所需的所有列数据,那么就可以称之为索引覆盖查询。
create index index_name_qqmail student(name,qq_mail)
当我们执行以下查询的时候,我们就进行了索引覆盖
select name,qq_mail from student where name='张三'
因为我们之前创建了name和qq_mail的索引,所以我们在进行索引查找找到了name='张三'的数据之后,我们根据索引存储的name和qq_mail信息,便可以直接把查询到的信息输出,没有必要再去主表进行查询操作了
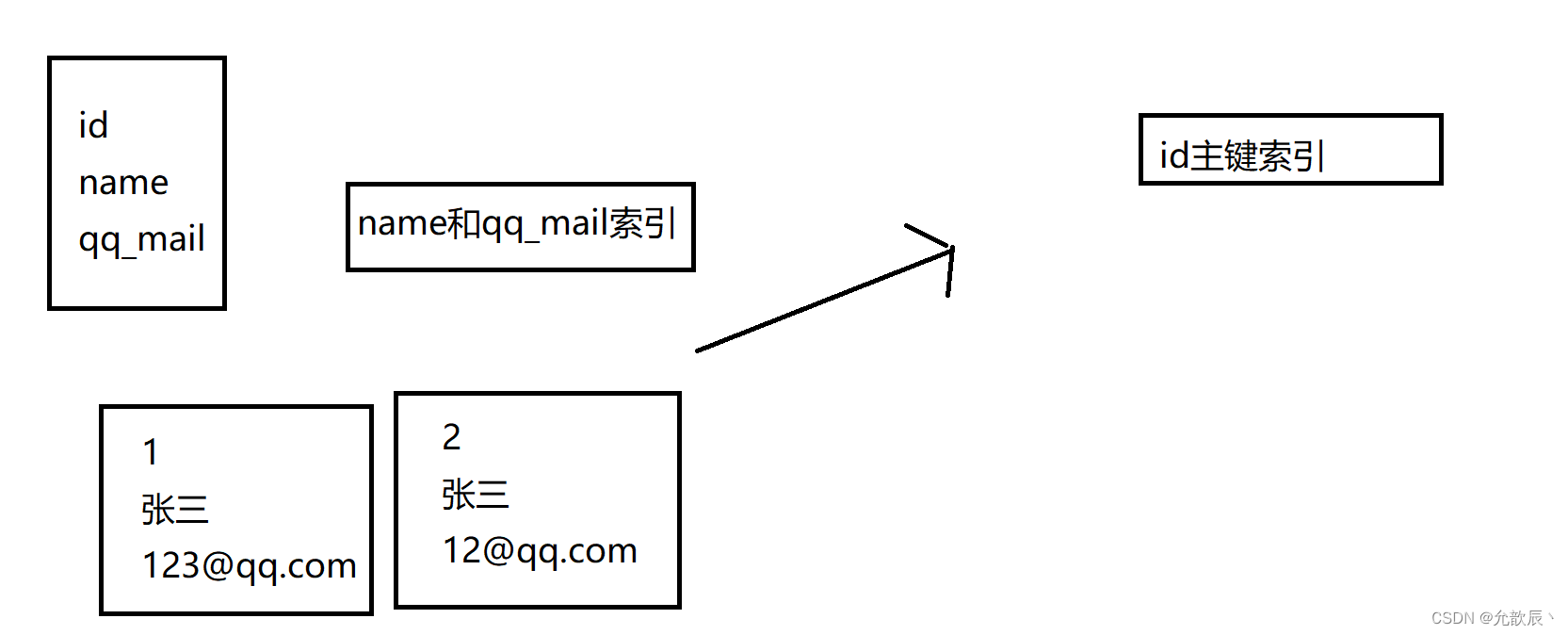
2.回表查询
回表查询和上边的操作有一些区别,当我们在索引查询到指定字段时候,但是不能完全满足查询条件(比如查询id,sn,name,qq_mail,classes_id,而索引只包含name和qq_mail的信息),这个时候我们使用到id到主键索引中查询到完整的信息(主键索引包含当前数据行中所有列的值)
比如创建了组合索引name和qq_mail,这个时候我们执行下面的select语句
select * from student where name='张三'
这个时候name和qq_mail的组合索引中并没有*的全部信息,所以我们查询到符合条件的name和qq_mail的id,然后到根据id到主键索引中寻找到完整的信息
五.索引失效
1.什么是索引失效
索引失效指的是索引在某些查询条件下无法使用,导致查询效率降低或者查询无法执行的情况。索引失效可能出现的原因包括但不限于:
**1. **最左原则:类似于字典的目录,这就是⼀个典型的复合索引
比如我们常见了一个组合索引(name,qq_mail),而我们查询的时候只是用了qq_mail进行筛选,这个时候索引就失效了
explain select * from student where name='张三'

explain select * from student where qq_mail='张三'

**2. **判断不等:每个都要判断
**3. **类型转换:与原类型不符
**4. **like '%xxx':第⼀个字符都不能确定,怎么去索引中⽐较呢?
**5. **索引列运算 age + 1:改了原来的值
**6. **is null 或 is not null : 全表扫描了
版权归原作者 允歆辰丶 所有, 如有侵权,请联系我们删除。