
1. 引言
我们上一次讲到了Multi-agent的基本概念,现在来讲讲具体的训练方法,以Actor-Critic方法为例。
2. 训练架构
我们知道在Single-agent中的Actor-Critic方法中需要一个策略函数 作为Actor进行执行action,还有一个价值函数
进行评价来辅助决策。在Multi-agent中我们就是要对这两个函数进行讨论从而引出三种结构。
2.1 Fully decentralized
完全去中心化(Fully decentralized),这一种结构完全仿照Single-agent使用Actor-Critic方法进行训练,将多个智能体看出一个个单智能体,分别使用Actor-Critic方法,具体就是使用对于第 个agent,以
作为策略函数(由于每个智能体通常不能观测到全局的state,我们用
代替
表示agent观测到的state)使用策略梯度下降更新参数,它接收一个state输出动作的概率分布,以
作为价值函数,使用TD 算法更新参数,输入state和action输出一个打分辅助决策。所有的agents都使用相同的方法并行训练。
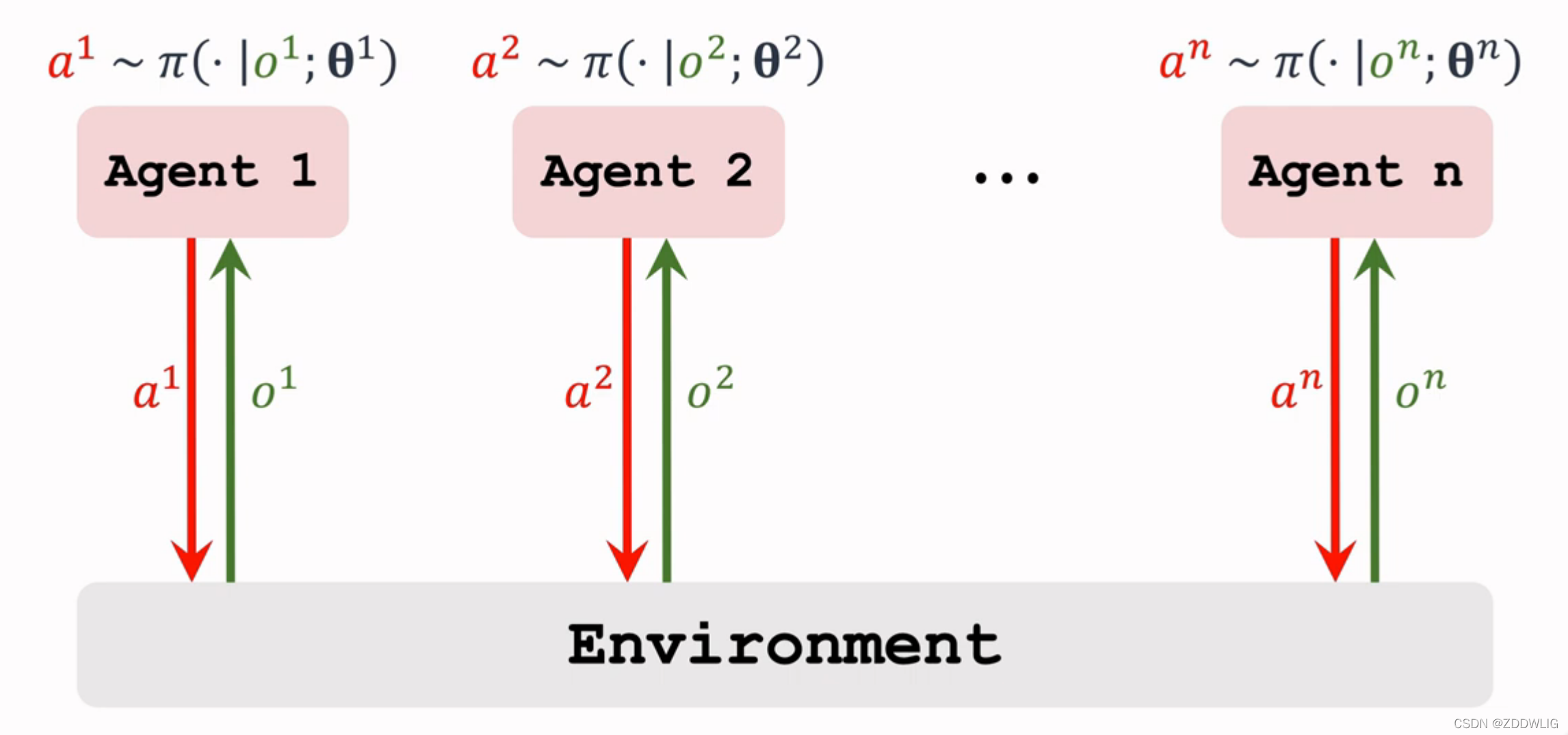
这种方法没考虑agent之间的相互作用,不适用于大部分情况。
2.2 Fully centralized
完全中心化(Fully centralized),考虑到agent之间有交互影响,我们引入一个中心处理器(Central controller),我们将所有的agent的观测值 传入中心处理器,中心处理器中有
个策略函数,对应第
个agent的策略函数为
,对应第
个agent的价值函数为
,每个agent都将与环境交互获得的
传入中心处理器,中心处理器同时处理所有agent的信息,这也是和 Fully decentralized 方法的最大不同,最后中心处理器再返回action给对应的agent即可。
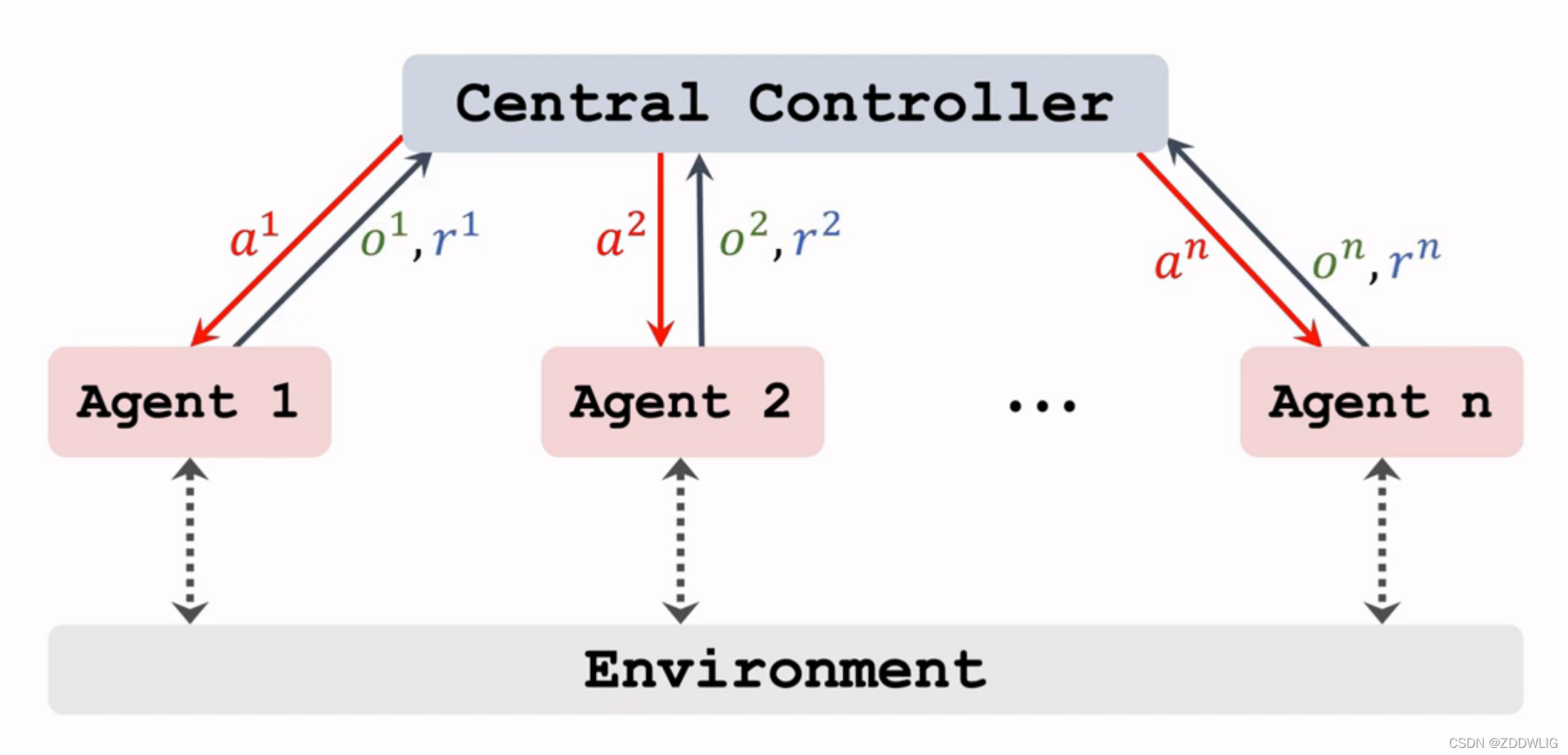
这种方法也有个缺点就是训练太慢,因为中心处理器需要处理所有agent的信息,这是非常耗时的。
2.3 Centralized&Decentralized
中心化训练去中心化执行(Centralized training,decentralized execution),这种方法就是为了解决完全中心化训练缓慢的问题,它只在中心处理器设置 个策略函数,第
个agent的价值函数为
,策略函数
在agent本身,每个agent都将与环境交互获得的
传入中心处理器,中心处理器返回
的输出给agent,agent再训练策略函数
,最后策略网络输出action。
agent与环境交互

agent将信息传入中心处理器

中心处理器返回打分供agent训练策略网络

版权归原作者 ZDDWLIG 所有, 如有侵权,请联系我们删除。