

Flink入门案例
需求:读取本地数据文件,统计文件中每个单词出现的次数。
一、IDEA Project创建及配置
本案例编写Flink代码选择语言为Java和Scala,所以这里我们通过IntelliJ IDEA创建一个目录,其中包括Java项目模块和Scala项目模块,将Flink Java api和Flink Scala api分别在不同项目模块中实现。步骤如下:
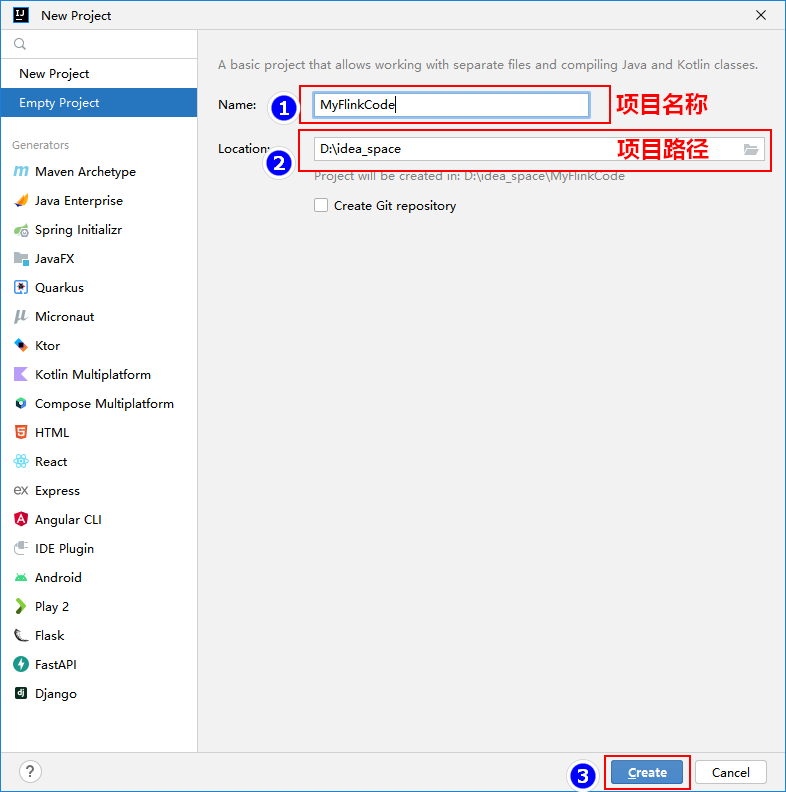
1、打开IDEA,创建空项目
2、在IntelliJ IDEA 中安装Scala插件
使用IntelliJ IDEA开发Flink,如果使用Scala api 那么还需在IntelliJ IDEA中安装Scala的插件,如果已经安装可以忽略此步骤,下图为以安装Scala插件。

3、打开Structure,创建项目新模块
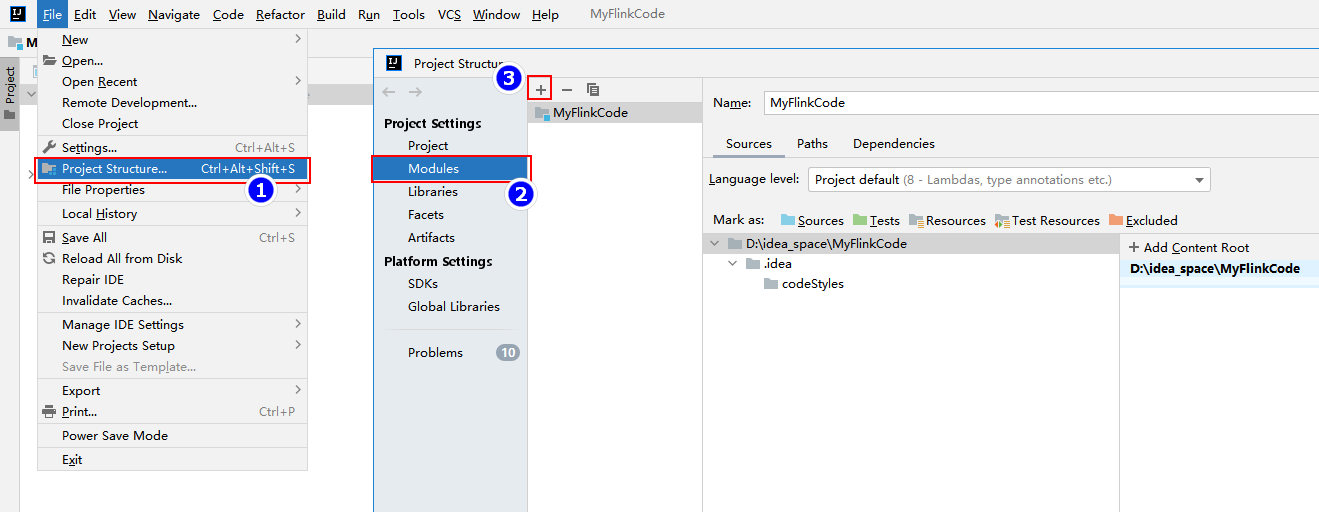
创建Java模块:
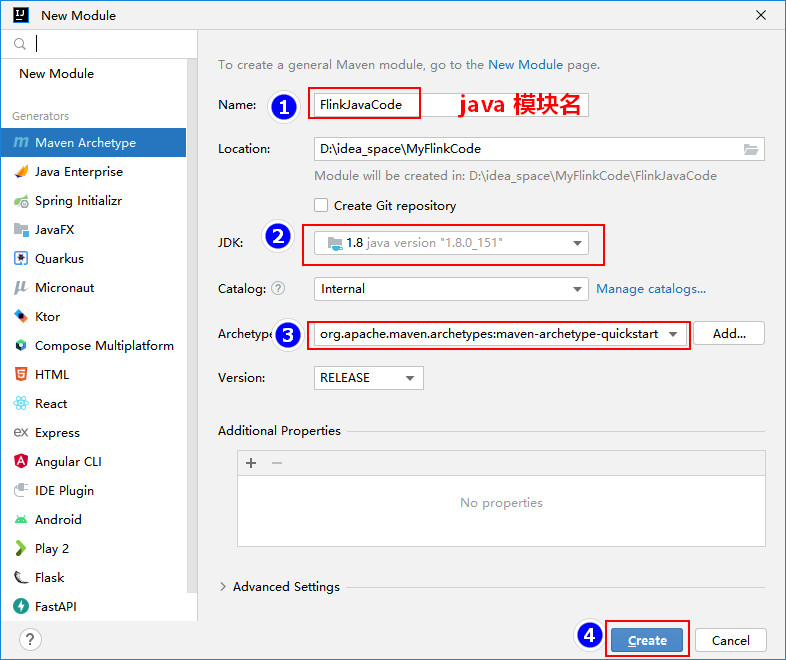
继续点击"+",创建Scala模块:
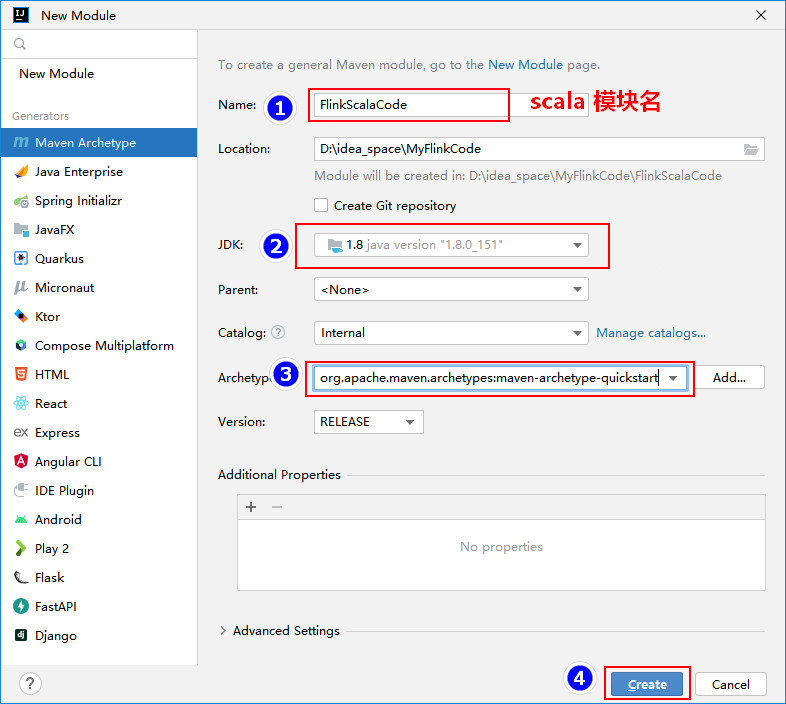
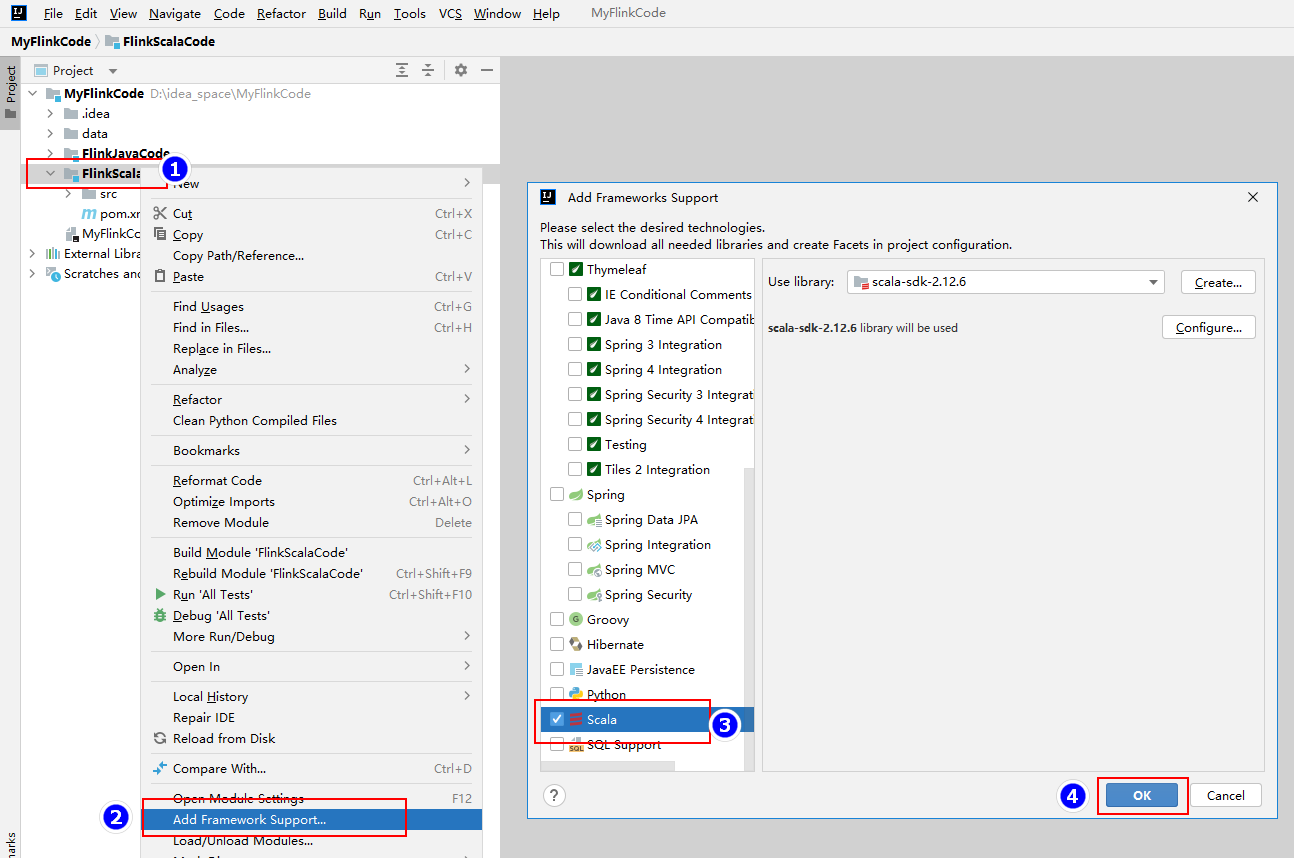
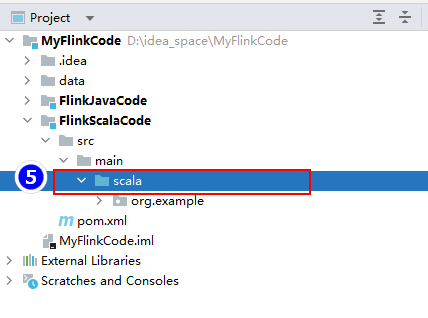
创建好"FlinkScalaCode"模块后,右键该模块添加Scala框架支持,并修改该模块中的"java"src源为"scala":
在"FlinkScalaCode"模块Maven pom.xml中引入Scala依赖包,这里使用的Scala版本为2.12.10。
<!-- Scala包 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.12.10</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.12.10</version>
</dependency>
4、Log4j日志配置
为了方便查看项目运行过程中的日志,需要在两个项目模块中配置log4j.properties配置文件,并放在各自项目src/main/resources资源目录下,没有resources资源目录需要手动创建并设置成资源目录。log4j.properties配置文件内容如下:
log4j.rootLogger=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{HH:mm:ss} %p %c{2}: %m%n
并在两个项目中的Maven pom.xml中添加对应的log4j需要的依赖包,使代码运行时能正常打印结果:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.36</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.17.2</version>
</dependency>
5、分别在两个项目模块中导入Flink Maven依赖
"FlinkJavaCode"模块导入Flink Maven依赖如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.16.0</flink.version>
<slf4j.version>1.7.36</slf4j.version>
<log4j.version>2.17.2</log4j.version>
</properties>
<dependencies>
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- slf4j&log4j 日志相关包 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
"FlinkScalaCode"模块导入Flink Maven依赖如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.16.0</flink.version>
<slf4j.version>1.7.31</slf4j.version>
<log4j.version>2.17.1</log4j.version>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Scala包 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- slf4j&log4j 日志相关包 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
注意: 在后续实现WordCount需求时,Flink Java Api只需要在Maven中导入"flink-clients"依赖包即可,而Flink Scala Api 需要导入以下三个依赖包:
flink-scala_${scala.binary.version}
flink-streaming-scala_${scala.binary.version}
flink-clients
主要是因为在Flink1.15版本后,Flink添加对opting-out(排除)Scala的支持,如果你只使用Flink的Java api,导入包不必包含scala后缀,如果使用Flink的Scala api,需要选择匹配的Scala版本。
二、案例数据准备
在项目"MyFlinkCode"中创建"data"目录,在目录中创建"words.txt"文件,向文件中写入以下内容,方便后续使用Flink编写WordCount实现代码。
hello Flink
hello MapReduce
hello Spark
hello Flink
hello Flink
hello Flink
hello Flink
hello Java
hello Scala
hello Flink
hello Java
hello Flink
hello Scala
hello Flink
hello Flink
hello Flink
三、案例实现
数据源分为有界和无界之分,有界数据源可以编写批处理程序,无界数据源可以编写流式程序。DataSet API用于批处理,DataStream API用于流式处理。
批处理使用ExecutionEnvironment和DataSet,流式处理使用StreamingExecutionEnvironment和DataStream。DataSet和DataStream是Flink中表示数据的特殊类,DataSet处理的数据是有界的,DataStream处理的数据是无界的,这两个类都是不可变的,一旦创建出来就无法添加或者删除数据元。
1、Flink 批数据处理案例
- Java版本WordCount
使用Flink Java Dataset api实现WordCount具体代码如下:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//1.读取文件
DataSource<String> linesDS = env.readTextFile("./data/words.txt");
//2.切分单词
FlatMapOperator<String, String> wordsDS =
linesDS.flatMap((String lines, Collector<String> collector) -> {
String[] arr = lines.split(" ");
for (String word : arr) {
collector.collect(word);
}
}).returns(Types.STRING);
//3.将单词转换成Tuple2 KV 类型
MapOperator<String, Tuple2<String, Long>> kvWordsDS =
wordsDS.map(word -> new Tuple2<>(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.按照key 进行分组处理得到最后结果并打印
kvWordsDS.groupBy(0).sum(1).print();
Scala版本WordCount
使用Flink Scala Dataset api实现WordCount具体代码如下:
//1.准备环境,注意是Scala中对应的Flink环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换,使用Scala API 时需要隐式转换来推断函数操作后的类型
import org.apache.flink.api.scala._
//3.读取数据文件
val linesDS: DataSet[String] = env.readTextFile("./data/words.txt")
//4.进行 WordCount 统计并打印
linesDS.flatMap(line => {
line.split(" ")
})
.map((_, 1))
.groupBy(0)
.sum(1)
.print()
以上无论是Java api 或者是Scala api 输出结果如下,显示的最终结果是统计好的单词个数。
(hello,15)
(Spark,1)
(Scala,2)
(Java,2)
(MapReduce,1)
(Flink,10)
2、Flink流式数据处理案例
- Java版本WordCount
使用Flink Java DataStream api实现WordCount具体代码如下:
//1.创建流式处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文件数据
DataStreamSource<String> lines = env.readTextFile("./data/words.txt");
//3.切分单词,设置KV格式数据
SingleOutputStreamOperator<Tuple2<String, Long>> kvWordsDS =
lines.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.分组统计获取 WordCount 结果
kvWordsDS.keyBy(tp->tp.f0).sum(1).print();
//5.流式计算中需要最后执行execute方法
env.execute();
- Scala版本WordCount
使用Flink Scala DataStream api实现WordCount具体代码如下:
//1.创建环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.导入隐式转换,使用Scala API 时需要隐式转换来推断函数操作后的类型
import org.apache.flink.streaming.api.scala._
//3.读取文件
val ds: DataStream[String] = env.readTextFile("./data/words.txt")
//4.进行wordCount统计
ds.flatMap(line=>{line.split(" ")})
.map((_,1))
.keyBy(_._1)
.sum(1)
.print()
//5.最后使用execute 方法触发执行
env.execute()
以上输出结果开头展示的是处理当前数据的线程,一个Flink应用程序执行时默认的线程数与当前节点cpu的总线程数有关。
3、DataStream BATCH模式
下面使用Java代码使用DataStream API 的Batch 模式来处理批WordCount代码,方式如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置批运行模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
DataStreamSource<String> linesDS = env.readTextFile("./data/words.txt");
SingleOutputStreamOperator<Tuple2<String, Long>> wordsDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {
@Override
public void flatMap(String lines, Collector<Tuple2<String, Long>> out) throws Exception {
String[] words = lines.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1L));
}
}
});
wordsDS.keyBy(tp -> tp.f0).sum(1).print();
env.execute();
以上代码运行完成之后结果如下,可以看到结果与批处理结果类似,只是多了对应的处理线程号。
3> (hello,15)
8> (Flink,10)
8> (Spark,1)
7> (Java,2)
7> (Scala,2)
7> (MapReduce,1)
此外,Stream API 中除了可以设置Batch批处理模式之外,还可以设置 AUTOMATIC、STREAMING模式,STREAMING 模式是流模式,AUTOMATIC模式会根据数据是有界流/无界流自动决定采用BATCH/STREAMING模式来读取数据,设置方式如下:
//BATCH 设置批处理模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//AUTOMATIC 会根据有界流/无界流自动决定采用BATCH/STREAMING模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//STREAMING 设置流处理模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
除了在代码中设置处理模式外,还可以在Flink配置文件(flink-conf.yaml)中设置execution.runtime-mode参数来指定对应的模式,也可以在集群中提交Flink任务时指定execution.runtime-mode来指定,Flink官方建议在提交Flink任务时指定执行模式,这样减少了代码配置给Flink Application提供了更大的灵活性,提交任务指定参数如下:
$FLINK_HOME/bin/flink run -Dexecution.runtime-mode=BATCH -c xxx xxx.jar
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Lansonli 原创,首发于 CSDN博客🙉
📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。