
一、VMware 虚拟机安装
(1)虚拟机创建及配置
VMware下载地址
VMware的安装过程比较简单,正常安装就行,打开后是以下页面:

点击文件==》新建虚拟机








这里选择提前下载好的CentOS镜像:

点击开启此虚拟机
Enter回车,开始安装CentOS镜像:
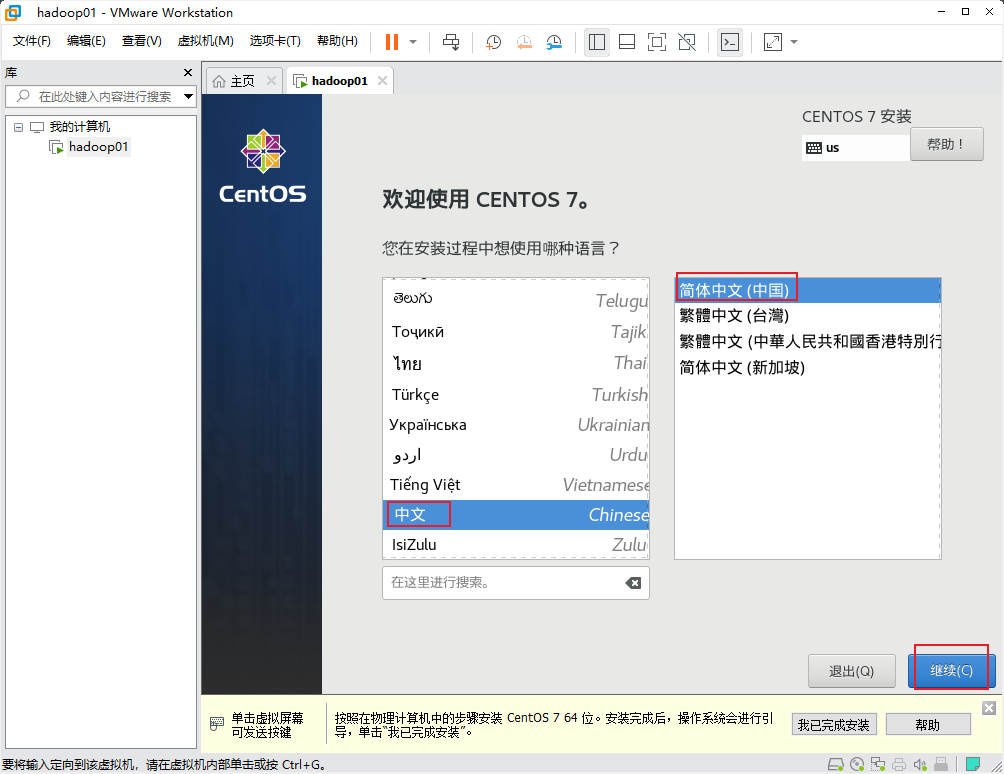
选择语言:
设置日期:

安装位置点进去,点击完成:

KDUMP禁用:

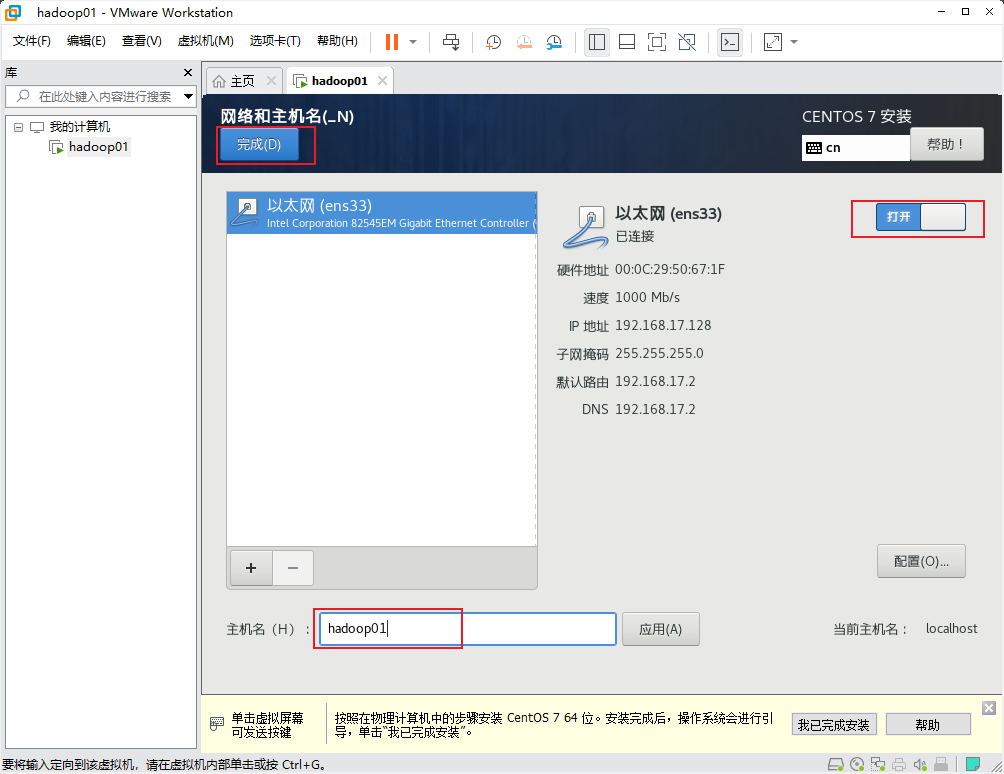
网络和主机名:
点击开始安装:

设置密码

这里要是密码设置过于简单,点击两次完成即可,后面就会继续执行安装了,等待执行完成,店点击重启按钮,重启后进入一下界面:

输入root和密码之后进入虚拟机:

(2)创建工作文件夹
在hadoop01上执行:
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software
二、克隆虚拟机
搭建集群需要3个虚拟机,hadoop01,hadoop02,hadoop03,已经安装了hadoop01,剩下两个需要用到虚拟机克隆。
先关闭hadoop01虚拟机:

点击克隆

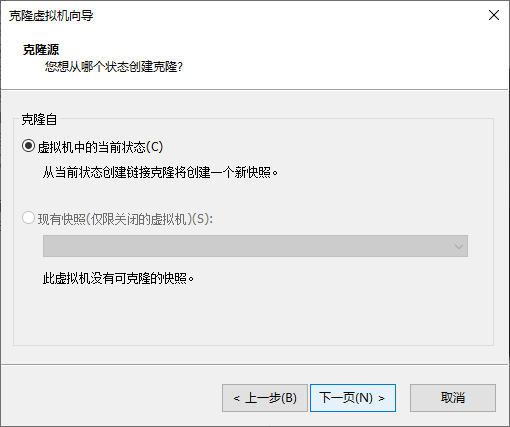


同理,克隆出hadoop03即可,到这虚拟机创建及配置完毕。
三、配置虚拟机的网络
三台虚拟机的ip和域名映射关系如下:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
(1)虚拟网络配置
打开虚拟网络编辑器:

选择VMnet8




之后点击确定即可。


(2)配置虚拟机 主机名
在hadoop01虚拟机下执行:
vi /etc/hostname
vi的insert、save等基本操作参考:https://blog.csdn.net/weixin_41231928
修改后如下:

同理修改hadoop02和hadoop03的hostname为 hadoop02 和 hadoop03,原因是hadoop02和hadoop03是由hadoop01克隆来的,不修改的话,hostname都是hadoop01,修改后如下:


(3)配置虚拟机hosts
其实就是配置ip和域名的映射关系。
vi /etc/hosts
上面的命令编辑hosts,在3个虚拟机都里面添加:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03

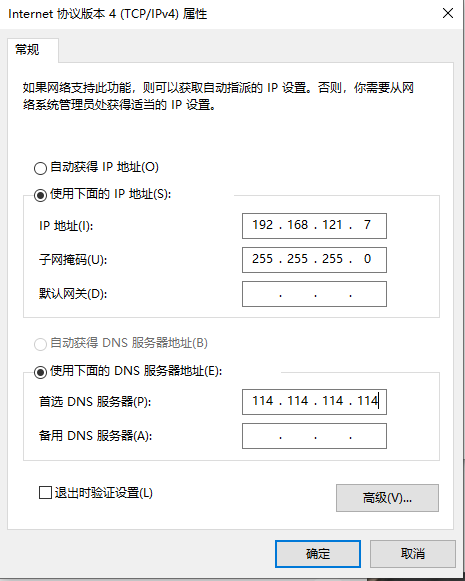
(4)配置DNS、网关等
在3个虚拟机下新增以下ip设置
IPADDR="192.168.121.221"
NETMASK="255.255.255.0"
GATEWAY="192.168.121.2"
DNS1="114.114.114.114"
执行以下命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33

(5)reboot 重启虚拟机
以上所有配置完成后,执行:
reboot
然后可以验证下网络是否通,出现一下说明配置正常:

四、配置SSH服务
SSH服务的作用一般是有两方面:一是便于虚拟机节点之间免密访问,二是传输数据时会有加解密的过程安全性更高。为了这三个节点间免密登录,比如后面在启动hadoop服务时,主节点启动其它从节点,就需要免密去执行。所以3台机器都执行以下流程,这样三台机器就可以使用ssh连接而无需输入密码了。
(1)确认ssh进程
输入以下命令,查看ssh进程是否存在(默认是开启的):
ps -e | grep sshd
如下便是开启状态:

(2)生成秘钥
ssh-keygen -t rsa
执行以上命令,不用输入,按3次回车:

(3)秘钥拷贝
三台机器的秘钥分别生成之后,需要将各自的秘钥拷贝到其他2台机器,3台机器都执行以下命令:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
每条命令中间会有询问,输入“yes”回车,然后输入密码即可:

验证下ssh配置:
在hadoop01下执行ssh hadoop02 和ssh hadoop03,能成功登录:

五、JDK安装
下载一个linux版本的JDK,这里是 jdk-8u161-linux-x64.tar.gz,3台机器均要执行以下。
(1)把JDK安装包传输到虚拟机
这里我们需要借助ftcp文件传输软件,这里使用的是MobaxTerm,也可以使用别的文件传输软件,**WinSCP\PuTTY**Xshell都可以。
MobaxTerm新建SFTP类型的session:

可以新建一个root用户,把3个虚拟机的密码输入:

点击ok后:

选择jdk文件,拖入之前建好的/export/software文件夹:


(2)把JDK安装包解压到/export/software/
执行以下命令:
cd /export/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
cd /export/servers/
mv jdk1.8.0_161/ jdk

(3)配置JDK环境变量
执行:
vim /etc/profile
在文末添加:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

注意:
修改 /etc/profile 文件最后都要执行下
source /etc/profile
才能是修改生效。最后执行java -version看下是否配置成功。
六、Hadoop安装
Hadoop下载地址
这里使用的是 hadoop-3.1.3.tar.gz
(1)安装包上传及解压
跟前面JDK一样,先用 mobaxterm 将 hadoop-3.1.3.tar.gz 上传到3台机器的 /export/software:

执行下面解压命令:
tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/

(2)Hadoop系统环境配置
执行:
vim /etc/profile
添加一下内容:
export HADOOP_HOME=/export/servers/hadoop-3.1.3
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

一样,修改 /etc/profile 文件最后都要执行下 “vim /etc/profile”。
执行验证下:
hadoop version

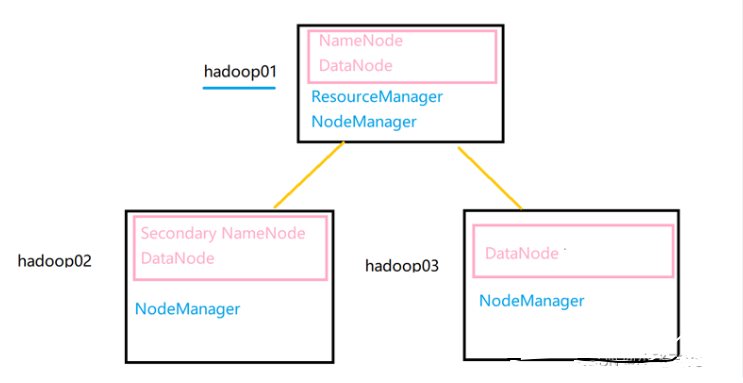
**(3)Hadoop集群境配置 **
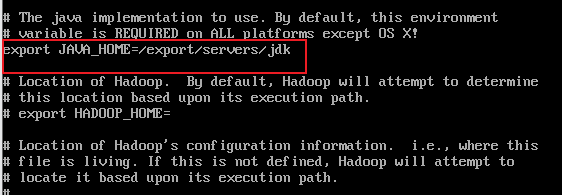
3.1 修改hadoop-env.sh文件
执行:
cd /export/servers/hadoop-3.1.3/etc/hadoop
vim hadoop-env.sh
找到export JAVA_HOME的位置修改:
export JAVA_HOME=/export/servers/jdk
3.2 修改core-site.xml文件
vim core-site.xml
添加以下配置:
<configuration></configuration><property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop-3.1.3/tmp</value> </property>

hadoop02、hadoop03修改时,把对于域名修改成hadoop02、hadoop03即可。
3.3 修改hdfs-site.xml文件
vim hdfs-site.xml
添加以下配置:
<configuration></configuration><property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:50090</value> </property>

dfs.namenode.secondary.http-address这配置在hadoop02、hadoop03不用配置。
3.4 修改mapred-site.xml文件
vim mapred-site.xml
添加以下配置:
<configuration></configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>start
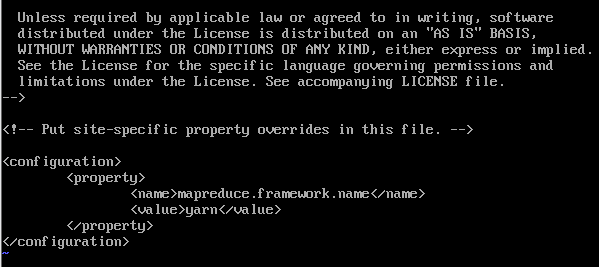
3.5 修改yarn-site.xml文件
vi yarn-site.xml
添加以下配置:
<configuration> <property></configuration><name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
另外,需要执行下:
hadoop classpath

将返回的地址也写入配置文件:
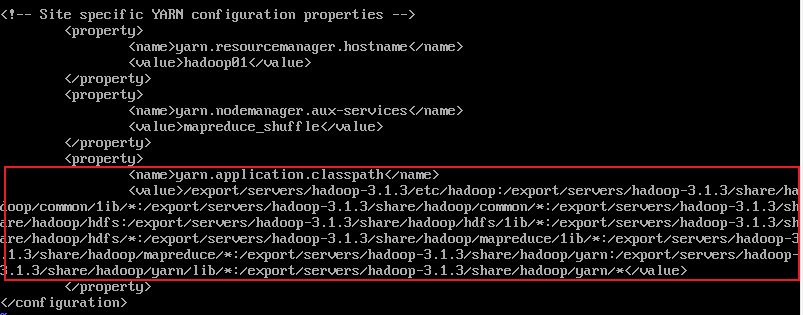
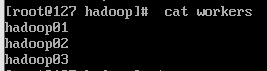
3.6 修改workers文件
vim workers
删除默认的localhost,添加以下内容:
hadoop01
hadoop02
hadoop03
(4)将集群主节点的配置文件分发到其他子节点
执行:
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令。
(5)格式化文件系统
hdfs namenode -format

这个执行成功以后,不要二次执行。
(6)集群启动
执行:
start-dfs.sh
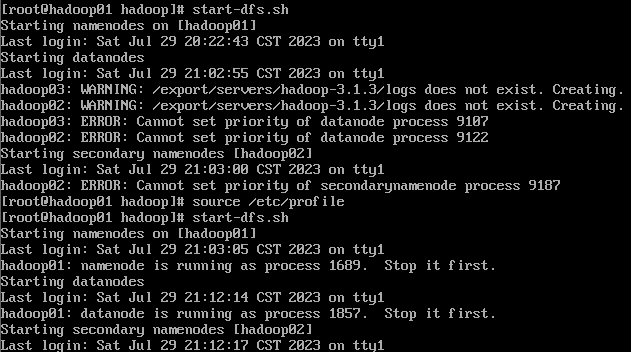
然后3个机器分别 jps 查看进程情况:

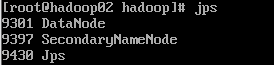
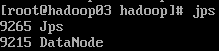
在主节点hadoop01上执行
start-yarn.sh
启动resourcemanager和nodemanager:

jps:
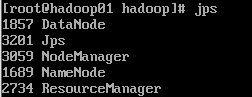
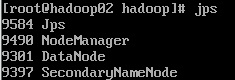
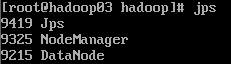
如果想要关闭,输入:
stop-dfs.sh
以上hadoop安装配置就完成了。
七、浏览器查看Hadoop集群
(1)修改windows下ip映射
修改 C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
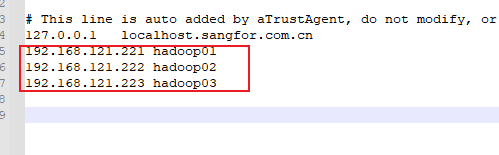
这样就可以通过hadoop01、hadoop02、hadoop03这样的域名来访问了。
(2)防火墙关闭
在3台虚拟机上均执行以下命令(一个是临时关闭,一个是开机就关闭即永久关闭,两个命令执行其中一个即可):
systemctl stop firewalld.service
systemctl disable firewalld.service
(3)浏览器查看
在浏览器输入:
即可访问 **HDFS **和 Yarn
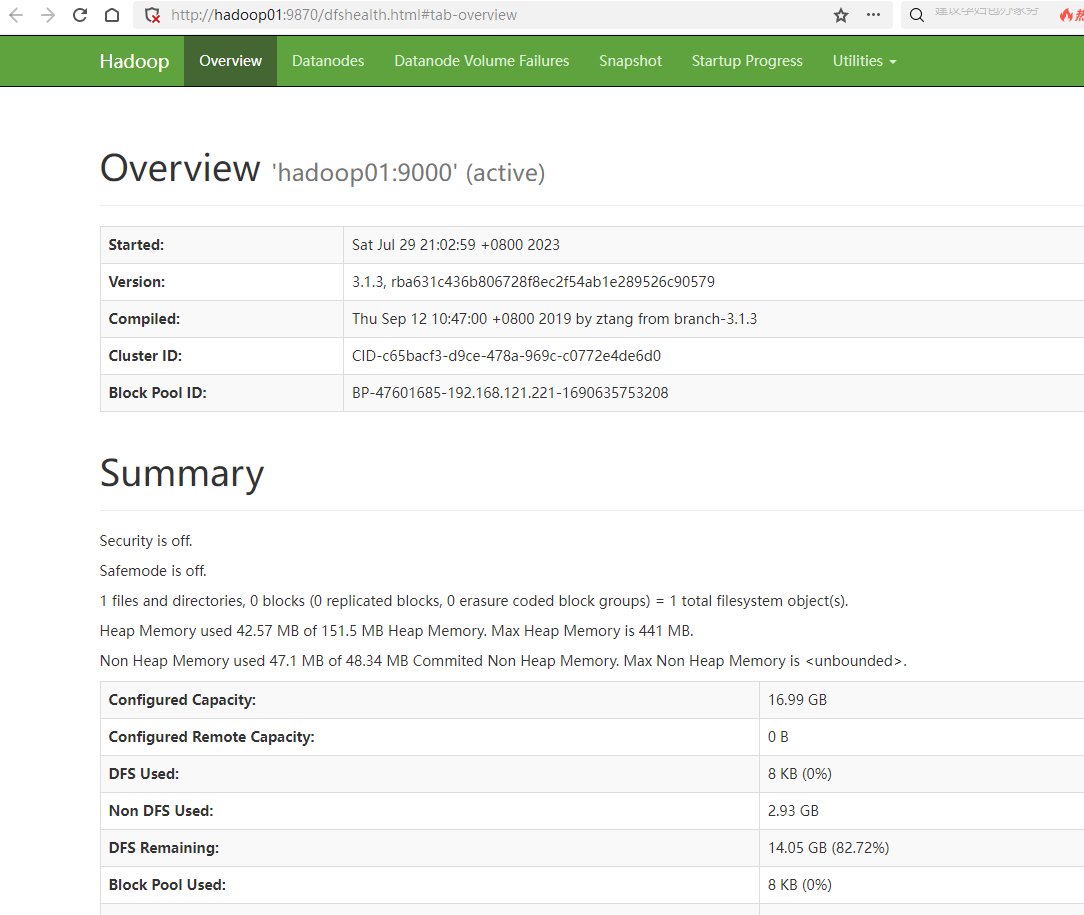
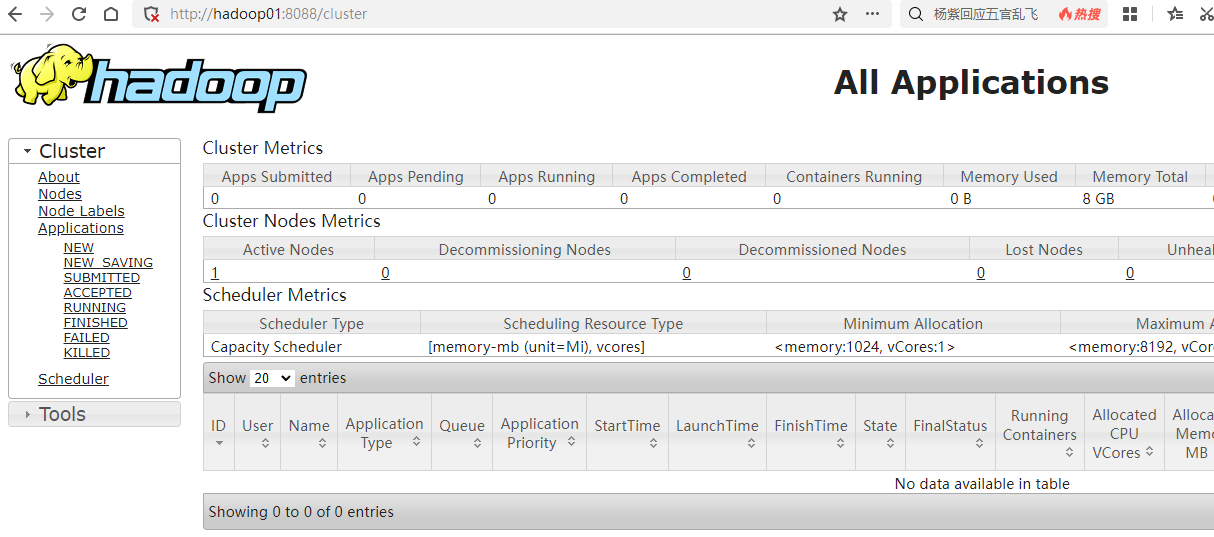
以上已经将Hadoop集群搭建完毕!
版权归原作者 沙滩de流沙 所有, 如有侵权,请联系我们删除。