
2019年5月,Facebook开放了他们的一些推荐方法,并引入了DLRM(深度学习推荐模型)。这篇文章旨在解释DLRM和其他现代推荐方法是如何以及为什么能够如此出色地工作的,通过研究它们是如何从该领域以前的结果中衍生出来的,详细解释它们的内部工作原理和思路。
基于AI的个性化广告已成为在线营销中的标准配置,而Facebook,Google,Amazon,Netflix等公司是在线营销之王,因为他们不仅采用了这种趋势,而且从根本上发明了这种趋势, 围绕它建立了他们的整个业务战略。Netflix的“您可能会喜欢的其他电影”或亚马逊的“购买此商品的顾客也购买了……”只是在线世界中许多例子。
作为Facebook和Gooogle用户,我们经常会问到:
“这到底是如何工作的?”
我们都知道基本的电影推荐例子来解释协作过滤/矩阵分解是如何工作的。此外,我不是在讨论每个用户训练一个直接的分类器的方法,它输出用户是否喜欢某个产品的概率。这两种方法,即协同过滤和基于内容的推荐必须产生某种性能和一些可用的预测,但谷歌、Facebook和Netflix等公司肯定有更好的方法,否则它们不会有今天的地位。
为了了解当今高端推荐系统的来源,我们必须看一下解决以下问题的基本方法:
预测某个用户对某个商品的喜爱程度。
在网络营销的世界里,这就增加了对可能的广告的预测点击率(CTR),基于明确的反馈,如评级,喜欢等,以及隐含的反馈,如点击,搜索历史,评论,或网站访问。
基于内容的过滤与协作过滤
- 基于内容的过滤
宽泛地说,基于内容的推荐是指通过用户的在线历史记录来预测用户是否喜欢某个产品。这包括用户给的赞(如在Facebook上),他/她搜索的关键字(如在谷歌上),以及简单的点击和访问他/她对某些网站。总之,它关注的是用户自己的偏好。例如,我们可以想象一个简单的二元分类器(或回归器),它为该用户输出特定广告组的点击率(或评级)。
- 协同过滤
协同过滤试是通过查看相似用户的偏好来预测用户是否会喜欢某个产品。在这里,我们可以考虑电影推荐的标准矩阵分解(MF)方法,其中评级矩阵被分解成一个针对用户的嵌入矩阵和一个针对电影的嵌入矩阵。
经典的MF的一个缺点是我们不能使用任何侧面特征,例如电影类型、上映日期等,MF本身必须从现有的交互中学习。此外,MF还遭遇了所谓的“冷启动问题”,这意味着尚未被任何人评级的新电影不能推荐。基于内容的过滤解决了这两个问题,然而,缺乏观察相似用户偏好的预测能力。
这两种不同方法的优点和缺点很明显地提出了一种混合方法的需要,即两种想法以某种方式结合到一个模型中。
混合推荐模型
- 分解机
Steffen Rendle在2010年提出的一个想法是分解机。它掌握了将矩阵分解与回归相结合的基本数学方法
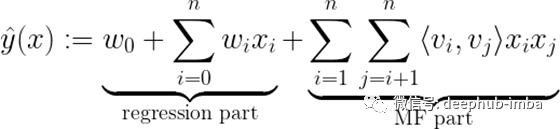
其中学习过程中需要估计的模型参数为:

⟨ ∙ , ∙ ⟩ 是两个向量vᵢ和vⱼ之间的点积,它们可以看成V中的行。
当查看如何表示该模型中的数据x的示例时,可以很直观地看出这个方程的意义。让我们看一看Steffen Rendle在《因子分解机》中描述的例子:
假设有以下关于电影评论的交易数据,用户在特定时间给电影评级:
用户u∈u = {Alice (A), Bob (B),…}
∈i ={泰坦尼克(TI),诺丁山(NH),星球大战(SW),星际迷航(ST),…}
评级r∈{1,2,3,4,5}在时间t∈ℝ

上图中,我们可以看到混合推荐模型的数据设置。代表用户和项目的稀疏特征以及任何其他元或边信息(例如,在此示例中为“时间”或“上次评分的电影”)都是映射到目标y的特征向量x的一部分。现在的关键是模型如何处理它们。
FM的回归部分像标准回归任务一样处理稀疏数据(例如“用户”)和连续数据(例如“时间”),因此可以解释为FM中基于内容的过滤方法。 FM的MF部分现在说明了功能块之间的交互(例如“用户”和“电影”之间的交互),其中矩阵V可以解释为协作过滤方法中使用的嵌入矩阵。这些跨用户电影的关系为我们带来了如下解释:
用户i与具有嵌入 vᵢ 的另一个用户j具有相似的嵌入vⱼ(表示他对电影属性的偏好)的用户,很可能喜欢与用户j类似的电影。
将回归部分和MF部分的两个预测相加,并在一个成本函数中同时学习它们的参数,就得到了混合FM模型,该模型现在使用“两全齐美”的方法为用户提供推荐。
乍一看,这种分解机器的混合方法似乎是一个完美的模型,然而,许多不同的人工智能领域,如自然语言处理或计算机视觉,在过去已经证明:
“把它扔进神经网络,你会让它变得更好”
Wide and Deep,神经网络协同过滤(NCF)和深度分解机(DeepFM)
首先,我们将通过查看NCF论文来探讨如何通过神经网络方法解决协同过滤问题,这将使我们进入深度分解机器(DeepFM),这是分解机器的神经网络版本。我们将看到为什么它们优于常规FM,以及如何解释神经网络体系结构。我们将看到DeepFM是如何开发的,它是对Google先前发布的Wide&Deep模型的改进,这是推荐系统中深度学习的第一个重大突破之一。最终,这将使我们进入Facebook在2019年发布的上述DLRM论文,这可以看作是DeepFM的简化和稍作调整的版本。
Neural Collaborative Filtering
2017年,一组研究人员发布了他们在神经协作过滤方面的工作。它包含一个通用框架,用于学习在与神经网络的协同过滤中通过矩阵分解进行建模的功能关系。作者还解释了如何实现更高阶的交互(MF仅是2阶),以及如何将这两种方法融合在一起。
一般的想法是,神经网络可以(理论上)学习任函数关系。这意味着神经网络也可以学习协作过滤模型与其MF所表达的关系。NCF提出了一个针对用户和物品的简单嵌入层(类似于标准MF),然后提出了一个简单易懂的多层感知器神经网络,以通过神经网络从根本上了解两个嵌入之间的MF点积关系。
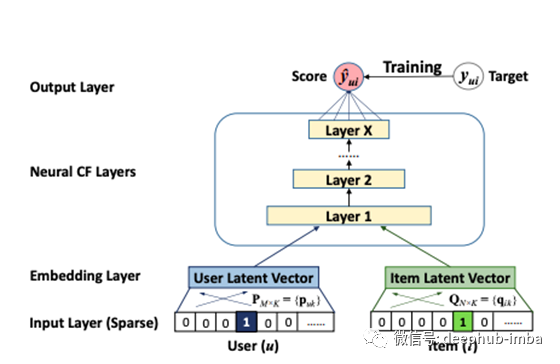
这种方法的优点在于MLP的非线性。MF中使用的简单点积将始终将模型限制为学习2度的相互作用关系,而具有X层的神经网络在理论上可以学习更高度的相互关系。想想3种都具有互动的分类特征,例如男性、青少年和RPG电脑游戏。。
在实际问题中,我们不仅将用户和项目二值化向量用作嵌入的原始输入,而且显然包括各种其他有价值的元数据或附带信息(例如年龄,国家/地区,音频/文本记录,时间戳记 ,…),因此实际上我们有一个高维,高度稀疏和连续分类的混合数据集。在这一点上,上述图2所示的神经网络也很容易以简单的二进制分类前馈神经网络的形式解释为基于内容的推荐。这种解释对于理解它最终如何成为CF和基于内容的推荐之间的混合方法至关重要。该网络实际上可以学习任何函数关系,从而以CF等级3或更高的意义进行交互,例如3度 x₁ ∙ x₂ ∙ x₃,或经典神经网络分类意义上的任何非线性变换,形式为σ( … σ(w₁x₁+w₂x₂ + w₃x₃ + b)),都是可以被学习的。
由于具备了学习高阶交互作用的能力,我们可以通过将神经网络与众所周知的学习低阶交互作用的模型——分解机相结合,使我们的模型更容易学习1阶和2阶的低阶交互作用。这正是DeepFM的作者在他们的论文中提出的。这种同时学习高阶和低阶特征交互的组合思想是许多现代推荐系统的关键部分,在业内几乎所有提出的网络架构中都可以以某种形式找到它。
DeepFM
DeepFM是FM和深度神经网络的混合方法,彼此共享相同的输入嵌入层。对原始特征进行转换,以使连续字段由其自身表示,而分类字段则进行一次独热编码。NN中的最后一层给出的最终(例如CTR)预测定义为:
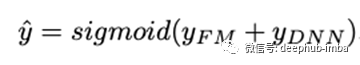
这是一个s型激活sigmoid 函数和FM和NN网络相加组成的函数。
FM组件是装扮成神经网络架构风格的常规分解机器:
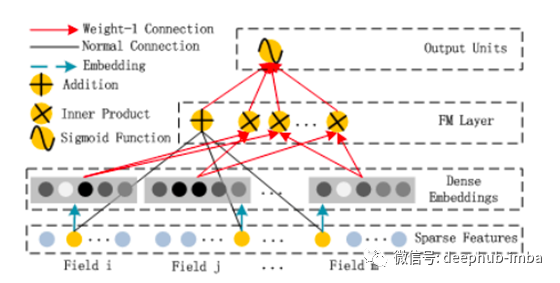
FM层的加法部分直接获取原始输入向量x(稀疏特征层),然后将每个元素与其权重相乘(“正常连接”),然后求和。FM层的“内积”部分也获得原始输入x,但仅在原始输入x通过嵌入层之后才获取,并且简单地获取嵌入向量之间的点积而没有任何权重(“ Weight-1 Connection”)。通过另一个“ Weight-1 Connection”将两个部分加在一起,得出以下FM方程:

仅需要等式中的xᵢxⱼ乘法才能写出从i = 1到n的和。它实际上并不是神经网络计算的一部分。由于嵌入层的架构,网络会自动知道哪个嵌入向量vᵢ,vⱼ在其之间取点积。
该嵌入层体系结构如下所示:
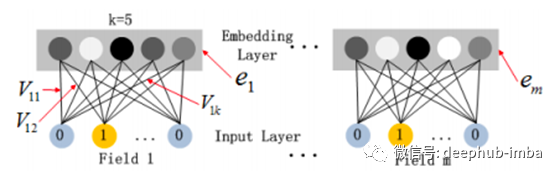
其中Vᵖ是每个字段的嵌入矩阵p = {1,…,m},具有k列,但是该字段的二值化版本中有很多行具有元素。因此,嵌入层的输出为:

需要注意的是,这不是一个完全连接的层,也就是说,任何字段的原始输入和任何其他字段的嵌入之间都没有连接。可以这样想:性别的一个独热编码向量(例如(0,1))不能与工作日的嵌入向量(例如(0,1,0,0,0,0)原始二值化工作日“星期二”,它是嵌入的向量,例如:k = 4;(12,4,5,9)。
FM分量作为分解机反映了1阶和2阶交互的高度重要性,这些交互直接添加到深层分量输出中,并在最后一层输入到sigmoid激活中。
理论上,深层组件可以是任何神经网络体系结构。作者专门研究了常规的前馈MLP神经网络(以及所谓的PNN)。下图给出了常规MLP:
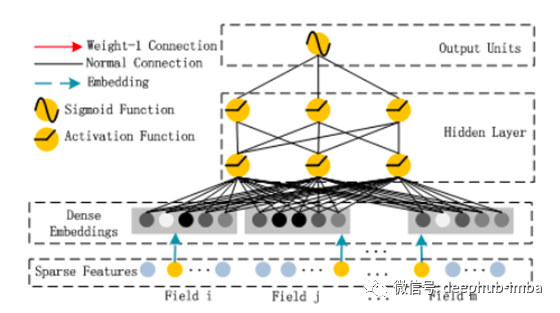
一个标准MLP网络,在原始数据(由于独热编码的分类输入并且高度稀疏)与以下神经网络层之间嵌入层,给定如下层:
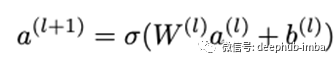
σ为激活函数,W为权重矩阵,a为前一层的激活,b为偏置。
这就产生了DeepFM的整体网络架构:
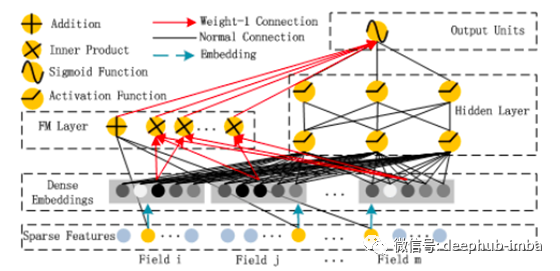
参数如下:
潜在向量Vᵢ,用于衡量要素i与其他要素(嵌入层)互动的影响
- Vᵢ被传递给FM组件以对2级交互进行建模(FM组件)
- wᵢ权衡原始特征i(FM组件)的顺序1的重要性
- Vᵢ还传递给Deep组件以对所有高阶交互(> 2)建模(Deep Component)
- Wˡ和bˡ,神经网络的权重和偏差(深度分量)
同时获得高阶和低阶交互的关键是在一个代价函数下同时训练所有参数,特别是对FM和Deep组件使用相同的嵌入层。
Wide&Deep和NeuMF的比较
关于如何调整此体系结构以使其变得更好,人们可以想到很多变体。但是,在核心方面,它们在如何同时建模高阶和低阶关系方面的混合方法都相似。DeepFM的作者还建议将MLP部分与所谓的PNN互换,这是一种深层神经网络,它将FM层作为初始输入与嵌入层结合在一起
NCF论文的作者还提出了一种类似的架构,他们称为NeuMF(“神经矩阵分解”)。他们没有使用FM作为低阶分量,而是使用了规则矩阵分解输入到激活函数中。但是,这种方法缺少由FM的线性部分建模的特定1级交互。同样,作者特别允许模型学习不同的用户和项嵌入,以进行矩阵分解以及MLP部分。
如前所述,Google的研究小组是最早提出用于混合推荐方法的神经网络的小组之一。DeepFM可以看作是Google的Wide&Deep算法的进一步发展,它看起来像这样:

右侧是我们著名的带有嵌入层的MLP,但是左侧具有不同的人工设计输入,这些输入直接输入到最终的整体输出单元中。这些人工设计的功能隐藏了点积运算形式的低阶交互,作者说这些可以有很多不同的东西,例如:
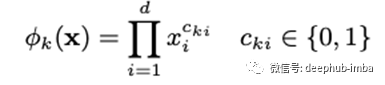
通过相互交叉相乘(如果x features是第k个变换的一部分,指数等于1)来捕获d个特征(具有或不具有其他先前的嵌入)之间的相互作用。
很容易看出DeepFM是一种改进,因为它不需要任何先验功能工程,并且能够从完全共享的一个公共嵌入层的完全相同的输入数据中学习低阶和高阶交互。DeepFM实际上将FM模型作为其核心网络的一部分,而Wide&Deep并不将点积计算作为实际神经网络的一部分,而是事先在特征工程步骤中进行。
DLRM 深度学习推荐模型
因此,有了谷歌、华为(DeepFM架构的研究团队)和其他公司的这些不同选择,让我们来看看Facebook是如何看待这些模型的。他们在2019年发表了DLRM论文,重点关注了这些模型的实用性。并行训练设置,GPU计算以及不同处理的连续vs分类特征。
DLRM体系结构如下图所示:分类特征用一个嵌入向量表示,连续特征由MLP处理,使其与嵌入向量具有相同的长度。现在在第二阶段,计算所有嵌入向量组合与处理过的(MLP输出)密集向量之间的点积。然后,点积与密集特征的MLP输出连接,并通过另一个MLP,最终形成一个sigmoid函数给出一个概率。
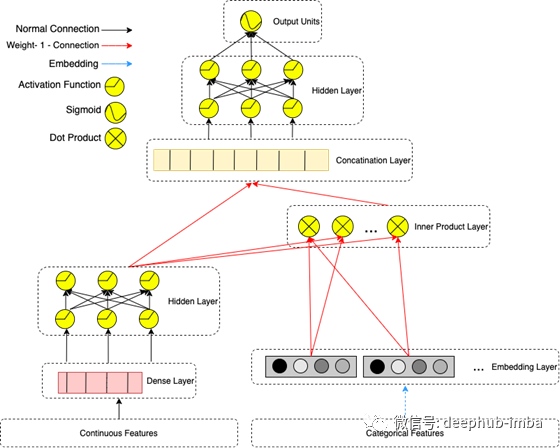
这个DLRM方案在某种程度上是DeepFM的简化和修改版本,因为它也使用嵌入向量之间的点积计算,但它特别试图通过不直接通过MLP层强制嵌入分类特征来避免高阶交互。该设计是为了模拟因式分解机计算嵌入之间二阶交互的方式而定制的。我们可以把整个DLRM设置看作是DeepFM (FM组件)的专用部分。在DLRM设置中,可以认为完全忽略了DeepFM的经典深度分量,它被添加到DeepFM最后一层的FM分量的结果中(然后被输入到一个sigmoid函数中)。DeepFM的理论优势是显而易见的,从设计上来说,它可以更好地学习高阶交互,但根据Facebook的说法:
在其他网络中发现的高于二阶的高阶交互可能并不一定值得额外的计算/内存成本
前景和代码
在介绍了各种深度推荐方法及其优缺点之后,我在Facebook的GitHub页面上研究了PyTorch对DLRM的建议实现。
我检查了实现的细节,并尝试了它们内置的预定义数据集API,以直接处理不同的原始数据集。Criteo的Kaggle展示广告挑战赛及其Terabyte数据集均已实现,可以下载并随后用于仅使用一个bash命令来训练完整的DLRM(有关说明,请参阅DLRM项目)。然后,我扩展了Facebook的DLRM模型API,以包括针对另一个数据集2020 DIGIX广告CTR预测的预处理和数据加载步骤。
在下载并解压缩digix数据之后,您也可以使用一个bash命令来训练模型。为了处理digix数据集,所有的预处理步骤、嵌入的形状和神经网络结构参数都进行了调整。该模型提供了一些不错的结果,因为我正在继续对其进行研究,以便通过更好地理解digix数据背后的原始数据和广告过程来提高性能。具体的数据清理、超参数调优和特性工程都是我想进一步研究的内容,在notebook也有提到。第一个目标只是在技术上对DLRM模型API进行合理的扩展,可以使用原始digix数据作为输入。
总之,我相信混合深度模型是解决推荐任务最强大的工具之一。然而,最近出现了一些非常有趣和有创意的无监督方法来解决使用自动编码器的协作过滤问题。所以在这一点上,我只能猜测今天的互联网巨头都在用什么来给我们提供我们最有可能点击的广告。我认为它很可能是前面提到的自动编码器方法和本文中介绍的某种形式的深层混合模型的组合。
代码地址:https://github.com/mabeckers/dlrm/
引用
Steffen Rendle. Factorization machines. In Proc. 2010 IEEE International Conference on Data Mining, pages 995–1000, 2010.
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. In Proc. 26th Int. Conf. World Wide Web, pages 173–182, 2017.
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. DeepFM: a factorizationmachine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247, 2017.
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. xDeepFM: Combining explicit and implicit feature interactions for recommender systems. In Proc. of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1754–1763. ACM, 2018.
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. Wide & deep learning for recommender systems. In Proc. 1st Workshop on Deep Learning for Recommender Systems, pages 7–10, 2016.
M. Naumov, D. Mudigere, H. M. Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C. Wu, A. G. Azzolini, D. Dzhulgakov, A. Mallevich, I. Cherniavskii, Y. Lu, R. Krishnamoorthi, A. Yu, V. Kondratenko, S. Pereira, X. Chen, W. Chen, V. Rao, B. Jia, L. Xiong, and M. Smelyanskiy, “Deep learning recommendation model for personalization and recommendation systems,” CoRR, vol. abs/1906.00091, 2019. [Online]. Available: http://arxiv.org/abs/1906. 00091 [39]
作者:Maximilian Beckers
原文地址:https://towardsdatascience.com/modern-recommender-systems-a0c727609aa8
deephub翻译组