
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解Spark的协同过滤概念;
一、协同过滤概念
1. 概念
协同过滤是一种借助众包智慧的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。其内在思想是相似度的定义。
1. 基于用户的协同过滤概念
在基于用户的方法的中,如果两个用户表现出相似的偏好(即对相同物品的偏好大体相同),
那就认为他们的兴趣类似。要对他们中的一个用户推荐一个未知物品,便可选取若干与其类似的
用户并根据他们的喜好计算出对各个物品的综合得分,再以得分来推荐物品。其整体的逻辑是,
如果其他用户也偏好某些物品,那这些物品很可能值得推荐。
2. 基于物品的协同过滤概念
同样也可以借助基于物品的方法来做推荐。这种方法通常根据现有用户对物品的偏好或是评
级情况,来计算物品之间的某种相似度。这时,相似用户评级相同的那些物品会被认为更相近。
一旦有了物品之间的相似度,便可用用户接触过的物品来表示这个用户,然后找出和这些已知物
品相似的那些物品,并将这些物品推荐给用户。同样,与已有物品相似的物品被用来生成一个综
合得分,而该得分用于评估未知物品的相似度。
2. 协同过滤的推荐方法
1. 基于用户的推荐
对于基于用户相似性的推荐,用简单的一个词表述,那就是“志趣相投”。事实也是如此。
比如说你想去看一个电影,但是不知道这个电影是否符合你的口味,那怎么办呢?从网上找介绍和看预告短片固然是一个好办法,但是对于电影能否真实符合您的偏好却不能提供更加详细准确的信息。这时最好的办法可能就是这样:
小王:哥们,我想去看看这个电影,你不是看了吗,怎么样?
小张:不怎地,陪女朋友去看的,她看得津津有味,我看了一小半就玩手机去了。小王:那最近有什么好看的电影吗?
小张:你去看《雷霆XX》吧,我看了不错,估计你也喜欢。
小王:好的。
这是一段日常生活中经常发生的对话,也是基于用户的协同过滤算法的基础。
小王和小张是好哥们。作为好哥们,其也应具有相同的爱好。那么在此基础上相互推荐自己喜爱的东西给对方那必然是合乎情理,有理由相信被推荐者也能够较好地享受到被推荐物品所带来的快乐和满足感。
下图展示了基于用户的协同过滤算法的表现形式。
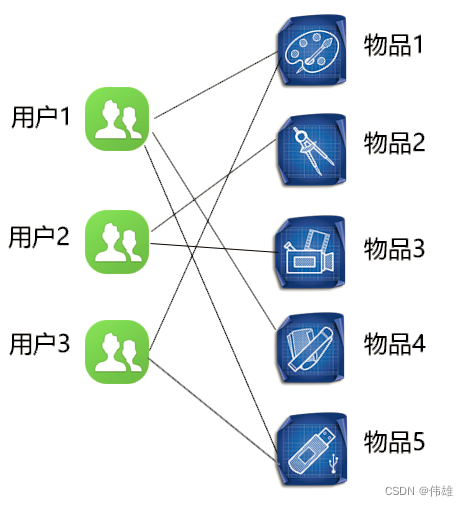
从图上可以看到,想向用户3推荐一个商品,那么如何选择这个商品是一个很大的问题。在已有信息中,用户3已经选择了物品1和物品5,用户2比较偏向于选择物品2和物品4,而用户1选择了物品1、物品4以及物品5。
根据读者的理性思维,不用更多地分析可以看到,用户1和用户3在选择偏好上更加相似。那么完全有理由相信用户1和用户3都选择了相同的物品1和物品5,那么将物品3向用户3推荐也是完全合理的。
这个就是基于用户的协同过滤算法做的推荐。用特定的计算方法扫描和指定目标相同的已有用户,根据给定的相似度对用户进行相似度计算,选择最高得分的用户并根据其已有的信息作为推荐结果从而反馈给用户。这种推荐算法在计算结果上较为简单易懂,具有很高的实践应用价值。
2. 基于物品的推荐
在基于物品的推荐算法中,同样可以使用一个词来形容整个算法的原理。那就是“物以类聚”。
这次小张想给他女朋友买个礼物。
小张:马上情人节快到了,我想给我女朋友买个礼物,但是不知道买什么,上次买了个赛车模型的差点被她骂死。
小王:哦?那你真是的,也不买点她喜欢的东西。她平时喜欢什么啊?
小张:她平时比较喜欢看动画片,特别是《机器猫》,没事就看几集。
小王:那我建议你给她买套机器猫的模型套装,绝对能让她喜欢。
小张:好主意,我试试。
从对话中可以感受到,小张想给自己的女朋友买个礼物从而向小王咨询。
对于不熟悉的用户,在缺少特定用户信息的情况下,根据用户已有的偏好数据去推荐一个未知物品是合理的。这就是基于物品的推荐算法。
二、案例—用户和电影推荐
1. 简化版代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import scala.collection.mutable.Map
object Driver1{
def main(args:Array[String]):Unit={
版权归原作者 伟雄 所有, 如有侵权,请联系我们删除。