
RabbitMq简介
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
RabbitMq工作模型
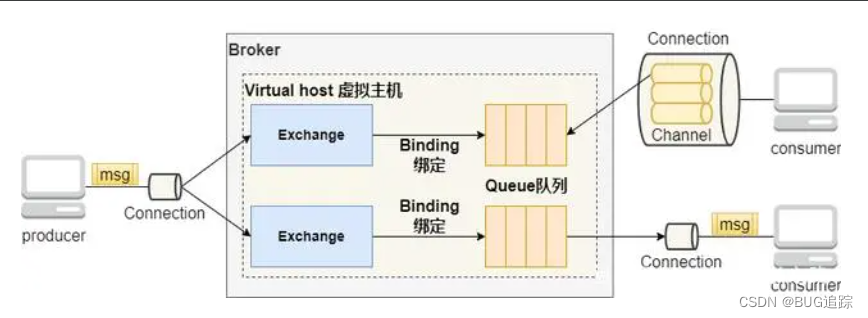
producer生产者生产消息,发送到绑定了queue队列的exchange交换机上,并进入到指定的queue队列,最后推送到consumer消费端。
RabbitMq消息丢失情况
1、producer生产者丢失消息
2、broker消息中间件自身丢失消息
3、consumer消费者丢失消息
RabbitMq消息丢失原因及解决方案
1、producer生产者丢失消息
原因:生产者发送消息由于网络等原因并没有发送到RabbitMq
解决方案:
1.1、开启RabbitMq事务机制
生产者发送数据之前开启 RabbitMQ 事务channel.txSelect,然后发送消 息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务channel.txCommit,类似我们数据库数据库事务机制。
1.2、开启 confirm 模式
在生产者端设置开启 confirm 模式之后,你每次写的消息都会分配一个唯一的 ID,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息已经收到。如果 RabbitMQ 没能处理这个消息,会回调你的一个 nack 接口,告诉你这个消息接收失败,你可以重试。而且可以结合这个机制在自己业务里维护每个消息 ID 的状态,如果超过一定时间还没接收到这个消息的回调,那么可以业务主动重发。
事务机制和 confirm 机制优劣:
事务机制是同步的,提交一个事务之后会阻塞,吞吐量会下来,耗性能。
confirm 机制是异步的,流程不会阻塞,吞吐量较高,性能较好。
2、broker消息中间件自身丢失消息
原因:RabbitMq收到生产者的消息后还没有来得及持久化到磁盘,又或者创建队列没有持久化以及消息并没有设置为持久化,在Mq故障宕机后都会有消息丢失的情况。
解决方案:
2.1、创建队列queue的时候设置队列持久化
2.2、mq配置deliveryMode == 2 消息持久化
重点:必须同时设置队列持久化和消息持久化,再结合生产者的confrim模式,才能保证消息准确投递到broker并保证进入磁盘。
3、consumer消费者丢失消息
原因:消费者自动ack配置情况下,业务代码异常或者其他故障消息并没有处理完成也会自动ack。RabbitMq消息ack后就会丢弃,这就导致异常情况下的消息丢失了。
解决方案:
3.1 关闭RabbitMq自动ack,业务代码成功消费了消息手动调用Mq ack,让Mq丢弃消息;如果业务代码异常则直接nack,让Mq重新推送消息进行处理。当然,在要求比较高的情况下也可以异常数据进入死信队列,保证数据的完整性。
版权归原作者 小沈同学呀 所有, 如有侵权,请联系我们删除。