
title: Flink系列
一、Flink StateBackend 深入剖析和应用
StateBackend 定义了状态是如何存储的,不同的 State Backend 会采用不同的方式来存储状态,核心入口是: StateBackend, Flink 提供了三种不同形式的存储后端,分别是 MemoryStateBackend, FsStateBackend 和 RocksDBStateBackend。
- MemoryStateBackend 会将工作状态(Task State)存储在 TaskManager 的内存中,将检查点(Job State)存储在 JobManager 的内存中,速度很快,不支持持久化,通常用来存储一些 state 量小的情况下的 state。这种方式是非常不安全的,且受限于JobManager的内存大小,主要在开发调试中使用。
- FsStateBackend 会将工作状态存储在 TaskManager 的内存中,将检查点存储在文件系统中(通常是分布式文件系统),用来存储 state 量比较大的,window 窗口很长的一些 job 的 state 比较合适。生产环境常用此方案。
- RocksDBStateBackend 会把状态存储在 RocksDB 中,将检查点存储在文件系统中(类似 FsStateBackend),和 MemoryStateBackend 对比是速度快,GC 少,支持异步 Snapshot 持久化。用来存储 state 量比较大的,window 窗口很长的一些 job 的 state 比较合适。
综上所述,MemoryStateBackend 和 FsStateBackend 都是在内存中进行状态管理,所以可以获取较低的读写延迟,但会受限于 TaskManager 的内存大小;而RocksDBStateBackend 直接将 State 存储到 RocksDB 数据库中,所以不受 JobManager 的内存限制,但会有读写延迟,同时 RocksDBStateBackend 支持增量备份,这是其他两个都不支持的特性。一般来说,如果不是对延迟有极高的要求,RocksDBStateBackend 是更好的选择。
淘汰掉原来的三种实现,提供两种新的实现的目的:为了接口统一!底层原理没变。window编程也被统一了,Time编程也被统一了。
配置:
state.backend: hashmap
state.checkpoint-storage: jobmanager
state.checkpoints.dir: hdfs://hadoop10/flink/checkpoints
state.savepoints.dir: hdfs://hadoop10/flink/savepoints
实现支持MemoryStateBackend
HashMapStateBackendFsStateBackend
HashMapStateBackendRocksDBStateBackend
EmbeddedRocksDBStateBackend代号jobmanager
hashmapfilesystem
hashmaprocksdbTask StateTaskManager 堆内存中TaskManager 堆内存中TaskManager 中的 RocksDB 实例中Job StateJobManager 堆内存中
hashmap 的话基于 CheckpointStorage 来定外部高可用文件系统,比如 HDFS
hashmap 的话基于 CheckpointStorage 来定外部高可用文件系统,比如 HDFS缺点只能保存数据量小的状态
状态数据有可能会丢失状态大小受TaskManager内存限制(默认支持5M)状态访问速度有所下降优点开发测试很方便
性能好状态访问速度很快
状态信息不会丢失可以存储超大量的状态信息
状态信息不会丢失使用场景本地开发测试State 量比较大
分钟级 window 窗口的状态数据
生产环境使用State 量超大
小时级 window 窗口的状态数据
生产环境使用
细粒度:Task State: 一个 Application 会运行很多的 Task, 每个 Task 运行的时候,都有自己的状态, 故障转移 = FailOverStrategy
- 要么是 TaskManager 的堆内存
- 要么是 RocksDB 中
粗粒度:Job State:在某个时候,通过某种手段(checkpoint)把这个 job 的所有 Task 的 state 做一个持久化,就形成了 job 的 state, 重启策略 = RestartStrategy
- 要么是 JobManager 的堆内存
- 要么是外部的高可用系统中,可以是HDFS
Flink StateBackend 的三种实现对比:
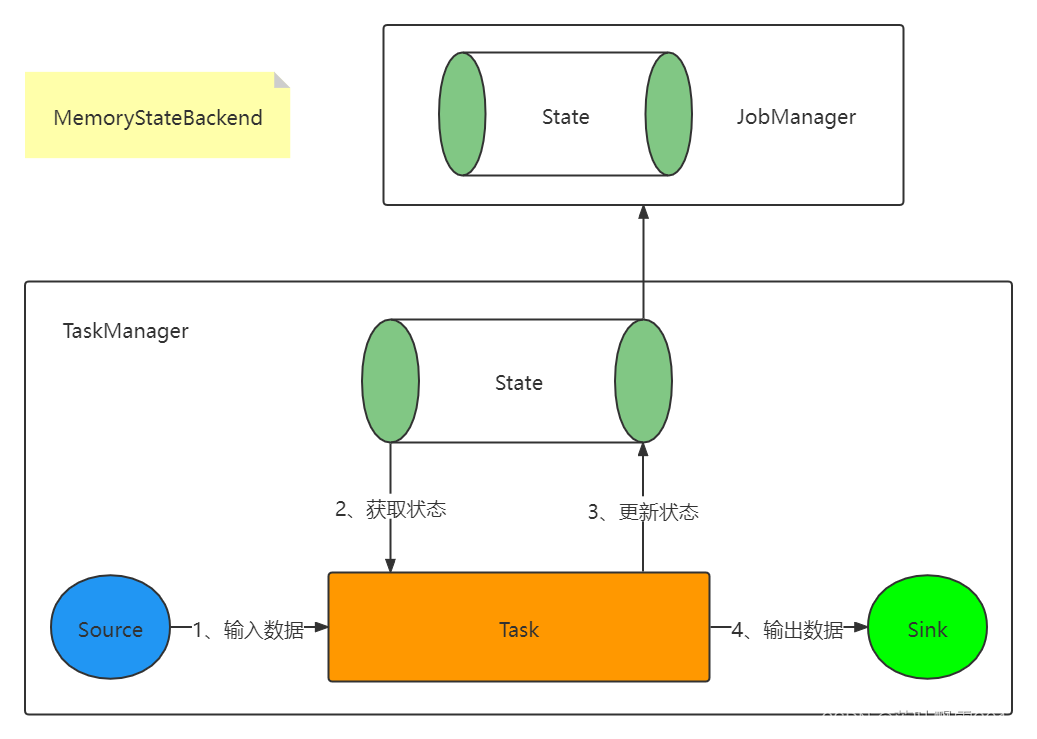
1.1 MemoryStateBackend
默认情况下,状态信息是存储在 TaskManager 的堆内存中的,checkpoint 的时候将状态保存到 JobManager 的堆内存中。
缺点:
只能保存数据量小的状态
状态数据有可能会丢失
优点:
开发测试很方便
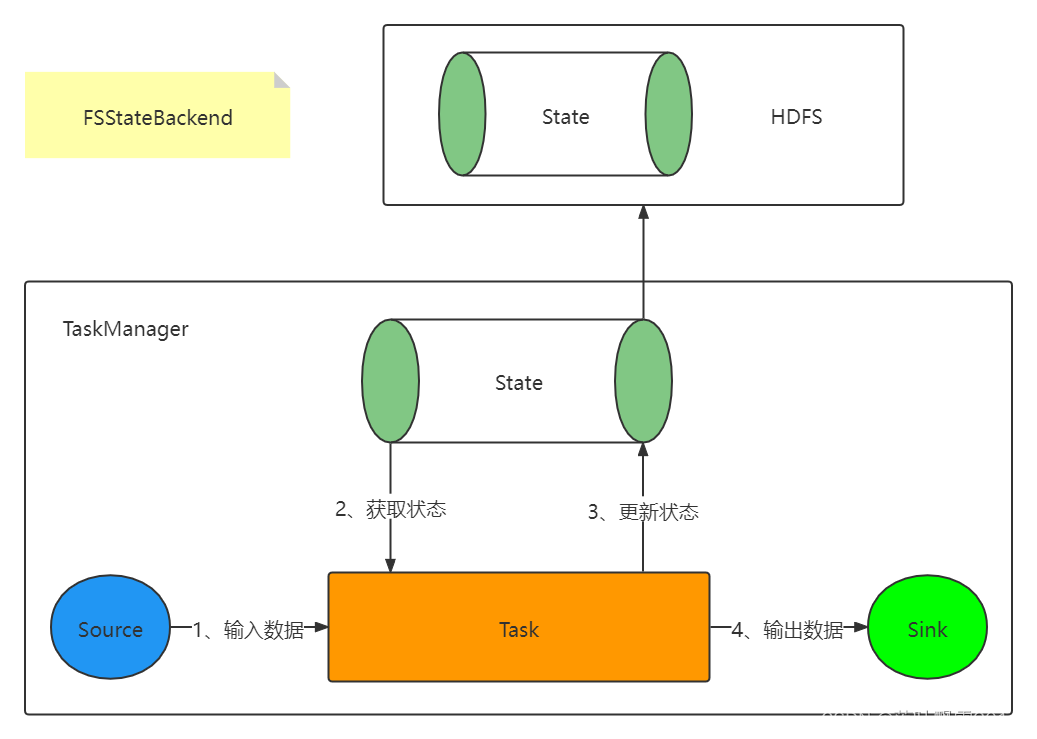
1.2 FSStateBackend
状态信息存储在 TaskManager 的堆内存中的,checkpoint 的时候将状态保存到指定的文件中 (HDFS 等文件系统)
缺点:
状态大小受TaskManager内存限制(默认支持5M)
优点:
状态访问速度很快
状态信息不会丢失
用于:
生产,也可存储状态数据量大的情况
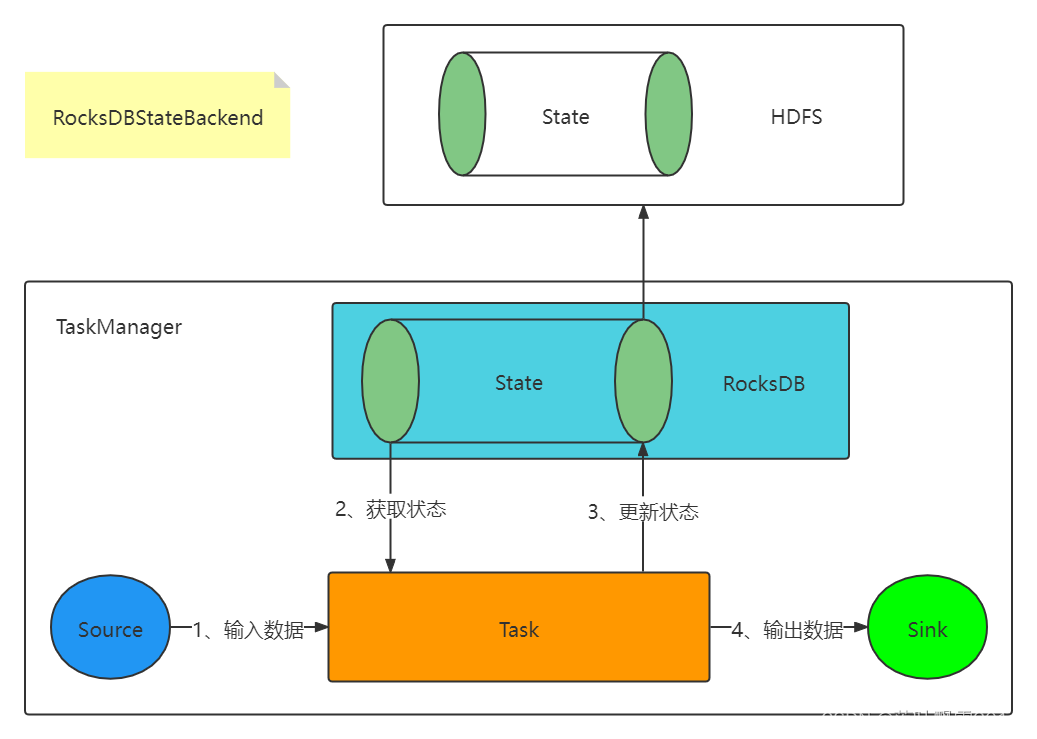
1.3 RocksDBStateBackend
状态信息存储在 RocksDB 数据库 (key-value 的数据存储服务), 最终保存在本地文件中。checkpoint 的时候将状态保存到指定的文件中 (HDFS 等文件系统)
缺点:
状态访问速度有所下降
优点:
可以存储超大量的状态信息
状态信息不会丢失
用于:
生产,可以存储超大量的状态信息
二、Flink StateBackend 原理剖析与实践
第一种:单任务调整
修改当前任务代码
env.setStateBackend(new FsStateBackend("hdfs://hadoop10/flink/checkpoints"));
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new RocksDBStateBackend(filebackend, true));
第二种:全局调整
修改 flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://hadoop10/flink/checkpoints
注意:state.backend的值可以是下面几种:
1、jobmanager(MemoryStateBackend)
2、filesystem(FsStateBackend)
3、rocksdb(RocksDBStateBackend)
MemoryStateBackend(老版本的默认实现) 和 FsStateBackend 的代码写法,其实它们已经被废弃,建议使用:HashMapStateBackend(新版本的默认实现)
用的是HashMapStateBackend,但是给job级别的数据保存到 Job Manager 的堆内内存中:
// HashMapStateBackend 替代 MemoryStateBackendStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 1、设置使用 HashMapStateBackend,Task State 存储在 TaskManager 的堆内存中
env.setStateBackend(newHashMapStateBackend());// 2、这样设置 checkpoint 的 state 存储方式:把 job State 存储在 JobManager 的堆内存中
env.getCheckpointConfig().setCheckpointStorage(newJobManagerCheckpointStorage());
用的是HashMapStateBackend,但是给job级别的数据保存到 Job Manager 的外面的高可用系统HDFS中:
// HashMapStateBackend 替代 FsStateBackendStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 1、设置使用 HashMapStateBackend,Task State 存储于 TaskManager 堆内存中
env.setStateBackend(newHashMapStateBackend());// 2、需要设置外部高可用文件系统存储路径用来保存 Job State
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop10/flink/checkpoints");
RocksDBStateBackend 代码写法,其实 RocksDBStateBackend 也已经被废弃,建议使用 EmbeddedRocksDBStateBackend
// EmbeddedRocksDBStateBackendStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 1、设置 EmbeddedRocksDBStateBackend,Task State 存储在 RocksDB 中(内存+磁盘)
env.setStateBackend(newEmbeddedRocksDBStateBackend());// 2、设置外部高可用文件系统存储路径用来保存 Job State
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop10/flink/checkpoints");
如果使用 RocksDB 的方式,需要引入依赖:
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-statebackend-rocksdb --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.12</artifactId><version>1.14.3</version><scope>test</scope></dependency>
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接
版权归原作者 落叶飘雪2014 所有, 如有侵权,请联系我们删除。