
Linux常见指令3
一.Linux指令
1.时间相关的指令
1.date指定格式显示时间

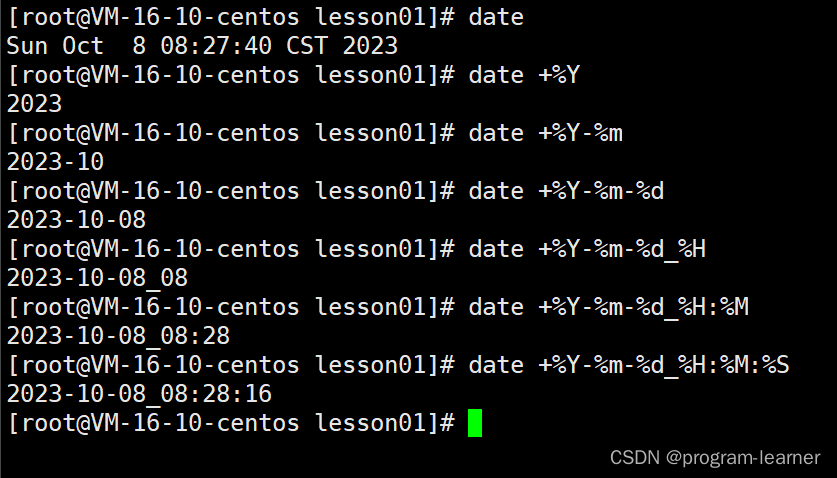
date +%Y-%m-%d_%H:%M:%S(年月日时分秒)
注意:这里的大小写必须严格这样写,而分隔符(例如:- _ :)则无所谓
2.时间戳

以格林威治的时间作为标准时间,类似于我国普遍使用北京时间
又因为不同国家不同地域存在时差,所以使用时间戳通过这种时差的计算把时间换算出来
换算成统一的世界时间,方便各国通信往来,跨国贸易等等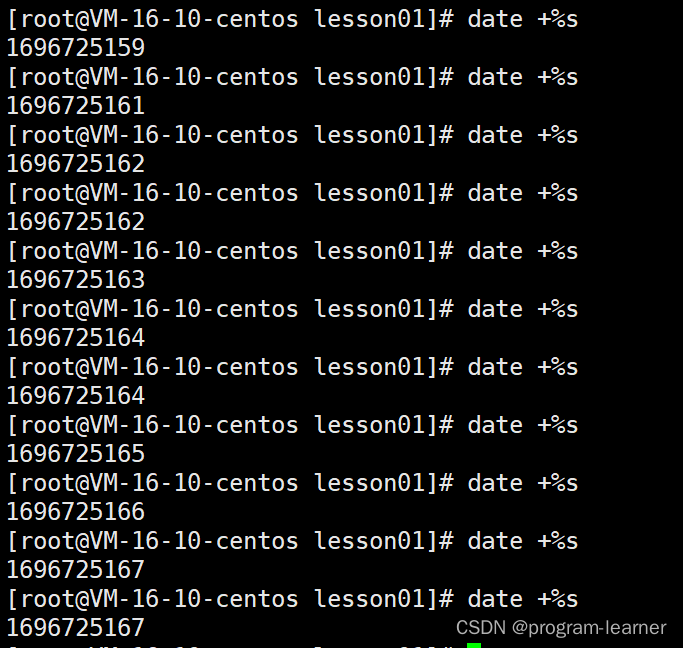
3.补充内容-日志
在软件开发中,
当一个线上的服务挂掉之后,我们比较关心的是三个问题:
1.什么时候挂掉的?
2.因为什么原因挂掉的?
3.我们接下来该怎么修正?
所以说日志的核心作用:辅助程序员进行问题排查
而日志中有一个非常重要的概念:时间
我们一般带两种时间
date +%Y-%m-%d_%H:%M:%S
date +%s
其中:
第一种:很明显很直观
第二种:因为时间戳是严格递增的,所以具有比较好的唯一性,也可以更好的进行范围查找
(比方说我要查找昨天晚上7点到8点的时间段的某个文件,就可以用7点和8点的时间戳,通过比较大小的方式来查找到对应的文件)
我们还可以把时间戳转换为时间
比方说我们想将0秒的时间戳的这个数据转换成对应的时间
同时我们还可以加上格式
至于这里为什么显示的是8点而不是0点,是因为地域关系,我国与格林威治存在一定的时差,这是转换之后的
我们还可以从网上查时间戳转换工具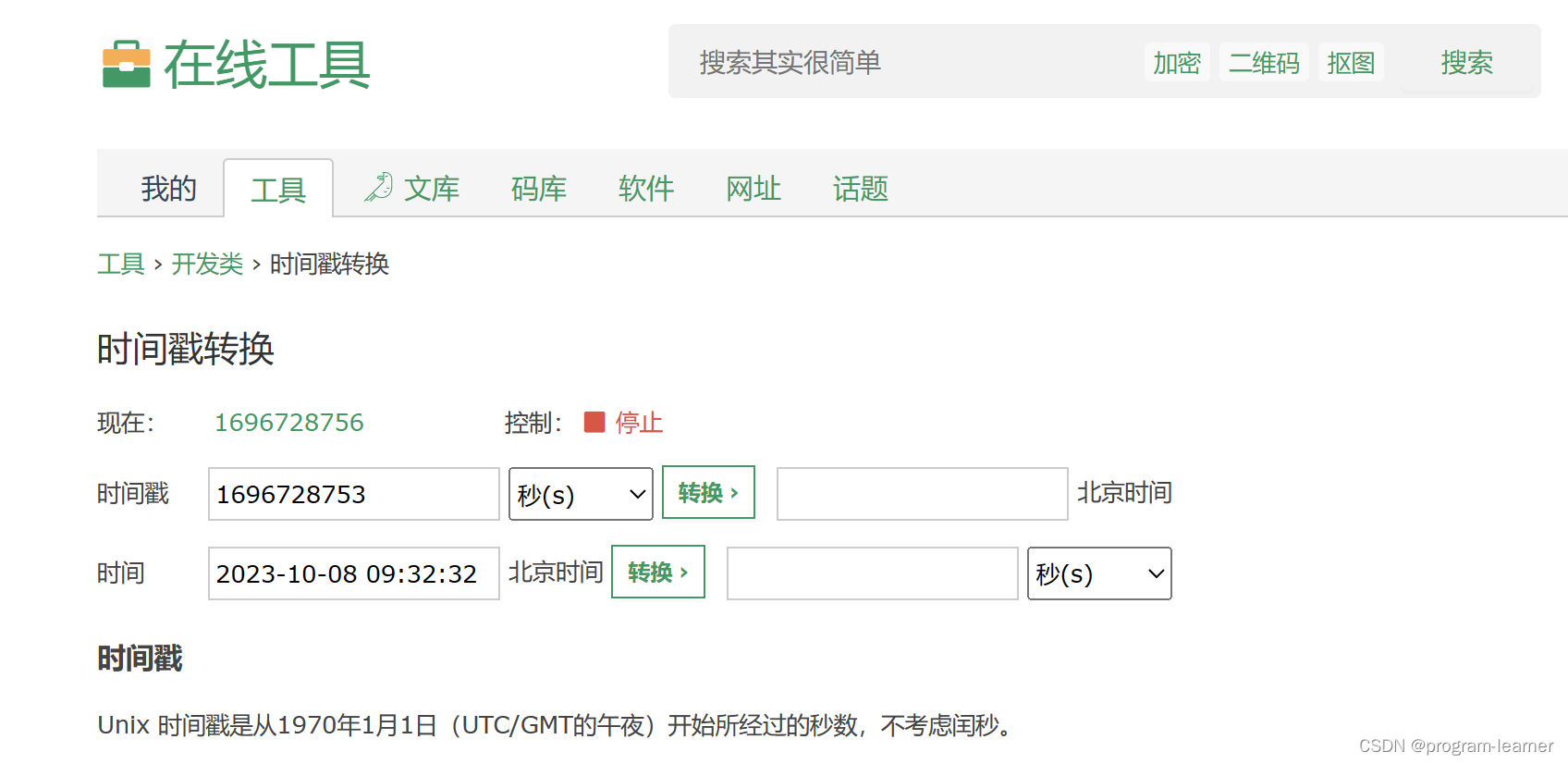
3.Cal

这个-y可加可不加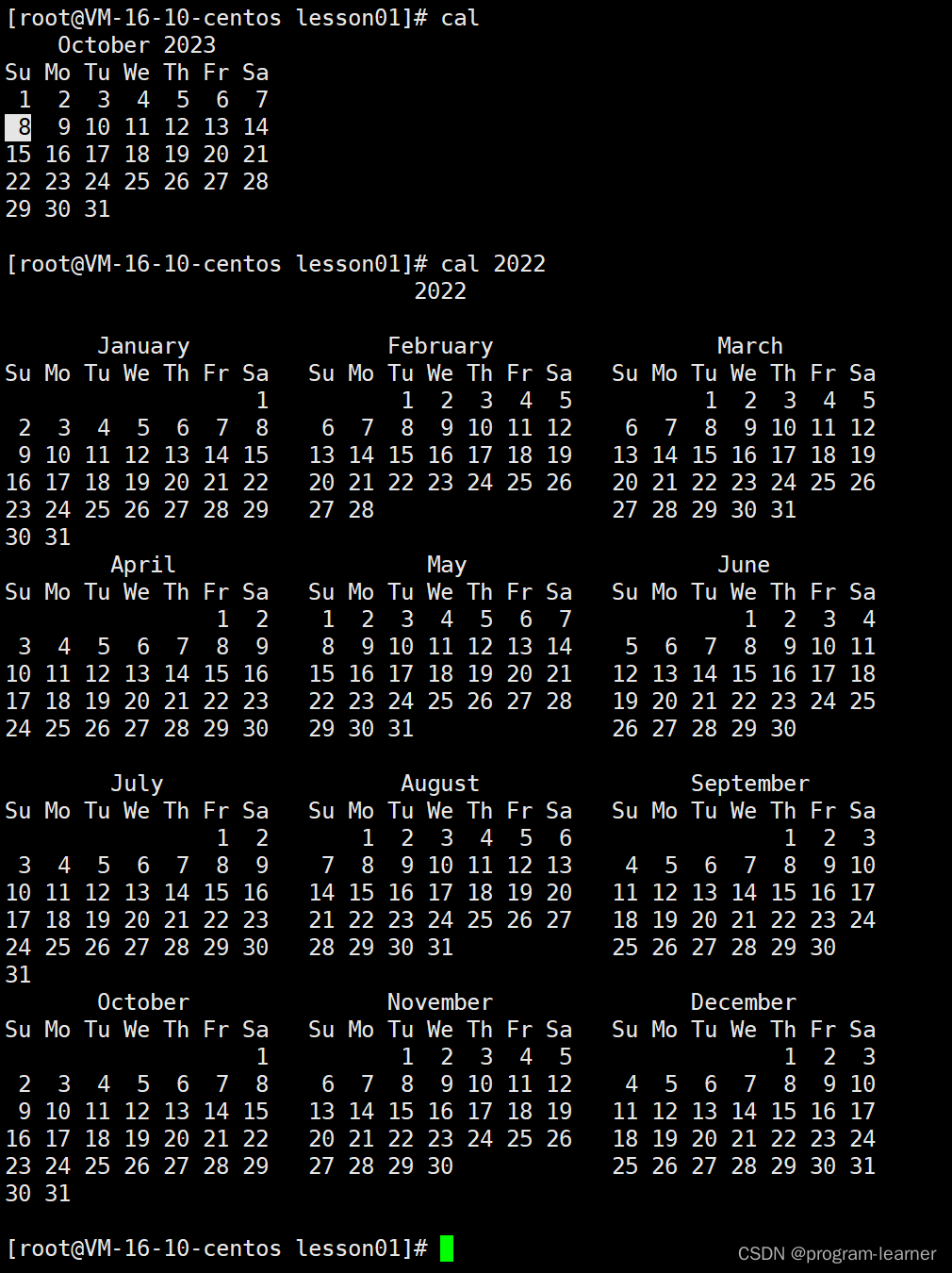
2.find

因为find命令后面可以跟的选项太多了,所以我们在这里只介绍一种
-name
比方说我现在想查找普通用户wzs的家目录下一共创建了多少个test.c文件
find命令不仅可以查找文件
还可以查找命令,库文件等等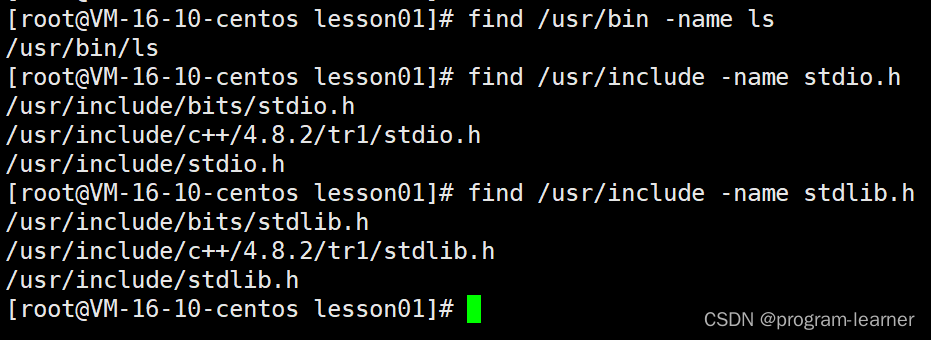
第一次可能查的比较慢,因为find命令是真的会在文件系统这个多叉树下进行遍历查找
不过第二次第三次会明显加快,因为有些查找过的目录结构已经提前缓存起来了
请注意:find命令在查找的时候需要指定路径
补充
1.which
which只用于查找指令,而且查找的时候不需要指定路径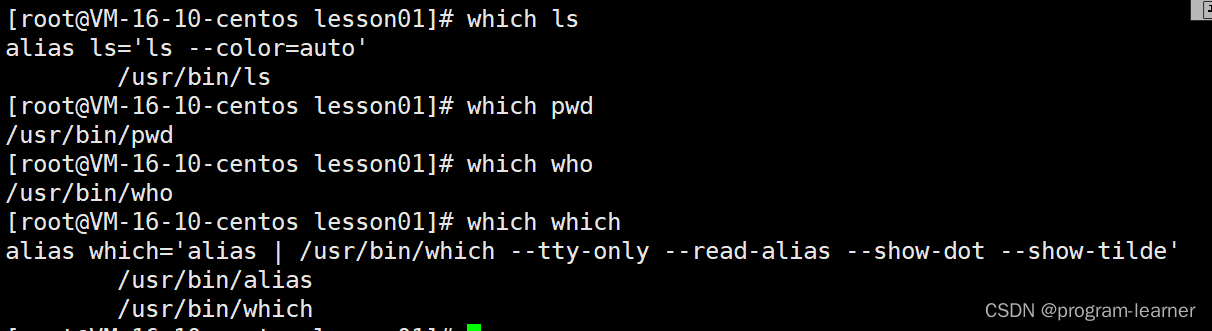
其中这个alias是重命名的意思
2.whereis
我们可以使用whereis查找
1.一些曾经安装过的文档
2.系统安装过的库头文件
3.指令
whereis也适用于*通配符
3.uname

-a
uname-a(显示Linux系统的详细信息)
[root@VM-16-10-centos lesson01]# uname -a
Linux VM-16-10-centos 3.10.0-1160.88.1.el7.x86_64 #1 SMP Tue Mar 7 15:41:52 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux

其中:
VM-16-10-centos :服务器的名称
3.10.0-1160.88.1.el7.x86_64 :采用的内核的版本
1 SMP Tue Mar 7 15:41:52 UTC 2023:系统安装时间
x86_64 x86_64 x86_64 GNU/Linux:体系结构
什么是体系结构呢?
狭义上讲:CPU的架构
广义上讲:整个操作系统加上计算机硬件的宏观上的各种各样的结构
-r
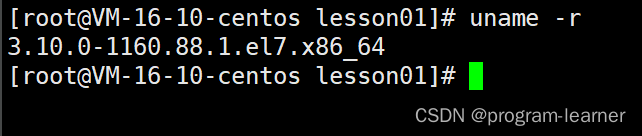
[root@VM-16-10-centos lesson01]# uname -r3.10.0-1160.88.1.el7.x86_64
技术发行版:3.10.0-1160.88.1
商业化发行版:el7
芯片架构:x86_64
显示我们用的是哪个商业化发行版本的系统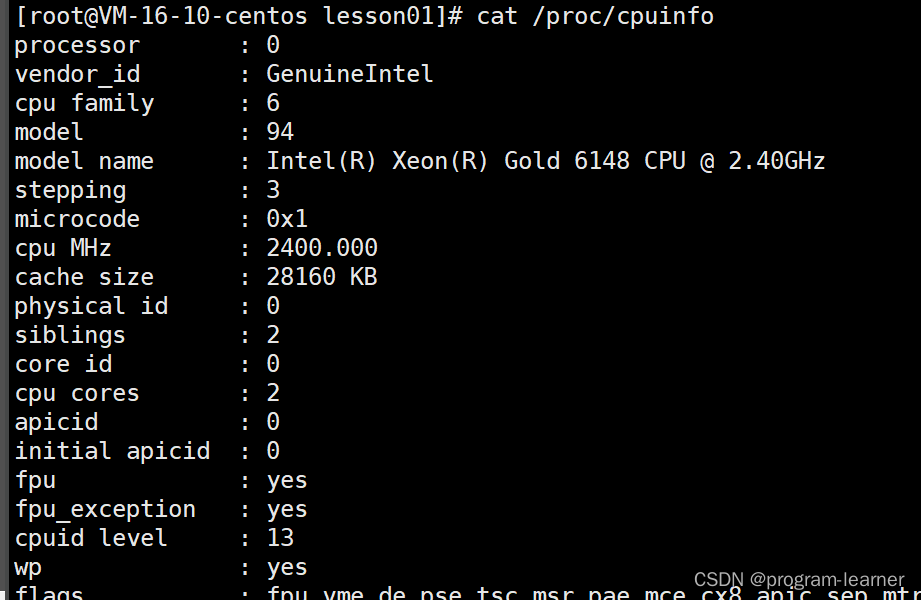
查看cpu的信息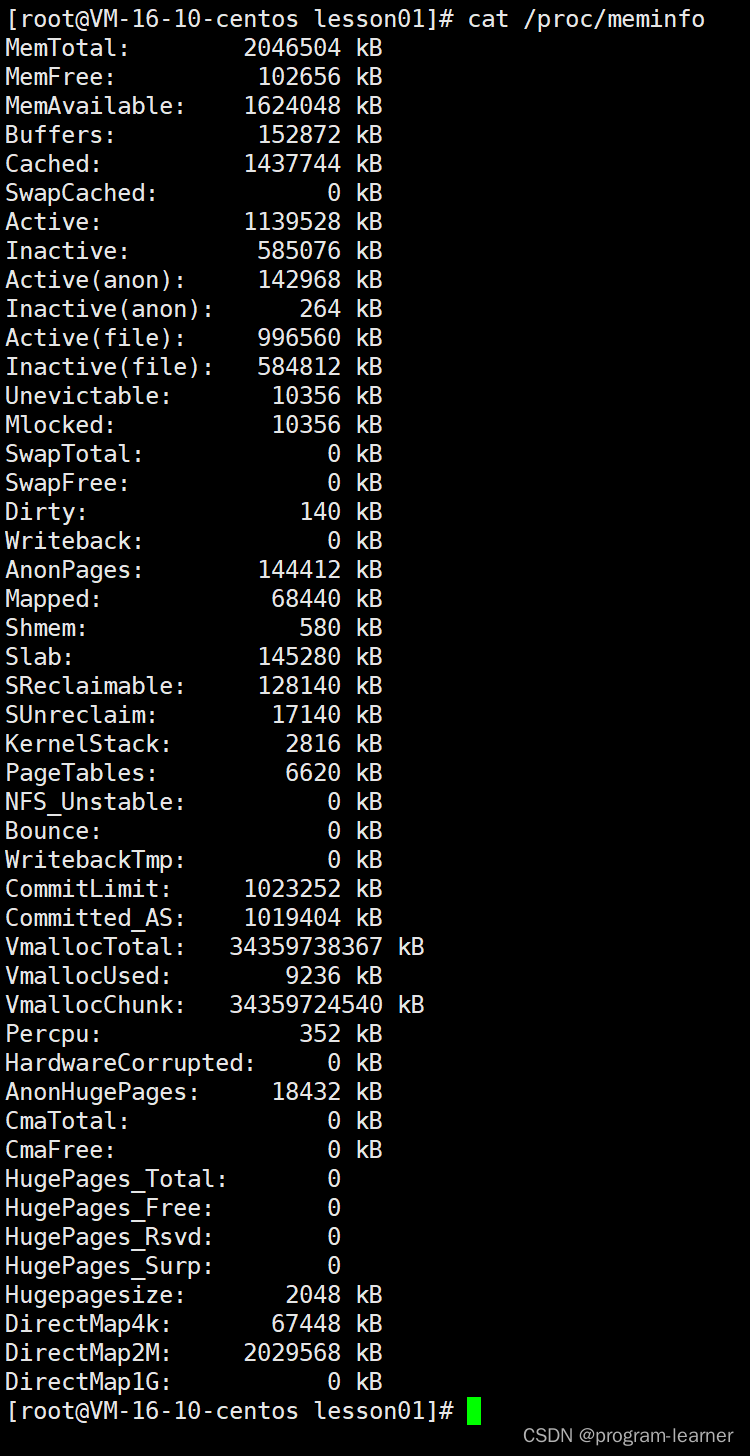
查看内存的使用信息
4.重要的几个热键

Tab快按两下
下面分别查询以a开头和以b开头的指令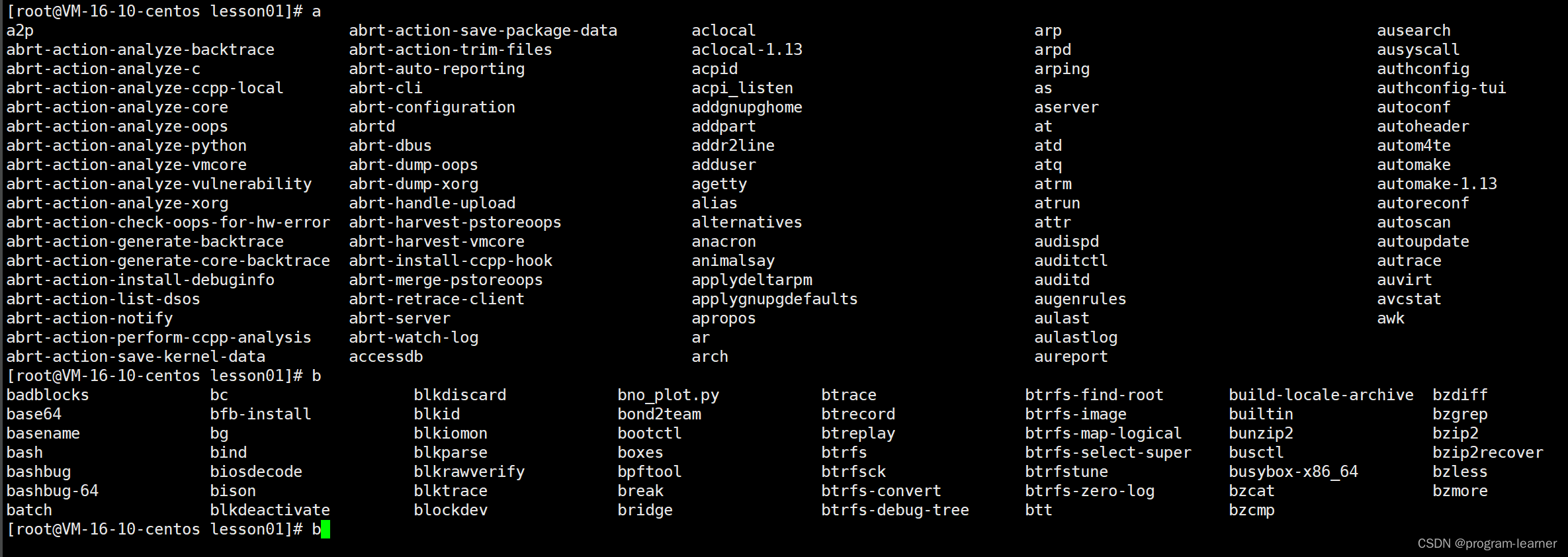
5.关机命令

不过请注意:云服务器永远不关机
跟windows不一样
二.grep

为了接下来方便操作我们先创建一个目录10.8
然后nano一个文件test.txt
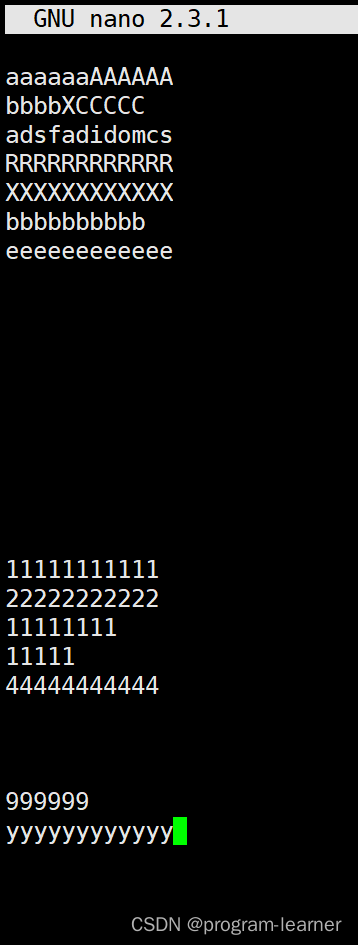
然后我们查找包含’A’的行
查找’ads’
查找’a’
-i选项
查找’A’和’a’的结果不同,说明grep默认是大小写敏感的
而我们可以通过-i选项来让它不敏感
(i:ignore:忽略的意思)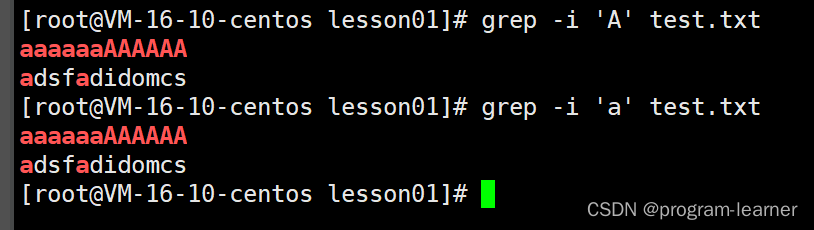
-n选项
我们在这里匹配的是空串
因此所有行都能被匹配上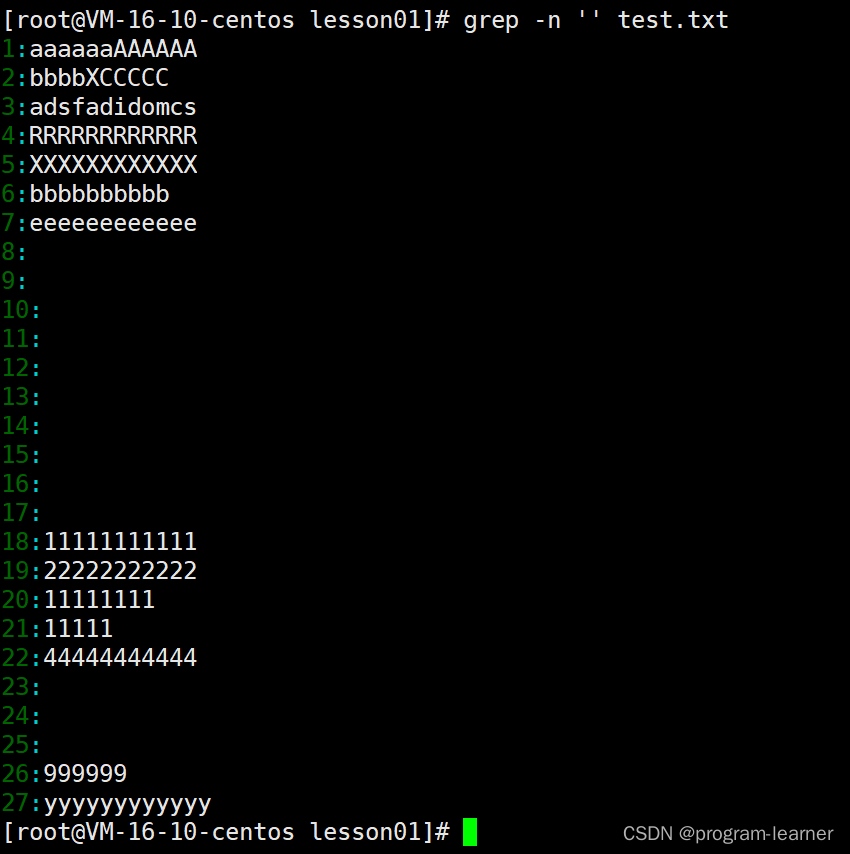
grep的选项也可以连起来,例如-ni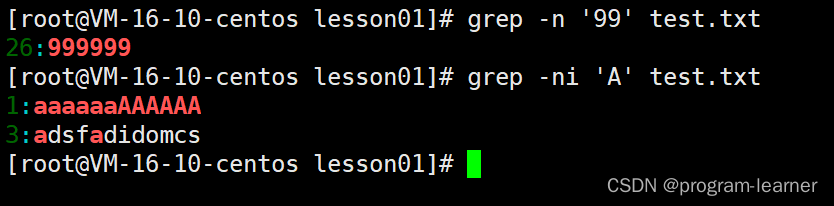
-v选项
-v:把不包含该关键字信息的行显示出来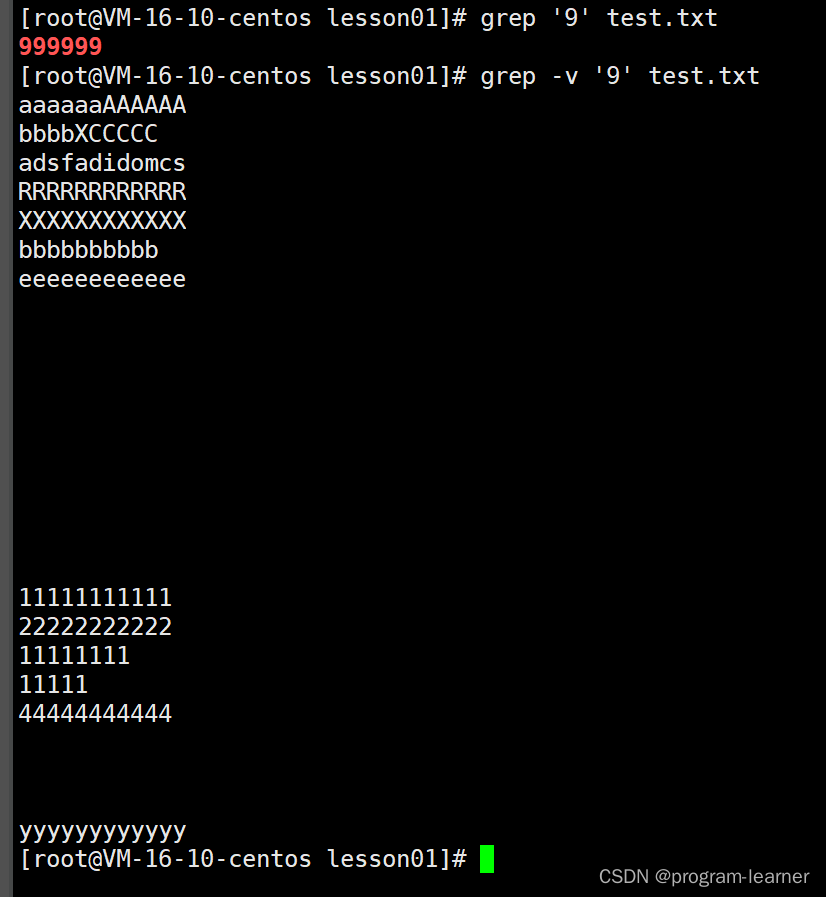
grep其他用途
1.搜索指定进程信息
ps:显示进程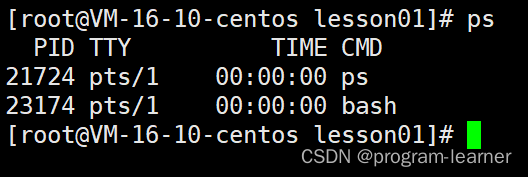
ps ajx:显示终端上的所有进程,包括其他用户的进程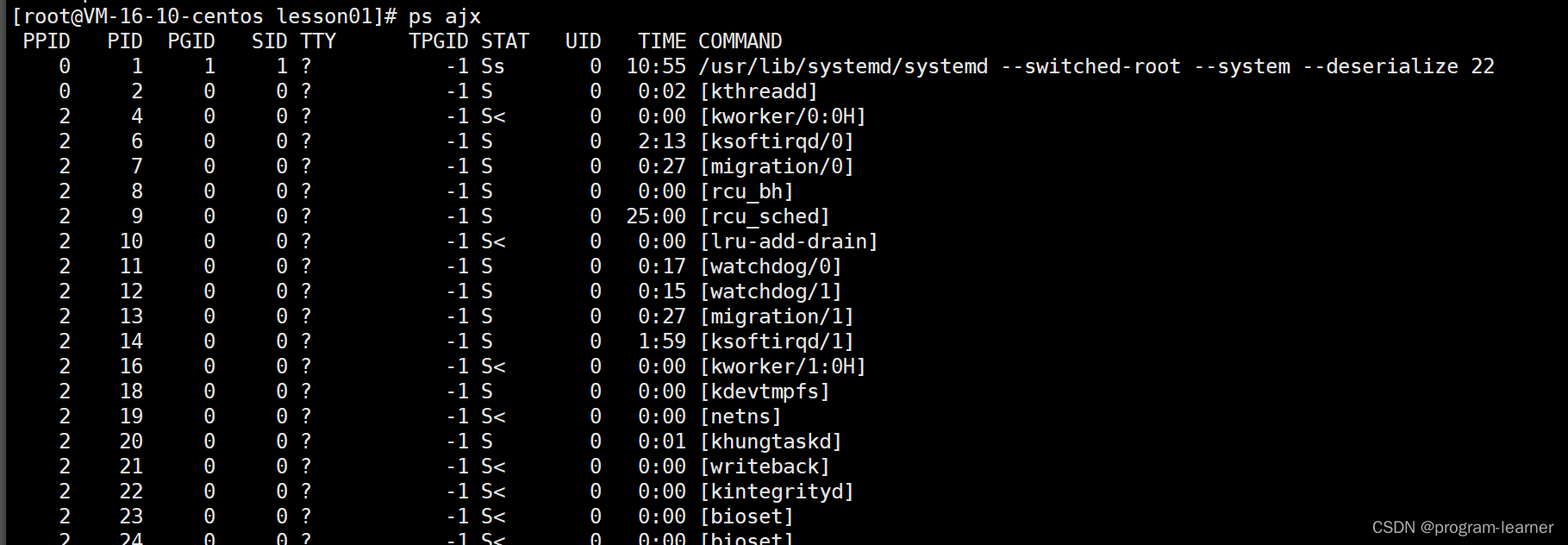
后面还有很多进程,没有给大家截图出来
可是如果我们现在只想找sleep的进程呢?
可以借助管道和grep命令
2.查找日志等级
日志等级包括:
DEBUG,Normal,Warning,Fatal等等…
如果我们现在想要查找error等级的日志呢?
补充命令
我们再次使用nano test.txt
加了几行e
补充命令:sort
sort可以按照文本对应的ASCII码值来进行排序后显示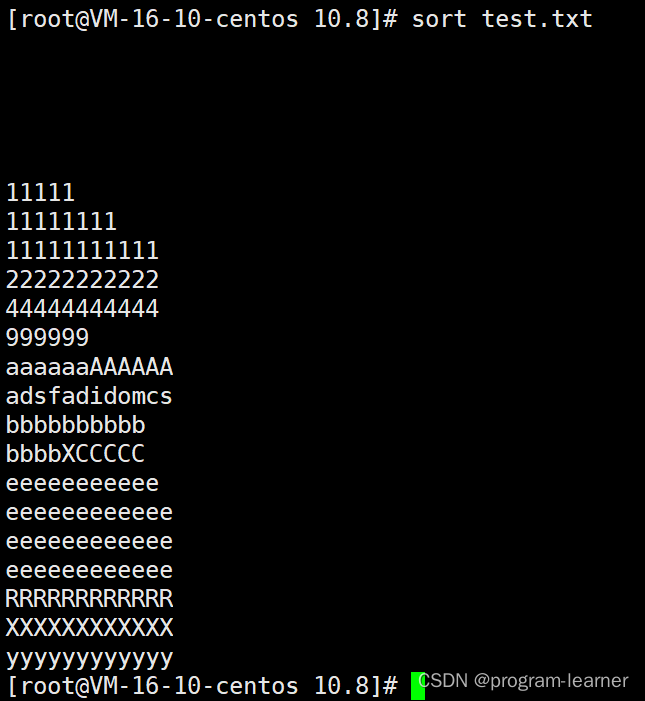
sort -r可以对文本进行逆向排序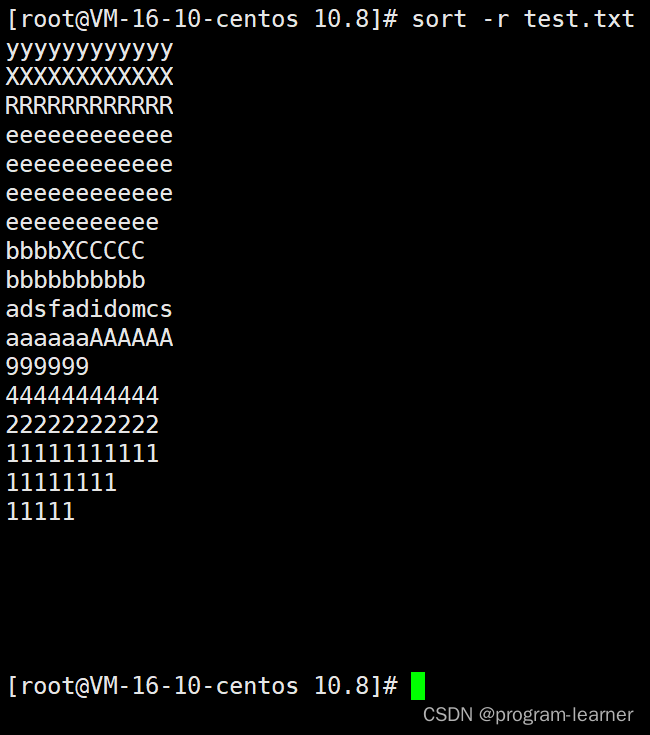
sort重要的是可以按照某种规则将相同的行放到一起
补充命令:uniq
uniq:就是unique(唯一的)的缩写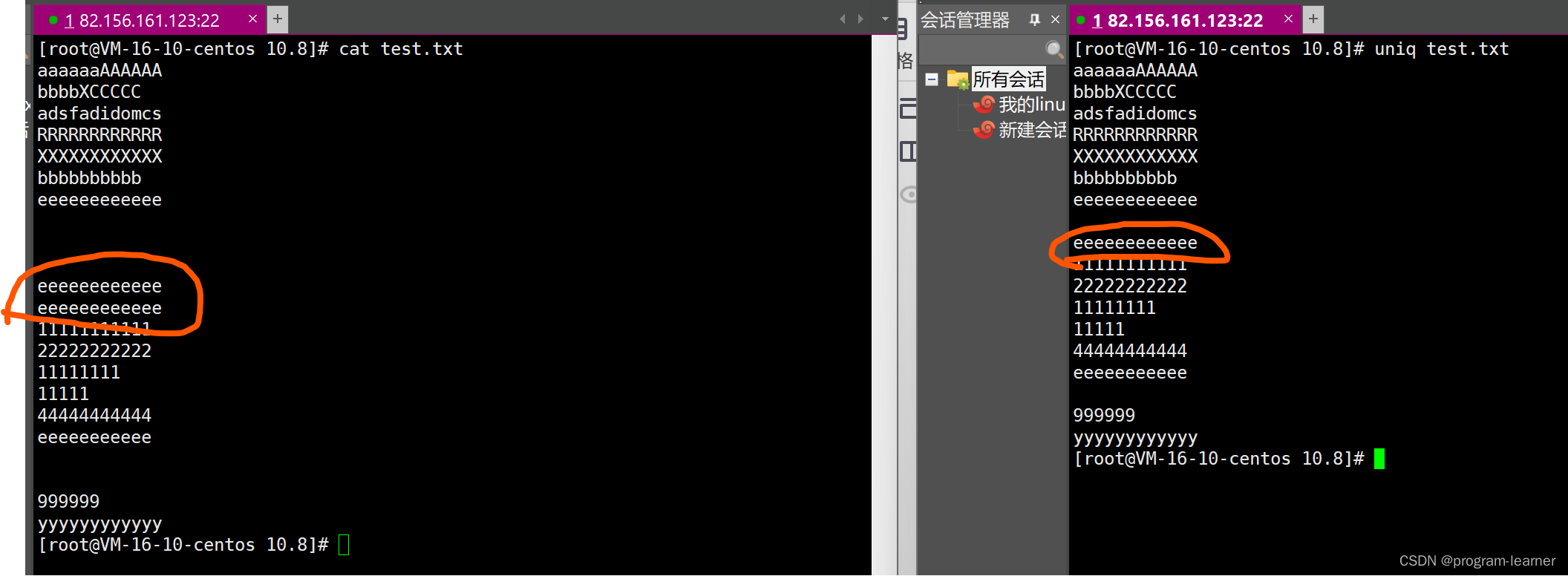
我们重点看这两行e
uniq后少了一行e
因此uniq的作用:对相邻两行进行压缩
如果相邻两行是重复的,那么就可以直接改为一行
uniq -u
uniq -u跟uniq的作用一样
也就是说uniq默认跟-u选项
uniq -d
uniq -d:把重复的行显示出来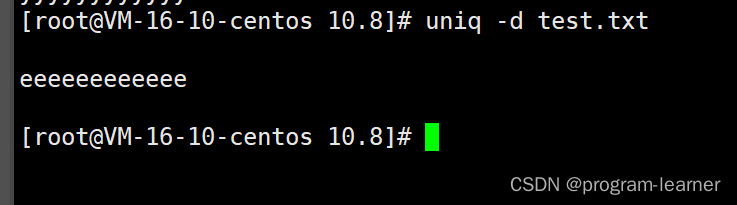
但是只进行uniq的话去重并不彻底
因此我们可以先sort将重复行放到相邻的位置,并且借助管道,然后再uniq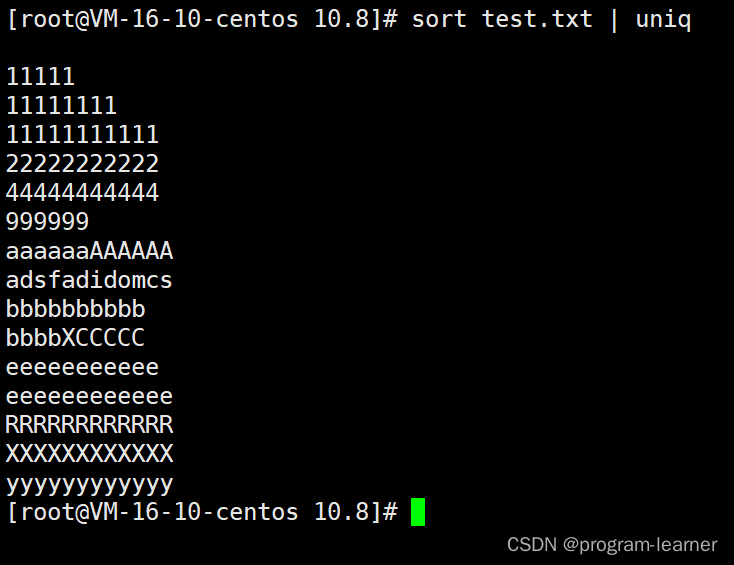
那么有什么用呢?
如果我们现在有一台服务器,我现在想知道一共有多少个用户访问过我(不要重复)
那么我们就可以对访问我的IP地址先sort,后uniq,然后统计一下个数即可
uniq -c
uniq -c:
把每一行的出现次数打印出来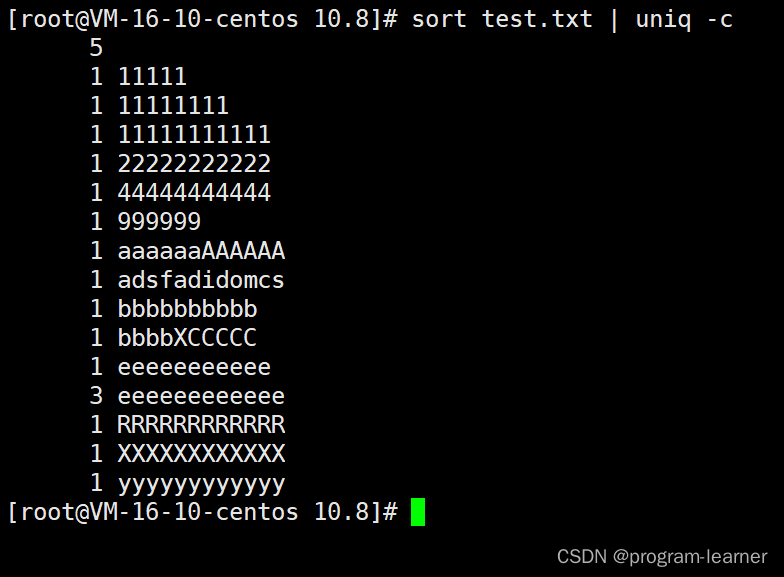
wc - l
wc -l(word count -line)
可以统计出行数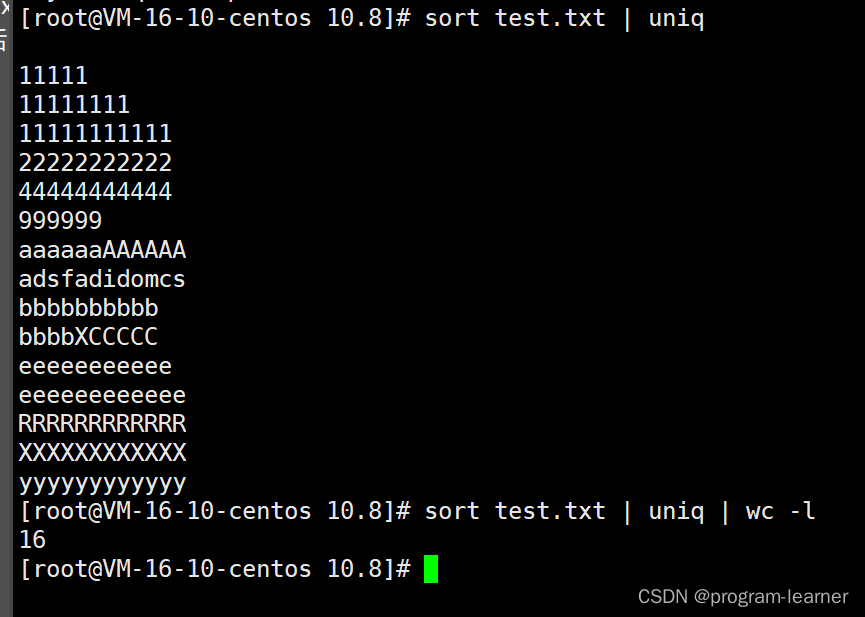
那么如果我现在想知道test.txt中
包含文本’1’的文本行拿出并且去重
去重之后再统计出一共有多少行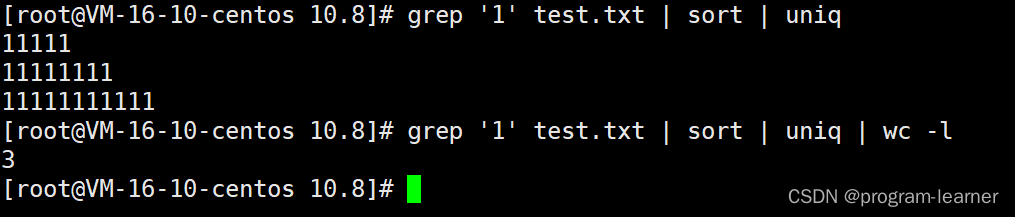
三.打包压缩相关命令
Linux下的两种最常见的压缩文件后缀名:
.zip
.tgz
1.知识点
为什么要进行打包压缩呢?
主要是为了
1.让多个文件变成一个文件,防止文件丢失
2.更节省空间
3.网络传输的时候更节省时间
在目前的时代下,第三个原因是最重要的
2.zip

比方说我们现在想要把
lesson01目录下的10.8目录压缩打包后转移到zipdir目录下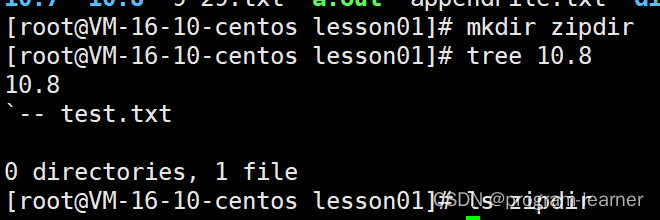
如果大家使用zip或者unzip的时候出现了command not found的提示的话,
那么就需要用yum安装zip
直接使用root用户输入:
yum install-yzip
我们先试一下不带-r选项,看看能不能把目录打包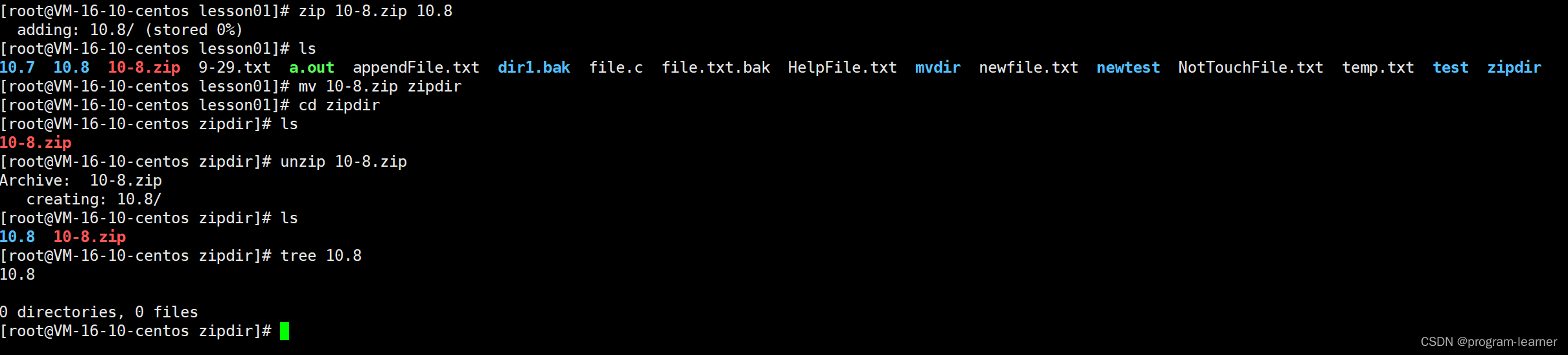
经过一顿操作之后,我们发现
尽管10.8目录的确打包到了zipdir目录中,但是:
10.8目录下的test.txt文件并没有成功打包到zipdir目录中
也就是说zip默认并不会把对应目录下的所有文件都进行打包
所以我们需要带上-r选项
我们先把zipdir清空
删除和清空之后,我们又经过一顿操作
最后打包成功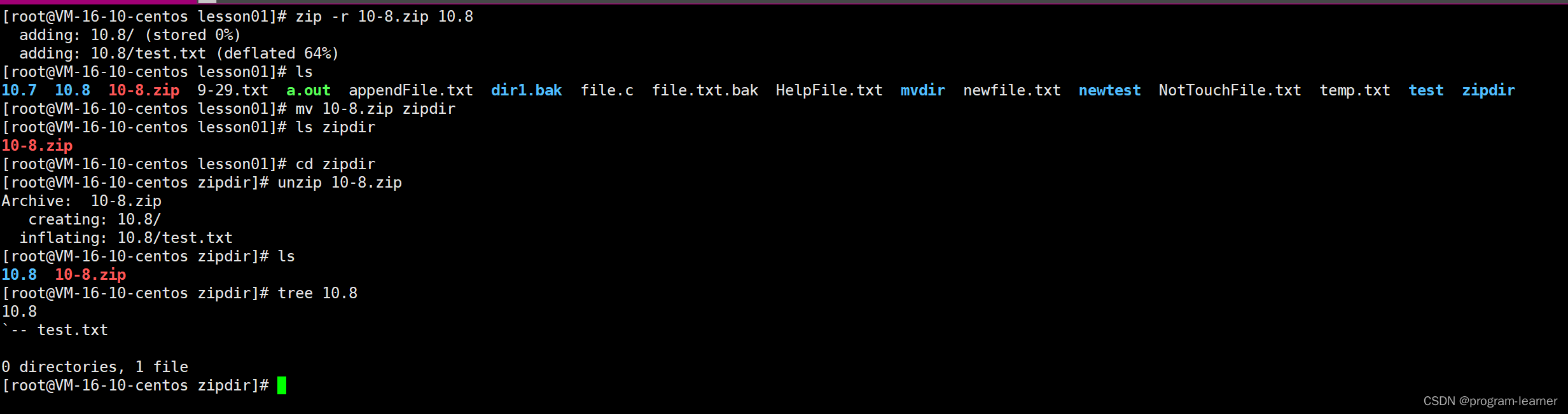
我们知道windows系统中的压缩文件我们可以自主选择解压到哪里
Linux下也是如此,不过需要用到-d选项
-d选项
为了便于操作,我们再次清空zipdir,
然后继续压缩+解压,只不过这次就不用mv命令了,直接把lesson01目录下的压缩文件解压到zipdir目录下

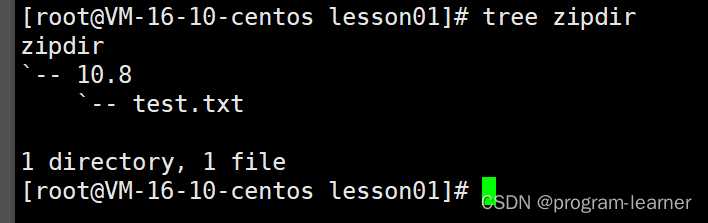
3.tar

我们通常是这样使用的
-c:创建一个新的压缩包
-z:打包的时候顺便进行压缩
-f:后面紧跟要打包为…的名称(xxx.tgz)(即指定一个新的名称,不要再去使用默认名称)
压缩: -czf
解压: 把c选项换成x选项即可:
-x:代表解包命令
接下来我们创建一个新目录tardir
将10.8目录打包压缩到tardir目录中
经过一顿操作后,我们解压成功
而这个-v选项就是把压缩或者解压的过程显示出来而已
因此:
tar -czf/cvzf dst.tgz src
tar -xzf/xvzf dst.tgz
dst:要形成的压缩文件的名称
src:要打包的文件名/目录名
那么tar可不可以解压到指定目录下面呢?
当然可以
只不过需要带上-C选项
-C选项
我们清空tardir目录
经过一顿操作后打包成功
补充内容:windows和Linux互传数据
建议传送文件的时候传送压缩文件
首先需要安装sz,rz命令
使用root用户执行:
yum install -y lrzsz
1.Linux传送文件到windows中:
比方说我们要把10.8目录下的test.txt文件传到windows中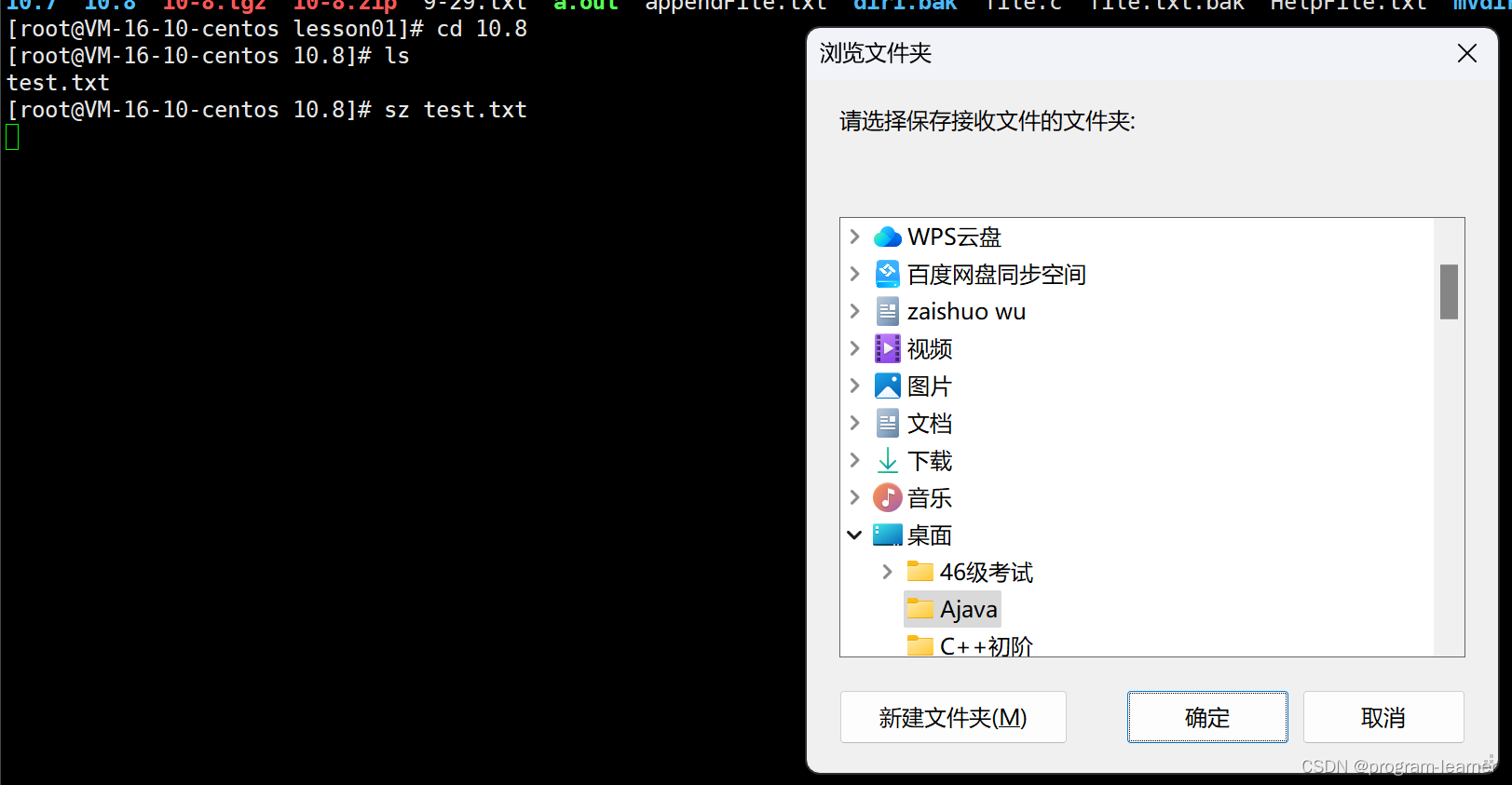
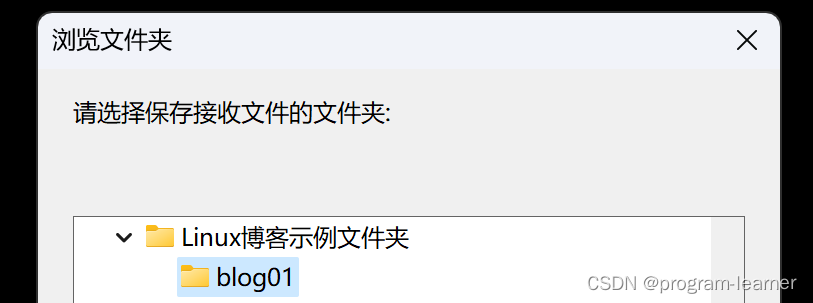
我们把它放到这个文件夹下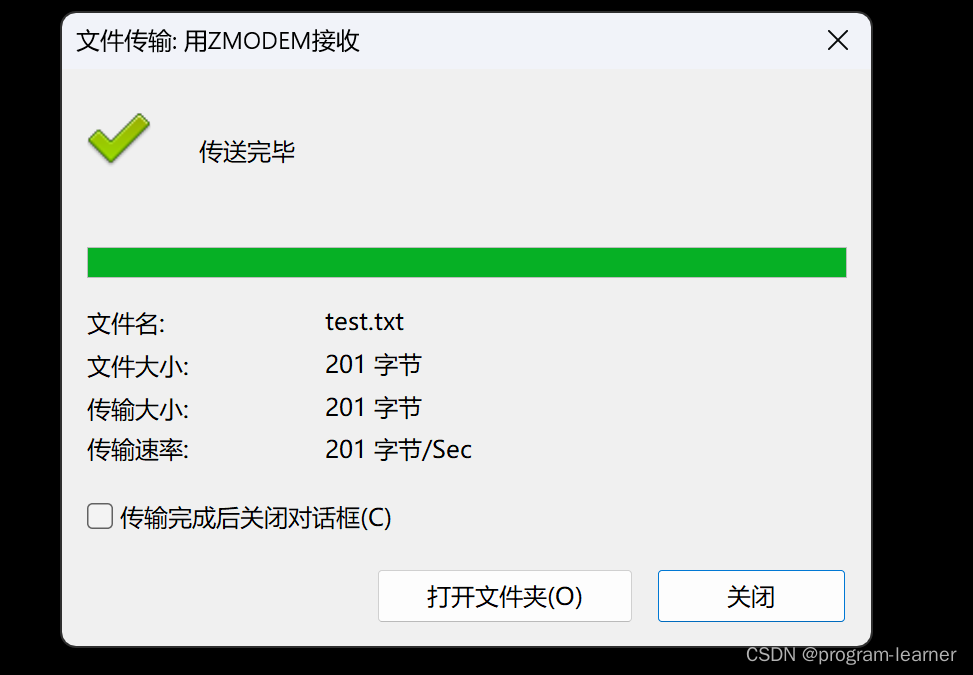
然后我们打开这个文件,里面的内容完全相同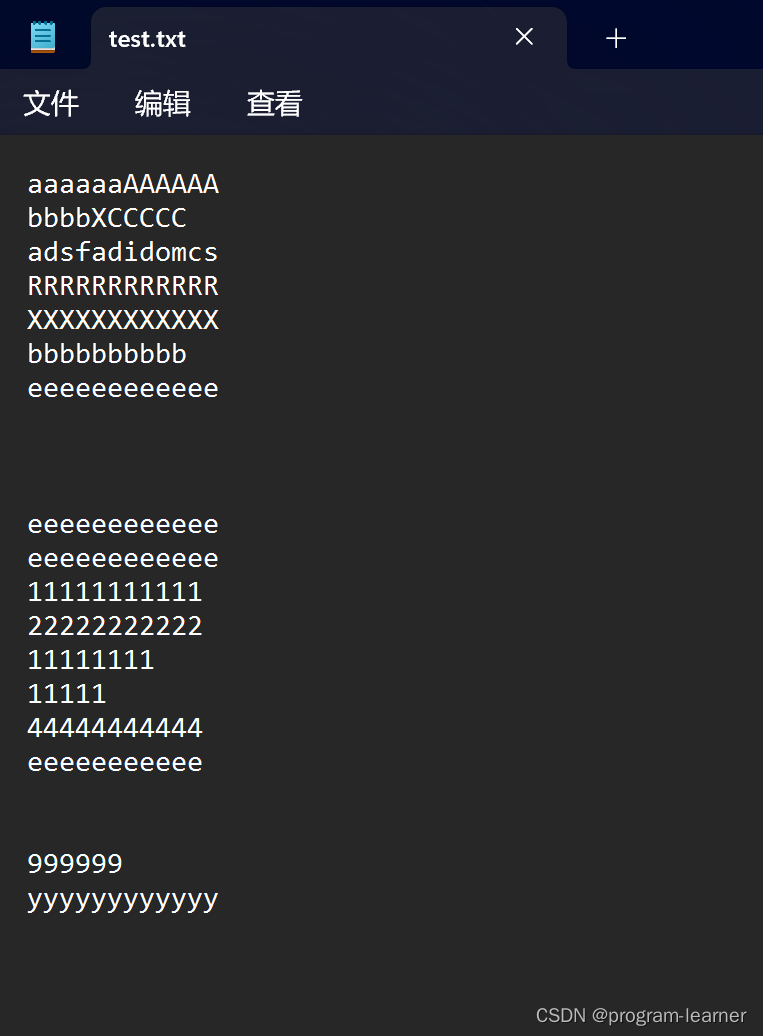
2.windows文件传送到Linux中,直接拖拽进去即可
我们现在在10.8目录下,我想把桌面上的wintest.txt传送到Linux的10.8目录下
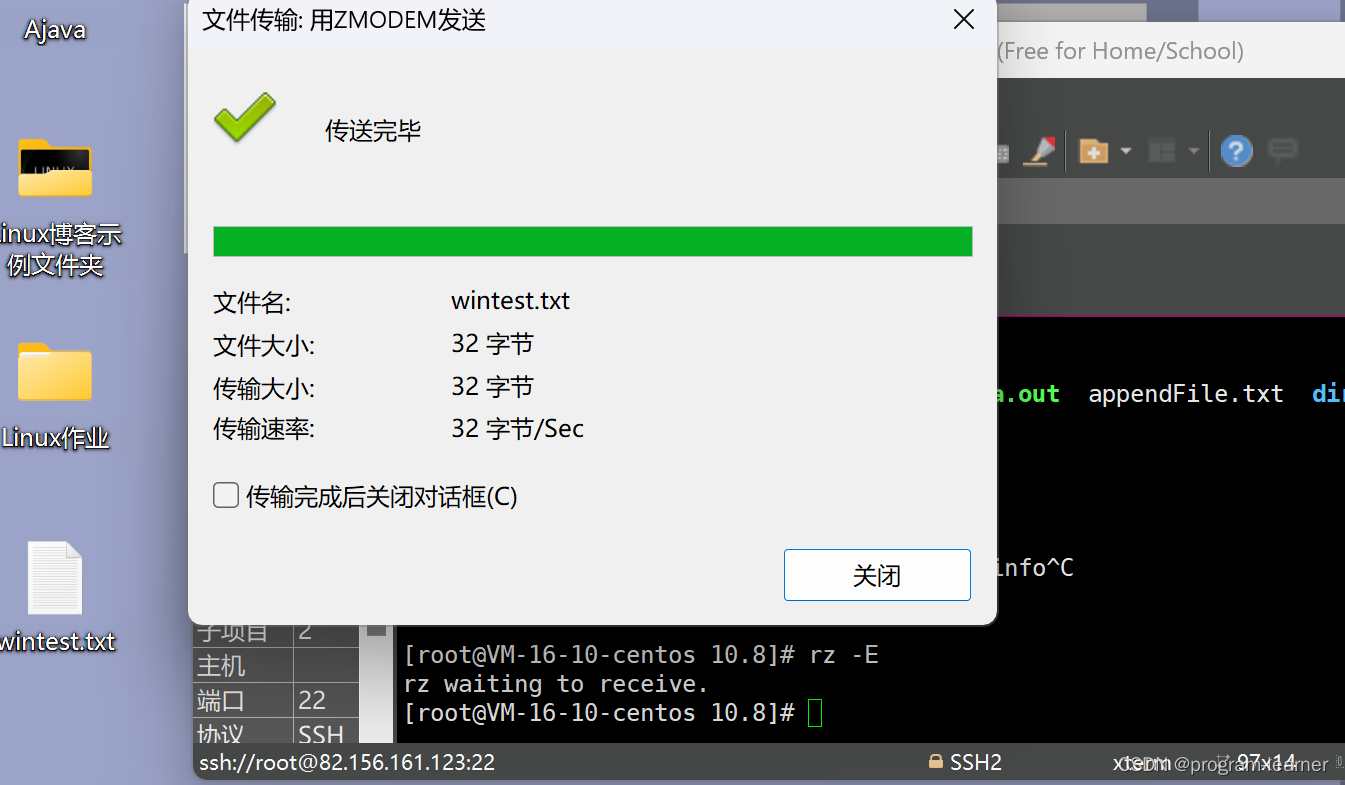
传输成功
如果我想进行两台Linux服务器之间的文件传送呢?
scp 文件名 用户名@机器的IP地址:该用户的家目录
scp:远程拷贝
需要输入接收文件的用户的密码
以上就是Linux常见指令3的全部内容,希望能对大家有所帮助!
版权归原作者 program-learner 所有, 如有侵权,请联系我们删除。