
1.选择题
1.经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含多个子项目,其中YARN的主要功能是?
A.负责集群资源调度管理的组件
B.分布式并行编程模型
C.分布式海量日志采集、聚合和传输系统
D.数据仓库工具
正确答案:A
2.[单选题]大数据时代,数据使用的关键是?
A.数据收集
B.数据存储
C.数据分析
D.数据再利用
正确答案:D
3.[单选题]
大数据的最显著特征是?
A.数据规模大
B.数据类型多样
C.数据处理速度快
D.数据价值密度高
我的答案:A
4.[单选题]
以下哪一项不是Hadoop的缺点?
A.计算延迟高
B.数据文件被分布存储到多台机器上
C.磁盘I/O开销大
D.计算表达能力有限
正确答案:B
5.[单选题]
大数据计算模式有以下四种,对电子商务网站购物平台数据的实时分析处理过程属于哪一种?
A.查询分析计算
B.图计算
C.流计算
D.批处理计算
我的答案:C
6.[单选题]
当前大数据技术的基础是由()首先提出来的?
A.微软
B.百度
C.谷歌
D.阿里巴巴
我的答案:C
7.[单选题]
大数据的起源是?
A.金融
B.电信
C.互联网
D.公共管理
正确答案:C
8.[多选题]
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统,可以支持以下哪些操作计算?
A.流式计算
B.SQL即席查询
C.图计算
D.机器学习
正确答案:ABCD
9.[多选题]
Hadoop两大核心组成部分是什么?
A.分布式协作服务Zookeeper
B.分布式文件系统HDFS
C.分布式计算框架MapReduce
D.资源调度管理框架YARN
正确答案:BC
10.[多选题]
目前学术界和业界比较认可的关于大数据的四个特点是?
A.处理速度快
B.数据量大
C.数据类型多
D.数据可重复使用
正确答案:ABC
11.[多选题]大数据处理流程可以概括为以下哪几步?
A.挖掘
B.采集
C.统计与分析
D.导入和预处理
正确答案:ABCD
12.[判断题]目前非结构化数据已经占据人类数据总量的10%。
正确答案:错
1.[单选题]spark是Hadoop生态下哪个组件的替代方案?
A.Hadoop
B.Yarn
C.HDFS
D.MapReduce
我的答案:D
正确答案:D
2.[单选题]Spark的四大组件下面哪个不是?
A.Spark Streaming
B.Mlib
C.Graphx
D.Spark R
我的答案:D
正确答案:D
3.[单选题]Spark是用以下哪种编程语言实现的?
A.C
B.C++
C.Java
D.Scala
我的答案:D
正确答案:D
4.[单选题]
下列哪个不是Spark的组件?
A.Driver
B.SparkContext
C.ClusterManager
D.ResourceManager
我的答案:D
正确答案:D
5.[单选题]
下面哪个不是 RDD 的特点
A.可分区
B.可序列化
C.可修改
D.可持久化
我的答案:C
6.[单选题]
Task是Executor上的工作单元,运行于下面哪个组件上?
A.Driver Program
B.Spark Master
C.Worker Node
D.Cluster Manager
我的答案:C
正确答案:C
7.[多选题]
Spark的运行架构包括哪些
A.集群资源管理器
B.执行进程
C.worker Node
D.任务控制节点
我的答案:ABCD
正确答案:ABCD
8.[多选题]
以下是Spark的主要特点的有?
A.运行速度快
B.容易使用,简洁的API设计有助于用户轻松构建并行程序
C.通用性,Spark提供了完整而强大的技术栈
D.运行模式多样
我的答案:ABCD
正确答案:ABCD
9.[多选题]
Spark可以采用几种不同的部署方式,以下正确的部署方式有?
A.Local
B.Standalone
C.Spark on Mesos
D.Spark on YARN
我的答案:ABCD
正确答案:ABCD
10.[多选题]
目前的大数据处理典型应用场景可分为哪几个类型?
A.复杂的批量数据处理
B.基于历史数据的交互式查询
C.大数据的分布式计算
D.基于实时数据流的数据处理
我的答案:ABD
正确答案:ABD
11.[多选题]
以下选项中哪些是Spark的优点?
A.具有高效的容错性
B.利用进程模型
C.可以将中间结果持久化到内存
D.表达能力有限
我的答案:AC
正确答案:AC
spark-shell在启动时,采用local[*]时,它的含义是?
A.使用任意个线程来本地化运行Spark
B.使用与逻辑CPU个数相同数量的线程来本地化运行Spark
C.使用与逻辑CPU个数相同数量的进程来本地化运行Spark
D.使用单个线程来本地化运行Spark
我的答案:B
正确答案:B
2.[单选题]
判断HDFS是否启动成功,可以通过哪个命令?
A.hdfs
B.spark
C.jps
D.start-dfs
我的答案:C
正确答案:C
3.[单选题]
下列描述正确的是()
A.Hadoop和Spark不能部署在同一个集群中
B.Hadoop只包含了存储组件,不包含计算组件
C.Spark是一个分布式计算框架,可以和Hadoop组合使用
D.Spark和Hadoop是竞争关系,二者不能组合使用
我的答案:C
正确答案:C
4.[多选题]
关于Hadoop和Spark的相互关系,以下说法正确的是?
A.Hadoop和Spark可以相互协作
B.Hadoop负责数据的存储和管理
C.Spark负责数据的计算
D.Spark要操作Hadoop中的数据,需要先启动HDFS
我的答案:ABCD
正确答案:ABCD
5.[多选题]
HDFS若启动成功,系统会列出以下哪些进程?
A.NameNode
B.HDFS
C.DataNode
D.SecondaryNameNode
我的答案:ACD
正确答案:ACD
6.[多选题]
Spark-shell在启动时;采用yarn-client模式时,以下说法正确的是()
A.当用户提交了作业之后,不能关掉Client
B.当用户提交了作业之后,就可以关掉Client
C.该模式适合运行交互类型的作业
D.该模式不适合运行交互类型的作业
正确答案:AC
7.[多选题]
Spark-shel在启动时,采用yarn-cluster模式时,以下说法正确的是?
A.当用户提交了作业之后,不能关掉Client
B.当用户提交了作业之后,就可以关掉Client
C.该模式适合运行交互类型的作业
D.该模式不适合运行交互类型的作业
我的答案:BD
正确答案:BD
8.[多选题]
开发Spark独立应用程序的基本步骤通常有哪些?
A.安装编译打包工具,如sbt、Maven
B.编写Spark应用程序代码
C.编译打包
D.通过spark-submit运行程序
我的答案:ABCD
正确答案:ABCD
9.[多选题]
集群上运行Spark应用程序的方法步骤有哪些?
A.启动Hadoop集群
B.启动Spark的Master节点和所有Slave节点
C.在集群中运行应用程序JAR包
D.查看集群信息以获得应用程序运行的相关信息
我的答案:ABCD
正确答案:ABCD
假设有一个RDD的名称为words,包含9个元素,分别是:(”Hadoop”,1),(”is”,1),(”good”,1),(”Spark”,1),(”is”,1),(”fast”,1),(”Spark”,1),(”is”,1),(”better”,1)。则语句words.groupByKey()的执行结果得到的新的RDD中,所包含的元素是()
A.(”good”,1),(”Spark”,1),(”is”,1),(”fast”,1)
B.(”Hadoop”,1),(”is”,1),(”good”,1),(”Spark”,1),(”is”,1)
C.(”Hadoop”,1),(”is”,(1,1,1)),(”good”,1),(”Spark”,(1,1)),(”fast”,1),(”better”,1)
D.(”good”,(1,1)),(”Spark”,(1,1,1)),(”is”,1),(”fast”,1)
我的答案:C
正确答案:C
2.[单选题]
val rdd=sc.parallelize(Array(1,2,3,4,5))
rdd.take(3)
上述语句执行的结果是?
A.6
B.Array(1,2,3)
C.3
D.Array(2,3,4)
我的答案:B
正确答案:B
3.[单选题]
有一个键值对RDD,名称为pairRDD,它包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1),则pairRDD.reduceByKey((a,b)=>a+b)执行结果得到的RDD,它里面包含的元素是
A.(“Hadoop”,1),(“Spark”,2),(“Hive”,2)
B.(“Hadoop”,1),(“Spark”,2),(“Hive”,1)
C.(“Hadoop”,2),(“Spark”,2),(“Hive”,2)
D.(“Hadoop”,2),(“Spark”,1),(“Hive”,1)
我的答案:B
正确答案:B
4.[单选题]
val words = Array(“one”, “two”, “two”, “three”, “three”, “three”)
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithGroup = wordPairsRDD. groupByKey().map(t => (t._1, t._2.sum))
上述语句的执行结果wordCountsWithGroup中包含的元素是
A.(“one”,1),(“two”,2),(“three”,3)
B.(“one”,1),(“two”,2),(“three”,1)
C.(“one”,3),(“two”,2),(“three”,1)
D.(“one”,1),(“two”,1),(“three”,1)
我的答案:A
5.[单选题]
val pairRDD1 = sc. parallelize(Array((“spark”,1),(“spark”,2),(“hadoop”,3),(“hadoop”,5)))
val pairRDD2 = sc.parallelize(Array((“spark”,“fast”)))
pairRDD1.join(pairRDD2)
上述语句执行以后,pairRDD1这个RDD中所包含的元素是
A.(“hadoop”,(3,”fast”)), (“hadoop”,(5,”fast”))
B.(“spark”,(3,”fast”)), (“spark”,(5,”fast”))
C. (“hadoop”,(2,”fast”)), (“hadoop”,(1,”fast”))
D.(“spark”,(1,”fast”)), (“spark”,(2,”fast”))
我的答案:D
正确答案:D
6.[多选题]
RDD操作包括哪两种类型
A.转换
B.连接
C.行动
D.分组
我的答案:AC
正确答案:AC
7.[多选题]
以下操作中,哪些是转换操作?
A.count()
B.first()
C.filter()
D.reduceByKey(func)
我的答案:CD
正确答案:CD
8.[多选题]
以下操作中,哪些是行动操作?
A.reduce()
B.collect()
C.groupByKey()
D.map()
我的答案:AB
正确答案:AB
要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:
A.df.write.json(“people.json”)
B.df.json(“people.json”)
C.df.write.format(“csv”).save(“people.json”)
D.df.write.csv(“people.json”)
我的答案:A
正确答案:A
2.[单选题]
以下操作中,哪个不是DataFrame的常用操作:
A.printSchema()
B.select()
C.filter()
D.sendto()
我的答案:D
正确答案:D
3.[多选题]
下面关于为什么推出Spark SQL的原因的描述正确的是:
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力
正确答案:AB
4.[多选题]
下面关于DataFrame的描述正确的是:
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
我的答案:ABCD
正确答案:ABCD
5.[多选题]
要读取people.json文件生成DataFrame,可以使用下面哪些命令:
A.spark.read.json(“people.json”)
B.spark.read.parquet(“people.json”)
C.spark.read.format(“json”).load(“people.json”)
D.spark.read.format(“csv”).load(“people.json”)
我的答案:AC
6.[多选题]
从RDD转换得到DataFrame包含两种典型方法,分别是:
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式
正确答案:AB
7.[多选题]
使用编程方式定义RDD模式时,主要包括哪三个步骤:
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起
正确答案:ABD
下面关于Spark Streaming的描述错误的是:
A.Spark Streaming的基本原理是将实时输入数据流以时间片为单位进行拆分,然后采用Spark引擎以类似批处理的方式处理每个时间片数据
B.Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流
C.Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字
D.Spark Streaming的数据抽象是DataFrame
我的答案:D
2.[单选题]
下面描述错误的是:
A.在RDD编程中需要生成一个SparkContext对象
B.在Spark SQL编程中需要生成一个SparkSession对象
C.运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象
D.在Spark SQL编程中需要生成一个StreamingContext对象
正确答案:D
3.[多选题]
以下关于流数据特征的描述,哪些是正确的:
A.数据快速持续到达,潜在大小也许是无穷无尽的
B.数据来源众多,格式复杂
C.数据量大,但是不十分关注存储,一旦流数据中的某个元素经过处理,要么被丢弃,要么被归档存储
D.数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序
我的答案:ABCD
4.[多选题]
流计算处理流程一般包括哪三个阶段:
A.数据实时采集
B.数据实时计算
C.数据汇总分析
D.实时查询服务
正确答案:ABD
5.[多选题]
流处理系统与传统的数据处理系统的不同之处在于:
A.流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据
B.用户通过流处理系统获取的是实时结果,而通过传统的数据处理系统获取的是过去某一时刻的结果
C.流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户
D.流处理系统处理的是历史的数据,而传统的数据处理系统处理的是实时的数据
我的答案:ABC
正确答案:ABC
6.[多选题]
编写Spark Streaming程序的基本步骤包括:
A.通过创建输入DStream(Input Dstream)来定义输入源
B.通过对DStream应用转换操作和输出操作来定义流计算
C.调用StreamingContext对象的start()方法来开始接收数据和处理流程
D.通过调用StreamingContext对象的awaitTermination()方法来等待流计算进程结束
我的答案:ABCD
正确答案:ABCD
2.大题(必会)
- 6.Spark是一个大一统的软件栈,主要包括哪些部分?
Spark的核心是一个对由很多计算任务组成的,运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎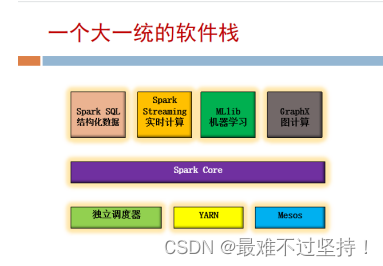
- 10.Spark的运行基本原理是什么?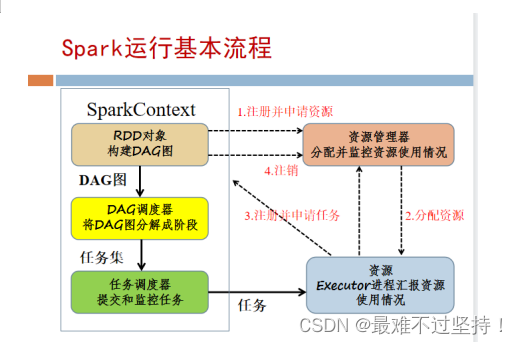
- 18.RDD转换操作和行动操作的区别是什么?
行动操作接受RDD但不返回RDD,主要用于执行计算并指定输出的形式;
转换操作接受RDD并返回RDD,主要用于指定RDD之间的依赖关系。
- 22.Shuffle是什么?以reduceByKey用来统计词频为例,来描述shuffle过程以及shuffle的缺点?
Shuffle(混洗):把Map输出结果进行分区、排序、合并等处理,并将结果分发到Reduce任务所在的机器。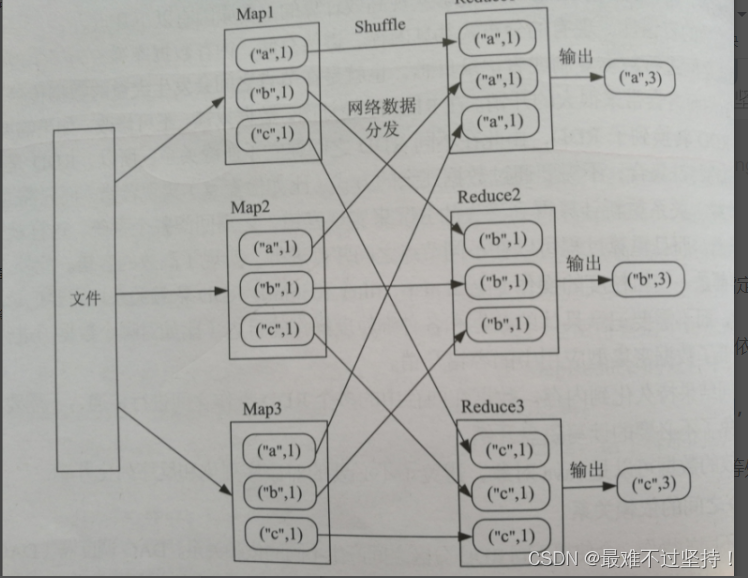
缺点:会产生大量网络传输开销,也会带来大量的磁盘I/O开销
- 33.DataFrame的常用操作有哪些?
DataFrame创建好以后,可以执行一些常用的DataFrame操作,包括printSchema()、select()、filter()、groupBy()、sort()等
- 37.Spark Streaming的基本原理是什么?
Spark Streaming的基本原理是将实时输入数据流以时间片(通常在0.5-2秒之间)为单位进行拆分,然后采用Spark引擎以类似批处理的方式处理每个时间片数据。
- 40.给定一组键值对(“spark”,2)、(“hadoop”,6)、(“hadoop”,4)、 (“spark”,6),键值对的key表示图书名称,value表示某天图书销量,现在需要计算每个键对应的平均值,也就是计算每种图书的每天平均销量。书上例题。
importorg.apache.spark.{SparkConf,SparkContext}
object tushu {
def main(args:Array[String]):Unit={
val conf =newSparkConf().setAppName("paixu").setMaster("local")
val sc =newSparkContext(conf)
val book =Array(("spark",2),("hadoop",6),("hadoop",4),("spark",6))
val rdd = sc.parallelize(book)
val result = rdd.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect().toList
println(result)}}//解释://1.var d = rdd.mapValues(x => (x,1) )//得到Array[(String, (Int, Int))] = Array((spark,(2,1)), (hadoop,(6,1)), (hadoop,(4,1)), (spark,(6,1)))//2.var dd = d.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))//得到Array[(String, (Int, Int))] = Array((spark,(8,2)), (hadoop,(10,2)))//3.var ddd = dd.mapValues(x => x._1/x._2).collect().toList//得到List((spark,4), (hadoop,5))
- 41.现利用反射机制推断RDD的模式完成查询年龄大于20岁的人的所有信息。书上例题。
- 42.统计词频以及每行单词个数。
//词频分析:varwords=sc.textFile("word.txt")varwords=words.flatMap(line=>line.split(" "))//拆分varwords=words.map(word=>(word,1))//映射成(word,1)varwords=words.reduceByKey((a,b)=>a+b)words.collect()//输出//数据筛选vararray=Array(1,2,3,4)varrdd=sc.parallelize(array)//将数组转化为rddrdd.filter(x=>x%2==0).collect()
版权归原作者 苦学java只为一口饭吃 所有, 如有侵权,请联系我们删除。