
第1关:Create/Alter/Drop 数据库
创建数据库的语法为:
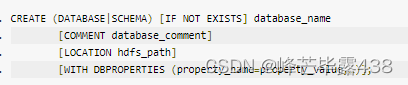
DATABASE|SCHEMA:用于限定创建数据库或数据库模式IF NOT EXISTS:目标对象不存在时才执行创建操作(可选)COMMENT:起注释说明作用LOCATION:指定数据库位于HDFS上的存储路径。若未指定,将使用${hive.metastore.warehouse.dir}定义值作为其上层路径位置WITH DBPROPERTIES:为数据库提供描述信息,如创建database的用户或时间
修改数据库的语法为:
ALTER (DATABASE|SCHEMA)database_name SET DBPROPERTIES (property_name=property_value,…);
- 只能修改数据库的键值对属性值。数据库名和数据库所在的目录位置不能修改
删除数据库语法:

DATABASE|SCHEMA:用于限定删除的数据库或数据库模式IF EXISTS:目标对象存在时才执行删除操作(可选)RESTRICT|CASCADE:RESTRICT为 Hive 默认操作方式,当database_name中不存在任何数据库对象时才能执行DROP操作;CASCADE采用强制DROP方式,汇联通存在于database_name中的任何数据库对象和database_name一起删除(可选)

代码块:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test1
LOCATION '/hive/test1'
WITH DBPROPERTIES('creator'='John','date'='2019-02-25');
ALTER DATABASE test1 SET DBPROPERTIES('creator'='Marry');
DROP DATABASE test1;
"
#创建数据库test1,位于HDFS的/hive/test1下,创建人creator为John,创建日期date为2019-02-25
#修改数据库test1的创建人为Marry
#删除数据库test1
#********* End *********#
第2关:Create/Drop/Truncate 表
创建表的语法为:
CREATE [TEMPOPARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name[(col_name data_type [COMMENT col_comment], ...)][COMMENT table_comment][PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)][CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][SKEWED BY (col_name,col_name,…) ON ([(col_value,col_value,…),…|col_value,col_value,…]) [STORED AS DIRECTORIES] ][[ROW FORMAT DELIMITED [FIFLDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char]| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value,…)]][STORED AS file_format]| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (…)]][LOCATION hdfs_path][TBLPROPERTIES (property_name=property_value,…)][AS select_statement];
- 参数说明如下:
TEMPOPARY:创建临时表,若未指定,则默认创建的是普通表EXTERNAL:创建外部表,若未指定,则默认创建的是内部表IF NOT EXISTS:若表不存在才创建,若未指定,当目标表存在时,创建操作抛出异常db_name.:前缀,指定表所属于的数据库。若未指定且当前数据库非db_name,则使用default数据库COMMENT:添加注释说明,注释内容位于单引号内PARTITIONED BY:针对存储有大量数据集的表,根据表内容所具有的某些共同特征定义一个标签,将这类数据存储在该标签所标识的位置,可以提高表内容的查询速度。PARTITIONED BY中的列名为伪列或标记列,不能与表中的实体列名相同,否则 hive 表创建操作报错CLUSTERED BY:根据列之间的相关性指定列聚类在相同桶中(BUCKETS),可以对表内容按某一列进行升序(ASC)或降序(DESC)排序(SORTED BY关键字)SKEWED BY:用于过滤掉特定列col_name中包含值col_value(ON(col_value,…)关键字指定的值)的记录,并单独存储在指定目录(STORED AS DIRECTORIES)下的单独文件中ROW FORMAT:指定 hive 表行对象(ROW Object)数据与 HDFS 数据之间进行传输的转换方式(HDFS files -> Deserializer ->Row object以及Row object ->Serializer ->HDFS files),以及数据文件内容与表行记录各列的对应。在创建表时可以指定数据列分隔符(FIFLDS TERMINATED BY 子句)、对特殊字符进行转义的特殊字符(ESCAPED BY 子句)、符合数据类型值分隔符(COLLECTION ITEMS TERMINATED BY 子句)、MAP key-value类型分隔符(MAP KEYS TERMINATED BY)、数据记录行分隔符(LINES TERMINATED BY)、定义NULL字符(NULL DEFINED AS),同时可以指定自定义的SerDE(Serializer和Deserializer,序列化和反序列化),也可以指定默认的SerDE。如果ROW FORMAT未指定或指定为ROW FORMAT DELIMITED,将使用内部默认SerDeSTORED AS:指定 hive 表数据在 HDFS 上的存储方式。file_format值包括TEXTFILE(普通文本文件,默认方式)、SEQUENCEFILE(压缩模式)、ORC(ORC文件格式)和AVRO(AVRO文件格式)STORED BY:创建一个非本地表,如创建一个 HBase 表LOCATION:指定表数据在 HDFS 上的存储位置。若未指定,db_name数据库将会储存在${hive.metastore.warehouse.dir}定义位置的db_name目录下TBLPROPERTIES:为所创建的表设置属性(如创建时间和创建者,默认为当前用户和当前系统时间)AS select_statement:使用select子句创建一个复制表(包括select子句返回的表模式和表数据)
- 复制表:按照已存在的表或视图定义一个相同结构的表或视图(使用
LIKE关键字,只复制表定义,不复制表数据)。
复制刚才创建的表
items_info
起名为
items_info2
。
CREATE TABLE IF NOT EXISTS items_info2
LIKE items_info;
删除表的语法为:
DROP TABLE [IF EXISTS] table_name;
[IF EXISTS]
:关键字可选;
若未指定且表
table_name
不存在时,
Hive
返回错误。

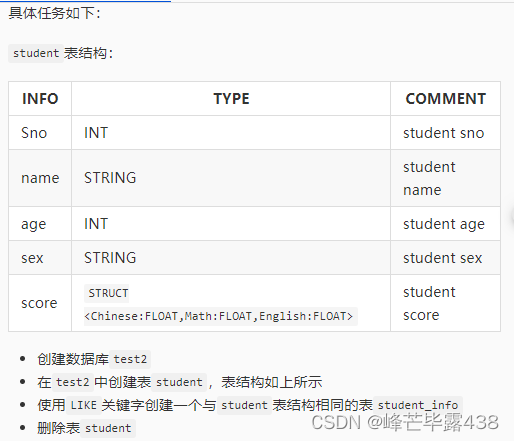
代码块:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test2;
CREATE TABLE IF NOT EXISTS test2.student(
Sno INT COMMENT 'student sno',
name STRING COMMENT 'student name',
age INT COMMENT 'student age',
sex STRING COMMENT 'student sex',
score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score');
CREATE TABLE IF NOT EXISTS student_info LIKE student;
DROP TABLE student;
"
#********* End *********#
** 第3关:Alter 表/列**
重命名表的语法为:
ALTER TABLE table_name RENAME TO new_table_name;
修改表列的语法为:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUM] col_old_name col_new_name colum_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
- 以上操作可以修改表的列名、列数据类型、列存储位置以及注释说明
FIRST、AFTER用于指定是否交换列的前后顺序- 该操作只改变表的
metadata(RESTRICT方式,即默认方式) CASCADE关键字用于限定修改操作同时同步到表metadata和分区metadata
增加表列和删除表列或替换表列的语法为:
ALTER TABLE table_name [PARTITION partition_spec] ADD|REPLACE COLUMNS (col_namedata_type [COMMENT col_comment],…) [CASCADE|RESTRICT]
ADD COLUMNS:用于在表中已存在实体列(existing columns)之后且分区列(partition columns,或伪列)之前添加新的列REPLACE COLUMNS:删除表中现有的全部列,添加新的列集合。该操作仅支持使用内部的SerDe(DynamicSerDe、MetadataTypedColumnsetSerDe/LazySimpleSerDe和ColumnarSerDe)的表(SerDe用于实现表数据与 HDFS 数据之间的转换方式)
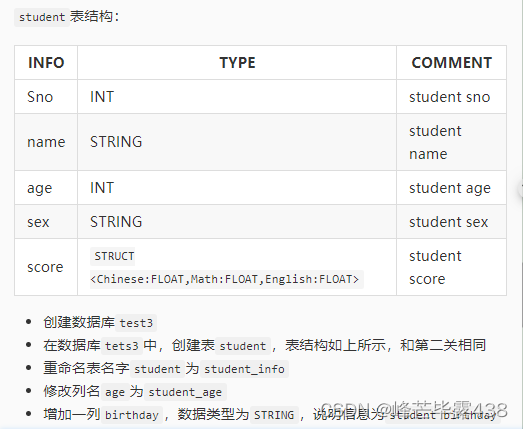
代码块:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test3;
CREATE TABLE IF NOT EXISTS test3.student(
Sno INT COMMENT 'student sno',
name STRING COMMENT 'student name',
age INT COMMENT 'student age',
sex STRING COMMENT 'student sex',
score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score');
ALTER TABLE student RENAME TO student_info;
ALTER TABLE student_info CHANGE age student_age INT COMMENT 'student age';
ALTER TABLE student_info ADD COLUMNS (birthday STRING COMMENT 'student birthday');
"
#********* End *********#
第4关:表分区
创建分区表
使用
shopping
数据库创建一张商品信息分区表
items_info2
,按商品品牌
p_brand
和商品分类
p_category
进行分区:
CREATE TABLE IF NOT EXISTS shopping.items_info2(name STRING COMMENT 'item name',price FLOAT COMMENT 'item price',category STRING COMMENT 'item category',brand STRING COMMENT 'item brand',type STRING COMMENT 'item type',stock INT COMMENT 'item stock',address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> COMMENT 'item sales address')COMMENT 'goods information table'PARTITIONED BY (p_category STRING,p_brand STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t'COLLECTION ITEMS TERMINATED BY ','TBLPROPERTIES ('creator'='Xiaoming','date'='2019-01-01');
添加分区
向表
items_info2
添加两个分区:
ALTER TABLE items_info2 ADD PARTITION (p_category='clothes',p_brand='playboy') LOCATION '/hive/shopping/items_info2/playboy/clothes'
PARTITION (p_category='shoes',p_brand='playboy') LOCATION '/hive/shopping/items_info2/playboy/shoes';

交换表分区的语法为:
ALTER TABLE table_name_1 EXCHANGE PARTITION (partition_spec) WITH TABLE table_name_2;
该操作移动表
table_name_1
中特定分区下的数据到具有相同表模式且不存储在相应分区的
table_name_2
中。
表分区信息持久化的语法为:
MSCK REPAIR TABLE table_name;
该操作作用于同步表
table_name
在
HDFS
上的分区信息到
Hive
位于
RDBMS
的
metastore
中。
删除表分区的语法为:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,PARTITION partition_spec,…;
该操作会删除与特定分区相关的数据以及
metadata
。
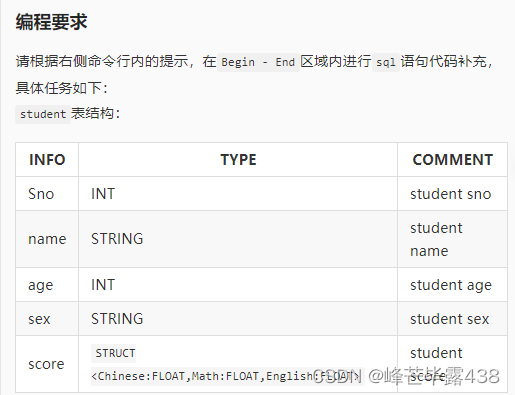

代码块:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test4;
CREATE TABLE IF NOT EXISTS test4.student(
Sno INT COMMENT 'student sno',
name STRING COMMENT 'student name',
age INT COMMENT 'student age',
sex STRING COMMENT 'student sex',
score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score')
PARTITIONED BY (stu_year STRING,subject STRING);
ALTER TABLE student ADD PARTITION (subject='Chinese',stu_year='2018')
LOCATION '/hive/test4/student/2018/Chinese'
PARTITION (subject='Math',stu_year='2018')
LOCATION '/hive/test4/student/2018/Math';
ALTER TABLE student PARTITION (subject='Math',stu_year='2018')
RENAME TO PARTITION (subject='English',stu_year='2018');
ALTER TABLE student DROP IF EXISTS PARTITION (subject='Chinese',stu_year='2018');
"
#********* End *********#
本文转载自: https://blog.csdn.net/qq_71139242/article/details/127534855
版权归原作者 峰芒毕露438 所有, 如有侵权,请联系我们删除。
版权归原作者 峰芒毕露438 所有, 如有侵权,请联系我们删除。