
介绍
Kafka 是一个开源的分布式消息引擎/消息中间件,同时Kafka也是一个流处理平台。Kakfa 支持以发布/订阅的方式在应用间传递消息,同时并基于消息功能添加了 Kafka Connect、Kafka Streams 以支持连接其他系统的数据源,如 ES、Hadoop 等。Kafka 最核心的最成熟的还是他的消息引擎,所以 Kafka 大部分应用场景还是用来作为消息队列削峰平谷。另外,Kafka 也是目前性能最好的消息中间件。
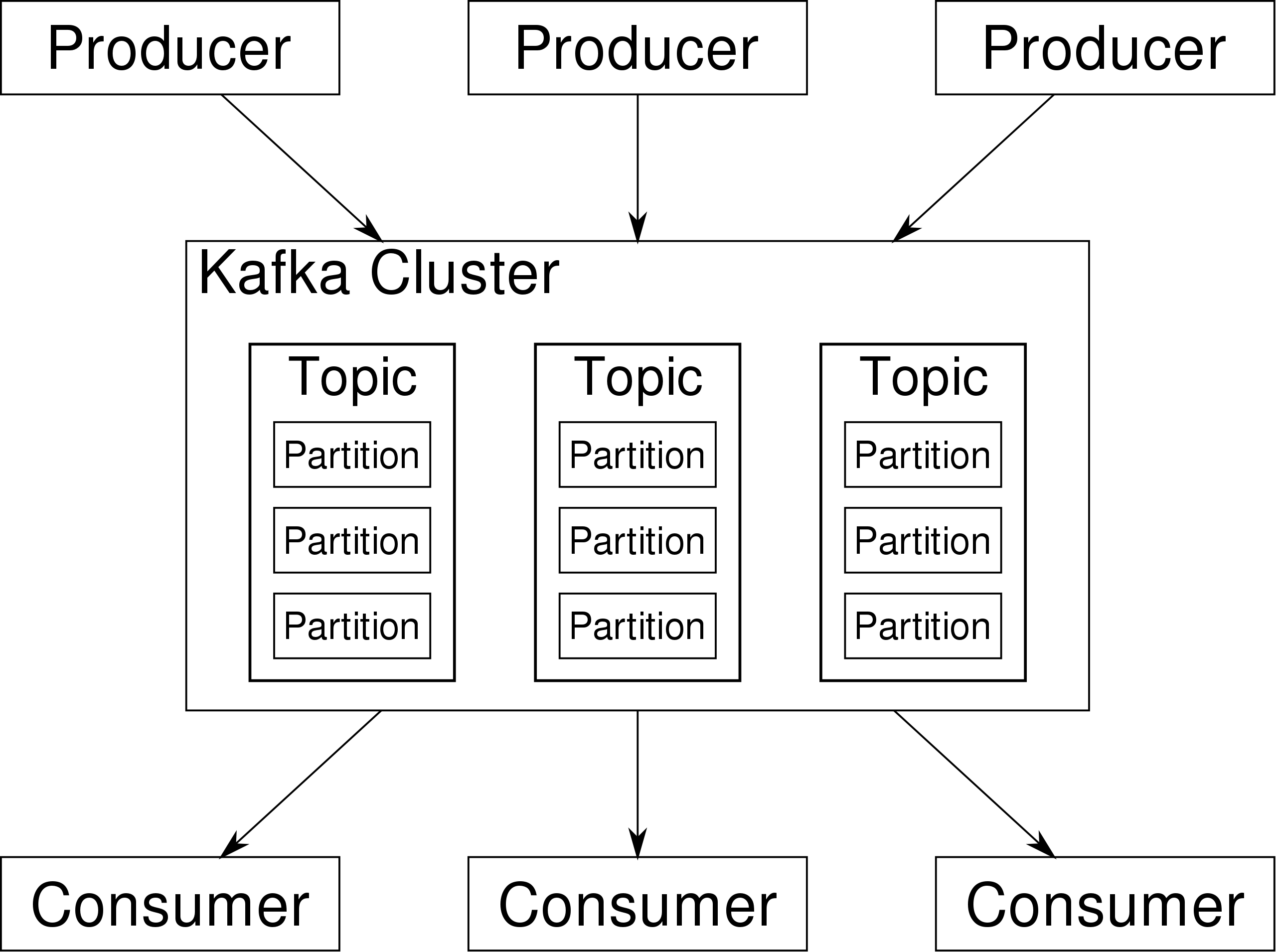
在 Kafka 架构中,有几个术语:
- Producer:生产者,即消息发送者,push 消息到 Kafka 集群中的 broker(就是 server)中;
- Broker:Kafka 集群由多个 Kafka 实例(server) 组成,每个实例构成一个 broker,说白了就是服务器;
- Topic:producer 向 kafka 集群 push 的消息会被归于某一类别,即Topic,这本质上只是一个逻辑概念,面向的对象是 producer 和 consumer,producer 只需要关注将消息 push 到哪一个 Topic 中,而 consumer 只需要关心自己订阅了哪个 Topic;
- Partition:每一个 Topic 又被分为多个 Partitions,即物理分区;出于负载均衡的考虑,同一个 Topic 的 Partitions 分别存储于 Kafka 集群的多个 broker 上;而为了提高可靠性,这些 Partitions 可以由 Kafka 机制中的 replicas 来设置备份的数量;如上面的框架图所示,每个 partition 都存在两个备份;
- Consumer:消费者,从 Kafka 集群的 broker 中 pull 消息、消费消息;
- Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer-group,每条消息只能被 consumer-group 中的一个 Consumer 消费,但可以被多个 consumer-group 消费;
- replicas:partition 的副本,保障 partition 的高可用;
- leader:replicas 中的一个角色, producer 和 consumer 只跟 leader 交互;
- follower:replicas 中的一个角色,从 leader 中复制数据,作为副本,一旦 leader 挂掉,会从它的 followers 中选举出一个新的 leader 继续提供服务;
- controller:Kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover;
- ZooKeeper:Kafka 通过 ZooKeeper 来存储集群的 meta 信息等。
安装
zookeeper
# 安装已编译的 zookeeperwget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz --no-check-certificate
tar -zxf apache-zookeeper-3.7.1-bin.tar.gz
mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper-3.7.1
kafka
# 安装已编译的 kafkawget https://downloads.apache.org/kafka/3.3.1/kafka_2.13-3.3.1.tgz --no-check-certificate
tar -zxf kafka_2.13-3.3.1.tgz
mv kafka_2.13-3.3.1 /usr/local/kafka-2.13-3.3.1
配置启动
zookeeper
cd /usr/local/zookeeper-3.7.1
cp conf/zoo_sample.cfg conf/zoo.cfg
mkdir -p /data/zookeeper
vim conf/zoo.cfg
# 指定 Zookeeper 的数据存储目录,类比于 MySQL 的 dataDirdataDir=/data/zookeeper
# 启动
./bin/zkServer.sh start
kafka
cd /usr/local/kafka-2.13-3.3.1
mkdir -p /usr/local/kafka-2.13-3.3.1/kafka-logs
vim config/server.properties
# 指定监听的地址及端口号,该配置项是指定内网iplisteners=PLAINTEXT://:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://10.124.5.222:9092
# 指定kafka日志文件的存储目录
log.dirs=/usr/local/kafka-2.13-3.3.1/kafka-logs
# 指定zookeeper的连接地址,多个地址用逗号分隔
zookeeper.connect=localhost:2181
# 先不要后台启动,检查是否配置有错
./bin/kafka-server-start.sh ./config/server.properties
./bin/kafka-server-start.sh -daemon config/server.properties
使用
这里用 python 编写了两个脚本,用于测试部署的 kafka 是否正常运行:
Producer
import json
from datetime import datetime
importtime
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='10.124.5.222:9092',
value_serializer=lambda msg: json.dumps(msg).encode(),
api_version=(2, 13))
topic ='test'foriin range(0, 100):
data ={'num': i,
'time': datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
print(data)
producer.send(topic, data)
time.sleep(1)
Consumer
importtime
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',
bootstrap_servers=['10.124.5.222:9092'],
api_version=(2, 13),
group_id='test',
auto_offset_reset='earliest')formsgin consumer:
print(msg.value)
常用命令
这边提供了三个常用的命令,在命令行中操作 topic:
# 创建 topic
bin/kafka-topics.sh --create --bootstrap-server 10.124.5.222:9092 --replication-factor 3 --partitions 1 --topic test-for-cluster
# 查看 topic 信息# 集群的话,只用写一个节点即可查询该 topic 所有信息
bin/kafka-topics.sh --describe --bootstrap-server 10.124.5.222:9092 --topic test-for-cluster
# 删除 topic
bin/kafka-topics.sh --delete --bootstrap-server 10.124.5.222:9092 --topic test-for-cluster
本文转载自: https://blog.csdn.net/qq_43619899/article/details/127548130
版权归原作者 ColorlessCube 所有, 如有侵权,请联系我们删除。
版权归原作者 ColorlessCube 所有, 如有侵权,请联系我们删除。