
文章末尾附有flinkcdc对应瀚高数据库flink-cdc-connector代码下载地址
1、业务需求
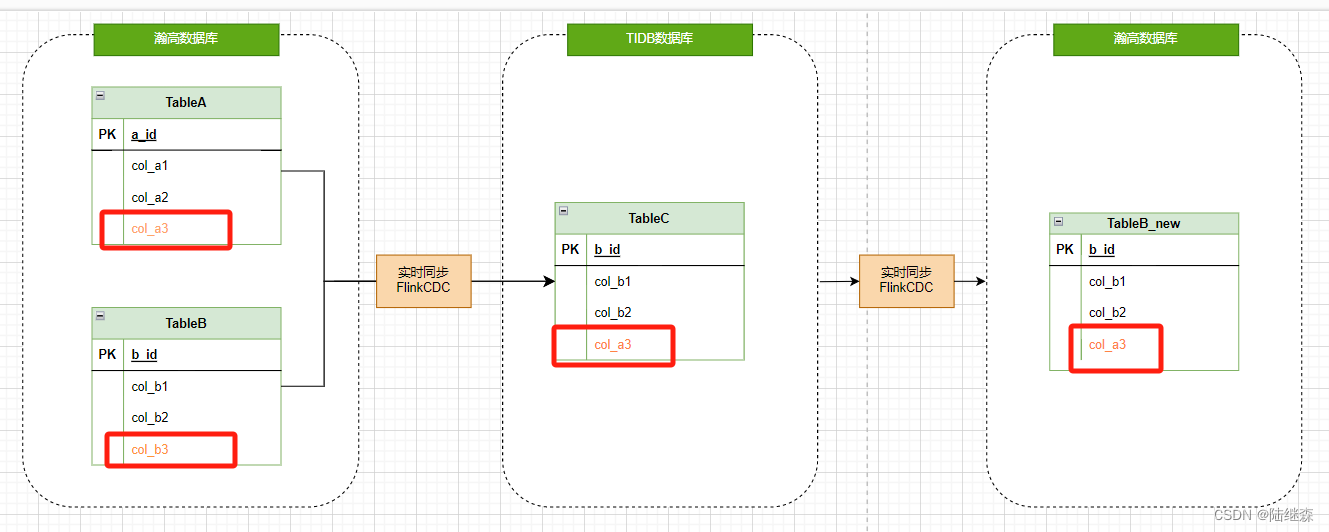
目前项目有主数据系统和N个业务系统,为保障“一数一源”,各业务系统表涉及到主数据系统的字段都需用主数据系统表中的字段进行实时覆盖,这里以某个业务系统的一张表举例说明:业务系统表TableB字段col_b3与主数据系统表TableA中col_a3不一致,需要用col_a3实时覆盖col_b3生成目标表TableB_new中间表,业务系统存储为国产瀚高数据库,中间库用TIDB。
2、需求分析
业务系统已上线多年,存在历史数据和新数据,需要分两个阶段进行处理。
第一阶段,历史数据通过TableA、TableB联合关联生成中间表TableC,其中TableC中的主数据字段已用主数据进行了更新,再将TableC实时同步到瀚高数据库中生成一个新的业务表TableB_new(TableC和TableB_new表结构一致);
第二阶段,历史数据处理结束后,业务系统直接割接到新表TableB_new,后期新的业务数据用TableB_new与主数据表TableA关联,实时生成中间表TableC,再用FlinkCDC,实时同步TableC数据覆盖TableB_new主数据字段。
3、具体实现
第一阶段流程图,历史数据处理,由TableA和TableB实时关联生成中间表TableC,再实时同步TableC到新的业务表TableB_new,完成历史数据主数据字段的覆盖:
第二阶段流程图,业务割接到新表TableB_new实时同步,直接由TableA和TableB_new关联生成TableC,再用cdc任务实时同步到新业务 表TableB_new中,即可完成主数据的覆盖:

4、FlinkSQL脚本
4.1、第一阶段脚本
4.1.1、TableA实时关联TableB生成中间表TableC
//指定任务名称
set pipeline.name=task_TablA_Table_B_TableC;
//主数据源表TableA
DROP TABLE IF EXISTS TableA;
CREATE TABLE TableA(
col_a1 varchar(255),
col_a2 varchar(255),
col_a3 varchar(255)
) WITH (
'connector' = 'highgo-cdc',
'hostname' = '10.*.*.*',
'port' = '5866',
'username' = 'cdcuser',
'password' = '123456a?',
'database-name' = 'databaseA',
'schema-name' = 'public',
'table-name' = 'TableA',
'slot.name' = 'TableA',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'false'
);
//业务数据源表TableB
DROP TABLE IF EXISTS tableB;
CREATE TABLE tableB(
col_b1 varchar(255),
col_b2 varchar(255),
col_b3 varchar(255)
) WITH (
'connector' = 'highgo-cdc',
'hostname' = '10.*.*.*',
'port' = '5866',
'username' = 'cdcuser',
'password' = '123456a?',
'database-name' = 'databaseB',
'schema-name' = 'public',
'table-name' = 'TableB',
'slot.name' = 'TableB',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'false'
);
//中间表TableC
DROP TABLE IF EXISTS TableC;
CREATE TABLE TableC(
col_c1 varchar(255),
col_c2 varchar(255),
col_c3 varchar(255)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.8.8.8:4000/databaseC',
'username' = 'root',
'password' = '*****',
'table-name' = 'TableC',
'driver' = 'com.mysql.jdbc.Driver'
);
insert into tableC
select
b.col_b1 as col_c1,
b.col_b2 as col_c2,
CASE
WHEN a.col_a3 IS NOT NULL THEN a.col_a3
ELSE b.col_b3
END as col_c3
from TableB t1 left join TableA t2 on b.fk=a.id;
4.1.2、TableC实时同步到TableB_new
//指定任务名称
set pipeline.name=task_TableC_TableB_new;
//中间表TableC TIDB
DROP TABLE IF EXISTS TableC;
CREATE TABLE TableC(
col_c1 varchar(255),
col_c2 varchar(255),
col_c3 varchar(255)
) WITH (
'connector' = 'tidb-cdc',
'tikv.grpc.timeout_in_ms' = '20000',
'pd-addresses' = '10.*.*.*:4000',
'database-name' = 'databaseC',
'table-name' = 'TableC'
);
//业务结果表 写入瀚高数据库
DROP TABLE IF EXISTS TableB_new;
CREATE TABLE TableB_new(
col_b1 varchar(255),
col_b2 varchar(255),
col_b3 varchar(255)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:highgo://10.*.*.*:5866/databaseB?currentSchema=public',
'username' = 'sysdba',
'password' = '****',
'table-name' = 'TableB_new',
'driver' = 'com.highgo.jdbc.Driver'
);
insert into TableB_new
select
col_c1 as col_b1,
col_c2 as col_b2,
col_c3 as col_b3,
from TableC;
4.2、第二阶段脚本
4.2.1、TableA实时关联TableB_new生成中间表TableC
//指定任务名称
set pipeline.name=task_TablA_Table_B_TableC;
//主数据源表TableA
DROP TABLE IF EXISTS TableA;
CREATE TABLE TableA(
col_a1 varchar(255),
col_a2 varchar(255),
col_a3 varchar(255)
) WITH (
'connector' = 'highgo-cdc',
'hostname' = '10.*.*.*',
'port' = '5866',
'username' = 'cdcuser',
'password' = '123456a?',
'database-name' = 'databaseA',
'schema-name' = 'public',
'table-name' = 'TableA',
'slot.name' = 'TableA',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'false'
);
//业务数据源表 也是目标表TableB_new
DROP TABLE IF EXISTS TableB_new;
CREATE TABLE tableB(
col_b1 varchar(255),
col_b2 varchar(255),
col_b3 varchar(255)
) WITH (
'connector' = 'highgo-cdc',
'hostname' = '10.*.*.*',
'port' = '5866',
'username' = 'cdcuser',
'password' = '123456a?',
'database-name' = 'databaseB',
'schema-name' = 'public',
'table-name' = 'TableB_new',
'slot.name' = 'TableB_new',
'decoding.plugin.name' = 'pgoutput',
'scan.incremental.snapshot.enabled' = 'false'
);
//中间表TableC
DROP TABLE IF EXISTS TableC;
CREATE TABLE TableC(
col_c1 varchar(255),
col_c2 varchar(255),
col_c3 varchar(255)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.8.8.8:4000/databaseC',
'username' = 'root',
'password' = '*****',
'table-name' = 'TableC',
'driver' = 'com.mysql.jdbc.Driver'
);
insert into tableC
select
b.col_b1 as col_c1,
b.col_b2 as col_c2,
CASE
WHEN a.col_a3 IS NOT NULL THEN a.col_a3
ELSE b.col_b3
END as col_c3
from TableB_new t1 left join TableA t2 on b.fk=a.id;
4.2.2、TableC实时同步到TableB_new
与4.1.2脚本一致,略
备:flink-cdc-connector代码:支持瀚高数据库Highgo下载地址:
https://github.com/lujisen/flink-cdc-connectors.githttp://xn--flink-cdc-connector-jz52b18z5q4dqpxn
本文转载自: https://blog.csdn.net/lujisen/article/details/134553890
版权归原作者 陆继森 所有, 如有侵权,请联系我们删除。
版权归原作者 陆继森 所有, 如有侵权,请联系我们删除。