
HDFS
1.选择自定义。
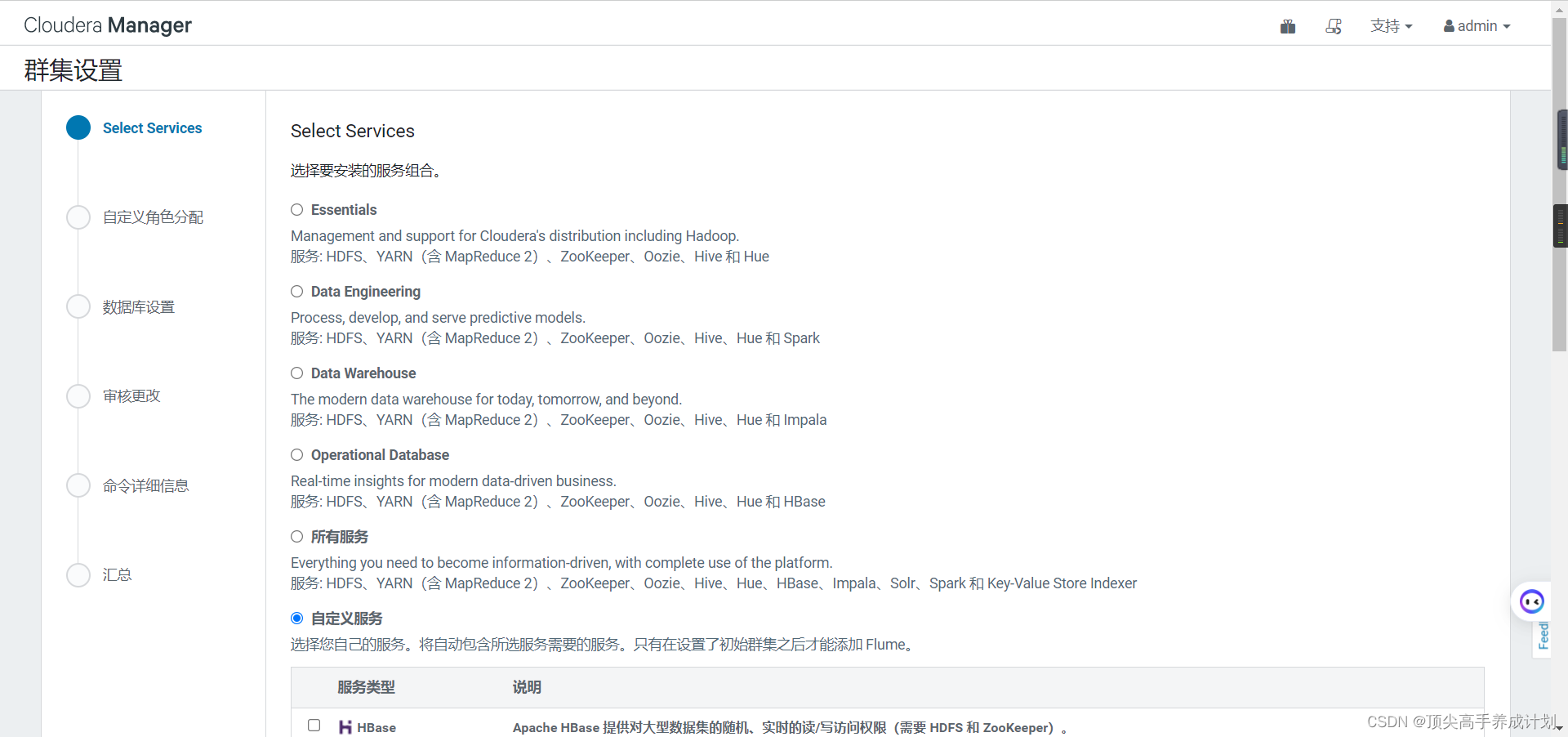
2.选择HDFS ZK YARN然后点继续。

3.选择安装的主机。
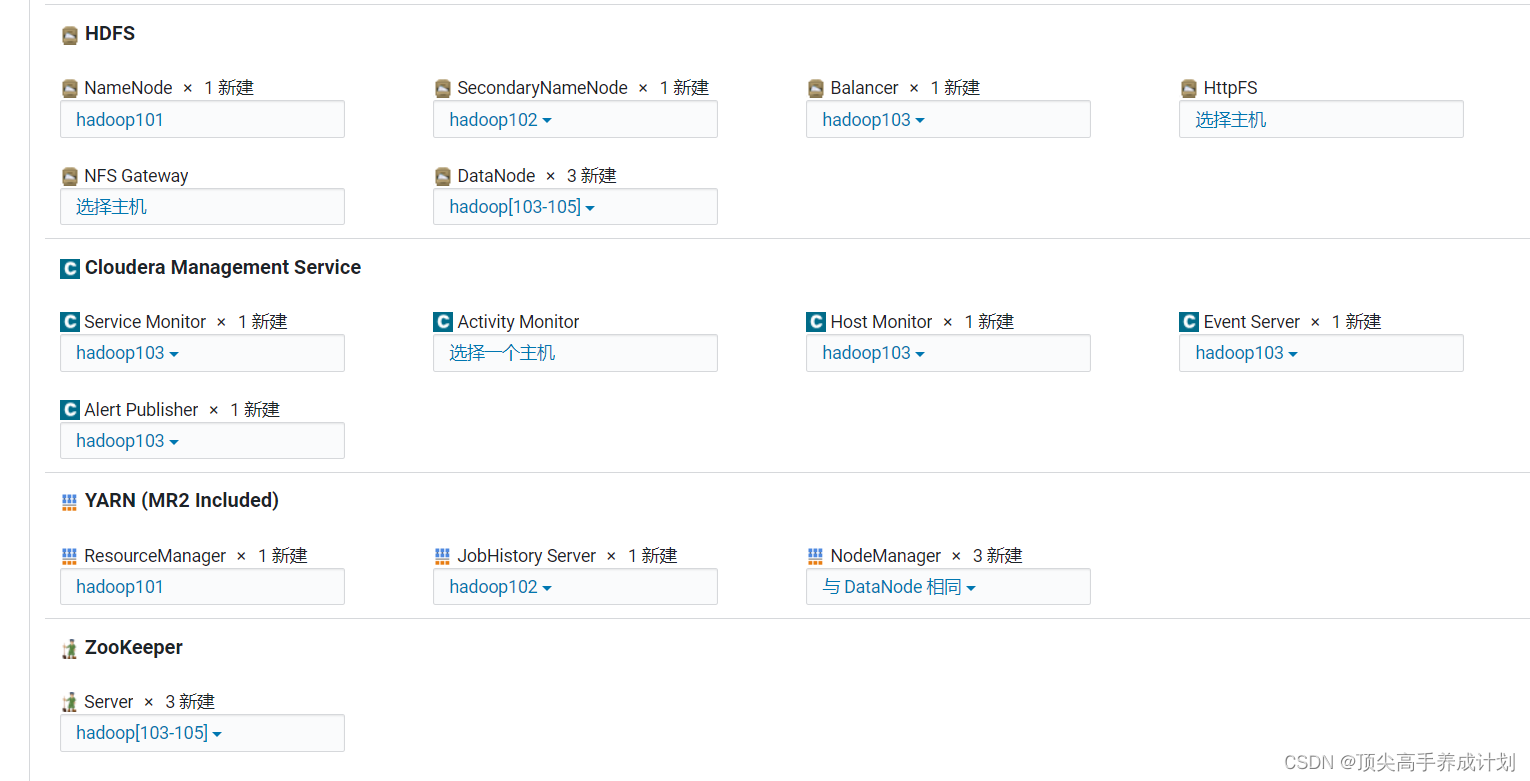 4.审核更改默认就行,点继续。
4.审核更改默认就行,点继续。
5.配置HDFS的HA。
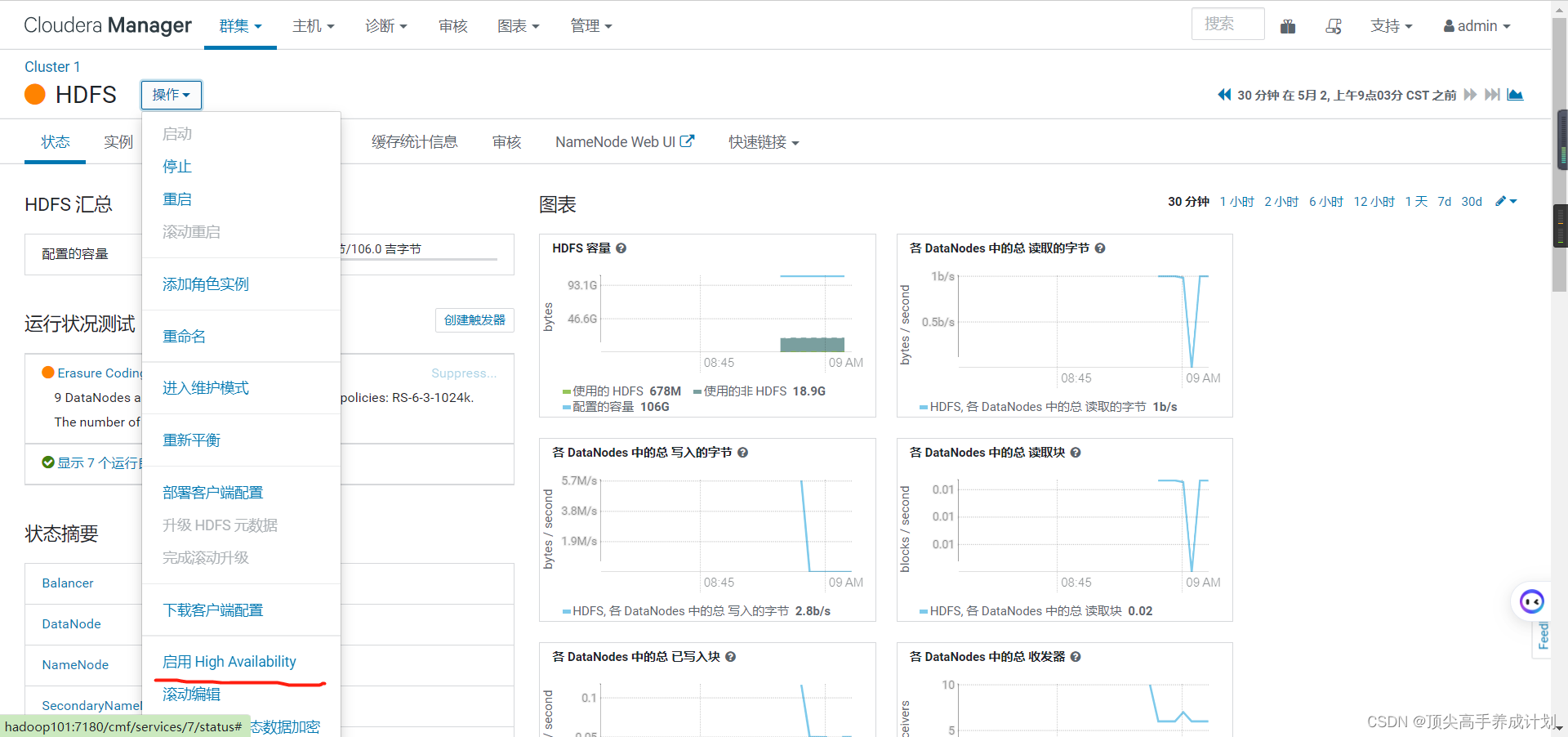

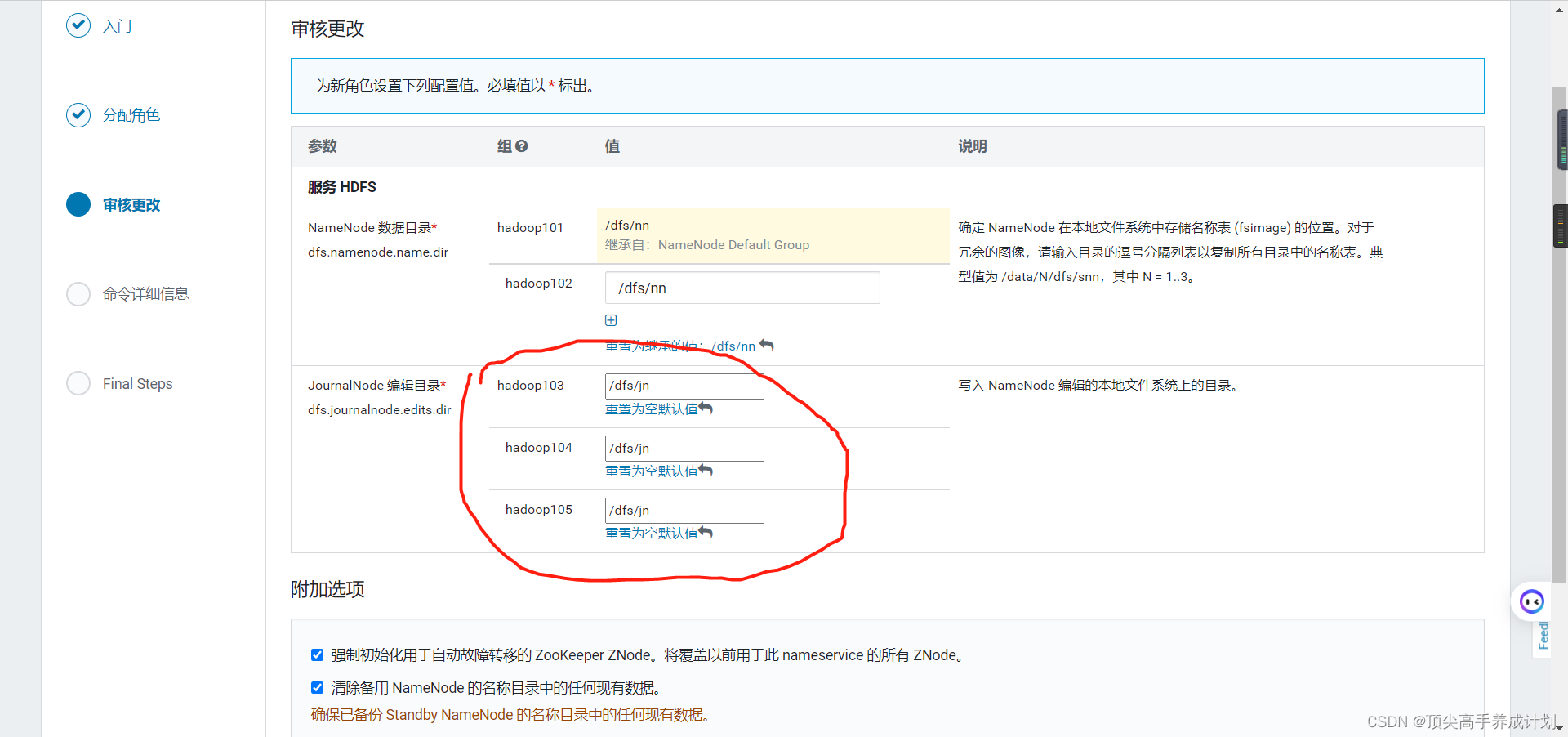 安装好以后点击hdfs进入实例就能够看到启动了高可用。
安装好以后点击hdfs进入实例就能够看到启动了高可用。
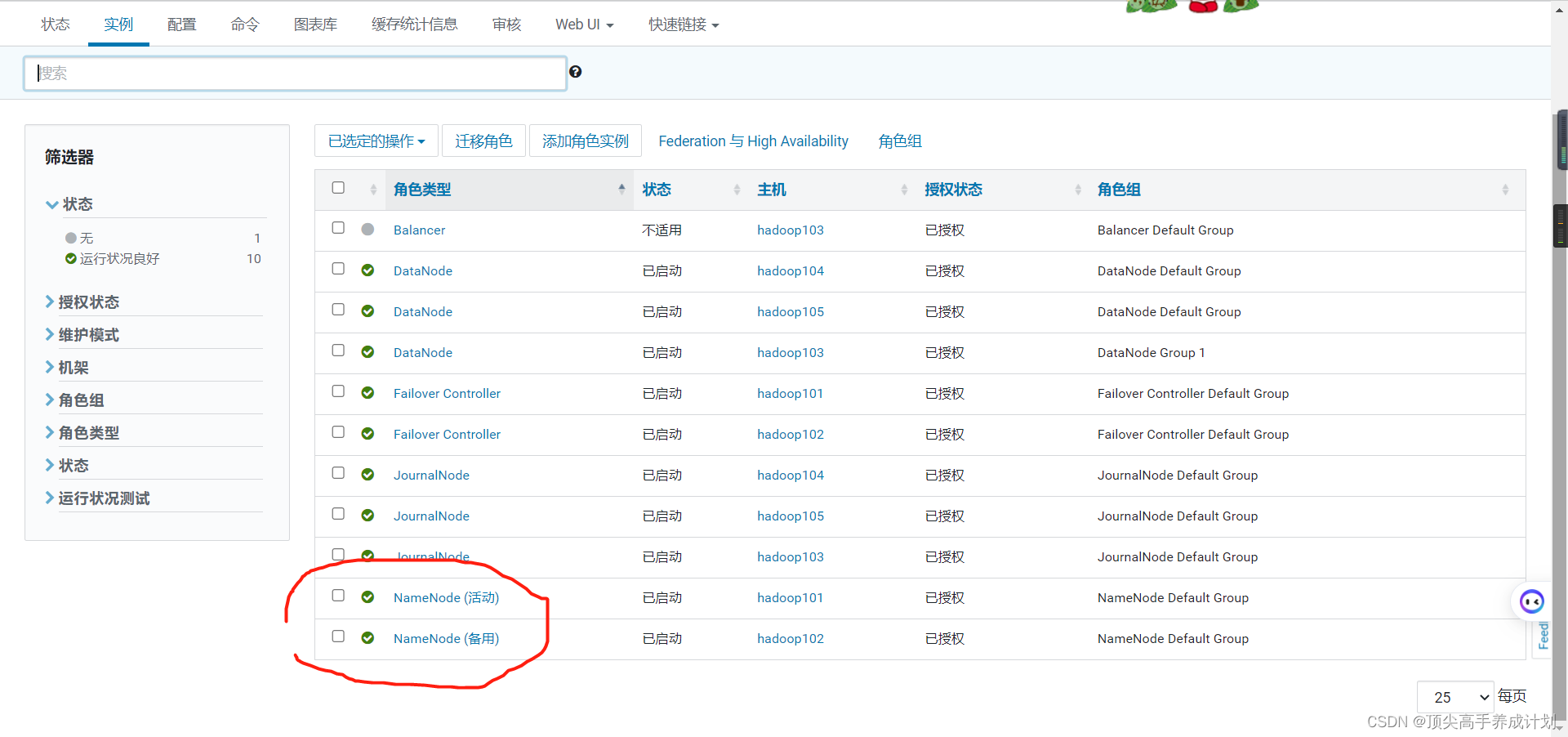
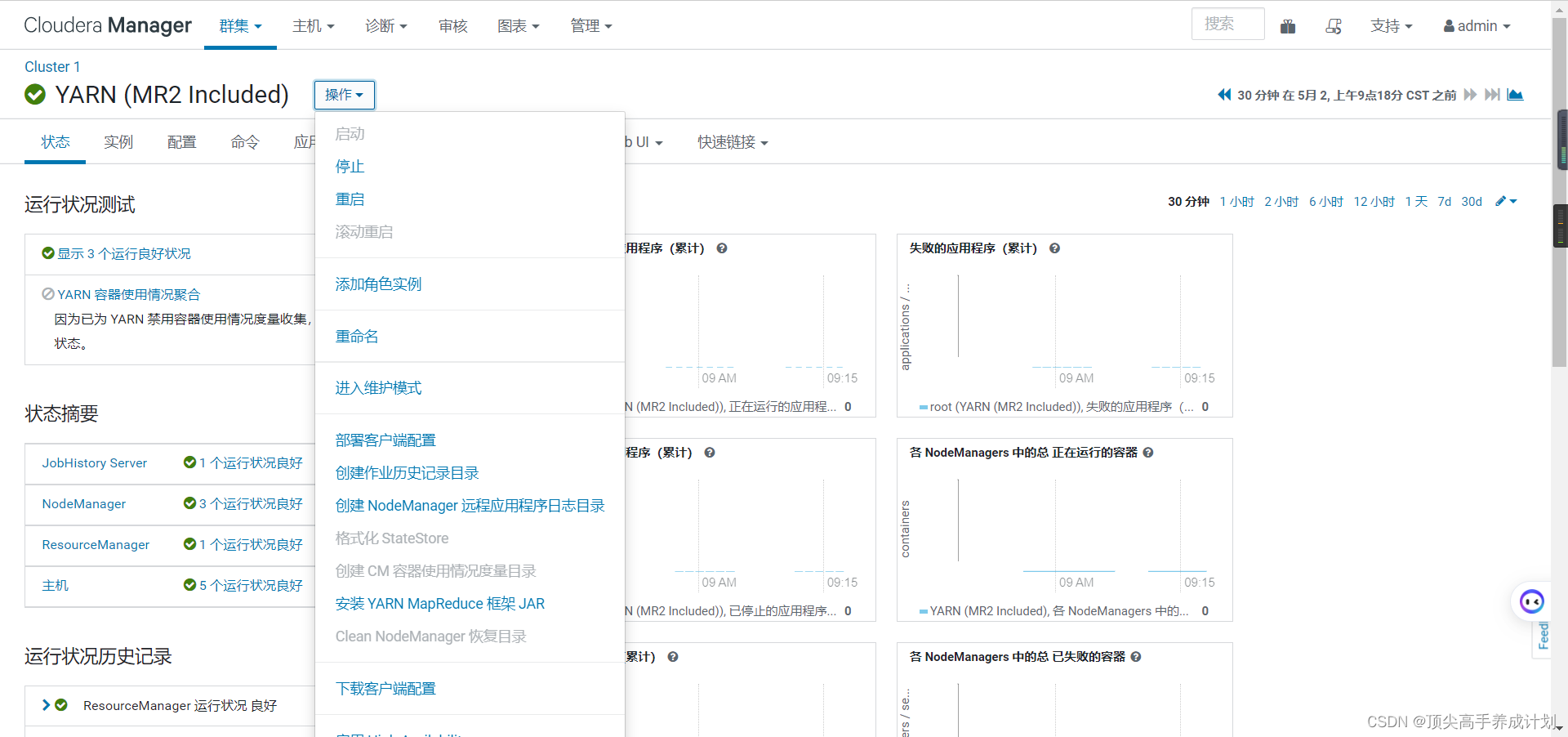
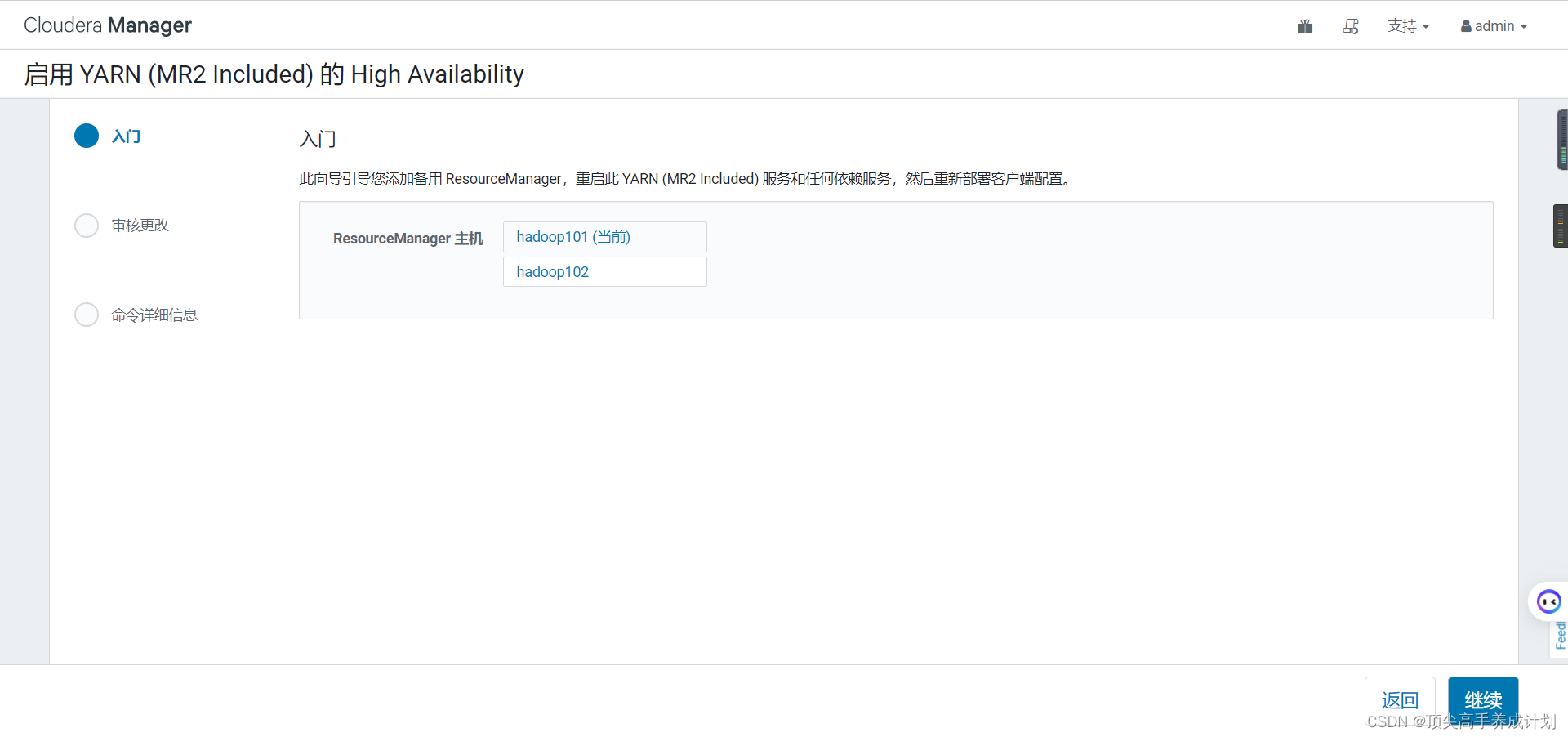
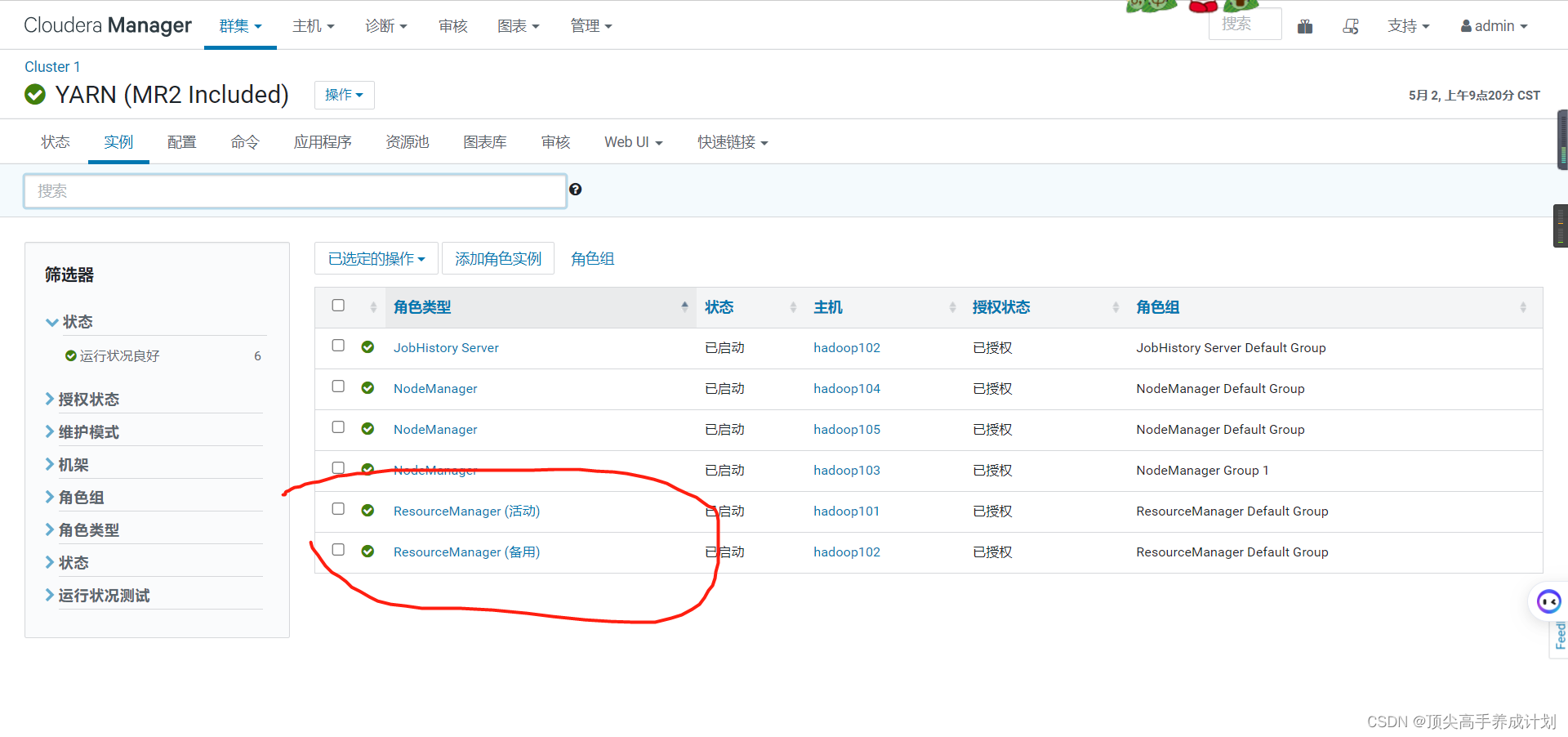
6.启动YARN的高可用。
KAFKA


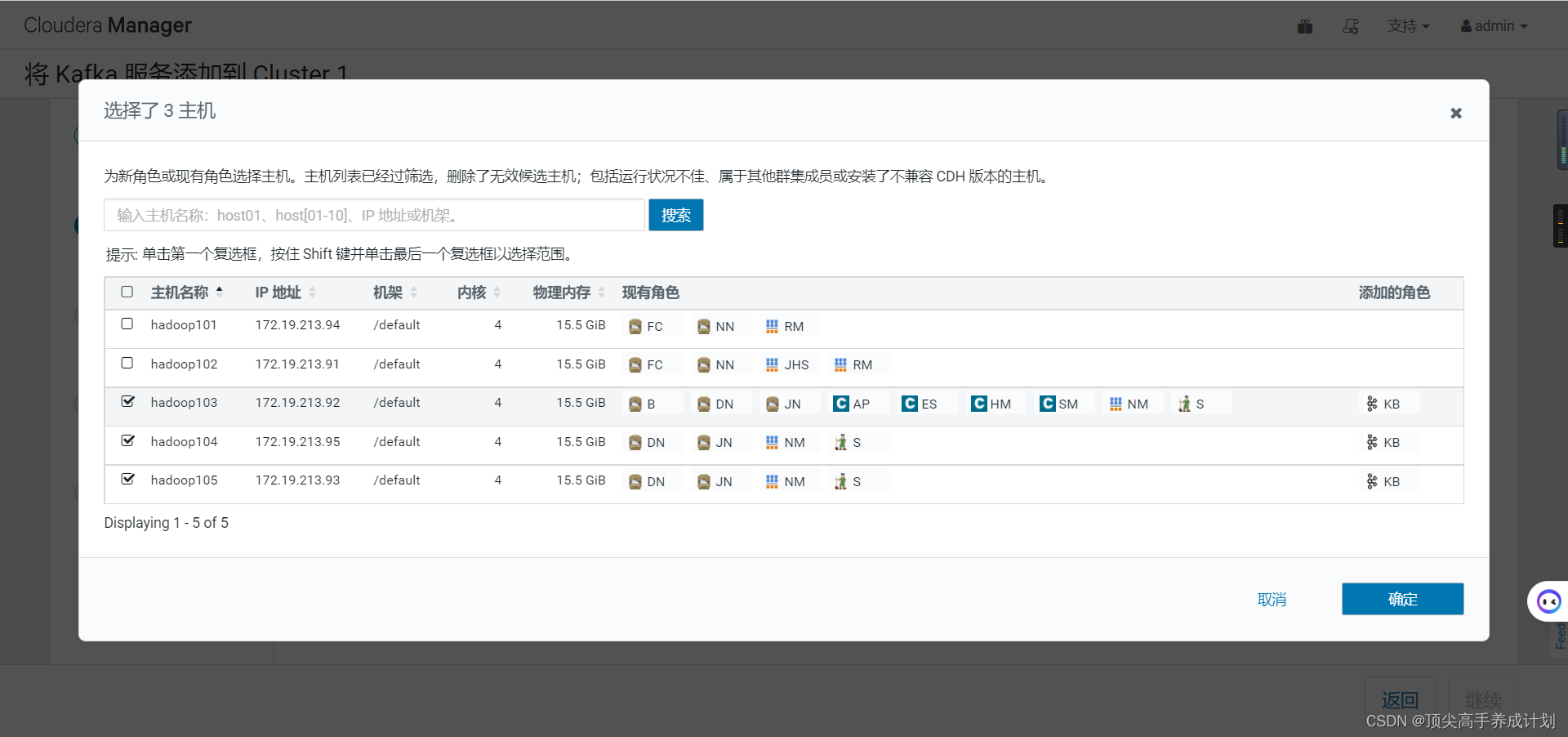
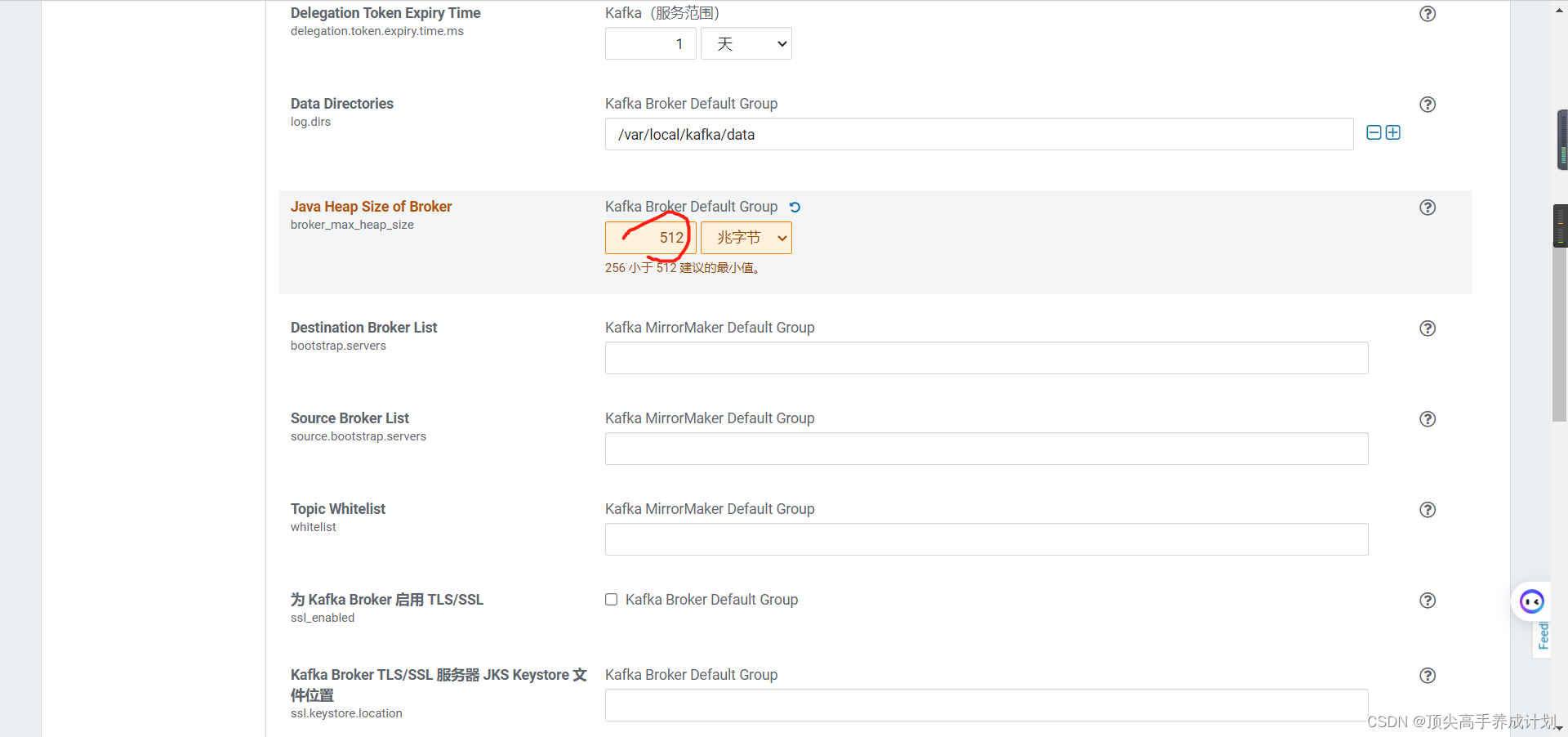
更具需求修改资源
一直点继续就行了

FlUME



HIVE
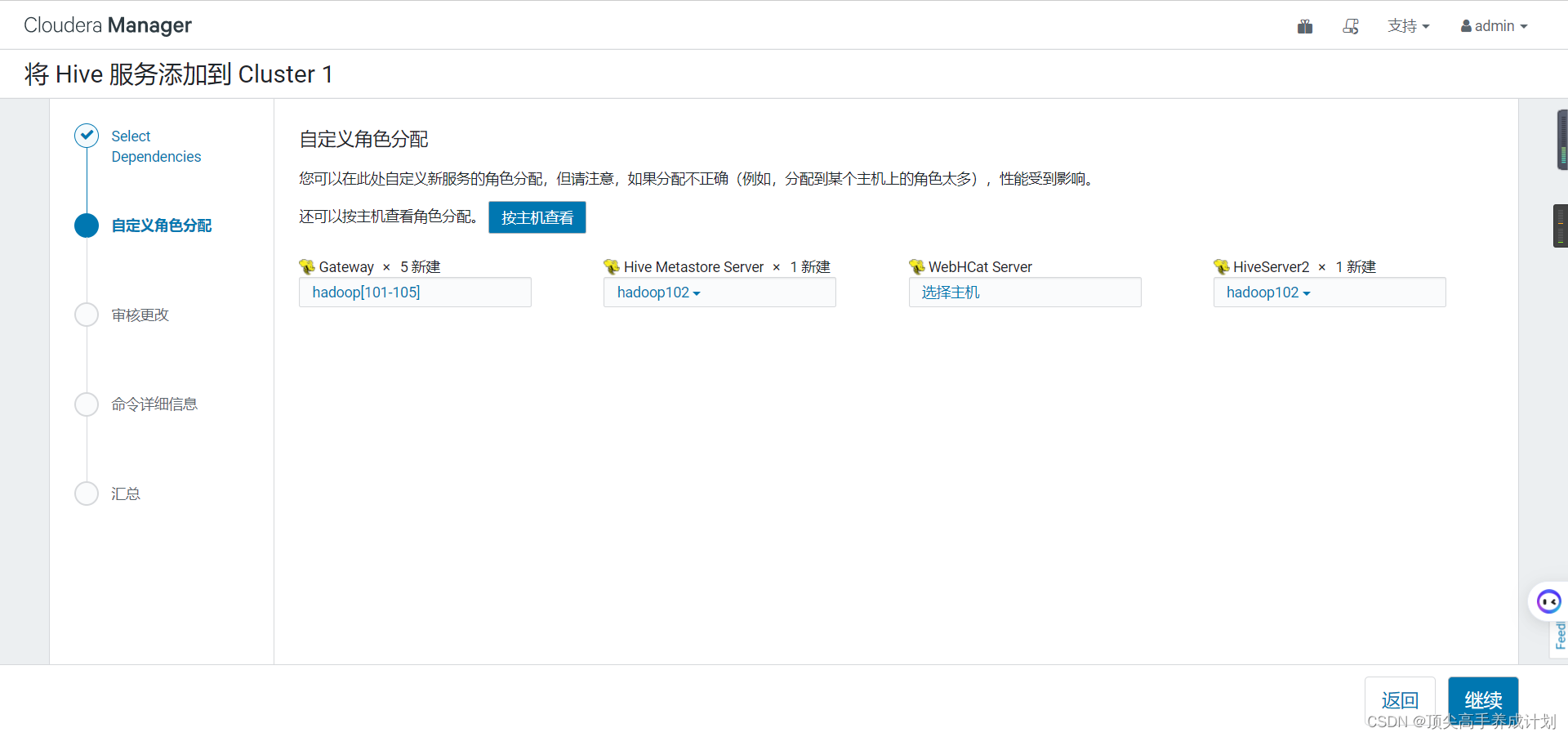

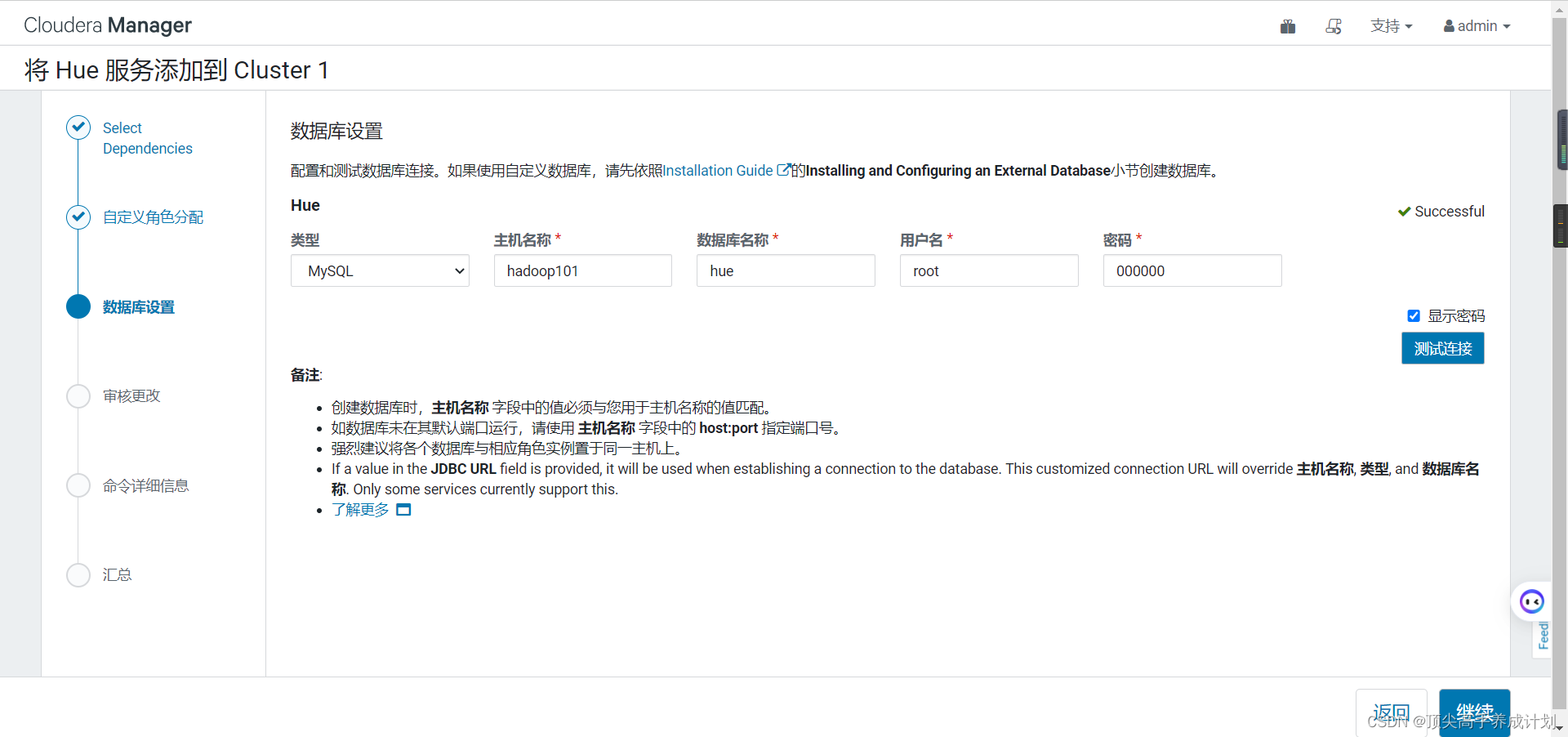
在/usr/share/java下面有mysql的驱动才行,不然就连接失败,最好所有机器都分发下驱动。

连通成功以后一直点击继续。
SPARK



然后一直点继续就行了。
然后一直点下一步就行。
OOZIE

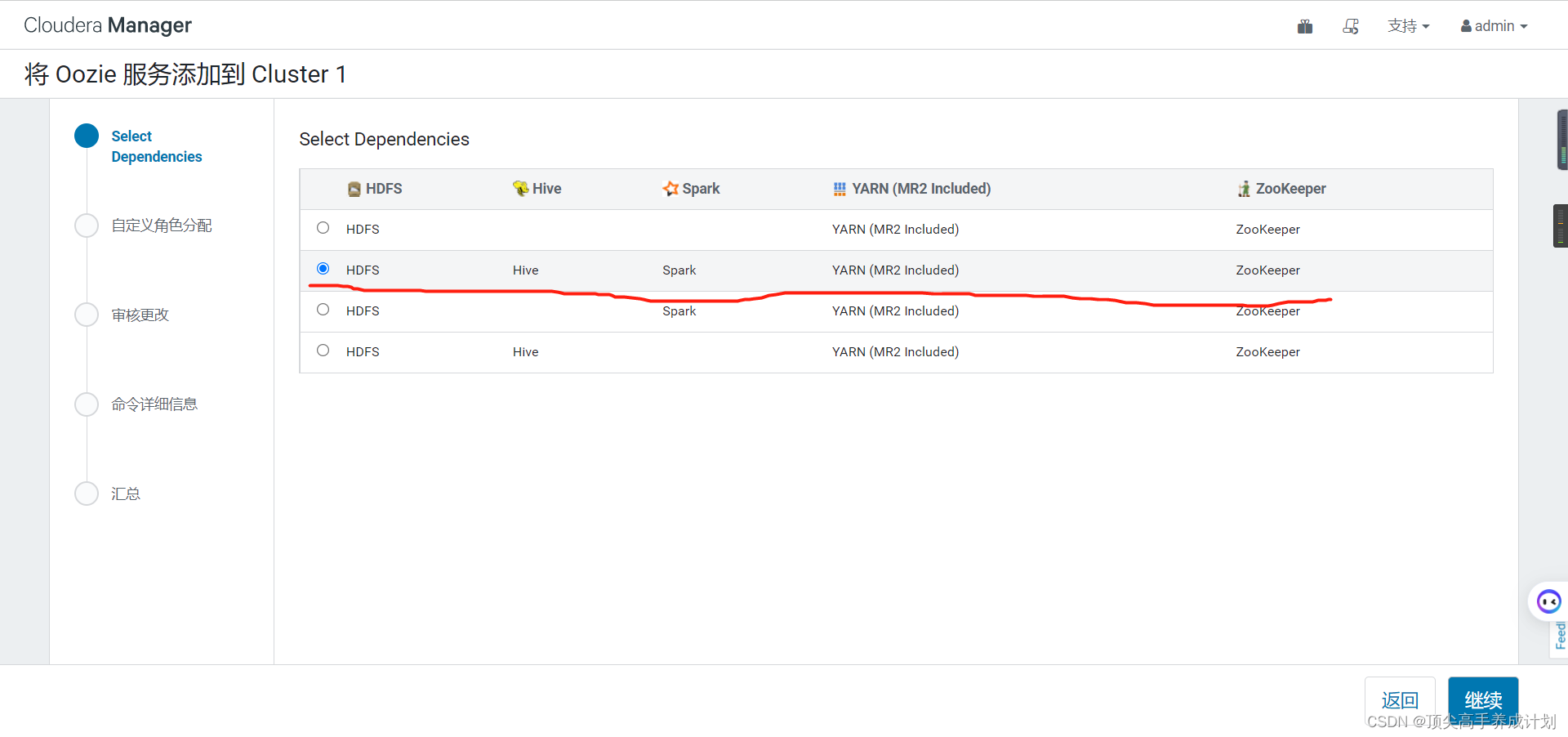
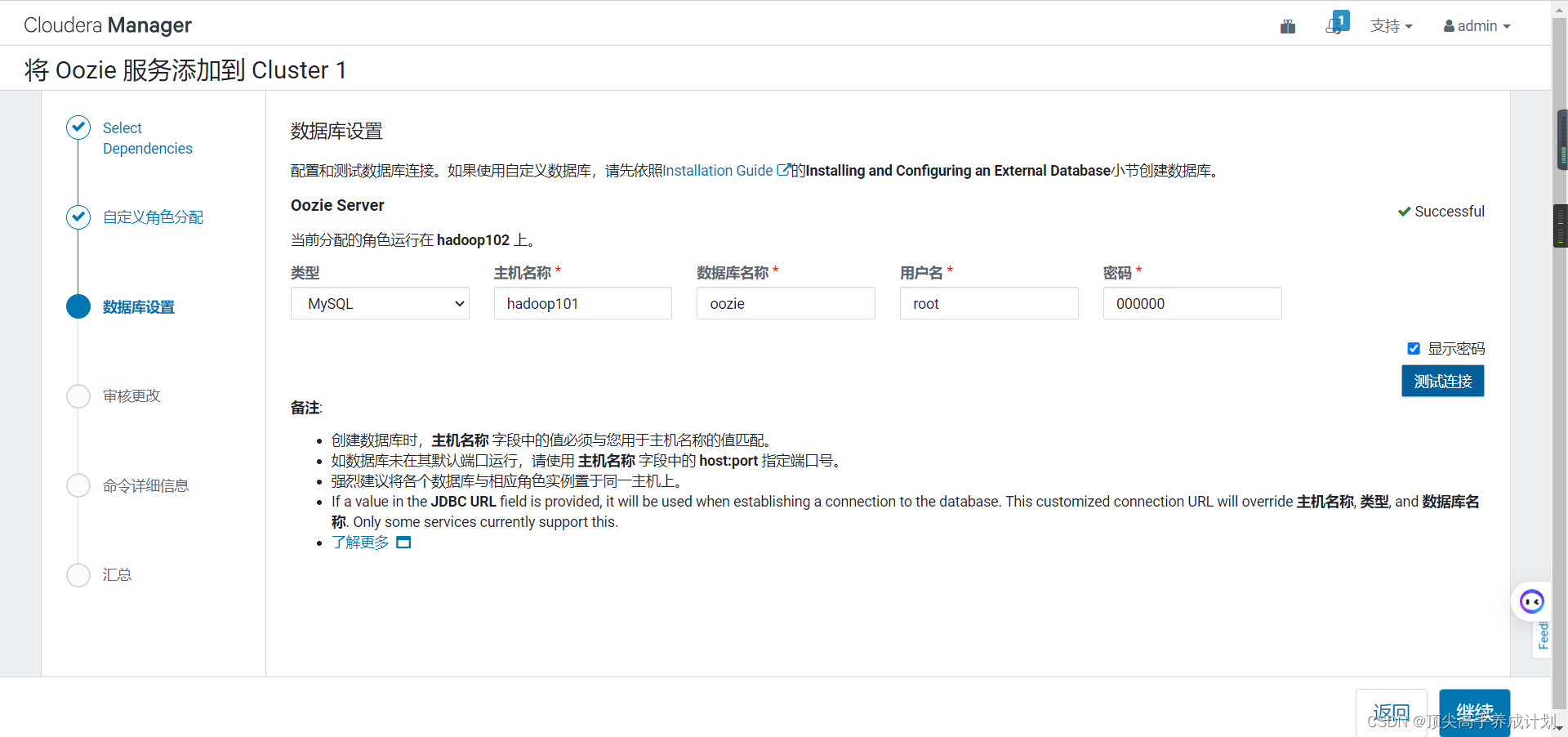
下面的操作一直点继续安装就行了。
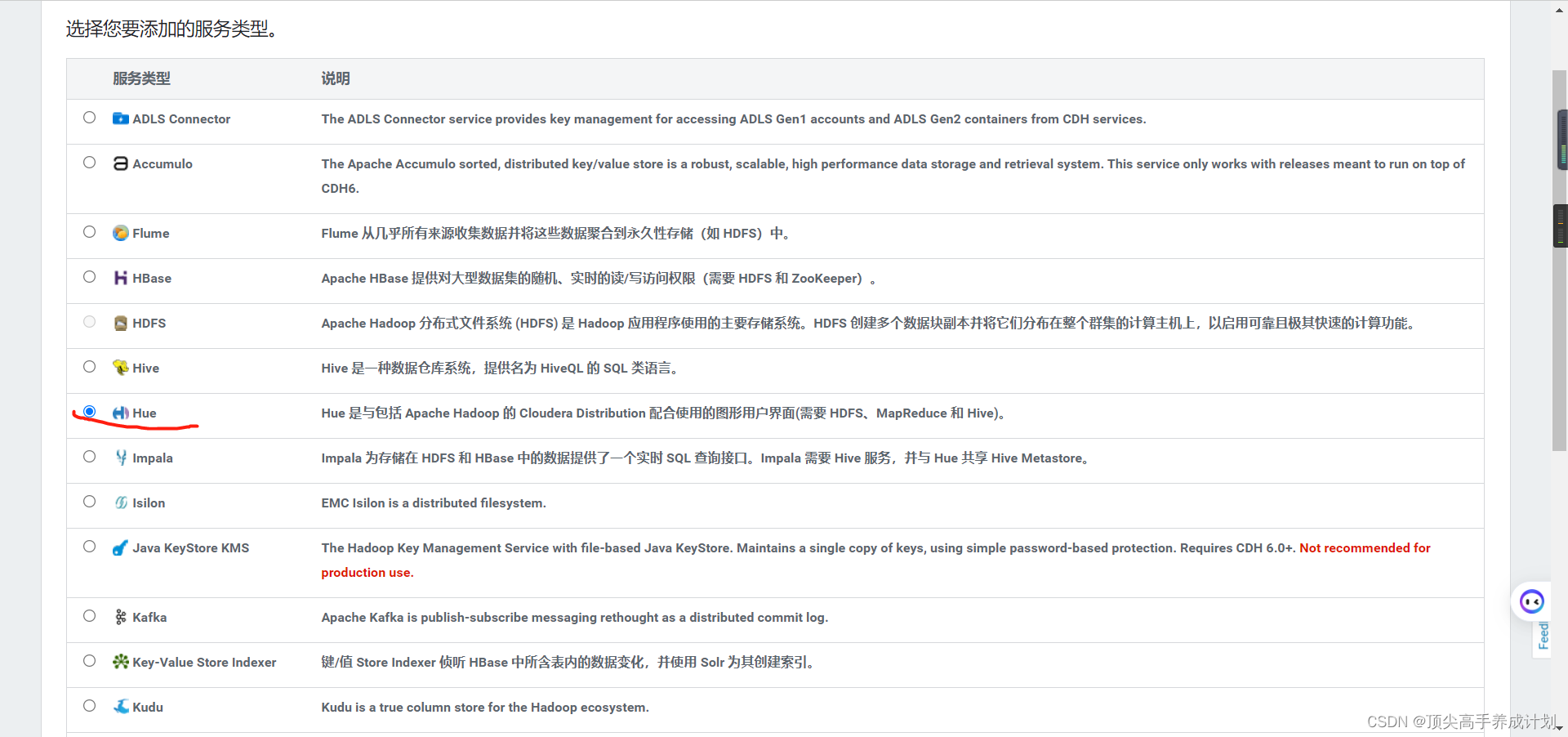
HUE
修改完配置以后记得重启,也就是修改了指定的namenode以后要重启才会生效。

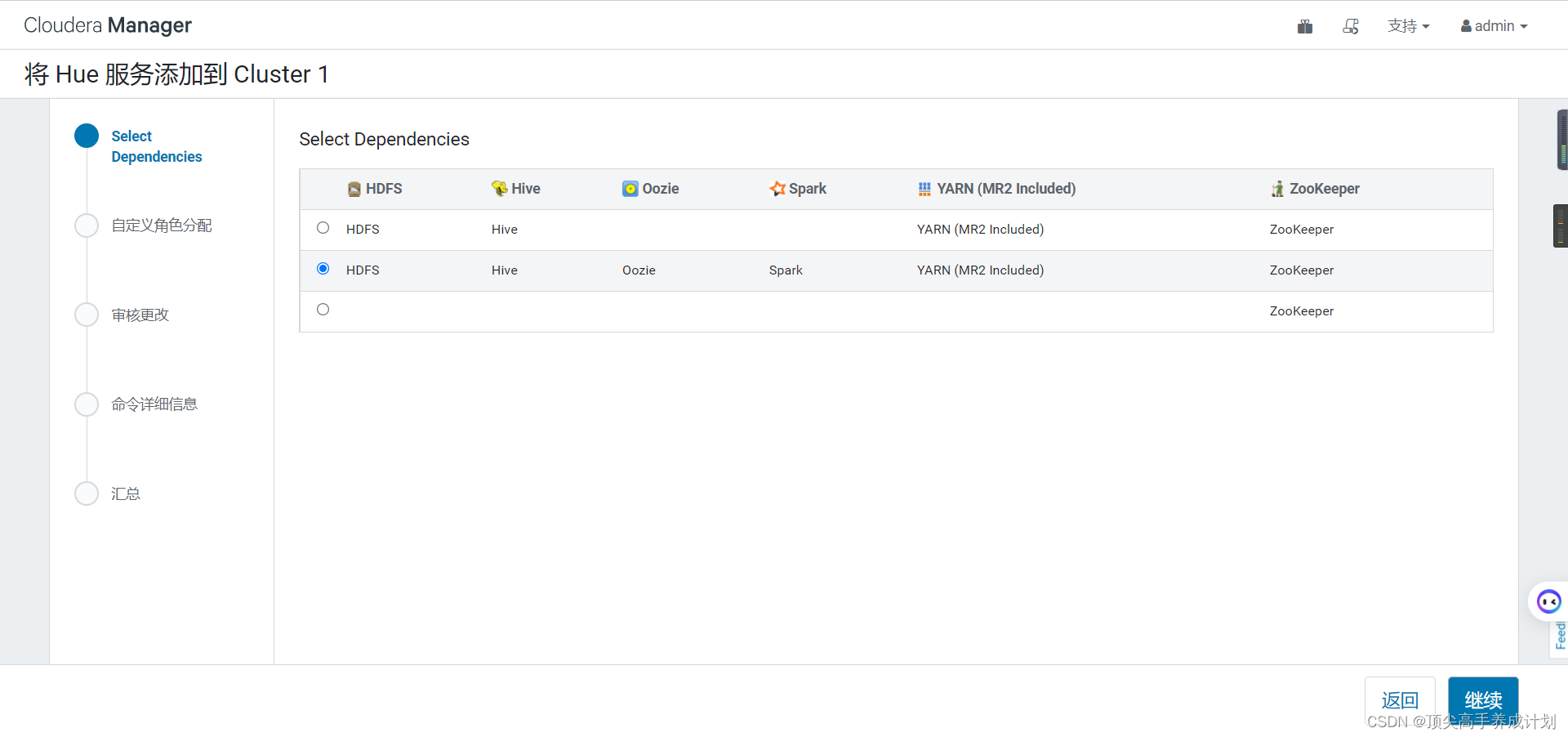
配置负责均衡
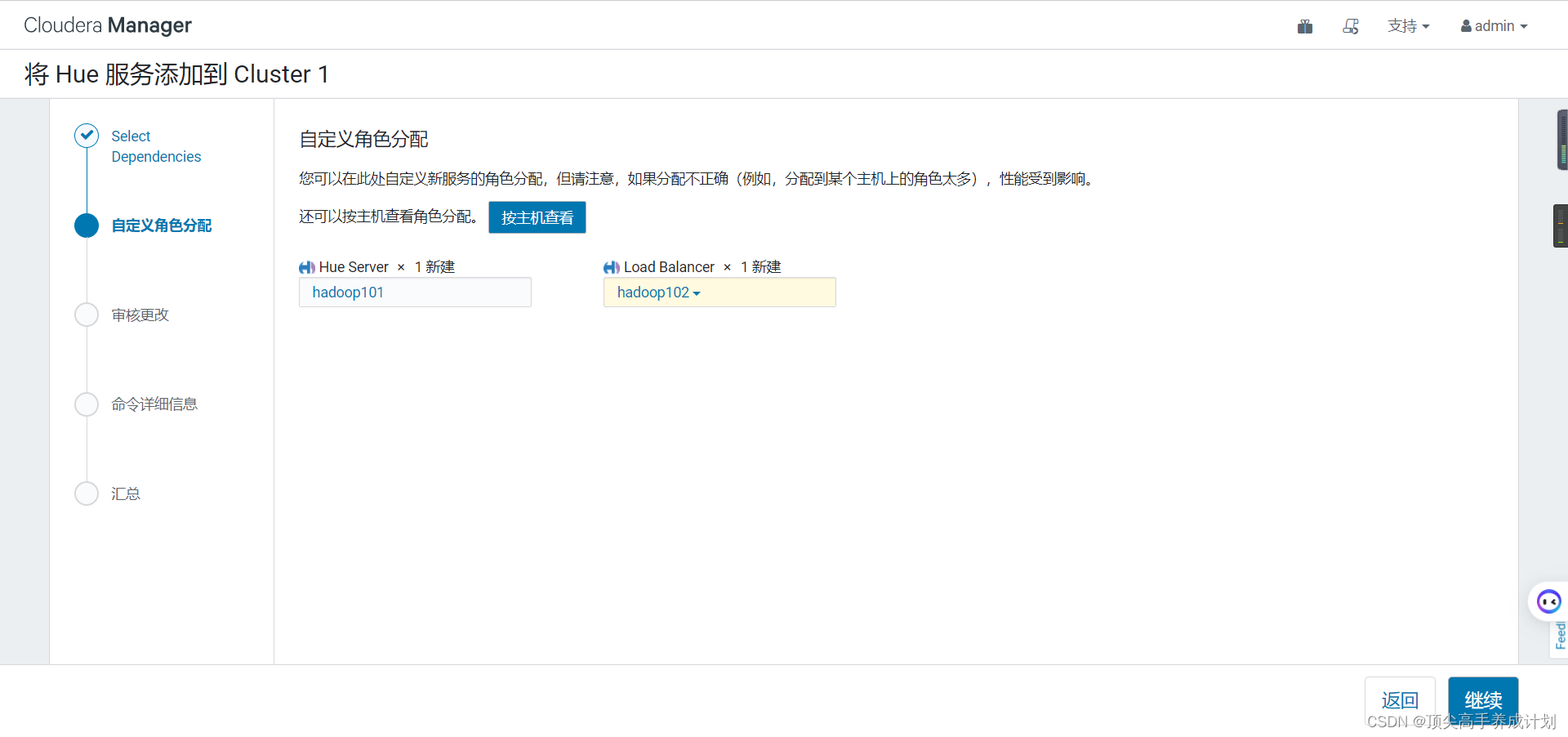
 然后一直下一步就行了。
然后一直下一步就行了。
FLINK
编译Flink的准备工作
mkdir /opt/software && cd /opt/software
cd /opt/software/
# 下载相关的包
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.11.tgz
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-src.tgz
wget https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
#安装配置maven
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module
vi /etc/profile.d/my_env.sh
##添加以下变量
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin
source /etc/profile.d/my_env.sh
mvn -v
cd /opt/module/apache-maven-3.6.3/conf/
rm -rf settings.xml
wget https://cdh6-3-2.oss-cn-hangzhou.aliyuncs.com/cdh/settings.xml
修改Flink源码配置文件
tar -zxvf /opt/software/flink-1.13.6-src.tgz -C /opt/module
cd /opt/module
mv flink-1.13.6/ flink-1.13.6-src
cd /opt/software/
tar -zxvf flink-1.13.6-bin-scala_2.11.tgz -C /opt/module
cd /opt/module/flink-1.13.6-src/
vi /opt/module/flink-1.13.6-src/pom.xml
<!-- 修改hadoop版本 96行 -->
<hadoop.version>3.0.0-cdh6.3.2</hadoop.version>
<!-- 修改hive版本 149行 -->
<hive.version>2.1.1-cdh6.3.2</hive.version>
<!-- 156行 -->
<hivemetastore.hadoop.version>3.0.0-cdh6.3.2</hivemetastore.hadoop.version>
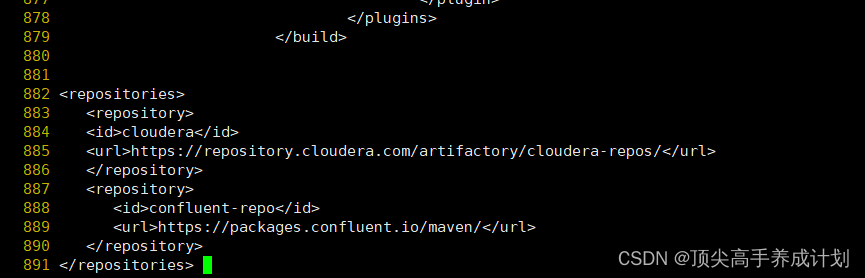
<!-- </build>标签之后 </project>之前 添加-->
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>confluent-repo</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>


 下面加到第一个一个build后面就行了
下面加到第一个一个build后面就行了
vi /opt/module/flink-1.13.6-src/flink-connectors/flink-sql-connector-hive-2.2.0/pom.xml
<!-- 修改hive-exec版本 48行-->
<artifactId>hive-exec</artifactId>
<version>2.1.1-cdh6.3.2</version>
配置MAVEN仓库
cd /opt/module/apache-maven-3.6.3
#选用地址
wget https://vauolab39lsdutji7q2p.oss-cn-zhangjiakou-internal.aliyuncs.com/apache/flink/repository.zip
#备用地址
wget https://cdh6-3-2.oss-cn-hangzhou.aliyuncs.com/cdh/repository.zip
yum -y install unzip
unzip repository.zip
vi /opt/module/apache-maven-3.6.3/conf/settings.xml
<localRepository>/opt/module/apache-maven-3.6.3/repository</localRepository>
编译Flink源码
cd /opt/module/flink-1.13.6-src
mvn clean install -DskipTests -Dfast -Drat.skip=true -Dhaoop.version=3.0.0-cdh6.3.2 -Dinclude-hadoop -Dscala-2.11 -T10C
稍等半个小时以后编译成功了。
考备编译好的包到下载的正式包的lib下面。
cp /opt/module/flink-1.13.6-src/flink-connectors/flink-sql-connector-hive-2.2.0/target/flink-sql-connector-hive-2.2.0_2.11-1.13.6.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hive-exec-2.1.1-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/libfb303-0.9.3.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-hs-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cp /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.6/lib/
cd /opt/module/flink-1.13.6/lib/
制作parcel包和csd文件
#制作parcel包和csd文件
cd /opt/module
tar -zcvf flink-1.13.6-cdh6.3.2.tgz flink-1.13.6
yum install -y git
cd /opt/module
git clone https://github.com/YUjichang/flink-parcel.git
#加速地址
git clone https://gitclone.com/github.com/YUjichang/flink-parcel.git
cd /opt/module/flink-parcel/
#修改配置文件如下
vi flink-parcel.properties
放目录地址
FLINK_URL= /opt/module/flink-1.13.6-cdh6.3.2.tgz
#flink版本号
FLINK_VERSION=1.13.6
#扩展版本号
EXTENS_VERSION=CDH6.3.2
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=6.0
CDH_MAX_FULL=6.4#CDH大版本
CDH_MIN=5
CDH_MAX=6
./build.sh parcel
./build.sh csd
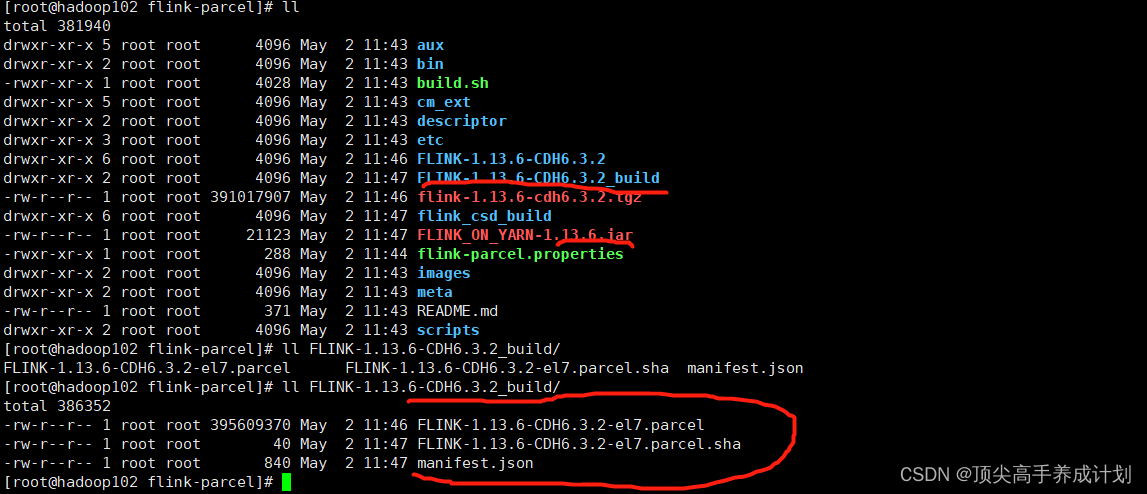
CM安装Flink
cd /opt/cloudera/parcel-repo
sz manifest.json
#然后在下载上面生成的manifest.json
# 在hadoop102执行
scp FLINK-1.13.6-CDH6.3.2-el7.parcel* hadoop101:/opt/cloudera/parcel-repo
# 在hadoop101上面的包如下
-rw-r--r-- 1 root root 2082186246 May 1 17:26 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel
-rw-r--r-- 1 root root 40 May 1 17:20 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.sha
-rw-r----- 1 cloudera-scm cloudera-scm 79610 May 2 00:09 CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel.torrent
-rw-r--r-- 1 root root 395609370 May 2 12:43 FLINK-1.13.6-CDH6.3.2-el7.parcel
-rw-r--r-- 1 root root 40 May 2 12:43 FLINK-1.13.6-CDH6.3.2-el7.parcel.sha
-rw-r--r-- 1 root root 33892 May 1 17:19 manifest.json
sz manifest.json
#拷贝FLINK_ON_YARN
cd /opt/module/flink-parcel
scp FLINK_ON_YARN-1.13.6.jar hadoop101:/opt/cloudera/csd/
[root@hadoop101 csd]# ls
FLINK_ON_YARN-1.13.6.jar
#重启服务
systemctl restart cloudera-scm-server
#查看启动日志
tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log
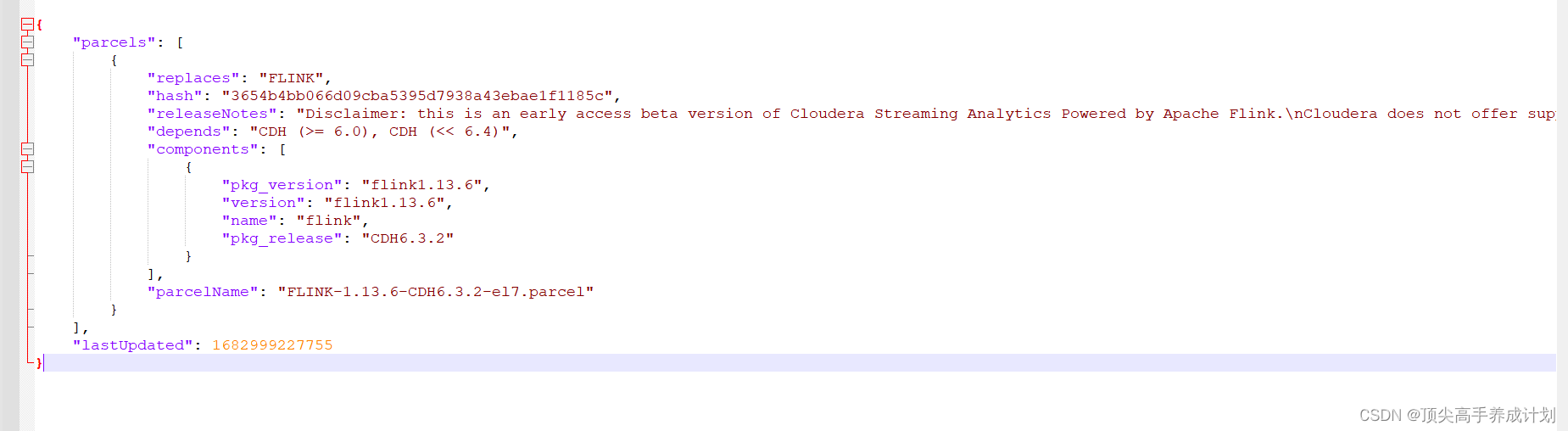
把hadoop102生成的manfest.json放在hadoop101的 manfest.json最下面就行
 下面分配完以后点击激活
下面分配完以后点击激活

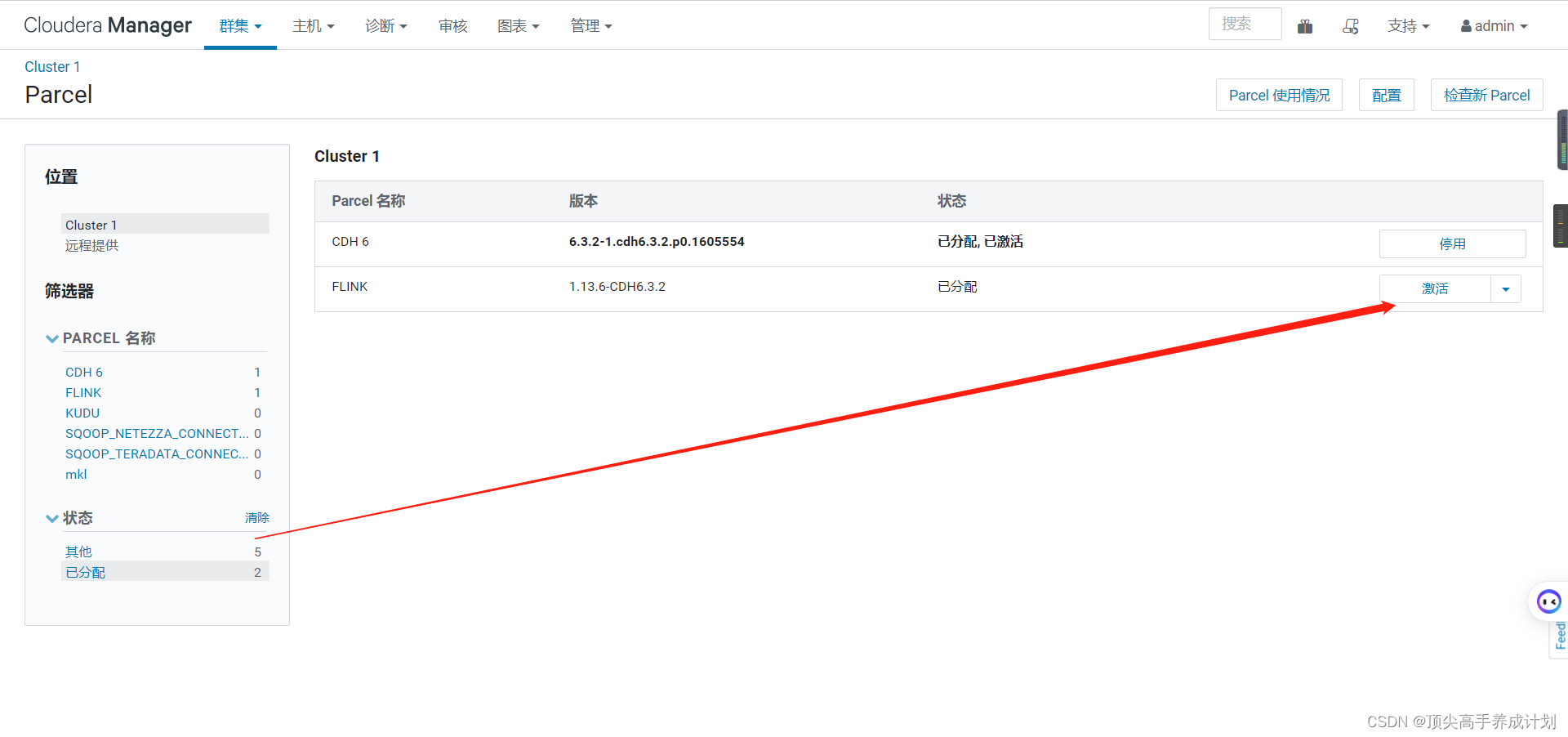 添加服务
添加服务
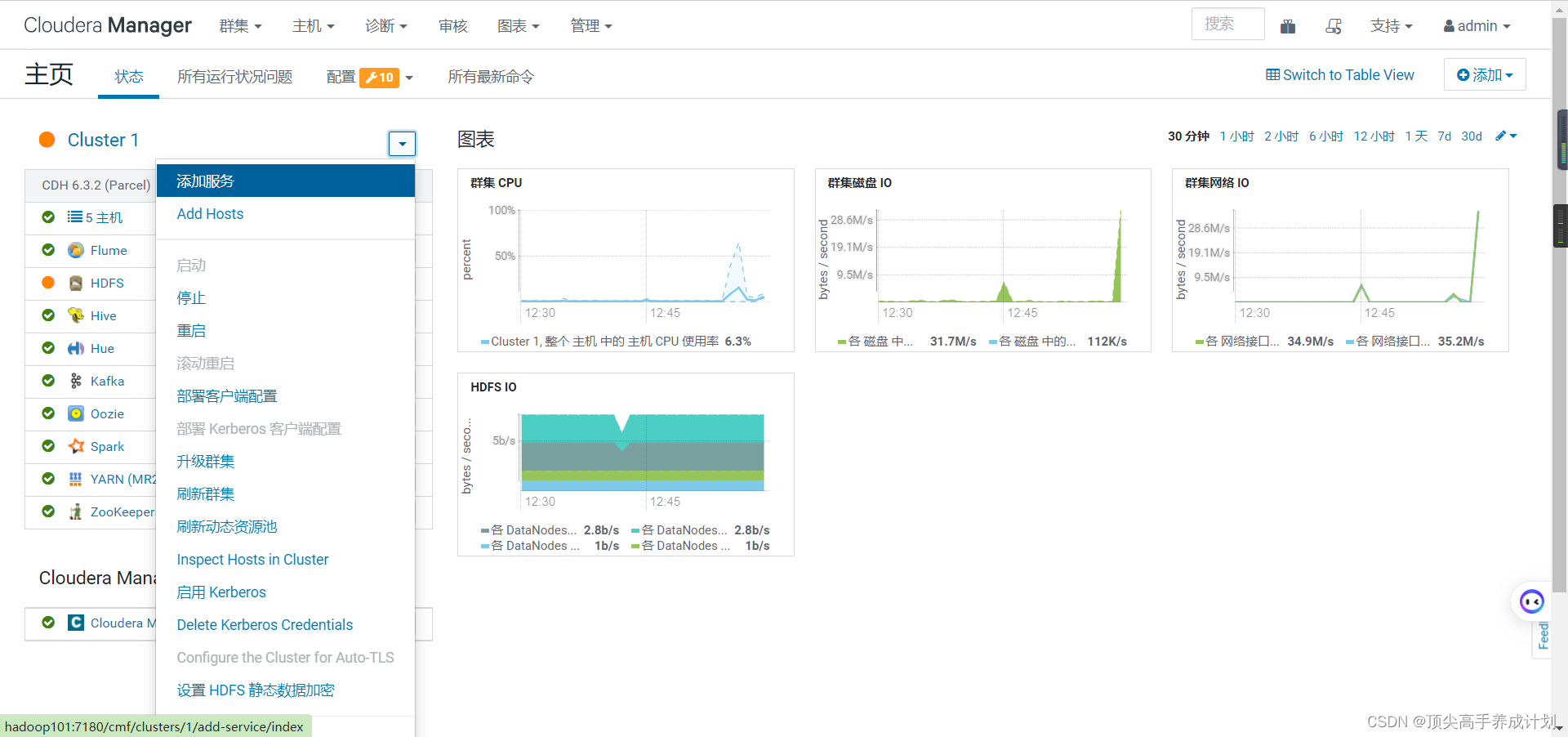 下面就出现了flink
下面就出现了flink



然后一直点继续就行了
由于没有监控到Flink服务,重启下CM
 直接点击下面的重启不用修改任何配置。
直接点击下面的重启不用修改任何配置。
 刷新下就行了,或者点进去退出刷新下。
刷新下就行了,或者点进去退出刷新下。
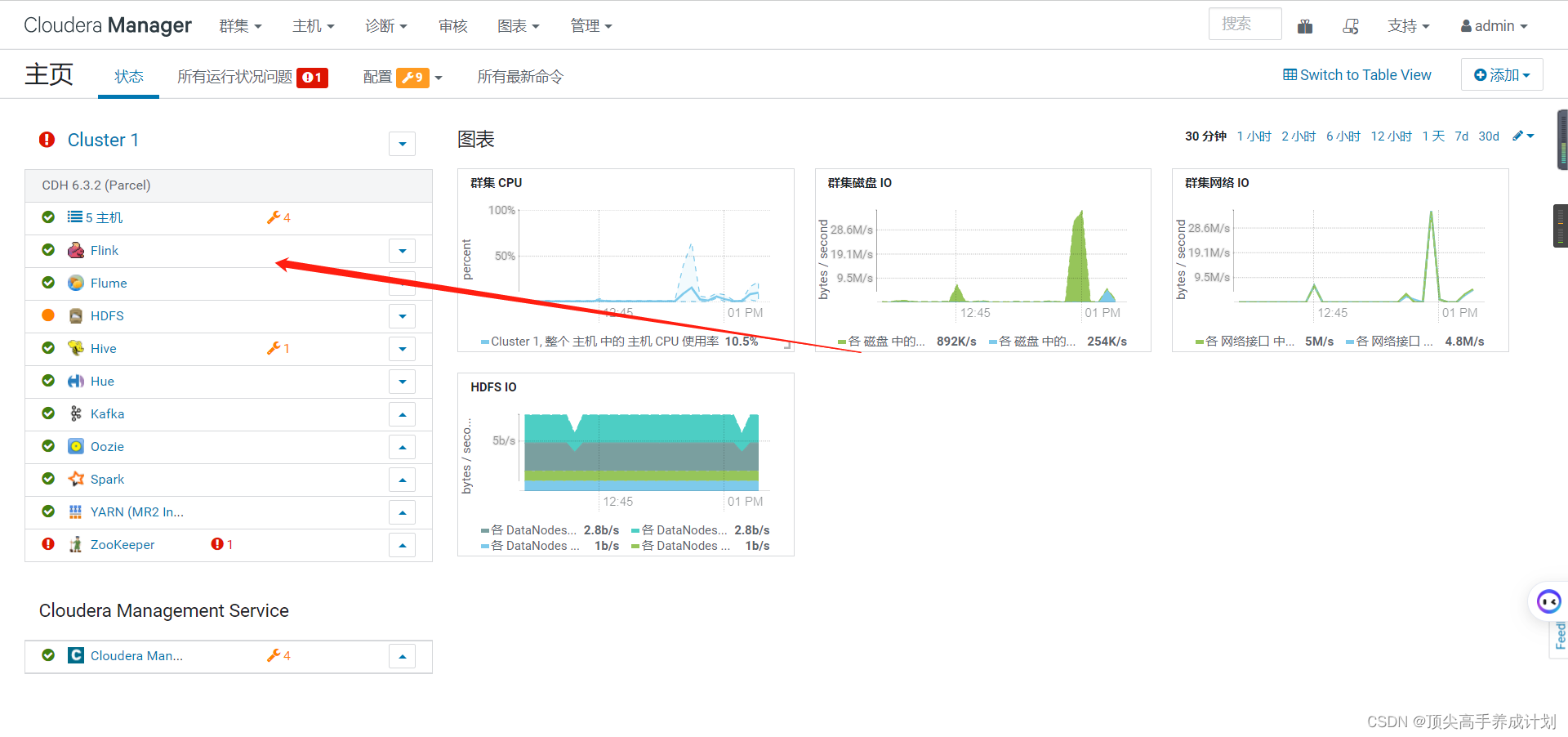
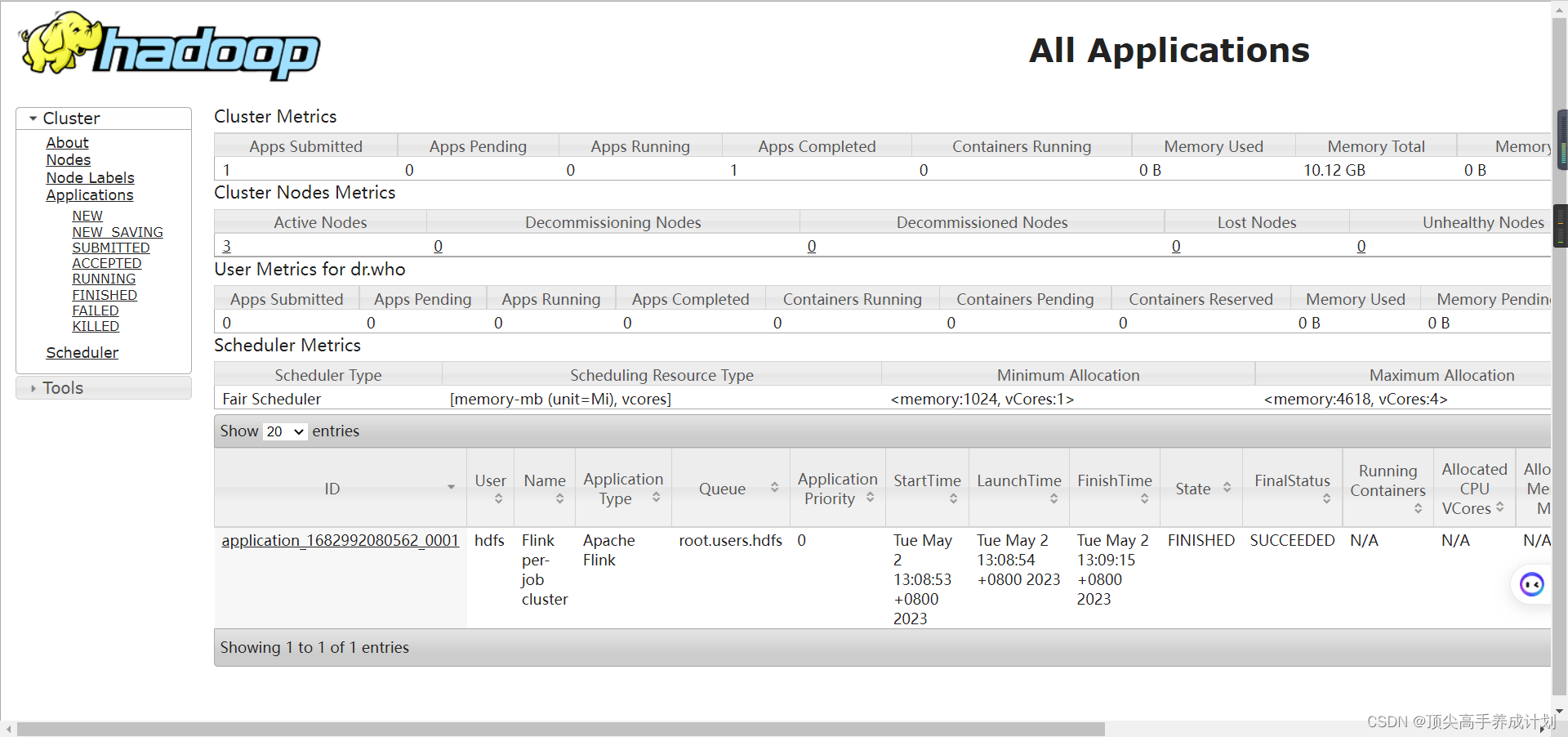
验证Flink是否成功
跑一个per-job
chmod 777 /opt/cloudera/parcels/FLINK/bin/flink
sudo -u hdfs /opt/cloudera/parcels/FLINK/bin/flink run -t yarn-per-job /opt/cloudera/parcels/FLINK/lib/flink/examples/batch/WordCount.jar

验证Flink SQL
#验证flink sql
/opt/cloudera/parcels/FLINK/bin/flink-sql-client
Kerberos
概念
Kerberos中有以下一些概念需要了解:
(1)KDC:密钥分发中心,负责管理发放票据,记录授权。
(2)Realm:Kerberos管理领域的标识。(领域名)
(3)principal:当每添加一个用户或服务的时候都需要向kdc添加一条principal,principl的形式为:主名称(用户|服务名)/实例名(组|实例名)@领域名。(账户)
(4)主名称:主名称可以是用户名或服务名,表示是用于提供各种网络服务(如hdfs,yarn,hive)的主体。
(5)实例名:实例名简单理解为主机名。
使用的时候不光用户要注册,所使用的服务也要注册。
认证原理
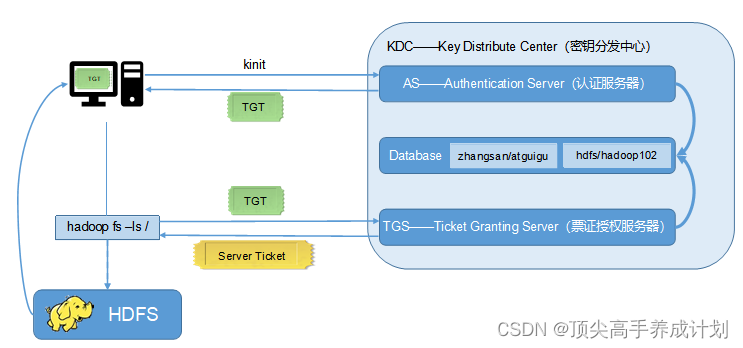
上面的KDS包含AS认证服务器,Database数据库,TGS授权票据服务器。
zhangsan/atguigu是用户主体,hdfs/hadoop102是服务主体。
kinit带有用户主体,他会在Database找有没有对应的用户zhangsan/atguigu.
如果找到了那么就返回一个TGT。得到TGT以后缓存到客户端,这个时候用户认证通过。
用户发送hadoop fs -ls / 就会携带TGT到TGS里面去授权,TGS更具TGT的信息查看是否对应的服务有注册,如果服务有注册,那么就会返回给客户端一个Server Ticket服务票据。这个时候才能够访问HDFS,这个时候结果才能够返回给客户端。
Apache : 1.用户认证。2.用户主体的注册&服务主体的注册。3. 用户的认证。
CDH:1.用户主体的注册。2.用户的认证。服务主体CDH会自动的创建。
安装
安装
################安装#############
#server安装(hadoop101)
yum install -y krb5-server krb5-workstation krb5-libs
rpm -qa | grep krb5
[root@hadoop101 bin]# rpm -qa | grep krb5
krb5-workstation-1.15.1-55.el7_9.x86_64
krb5-devel-1.15.1-55.el7_9.x86_64
krb5-server-1.15.1-55.el7_9.x86_64
krb5-libs-1.15.1-55.el7_9.x86_64
#client安装(hadoop102,hadoop103,hadoop104,hadoop105)
yum install -y krb5-workstation krb5-libs
rpm -qa | grep krb5
[root@hadoop105 ~]# rpm -qa | grep krb5
krb5-devel-1.15.1-55.el7_9.x86_64
krb5-libs-1.15.1-55.el7_9.x86_64
krb5-workstation-1.15.1-55.el7_9.x86_64
修改kdc配置
##############修改配置###########
#hadoop101
vi /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
HADOOP.COM = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
max_life = 1d
max_renewable_life = 7d
supported_enctypes = aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
HADOOP.COM:realm名称,Kerberos支持多个realm,一般全用大写。
max_life = 1d: 保存到客户端的TGT的时间。
max_renewable_life = 7d :自动刷新TGT时间,这里配置最多刷新7天。
supported_enctypes:这些是认证的算法,这里配置比原来的少了一个最前面的算法,因为加的话要有对应的依赖包。
krb5文件配置
##############修改配置###########
#hadoop101
vi /etc/krb5.conf
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = /etc/pki/tls/certs/ca-bundle.crt
default_realm = HADOOP.COM
#default_ccache_name = KEYRING:persistent:%{uid}
udp_preference_limit = 1
[realms]
HADOOP.COM = {
kdc = hadoop101
admin_server = hadoop101
}
[domain_realm]
# .example.com = EXAMPLE.COM
# example.com = EXAMPLE.COM
udp_preference_limit :禁止使用udp防止返回Hadoop的时候有错误。
default_realm:配置默认域。
ticket_lifetime = 24h 这两个和上面的配置一样的TGT时间。
renew_lifetime = 7d 这两个和上面的配置一样的TGT时间。
分发配置文件
/opt/shell/bin/xsync /etc/krb5.conf
生成Kerberos数据库
##############生成Kerberos数据库###########
#hadoop101
kdb5_util create -s #后面我输入了123,密码随意记住就行
ls /var/kerberos/krb5kdc/
[root@hadoop101 bin]# ls /var/kerberos/krb5kdc/
kadm5.acl kdc.conf principal principal.kadm5 principal.kadm5.lock principal.ok
# 赋予Kerberos管理员所有权限
vi /var/kerberos/krb5kdc/kadm5.acl
#修改为以下内容:
*/[email protected] *
说明:
*/admin:admin实例的全部主体
@HADOOP.COM:realm
*:全部权限
这个授权的意思:就是授予admin实例的全部主体对应HADOOP.COM领域的全部权限。也就是创建Kerberos主体的时候如果实例为admin,就具有HADOOP.COM领域的全部权限,比如创建如下的主体user1/admin就拥有全部的HADOOP.COM领域的权限。
启动Kerberos服务
#########启动Kerberos服务#########
# hadoop101
systemctl start krb5kdc
systemctl start kadmin
systemctl enable krb5kdc
systemctl is-enabled krb5kdc
systemctl enable kadmin
systemctl is-enabled kadmin
登录Kerberos数据库
##############登录Kerberos数据库#################
# 1)本地登录(无需认证),按两下tab键就能够打印所有的命令
kadmin.local
# 2)远程登录(需进行主体认证)
kadmin
# 3)退出输入:exit
#创建一个admin主体在admin组,输入密码的时候就是刚才初始化Kerberos数据库的123
addprinc admin/admin
kadmin.local: addprinc admin/admin
WARNING: no policy specified for admin/[email protected]; defaulting to no policy
Enter password for principal "admin/[email protected]":
Re-enter password for principal "admin/[email protected]":
Principal "admin/[email protected]" created.
########查看所有的主体#############
listprincs
kadmin.local: listprincs
K/[email protected]
admin/[email protected]
kadmin/[email protected]
kadmin/[email protected]
kadmin/[email protected]
kiprop/[email protected]
krbtgt/[email protected]
#############为刚才的admin/admin修改密码########### 123 密码随意
cpw admin/admin
##########使用命令行配置###########
kadmin.local -q "addprinc zhangsan/test"
kadmin.local -q "listprincs"
[root@hadoop101 bin]# kadmin.local -q "listprincs"
Authenticating as principal root/[email protected] with password.
K/[email protected]
admin/[email protected]
kadmin/[email protected]
kadmin/[email protected]
kadmin/[email protected]
kiprop/[email protected]
krbtgt/[email protected]
zhangsan/[email protected]
Kerberos主体认证
Kerberos提供了两种认证方式,一种是通过输入密码认证,另一种是通过keytab密钥文件认证,但两种方式不可同时使用。
#########################密码认证########################
# 1)使用kinit进行主体认证
kinit admin/admin
# 2)查看认证凭证
klist
[root@hadoop101 bin]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: admin/[email protected]
Valid starting Expires Service principal
05/02/2023 14:32:48 05/03/2023 14:32:48 krbtgt/[email protected]
renew until 05/09/2023 14:32:48
# 3)销毁认证凭证
kdestroy
[root@hadoop101 bin]# kdestroy
[root@hadoop101 bin]# klist
klist: No credentials cache found (filename: /tmp/krb5cc_0)
#################秘钥认证################################
# 由于认证过程中都需要输入密码。所以我们需要为user用户生成keytab文件,便于后续免密登录,不指定路径的话默认放在当前工作目录,我们指定到“/etc/ security/”下。
# 注意:在生成keytab文件时需要加参数”-norandkey”,否则CDH平台的kerberos密码会重置,会导致直接使用kinit admin/admin初始化时会提示密码错误。
# kadmin.local -q "xst -k /root/admin.keytab admin/[email protected]" #这种会对于密码进行修改
kadmin.local -q "xst -norandkey -k /root/admin.keytab admin/[email protected]"
kinit -kt /root/admin.keytab admin/admin
klist
[root@hadoop101 bin]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: admin/[email protected]
Valid starting Expires Service principal
05/02/2023 14:37:51 05/03/2023 14:37:51 krbtgt/[email protected]
renew until 05/09/2023 14:37:51
kdestroy
CDH启用Kerberos安全认证
#############创建一个cm的用户#########密码随意,我设置了123456
kadmin.local -q "addprinc cloudera-scm/admin"

 Kerberos 加密类型:aes128-cts、des3-hmac-sha1、arcfour-hmac。
Kerberos 加密类型:aes128-cts、des3-hmac-sha1、arcfour-hmac。

因为上面已经配置了

后面的就一直继续就行了。
实操
使用hive和hdfs
###############Kerberos安全环境实操######################
# [root@hadoop101 bin]# kdestroy
# [root@hadoop101 bin]# klist
#登录
# kinit admin/[email protected]
#添加主体
# kadmin.local -q "addprinc hive/[email protected]" ,kinit hive/[email protected],hadoop fs -ls /(hive/[email protected]这个用户也能够访问)
#删除主体
# kadmin.local -q "delprinc hive/[email protected]"
# 在启用Kerberos之后,系统与系统(flume-kafka)之间的通讯,以及用户与系统(user-hdfs)之间的通讯都需要先进行安全认证,认证通过之后方可进行通讯。
# 故在启用Kerberos后,数仓中使用的脚本等,均需要加入一步安全认证的操作,才能正常工作。
# 1)在Kerberos数据库中创建用户主体/实例
kadmin.local -q "addprinc hive/[email protected]"
# 2)进行用户认证
kinit hive/[email protected]
# 3)访问HDFS
hadoop fs -ls /
Found 2 items
drwxrwxrwt - hdfs supergroup 0 2023-01-04 11:26 /tmp
drwxr-xr-x - hdfs supergroup 0 2023-01-04 11:29 /user
# 4)hive查询
hive
hive> show databases;
OK
default
使用kafka
# 修改Kafka配置
# 在Kafka的配置项搜索“security.inter.broker.protocol”,设置为SALS_PLAINTEXT
vi /var/lib/hive/jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useTicketCache=true;
};
vi /etc/kafka/conf/consumer.properties
security.protocol=SASL_PLAINTEXT
sasl.kerberos.service.name=kafka
export KAFKA_OPTS="-Djava.security.auth.login.config=/var/lib/hive/jaas.conf"
#消费数据
kafka-console-consumer --bootstrap-server hadoop103:9092 --topic topic_start --from-beginning --consumer.config /etc/kafka/conf/consumer.properties
Caused by: javax.security.auth.login.LoginException: Could not login: the client is being asked for a password, but the Kafka client code does not currently support obtaining a password from the user. not available to garner authentication information from the user
at com.sun.security.auth.module.Krb5LoginModule.promptForPass(Krb5LoginModule.java:940)
at com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:760)
at com.sun.security.auth.module.Krb5LoginModule.login(Krb5LoginModule.java:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at javax.security.auth.login.LoginContext.invoke(LoginContext.java:755)
at javax.security.auth.login.LoginContext.access$000(LoginContext.java:195)
at javax.security.auth.login.LoginContext$4.run(LoginContext.java:682)
at javax.security.auth.login.LoginContext$4.run(LoginContext.java:680)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.login.LoginContext.invokePriv(LoginContext.java:680)
at javax.security.auth.login.LoginContext.login(LoginContext.java:587)
at org.apache.kafka.common.security.authenticator.AbstractLogin.login(AbstractLogin.java:60)
at org.apache.kafka.common.security.kerberos.KerberosLogin.login(KerberosLogin.java:103)
at org.apache.kafka.common.security.authenticator.LoginManager.<init>(LoginManager.java:61)
at org.apache.kafka.common.security.authenticator.LoginManager.acquireLoginManager(LoginManager.java:111)
at org.apache.kafka.common.network.SaslChannelBuilder.configure(SaslChannelBuilder.java:149)
... 8 more
#如果没有进行认证,那么就会报错
kadmin.local -q "addprinc kafka/[email protected]" , kinit kafka/[email protected] ,klist , kdestroy
kafka-console-consumer --bootstrap-server hadoop103:9092 --topic topic_start --from-beginning --consumer.config /etc/kafka/conf/consumer.properties
vi /etc/profile.d/my_env.sh
export KAFKA_OPTS="-Djava.security.auth.login.config=/var/lib/hive/jaas.conf"
source /etc/profile.d/my_env.sh
HDFS WebUI浏览器认证
这个要安装火狐,配置东西才能用,用处不太大Hue也能够看,就不配置了。
安全之Sentry权限管理
Apache Sentry是Cloudera公司发布的一个Hadoop开源组件,它提供了细粒度级、基于角色的授权以及多租户的管理模式。
Sentry提供了对Hadoop集群上经过身份验证的用户和应用程序的数据控制和强制执行精确级别权限的功能。Sentry目前可以与Apache Hive,Hive Metastore / HCatalog,Apache Solr,Impala和HDFS(仅限于Hive表数据)一起使用。
Sentry旨在成为Hadoop组件的可插拔授权引擎。它允许自定义授权规则以验证用户或应用程序对Hadoop资源的访问请求。Sentry是高度模块化的,可以支持Hadoop中各种数据模型的授权。

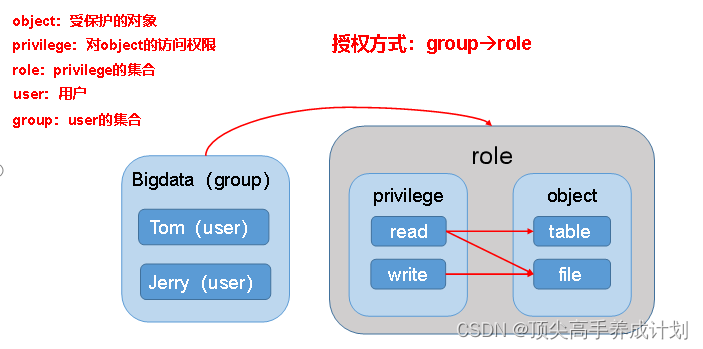
Sentry中的角色
安装
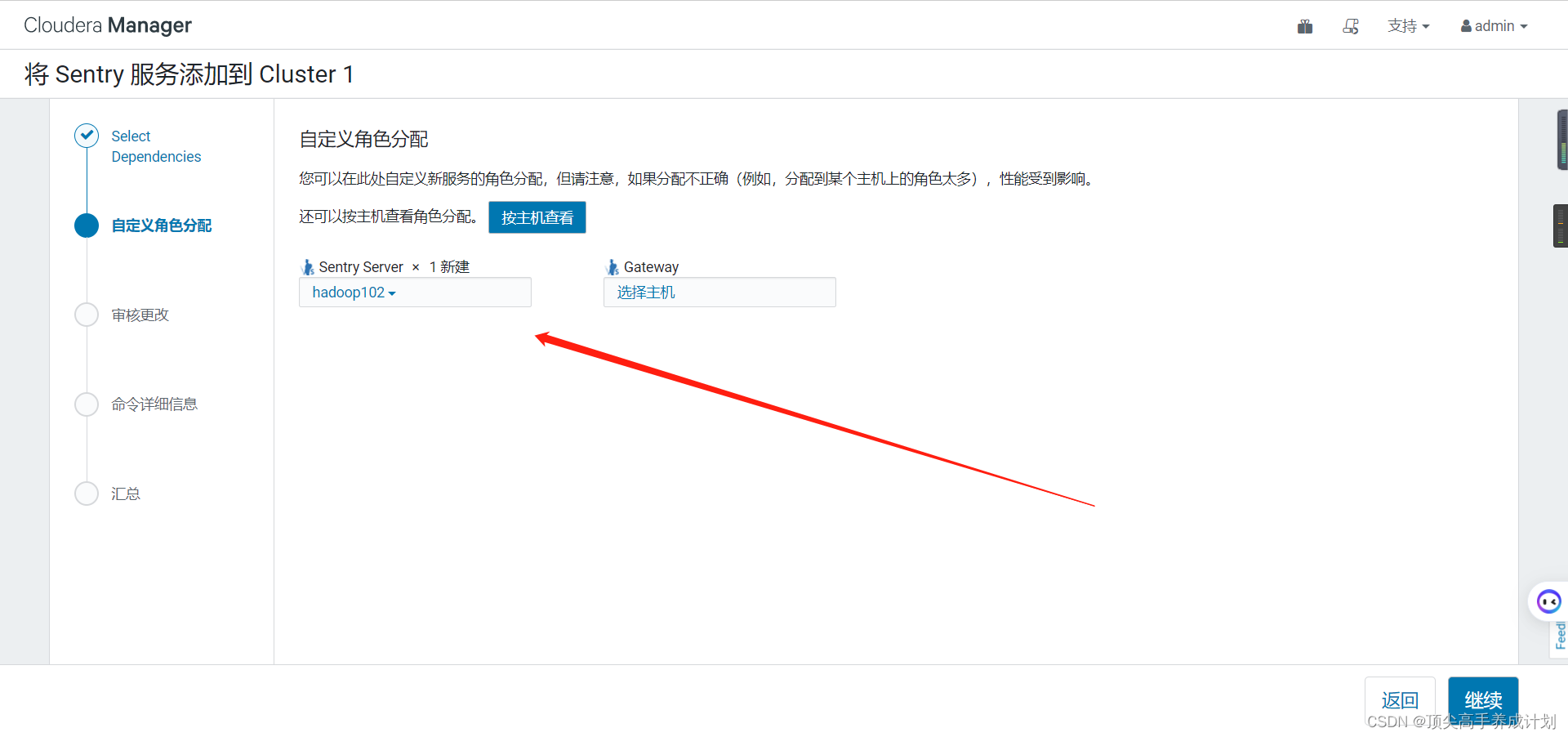

集成HIVE,YARN,HDFS
配置好以后记得重启相关服务。
#与hive集成(hive)
# 在hive配置项中搜索“HiveServer2 启用模拟”,取消勾选
# 在Hive配置项中搜索“启用数据库中的存储通知”,勾选。
# 在Hive配置项中搜索“Sentry”,勾选Sentry。
#确保hive用户能够提交MR任务(yarn)
# 在yarn配置项中搜索“允许的系统用户”,确保包含“hive”。
#在HDFS配置项中搜索“启用访问控制列表”,勾选。(hdfs)
实战HUE
##############实战###############
#HUE(配置完以后重启)
# 在HUE配置项中搜索“Sentry”,勾选Sentry。
#Sentry
# 在Sentry的配置项中搜索“管理员组”,其中包括hive、impala,只有当某用户所属组位于其中时,才可为其他用户授予权限。
#######添加linux用户#########
# 在Hive集群所有节点创建两个用户reader,writer,为权限测试做准备。
useradd reader
passwd reader
useradd writer
passwd writer
# 使用hive用户登录HUE,创建两个用户组reader、writer,并在两个用户组下创建两个用户reader、writer,为权限测试做准备,并且需要创建hive组,将hive用户添加进hive组。
##########################hadoop101操作######################
#如果不用hive登录
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:User kafka does not have privileges for CREATETABLE)
#先用hive相关用户登录
kdestroy
kadmin.local -q "addprinc hive/[email protected]"
kinit hive/[email protected]
#创建hive表
hive
create table student(
id string comment '学号',
name string comment '姓名',
sex string comment '性别',
age string comment '年龄'
) comment '学生表';
insert into student values('1','孙悟空','男','100');
insert into student values('2','明世隐','男','101');
insert into student values('3','高渐离','男','102');
insert into student values('4','孙尚香','女','103');
insert into student values('5','安琪拉','女','104');
##########创建表以后只有hive用户可以看到##############
添加角色
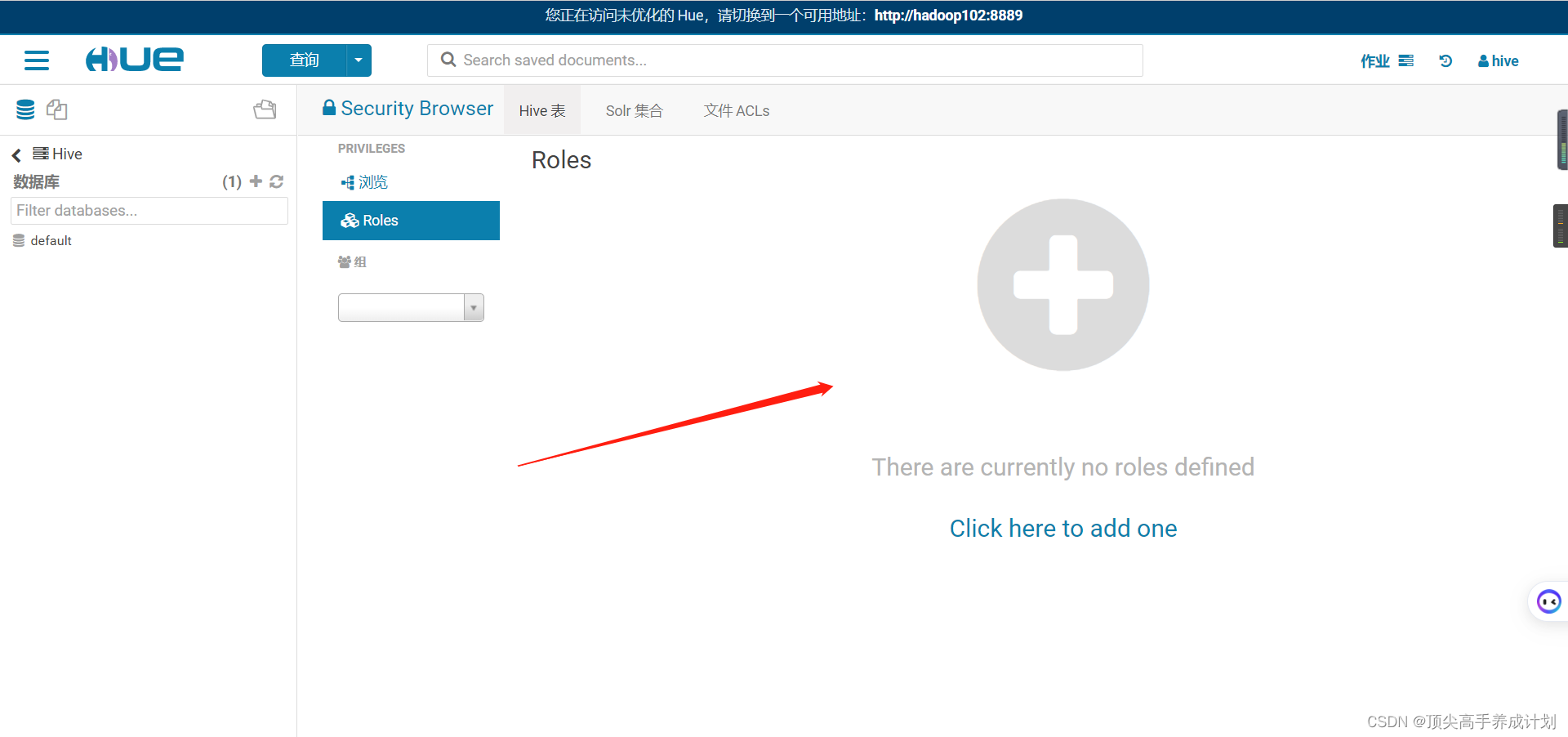

由于上面只配置了只能查询student的name,那么查询的时候就只能查询name。
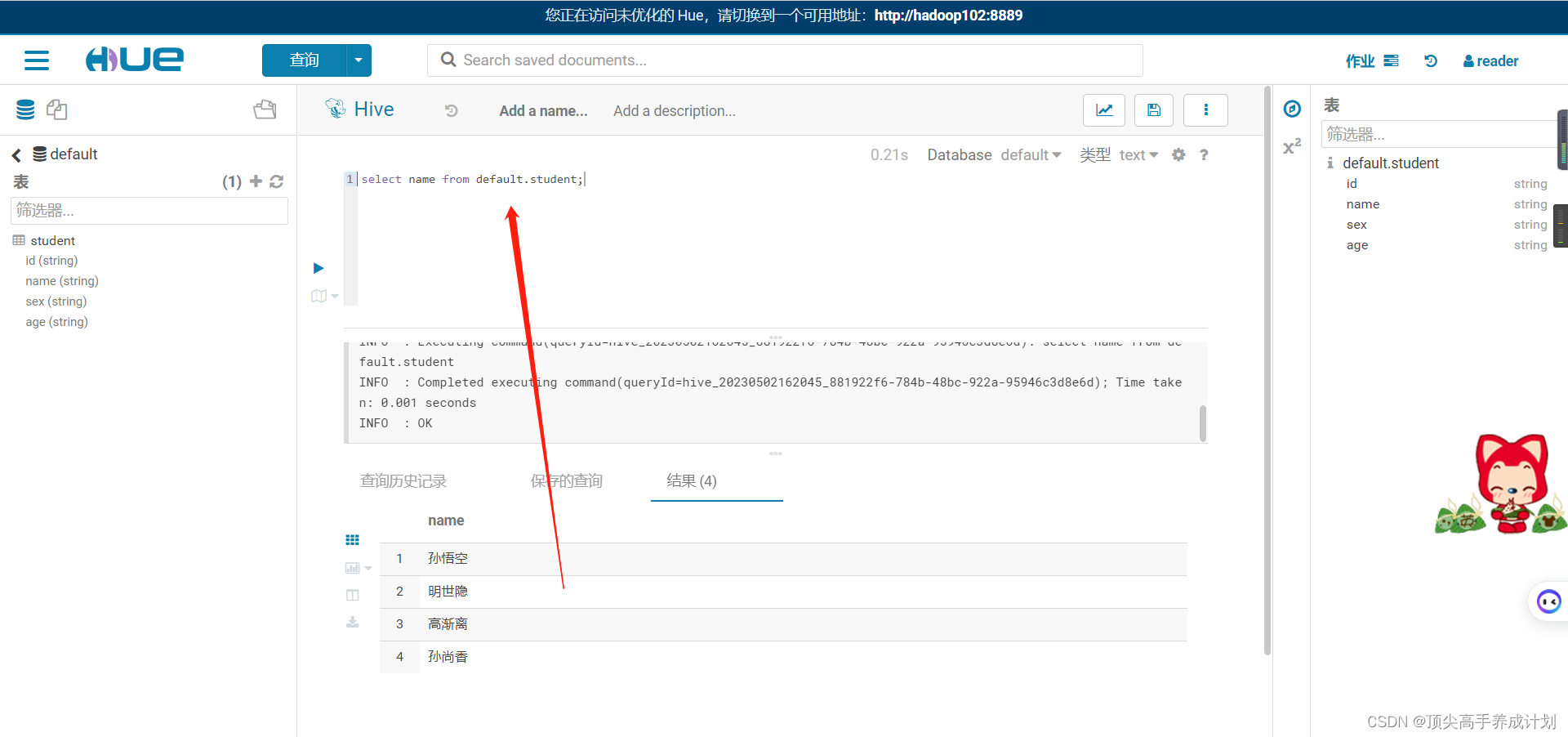
useradd buzhidao
passwd buzhidao
密码buzhidao
hive用户登录,创建 buzhidao 组权限全部和 buzhidao 用户添加到buzhidao组里面然后给表权限
##############linux的密码和HUE的密码相同才行第一次使用的时候##################
Sentry实战之命令行
# 1)在所有节点创建两个用户reader_cmd,writer_cmd
useradd reader_cmd
passwd reader_cmd
useradd writer_cmd
passwd writer_cmd
# 密码都是123456
# 2)使用Sentry管理员用户hive通过beeline客户端连接HiveServer2
kinit hive/[email protected]
beeline -u "jdbc:hive2://hadoop102:10000/;principal=hive/[email protected]"
# 3)创建Role(reader_role_cmd,writer_role_cmd)
create role reader_role_cmd;
create role writer_role_cmd;
# 4)为role赋予privilege
GRANT select ON DATABASE default TO ROLE reader_role_cmd;
GRANT insert ON DATABASE default TO ROLE writer_role_cmd;
# 5)将role授予用户组
GRANT ROLE reader_role_cmd TO GROUP reader_cmd;
GRANT ROLE writer_role_cmd TO GROUP writer_cmd;
# 6)查看权限授予情况
# (1)查看所有role(管理员)
SHOW ROLES;
+------------------+
| role |
+------------------+
| buzhidao |
| fasdf |
| fasdffadsf |
| reader_role |
| reader_role_cmd |
| teset |
| testetset |
| writer_role_cmd |
+------------------+
# (2)查看指定用户组的role(管理员)
SHOW ROLE GRANT GROUP reader_cmd;
+------------------+---------------+-------------+----------+
| role | grant_option | grant_time | grantor |
+------------------+---------------+-------------+----------+
| reader_role_cmd | false | 0 | -- |
+------------------+---------------+-------------+----------+
# (3)查看当前认证用户的role
SHOW CURRENT ROLES;
# (4)查看指定ROLE的具体权限(管理员)
SHOW GRANT ROLE reader_role_cmd;
+-----------+--------+------------+---------+------------------+-----------------+------------+---------------+----------------+----------+
| database | table | partition | column | principal_name | principal_type | privilege | grant_option | grant_time | grantor |
+-----------+--------+------------+---------+------------------+-----------------+------------+---------------+----------------+----------+
| default | | | | reader_role_cmd | ROLE | SELECT | false | 1683019307000 | -- |
+-----------+--------+------------+---------+------------------+-----------------+------------+---------------+----------------+----------+
# 7)权限测试
# (1)为reader_cmd、writer_cmd创建Kerberos主体
kadmin.local -q "addprinc reader_cmd/[email protected]"
kadmin.local -q "addprinc writer_cmd/[email protected]"
# (2)使用reader_cmd登录HiveServer2,查询default库下的任意一张表
kinit reader_cmd/[email protected]
beeline -u "jdbc:hive2://hadoop102:10000/;principal=hive/[email protected]"
+-----------+
| tab_name |
+-----------+
| student |
+-----------+
1 row selected (0.417 seconds)
select * from student;
+-------------+---------------+--------------+--------------+
| student.id | student.name | student.sex | student.age |
+-------------+---------------+--------------+--------------+
| 1 | 孙悟空 | 男 | 100 |
| 2 | 明世隐 | 男 | 101 |
| 3 | 高渐离 | 男 | 102 |
| 4 | 孙尚香 | 女 | 103 |
+-------------+---------------+--------------+--------------+
insert into student values('5','安琪拉','女','104');
0: jdbc:hive2://hadoop102:10000/> insert into student values('5','安琪拉','女','104');
Error: Error while compiling statement: FAILED: SemanticException No valid privileges
User reader_cmd does not have privileges for QUERY
The required privileges: Server=server1->Db=default->Table=student->action=insert->grantOption=false; (state=42000,code=40000)
# (3)使用writer_cmd登录HiveServer2,查询gmall库下的任意一张表
kinit writer_cmd/[email protected]
beeline -u "jdbc:hive2://hadoop102:10000/;principal=hive/[email protected]"
insert into student values('5','你好','女','104');
select * from student;
0: jdbc:hive2://hadoop102:10000/> select * from student;
Error: Error while compiling statement: FAILED: SemanticException No valid privileges
User writer_cmd does not have privileges for QUERY
The required privileges: Server=server1->Db=default->Table=student->Column=id->action=select->grantOption=false; (state=42000,code=40000)
上面创建的用户类似于下面,这里只是命令行能用,如果现在HUE上面使用,用hive用户直接创建用户和对应的linux密码就行了,因为上面配置了权限和组,所以就不用配置就直接创建用户就可以用了。
useradd reader_cmd
passwd reader_cmd
useradd writer_cmd
passwd writer_cmd

版权归原作者 顶尖高手养成计划 所有, 如有侵权,请联系我们删除。