
HDFS的Shell命令
Hadoop提供了文件系统的shell命令使用格式如下: hadoop fs 或者 hdfs dfs
-ls 格式: hadoop fs -ls URI
作用:类似于Linux的ls命令,显示文件列表
应用:hadoop fs -ls / #显示文件列表 hadoop fs –ls -R / #递归显示文件列表
mkdir命令 格式 : hadoop fs –mkdir [-p]
作用 : 以中的URI作为参数,创建目录。使用-p参数可以递归创建目录
应用: hadoop fs -mkdir /dir1 hadoop fs -mkdir -p /aaa/bbb/ccc
mv命令 格式 : hadoop fs -mv
作用: 将hdfs上的文件从原路径src移动到目标路径dst,该命令不能夸文件系统
应用: hadoop fs -mv /dir1/1.txt /dir2
rm命令 格式: hadoop fs -rm [-r] [-skipTrash] URI [URI 。。。]
作用: 删除参数指定的文件和目录,参数可以有多个,删除目录需要加-r参数 如果指定-skipTrash选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件; 否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
应用: hadoop fs -rm /initial-setup-ks.cfg #删除文件 hadoop fs -rm -r /dir2 #删除目录
cp命令 格式: hadoop fs -cp
作用: 将文件拷贝到目标路径中
应用: hadoop fs -cp /dir1/1.txt /dir2
cat命令 格式: hadoop fs -cat
作用: 将参数所指示的文件内容输出到控制台
应用: hadoop fs -cat /dir1/1.txt
put命令 格式 : hadoop fs -put ...
作用 : 将单个的源文件或者多个源文件srcs从本地文件系统上传到目标文件系统中。
应用: hadoop fs -put /root/1.txt /dir1 #上传文件 hadoop fs –put /root/dir2 / #上传目录
get命令 格式 : hadoop fs -get
作用: 将HDFS文件拷贝到本地文件系统。
应用: hadoop fs -get /initial-setup-ks.cfg /opt
Apache Hive
分布式SQL计算Hive入门主要涵盖Hive的基本概念、架构、操作以及其在大数据处理中的应用。
一、Hive概述
Hive是一个基于Hadoop的数据仓库系统,它提供了类似于SQL的查询语言HiveQL,可以将结构化数据存储在Hadoop分布式文件系统中,并通过MapReduce进行过处理。Hive的目标是使数据分析师和其他人员能够使用SQL语言来查询大规模的数据集,而无需编写MapReduce程序。Hive提供了一个高层次的抽象层,使得用户可以使用类似于SQL的查询语言来查询和分析数据。
二、Hive基础架构
Hive的基础架构主要包括元数据存储、Driver驱动程序和用户接口。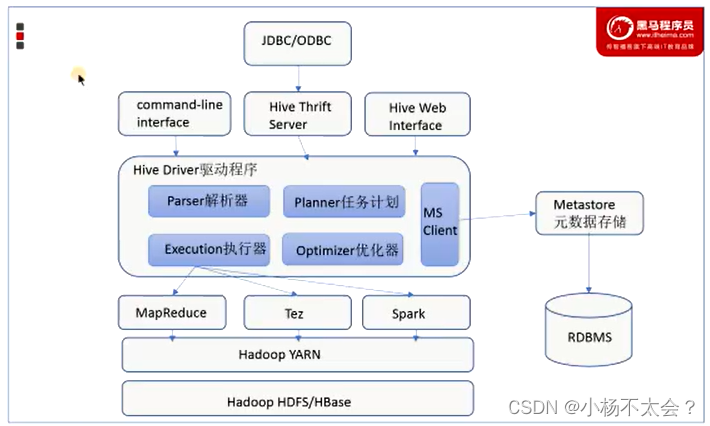
元数据存储:通常存储在关系数据库如MySQL/Derby中。Hive中的元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。Hive提供了Metastore服务进程来提供元数据管理功能。
Driver驱动程序:包括语法解析器、计划编译器、优化器、执行器,完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由执行引擎调用执行。
用户接口:包括CLI、JDBC/ODBC、WebGUI等,提供多种方式来访问和操作Hive。
三、Hive操作
Hive的操作主要包括创建表、查询数据、数据导入导出等。例如,创建表可以使用create table查询数据则可以使用类似于SQL的HiveQL语句。此外,Hive还提供了内置函数和UDF(用户定义函数)来扩展其功能。

四、Hive的应用场景
Hive的优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。因此,Hive常用于数据分析、数据挖掘等对实时性要求不高的场合。通过Hive,用户可以轻松地对大规模数据集进行复杂的查询和分析操作,从而提取有价值的信息。
通过本次学习,Hive作为分布式SQL计算工具,为大数据处理和分析提供了强大的支持。
版权归原作者 小杨不太会? 所有, 如有侵权,请联系我们删除。