

本文章主要分享单行函数UDF(一进一出)
现在前面大体总结,后边文章详细介绍
自定义函数分为临时函数与永久函数
需要创建Java项目,导入hive依赖
创建类继承 GenericUDF(自定义函数的抽象类)(实现函数)
打成jar包,传到服务器上
将jar包添加到hive的class path上临时生效
通过hive创建函数与Java类建立连接
hive底层运行:
sql语句---》抽象语法树---》形成逻辑执行计划---》翻译成物理执行计划(可以是mapreduce / spark )
编码:
(一) 创建Java-maven项目:
(1)导入hive的maven依赖:
<groupId>org.example</groupId>
<artifactId>hive-UDTF</artifactId>
<version>1.0-SNAPSHOT</version>
(2)创建Java类:
创建的Java类是继承自GenericUDF类(抽象类)
继承之后会实现3个函数(initialize,evaluate,getDisplayString)
(3)实现Java类中的方法:
1.initialize
这是一个初始化方法,在该函数的调用之前必须要调用一次
一般进行数据检验
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
传入参数为:ObjectInspector[] objectInspectors
ObjectInspector[] 是一个存储源信息的ObjectInspector
处理后返回一个ObjectInspector 给下一个ObjectInspector[]进行处理
//1先取上一步的源信息
// 先判断参数的个数
if(objectInspectors.length!=1)
{
throw new UDFArgumentLengthException("请输入1个参数");
}
ObjectInspector objectInspector=objectInspectors[0];
// 判断参数是否是基本数据类型
if (objectInspectors[0].getCategory()!=ObjectInspector.Category.PRIMITIVE)
{
throw new UDFArgumentLengthException("请输入一个基本数据类型");
}
// 假设是string类型(基础数据类型在) 强制类型转化进行判断
//非指定类型就进行抛异常
PrimitiveObjectInspector primitiveObjectInspector = (PrimitiveObjectInspector) objectInspector;
if (primitiveObjectInspector.getPrimitiveCategory()!=PrimitiveObjectInspector.PrimitiveCategory.STRING)
{
throw new UDFArgumentException("只接受string类型");
}
//返回的时候 需要找到基本数据类型的工厂 让后getInt类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
2.evaluate方法(要实现函数的核心逻辑)
每行数据调用一次
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
传入参数:DeferredObject[] deferredObjects
DeferredObject[]是一个懒加载的值(根据数组下标获取的值不是真值)需要get一下获得真值
//DeferredObject[] deferredObjects、
//获取的是每行数据中的指定列的参数(不用进行校验(init已完成校验否则不会调用此函数))
//DeferredObject[]是一个懒加载的值 需要get一下获得真值
DeferredObject arg=deferredObjects[0];
Object o = arg.get();
// o可能是空值null
if(o==null)
{
return 0;
}
return o.toString().length();
构造hive函数:
(一)临时函数:
将Java编码成功后的代码进行打包(package)
打包后上传服务器
将jar包添加到hive的classpath,临时生效(临时函数)
add jar /opt/module/hive/datas/myudf.jar;
创建临时函数并于Java class相联:
create temporary function my_len
as "com.atguigu.hive.udf.MyUDF";
注意:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
(二)创建永久函数:
创建永久函数前需要先将jar包上传到hdfs中,在hive语句中using该路径
create function my_len2
as "com.atguigu.hive.udf.MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
函数的使用:
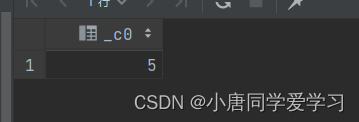
select my_len2("sdsrf");
版权归原作者 小唐同学爱学习 所有, 如有侵权,请联系我们删除。