
合集(不是我做的):https://ks.wjx.top/vm/rXgKD38.aspx#
大数据单元1在线测试:https://ks.wjx.top/vm/tv3XfFg.aspx#
大数据单元2在线测试:https://ks.wjx.top/vm/QfXBgWP.aspx#
大数据单元3在线测试-1:https://ks.wjx.top/vm/PeLX5WR.aspx#
大数据单元3在线测试-2:https://ks.wjx.top/vm/OlPYPbC.aspx#
大数据单元4在线测试-1:https://ks.wjx.top/vm/wFdcv3v.aspx#
大数据单元5在线测试-1:https://ks.wjx.top/vm/OtZyYPb.aspx#
大数据单元5在线测试-2:https://ks.wjx.top/vm/PeRLctH.aspx#
大数据单元6在线测试-1:https://ks.wjx.top/vm/Yd9JQ8l.aspx#
大数据单元7在线测试:https://ks.wjx.top/vm/rJKV92n.aspx#
大数据单元8在线测试:https://ks.wjx.top/vm/wvfvdLq.aspx#
手动目录(因为csdn自带的目录树无法展示到四级)
第1章 大数据概论
1. 特征
- 容量(Volume)
- 种类(Variety)
- 速度(Velocity)
- 价值(Value)
- 可变性(Variability)
- 真实性(Veracity)
- 复杂性(Complexity)
2. 结构
- 结构化
- 半结构化
- 非结构化数据
3. 大数据的处理流程
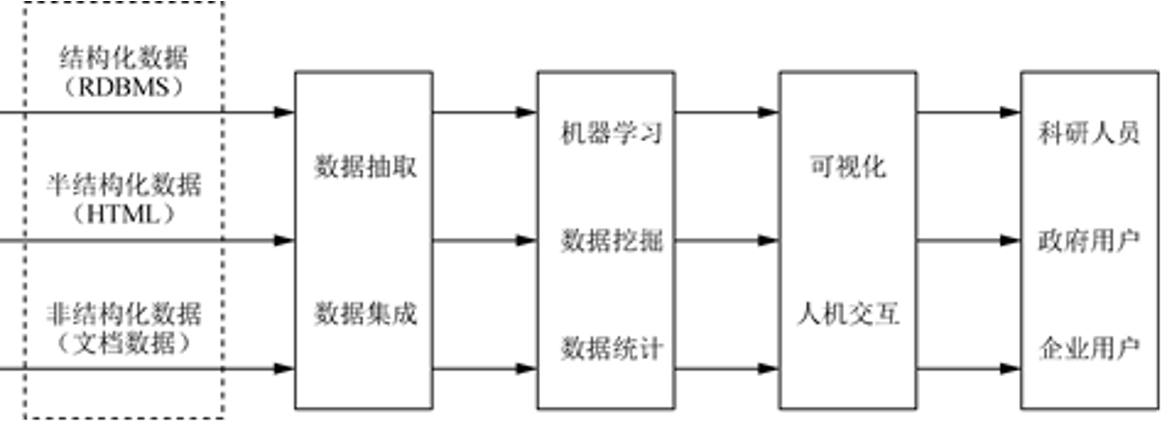
大数据的整体技术:
数据采集、数据存取、基础架构、数据处理、统计分析、数据挖掘、模型预测和结果呈现等。
第2章 Hadoop概论
1. Hadoop特点
- 高可靠性
- 高扩展性
- 高效性
- 高容错性
- 低成本
2. 启动Hadoop集群
start-all.sh
ips
HDFS的守护进程:NameNode, DataNode及Secondary-NameNode
MapReduce的守护进程:JobTracker和TaskTracker
第3章 HDFS分布式文件系统
1. HDFS体系结构
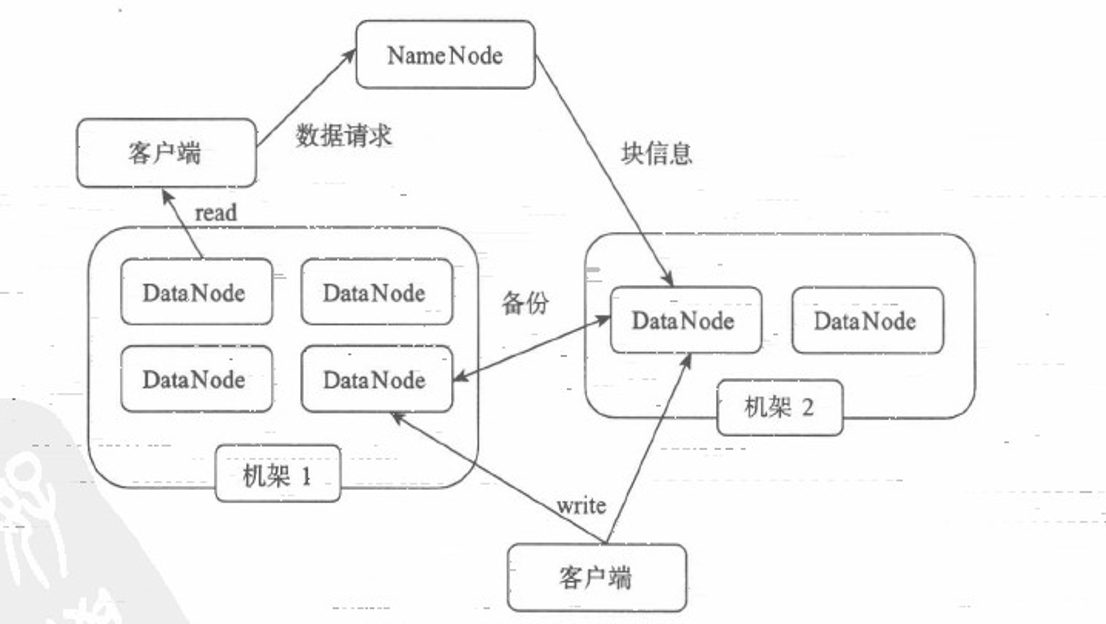
HDFS:主/从(Mater/Slave)体系结构
- 打开浏览器
- 输入http://master:50070
- Utilities -> browse the file system
- 输入路径
- 查看文件
1.1 NameNode
NameNode 管理者
说明信息-元数据Meta-data
HDFS中的文件也是被分成64M(128M)一块的数据块存储的。
副本策略: HDFS默认的副本系数是3。
1.2 Secondary namenode
1.3 DataNode
1.4 Client
1.5 文件写入
- NameNode
- DataNode
- Client
1.6 文件读取
- NameNode
- DataNode
- Client
ResourceManager NameNode
NodeManager DataNode
2. HDFS 常用命令
1. 创建目录
hadoop fs -mkdir <paths>
创建单个目录:
hadoop fs -mkdir /home/myfile/dir1
创建多个目录:
hadoop fs -mkdir /home/myfile/dir1 /home/myfile/dir2
2. 查看目录
hadoop fs -ls <paths>
示例:
hadoop fs -ls /home/myfile/
查看所有子目录
hadoop fs -ls –R <path>
(区分大小写)
示例:
hadoop fs -ls –R /home/myfile/
3. 上传文件
将一个或多个文件从本地系统复制到Hadoop文件系统。
hadoop fs -put <local_files> ... <hdfs_path>
示例:
hadoop fs -put Desktop/test.sh /home/myfile/dir1/
4. 下载文件
将文件从HDFS下载到本地文件系统。
hadoop fs -get <hdfs_paths> <local_path>
示例:
hadoop fs -get /home/myfile/test.sh Downloads/
5. 查看文件
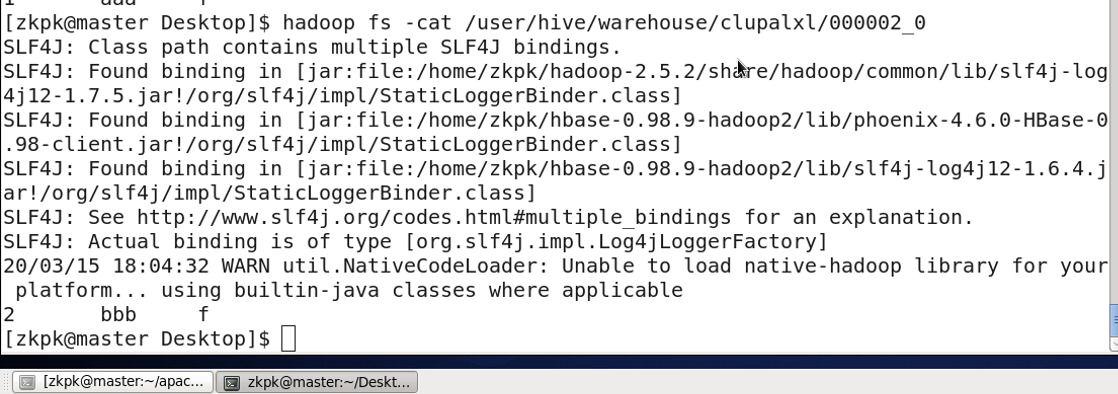
hadoop fs -cat <paths>
示例:
hadoop fs -cat /home/myfile/test.sh
6. 复制文件
hadoop fs -cp <source_path> ... <destination_path>
示例:
hadoop fs -cp /home/myfile/test.sh /home/myfile/dir
7. 移动文件
hadoop fs -mv <source_path> <destination_path>
示例:
hadoop fs -mv /home/myfile/test.sh /home/myfile/dir
8. 删除文件
删除指令有两个选项,
-rm
和
-rm -r
hadoop fs -rm <path>
示例:
hadoop fs -rm /home/myfile/test.sh
上述命令只会删除给定目录下的文件,如果要删除一个包含文件的目录,,需要使用参数-r。
用法:
hadoop fs -rm -r <path>
示例:
hadoop fs -rm -r /home/myfile/dir
9. 查看文件尾部
hadoop fs -tail <path>
示例:
hadoop fs -tail /home/myfile/test.sh
10. 显示文件总长度
hadoop fs -du <path>
示例:
hadoop fs -du /home/myfile/test.sh
11. 统计文件数
hadoop fs -count <path>
示例:
hadoop fs -count /home/myfile
12. 统计文件的详细信息
hadoop fs -df <path>
示例:
hadoop fs -df /home/myfile
13. 合并文件
从HDFS拷贝多个文件、合并排序为一个文件
hadoop fs –getmerge <src> <localdst>
示例:
hadoop fs –getmerge /user/hduser0011/test /home/myfile/dir
14. 屏幕显示内容存储到HDFS文件
echo abc
echo abc | hadoop fs –put - <path>
echo abc | hadoop fs –put /home/myfile/test.txt
第4章 MapReduce的工作机制
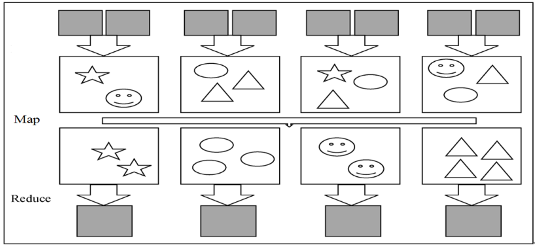
1. MapReduce功能
MapReduce实现了两个功能:
Map:把一个函数应用于集合中的所有成员
Reduce:对多个进程或者独立系统并行执行
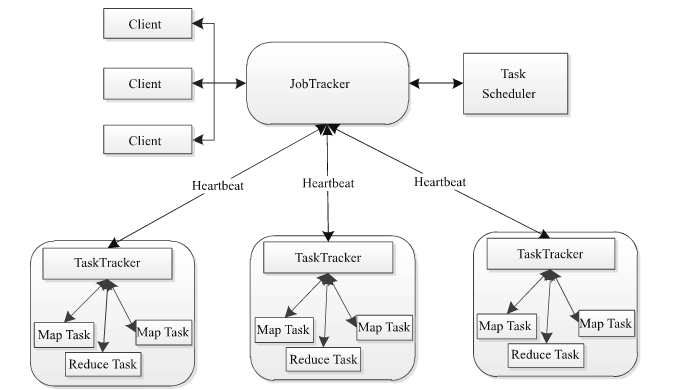
2. MapReduce的架构
Job(作业),Tasks(任务)
主从结构 master slave
Namenode Datanode
ResourceManager NodeManager
JobTracker(可变) TaskTracker
JobTracker负责
- 接收客户提交的作业,负责作业的分解和状态监控。
- 把任务分给TaskTracker执行
- 监控TaskTracker的执行情况
NodeManager:是执行应用程序的容器,
TaskTracker:从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。
TaskTracker :是JobTracker和Task之间的桥梁, 从JobTracker接收并执行各种命令:运行任务、提交任务、杀死任务等;将本地节点上各个任务的状态通过心跳周期性汇报给JobTracker。
MapReduce架构由4个独立的节点(Node)组成
(1)Client
(2)JobTracker
(3)TaskTracker
(4)HDFS
3. 作业的调度
FIFO 调度器
Fair Scheduler公平调度器
Capacity Scheduler计算能力调度(容量调度)
4. WordCount 流程
输入数据 -> split(分割)-> map -> shuffle(洗牌)-> reduce
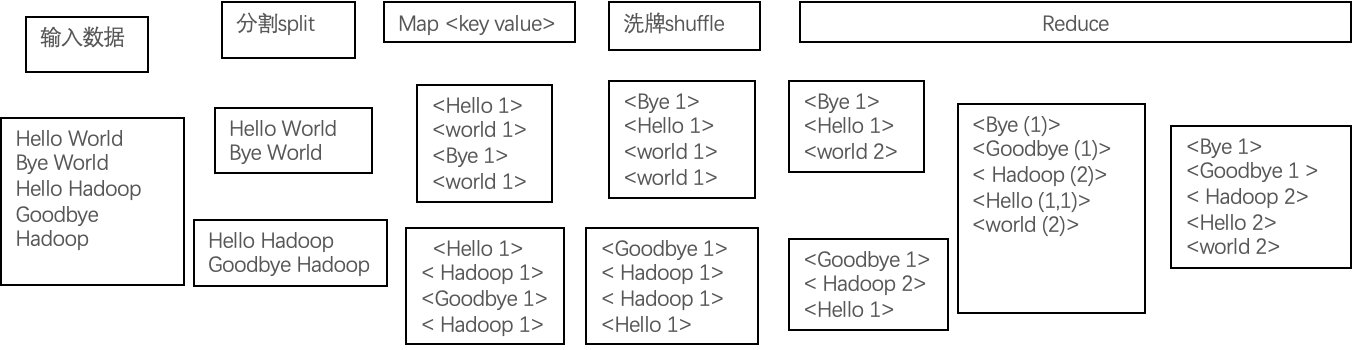
split包含
<文件名,开始位置,长度,位于哪些主机>
等信息
1.输入数据通过
Split
的方式,被分发到各个节点上
2.每个Map任务在一个Split上面进行处理;
3.
Map
任务输出中间数据;
4.在
Shuffle
过程中,节点之间进行数据交换(Shuffle意为洗牌);
5.拥有同样Key值的中间数据即键值对(Key-Value Pair)被送到同样的
Reduce
任务中
6.Reduce执行任务后,输出结果。
第5章 Hive
1. Hive数据模型
元数据(MetaData)又称“数据的数据”或“中介数据”,是用于描述数据各项属性信息的数据例如数据的类型、结构、历史数据信息,数据库、表、视图的信息等Hive的元数据要经常面临读取、修改和更新操作,因此并不适合储存在HDFS中,而是通常储存在关系型数据库中,
- 在 Hive 命令行里看到的是 元数据
- 在 HDFS 上看到的是它的 物理数据
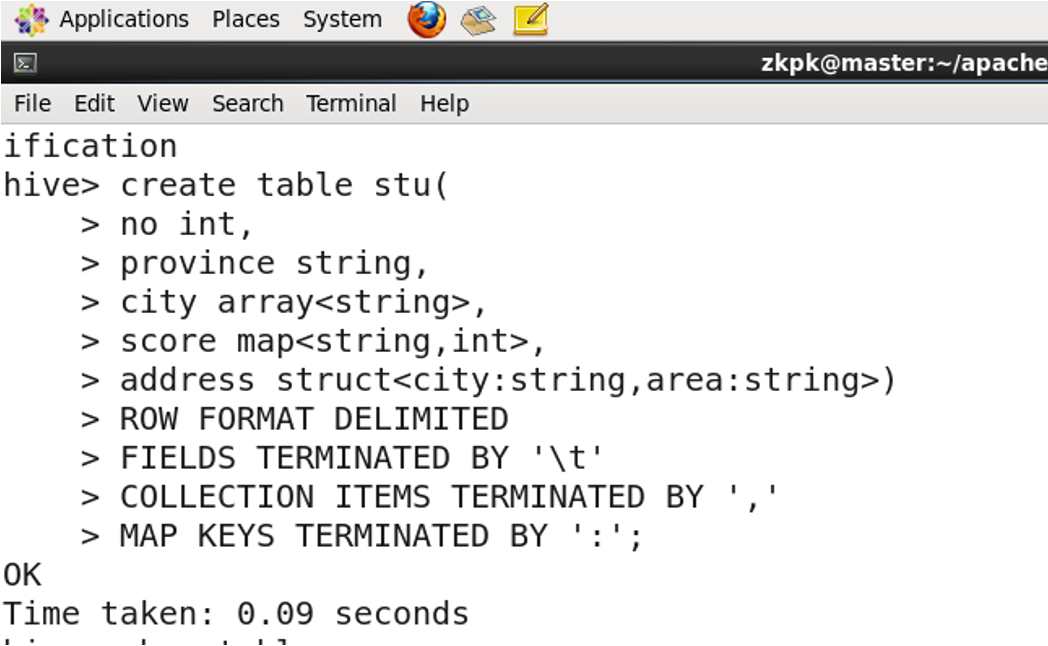
2. 复杂数据类型
- 数组 ARRAY:ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。
- 结构体 STRUCT:STRUCT可以包含不同数据类型的元素。
- 键值对 MAP:MAP包含key->value键值对,
3. Hive基本操作(大题)
3.1 进入 hive
start-all.sh
[zkpk@master ~]$ hive
hive>
3.2 查看hive中的表

Hive命令以 ; 结束
3.3 创建表
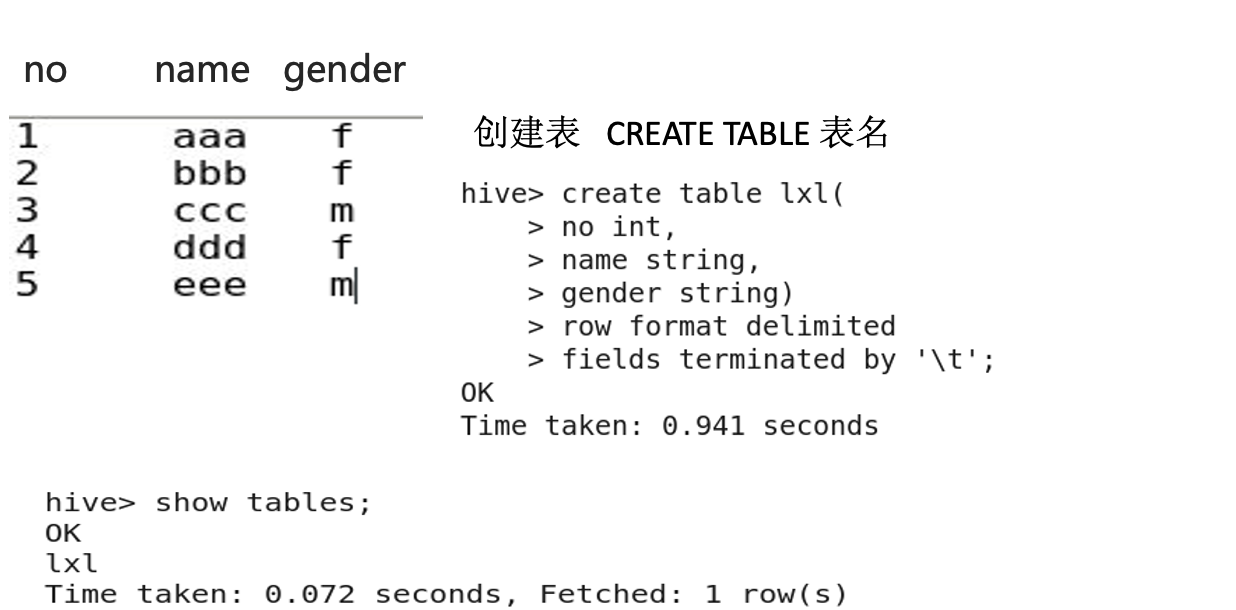
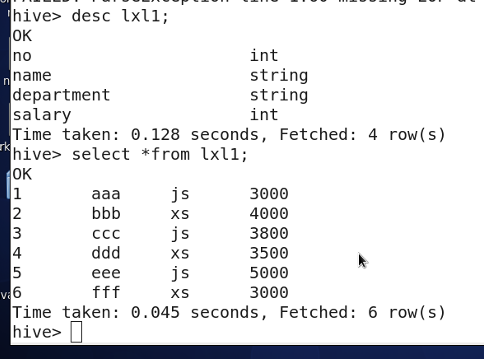
3.4 显示表结构
desc table-name;

3.5 显示表内容
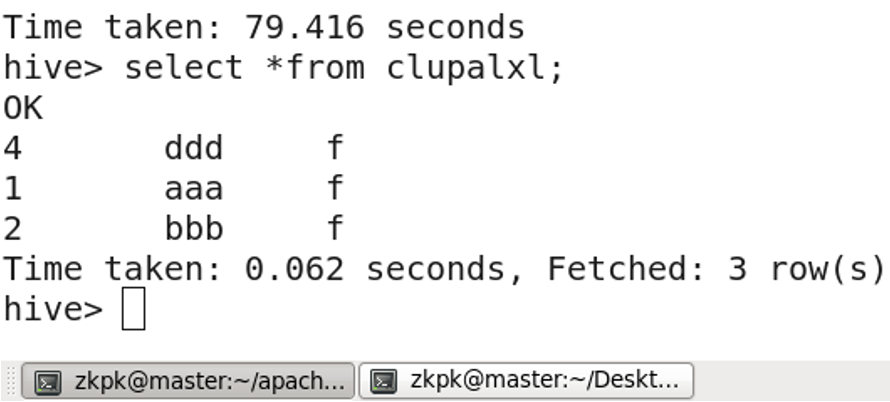
select * from table-name;
3.6 从文件中导入数据
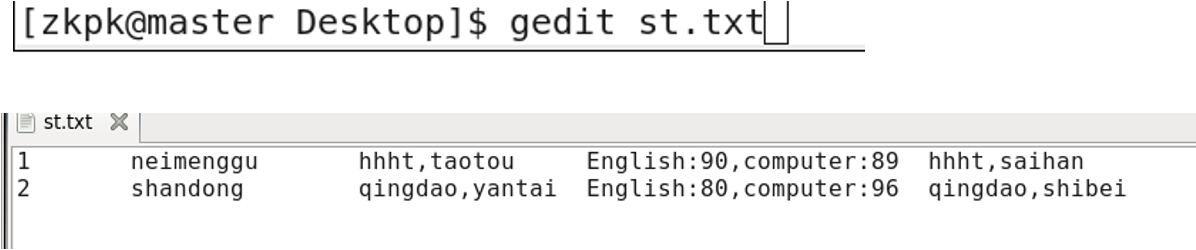
本地机创建文件
l.txt
在文件里添加数据
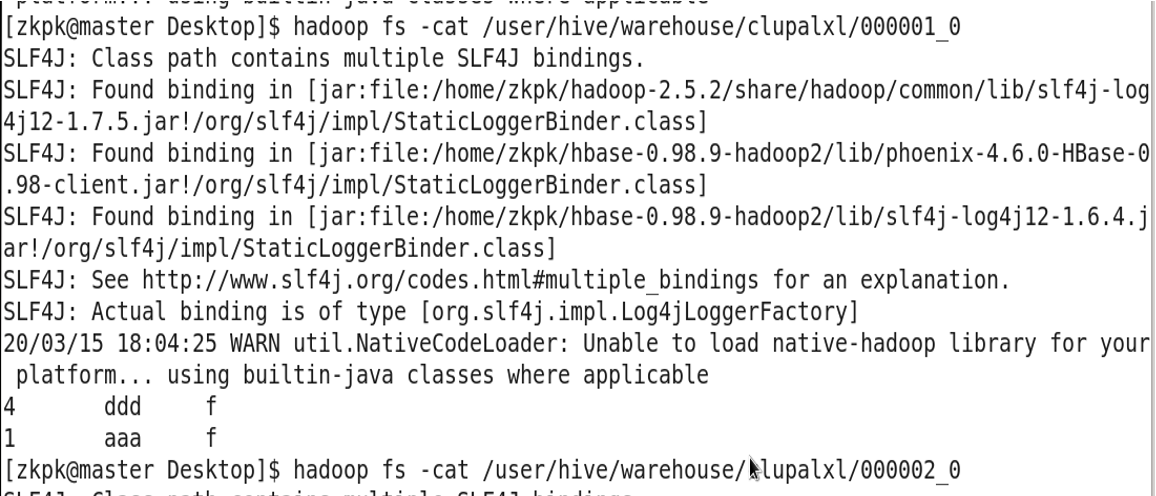
1 aaa f
2 bbb f
3 ccc m
4 ddd f
5 eee m
从文件中导入数据
查看表内容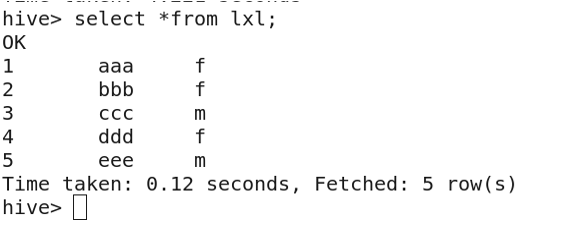
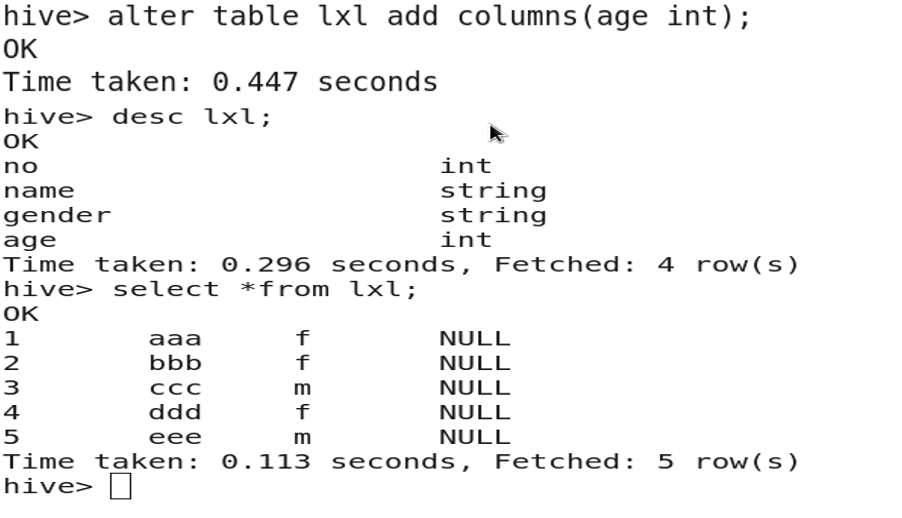
3.7 增加字段
altertable table_name addcolumns(newcolname type);
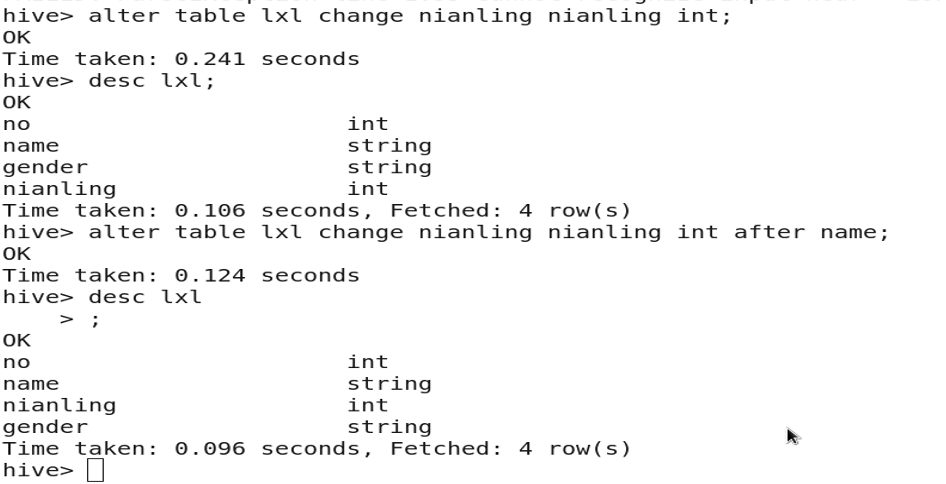
3.8 修改字段名称
altertable table_name change col_name new_col_name type;

3.9 修改字段类型、位置
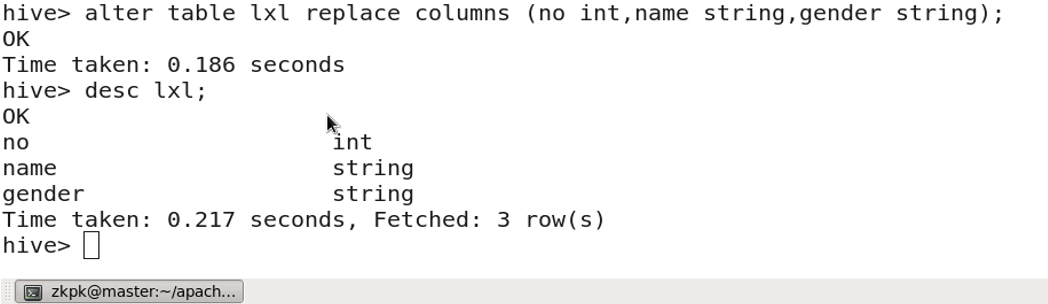
3.10 删除字段
altertable table_name replacecolumns(col1 type,col2 type,col3 type);
(COLUMNS中放保留的字段)
3.11 复制表
createtable new_table asselect*from exists_table;
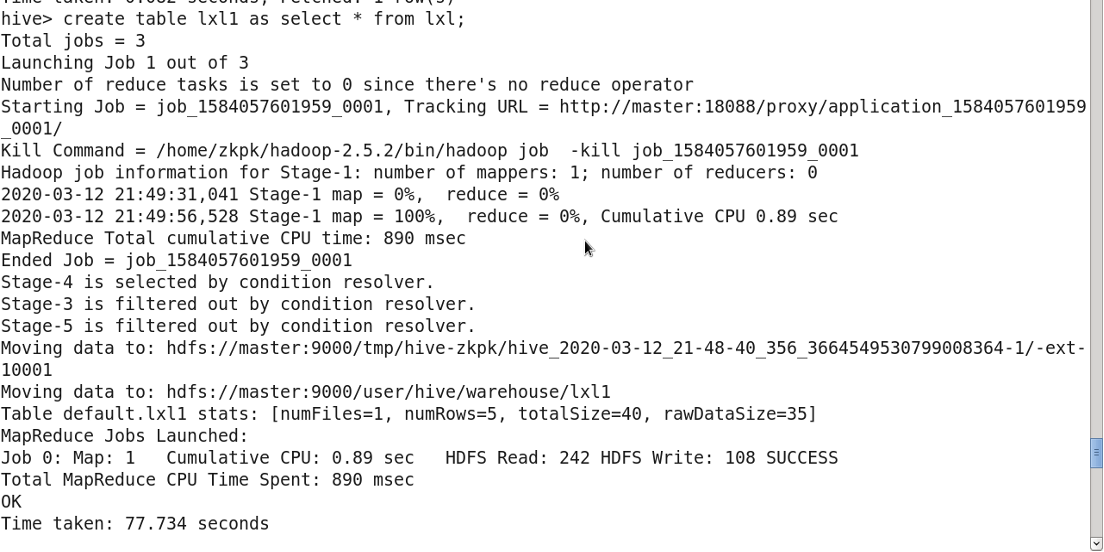
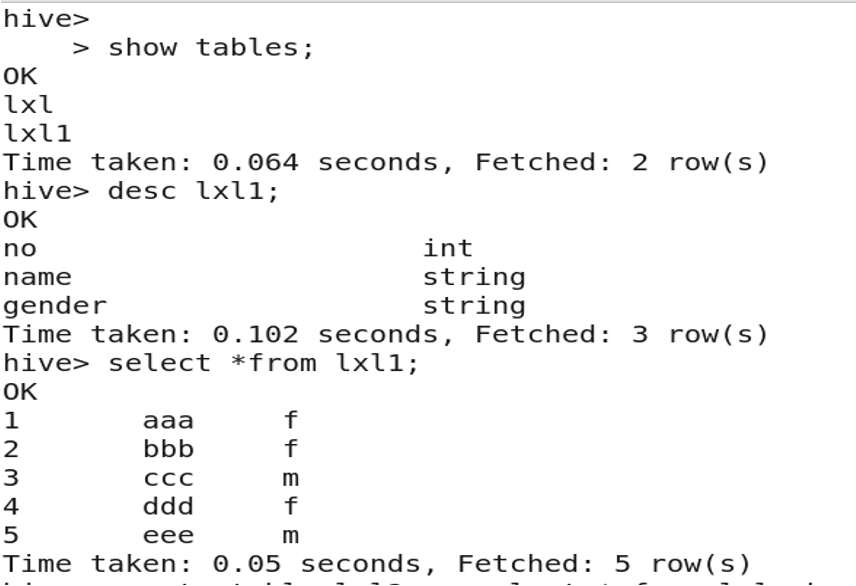
3.12 复制表结构
createtable new_table asselect*from exists_table where1=0;
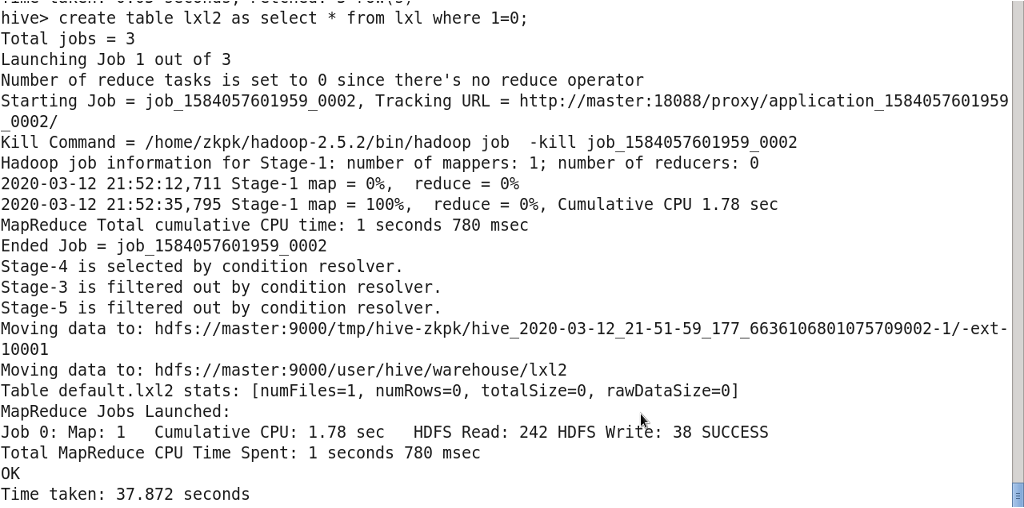
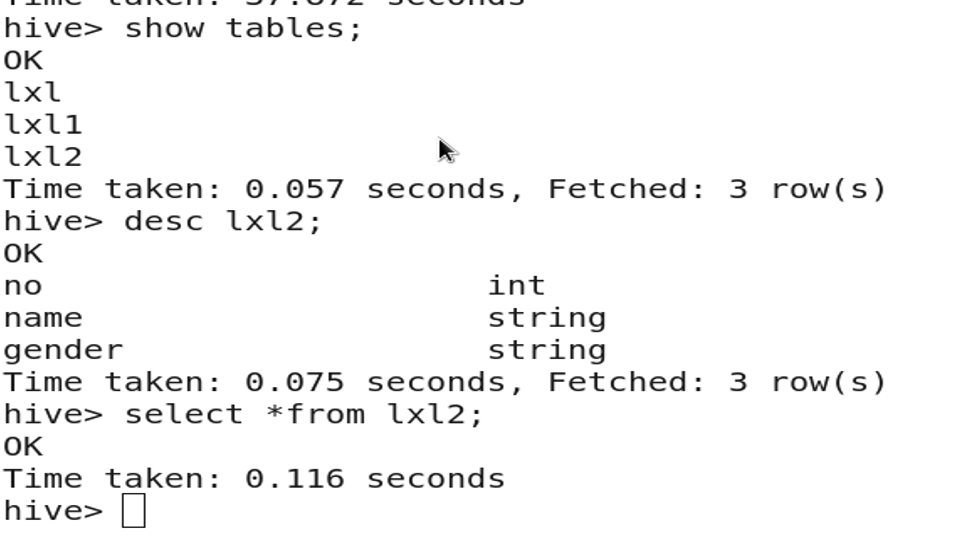
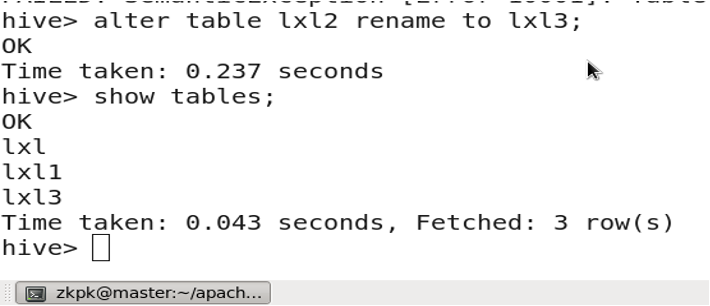
3.13 重命名表
altertable table_name renameto new_table_name;
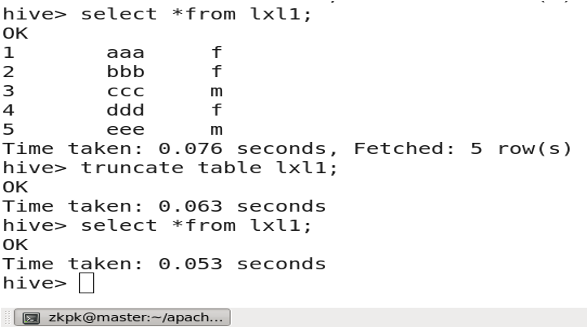
3.14 清空表中数据
truncatetable tableName;
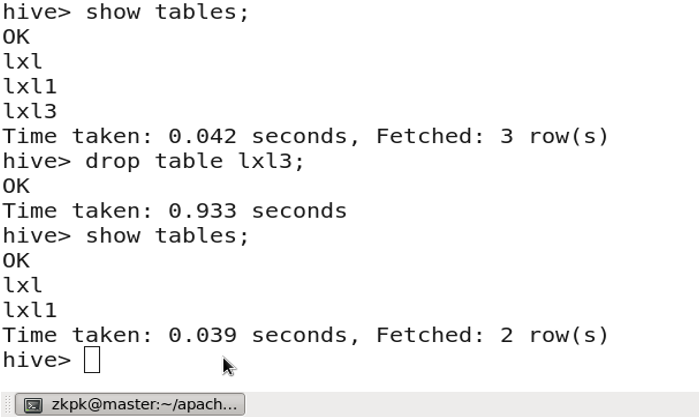
3.15 删除表
droptable 表名;
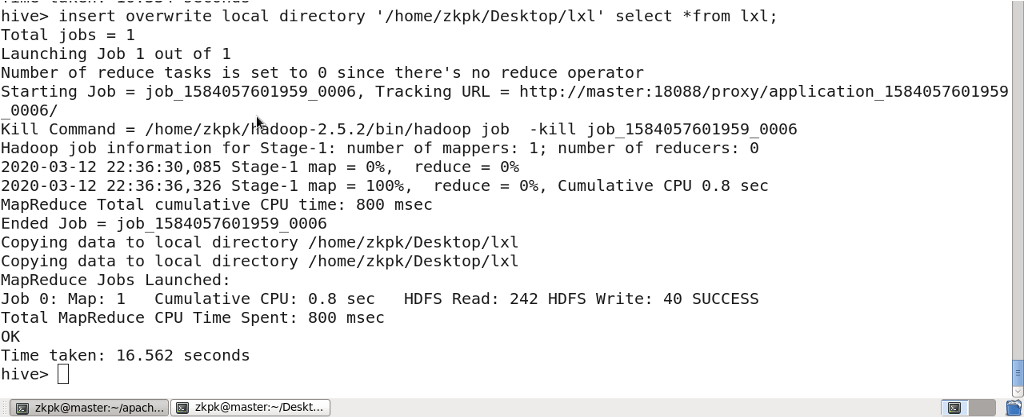
3.16 将hive 表中数据下载到本地

insert overwrite local directory ‘/home/zkpk/目录名’ select*from 表名;
查看下载到本地的数据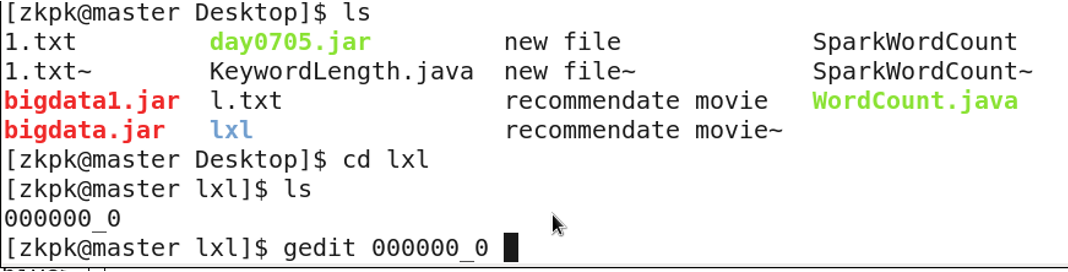
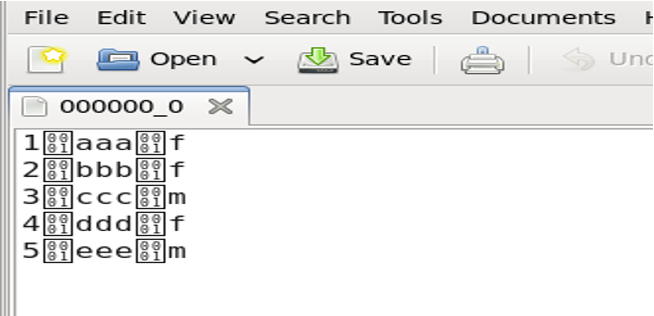
4. 表的存储
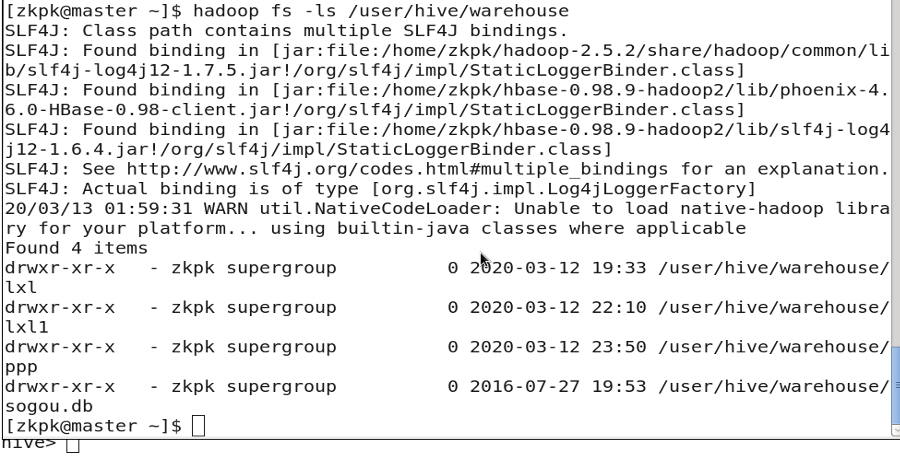
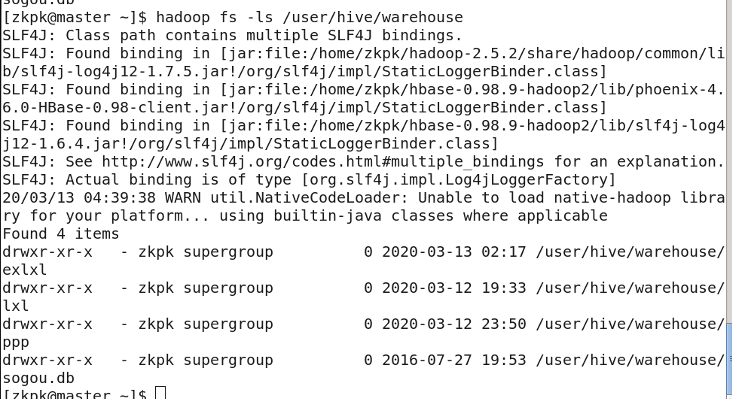
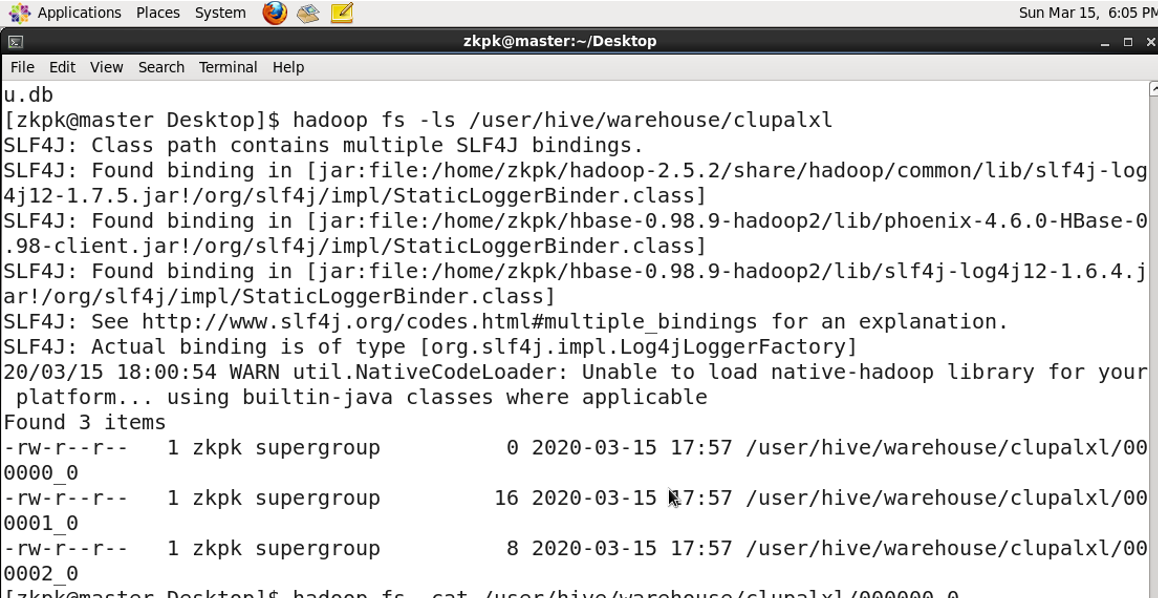
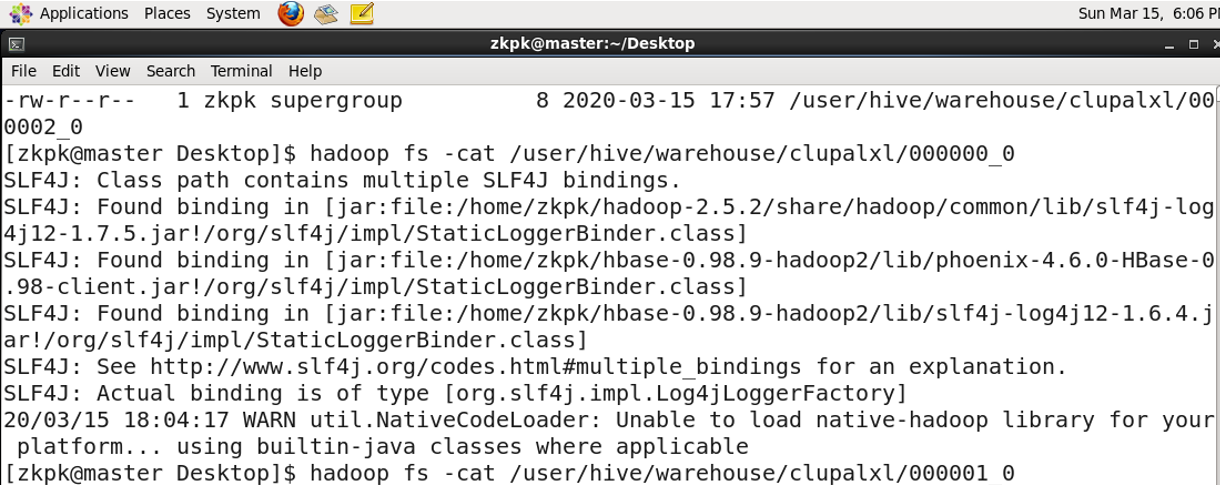
表: 存储在 HDFS:
/user/hive/warehouse

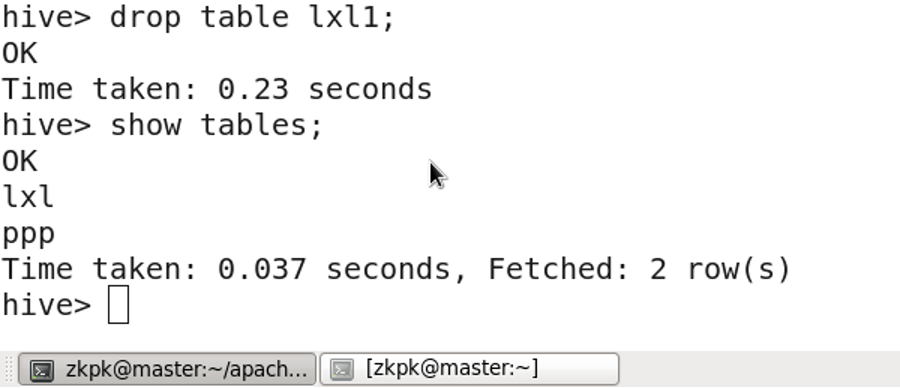

5. 外部表和内部表
表:管理表(内部表,临时表) 删除的时候,元数据、实际表文件全部删除。
外部表:删除的时候,只删除元数据、实际表文件不删除。
创建外部表:
create external table tablename;
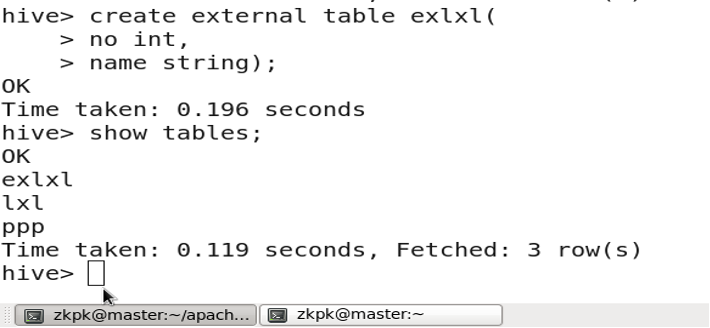

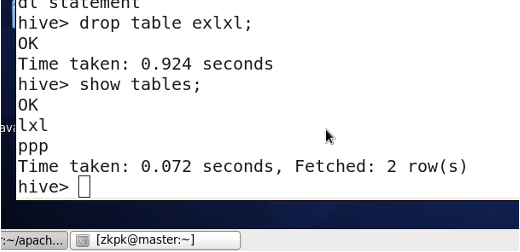
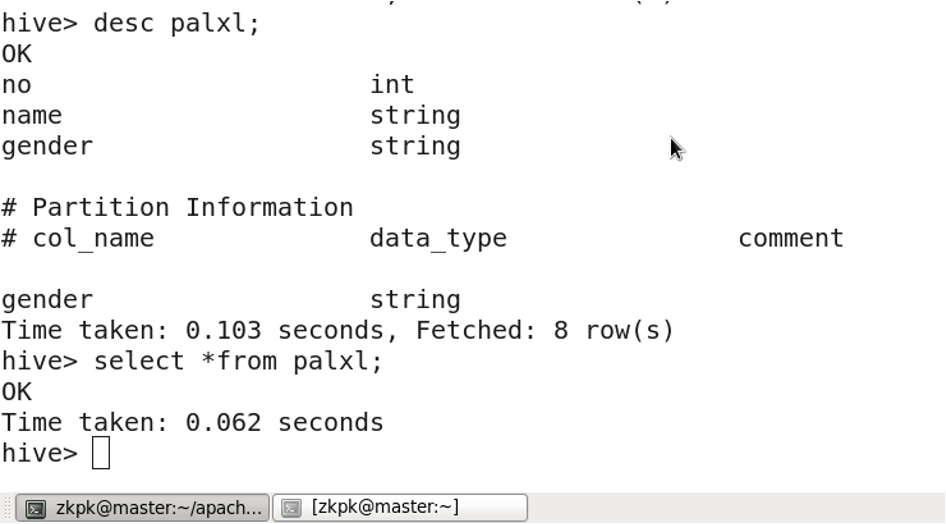
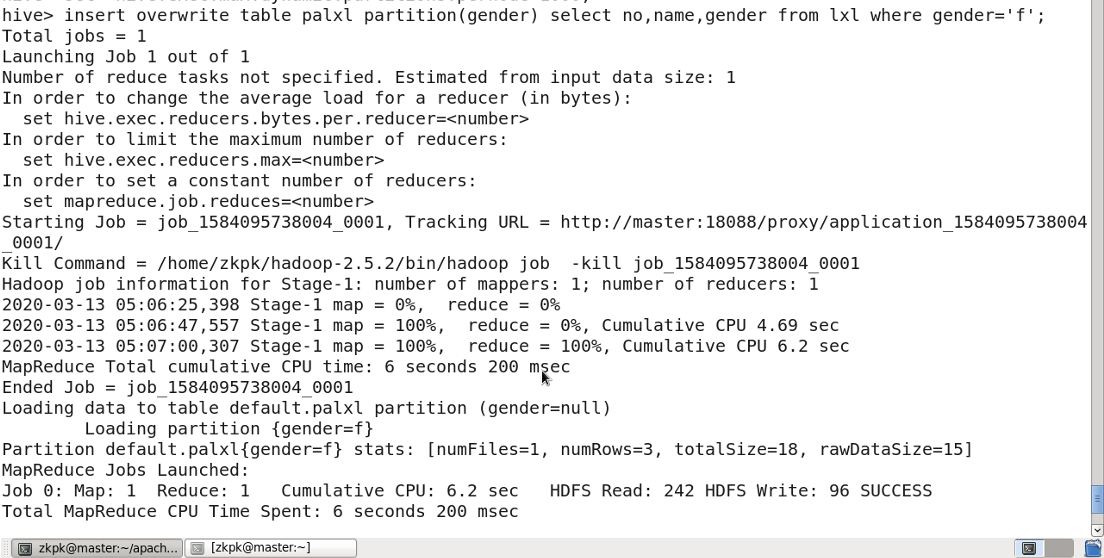
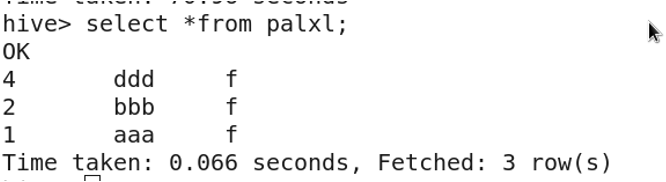
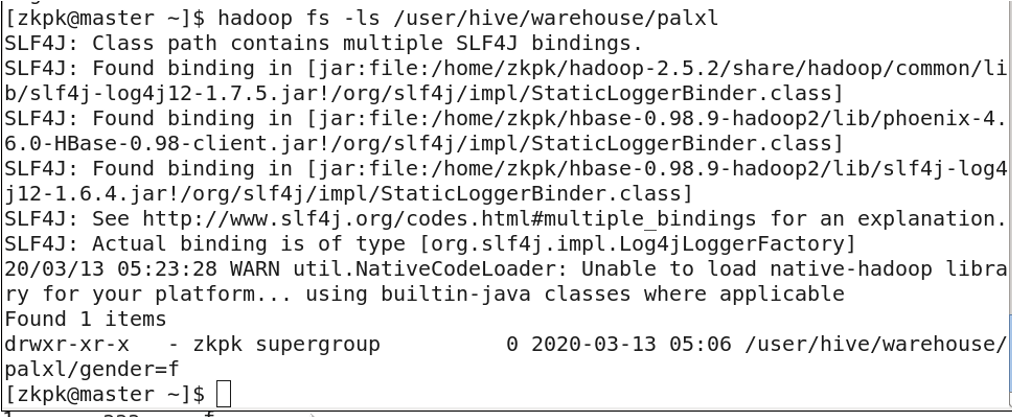
6. 分区表
分区表:将一张表的数据按照分区规则分成多个目录存储。这样可以通过指定分区来提高查询速度。
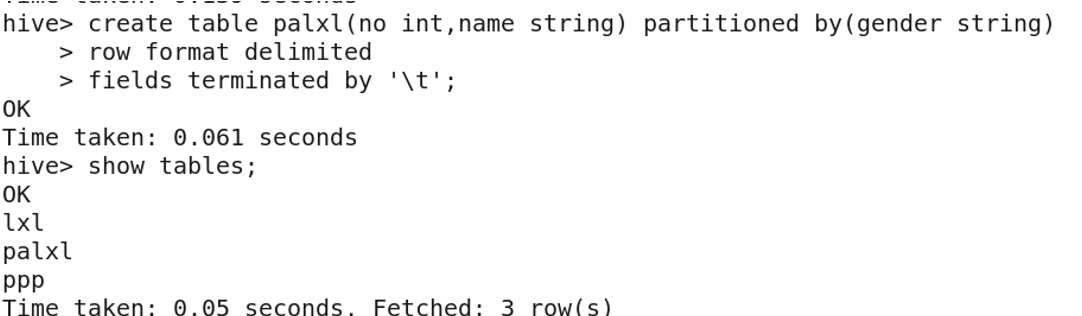

开启动态分区功能
# 开启动态分区功能set hive.exec.dynamic.partition=true;# 所有分区都是动态的(动态分区的模式)set hive.exec.dynamic.partition.mode=nonstrict;# 最大动态分区个数set hive.exec.max.dynamic.partitions.pernode=1000;

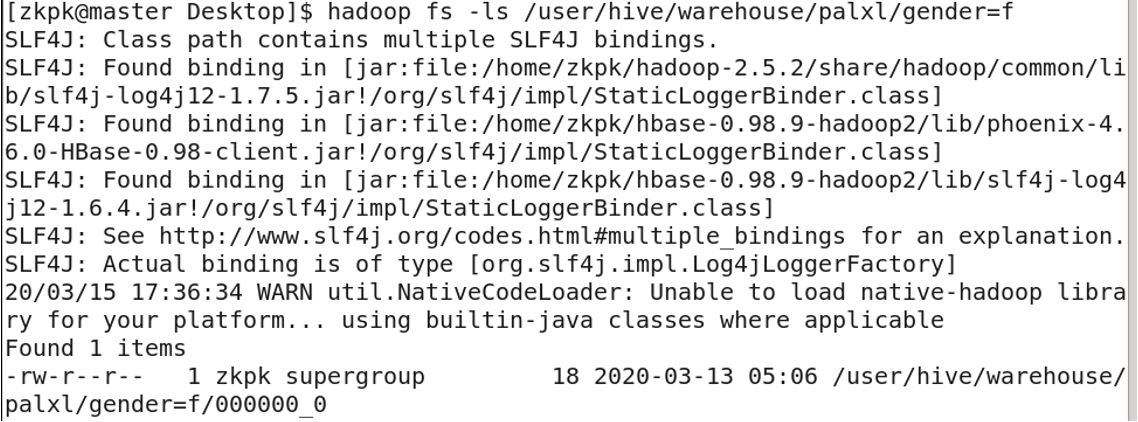
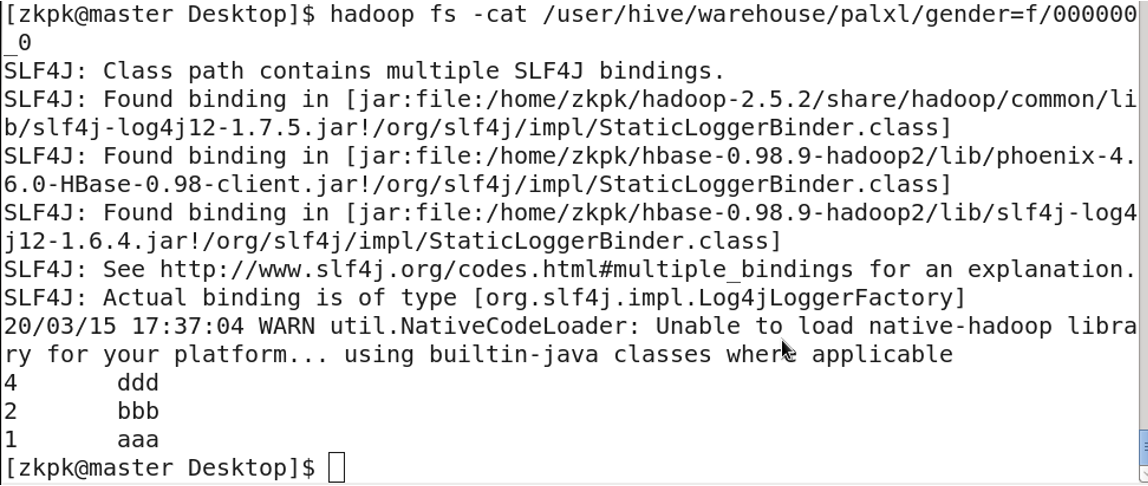
7. 桶表
对于每一个表(table)或者分区,Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分
创建桶表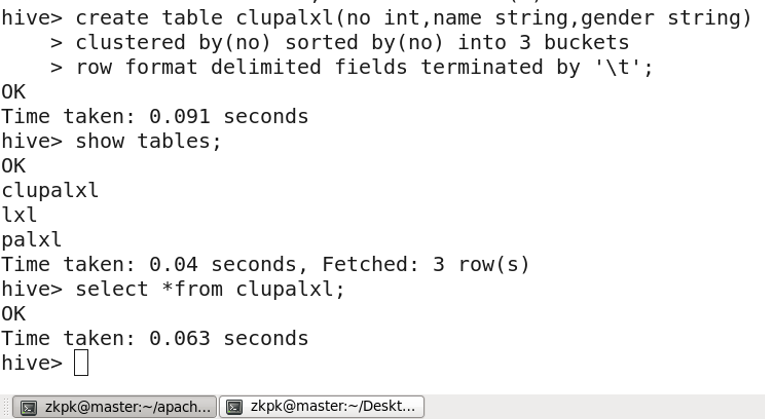
向桶表输入数据


8. 复杂数据类型
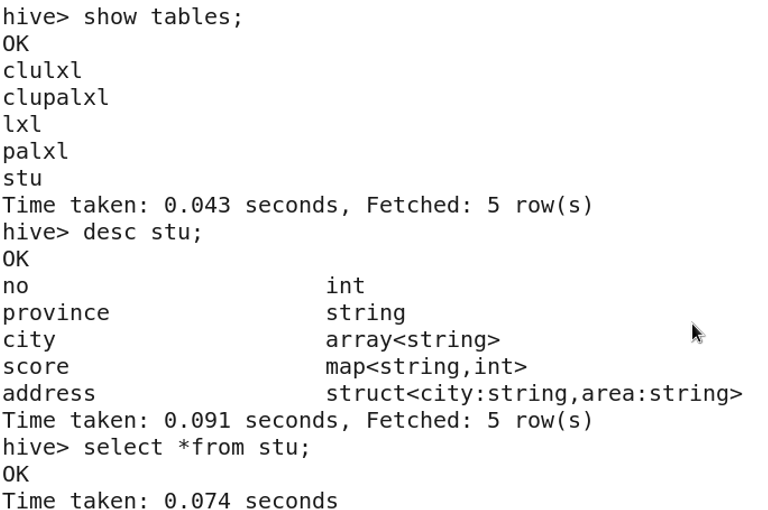
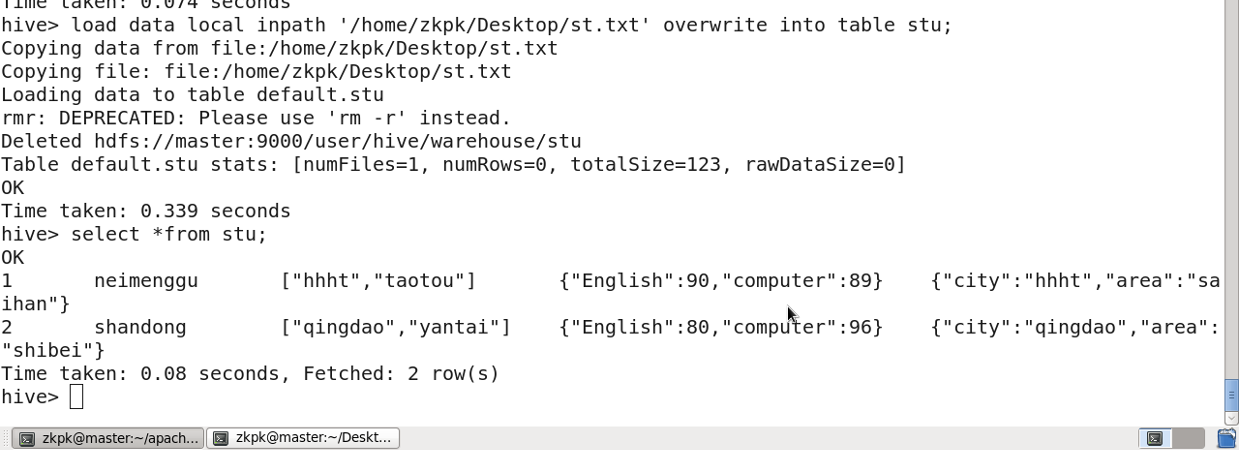
9. 其他语句
9.1 创建数据库
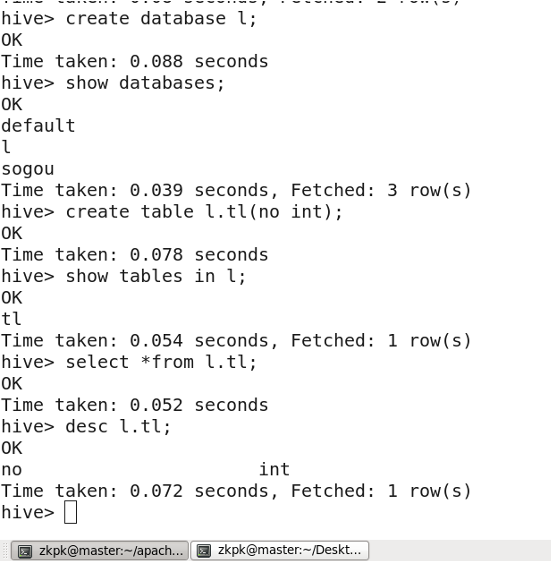
9.2 删除数据库
Hive不允许用户删除一个包含有表的数据库
DROPTABLE 数据库名.表名;
DROPDATABASE 数据库名;
删除命令的最后面加上关键字
CASCADE
,这样可以使Hive自行先删除数据库中的表
DROPDATABASE 数据库名 CASCADE;
10. 视图
略
11. 常用HQL命令
1.* 代表查询所有字段
select*from lxl;
- 查询指定字段
select name,gender from lxl;
- limit 限制查询条数
select*from lxl limit3;
- where 代表限定条件
select*from lxl where gender=‘f’;
- where 后面加多个条件
select*from lxl where gender=‘f’ andno=1;
查询条件是字符、字符串的加上 ‘’ “” 均可
- distinct :去重
selectdistinct age from lxlage;(age相同的只显示一个)
- group by 分组
做一些运算,通常与聚合函数配合使用,聚合函数还有max(),min(),count()

8. order by
对数据排序,默认是按升序,如果要按降序进行在最后加一个desc
- like主要用于模糊匹配
select*from lxl where name like'%a%';
查找name中含有a 这个字符的数据
in关键字的用法
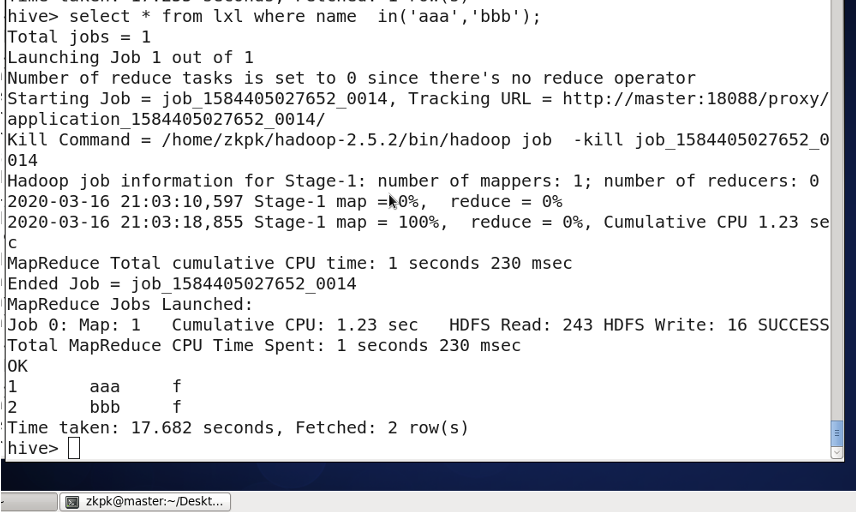
10. between and的用法
select*from lxl wherenobetween2and4;
- join 按照条件把数据连接起来
select*from lxl join lxlage on lxl.no=lxlage.no;
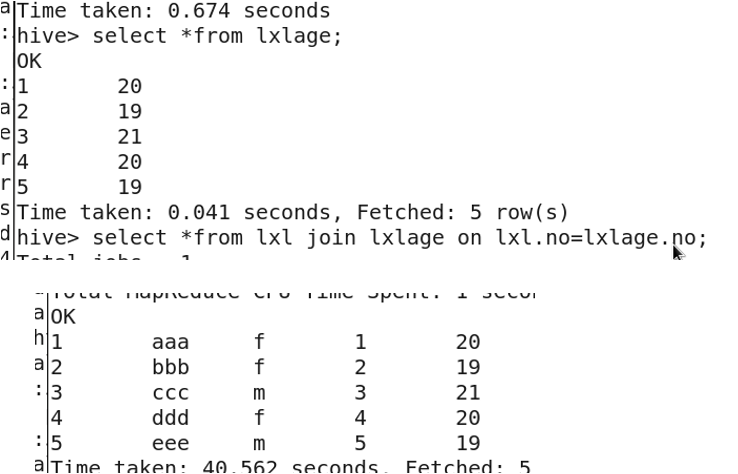
select*from lxl leftjoin lxlage on lxl.no=lxlage.no;
左右表有不一致数据,左表全部显示
select*from lxl rightjoin lxlage on lxl.no=lxlage.no;
左右表有不一致数据,右表全部显示
- union all 把数据合起来,条件是字段名与类型必须相同
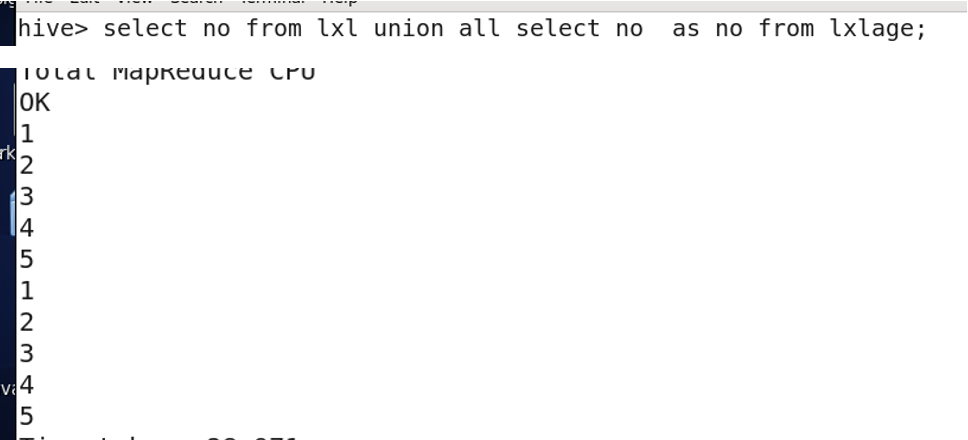
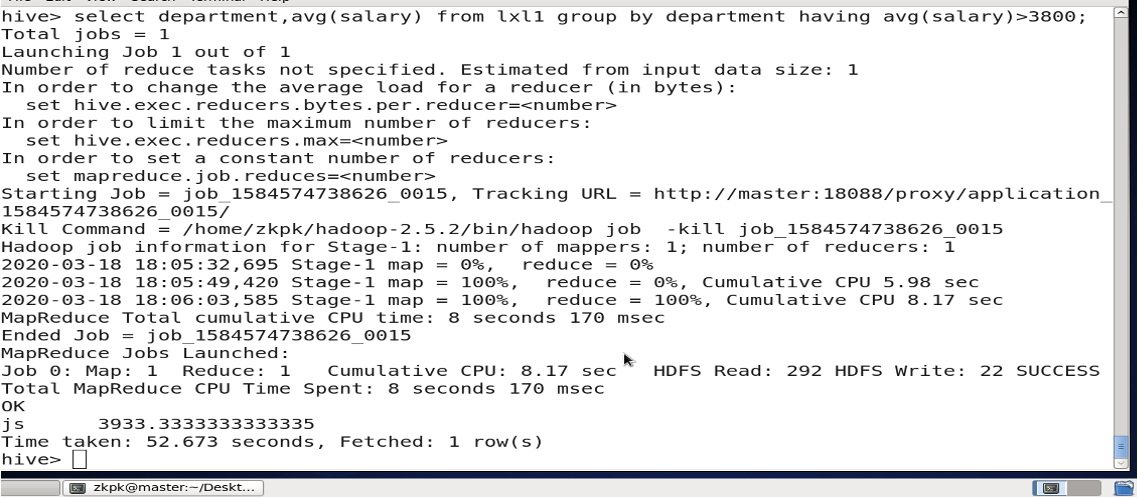
- having
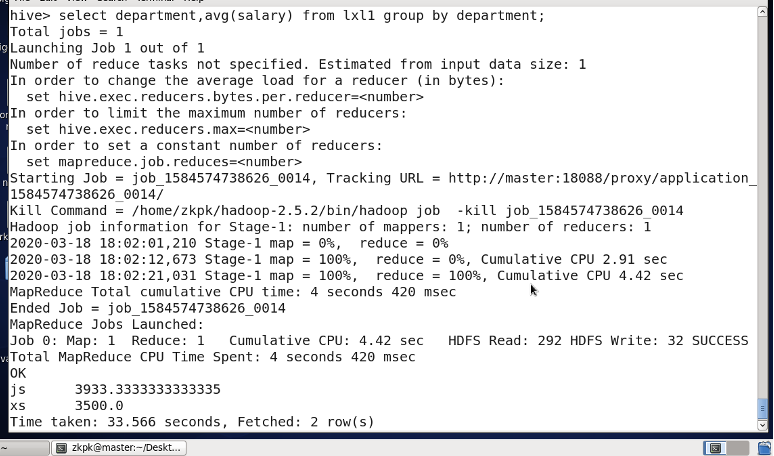
统计平均工资3800以上的部门。
where 关键字无法与聚合函数一起使用, having只用于group by分组统计语句。

11. 关闭hive
quit;
第6章 ZooKeeper分布式协调系统
1. 简介
ZooKeeper是一个分布式应用程序协调服务,主要用于解决分布式集群中应用系统的一致性问题。
ZooKeeper = 文件系统+通知机制。(类似于资源管理系统)
Zookeeper 和 Kafka 启动的时候都是需要在所有的计算机(指主从)都启动
不需要启动Hadoop集群
分别登录master和slave01、slave02节点
进入zookeeper安装目录,启动服务
# master节点cd zookeeper-3.4.10/
bin/zkServer.sh start #(s必须大写)# slave节点cd zookeeper-3.4.10/
bin/zkServer.sh start
启动命令:
bin/zkServer.sh start
ZooKeeper可以处理两种类型的队列:
- 同步队列,即当一个队列的所有成员都聚齐时,这个队列才可用,否则会一直等待所有成员聚齐
- 先入先出队列,即按照先入先出方式进行入队和出队操作。
2. 持久节点和临时节点
ZooKeeper中节点主要有四种类型:
- 持久节点(PERSISTENT): 是指节点在被创建后就一直存在,直到有删除操作来主动清除这个节点。这类节点不会因为创建该节点的客户端会话失效而消失。
- 持久顺序节点(PERSISTENT_SEQUENTIAL): 在ZooKeeper中,每个父节点会为自己的第一级子节点维护一份时序文件,记录每个子节点创建的先后顺序。基于这个特性,可以创建持久顺序节点,即在创建子节点的时候,用户可以指定其顺序属性,ZooKeeper就会自动为给定节点名加上一个数字后缀,作为新的节点名
- 临时节点(EPHEMERAL): 和持久节点不同,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉(注意是会话失效,而非连接断开)。另外,在临时节点下面不能创建子节点。
- 临时顺序节点(EPHEMERAL_SEQUENTIAL): 临时顺序节点与临时节点的不同在于:临时顺序节点在创建时会自动加上编号,其创建方法与编号格式与持久顺序节点相同。
3. get 获取节点数据和更新信息
cZxid :创建节点的事务id
ctime : 节点的创建时间
mZxid :修改节点的事务id
mtime :修改节点的时间
pZxid :子节点的id
cversion : 子节点的版本
dataVersion : 当前节点数据的版本
aclVersion :权限的版本
ephemeralOwner :判断是否是临时节点
dataLength : 数据的长度
numChildren :子节点的数量
4. 访问权限
ACL:Access Control List 访问控制列表
ZK的节点有5种操作权限:CREATE、READ、WRITE、DELETE、ADMIN 也就是 增、删、改、查、管理权限,这5种权限简写为crwda
这5种权限中,除了 DELETE ,其它4种权限指对自身节点的操作权限
5. 四级命令
5.1.stat 查看状态信息
[zkpk@master zookeeper-3.4.5]$ su root
[root@master zookeeper-3.4.5]# echo stat | nc 192.168.1.100 2181
Zookeeper version: 3.4.5-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
Clients:
/192.168.1.68:49346[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/4
Received: 62
Sent: 61
Connections: 1
Outstanding: 0
Zxid: 0x50000000a
Mode: follower
Node count: 10[root@master zookeeper-3.4.5]#
5.2 ruok 查看zookeeper是否启动
[root@master zookeeper-3.4.5]# echo ruok | nc 192.168.1.100 2181
imok[root@master zookeeper-3.4.5]#
5.3 dump 列出没有处理的节点,临时节点
imok[root@master zookeeper-3.4.5]# echo dump | nc 192.168.1.100 2181
SessionTracker dump:
org.apache.zookeeper.server.quorum.LearnerSessionTracker@29805957
ephemeral nodes dump:
Sessions with Ephemerals (0):
[root@master zookeeper-3.4.5]#
5.4 conf 查看服务器配置
[root@master zookeeper-3.4.5]# echo conf | nc 192.168.1.100 2181clientPort=2181dataDir=/usr/home/zookeeper-3.4.5/data/version-2
dataLogDir=/usr/home/zookeeper-3.4.5/data/version-2
tickTime=2000maxClientCnxns=60minSessionTimeout=4000maxSessionTimeout=40000serverId=2initLimit=10syncLimit=5electionAlg=3electionPort=3888quorumPort=2888peerType=0[root@master zookeeper-3.4.5]#
3.5 cons 显示连接到服务端的信息
[root@master zookeeper-3.4.5]# echo cons | nc 192.168.1.100 2181
/192.168.0.68:49354[0](queued=0,recved=1,sent=0)[root@master zookeeper-3.4.5]#
3.6 envi 显示环境变量信息
[root@master zookeeper-3.4.5]# echo envi | nc 192.168.1.100 2181
Environment:
zookeeper.version=3.4.5-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
host.name=localhost
java.version=1.8.0_111
java.vendor=Oracle Corporation
java.home=/usr/local/jdk1.8.0_111/jre
java.class.path=/usr/home/zookeeper-3.4.5/bin/../build/classes:/usr/home/zookeeper-3.4.5/bin/../build/lib/*.jar:/usr/home/zookeeper-3.4.5/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/home/zookeeper-3.4.5/bin/../lib/slf4j-api-1.6.1.jar:/usr/home/zookeeper-3.4.5/bin/../lib/netty-3.10.5.Final.jar:/usr/home/zookeeper-3.4.5/bin/../lib/log4j-1.2.16.jar:/usr/home/zookeeper-3.4.5/bin/../lib/jline-0.9.94.jar:/usr/home/zookeeper-3.4.5/bin/../lib/audience-annotations-0.5.0.jar:/usr/home/zookeeper-3.4.5/bin/../zookeeper-3.4.5.jar:/usr/home/zookeeper-3.4.5/bin/../src/java/lib/*.jar:/usr/home/zookeeper-3.4.5/bin/../conf:
java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
java.io.tmpdir=/tmp
java.compiler=<NA>
os.name=Linux
os.arch=amd64
os.version=3.10.0-514.10.2.el7.x86_64
user.name=root
user.home=/root
user.dir=/usr/home/zookeeper-3.4.5/bin
[root@master zookeeper-3.4.5]#
3.7 mntr 查看zk的健康信息
[root@master zookeeper-3.4.5]# echo mntr | nc 192.168.1.100 2181
zk_version 3.4.5-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
zk_avg_latency 0
zk_max_latency 4
zk_min_latency 0
zk_packets_received 68
zk_packets_sent 67
zk_num_alive_connections 1
zk_outstanding_requests 0
zk_server_state follower
zk_znode_count 10
zk_watch_count 0
zk_ephemerals_count 0
zk_approximate_data_size 124
zk_open_file_descriptor_count 32
zk_max_file_descriptor_count 4096[root@master zookeeper-3.4.5]#
3.8 wchs 展示watch的信息
[root@master zookeeper-3.4.5]# echo wchs | nc 192.168.1.100 21810 connections watching 0 paths
Total watches:0
[root@master zookeeper-3.4.5]#
3.9 wchc和wchp 显示session的watch信息 path的watch信息
[root@master zookeeper-3.4.5]# echo wchc | nc 192.168.1.100 2181
wchc is not executed because it is not in the whitelist.
[root@master zookeeper-3.4.5]# echo wchp | nc 192.168.1.100 2181
wchp is not executed because it is not in the whitelist.
6. 关闭zookeepr
关闭ZooKeeper (master,slave)

第7章 Kafka
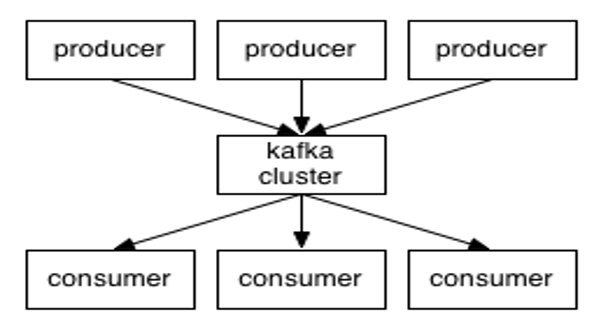
1. Kafka概念
Kafka是一种高吞吐量的分布式发布订阅消息系统
Producer
:消息生产者,负责将消息发布到Kafka上。
Consumer
:消息消费者,从Kafka上读取消息。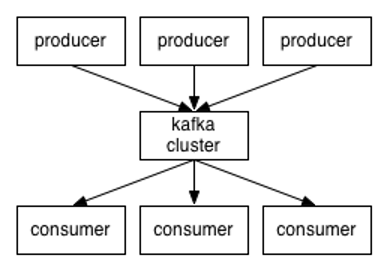
Broker
即代理,也就是通常所说的服务器节点。Kafka集群包含一个或多个服务器节点,这种服务器就被称为Broker。一个Kafka节点就是一个Broker。
Message
即消息。Kafka的数据单元被称为消息。
消息元数据,键。
Partition
分区。Partition是物理上的概念,为了使得Kafka的吞吐率可以水平扩展.
Topic
主题。每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
Segment
Partition物理上由多个Segment组成,每个Segment存着消息(message)信息。
2. kafka 特点
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费。
- 分布式系统,易于向外扩展。
- 支持online和offline的场景。
- 支持压缩(snappy、gzip)
3. 常用命令
分别登录master和slave节点启动Zookeeper
分别登录master和slave节点启动Kafka
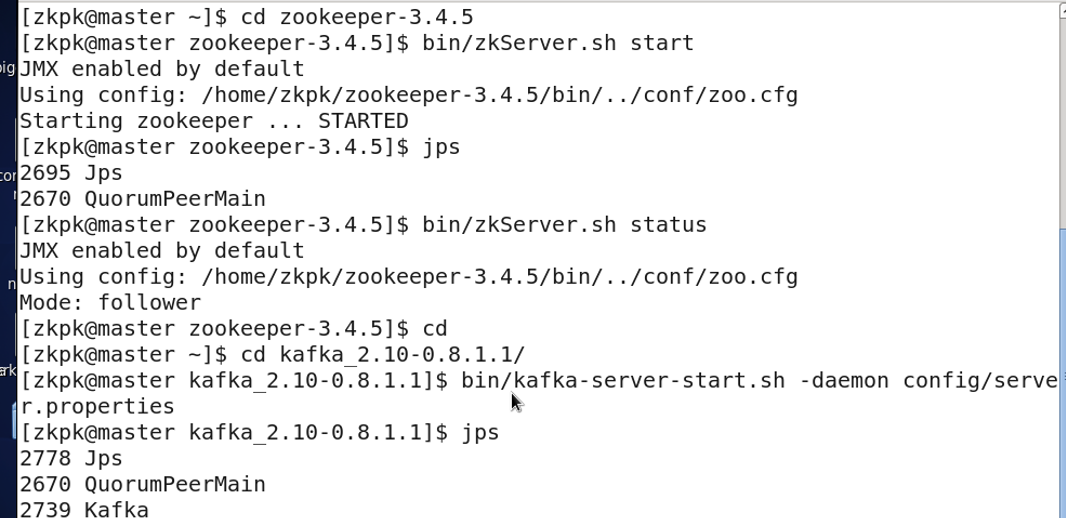
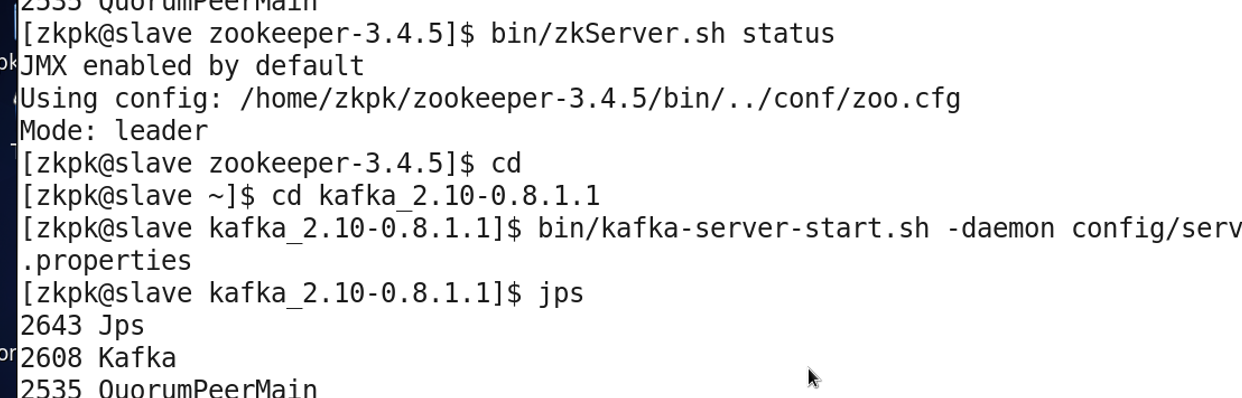
在master创建一个名为 test的主题topic
[zkpk@master kafka_2.11-0.10.2.1]$ bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test

启动一个生产者,并在键盘上输入hello 然后回车
[zkpk@master kafka_2.11-0.10.2.1]$ bin/kafka-console-producer.sh --broker-list master:9092 --topic test
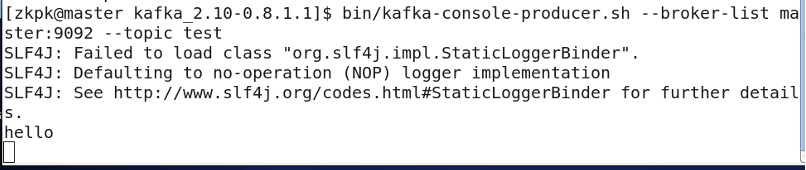
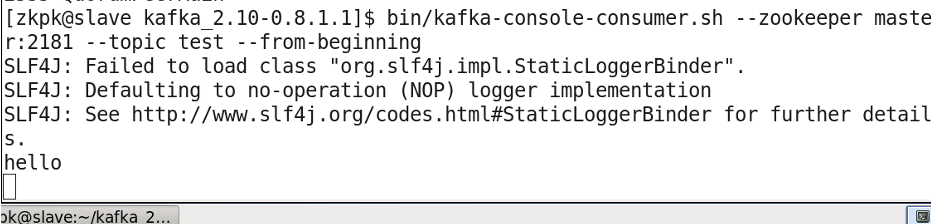
在slave01终端上启动一个消费者
[zkpk@master kafka_2.11-0.10.2.1]$ bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test --from-beginning
查看topic列表
bin/kafka-topics.sh --list --zookeeper master:2181
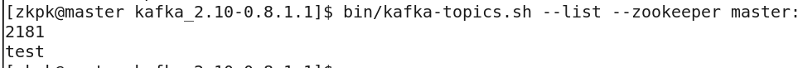
查看topic说明信息
bin/kafka-topics.sh --describe --zookeeper master:2181 --topic test

4. 关闭
bin/kafka-server-stop.sh
bin/zkServer.sh stop
第8章 HBase
1. 简介
HBase是一个高可靠、高性能、面向列、可伸缩的、实时读写的分布式数据库,是Hadoop的一个重要组件。
2. 和传统关系数据库的区别
HBase与传统的关系数据库的区别主要体现在以下几个方面:
(1)数据类型:HBase字符串
(2)数据操作:HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等
(3)存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的
(4)数据索引:HBase只有一个索引——行键
(5)数据维护:HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留
(6)可伸缩性:
3. 常用命令
3.1 启动
单机模式
start-hbase.sh
stop-hbase.sh
伪分布式模式
start-all.sh
start-hbase.sh
(jps master:Hmaster slave:Hregionserver)
完全分布式模式
start-all.sh
zkServer.sh start
#(分别在master,slave上启动 jps quorumpeermain)
zkServer.sh status
follower leader
start-hbase.sh #(master)
3.2 启动2
start-all.sh
start-hbase.sh
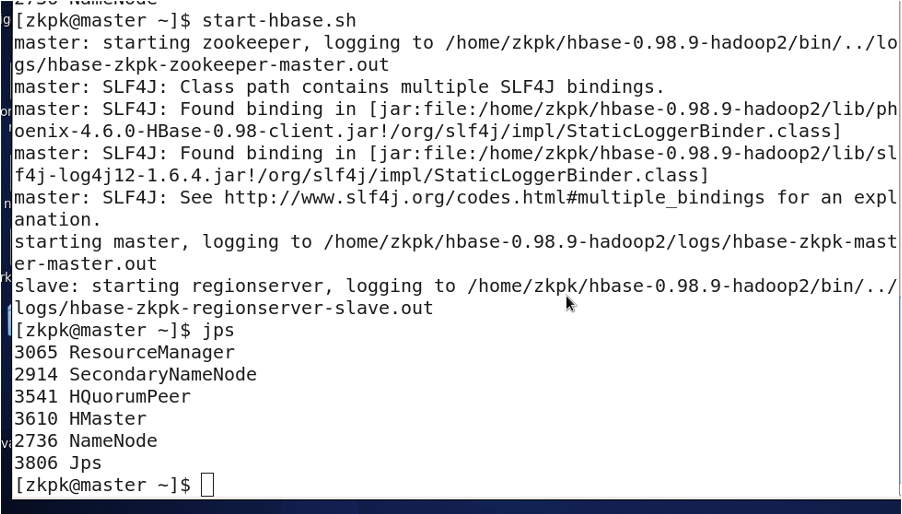
3.3 进入Hbase shell
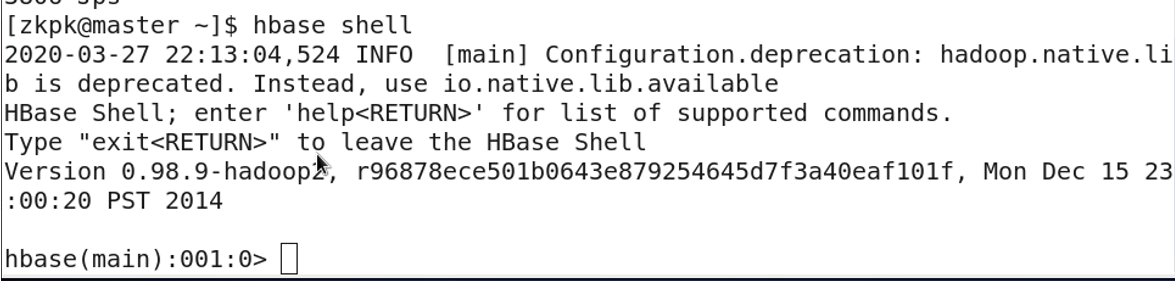
3.4 集群状态命令 status
1 servers, 0 dead, 2.5000 average load
该集群共有1台RegionServer,平均每台山有2.5个region
3.5 创建表:
create '表名称', '列名称1','列名称2','列名称N'
create'student','college','profile'

列举表:
list
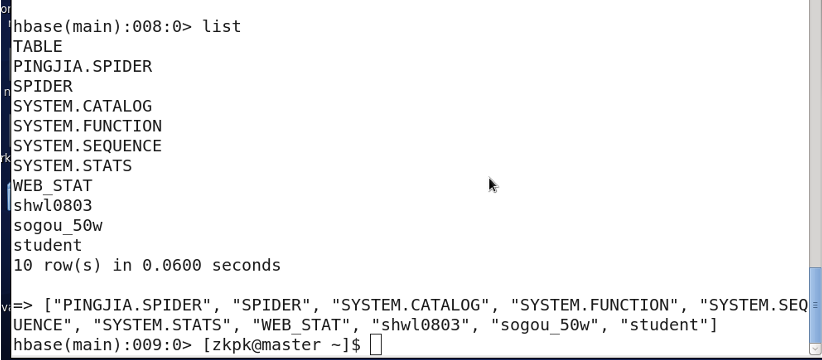
3.6 查看表结构
desc '表名'

3.7 查看所有记录
scan '表名称'

3.8 查看表中的记录总数
count '表名称'
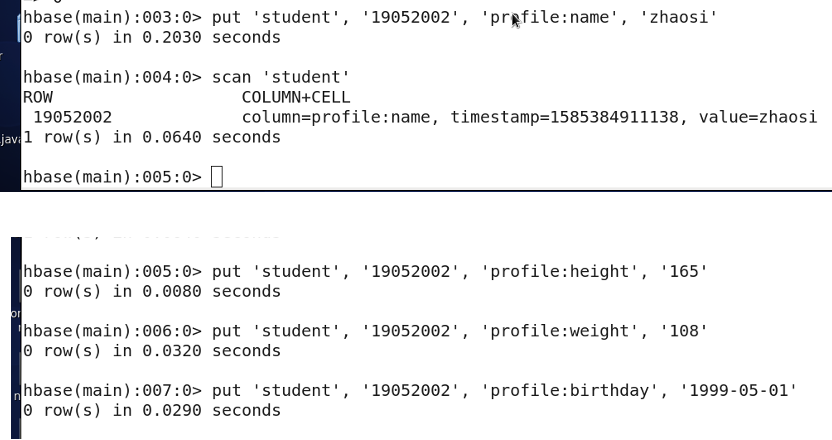
3.9 添加记录
put '表名称','行名称','列名称:','值'
hbase (main) : 006: 0 > put 'student', '19052002', ‘college:school', ' Computer Engineering'
hbase (main) : 007: 0 > put 'student', '19052002', 'college:department', 'CS'
hbase (main) : 008: 0 > put 'student', '19052006', 'profile:name', 'liuneng'
hbase (main) : 009: 0 > put 'student', '19052006', 'profile:height', '170'
hbase (main) : 010: 0 > put 'student', '19052006', 'profile:weight', '122'
hbase (main) : 011: 0 > put 'student', '19052006', 'profile:birthday', '1999-08-02'
hbase (main) : 012: 0 > put 'student', '19052006', 'college:school', ' Computer Engineering '
hbase (main) : 013: 0 > put 'student', '19052006', 'college:department', 'EE'
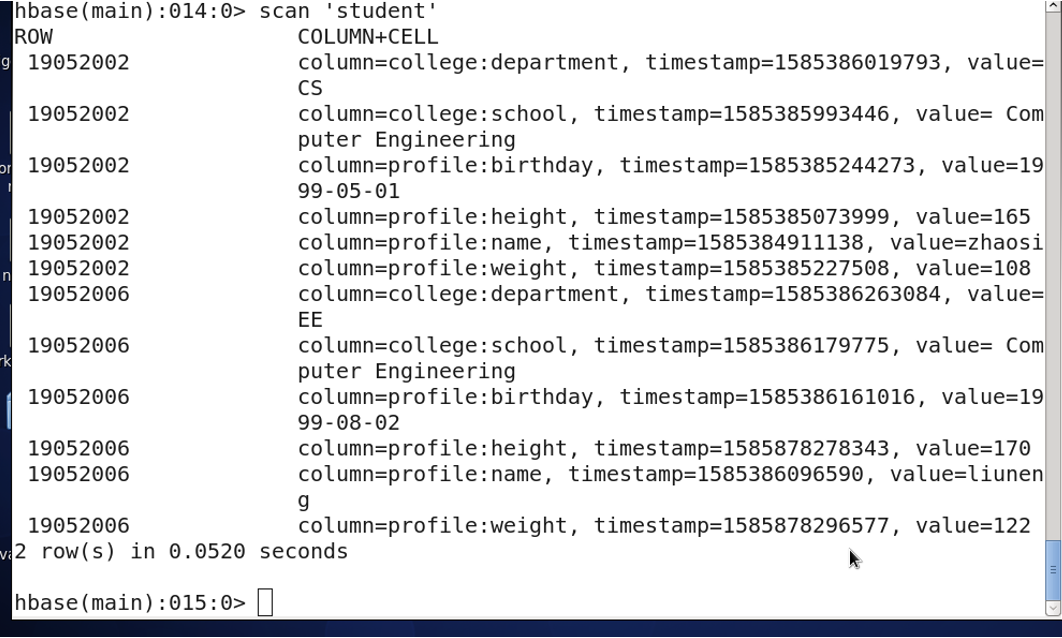
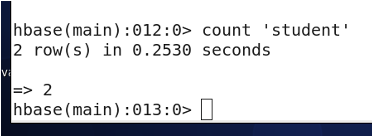
3.10 查询表中有多少条记录,使用count命令。
hbase (main) : 014: 0> count 'student'
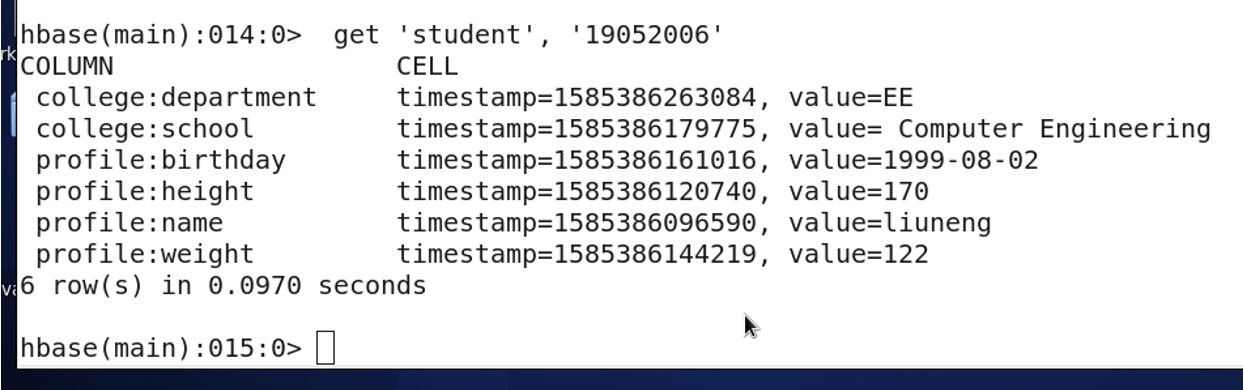
3.11 获取一条数据,使用get命令
需要给出Row key。
hbase (main) : 015: 0> get 'student', '19052006’
3.12 获取某行数据一个列族的所有数据,使用get命令。
hbase (main) : 016: 0> get‘student’, ‘19052006’, ‘profile’
3.13 获取某行数据一个列族中一个列的所有数据,使用get命令
hbase (main) : 017: 0> get 'student','19052006','profile:name'
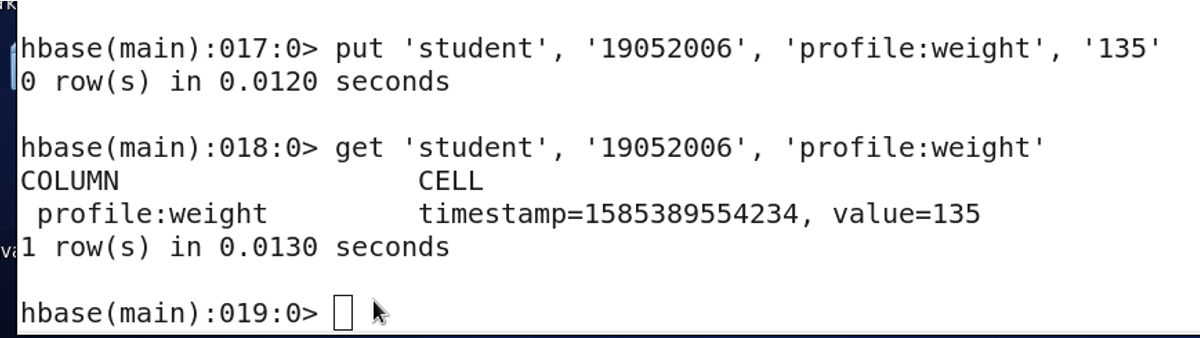
3.14 更新一条记录,使用put命令
将liuneng的体重改为135。
hbase (main) : 018: 0> put 'student','19052006','profile:weight','135'0row(s)in0.0850 seconds

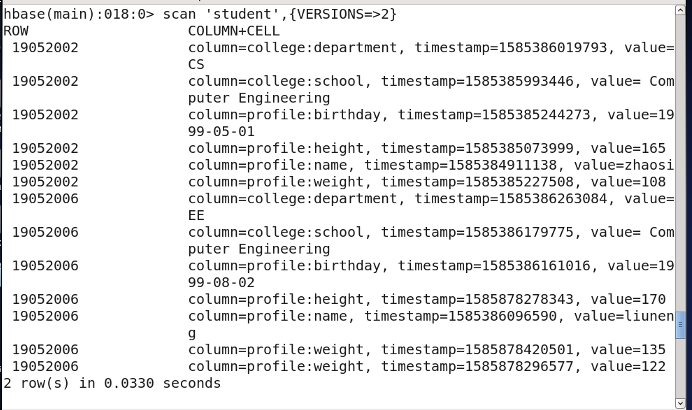
Version
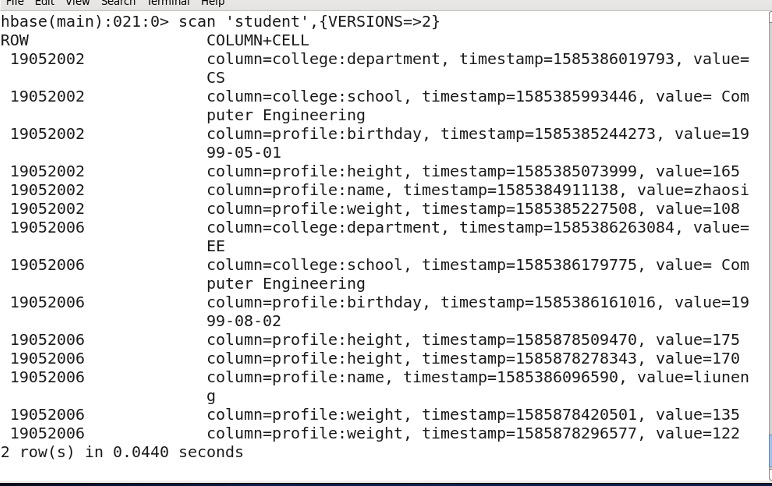
Filter {VERSIONS=2} 必须大写
时间戳的类型是64位整型。时间戳可以由HBASE(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间点细化为一连串数字,值越大,版本越新。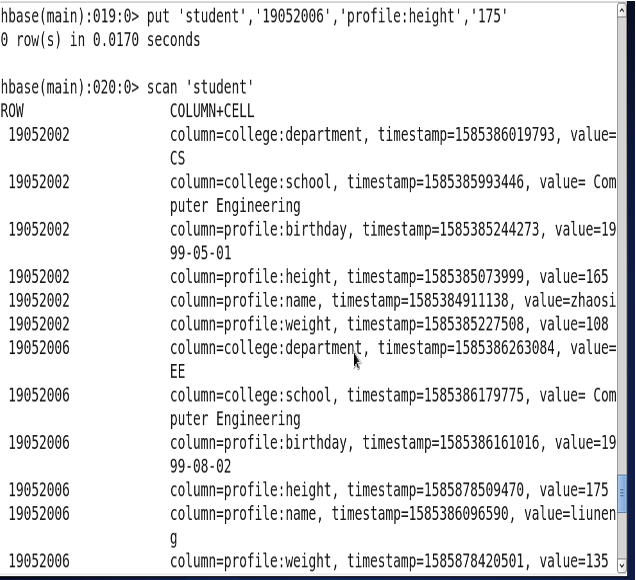
3.15 删除行键值为19052006的列height,使用delete命令。
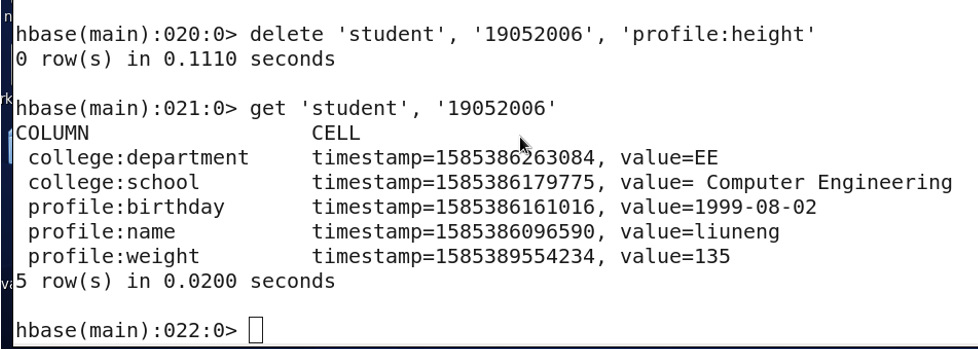
可以看到,列height已经被删除。
3.16 增加列族
alter'表名','列族名'
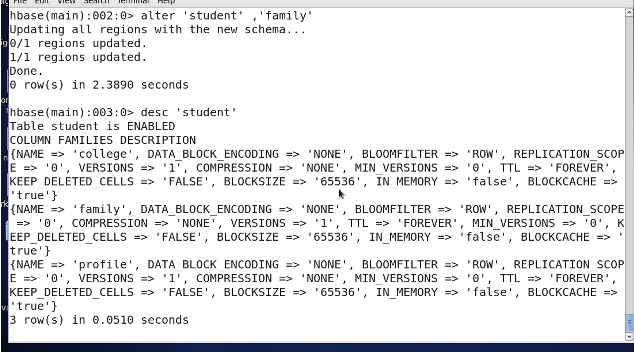
3.16 删除列族
alter'表名','delete'=>'列族名'
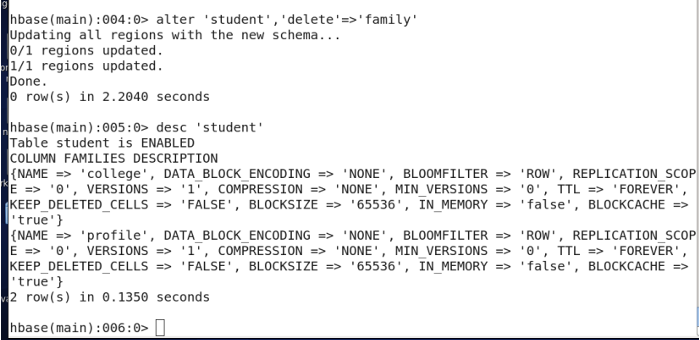
3.17 删除整行
deleteall ‘表名’,‘行键’
deleteall ‘student’,’19052002’
put一次一个列
hbase (main) : 002: 0> put student', '19052002', 'profile:name', 'zhaosi'
hbase (main) : 003: 0 > put 'student', '19052002', 'profile:height', '165'
put ‘student’, ‘19052002’, ‘profile:name’, ‘zhaosi‘,’profile:height’, ‘165’ 错误
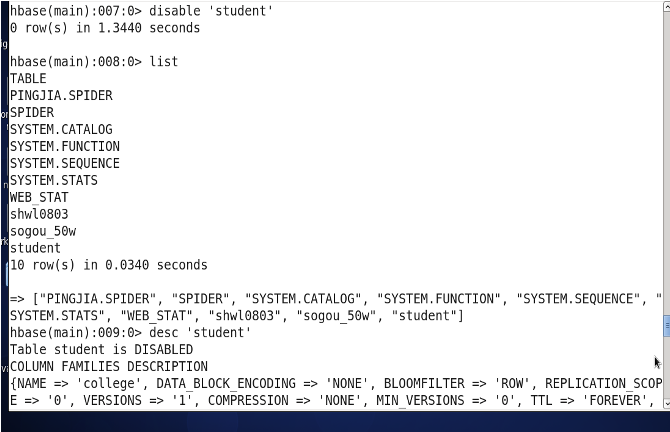
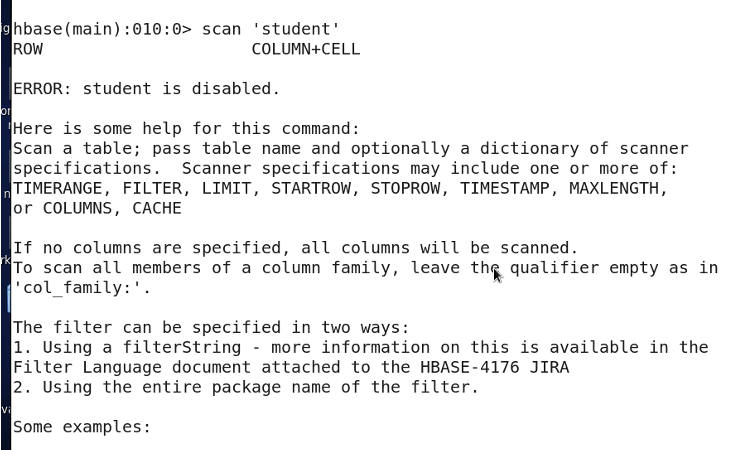
3.18 下线 disable
disable 下线某个表
disable'表名'
3.19 上线表 enable
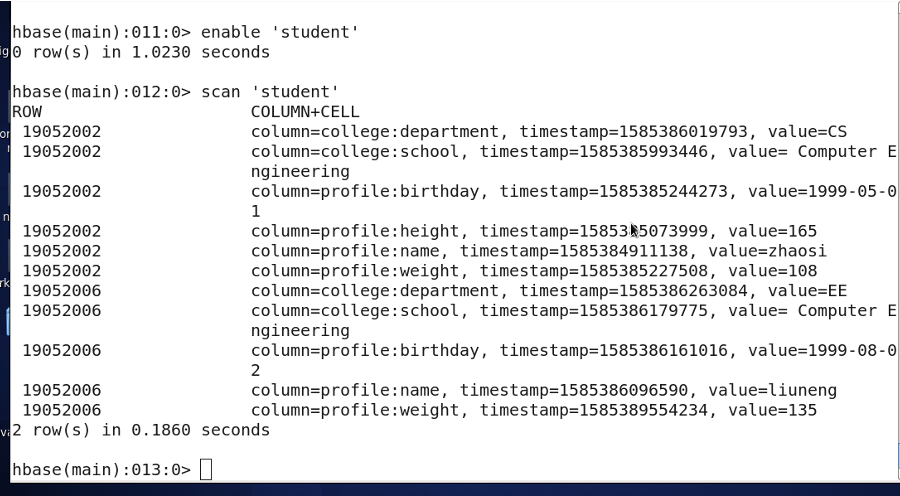
enable 上线某个表
enable'表名'
3.19 判断命令(exists,is_enabled,is_disabled)
exists 判断表是否存在
is_enabled 判断表是否上线
is_disabled 判断表是否下线
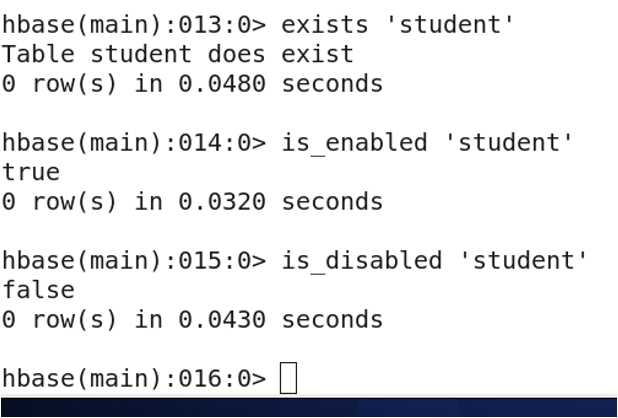
3.20 删除表中所有数据
truncate'表名'
3.21 删除表 (先下线表)
disable'表名'drop'表名'
3.22 退出hbase shell
exit
3.23 关闭hbase
stop-hbase.sh
Shutdown: 关闭hbase服务,exit: 只是退出hbase shell
SP 特别篇
SP1 启动命令
- Hadoop:
start-all.sh - Hive:
start-all.sh(需要先启动 hadoop集群),然后hive - zookeeper:
bin/zkServer.sh start(master & slave) - kafka: (master & slave)
bin/zkServer.sh start(先启动 zookeeper)bin/kafka-server -start.sh --daemon config/server.properties
- Hbase:
# 单机模式
start-hbase.sh
# 伪分布式模式
start-all.sh
start-hbase.sh
SP2 关闭命令
- Hadoop:
stop-all.sh - Hive:
stop-all.sh - zookeeper:
bin/zkServer.sh stop(master & slave) - kafka: (master & slave)
bin/kafka-server-stop.shbin/zkServer.sh stop
- Hbase:
stop-hbase.sh
版权归原作者 okfang616 所有, 如有侵权,请联系我们删除。