
1、常用OLAP查询引擎
目前大数据比较常用的OLAP查询引擎包括:Presto、Impala、Druid、Kylin、Doris、Clickhouse、GreenPlum等。
不同引擎特点不尽相同,针对不同场景,可能每个引擎的表现也各有优缺点。下面就以上列举的几个查询引擎做简单介绍。
2、Presto
2.1、Presto简介
Presto是 Facebook 推出的一个开源的分布式SQL查询引擎,数据规模可以支持GB到PB级,主要应用于处理秒级查询的场景。Presto 的设计和编写完全是为了解决像 Facebook 这样规模的商业数据仓库的交互式分析和处理速度的问题。虽然 Presto 可以解析 SQL,但它不是一个标准的数据库。不是 MySQL、Oracle 的代替品,也不能用来处理在线事务(OLTP)。
2.2、Presto 应用场景
Presto 支持在线数据查询,包括 Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条 Presto 查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析(跨库执行)。Presto 主要用来处理 响应时间小于 1 秒到几分钟的场景 。
2.3、Presto架构
Presto 是一个运行在多台服务器上的分布式系统。完整安装包括一个 Coordinator 和多 个 Worker。由客户端提交查询,从 Presto 命令行 CLI 提交到 Coordinator。Coordinator 进行 解析,分析并执行查询计划,然后分发处理队列到 Worker 。
Presto也是一个master-slave架构的查询引擎。其架构图如下图所示:
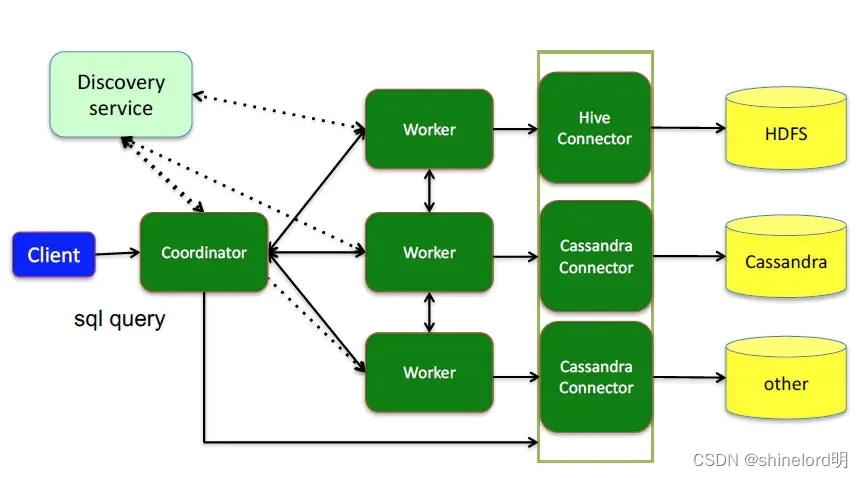
3、Impala
3.1、Impala简介
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
**
Impala
是一个
MPP
(大规模并行处理)
SQL
查询引擎**:
- 是一个用
C++和Java编写的开源软件; - 用于处理存储在
Hadoop集群中大量的数据; - 性能最高的
SQL引擎(提供类似RDBMS的体验),提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。 - 使用impala,用户可以使用传统的SQL知识以极快的速度处理存储在HDFS、HBase和Amazon s3中的数据中的数据,而无需了解Java(MapReduce作业)。
- 由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
** 但是:**
- 不提供任何对序列化和反序列化的支持;
- 只能读取文本文件,而不能读取自定义二进制文件;
- 每当新的记录/文件被添加到
HDFS中的数据目录时,该表需要被刷新; - 不支持text域的全文搜索;
- 不支持Transforms;
- 对内存要求高;
- 不支持查询期的容错。
3.2、Impala应用场景
查询速度快。Impala不同于hive,hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程。不同于hive,impala中间结果不写入磁盘,即使及时通过网络以流的形式传递,大大降低的节点的IO开销。灵活性高。在一些实时性要求很高的场景中,一方面满足实时性要求,一方面提升用户体验。
3.3、Impala架构
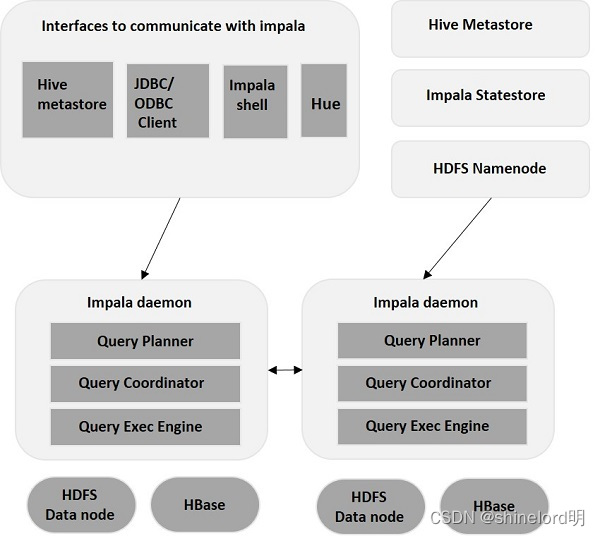
impala是典型的mpp架构,采用了***对等式架构***,所有角色之间是对等的,没有主从之分。
impala
主要由以下三个组件组成:
Impala daemon(守护进程);
Impala Statestore(存储状态);
Impala元数据或metastore(元数据即元存储)。
4、Druid
4.1、Druid简介
Apache Druid 由 *Metamarkets 公司*(一家为在线媒体或广告公司提供数据分析服务的公司)开发,在2019年春季被捐献给 Apache 软件基金会。
是一个高性能实时分析数据库。它是为大型数据集上实时探索查询的引擎,提供专为 OLAP 设计的开源分析数据存储系统,它的设计意图是在面对代码部署、机器故障以及其他产品系统遇到不测时能保持 100% 正常运行。它也可以用于后台用例,但设计决策明确定位线上服务。
4.2、Druid应用场景
Apache Druid适用于对实时数据提取,高性能查询和高可用要求较高的场景。因此,Druid通常被作为一个具有丰富GUI的分析系统,或者作为一个需要快速聚合的高并发API的后台。Druid更适合面向事件数据。
比较常见的使用场景:
- 点击流分析(web和mobile分析)
- 风控分析
- 网路遥测分析(网络性能监控)
- 服务器指标存储
- 供应链分析(制造业指标)
- 应用性能指标
- 商业智能/实时在线分析系统OLAP
4.3、Druid架构
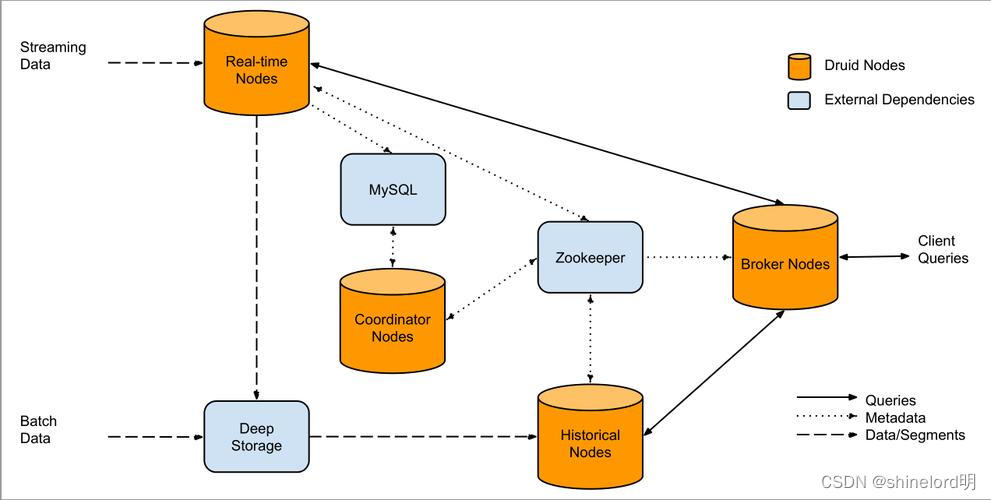
Druid是一组系统,按照职责分成不同的角色。目前存在五种节点类型:
Historical: 历史节点的职责主要是对历史的数据进行存储和查询,历史节点从Deep Storage下载Segment,然后响应Broker对于Segment的查询将查询结果返回给Broker节点,它们通过Zookeeper来声明自己存储的节点,同时也通过zookeeper来监听加载或删除Segment的信号。
Coordinator:协调节点监测一组历史节点来保证数据的可用和冗余。协调节点读取元数据存储来确定哪些Segment需要load到集群中,通过zk来感知Historical节点的存在,通过在Zookeeper上创建entry来和Historical节点通信来告诉他们加载或者删除Segment
Broker:节点接收外部客户端的查询,并且将查询路由到历史节点和实时节点。当Broker收到返回的结果的时候,它将结果merge起来然后返回给调用者。Broker通过Zook来感知实时节点和历史节点的存在。
Indexing Service: 索引服务是一些worker用来从实时获取数据或者批量插入数据。
Realtime:获取实时数据
索引服务是一个高可用的,分布式的服务来运行索引相关的Task。索引服务会创建或者销毁Segment。索引服务是一个Master/Slave架构。索引服务是三个组件的集合。
5、Kylin
5.1、Kylin简介
*Apache Kylin*是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
5.2、Kylin应用场景
- 用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上。
- 每天有数G甚至数十G的数据增量导入。
- 有10个以内较为固定的分析维度。
Kylin 的核心思想是利用空间换时间,在数据 ETL 导入 OLAP 引擎时提前计算各维度的聚合结果并持久化保存
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
定义数据集上的一个星形或雪花形模型
在定义的数据表上构建cube
使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau,PowerBI 等,令用户可以使用 BI 工具对 Hadoop 数据进行分析。
5.3、Kylin架构
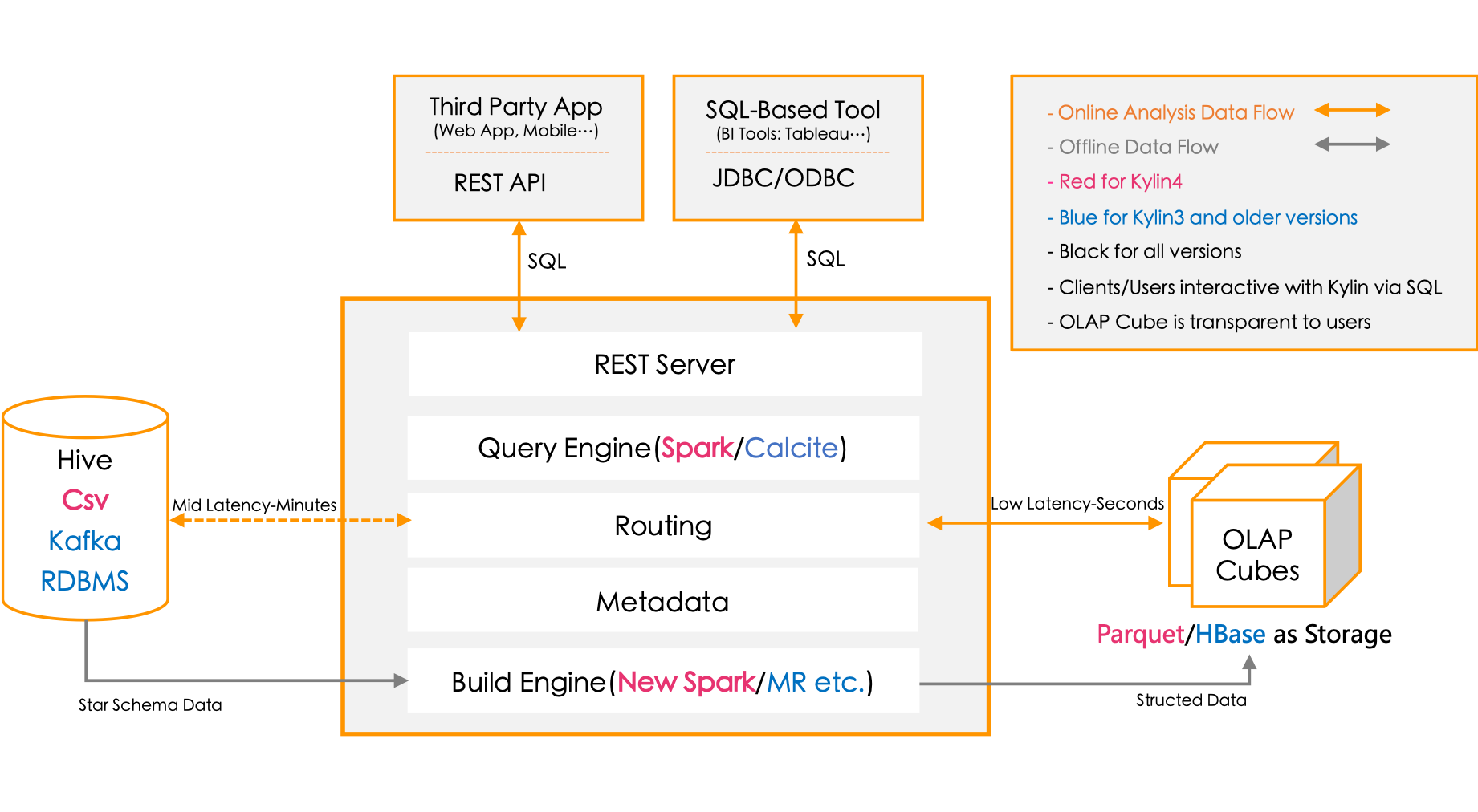
Kylin不同于大规模并行处理的Hive等*架构*,*Kylin是*预计算的模式,我们提前定义好查询的维度,Kylin就会帮助我们进行计算,并将结果存储到Hbase。cube是其比较核心的概念。
6、Doris
6.1、Doris简介
*Apache Doris* (incubating)(原Palo)是一款百度大数据团队自主研发的MPP数据库,其功能和性能已达到或超过国内外同类产品。是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
- 分布式存储:数据分散存储在集群中的多个节点上,提高了数据的可靠性和可扩展性。
- 高性能查询:支持实时查询和分析大规模的数据,采用MPP(Massively Parallel Processing)架构,以及多种查询优化和执行技术,提高了查询的效率。
- 多维分析:支持多维分析、OLAP(Online Analytical Processing)查询和报表功能,满足商业智能和数据分析的需求。
- 实时同步:支持实时同步和增量更新,保证数据的及时性和准确性。
- 安全可靠:提供多种安全措施和机制,包括访问控制、数据备份和恢复、故障转移等,保证数据的安全和可靠性。
- 兼容mysql协议。
6.2、Doris应用场景
Apache Doris 能够较好的满足报表分析、即时查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
应用场景主要包括以下方面:
- 数据仓库:用于构建大规模的数据仓库,支持数据的存储、查询和分析等功能。
- 商业智能:用于支持商业智能和数据分析,包括多维分析、OLAP查询和报表功能等。
- 实时报表:用于构建实时报表系统,支持数据的实时同步和查询,满足实时报表和分析的需求。
- 物联网:用于物联网领域的数据处理和分析,支持海量数据的存储和查询,提供实时数据分析和决策支持。
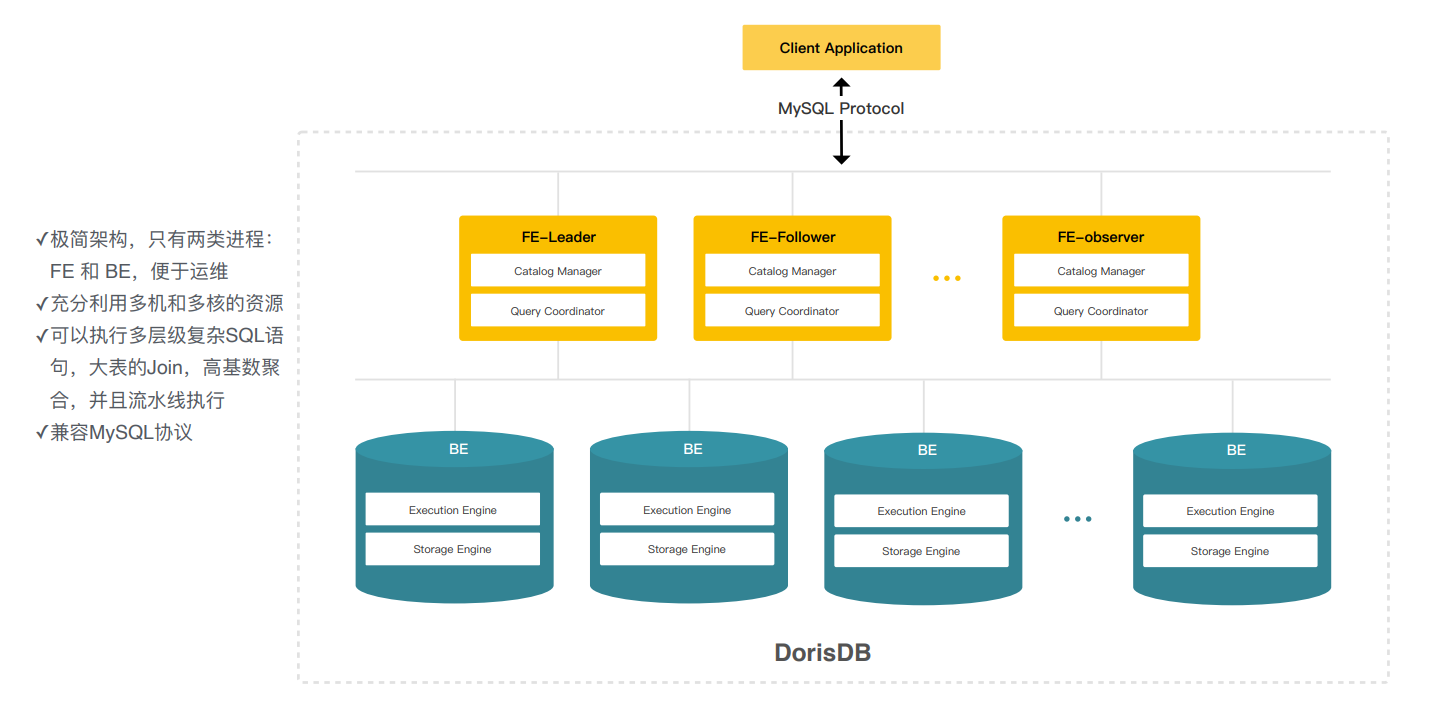
6.3、Doris架构
*Apache Doris* 是一个基于 MPP *架构*的高性能、实时的分析型数据库,采用了***对等式架构***,所有角色之间是对等的,没有主从之分。
FE前端节点-主要负责元数据的管理、查询调度,解析sql的执行计划给BE,
BE-数据的存储和执行的引擎,这里存储和计算还是在一起的;
FE:leader 、follower(参与选举),水平扩容
对外提供了mysql兼容的协议;
跟传统架构的区别:
通过分布式拆分成不同的task,再在中心节点汇聚;
druid、clickhouse都是类型;
MR是任务的拆分、落盘;
doris是MPP架构,任务之间分成task、全都在内存中执行和传输,所有任务都是流水线,没有磁盘IO,适用于低延迟亚秒级查询;
7、Clickhouse
7.1、Clickhouse简介
ClickHouse是俄罗斯的Yandex于2016年开源的一个**用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System),简称CK,**使用**C++ 语言**编写,主要用于**在线分析处理查询(OLAP)**,能够使用SQL查询实时生成分析数据报告。
ClickHouse是一个完全的**列式数据库管理系统**,允许在**运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器**,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage 作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。另外就是它比较快。
7.2、Clickhouse应用场景
- 读多于写
- 大宽表,读大量行但是少量列,结果集较小 通常存在一张或是几张多列的大宽表,列数高达数百甚至数千列。对数据分析处理时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一个较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。而聚合计算的结果集相比于动辄数十亿的原始数据,也明显小得多
- 向量引擎 :数据不仅按列存储,而且通过向量(列的一部分)进行处理,从而可以实现较高的CPU效率。
- 实时数据更新 :ClickHouse支持具有主键的表。为了在主键范围内快速执行查询,使用合并树对数据进行增量排序。因此,可以将数据连续添加到表中。摄取新数据时不采取任何锁定。
- 数据批量写入:且数据不更新或少更新 由于数据量非常大,通常更加关注写入吞吐,要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新、删除操作。
- 无需事务,数据一致性要求低
- 灵活多变,不适合预先建模 分析场景下,随着业务变化要及时调整分析维度、挖掘方法,以尽快发现数据价值、更新业务指标。而数据仓库中通常存储着海量的历史数据,调整代价十分高昂。预先建模技术虽然可以在特定场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高
- 数据有序存储 ClickHouse支持在建表时,指定将数据按照某些列进行sort by。排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault
- 高吞吐写入能: 能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度
- 分布式计算 ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
- 多核并行:MySQL单条SQL是单线程的,只能跑满一个core,ClickHouse相反,ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。

7.3、Clickhouse架构
ClickHouse 是一个真正的**列式**数据库管理系统(DBMS),列式存储(Columnar or column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。在 ClickHouse 中,数据始终是**按列存储**的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为矢量化查询执行,它有利于降低实际的数据处理开销。
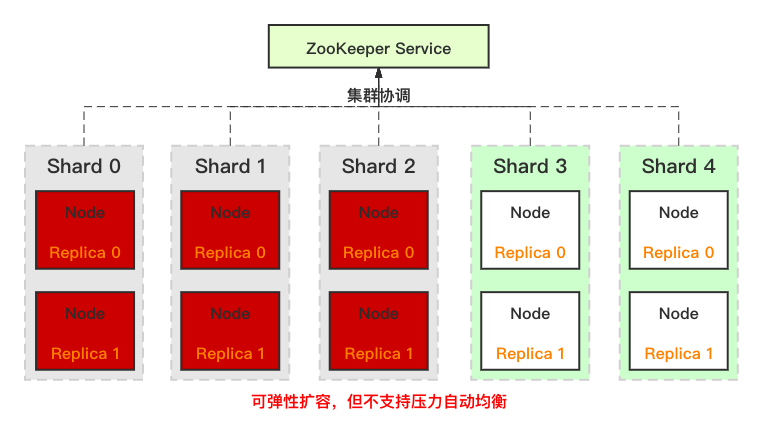
采用**双副本机制**来保证数据的高可靠,同时用nginx代理clickhouse集群,通过域名的方式进行读写操作,实现了数据均衡及高可靠写入,且对于域名的响应时间及流量还可进行对应的实时监控,一旦响应速度出现波动或异常我们能在第一时间收到报警通知。
采用多主架构,zk进行协调。

8、GreenPlum
8.1、GreenPlum简介
*Greenplum* 公司开发的GP(GreenPlum)是业界最快最高性价比的关系型分布式数据库,它在开源的PG(PostgreSql)的基础上采用MPP架构(Massive Parallel Processing,海量并行处理),具有强大的大规模数据分析任务处理能力。Greenplum 是全球领先的大数据分析引擎,专为分析、机器学习和AI而打造。
其中 *Greenplum* 中文社区尤为活跃,*目前约有半数的贡献来自中国开发者,社区贡献者包括阿里云、中移动等大公司*,也有诸多中小公司和数据库爱好者。
底层基于PostgreSQL,但是GreenPlum数据库增加了大量并行分析的创新设计。
8.2、GreenPlum应用场景
- 大规模并行处理架构
GreenPlum 数据库架构提供了横向扩展,无共享体系结构的数据和查询并行化设计。
- PB规模数据加载
高性能加载使用MPP技术。加载速度随着增加节点而增加,每个机架每小时10TB以上
- 创新的查询优化器
GreenPlum 数据库提供的查询优化器是业界首个针对大数据工作负载而设计的基于成本的查询优化器。可以将交互式和批处理模式应用到PB级别的大型数据集上,但是不会降低查询性能和吞吐量
- 多态数据存储和执行
表或者分区存储,执行和压缩设置可以按照数据访问方式进行配置。用户为每个表或者分区选择面向行或者列的存储和处理。
- 高级的机器学习
由Apache MADlib提供,这是一个可扩展的数据库内分析库,通过用户定义的函数扩展了Greenplum 数据库的SQL功能
- 外部数据访问
通过外部表语法访问和查询所有数据, 支持传统的内部部署和下一代公共数据湖。
GreenPlum数据库是一个大规模并行处理(MPP)数据库服务器。其架构设计专门应用于管理大型分析数据仓库和商业BI工作。
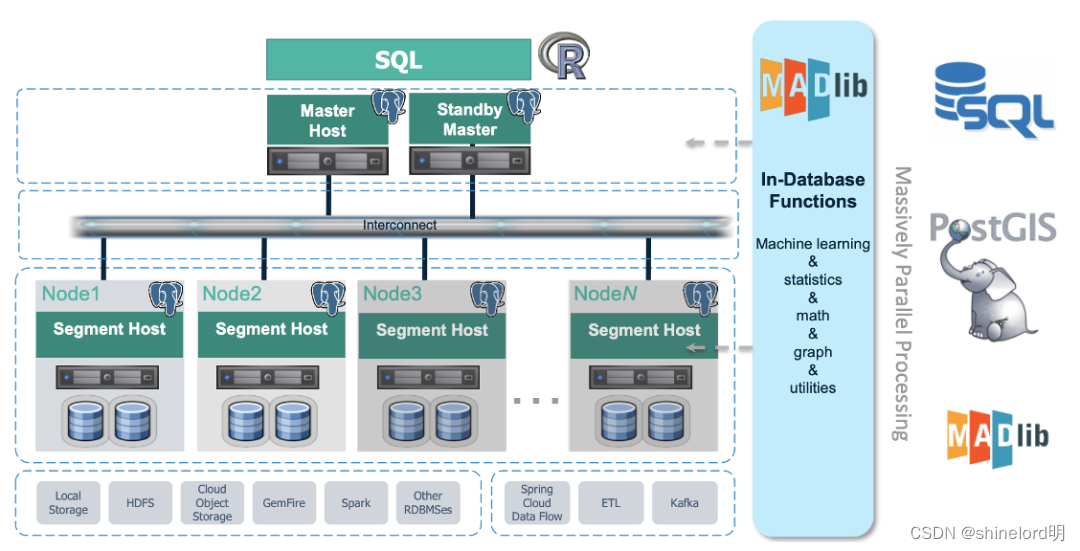
8.3、GreenPlum架构
GP是一种基于pg的分布式数据库,其采用的Shared-Nothing架构(MPP),主机、操作系统、内存、存储都是自我控制的,不存在共享。gp架构主要由Master Host、Segment Host、Interconnect三大部分组成。
9、OLAP查询引擎对比
特点PrestoImpalaDruidKylinDorisClickhouseGreenPlum查询延时一般(秒)一般(秒)低(亚秒)非常低(亚秒)
相较于Clickhouse,Doris还能支持各种主
流分布式join,不仅支持大宽表模型,还支
持星型模型和雪花模型
明细查询较低,单表查询性能
高,Join在一些情况下性能不佳
物化视图查询延迟非常低
一般,小查询会极大
消耗集群资源,无法
实现高效并发查询
SQL支持程度
非常完善
较完善
较完善非常完善
较完善
较完善
非常完善
生产数据成本
低
低
中
高
中
中
中
发展定位
MPP系统,SQL
on Hadoop
是一种 SQL on Hadoop 解决方
案,使用 MPP 数据库技术来提
高查询速度
位图索引查询、编码。预聚合
技术,但是只聚合最细的维度
组合,在此基础进行聚合
完全预聚合立方体
一个 MPP 的 OLAP 系统,对多维查询分析
提供支持,主要整合了 Google Mesa(数
据模型),Apache Impala(MPP
Query Engine) 和 Apache ORCFile (存
储格式,编码和压缩) 的技术
明细动态聚合查询
物化视图
一个开源的大规模并
行数据分析引擎
支持join
支持
支持
不够成熟,维度lookup支持
支持
支持
有限支持
支持
版权归原作者 shinelord明 所有, 如有侵权,请联系我们删除。