
当计算出文本的Count Vector后,通过如下几种方法计算文本相似度。
Count Vector相关计算:(8条消息) 利用python文章关键信息提取_菜鸟1号——的博客-CSDN博客https://blog.csdn.net/qq_45099699/article/details/125798516?spm=1001.2014.3001.5501
以下相似度计算均以此例子进行:
句子1:这只皮靴号码大了,那只号码合适
句子2:这只皮靴号码不小,那只更合适
1.余弦相似度(常用)

#运用前边计算的count vector
def cosine(v1,v2):
v1_arr=np.array(v1)
v2_arr=np.array(v2)
up = np.sum(v1_arr*v2_arr)
downl = np.power(np.sum(v1_arr*v1_arr),0.5)
downr = np.power(np.sum(v2_arr * v2_arr), 0.5)
cosine_=up/(downl*downr)
return cosine_
print('cosine:',cosine(count_vector[0],count_vector[1]))
2.Jaccard相似度

# 该方法不需要count vector,只用文本的交并集
def Jaccard(v1,v2):
v1=set(v1)
v2=set(v2)
up=v1.intersection(v2)
down=v1.union(v2)
jaccard=1.0*len(up)/len(down)
return jaccard
print('Jaccard:',Jaccard(list_[0],list_[1]))
3.欧式距离计算
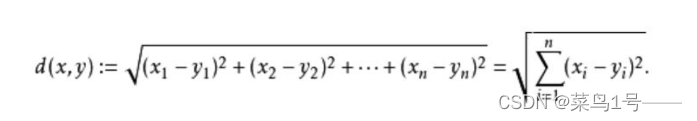
# 运用前边计算的count vector
def Distance(v1,v2):
v1_arr=np.array(v1)
v2_arr=np.array(v2)
distance=np.linalg.norm(v1_arr-v2_arr)
return distance
print('欧式距离:',Distance(count_vector[0],count_vector[1]))
本文转载自: https://blog.csdn.net/qq_45099699/article/details/125804150
版权归原作者 菜鸟1号—— 所有, 如有侵权,请联系我们删除。
版权归原作者 菜鸟1号—— 所有, 如有侵权,请联系我们删除。