
文章目录
准备工作
准备工作:集群部署的前提,每台虚拟机都需要完成。
静态IP设置
# 1.编辑网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 需要的内容修改如下:
BOOTPROTO=static # 修改成static
IPADDR=192.168.225.100 # 根据自己的网段自定义IP地址
GATEWAY=192.168.225.2 # 根据自己的网段填写对应的网关地址
NETMASK=255.255.255.0 # 子网掩码
DNS1=192.168.225.2 # 同网关地址保持一致即可
DNS2=223.6.6.6 # 使用阿里巴巴的公共DNS# 2.关闭NetworkManager,并取消开机自启
systemctl stop NetworkManager
systemctl disable NetworkManager
# 3.重启网络服务
systemctl restart network
# 4.ping测试网络
ping www.baidu.com
# 5.使用shell工具连接虚拟机
修改主机名
本文三台虚拟机分别设置为:master、node1、node2
hostnamectl set-hostname master
# 修改完后需要重新连接虚拟机
关闭防火墙
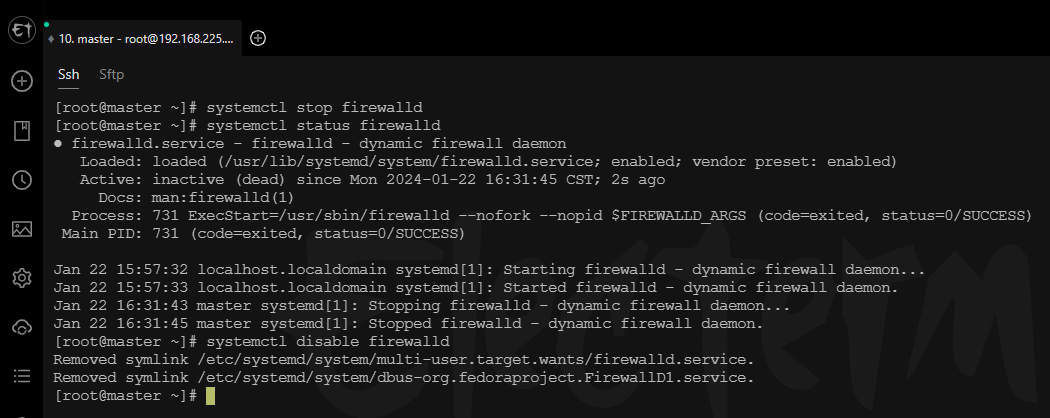
# 暂时关闭防火墙
systemctl stop firewalld
# 查看防火墙状态
systemctl status firewalld
# 取消防火墙自启
systemctl disable firewalld
同步时间
# 调整时区
timedatectl set-timezone Asia/Shanghai
# 安装ntpdate
yum install ntpdate
# 同步时间
ntpdate ntp.aliyun.com

安装JDK
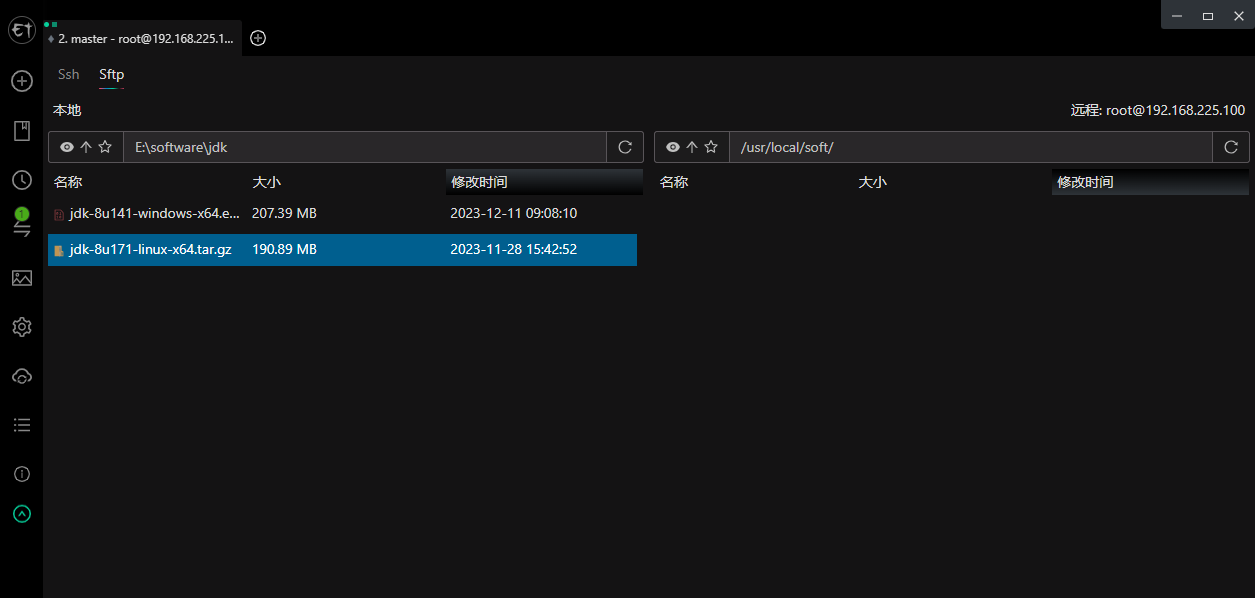
上传jdk安装包并解压
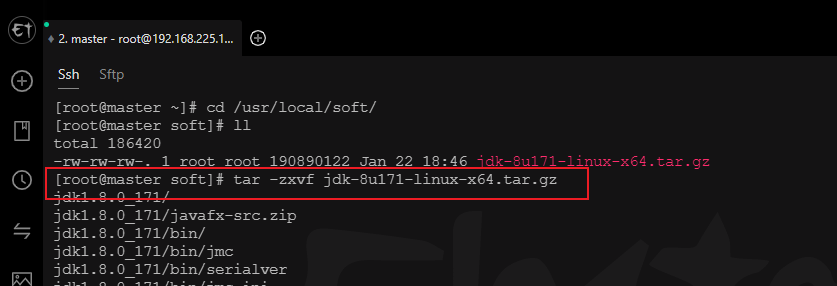
# 解压安装包
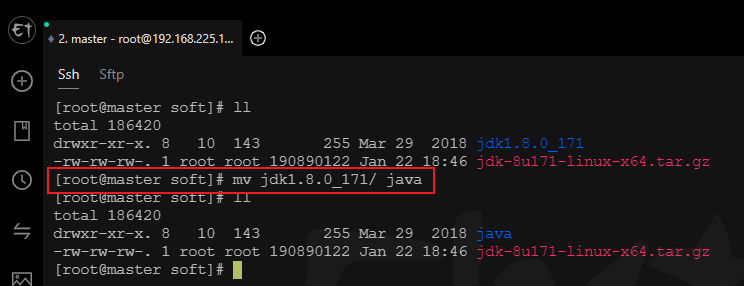
tar -zxvf jdk-8u171-linux-x64.tar.gz
# 修改名称mv jdk1.8.0_171/ java
配置环境变量
# 编辑profile文件
vi /etc/profile
# 在文件的末尾添加
export JAVA_HOME=/usr/local/soft/java # 修改为自己的JAVA路径
export PATH=$PATH:$JAVA_HOME/bin
重新加载环境变量
source /etc/profile
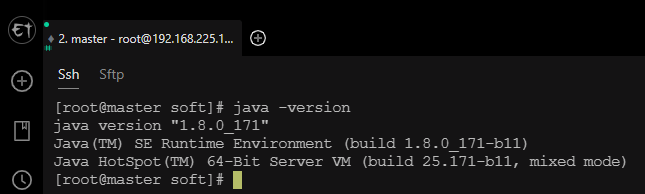
验证是否配置成功
java -version
配置从节点虚拟机
克隆虚拟机
快照备份当前虚拟机再克隆俩台虚拟机
设置IP地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# node1 只需要修改IPADDR 这里推荐设置成连续IP
IPADDR=192.168.225.101
# node2 一样的操作设置
IPADDR=192.168.225.102
# 重启网络
systemctl restart network
设置主机名
# node1
hostnamectl set-hostname node1
# node2
hostnamectl set-hostname node2
# 修改完成后重新连接虚拟机
配置hosts文件
# 三台虚拟机都需要如下操作
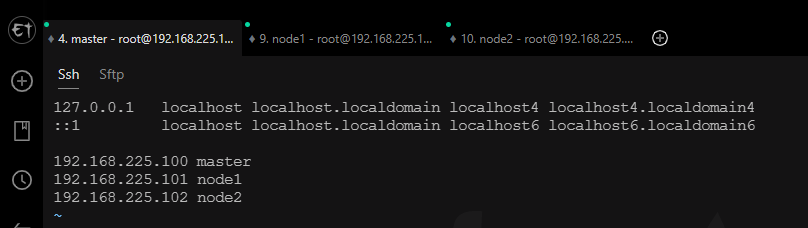
vi /etc/hosts
# 添加IP和主机名
192.168.225.100 master
192.168.225.101 node1
192.168.225.102 node2
配置免密登录
# 只需要在master虚拟机上配置主节点到从节点即可# 1.生成密钥
ssh-keygen -t rsa
# 2.配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3.测试免密登录 不需要输入密码直接切换过去则配置成功# 从master分别登录node1、node2
ssh node1
ssh node2
集群搭建
安装hadoop
上传hadoop安装包并解压
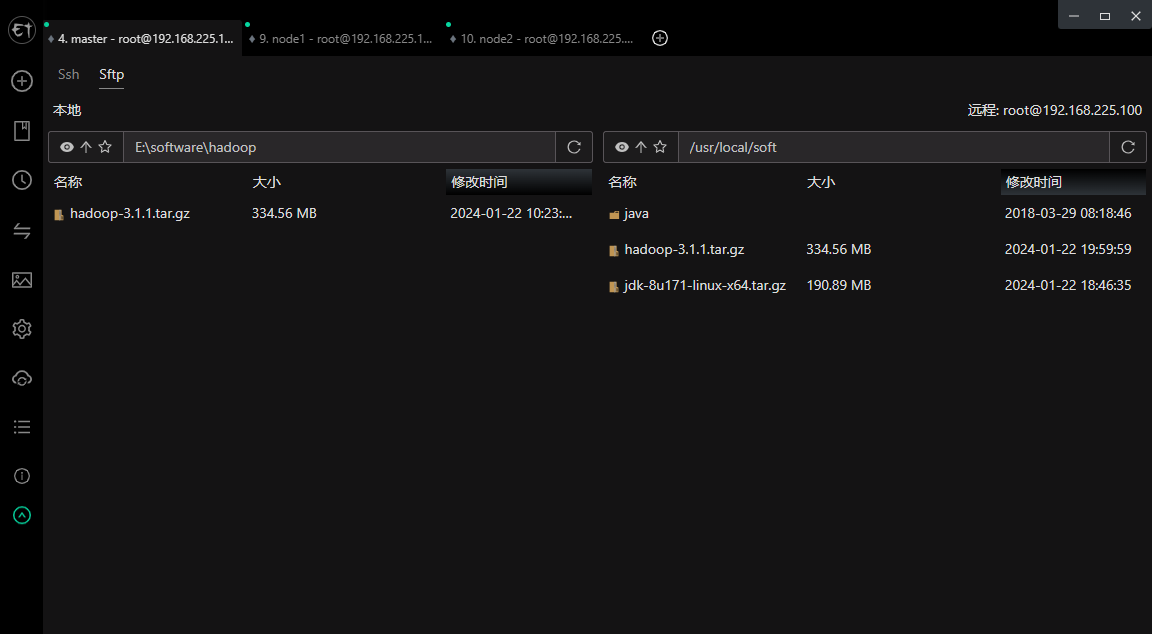
cd /usr/local/soft/# 解压安装包
tar -zxvf hadoop-3.1.1.tar.gz
# 修改名称mv hadoop-3.1.1.tar.gz hadoop
配置环境变量
vi /etc/profile
# 增加以下配置
export HADOOP_HOME=/usr/local/soft/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# 重新加载环境变量
source /etc/profile
配置Hadoop文件
# 先切换到配置文件所在目录
cd /usr/local/soft/hadoop/etc/hadoop/
hadoop-env.sh
vi hadoop-env.sh
# 在文件末尾添加以下配置exportJAVA_HOME=/usr/local/soft/java #java路径exportHDFS_NAMENODE_USER=root
exportHDFS_DATANODE_USER=root
exportHDFS_SECONDARYNAMENODE_USER=root
exportYARN_RESOURCEMANAGER_USER=root
exportYARN_NODEMANAGER_USER=root
core-site.xml
vi core-site.xml
# 在<configuration></configuration>中插入以下内容<property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/soft/hadoop/data</value># hadoop路径</property><property><name>fs.trash.interval</name><value>1440</value></property>
hdfs-site.xml
vi hdfs-site.xml
# 在<configuration></configuration>中插入以下内容<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property>
mapred-site.xml
vi mapred-site.xml
# 在<configuration></configuration>中插入以下内容<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
yarn-site.xml
vi yarn-site.xml
# 在<configuration></configuration>中插入以下内容<property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property>
workers
vi workers
# 添加如下
node1
node2
分发hadoop到从节点虚拟机
# 先回到soft目录cd /usr/local/soft/
# 分发到node1scp -r hadoop node1:`pwd`# 分发到node2scp -r hadoop node2:`pwd`# 顺便将环境变量文件分发过去省去配置步骤cd /etc/
scp -r profile node1:`pwd`scp -r profile node2:`pwd`# 分发完成后node1和node2都需要重新加载环境变量source /etc/profile

集群启动
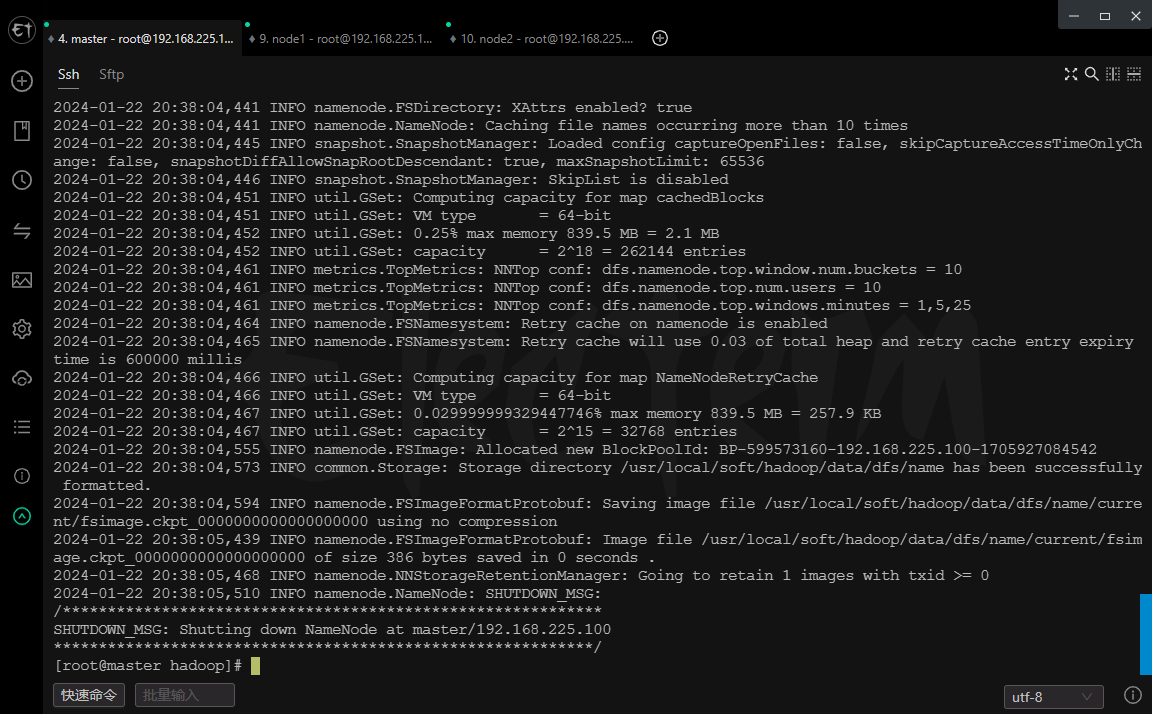
格式化namenode
# 只需要在第一次启动时执行
hdfs namenode -format
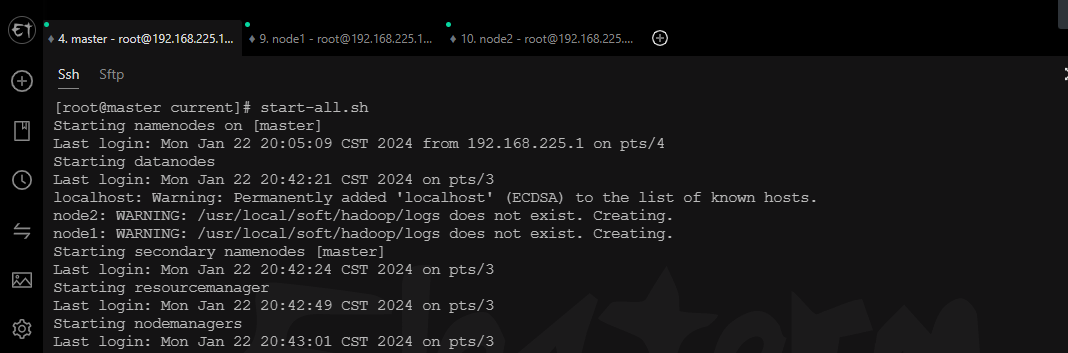
启动Hadoop集群
start-all.sh
检查虚拟机进程
master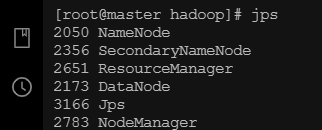
node1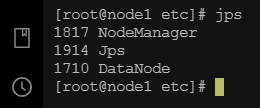
node2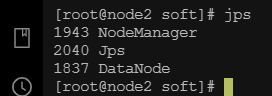
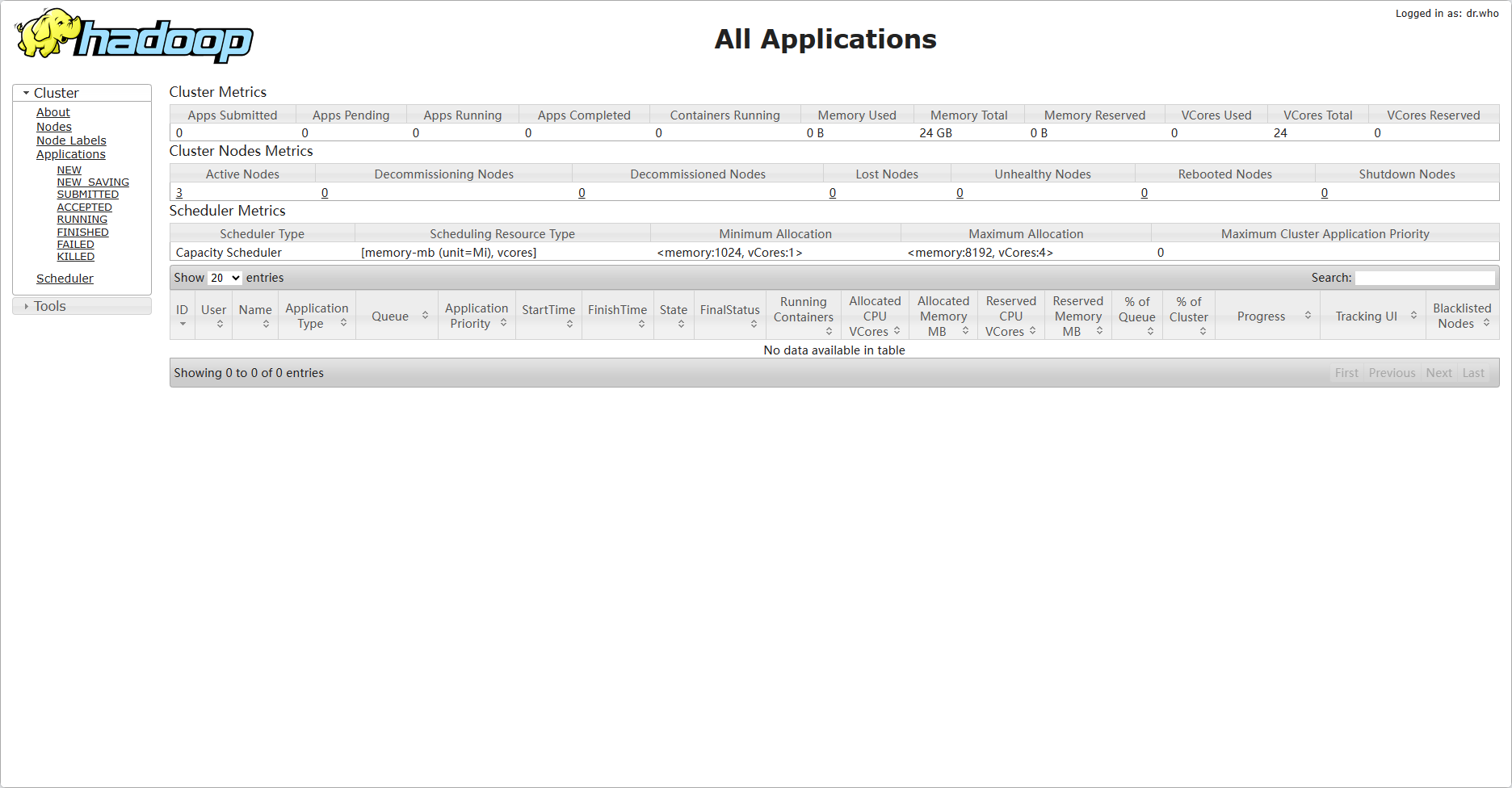
访问Web页面
HDFS
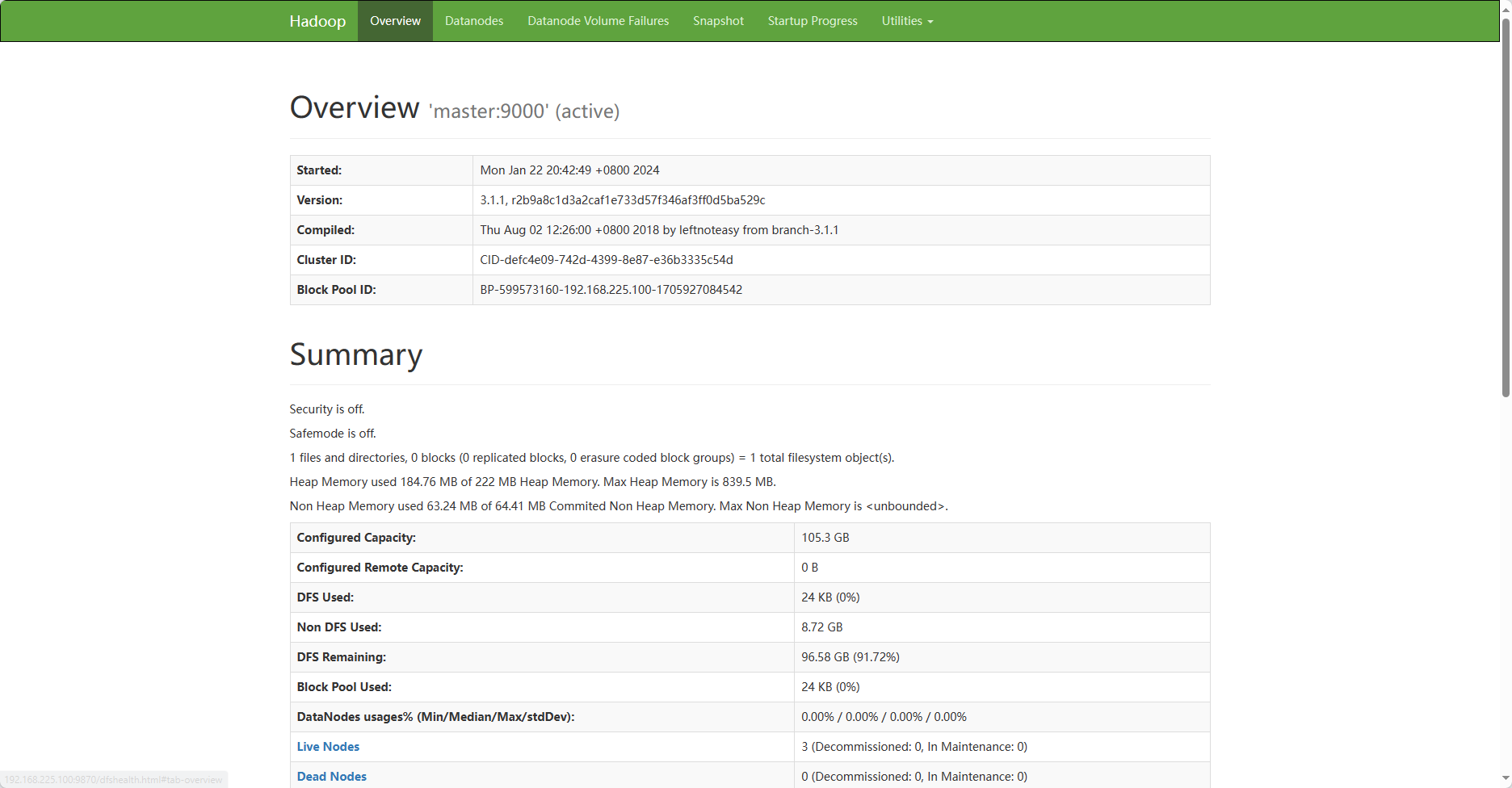
YARN
集群重置
如果需要重置Hadoop集群
停止集群
stop-all.sh
删除所有节点产生的数据文件
# 三台虚拟机都需要执行
cd /usr/local/soft/hadoop
rm-rf data/
重新格式化namenode
hdfs namenode -format
启动集群
start-all.sh
本文转载自: https://blog.csdn.net/weixin_49184448/article/details/135829978
版权归原作者 大数据·流浪法师 所有, 如有侵权,请联系我们删除。
版权归原作者 大数据·流浪法师 所有, 如有侵权,请联系我们删除。