
环境说明
- flink-1.13.1-bin-scala_2.11.tgz
- hadoop-2.7.3.tar.gz
- flink-cdc-connectors(git clone源码编译)
- hudi(git clone源码编译)
- spark-2.4.8-bin-hadoop2.7.tgz
- scala-2.11
- oracle jdk-1.8.x
版本问题
flink cdc与flink对应版本
https://ververica.github.io/flink-cdc-connectors/master/content/about.html#supported-flink-versions
hudi与flink版本
编译所需jar包
编译flink-cdc-connectors
- 进入flink-cdc-connectors目录,修改flink-cdc-connectors/pom.xml文件中flink的版本号为1.13.1
<flink.version>1.13.1</flink.version>
- maven编译
mvn clean package -DskipTests
- 编译完成,将以下jar包拷贝到flink-1.13.1/lib下
flink-cdc-connectors/flink-sql-connector-mysql-cdc/target/flink-sql-connector-mysql-cdc-2.1-SNAPSHOT.jar
flink-cdc-connectors/flink-sql-connector-postgres-cdc/target/flink-sql-connector-postgres-cdc-2.1-SNAPSHOT.jar
flink-cdc-connectors/flink-format-changelog-json/target/flink-format-changelog-json-2.1-SNAPSHOT.jar
编译hudi
- 进入hudi目录,修改hudi/pom.xml,修改对应组件的版本,由于flink使用的是scala-2.11版本,spark3.x版本以上默认使用scala-2.12预编译,为了节省时间,我们在此使用spark2.4.8以scala-2.11预编译的版本,对应的hadoop版本为2.7
<flink.version>1.13.1</flink.version>
<hadoop.version>2.7.3</hadoop.version>
<spark2.version>2.4.8</spark2.version>
- maven编译
mvn clean package -DskipTests
- 编译完成,将以下jar包拷贝到flink-1.13.1/lib下
hudi/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.11-0.10.0-SNAPSHOT.jar
- 将以下jar包拷贝到spark-2.4.8-bin-hadoop2.7/jars下
hudi/packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.11-0.10.0-SNAPSHOT.jar
- 将以下jar包拷贝到hadoop-2.7.3/share/hadoop/hdfs/下
hudi/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar
- 另外为了把数据写入ES和kafka中,需要下载以下jar包,并拷贝到flink-1.13.1/lib下
flink-sql-connector-elasticsearch7_2.11-1.13.1.jar
flink-sql-connector-kafka_2.11-1.13.1.jar
- flink sink到hudi还需要以下jar包
flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
- 所有依赖放置完成后的flink-1.13.1/lib如下
Docker中创建所需的组件
- 创建一个目录,创建一个新文件docker-compose.yml,内容如下,包含postgres mysql es kibana kafka zookeeper组件:
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=1234
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
elasticsearch:
image: elastic/elasticsearch:7.6.0
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
kibana:
image: elastic/kibana:7.6.0
ports:
- "5601:5601"
zookeeper:
image: wurstmeister/zookeeper:3.4.6
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.2.1
ports:
- "9092:9092"
- "9094:9094"
depends_on:
- zookeeper
environment:
- KAFKA_ADVERTISED_LISTENERS=INSIDE://:9094,OUTSIDE://localhost:9092
- KAFKA_LISTENERS=INSIDE://:9094,OUTSIDE://:9092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_CREATE_TOPICS="user_behavior:1:1"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- 进入目录,启动并初始化所有容器
docker-compose build
docker-compose up -d
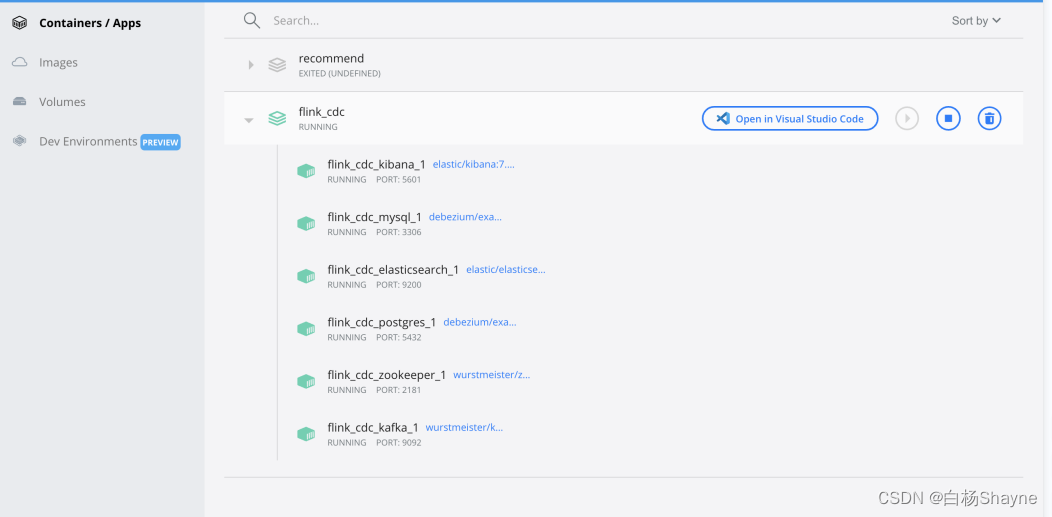
- 打开docker 应用,可以看到组件已经全部启动
初始化数据
- 通过docker命令进入mysql容器内部
docker-compose exec mysql mysql -uroot -p123456
- 初始化MySQL数据
-- MySQL
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- 是否下单
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
- 通过docker命令进入postgres容器内部
docker-compose exec postgres psql -h localhost -U postgres
- 初始化postgres数据
-- PG
CREATE TABLE shipments (
shipment_id SERIAL NOT NULL PRIMARY KEY,
order_id SERIAL NOT NULL,
origin VARCHAR(255) NOT NULL,
destination VARCHAR(255) NOT NULL,
is_arrived BOOLEAN NOT NULL
);
ALTER SEQUENCE public.shipments_shipment_id_seq RESTART WITH 1001;
ALTER TABLE public.shipments REPLICA IDENTITY FULL;
INSERT INTO shipments
VALUES (default,10001,'Beijing','Shanghai',false),
(default,10002,'Hangzhou','Shanghai',false),
(default,10003,'Shanghai','Hangzhou',false);
修改环境变量、hadoop配置文件并启动hadoop
- 修改环境变量vim ~/.zshrc 或者 vim /etc/profile
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin
export SCALA_HOME=/xxx/xxx/xxx/xxx/xxx/xxx/scala
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/xxx/xxx/xxx/xxx/xxx/xxx/spark
export PATH=$PATH:$SPARK_HOME/bin
export MAVEN_HOME=/xxx/xxx/xxx/xxx/xxx/xxx/apache-maven
export PATH=$PATH:$MAVEN_HOME/bin
export HADOOP_HOME=/xxx/xxx/xxx/xxx/xxx/xxx/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export FLINK_HOME=/xxx/xxx/xxx/xxx/xxx/xxx/flink
export PATH=$PATH:$FLINK_HOME/bin
export PATH=/xxx/xxx/xxx/xxx/xxx/xxx/protobuf/bin:$PATH
修改完成执行命令 source ~/.zshrc 或者source /etc/profile让环境变量生效
- 修改hadoop-2.7.3/etc/hadoop/core-site.xml,如果目录不存在,给创建上
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/xxx/xxx/xxx/xxx/xxx/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
- 修改hadoop-2.7.3/etc/hadoop/hdfs-site.xml,如果目录不存在,给创建上
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/xxx/xxx/xxx/xxx/xxx/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/xxx/xxx/xxx/xxx/xxx/hadoop-2.7.3/dfs/data</value>
</property>
</configuration>
- 修改hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 修改hadoop-2.7.3/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name
</name>
<value>yarn</value>
</property>
</configuration>
- 启动,hadoop目录下执行
./sbin/start-all.sh
# 格式化namenode
hdfs namenode -format
如果不能发现Java环境变量,建议直接修改hadoop-2.7.3/etc/hadoop/hadoop-env.sh
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8/Contents/Home
- 启动完成,通过jps命令查看组件是否已启动,NameNode、SecondaryNameNode、DataNode、ResourceManager、NodeManager均已启动,启动完成,可以登录浏览器:http://localhost:50070/查看hdfs状态
➜ hadoop-2.7.3 jps
63696 NodeManager
63969 Jps
62178 DataNode
62805 SecondaryNameNode
63510 ResourceManager
2392
61789 NameNode
修改flink配置文件、并启动
- 修改flink-1.13.1/conf/flink-conf.yaml,增加slots数量,修改jobmanager的端口
taskmanager.numberOfTaskSlots: 1
taskmanager.numberOfTaskSlots: 6
- 启动flink
./bin/start-cluster.sh
- 启动完成,使用jps命令查看进程状态,访问flink webUI http://localhost:8081/
➜ flink-1.13.1 jps
2320 SecondaryNameNode
3137 ResourceManager
3489 NodeManager
85906 TaskManagerRunner
16275 NameNode
1813 DataNode
2392
85565 StandaloneSessionClusterEntrypoint
86431 Jps
- 启动flink的sql client
./bin/sql-client.sh
创建flink cdc表,分别以mysql、pgsql作为数据源,将数据写入到es中和kafka中
分别创建mysql和pgsql的flink-sql表
--Flink SQL
-- 设置 checkpoint 间隔为 3 秒
Flink SQL> SET execution.checkpointing.interval = 3s;
Flink SQL> set dfs.client.block.write.replace-datanode-on-failure.enable = ture;
Flink SQL> set dfs.client.block.write.replace-datanode-on-failure.policy = NEVER;
Flink SQL> CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
Flink SQL> CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
Flink SQL> CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
sink到es
Flink SQL> CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
shipment_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://localhost:9200',
'index' = 'enriched_orders'
);
Flink SQL> INSERT INTO enriched_orders
SELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrived
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
LEFT JOIN shipments AS s ON o.order_id = s.order_id;
- 打开kibana webUI http://localhost:5601/,创建索引

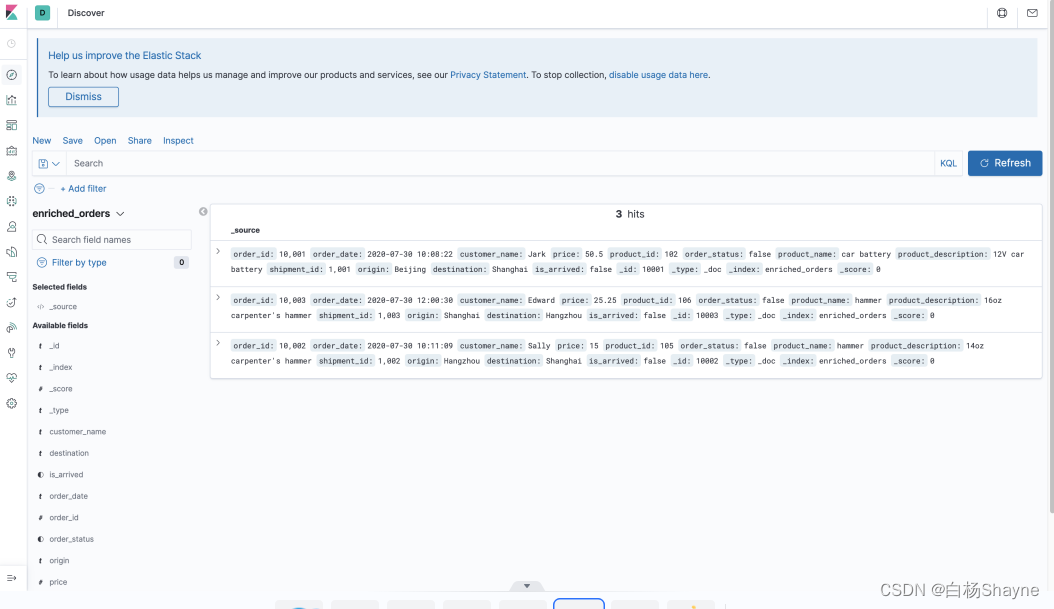
- 修改 mysql 和 postgres 里面的数据,观察 elasticsearch 里的结果
-- 修改MySQL
INSERT INTO orders
VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);
-- 修改PG
INSERT INTO shipments
VALUES (default,10004,'Shanghai','Beijing',false);
-- 修改MySQL
UPDATE orders SET order_status = true WHERE order_id = 10004;
-- 修改PG
UPDATE shipments SET is_arrived = true WHERE shipment_id = 1004;
-- 修改MySQL
DELETE FROM orders WHERE order_id = 10004;
sink到kafka
--Flink SQL
Flink SQL> CREATE TABLE kafka_gmv (
day_str STRING,
gmv DECIMAL(10, 5)
) WITH (
'connector' = 'kafka',
'topic' = 'kafka_gmv',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'changelog-json'
);
Flink SQL> INSERT INTO kafka_gmv
SELECT DATE_FORMAT(order_date, 'yyyy-MM-dd') as day_str, SUM(price) as gmv
FROM orders
WHERE order_status = true
GROUP BY DATE_FORMAT(order_date, 'yyyy-MM-dd');
-- 读取 Kafka 的 changelog 数据,观察 materialize 后的结果
Flink SQL> SELECT * FROM kafka_gmv;
- 观察kafka的数据
docker-compose exec kafka bash -c 'kafka-console-consumer.sh --topic kafka_gmv --bootstrap-server kafka:9092 --from-beginning'
- 更新 orders 数据,观察SQL CLI 和 kafka console 的输出
-- 更新MySQL
UPDATE orders SET order_status = true WHERE order_id = 10001;
UPDATE orders SET order_status = true WHERE order_id = 10002;
UPDATE orders SET order_status = true WHERE order_id = 10003;
INSERT INTO orders
VALUES (default, '2020-07-30 17:33:00', 'Timo', 50.00, 104, true);
UPDATE orders SET price = 40.00 WHERE order_id = 10005;
DELETE FROM orders WHERE order_id = 10005;

sink到hudi
- 创建flink-hudi表
Flink SQL> CREATE TABLE enriched_orders_hudi (
order_id INT PRIMARY KEY NOT ENFORCED,
order_date TIMESTAMP(3),
customer_name STRING,
price DOUBLE,
product_id INT,
order_status BOOLEAN,
`partition` VARCHAR(20)
) PARTITIONED BY (`partition`) WITH (
'connector' = 'hudi'
,'write.precombine.field' = 'order_date'
,'table.type' = 'MERGE_ON_READ'
,'path' = 'hdfs://localhost:9000/hudi/enriched_orders_hudi'
,'compaction.tasks' = '1'
,'compaction.trigger.strategy' = 'num_or_time'
,'compaction.delta_commits' = '10'
,'compaction.delta_seconds' = '10'
,'read.tasks' = '1'
,'read.streaming.enabled' = 'true'
,'hoodie.datasource.query.type' = 'snapshot'
,'read.streaming.check-interval' = '10'
,'hoodie.datasource.merge.type' = 'payload_combine'
,'read.utc-timezone' = 'false'
);
-- 插入数据
Flink SQL> INSERT INTO enriched_orders_hudi
SELECT *,DATE_FORMAT(order_date, 'yyyyMMdd')
FROM orders;
-- 查看表是否有数据
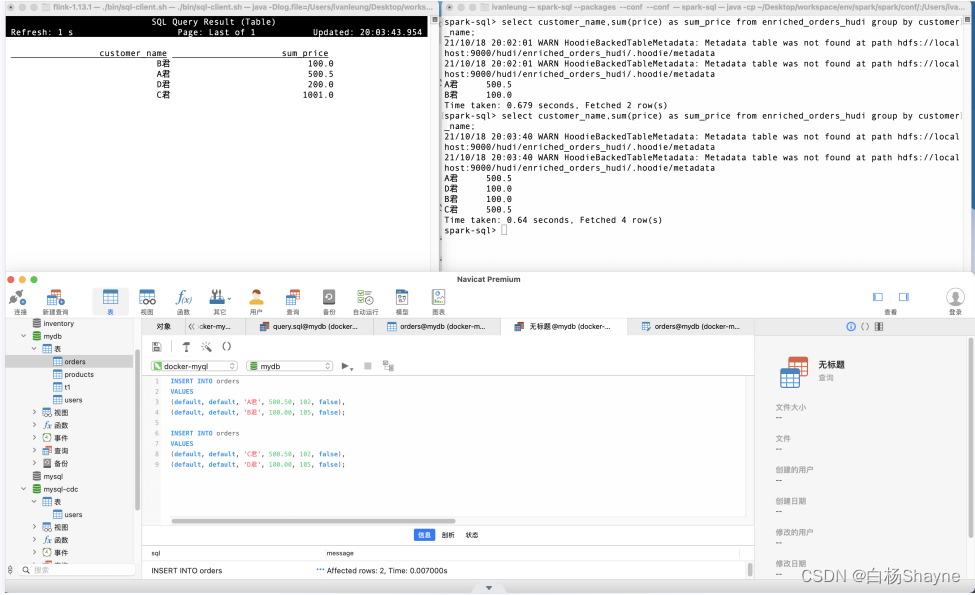
Flink SQL> select customer_name,sum(price) as sum_price from enriched_orders_hudi group by customer_name;
spark-sql使用hudi已有数据,创建spark-sql hudi表
- 启动spark-sql,必须用带以下参数的方式启动
spark-sql --packages org.apache.hudi:hudi-spark-bundle_2.11:0.9.0,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
- 创建spark-sql hudi表,不指定schema,自适应,分区,主键为可选
create table if not exists enriched_orders_hudi
using hudi
location 'hdfs://localhost:9000/hudi/enriched_orders_hudi'
options (
type = 'mor',
primaryKey = 'order_id',
preCombineField = 'order_date'
)
partitioned by (`partition`);
- 验证
-- 在mysql的orders表中数据
INSERT INTO orders
VALUES
(default, default, 'A君', 500.50, 102, false),
(default, default, 'B君', 100.00, 105, false);
INSERT INTO orders
VALUES
(default, default, 'C君', 500.50, 102, false),
(default, default, 'D君', 100.00, 105, false);
-- 分别在flink sql client 和spark-sql cli执行
Flink SQL> select customer_name,sum(price) as sum_price from enriched_orders_hudi group by customer_name;
spark-sql> select customer_name,sum(price) as sum_price from enriched_orders_hudi group by customer_name;
-- 效果分别如下两图
-- 更新、删除自行演示

遇到的问题
- 由于我是单节点的hadoop,单个datanode会触发数据写入hdfs失败,报错信息如下:
Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try.
网上文章大部分都是让修改hdfs-site.xml添加两个配置项:
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
但并不起效,因为导致这一问题的原因是客户端产生的不是服务端产生的,所以,需要修改hdfs的客户端,那么当前使用的是spark-sql,因此客户端就是spark-sql所持有的hdfs client,因此需要在启动spark-sql之后设置两个参数:
spark-sql> set dfs.client.block.write.replace-datanode-on-failure.enable = ture;
spark-sql> set dfs.client.block.write.replace-datanode-on-failure.policy = NEVER;
报错问题解决,并且可以通过insert into往hudi插入数据,通过select * from table查到hudi中的数据。
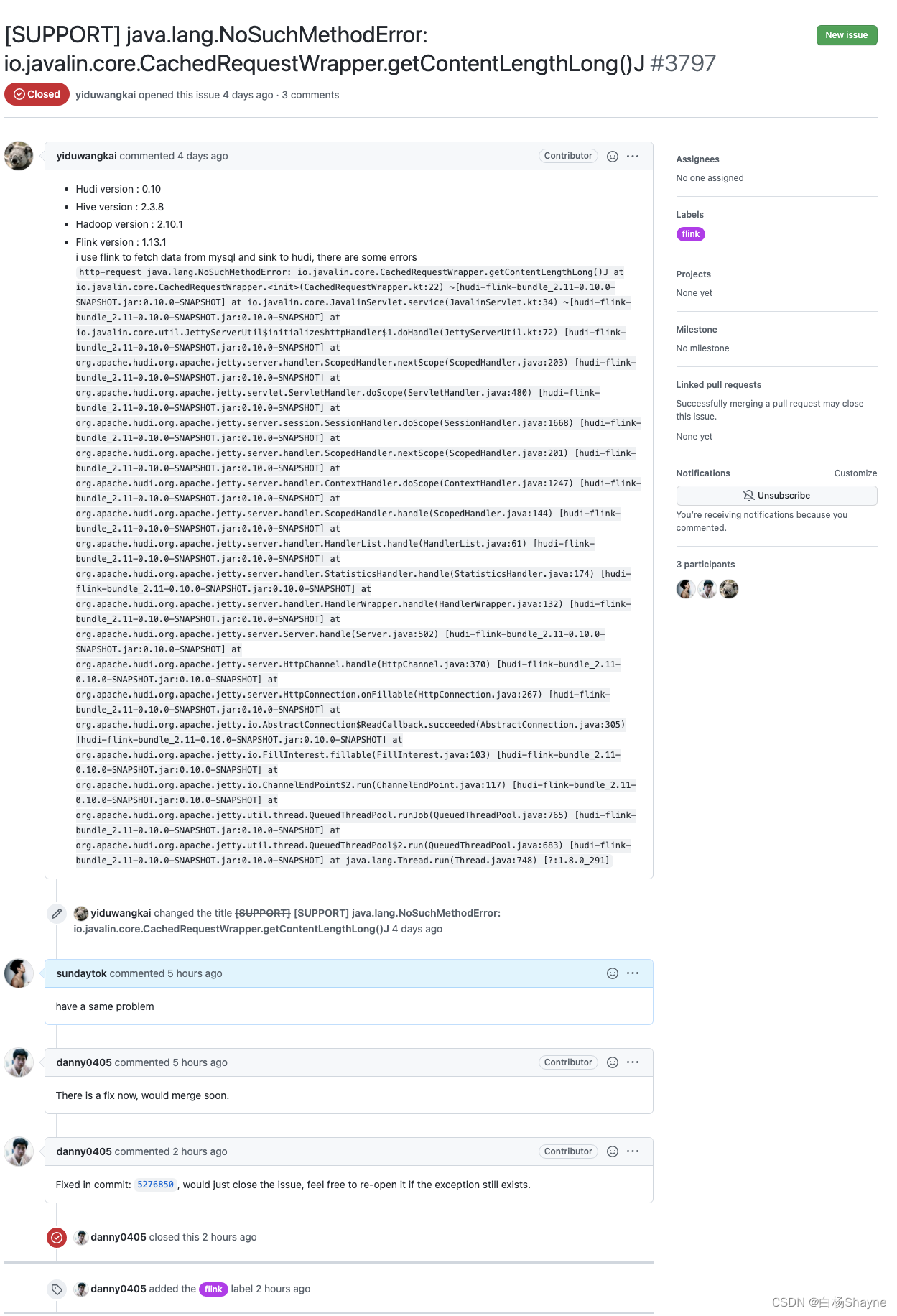
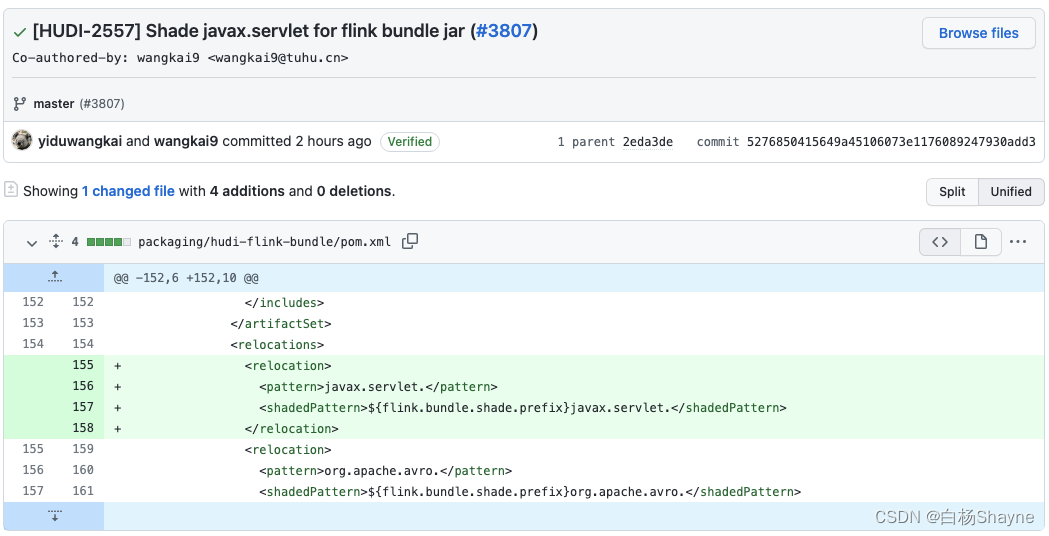
- http-request java.lang.NoSuchMethodError: io.javalin.core.CachedRequestWrapper.getContentLengthLong()J

解决办法:
直接给官方提issue https://github.com/apache/hudi/issues/3797,问题解决
版权归原作者 白杨Shayne 所有, 如有侵权,请联系我们删除。