
Kyuubi1.6.0是支持Spark3.0.0的最后一个版本,再往上需要更高的Spark版本,我这里就没再测试。
一、下载Kyuubi与Spark
由于我这里的集群是ambari安装的,默认Spark版本为Spark2,因此需要配置一下Spark的环境,下载Spark3.0.0的安装包,百度云连接在这里:
链接:https://pan.baidu.com/s/1ZdM5IOyHoE52-KMd_EoMYg?pwd=6666
提取码:6666
二、配置Spark3与Kyuubi
2.1配置Spark(非ambari安装的就省略吧,直接解压spark3)
1.下载好上面spark3的包,解压
unzip spark3.zip
2.然后cd spark3 执行
tar -xvf spark-3.0.0-bin-hadoop3.2.tgz
mv spark-3.0.0-bin-hadoop3.2 spark3
cp ../jars/* spark3/jars/
mv spark3 /usr/hdp/3.1.0.0-78/
3.将/usr/hdp/3.1.0.0-78/spark2/conf下的配置文件spark-env.sh和spark-defaults.conf复制到
/usr/hdp/3.1.0.0-78/spark3/conf路径下
4.在spark-defaults.conf这个文件中添加
spark.driver.extraJavaOptions -Dhdp.version=3.1.0.0-78
spark.yarn.am.extraJavaOptions -Dhdp.version=3.1.0.0-78
测试一下好不好使,提交个测试任务到yarn
/usr/hdp/3.1.0.0-78/spark3/bin/spark-submit --master yarn --name spark-pi --class org.apache.spark.examples.SparkPi /usr/hdp/3.1.0.0-78/spark3/examples/jars/spark-examples_2.11-2.3.2.3.1.0.0-78.jar
2.2配置Kyuubi
1.下载好上面Kyuubi的包,我这里上传到了/home/tools,解压
tar -xvf apache-kyuubi-1.6.0-incubating-bin.tgz
mv apache-kyuubi-1.6.0-incubating-bin.tgz kyuubi-1.6.0
cd kyuubi-1.6.0/conf
cp kyuubi-defaults.conf.template kyuubi-defaults.conf
cp kyuubi-env.sh.template kyuubi-env.sh
2.首先配置kyuubi-env.sh,按照实际的路径写
export JAVA_HOME=/usr/java/jdk1.8.0_271-amd64
export SPARK_HOME=/usr/hdp/3.1.0.0-78/spark3
export HADOOP_CONF_DIR=/usr/hdp/3.1.0.0-78/hadoop/etc/hadoop
3.配置kyuubi-defaults.conf(重点来了,我的集群是kerberos权限,hive是ladp认证)
kyuubi.ha.enabled true
kyuubi.ha.client.class org.apache.kyuubi.ha.client.zookeeper.ZooKeeperDiscoveryClient
kyuubi.ha.namespace kyuubi_cluster
kyuubi.ha.zookeeper.quorum zk1,zk2,zk3
kyuubi.ha.client.port 2181
kyuubi.ha.zookeeper.auth.type KERBEROS
kyuubi.ha.zookeeper.auth.principal zookeeper/[email protected]
kyuubi.ha.zookeeper.auth.keytab /etc/xxxx.keytab
kyuubi.authentication LDAP
kyuubi.authentication.ldap.url ldap://xx.xxx.xx.xx:389
kyuubi.authentication.ldap.base.dn ou=people,dc=hadoop,dc=com
kyuubi.kinit.principal hive/[email protected]
kyuubi.kinit.keytab /etc/security/keytabs/hive.service.keytab
kyuubi.frontend.bind.host xx.xxx.xx.xx
kyuubi.frontend.bind.port 10009
要是不配高可用kyuubi.ha那堆就可以省略了,如果配了,集群是KERBEROS权限的话,直接把ZK节点下面的那个keytab文件拿过来用,ambari安装的一般在/etc/security/keytabs/zk.service.keytab,没有去生成一下
kyuubi.kinit.principal和kyuubi.kinit.keytab是认证集群权限的,你这用户需要可以提交到yarn,可以访问hive,我这里偷懒就用了hive,也可以新建kyuubi用户,然后授权,principal必须为三段式命名,类似我上面写的,不过多介绍了,keytab就是与之对应的验证文件。而且hadoop必须要有以下配置,如下图
hadoop.proxyuser.用户.groups 设置为*就可以
hadoop.proxyuser.用户.hosts 可以为*或者具体的主机名,逗号隔开
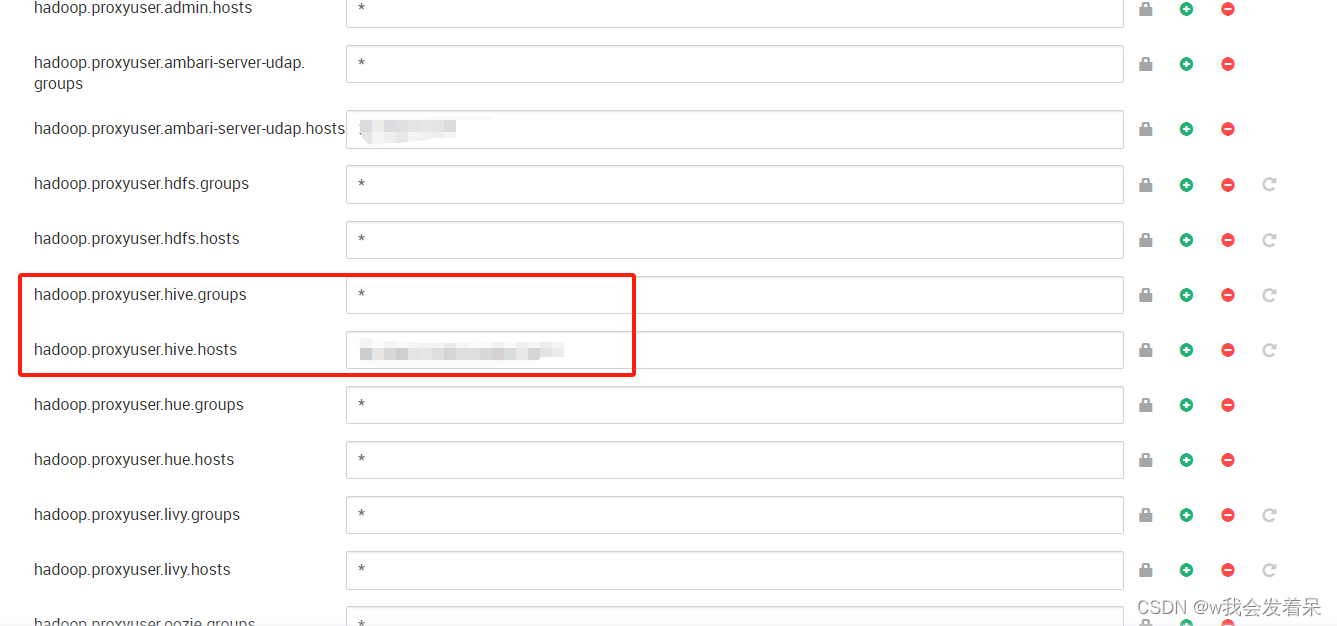
这里别的用户我也尝试了,死活不成功,只有hive成功了,不知道什么原因哈,用别的用户就会出现xxxxxx is not allowed to impersonate xxxxxx,奇了怪了,后面解决了我再更新哈,暂时先用hive
kyuubi登录设置为ladp验证,正好和hive一样,这三个
kyuubi.authentication LDAP
kyuubi.authentication.ldap.url ldap://xx.xxx.xx.xx:389
kyuubi.authentication.ldap.base.dn ou=people,dc=hadoop,dc=com
三、启动Kyuubi
1.以上都设置好后就可以启动了,进入到kyuubi-1.6.0/bin
./kyuubi start
2.beeline连接
./beeline -u 'jdbc:hive2://xxxx.xxx.xxx.xxx:10009/' -n用户名 -p密码
这里的用户名密码就是ldap添加的,这样就是实现了多租户管理。
如果你配置了高可用的话,beeline要写下面的
beeline -u "jdbc:hive2://zk1:2181,zk2:2181,zk3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=xxxxxxx"(这里的zooKeeperNamespace是你在kyuubi-defaults.conf设置的kyuubi.ha.namespace)
spark参数设置详见Deploy Kyuubi engines on Yarn — Apache Kyuubi
我这里也设置了一些,大家可以参考,常见的也就这些
beeline -u "jdbc:hive2://xxxxxxx:10009/xxxxxxx?spark.yarn.queue=xxxxxx;spark.driver.memory=40g;spark.executor.memory=20g;spark.executor.cores=10;spark.executor.instances=20"(spark.executor.instances就是spark里面的spark.num.executors)
下面的kyuubi-defaults.conf里面的参数
kyuubi.engine.share.level (CONNECTION用户不共享连接,USER同一用户共享连接)
kyuubi.session.force.cancel true(当你把beeline那个ctrl+c之后,yarn上提交的任务会自动kill掉,这个就比较好了)
版权归原作者 w我会发着呆 所有, 如有侵权,请联系我们删除。