
系列文章目录
第一章:JAVA Spark的学习和开发【由浅入深】之搭建windows本地开发环境搭建
文章目录
前言
最近个人学习了一些大数据相关的开发技术,想分享给那些刚入门,不知道怎么入手开发的小伙伴们。文本主要介绍了如果在windows的环境下搭建单机版spark应用程序【java】
一、安装包和环境准备
spark安装包:spark-3.3.1-bin-hadoop3.tgz
hadoop安装包:hadoop-3.3.0.tar.gz
hadoop相关安装包:winutils-master.zip
jdk1.8安装包:jdk-8u401-windows-x64.exe
maven安装包:apache-maven-3.9.6-bin.zip
我的电脑用的是win11,最好是win10以上的环境去用,win7和win8没有测试过。
二、安装步骤
1.安装及环境变量配置
下载完成的spark、hadoop和winutils包解压缩,并统一放到磁盘的某个目录下
我的安装目录为:D:\bigdata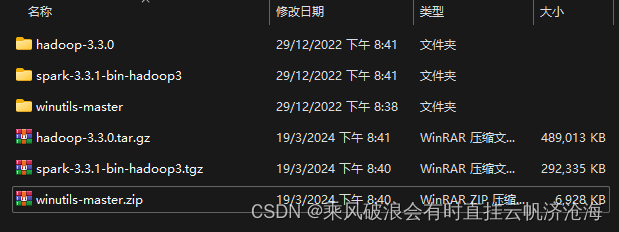
注意! winutils-master包解压完成后进入目录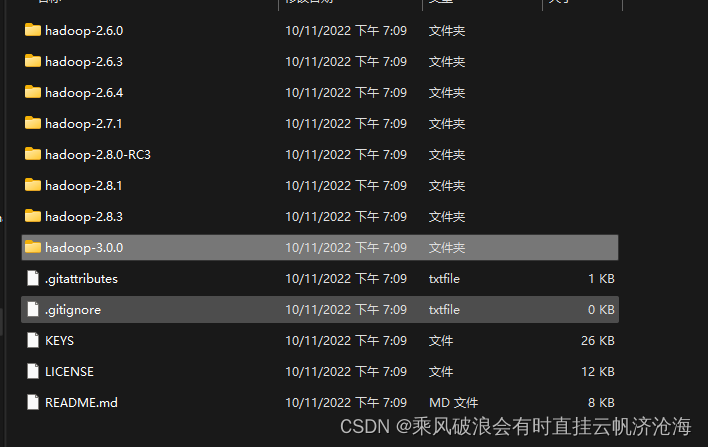
然后进入hadoop-3.0.0,把目录下的bin目录及文件复制替换到hadoop-3.3.0的bin目录中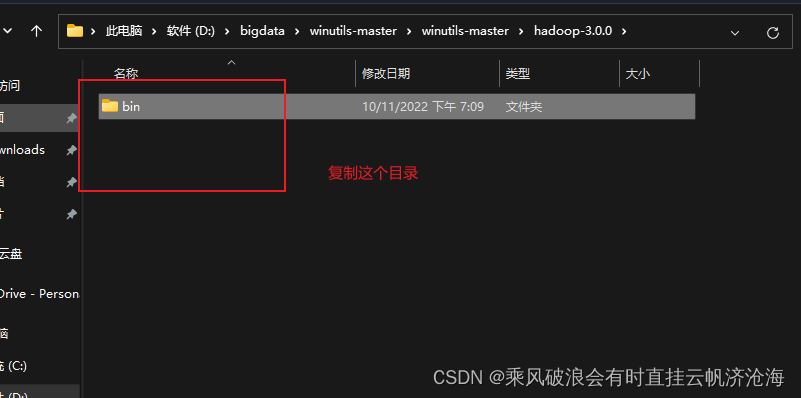
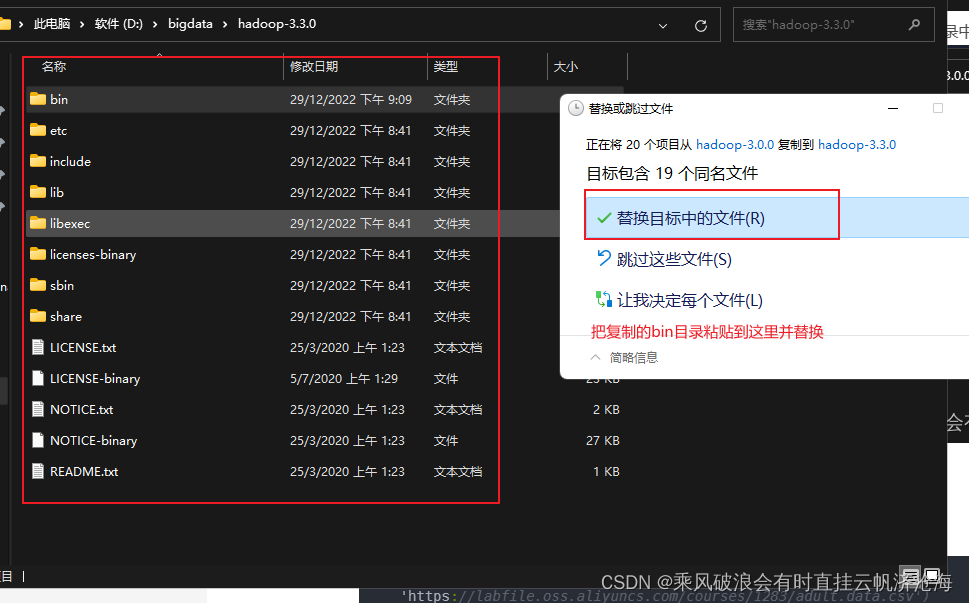
以上步骤操作完成后,开始设置系统环境变量。
新建:HADOOP_HOME D:\bigdata\hadoop-3.3.0(此路径为我的安装路径)
新建:SPARK_HOME D:\bigdata\spark-3.3.1-bin-hadoop3(此路径为我的安装路径)
PATH变量新增:
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
2.编写java spark代码
代码如下(示例):
public staticvoidmain(String[] args){getSparkCreate();}
public static SparkSession getSparkCreate(){
SparkSession sparkSession = SparkSession.builder().appName("sxw").master("local[*]")//单机版用local参数*为使用可用线程执行.getOrCreate();
List<user> ls = new ArrayList<>();
user kk = new user();
kk.setName("小明");
kk.setAge(19);
ls.add(kk);
Dataset<Row> dataset = sparkSession.createDataFrame(ls,user.class);
dataset.show();
dataset.printSchema();return sparkSession;}
user实体类
@Datapublicclass user implementsSerializable{privateString name;privateInteger age;}
pom依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.codehaus.janino</groupId><artifactId>janino</artifactId><version>3.0.8</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency>
总结
基本的搭建步骤都在上面了,有不对的环节或者按步骤搭建完成不能用的同学,欢迎留言评论
版权归原作者 乘风破浪会有时直挂云帆济沧海 所有, 如有侵权,请联系我们删除。