
前言
Spark RDD 中提供了丰富的行动算子可以帮助我们完成对RDD数据的一些常用统计、聚合等业务的操作,下面将常用的行动算子进行使用总结;
**reduce **
函数签名
def reduce(f: (T, T) => T): T
函数说明
聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 聚合数据
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
sc.stop()
}
}
代码中将列表中的数据进行两两聚合,运行代码,观察控制台输出效果

**count **
函数签名
def count(): Long
函数说明
返回 RDD 中元素的个数
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
// 聚合数据
//val reduceResult: Int = rdd.reduce(_+_)
//println(reduceResult)
val counts = rdd.count()
println(counts)
sc.stop()
}
}
统计列表中元素个数,运行上面的代码,观察输出效果
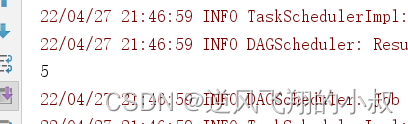
first
函数签名
def first(): T
函数说明
返回 RDD 中的第一个元素
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
// 聚合数据
//val reduceResult: Int = rdd.reduce(_+_)
//println(reduceResult)
//val counts = rdd.count()
//println(counts)
val first = rdd.first()
println(first)
sc.stop()
}
}
运行程序,观察控制台输出结果

take
函数签名
def take(num: Int): Array[T]
函数说明
返回一个由 RDD 的前 n 个元素组成的数组
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
val takeResult = rdd.take(2)
println(takeResult.mkString(","))
sc.stop()
}
}
运行上面的程序,观察控制台输出效果

**takeOrdered **
函数签名
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
函数说明
返回该 RDD 排序后的前 n 个元素组成的数组
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
// 返回 RDD 中元素的个数
val result: Array[Int] = rdd.takeOrdered(2)
println(result.mkString(","))
sc.stop()
}
}
运行上面的程序,观察控制台输出

**aggregate **
函数签名
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
函数说明
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
案例展示
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
// 将该 RDD 所有元素相加得到结果
val result: Int = rdd.aggregate(0)(_ + _, _ + _)
//val result: Int = rdd.aggregate(10)(_ + _, _ + _)
println(result)
sc.stop()
}
}
运行上面的程序,观察控制台输出结果

fold
函数签名
def fold(zeroValue: T)(op: (T, T) => T): T
函数说明
折叠操作,aggregate 的简化版操作
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_+_)
println(foldResult)
sc.stop()
}
}
运行上面的程序,观察控制台输出效果

countByKey
函数签名
def countByKey(): Map[K, Long]
函数说明
统计每种 key 的个数
案例操作
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ReduceTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2,
"b"), (3, "c"), (3, "c")))
// 统计每种 key 的个数
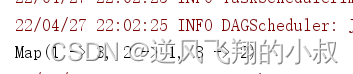
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
sc.stop()
}
}
运行上面的程序,观察控制台输出
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。