
文章目录

多余的话就不说了,直接上菜!

1、查询SQL尽量不要使用select *,而是select具体字段。
反例子:
select*from employee;
正例子:
select id,name from employee;
理由:
- 只取需要的字段,节省资源、减少网络开销。
- select * 进行查询时,很可能就不会使用到覆盖索引了,就会造成回表查询。
2、如果知道查询结果只有一条或者只要最大/最小一条记录,建议用limit 1
假设现在有employee员工表,要找出一个名字叫jay的人.
CREATETABLE`employee`(`id`int(11)NOTNULL,`name`varchar(255)DEFAULTNULL,`age`int(11)DEFAULTNULL,`date`datetimeDEFAULTNULL,`sex`int(1)DEFAULTNULL,PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8;
反例:
select id,name from employee where name='jay'
正例
select id,name from employee where name='jay'limit1;
理由:
- 加上limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高。
- 当然,如果name是唯一索引的话,是不必要加上limit 1了,因为limit的存在主要就是为了防止全表扫描,从而提高性能,如果一个语句本身可以预知不用全表扫描,有没有limit ,性能的差别并不大。
3、应尽量避免在where子句中使用or来连接条件
新建一个user表,它有一个普通索引userId,表结构如下:
CREATETABLE`user`(`id`int(11)NOTNULLAUTO_INCREMENT,`userId`int(11)NOTNULL,`age`int(11)NOTNULL,`name`varchar(255)NOTNULL,PRIMARYKEY(`id`),KEY`idx_userId`(`userId`))ENGINE=InnoDBDEFAULTCHARSET=utf8;
假设现在需要查询userid为1或者年龄为18岁的用户,很容易有以下SQL
反例:
select*fromuserwhere userid=1or age =18
正例:
//使用union allselect * from user where userid=1 union allselect * from user where age = 18//或者分开两条sql写:select * from user where userid=1select * from user where age = 18
理由:
- 使用or可能会使索引失效,从而全表扫描。
对于or+没有索引的age这种情况,假设它走了userId的索引,但是走到age查询条件时,它还得全表扫描,也就是需要三步过程:全表扫描+索引扫描+合并如果它一开始就走全表扫描,直接一遍扫描就完事。mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引可能失效,看起来也合情合理。
4、优化limit分页
我们日常做分页需求时,一般会用 limit 实现,但是当偏移量特别大的时候,查询效率就变得低下。
反例:
select id,name,age from employee limit10000,10
正例:
//方案一 :返回上次查询的最大记录(偏移量)select id,name from employee where id>10000 limit 10.//方案二:order by + 索引select id,name from employee order by id limit 10000,10//方案三:在业务允许的情况下限制页数:
理由:
- 当偏移量最大的时候,查询效率就会越低,因为Mysql并非是跳过偏移量直接去取后面的数据,而是先把偏移量+要取的条数,然后再把前面偏移量这一段的数据抛弃掉再返回的。
- 如果使用优化方案一,返回上次最大查询记录(偏移量),这样可以跳过偏移量,效率提升不少。
- 方案二使用order by+索引,也是可以提高查询效率的。
- 方案三的话,建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
5、优化你的like语句
日常开发中,如果用到模糊关键字查询,很容易想到like,但是like很可能让你的索引失效。
反例:
select userId,name fromuserwhere userId like'%123';
正例:
select userId,name fromuserwhere userId like'123%';
理由:
- 把%放前面,并不走索引,如下:
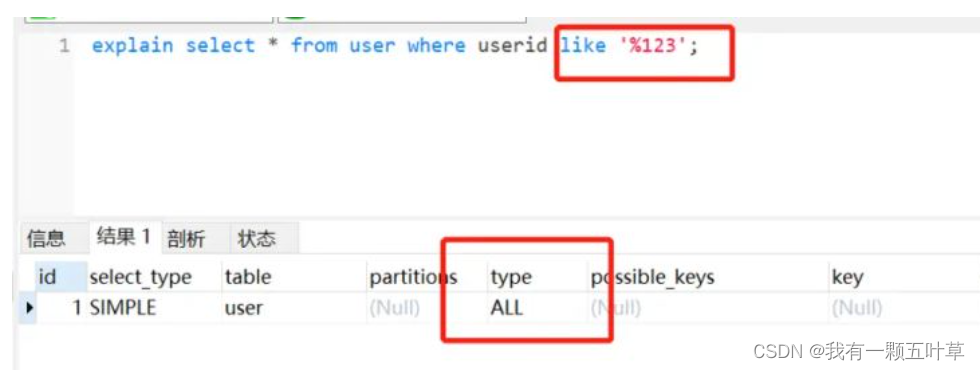
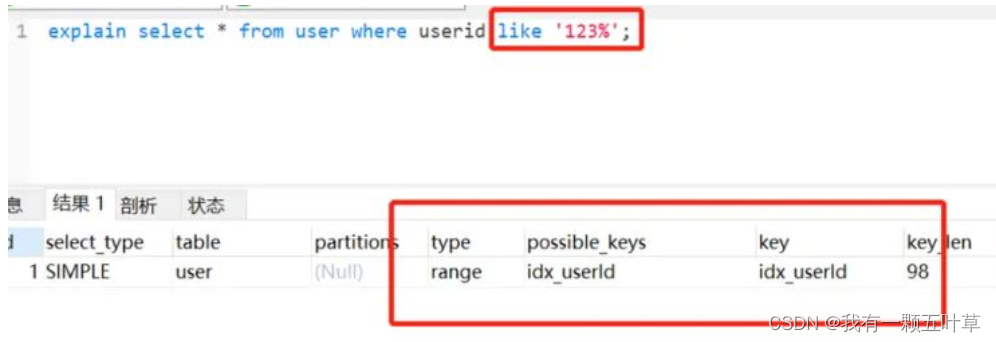
- 把% 放关键字后面,还是会走索引的。如下 :
6、使用where条件限定要查询的数据,避免返回多余的行
假设业务场景是这样:查询某个用户是否是会员。
Java 代码
反例:
List<Long> userIds = sqlMap.queryList("select userId from user where isVip=1");boolean isVip = userIds.contains(userId);
正例:
Long userId = sqlMap.queryObject("select userId from user where userId='userId' and isVip='1' ")boolean isVip = userId!=null;
理由:
- 需要什么数据,就去查什么数据,避免返回不必要的数据,节省开销。
7、尽量避免在索引列上使用mysql的内置函数
业务需求:查询最近七天内登陆过的用户(假设loginTime加了索引)
反例:
select userId,loginTime from loginuser where Date_ADD(loginTime,Interval7DAY)>=now();
正例:
explainselect userId,loginTime from loginuser where loginTime >= Date_ADD(NOW(),INTERVAL-7DAY);
理由:
- 索引列上使用mysql的内置函数,索引失效
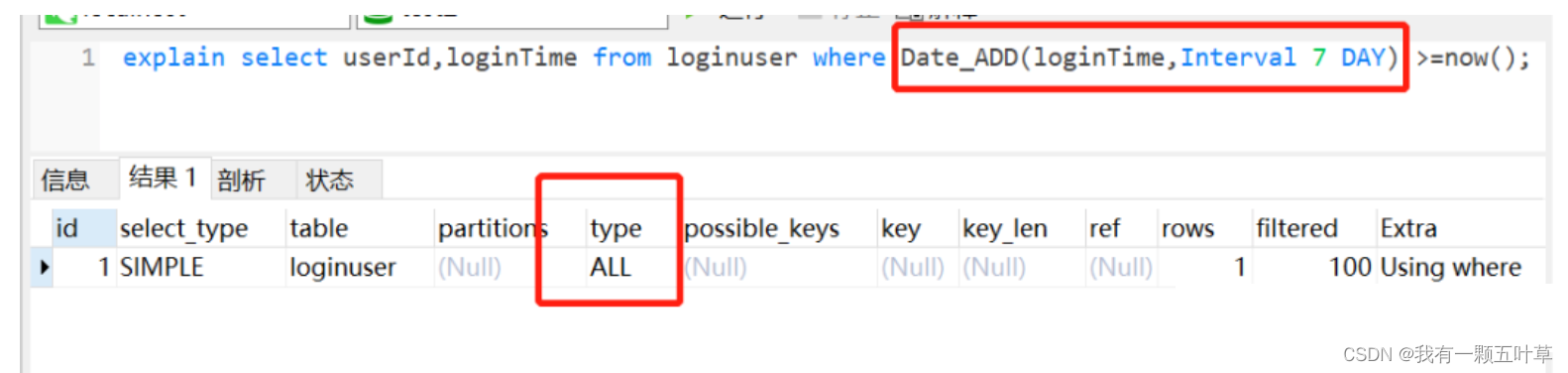
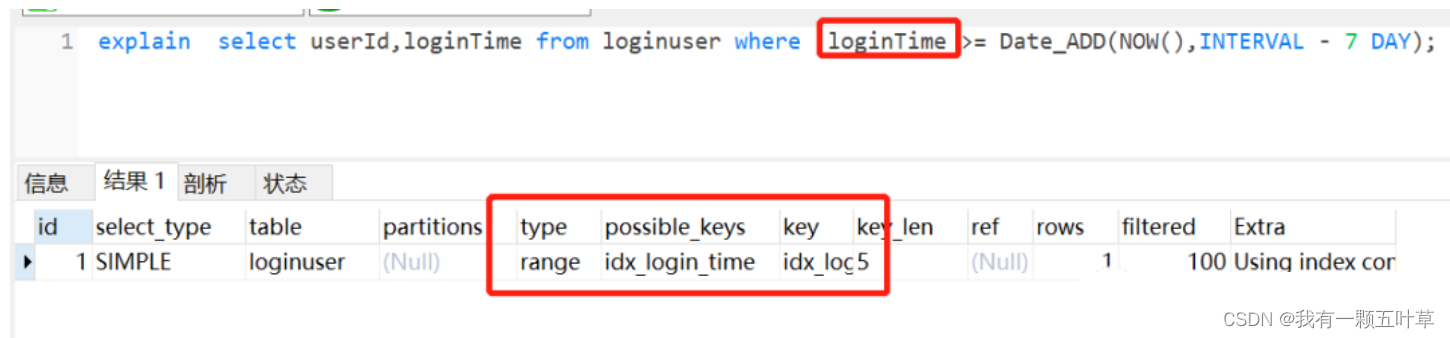
- 如果索引列不加内置函数,索引还是会走的。
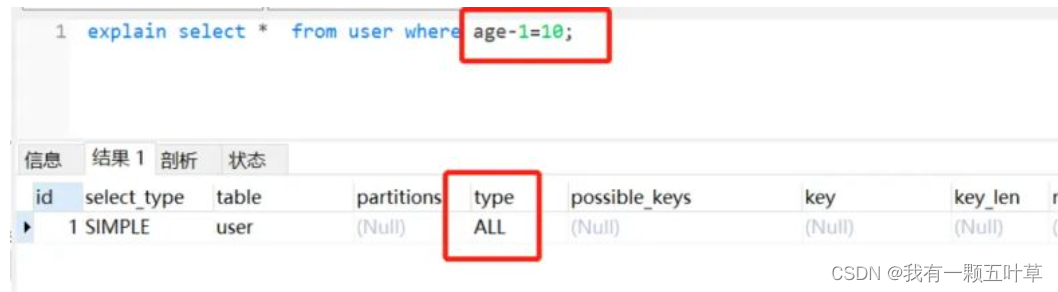
8、应尽量避免在where子句中对字段进行表达式操作,这将导致系统放弃使用索引而进行全表扫
反例:
select*fromuserwhere age-1=10;
正例:
select*fromuserwhere age =11;
理由:
- 虽然age加了索引,但是因为对它进行运算,索引直接迷路了。。
9、Inner join 、left join、right join,优先使用Inner join,如果是left join,左边表结果尽量小
- Inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集
- left join 在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
- right join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
都满足SQL需求的前提下,推荐优先使用Inner join(内连接),如果要使用left join,左边表数据结果尽量小,如果有条件的尽量放到左边处理。
反例:
select*from tab1 t1 leftjoin tab2 t2 on t1.size = t2.size where t1.id>2;
正例:
select*from(select*from tab1 where id >2) t1 leftjoin tab2 t2 on t1.size = t2.size;
理由:
- 如果inner join是等值连接,或许返回的行数比较少,所以性能相对会好一点。
- 同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。
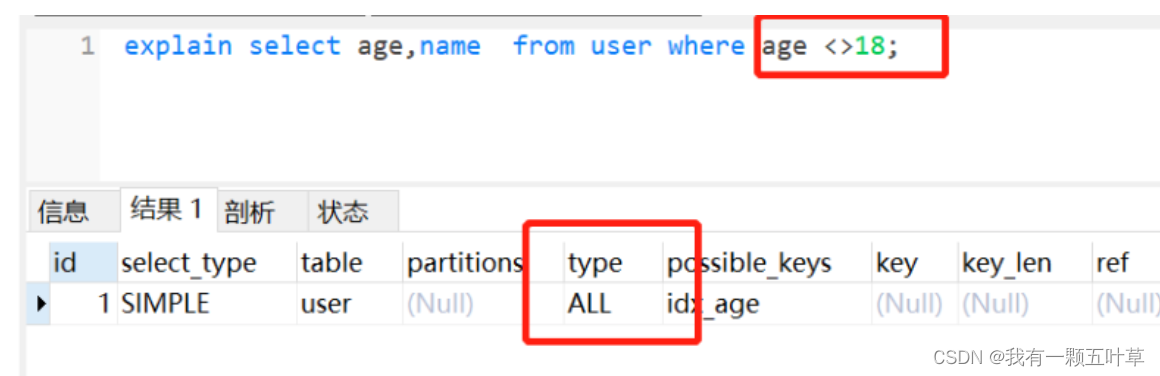
10、应尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
反例:
select age,name fromuserwhere age <>18;
正例:
//可以考虑分开两条sql写select age,name from user where age <18;select age,name from user where age >18;
理由:
- 使用!=和<>很可能会让索引失效

本文转载自: https://blog.csdn.net/m0_60915009/article/details/131695942
版权归原作者 我有一颗五叶草 所有, 如有侵权,请联系我们删除。
版权归原作者 我有一颗五叶草 所有, 如有侵权,请联系我们删除。