
文章目录
Spark环境准备
安装
spark 3.3.1
的步骤就不多说了。我这边在
/etc/profile
配置的
export SPARK_HOME=/usr/local/src/spark-3.3.1-bin-hadoop3
。
将hudi编译后的与spark相关的包
/usr/local/src/hudi-0.12.0/packaging/hudi-spark-bundle/target/hudi-spark3.3-bundle_2.12-0.12.0.jar
拷贝到
/usr/local/src/spark-3.3.1-bin-hadoop3/jars
这样就可以通过
spark
来操作hudi (Hadoop集群的启动自行处理)。
下面的例子基本都是参考hudi0.12.0官网文档中的例子结合自身服务器完成的。
Spark-shell 方式
Hudi支持的Spark3版本0.12.x3.3.x (default build), 3.2.x, 3.1.x0.11.x3.2.x (default build, Spark bundle only), 3.1.x0.10.x3.1.x (default build), 3.0.x0.7.0 - 0.9.03.0.x0.6.0 and prior不支持Spark3
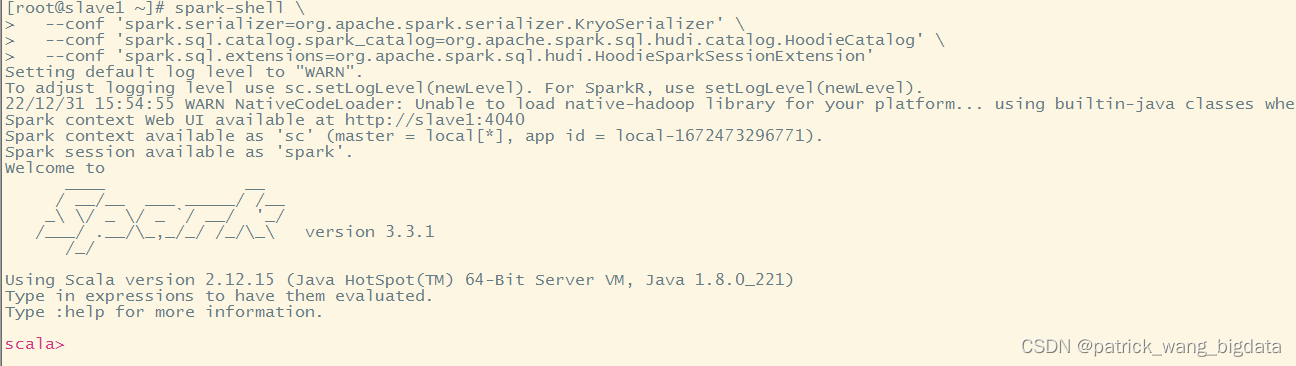
启动命令,需要显示指定一些参数
对于Spark3.2及以上版本,必须指定
spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog
spark-shell \--conf'spark.serializer=org.apache.spark.serializer.KryoSerializer'\--conf'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'\--conf'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
插入数据
设置表名、表路径以及hudi提供的数据生成器
// spark-shellimportorg.apache.hudi.QuickstartUtils._
importscala.collection.JavaConversions._
importorg.apache.spark.sql.SaveMode._
importorg.apache.hudi.DataSourceReadOptions._
importorg.apache.hudi.DataSourceWriteOptions._
importorg.apache.hudi.config.HoodieWriteConfig._
importorg.apache.hudi.common.model.HoodieRecord
val tableName ="hudi_trips_cow"// 这里是本地路径val basePath ="file:///tmp/hudi/hudi_trips_cow"// 可以使用hdfs路径, 前提是spark必须能连上hadoop环境// val basePath = "/tmp/hudi/hudi_trips_cow"val dataGen =new DataGenerator
用
Spark-shell
的方式写入hudi不需要手动显示建表,在第一次插入数据时就会自动建表。
// 插入数据val inserts = convertToStringList(dataGen.generateInserts(10))// 打印生成的数据 后面备用
inserts.foreach(println)// 将生成的json数据转化成DataFrameval df = spark.read.json(spark.sparkContext.parallelize(inserts,2))// 查看df对应的schema (自动解析)
df.dtypes.foreach(println)// 插入数据
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY,"ts").
option(RECORDKEY_FIELD_OPT_KEY,"uuid").
option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
注意第一次写入hudi表时这里的mode参数必须写成
Overwrite
。
我们对上面写的插入hudi表的代码做一定的解析
// 生成的数据即 inserts 集合的内容,能看到uuid都是不一样的。{"ts":1672386949058,"uuid":"cae66749-74ea-43c1-bdcb-a66beca6e56e","rider":"rider-213","driver":"driver-213","begin_lat":0.4726905879569653,"begin_lon":0.46157858450465483,"end_lat":0.754803407008858,"end_lon":0.9671159942018241,"fare":34.158284716382845,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672213281821,"uuid":"85f71297-4eaf-4995-931c-01226f420d07","rider":"rider-213","driver":"driver-213","begin_lat":0.6100070562136587,"begin_lon":0.8779402295427752,"end_lat":0.3407870505929602,"end_lon":0.5030798142293655,"fare":43.4923811219014,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672136180394,"uuid":"c9408af0-b64c-4e41-ab58-03c9086fc0ac","rider":"rider-213","driver":"driver-213","begin_lat":0.5731835407930634,"begin_lon":0.4923479652912024,"end_lat":0.08988581780930216,"end_lon":0.42520899698713666,"fare":64.27696295884016,"partitionpath":"americas/united_states/san_francisco"}{"ts":1671896860357,"uuid":"db42e8c3-ce9c-49d7-a35b-1a7437b53f89","rider":"rider-213","driver":"driver-213","begin_lat":0.21624150367601136,"begin_lon":0.14285051259466197,"end_lat":0.5890949624813784,"end_lon":0.0966823831927115,"fare":93.56018115236618,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672416111725,"uuid":"efb91807-2615-433a-b743-18a46a360141","rider":"rider-213","driver":"driver-213","begin_lat":0.40613510977307,"begin_lon":0.5644092139040959,"end_lat":0.798706304941517,"end_lon":0.02698359227182834,"fare":17.851135255091155,"partitionpath":"asia/india/chennai"}{"ts":1672134610405,"uuid":"ce3a01e9-d5c9-4154-a993-384288e235f6","rider":"rider-213","driver":"driver-213","begin_lat":0.8742041526408587,"begin_lon":0.7528268153249502,"end_lat":0.9197827128888302,"end_lon":0.362464770874404,"fare":19.179139106643607,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672075624664,"uuid":"71bbfaef-57f4-4279-b373-4401edba1281","rider":"rider-213","driver":"driver-213","begin_lat":0.1856488085068272,"begin_lon":0.9694586417848392,"end_lat":0.38186367037201974,"end_lon":0.25252652214479043,"fare":33.92216483948643,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672091725941,"uuid":"86c94192-6b82-4bc9-ad88-cda1980c4122","rider":"rider-213","driver":"driver-213","begin_lat":0.0750588760043035,"begin_lon":0.03844104444445928,"end_lat":0.04376353354538354,"end_lon":0.6346040067610669,"fare":66.62084366450246,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672418641807,"uuid":"2965f3ab-579a-487c-bcea-87fbb898329f","rider":"rider-213","driver":"driver-213","begin_lat":0.651058505660742,"begin_lon":0.8192868687714224,"end_lat":0.20714896002914462,"end_lon":0.06224031095826987,"fare":41.06290929046368,"partitionpath":"asia/india/chennai"}{"ts":1671979635294,"uuid":"77f89906-1aa8-4da3-ba61-76485a4f5b1e","rider":"rider-213","driver":"driver-213","begin_lat":0.11488393157088261,"begin_lon":0.6273212202489661,"end_lat":0.7454678537511295,"end_lon":0.3954939864908973,"fare":27.79478688582596,"partitionpath":"americas/united_states/san_francisco"}// 数据对应的schema(begin_lat,DoubleType)(begin_lon,DoubleType)(driver,StringType)(end_lat,DoubleType)(end_lon,DoubleType)(fare,DoubleType)(partitionpath,StringType)(rider,StringType)(ts,LongType)(uuid,StringType)// 一些常用参数,设置插入并行度的
scala> getQuickstartWriteConfigs()
res6: java.util.Map[String,String]={hoodie.upsert.shuffle.parallelism=2, hoodie.insert.shuffle.parallelism=2, hoodie.bulkinsert.shuffle.parallelism=2, hoodie.delete.shuffle.parallelism=2}// 该参数是用来处理多条记录的recordkey相同时根据哪个字段取哪条数据// 有点类似于hive的 row_number() over(partition by 主键 order by 预合并字段 desc) rn where rn = 1
scala> PRECOMBINE_FIELD_OPT_KEY
res7:String= hoodie.datasource.write.precombine.field
// 该参数是指定每条数据的主键字段
scala> RECORDKEY_FIELD_OPT_KEY
res8:String= hoodie.datasource.write.recordkey.field
// 该参数是指定每条数据的分区字段// 此处生成的是多级分区 /tmp/hudi/hudi_trips_cow/<region>/<country>/<city>/
scala> PARTITIONPATH_FIELD_OPT_KEY
res9:String= hoodie.datasource.write.partitionpath.field
// 该参数是hudi表名
scala> TABLE_NAME
warning: one deprecation;for details, enable `:setting -deprecation' or `:replay -deprecation'
res10:String= hoodie.table.name
// 该参数是指定数据保存模式, 这里是 overwrite 且如果表存在则重建
scala> Overwrite
res11: org.apache.spark.sql.SaveMode = Overwrite
// 该参数在上面没有显示指定,是用于指定 write operation的,默认就是 upsert
scala> OPERATION_OPT_KEY
res14:String= hoodie.datasource.write.operation
// 该参数在上面没有显示指定,是用于指定 表类型的,默认就是 COW 。表类型一旦确定后面用Append模式写入时必须保持一致
scala> TABLE_TYPE_OPT_KEY
res18:String= hoodie.datasource.write.table.type
通过
tree -a /tmp/hudi/hudi_trips_cow
命令我们查看到hudi表已经生成,且有对应的
.hoodie
元数据目录以及对应的分区目录如
americas/united_states/san_francisco
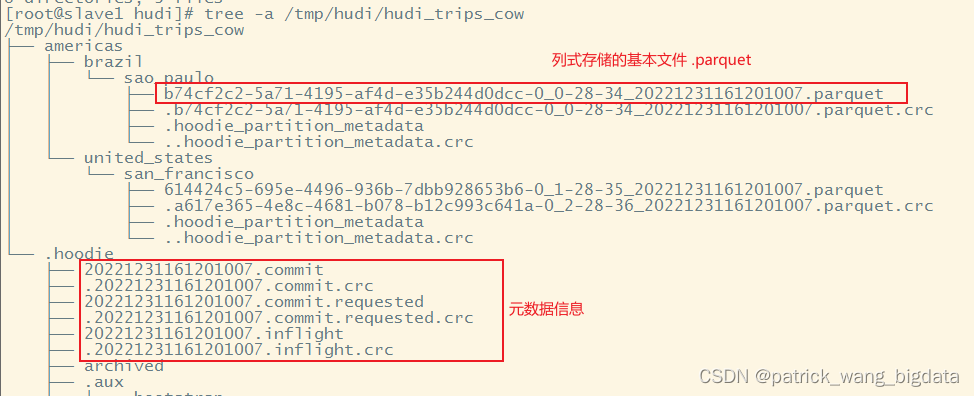
上面的基本文件的命名规范是
FileId_Token_InstantTimeFileExtension
如
b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-28-34_20221231161201007.parquet
文件所属的
FileId
就是
b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0
,对应的
Instant Time
为
20221231161201007

查询数据
通过
spark.read
读取hudi表的数据为
DataFrame
,然后映射成临时表用sql进行查询
// 读取hudi表数据为DataFrameval tripsSnapshotDF = spark.read.
format("hudi").
load(basePath)// 将DataFrame映射成一张临时表
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")// 查询 fare < 20.0 的数据// show函数第一个参数表示显示多少条,第二个参数表示字段过长时是否截取字段
spark.sql("select * from hudi_trips_snapshot where fare < 20.0").show(100,false)+-------------------+---------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+------------------+------------------+----------+------------------+-------------------+------------------+---------+-------------+------------------------------------+------------------------------------+|_hoodie_commit_time|_hoodie_commit_seqno |_hoodie_record_key |_hoodie_partition_path |_hoodie_file_name |begin_lat |begin_lon |driver |end_lat |end_lon |fare |rider |ts |uuid |partitionpath |+-------------------+---------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+------------------+------------------+----------+------------------+-------------------+------------------+---------+-------------+------------------------------------+------------------------------------+|20221231161201007|20221231161201007_1_4|ce3a01e9-d5c9-4154-a993-384288e235f6|americas/united_states/san_francisco|614424c5-695e-4496-936b-7dbb928653b6-0_1-28-35_20221231161201007.parquet|0.8742041526408587|0.7528268153249502|driver-213|0.9197827128888302|0.362464770874404|19.179139106643607|rider-213|1672134610405|ce3a01e9-d5c9-4154-a993-384288e235f6|americas/united_states/san_francisco||20221231161201007|20221231161201007_2_0|efb91807-2615-433a-b743-18a46a360141|asia/india/chennai |a617e365-4e8c-4681-b078-b12c993c641a-0_2-28-36_20221231161201007.parquet|0.40613510977307|0.5644092139040959|driver-213|0.798706304941517|0.02698359227182834|17.851135255091155|rider-213|1672416111725|efb91807-2615-433a-b743-18a46a360141|asia/india/chennai |+-------------------+---------------------+------------------------------------+------------------------------------+------------------------------------------------------------------------+------------------+------------------+----------+------------------+-------------------+------------------+---------+-------------+------------------------------------+------------------------------------+
注意hudi表有五个隐藏字段,如下所示,意思也不用过多介绍
_hoodie_commit_time
_hoodie_commit_seqno
_hoodie_record_key
_hoodie_partition_path
_hoodie_file_name
时间旅行(Time Travel Query)
查询某个具体时刻
Instant
的hudi表数据
// 再次插入5条新数据,注意这里的mode是Append,因为不是第一次插入hudi表了val inserts_1 = convertToStringList(dataGen.generateInserts(5))
inserts_1.foreach(println)val df_1 = spark.read.json(spark.sparkContext.parallelize(inserts_1,2))
df_1.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY,"ts").
option(RECORDKEY_FIELD_OPT_KEY,"uuid").
option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath){"ts":1672120014026,"uuid":"31d33c1a-6972-4527-8dd5-81c20c52763d","rider":"rider-284","driver":"driver-284","begin_lat":0.7340133901254792,"begin_lon":0.5142184937933181,"end_lat":0.7814655558162802,"end_lon":0.6592596683641996,"fare":49.527694252432056,"partitionpath":"asia/india/chennai"}{"ts":1672200490316,"uuid":"879dc9b6-e62e-44df-bafb-13e170484e55","rider":"rider-284","driver":"driver-284","begin_lat":0.1593867607188556,"begin_lon":0.010872312870502165,"end_lat":0.9808530350038475,"end_lon":0.7963756520507014,"fare":29.47661370147079,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672394126168,"uuid":"2770c069-5465-4e58-86fd-aca6cdf3e4f4","rider":"rider-284","driver":"driver-284","begin_lat":0.7180196467760873,"begin_lon":0.13755354862499358,"end_lat":0.3037264771699937,"end_lon":0.2539047155055727,"fare":86.75932789048282,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672235394640,"uuid":"3815301a-b9dc-4e7d-86a5-7b0368e5a8b8","rider":"rider-284","driver":"driver-284","begin_lat":0.6570857443423376,"begin_lon":0.888493603696927,"end_lat":0.9036309069576131,"end_lon":0.37603706507284995,"fare":63.72504913279929,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1671877544096,"uuid":"b973d602-d3ef-4b2c-9fea-961acfb821b8","rider":"rider-284","driver":"driver-284","begin_lat":0.08528650347654165,"begin_lon":0.4006983139989222,"end_lat":0.1975324518739051,"end_lon":0.908216792146506,"fare":90.25710109008239,"partitionpath":"americas/united_states/san_francisco"}
首先我们通过
.hoodie
元数据信息查看到有两个
Instant
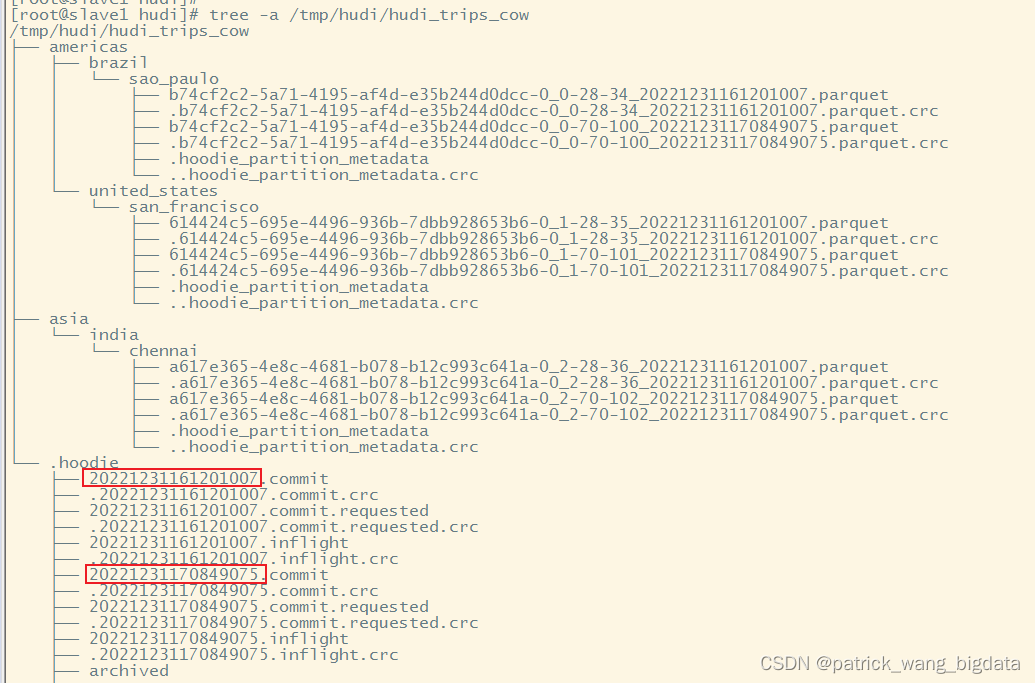
有如下两种(官方是3种,最后一种有点鸡肋)方式去做时间旅行
// 查询 20221231161201007 时刻的数据 ,共有10条是正确的
spark.read.
format("hudi").
option("as.of.instant","20221231161201007").
load(basePath).select("uuid","partitionpath").show(100,false)+------------------------------------+------------------------------------+|uuid |partitionpath |+------------------------------------+------------------------------------+|77f89906-1aa8-4da3-ba61-76485a4f5b1e|americas/united_states/san_francisco||c9408af0-b64c-4e41-ab58-03c9086fc0ac|americas/united_states/san_francisco||db42e8c3-ce9c-49d7-a35b-1a7437b53f89|americas/united_states/san_francisco||71bbfaef-57f4-4279-b373-4401edba1281|americas/united_states/san_francisco||ce3a01e9-d5c9-4154-a993-384288e235f6|americas/united_states/san_francisco||86c94192-6b82-4bc9-ad88-cda1980c4122|americas/brazil/sao_paulo ||cae66749-74ea-43c1-bdcb-a66beca6e56e|americas/brazil/sao_paulo ||85f71297-4eaf-4995-931c-01226f420d07|americas/brazil/sao_paulo ||efb91807-2615-433a-b743-18a46a360141|asia/india/chennai ||2965f3ab-579a-487c-bcea-87fbb898329f|asia/india/chennai |+------------------------------------+------------------------------------+// 查询 20221231170849075 时刻的数据 ,共有15条是正确的
spark.read.
format("hudi").
option("as.of.instant","20221231170849075").
load(basePath).select("uuid","partitionpath").show(100,false)+------------------------------------+------------------------------------+|uuid |partitionpath |+------------------------------------+------------------------------------+|77f89906-1aa8-4da3-ba61-76485a4f5b1e|americas/united_states/san_francisco||c9408af0-b64c-4e41-ab58-03c9086fc0ac|americas/united_states/san_francisco||db42e8c3-ce9c-49d7-a35b-1a7437b53f89|americas/united_states/san_francisco||71bbfaef-57f4-4279-b373-4401edba1281|americas/united_states/san_francisco||ce3a01e9-d5c9-4154-a993-384288e235f6|americas/united_states/san_francisco||b973d602-d3ef-4b2c-9fea-961acfb821b8|americas/united_states/san_francisco||879dc9b6-e62e-44df-bafb-13e170484e55|americas/united_states/san_francisco||2770c069-5465-4e58-86fd-aca6cdf3e4f4|americas/united_states/san_francisco||86c94192-6b82-4bc9-ad88-cda1980c4122|americas/brazil/sao_paulo ||cae66749-74ea-43c1-bdcb-a66beca6e56e|americas/brazil/sao_paulo ||85f71297-4eaf-4995-931c-01226f420d07|americas/brazil/sao_paulo ||3815301a-b9dc-4e7d-86a5-7b0368e5a8b8|americas/brazil/sao_paulo ||efb91807-2615-433a-b743-18a46a360141|asia/india/chennai ||2965f3ab-579a-487c-bcea-87fbb898329f|asia/india/chennai ||31d33c1a-6972-4527-8dd5-81c20c52763d|asia/india/chennai |+------------------------------------+------------------------------------+// 与上面的等价,只是格式不一样
spark.read.
format("hudi").
option("as.of.instant","2022-12-31 17:08:49.075").
load(basePath).select("uuid","partitionpath").show(100,false)
更新数据
注意更新数据的
mode
参数是
Append
// 生成10条更新数据val updates = convertToStringList(dataGen.generateUpdates(10))
updates.foreach(println)val df = spark.read.json(spark.sparkContext.parallelize(updates,2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY,"ts").
option(RECORDKEY_FIELD_OPT_KEY,"uuid").
option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)// 特别注意,生成的10条更新数据里有重复uuid的,那么这个时候根据参数 PRECOMBINE_FIELD_OPT_KEY 设定的ts字段就会取ts大的那一条数据// 如 b973d602-d3ef-4b2c-9fea-961acfb821b8 这个uuid有2条更新数据,写入hudi时会去重选择ts=1672411964233 的数据插入到hudi// 其他重复的数据类似{"ts":1672304648927,"uuid":"b973d602-d3ef-4b2c-9fea-961acfb821b8","rider":"rider-216","driver":"driver-216","begin_lat":0.25770004462445395,"begin_lon":0.8708158608552242,"end_lat":0.48762008412262503,"end_lon":0.4726423454301134,"fare":47.77395067707303,"partitionpath":"americas/united_states/san_francisco"}{"ts":1671963682899,"uuid":"31d33c1a-6972-4527-8dd5-81c20c52763d","rider":"rider-216","driver":"driver-216","begin_lat":0.028263672792464445,"begin_lon":0.40211140833035397,"end_lat":0.15658926939112228,"end_lon":0.8455880641363912,"fare":1.4159831486388885,"partitionpath":"asia/india/chennai"}{"ts":1672411964233,"uuid":"b973d602-d3ef-4b2c-9fea-961acfb821b8","rider":"rider-216","driver":"driver-216","begin_lat":0.9836743920572577,"begin_lon":0.6004750124394793,"end_lat":0.24929904973142092,"end_lon":0.3200976495774087,"fare":16.603428449020086,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672151908928,"uuid":"db42e8c3-ce9c-49d7-a35b-1a7437b53f89","rider":"rider-216","driver":"driver-216","begin_lat":0.2132173852420407,"begin_lon":0.15330847537835646,"end_lat":0.1962305768406577,"end_lon":0.36964170578655997,"fare":21.10206104048945,"partitionpath":"americas/united_states/san_francisco"}{"ts":1671922370425,"uuid":"86c94192-6b82-4bc9-ad88-cda1980c4122","rider":"rider-216","driver":"driver-216","begin_lat":0.5550300795070142,"begin_lon":0.5369977335639399,"end_lat":0.11107854425835006,"end_lon":0.2005101485487828,"fare":49.25455806562906,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672036486606,"uuid":"86c94192-6b82-4bc9-ad88-cda1980c4122","rider":"rider-216","driver":"driver-216","begin_lat":0.9045189017781902,"begin_lon":0.38697902072535484,"end_lat":0.21932410786717094,"end_lon":0.7816060218244935,"fare":44.596839246210095,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672463393936,"uuid":"c9408af0-b64c-4e41-ab58-03c9086fc0ac","rider":"rider-216","driver":"driver-216","begin_lat":0.856152038750905,"begin_lon":0.3132477949501916,"end_lat":0.8742438057467156,"end_lon":0.26923247017036556,"fare":2.4995362119815567,"partitionpath":"americas/united_states/san_francisco"}{"ts":1672293194249,"uuid":"c9408af0-b64c-4e41-ab58-03c9086fc0ac","rider":"rider-216","driver":"driver-216","begin_lat":0.244841817279154,"begin_lon":0.1072756362186601,"end_lat":0.942031609993243,"end_lon":0.4046750217523756,"fare":15.119997249522644,"partitionpath":"americas/united_states/san_francisco"}{"ts":1671981416785,"uuid":"86c94192-6b82-4bc9-ad88-cda1980c4122","rider":"rider-216","driver":"driver-216","begin_lat":0.07076797401073076,"begin_lon":0.8849896596590882,"end_lat":0.06184420667556445,"end_lon":0.016106173908908228,"fare":58.4204225520771,"partitionpath":"americas/brazil/sao_paulo"}{"ts":1672047164973,"uuid":"2770c069-5465-4e58-86fd-aca6cdf3e4f4","rider":"rider-216","driver":"driver-216","begin_lat":0.24922684654843108,"begin_lon":0.04816835556452426,"end_lat":0.27757407139306467,"end_lon":0.6871614209995992,"fare":14.503019204958845,"partitionpath":"americas/united_states/san_francisco"}
重新查看hudi表的最新数据
// 此处就直接用DataFrame的API查看数据,没有再重新映射成临时表去用sql查询
spark.read.format("hudi").load(basePath).select("uuid","ts","_hoodie_commit_time","_hoodie_file_name").show(100,false)// 总共就有15条// 这里展示了 _hoodie_commit_time 和 _hoodie_file_name 这两个隐藏字段// 因为有的最新数据是在 20221231161201007 有的最新数据是在 20221231170849075 有的最新数据是在 20221231172254604 ,所以这三个Instant的数据都有。// 参考COW表的Snapshot Query+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|uuid |ts |_hoodie_commit_time|_hoodie_file_name |+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|77f89906-1aa8-4da3-ba61-76485a4f5b1e|1671979635294|20221231161201007|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||c9408af0-b64c-4e41-ab58-03c9086fc0ac|1672463393936|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||db42e8c3-ce9c-49d7-a35b-1a7437b53f89|1672151908928|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||71bbfaef-57f4-4279-b373-4401edba1281|1672075624664|20221231161201007|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||ce3a01e9-d5c9-4154-a993-384288e235f6|1672134610405|20221231161201007|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||b973d602-d3ef-4b2c-9fea-961acfb821b8|1672411964233|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||879dc9b6-e62e-44df-bafb-13e170484e55|1672200490316|20221231170849075|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||2770c069-5465-4e58-86fd-aca6cdf3e4f4|1672047164973|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||86c94192-6b82-4bc9-ad88-cda1980c4122|1672036486606|20221231172254604|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||cae66749-74ea-43c1-bdcb-a66beca6e56e|1672386949058|20221231161201007|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||85f71297-4eaf-4995-931c-01226f420d07|1672213281821|20221231161201007|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||3815301a-b9dc-4e7d-86a5-7b0368e5a8b8|1672235394640|20221231170849075|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||efb91807-2615-433a-b743-18a46a360141|1672416111725|20221231161201007|a617e365-4e8c-4681-b078-b12c993c641a-0_2-130-210_20221231172254604.parquet||2965f3ab-579a-487c-bcea-87fbb898329f|1672418641807|20221231161201007|a617e365-4e8c-4681-b078-b12c993c641a-0_2-130-210_20221231172254604.parquet||31d33c1a-6972-4527-8dd5-81c20c52763d|1671963682899|20221231172254604|a617e365-4e8c-4681-b078-b12c993c641a-0_2-130-210_20221231172254604.parquet|+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+
增量查询(Incremental query)
hudi还提供了增量查询的方式,可以获取从给定提交时间以来更改的数据流,需要指定增量查询的
BeginTime
,选择性指定
EndTime
,如果我们希望在给定提交时间之后进行的所有更改,则不需要指定
EndTime
// 将hudi表数据映射成临时表
spark.read.format("hudi").load(basePath).createOrReplaceTempView("hudi_trips_snapshot")// 查询所有的commit timeval commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").
map(k => k.getString(0)).take(50)// 现在是有3个commit
commits: Array[String]= Array(20221231161201007,20221231170849075,20221231172254604)// 该参数指定的是 >该commit时间的数据// 其中 "000" 值表示timeline的最开始
scala> BEGIN_INSTANTTIME_OPT_KEY
res38:String= hoodie.datasource.read.begin.instanttime
// 该参数指定的是 <=该commit时间的数据
scala> END_INSTANTTIME_OPT_KEY
res39:String= hoodie.datasource.read.end.instanttime
如下是获取
20221231161201007
之后的更新数据。
注意重复uuid的数据会保留最新commit的数据。如
uuid="31d33c1a-6972-4527-8dd5-81c20c52763d"
在
Instant Time=20221231170849075
和
Instant Time=20221231172254604
val beginTime ="20221231161201007"
spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath).
select("uuid","ts","_hoodie_commit_time","_hoodie_file_name").
show(100,false)+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|uuid |ts |_hoodie_commit_time|_hoodie_file_name |+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|c9408af0-b64c-4e41-ab58-03c9086fc0ac|1672463393936|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||db42e8c3-ce9c-49d7-a35b-1a7437b53f89|1672151908928|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||b973d602-d3ef-4b2c-9fea-961acfb821b8|1672411964233|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||879dc9b6-e62e-44df-bafb-13e170484e55|1672200490316|20221231170849075|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||2770c069-5465-4e58-86fd-aca6cdf3e4f4|1672047164973|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||86c94192-6b82-4bc9-ad88-cda1980c4122|1672036486606|20221231172254604|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||3815301a-b9dc-4e7d-86a5-7b0368e5a8b8|1672235394640|20221231170849075|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||31d33c1a-6972-4527-8dd5-81c20c52763d|1671963682899|20221231172254604|a617e365-4e8c-4681-b078-b12c993c641a-0_2-130-210_20221231172254604.parquet|+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+
现在我们知道提交了3次,那么我可以指定
BEGIN_INSTANTTIME_OPT_KEY
和
END_INSTANTTIME_OPT_KEY
来获取每个
Instant Time
提交的数据
// 获取 20221231161201007 这个Instant提交的数据
spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY,"000").
option(END_INSTANTTIME_OPT_KEY,"20221231161201007").
load(basePath).
select("uuid","ts","_hoodie_commit_time","_hoodie_file_name").
show(100,false)// 获取 20221231170849075 这个Instant提交的数据
spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY,"20221231161201007").
option(END_INSTANTTIME_OPT_KEY,"20221231170849075").
load(basePath).
select("uuid","ts","_hoodie_commit_time","_hoodie_file_name").
show(100,false)// 获取 20221231172254604 这个Instant提交的数据
spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY,"20221231170849075").
option(END_INSTANTTIME_OPT_KEY,"20221231172254604").
load(basePath).
select("uuid","ts","_hoodie_commit_time","_hoodie_file_name").
show(100,false)// 原先这里有10条更新数据,但是由于去重实际上写入到hudi的只有6条数据+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|uuid |ts |_hoodie_commit_time|_hoodie_file_name |+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+|c9408af0-b64c-4e41-ab58-03c9086fc0ac|1672463393936|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||db42e8c3-ce9c-49d7-a35b-1a7437b53f89|1672151908928|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||b973d602-d3ef-4b2c-9fea-961acfb821b8|1672411964233|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||2770c069-5465-4e58-86fd-aca6cdf3e4f4|1672047164973|20221231172254604|614424c5-695e-4496-936b-7dbb928653b6-0_1-130-209_20221231172254604.parquet||86c94192-6b82-4bc9-ad88-cda1980c4122|1672036486606|20221231172254604|b74cf2c2-5a71-4195-af4d-e35b244d0dcc-0_0-130-208_20221231172254604.parquet||31d33c1a-6972-4527-8dd5-81c20c52763d|1671963682899|20221231172254604|a617e365-4e8c-4681-b078-b12c993c641a-0_2-130-210_20221231172254604.parquet|+------------------------------------+-------------+-------------------+--------------------------------------------------------------------------+
删除数据(Delete Data)
- 软删除:将
RECORDKEY_FIELD_OPT_KEY、PRECOMBINE_FIELD_OPT_KEY、PARTITIONPATH_FIELD_OPT_KEY这三个参数指定的字段之外的所有字段的值置为null值即可> 软删除的数据是会永远保存的并且不会被删除的譬如下面代码随机取2条数据进行软删除// 将hudi表映射成一张临时表spark. read. format("hudi"). load(basePath). createOrReplaceTempView("hudi_trips_snapshot")// 获取hudi表的数据量,下面两个sql的值应该都是 15spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()// 随机取两条进行软删除val softDeleteDs = spark.sql("select * from hudi_trips_snapshot").limit(2)softDeleteDs.select("uuid").show(false)+------------------------------------+|uuid |+------------------------------------+|77f89906-1aa8-4da3-ba61-76485a4f5b1e||c9408af0-b64c-4e41-ab58-03c9086fc0ac|+------------------------------------+// 获取其他需要置空的字段// HoodieRecord.HOODIE_META_COLUMNS 是hudi表自带的5个字段// ts", "uuid", "partitionpath" 是三个参数指定的字段val nullifyColumns = softDeleteDs.schema.fields. map(field =>(field.name, field.dataType.typeName)). filter(pair =>(!HoodieRecord.HOODIE_META_COLUMNS.contains(pair._1)&&!Array("ts","uuid","partitionpath").contains(pair._1)))// 需要置空的字段nullifyColumns: Array[(String,String)]= Array((begin_lat,double),(begin_lon,double),(driver,string),(end_lat,double),(end_lon,double),(fare,double),(rider,string))// 将需要删除的DataFrame数据的其他字段全部置为null值val softDeleteDf = nullifyColumns. foldLeft(softDeleteDs.drop(HoodieRecord.HOODIE_META_COLUMNS: _*))((ds, col)=> ds.withColumn(col._1, lit(null).cast(col._2)))+---------+---------+------+-------+-------+----+-----+-------------+------------------------------------+------------------------------------+|begin_lat|begin_lon|driver|end_lat|end_lon|fare|rider|ts |uuid |partitionpath |+---------+---------+------+-------+-------+----+-----+-------------+------------------------------------+------------------------------------+|null|null|null|null|null|null|null|1671979635294|77f89906-1aa8-4da3-ba61-76485a4f5b1e|americas/united_states/san_francisco||null|null|null|null|null|null|null|1672463393936|c9408af0-b64c-4e41-ab58-03c9086fc0ac|americas/united_states/san_francisco|+---------+---------+------+-------+-------+----+-----+-------------+------------------------------------+------------------------------------+// 对这些数据进行 upsert 默认操作softDeleteDf.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"upsert"). option(PRECOMBINE_FIELD_OPT_KEY,"ts"). option(RECORDKEY_FIELD_OPT_KEY,"uuid"). option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath)// 重新加载数据spark. read. format("hudi"). load(basePath). createOrReplaceTempView("hudi_trips_snapshot")// 返回的数据量和以前一样,是15spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()// 返回的数据量是13spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count() - 硬删除:通过传入
hoodie key (record key + partition path)来删除数据 下面的例子虽然也传入了PRECOMBINE_FIELD_OPT_KEY指定的字段,经测试不传入也是可以的// 15条数据spark.sql("select * from hudi_trips_snapshot").count()// 将上面软删除的2条进行硬删除val ds = spark.sql("select uuid, partitionpath, ts from hudi_trips_snapshot where uuid in ('77f89906-1aa8-4da3-ba61-76485a4f5b1e', 'c9408af0-b64c-4e41-ab58-03c9086fc0ac')")// Append默认, 设置 OPERATION_OPT_KEY 为 delete 进行删除ds.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY, DELETE_OPERATION_OPT_VAL). option(PRECOMBINE_FIELD_OPT_KEY,"ts"). option(RECORDKEY_FIELD_OPT_KEY,"uuid"). option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath)// 13 条数据spark. read. format("hudi"). load(basePath).count()
覆盖分区数据(Insert Overwrite)
类似于hive表的
insert overwrite table 表名 parition(分区字段)
这个动态分区,能直接覆盖hudi表的分区数据。
对于批量更新的任务,
insert_overwrite
这个操作类型比默认的
upsert
更加高效,因为是一次重新建立整个分区数据,而避开了
Index
、
precombine
和
repartition
等
upsert
写操作的步骤。
// 查看现在各分区数据
spark.read.format("hudi").load(basePath).select("uuid","ts","partitionpath","_hoodie_commit_time","_hoodie_file_name").show(100,false)// americas/united_states/san_francisco 这个分区是有2条数据+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+|uuid |ts |partitionpath |_hoodie_commit_time|_hoodie_file_name |+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+|b70d583c-92fb-4eb7-9c8a-614b0ad87b84|1671913247481|americas/brazil/sao_paulo |20221229140047416|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||f1c8ff18-6ee7-48a2-aad4-0eaffe88026b|1671968648525|americas/brazil/sao_paulo |20221229140047416|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||06f6a366-7e63-4d94-b08a-9d3664bb1e52|1672182519321|americas/brazil/sao_paulo |20221229170039311|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||ba2db2c9-753c-48ee-91e1-b4634cc65344|1672131402058|americas/brazil/sao_paulo |20221229170243779|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||29b5acb6-57b4-41a4-841a-c9fc4e7d0dce|1672109692806|americas/brazil/sao_paulo |20221229170243779|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||a58c36a6-752d-452b-8362-f8721e3f49be|1672082911226|americas/united_states/san_francisco|20221229211539434|e14139c4-bce8-46fa-9d3f-1e33b6965ac3-0_0-320-517_20221229211539434.parquet||f9c697c4-bdb7-4e5e-93ff-e5db218c71e4|1672008103441|americas/united_states/san_francisco|20221229211539434|e14139c4-bce8-46fa-9d3f-1e33b6965ac3-0_0-320-517_20221229211539434.parquet||295f33a7-a82d-4246-81e1-4dc1802d58b8|1671791767136|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||01b47755-7d31-4e7f-bdc8-ccc711dc2333|1671940055852|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||f271a7d3-e8a7-4ac3-bfae-4e9ac4af851f|1672018107402|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||e3959621-01b5-4538-bf49-83a815c869b3|1671873916544|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet|+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+val inserts = convertToStringList(dataGen.generateInserts(10))val df = spark.
read.json(spark.sparkContext.parallelize(inserts,2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
df.select("uuid","ts","partitionpath").show(100,false)// americas/united_states/san_francisco 分区现在生成5条数据+------------------------------------+-------------+------------------------------------+|uuid |ts |partitionpath |+------------------------------------+-------------+------------------------------------+|563f15b3-a24e-4638-8cb2-73b5c8214b3e|1672505965935|americas/united_states/san_francisco||0b6ed1e0-546c-44ab-8e99-0827173a747a|1672285607060|americas/united_states/san_francisco||d561fab5-1ff6-4567-9133-514ea2f624b1|1672399355255|americas/united_states/san_francisco||c39d896f-fd73-4c44-9a78-5267dceb9b58|1672377253065|americas/united_states/san_francisco||f4bfb9ca-a9fb-493b-a893-39fbe1ee941b|1672613717189|americas/united_states/san_francisco|+------------------------------------+-------------+------------------------------------+// 通过指定 OPERATION_OPT_KEY = INSERT_OVERWRITE_OPERATION_OPT_VAL 来覆盖hudi表分区数据
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY, INSERT_OVERWRITE_OPERATION_OPT_VAL).
option(PRECOMBINE_FIELD_OPT_KEY,"ts").
option(RECORDKEY_FIELD_OPT_KEY,"uuid").
option(PARTITIONPATH_FIELD_OPT_KEY,"partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
scala> INSERT_OVERWRITE_OPERATION_OPT_VAL
res5:String= insert_overwrite
// 再次查看发现 americas/united_states/san_francisco 分区数据变成5条了
spark.read.format("hudi").load(basePath).select("uuid","ts","partitionpath","_hoodie_commit_time","_hoodie_file_name").show(100,false)+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+|uuid |ts |partitionpath |_hoodie_commit_time|_hoodie_file_name |+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+|b70d583c-92fb-4eb7-9c8a-614b0ad87b84|1671913247481|americas/brazil/sao_paulo |20221229140047416|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||f1c8ff18-6ee7-48a2-aad4-0eaffe88026b|1671968648525|americas/brazil/sao_paulo |20221229140047416|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||06f6a366-7e63-4d94-b08a-9d3664bb1e52|1672182519321|americas/brazil/sao_paulo |20221229170039311|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||ba2db2c9-753c-48ee-91e1-b4634cc65344|1672131402058|americas/brazil/sao_paulo |20221229170243779|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||29b5acb6-57b4-41a4-841a-c9fc4e7d0dce|1672109692806|americas/brazil/sao_paulo |20221229170243779|71ffc931-289e-4e5e-9f4d-98940a3a89f8-0_0-231-379_20221229210932997.parquet||563f15b3-a24e-4638-8cb2-73b5c8214b3e|1672505965935|americas/united_states/san_francisco|20230102214059374|a4bf8088-e2cf-4b00-b1cc-edaee784374e-0_0-25-53_20230102214059374.parquet ||0b6ed1e0-546c-44ab-8e99-0827173a747a|1672285607060|americas/united_states/san_francisco|20230102214059374|a4bf8088-e2cf-4b00-b1cc-edaee784374e-0_0-25-53_20230102214059374.parquet ||d561fab5-1ff6-4567-9133-514ea2f624b1|1672399355255|americas/united_states/san_francisco|20230102214059374|a4bf8088-e2cf-4b00-b1cc-edaee784374e-0_0-25-53_20230102214059374.parquet ||c39d896f-fd73-4c44-9a78-5267dceb9b58|1672377253065|americas/united_states/san_francisco|20230102214059374|a4bf8088-e2cf-4b00-b1cc-edaee784374e-0_0-25-53_20230102214059374.parquet ||f4bfb9ca-a9fb-493b-a893-39fbe1ee941b|1672613717189|americas/united_states/san_francisco|20230102214059374|a4bf8088-e2cf-4b00-b1cc-edaee784374e-0_0-25-53_20230102214059374.parquet ||295f33a7-a82d-4246-81e1-4dc1802d58b8|1671791767136|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||01b47755-7d31-4e7f-bdc8-ccc711dc2333|1671940055852|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||f271a7d3-e8a7-4ac3-bfae-4e9ac4af851f|1672018107402|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet||e3959621-01b5-4538-bf49-83a815c869b3|1671873916544|asia/india/chennai |20221229211539434|0df94323-440d-4ca4-92dc-552f7ae9322c-0_1-320-518_20221229211539434.parquet|+------------------------------------+-------------+------------------------------------+-------------------+--------------------------------------------------------------------------+
PySpark方式
python3.7安装
首先
Spark3.3.1
版本需要
Python3.7
及以上版本的支持,所以需要在服务器所有
worker
节点都安装
Python3.7
。可以从华为云下载3.7.9的安装包,Windows64的安装包名是
python-3.7.9-amd64.exe
,Linux的安装包名是
Python-3.7.9.tgz
。
一、Windows环境Python3.7.9安装
Windows安装
python3.7
比较简单,按照步骤提示即可安装到指定目录,我本地Windows机器
python3.7.9
安装到目录
D:\python\python3.7
二、Linux环境Python3.7.9安装
Linux安装
Python3.7
稍微麻烦,可以根据以前写的文章Linux安装Python3来编译安装到linux指定目录,我这边三个服务器都是安装在
/usr/local/python3
目录。其中安装
python3
之前还需要通过
yum
安装
python
的一些依赖
yum -y install zlib-devel bzip2-devel openssl-devel openssl-static ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel lzma gcc
。
pyspark的安装及配置
一、Windows环境
python的
pip
源配置指定为阿里源,这样能加快包的安装速度。如果是windows则可以新建文件
%USERPROFILE%\pip\pip.ini
,其中环境变量
USERPROFILE
可以通过在
cmd
命令行界面输入
set
命令看到。文件内容如下:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host=mirrors.aliyun.com
为了单独创建一个
PySpark3.3.1
的环境,首先通过
pip install virtualenv
来安装
virtualenv
包。然后通过
virtualenv
给项目单独拷贝一个
Python3.7.9
的环境,并安装
PySpark3.3.1
。
具体步骤如下:
- 创建项目目录
D:\pycharm_pro\pyspark3.3.1_demo cmd进入到项目目录并执行命令D:\python\python3.7\Scripts\virtualenv.exe venv,这样就拷贝了一份Python3.7.9的环境到venv目录
Pycharm打开这个目录并在Settings>Project>Project Interperter里选择上面创建的虚拟环境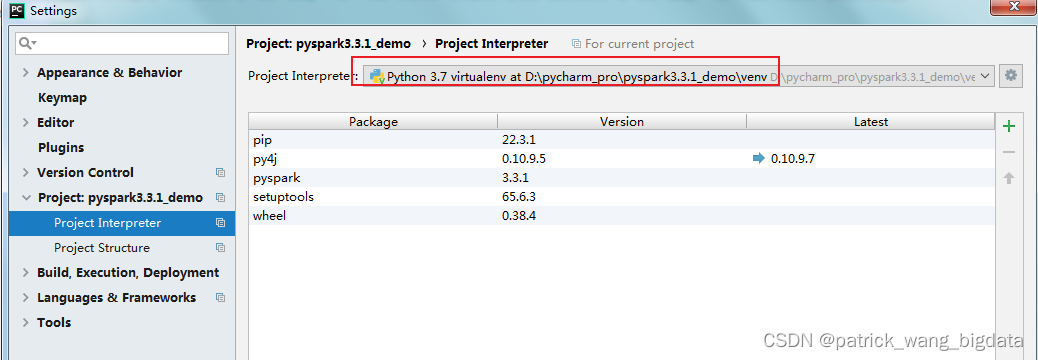
- 在打开的
Terminal终端执行命令安装pyspark:pip install pyspark==3.3.1,因为项目的Terminal会自动加载虚拟环境,这样在这个终端通过pip安装的包也是安装在这个虚拟环境里,其实这个pip命令也是虚拟环境的pip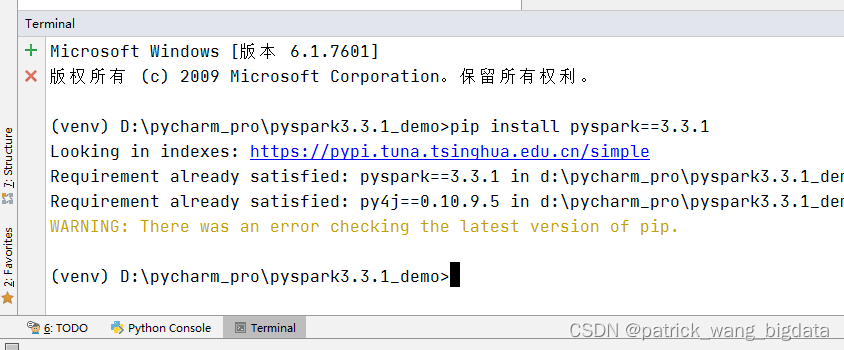
- 新建
test.py,内容如下,运行该文件看是否能正常出现结果。 这一步如果出现报错pyspark Exception: Java gateway process exited before sending its port number,一般是因为环境变量没有配置或者配置不对。环境变量只需配置JAVA_HOME,必须是1.8及以上;SPARK_HOME可以不用配置,如果配置了则要配置成对应版本的SPARK解压路径,不允许你这边pyspark=3.3.1但实际上SPARK_HOME对应的目录却是Spark2x。当然你也可以通过在SparkSession创建之前修改os.environ环境变量以生效,而不必去配置系统环境变量,坏处就是每个项目都得这么设置。from pyspark.sql import SparkSession# 可以修改 os.environ 来指定环境变量# import os# os.environ.setdefault("JAVA_HOME", "F:\jdk\jdk1.8")# os.environ.setdefault("HADOOP_HOME", "D:\hadoop-3.3.2")# os.environ.setdefault("SPARK_HOME", "D:\spark-3.3.1-bin-hadoop3")spark = SparkSession.builder.master("local[*]").getOrCreate()spark.sql("select 1 as id, 'a' as name union all select 2 as id, 'b' as name").show()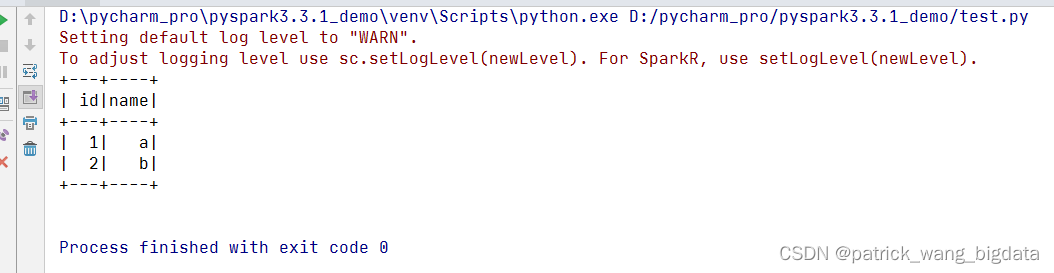
- 消除告警
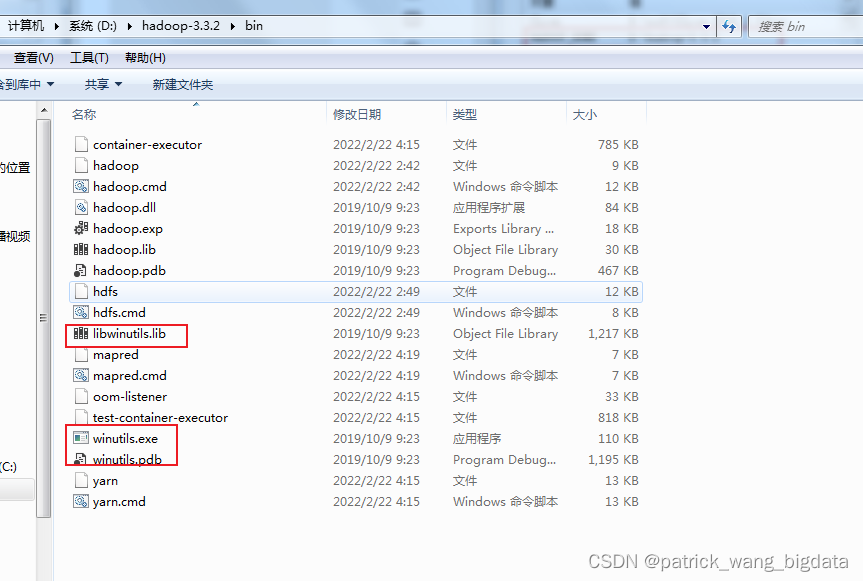
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems。这是由于没有指定HADOOP_HOME以及bin目录没有winutils.exe等相关文件的缘故。可以通过将下载的hadoop-3.3.2.tar.gz解压到目录D:\hadoop-3.3.2,并指定HADOOP_HOME=D:\hadoop-3.3.2,并将压缩包里的bin目录的文件放到D:\hadoop-3.3.2\bin即可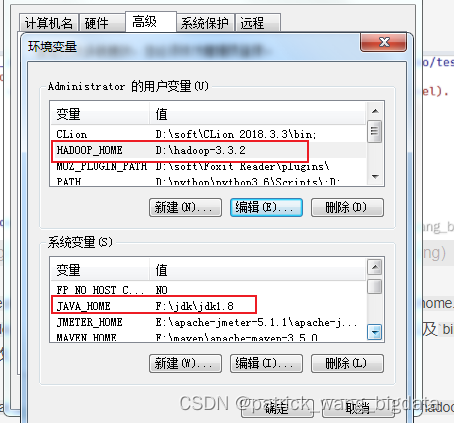
二、Linux环境
除了在每个
Worker
节点都需要安装
python3.7.9
之外,还需要指定环境变量
export PYSPARK_PYTHON=/usr/local/python3/bin/python3
标明PySpark使用的python3执行文件绝路径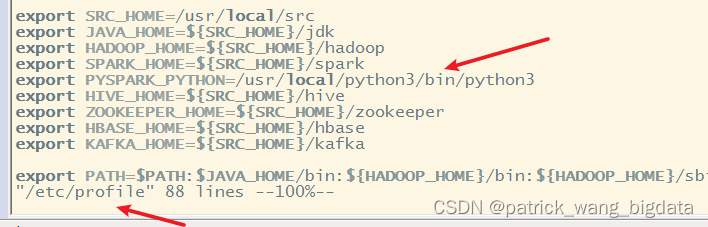
pyspark
脚本文件里面确定了需要用到
PYSPARK_PYTHON
,否则就在
PATH
里找
python3
命令,由于我并没有在
/etc/profile
文件更新
PATH
变量,所以就在
/etc/profile
文件指定了
PYSPARK_PYTHON
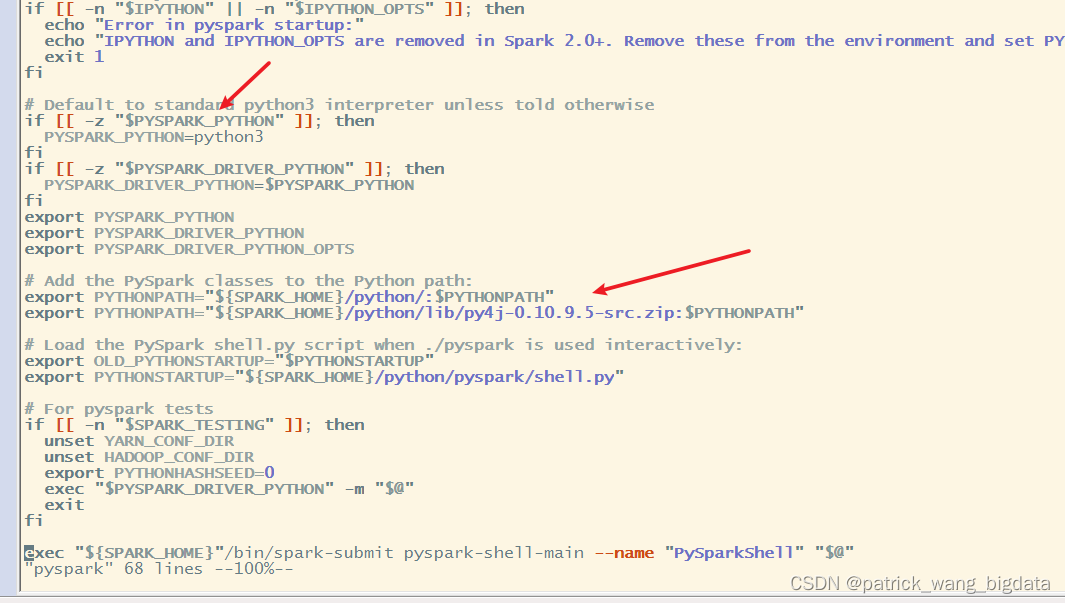
准备
test.py
文件,内容如下,只是查看Hive里
default
库下的所有表以及查看
tmp123
表内容
from pyspark.sql import SparkSession
# 如果要连接Hive需要 enableHiveSupport
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
spark.sql("use default")
spark.sql("show tables").show()
spark.sql("select * from tmp123").show()
spark.stop()
在
Spark
客户端机器提交命令
/usr/local/src/spark/bin/spark-submit --master yarn --deploy-mode cluster --queue root.default ~/test.py
提交python任务到YARN集群上执行
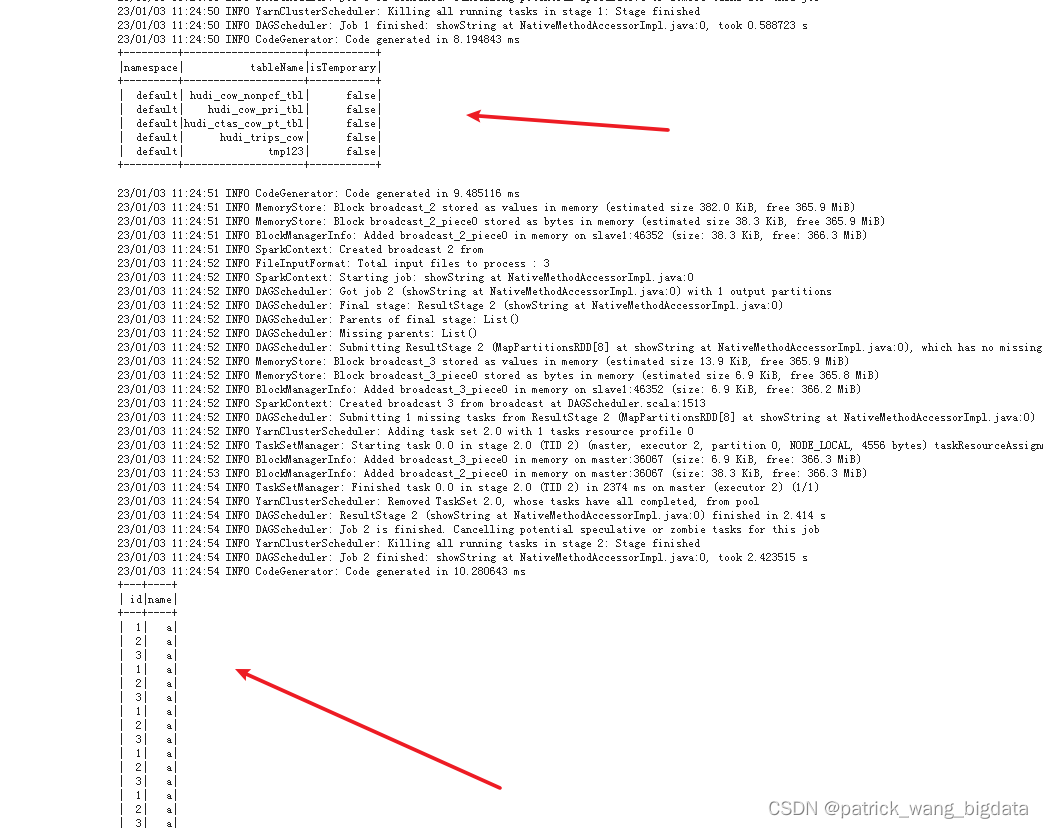
如果
Driver
端日志出现如下能够找到
hive-site.xml
文件的内容,则表明能够正确读到hive数据库,如果是
23/01/03 11:06:48 INFO HiveConf: Found configuration file null
则表明并没有找到对应的配置文件连上hive数据库。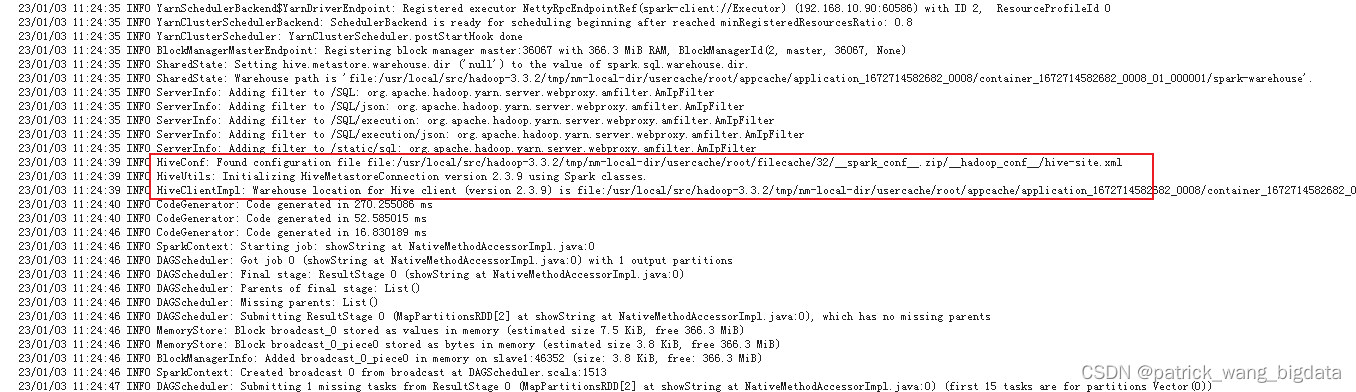
如何能够让
spark-submit
提交的程序正确读到
hive-site.xml
文件呢?有两种方式:
- 通过
spark-submit命令的--files选项指定hive-site.xml的文件路径 - 把
hive-site.xml文件拷贝一份到${SPARK_HOME}/conf目录下
这两种方式的最终目的就是能否通过
ClassLoader
在类路径下面找到
hive-site.xml
为了后面提交的一劳永逸,建议第2种方式。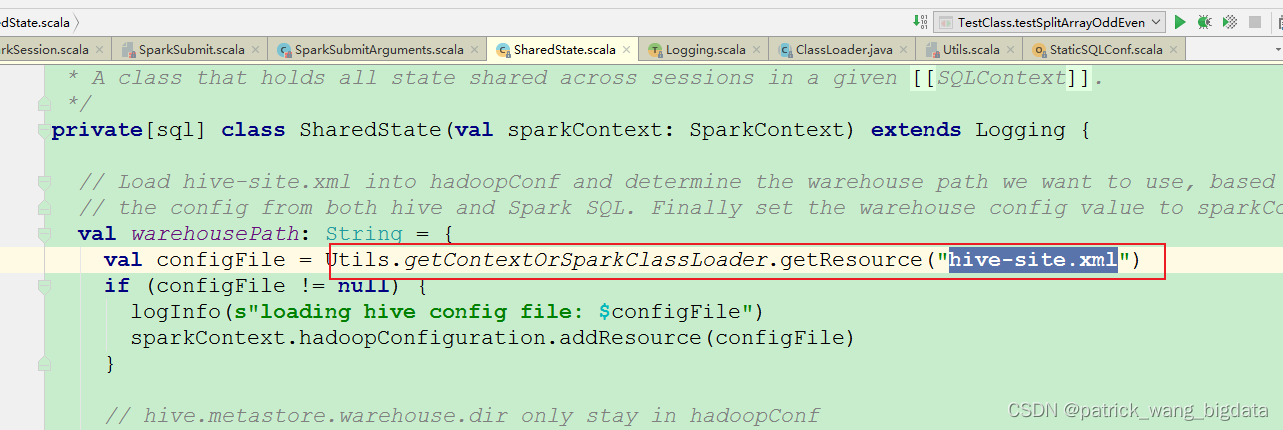
pyspark的启动命令
linux环境
/etc/profile
已经指定了
PYSPARK_PYTHON
,所以可以直接启动
pyspark
pyspark \--conf'spark.serializer=org.apache.spark.serializer.KryoSerializer'\--conf'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'\--conf'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
插入数据
设置表名、表路径以及hudi提供的数据生成器(这里是通过
SparkContext._jvm
来获取Java对象)
tableName ="python_hudi_trips_cow"
basePath ="/tmp/hudi/python_hudi_trips_cow"
dataGen = sc._jvm.org.apache.hudi.QuickstartUtils.DataGenerator()
用
pyspark
的方式写入hudi不需要手动显示建表,在第一次插入数据时就会自动建表。
# pyspark
inserts = sc._jvm.org.apache.hudi.QuickstartUtils.convertToStringList(dataGen.generateInserts(10))
df = spark.read.json(spark.sparkContext.parallelize(inserts,2))# 定义hudi配置项, 默认操作是 upsert
hudi_options ={'hoodie.upsert.shuffle.parallelism':2,'hoodie.insert.shuffle.parallelism':2,'hoodie.datasource.write.precombine.field':'ts','hoodie.datasource.write.recordkey.field':'uuid','hoodie.datasource.write.partitionpath.field':'partitionpath','hoodie.table.name': tableName,'hoodie.datasource.write.operation':'upsert'}# 第一次需要用 overwrite
df.write.format("hudi"). \
options(**hudi_options). \
mode("overwrite"). \
save(basePath)
已经在hdfs对应目录创建了hudi的元数据区和数据区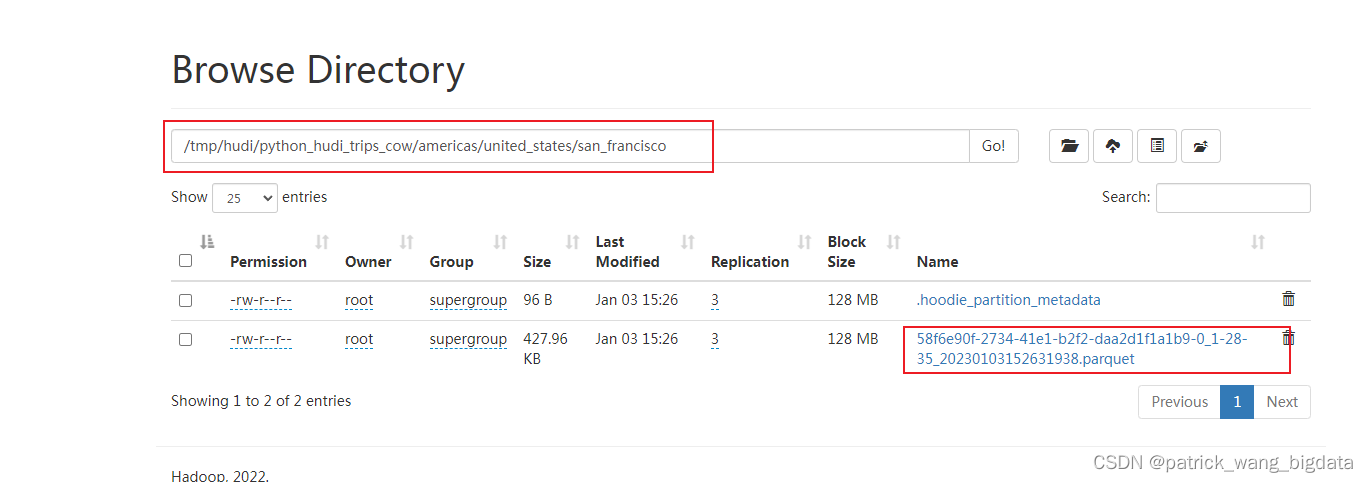
查询数据
tripsSnapshotDF = spark. \
read. \
format("hudi"). \
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select * from hudi_trips_snapshot where fare < 20.0").show(n=100, truncate=False)
时间旅行(Time Travel Query)
spark.read. \
format("hudi"). \
option("as.of.instant","20230103152631938"). \
load(basePath).select("uuid","partitionpath").show(n=100, truncate=False)
更新数据
updates = sc._jvm.org.apache.hudi.QuickstartUtils.convertToStringList(dataGen.generateUpdates(10))
df = spark.read.json(spark.sparkContext.parallelize(updates,2))
df.write.format("hudi"). \
options(**hudi_options). \
mode("append"). \
save(basePath)# 再次查询
spark. \
read. \
format("hudi"). \
load(basePath).select("uuid","ts","partitionpath").show(n=100, truncate=False)
增量查询(Incremental query)
spark. \
read. \
format("hudi"). \
load(basePath). \
createOrReplaceTempView("hudi_trips_snapshot")
commits =list(map(lambda row: row["commitTime"], spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").limit(50).collect()))
beginTime ="000"
endTime = commits[len(commits)-2]# incrementally query data
incremental_read_options ={'hoodie.datasource.query.type':'incremental','hoodie.datasource.read.begin.instanttime': beginTime,'hoodie.datasource.read.end.instanttime': endTime
}
tripsIncrementalDF = spark.read.format("hudi"). \
options(**incremental_read_options). \
load(basePath)
tripsIncrementalDF.select("uuid","ts","partitionpath").show(n=100, truncate=False)
删除数据(Delete Data)
- 软删除
# pysparkfrom pyspark.sql.functions import lit
from functools importreduce
spark.read.format("hudi"). \
load(basePath). \
createOrReplaceTempView("hudi_trips_snapshot")# fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()# fetch two records for soft deletes
soft_delete_ds = spark.sql("select * from hudi_trips_snapshot").limit(2)# prepare the soft deletes by ensuring the appropriate fields are nullified
meta_columns =["_hoodie_commit_time","_hoodie_commit_seqno","_hoodie_record_key", \
"_hoodie_partition_path","_hoodie_file_name"]
excluded_columns = meta_columns +["ts","uuid","partitionpath"]
nullify_columns =list(filter(lambda field: field[0]notin excluded_columns, \
list(map(lambda field:(field.name, field.dataType), soft_delete_ds.schema.fields))))
hudi_soft_delete_options ={'hoodie.table.name': tableName,'hoodie.datasource.write.recordkey.field':'uuid','hoodie.datasource.write.partitionpath.field':'partitionpath','hoodie.datasource.write.operation':'upsert','hoodie.datasource.write.precombine.field':'ts','hoodie.upsert.shuffle.parallelism':2,'hoodie.insert.shuffle.parallelism':2}
soft_delete_df =reduce(lambda df,col: df.withColumn(col[0], lit(None).cast(col[1])), \
nullify_columns,reduce(lambda df,col: df.drop(col[0]), meta_columns, soft_delete_ds))# simply upsert the table after setting these fields to null
soft_delete_df.write.format("hudi"). \
options(**hudi_soft_delete_options). \
mode("append"). \
save(basePath)# reload data
spark.read.format("hudi"). \
load(basePath). \
createOrReplaceTempView("hudi_trips_snapshot")# This should return the same total count as before
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()# This should return (total - 2) count as two records are updated with nulls
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()
- 硬删除
# fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()# fetch two records to be deleted
hard_delete_df = spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is null").limit(2)# issue deletes
hudi_hard_delete_options ={'hoodie.table.name': tableName,'hoodie.datasource.write.recordkey.field':'uuid','hoodie.datasource.write.partitionpath.field':'partitionpath','hoodie.datasource.write.operation':'delete','hoodie.datasource.write.precombine.field':'ts','hoodie.upsert.shuffle.parallelism':2,'hoodie.insert.shuffle.parallelism':2}
hard_delete_df.write.format("hudi"). \
options(**hudi_hard_delete_options). \
mode("append"). \
save(basePath)# run the same read query as above.
roAfterDeleteViewDF = spark. \
read. \
format("hudi"). \
load(basePath)
roAfterDeleteViewDF.createOrReplaceTempView("hudi_trips_snapshot")# fetch should return (total - 2) records
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
覆盖分区数据(Insert Overwrite)
spark.read.format("hudi"). \
load(basePath). \
select(["uuid","partitionpath"]). \
sort(["partitionpath","uuid"]). \
show(n=100, truncate=False)
inserts = sc._jvm.org.apache.hudi.QuickstartUtils.convertToStringList(dataGen.generateInserts(10))
df = spark.read.json(spark.sparkContext.parallelize(inserts,2)). \
filter("partitionpath = 'americas/united_states/san_francisco'")
hudi_insert_overwrite_options ={'hoodie.table.name': tableName,'hoodie.datasource.write.recordkey.field':'uuid','hoodie.datasource.write.partitionpath.field':'partitionpath','hoodie.datasource.write.operation':'insert_overwrite','hoodie.datasource.write.precombine.field':'ts','hoodie.upsert.shuffle.parallelism':2,'hoodie.insert.shuffle.parallelism':2}
df.write.format("hudi").options(**hudi_insert_overwrite_options).mode("append").save(basePath)
spark.read.format("hudi"). \
load(basePath). \
select(["uuid","partitionpath"]). \
sort(["partitionpath","uuid"]). \
show(n=100, truncate=False)
版权归原作者 patrick_wang_bigdata 所有, 如有侵权,请联系我们删除。