
pyspark RDD的创建
用自己的数据集创建
什么是 RDD
RDD
(
Resilient Distributed Dataset
)叫做分布式数据集,是
Spark
中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
RDD
具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。
RDD
允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
简单的来说
RDD
就是一个集合,一个将集合中数据存储在不同机器上的集合。
RDD
直观图,如下:
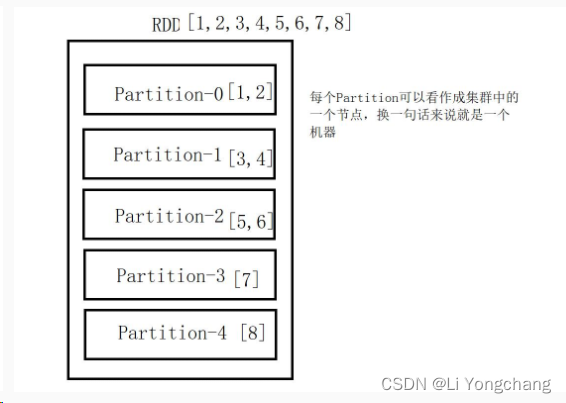
RDD 的 五大特性
- 一组分片(
Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 - 一个计算每个分区的函数。
Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。- 一个
Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 - 一个列表,存储存取每个
Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个 Partition 所在的块的位置。按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
相关API介绍
SparkContext创建;
sc = SparkContext("local", "Simple App")
说明:
"local"
是指让
Spark
程序本地运行,
"Simple App"
是指
Spark
程序的名称,这个名称可以任意(为了直观明了的查看,最好设置有意义的名称)。
- 集合并行化创建
RDD;
data = [1,2,3,4]rdd = sc.parallelize(data)
collect算子:在驱动程序中将数据集的所有元素作为数组返回(注意数据集不能过大);
rdd.collect()
- 停止
SparkContext。
sc.stop()
读取文件创建
textFile 介绍
PySpark
可以从
Hadoop
支持的任何存储源创建分布式数据集,包括本地文件系统,
HDFS
,
Cassandra
,
HBase
,
Amazon S3
等。
Spark
支持文本文件,
SequenceFiles
和任何其他
Hadoop InputFormat
。
文本文件
RDD
可以使用创建
SparkContex
的
textFile
方法。此方法需要一个
URI
的文件(本地路径的机器上,或一个
hdfs://,s3a://
等 URI),并读取其作为行的集合。这是一个示例调用:
distFile = sc.textFile("data.txt")
Basic Function in pyspark
Transformation - map
map
将原来
RDD
的每个数据项通过
map
中的用户自定义函数
f
映射转变为一个新的元素。
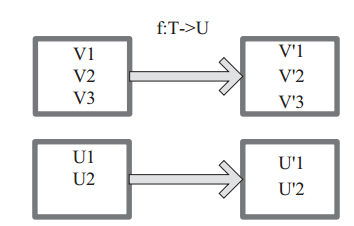
图中每个方框表示一个
RDD
分区,左侧的分区经过自定义函数
f:T->U
映射为右侧的新
RDD
分区。但是,实际只有等到
Action
算子触发后,这个
f
函数才会和其他函数在一个
Stage
中对数据进行运算。
map 案例
sc = SparkContext("local", "Simple App")data = [1,2,3,4,5,6]rdd = sc.parallelize(data)print(rdd.collect())rdd_map = rdd.map(lambda x: x * 2)print(rdd_map.collect())
输出:
[1, 2, 3, 4, 5, 6]
[2, 4, 6, 8, 10, 12]

说明:
rdd1
的元素(
1 , 2 , 3 , 4 , 5 , 6
)经过
map
算子(
x -> x*2
)转换成了
rdd2
(
2 , 4 , 6 , 8 , 10
)。
Transformation - mapPartitions
mapPartitions
mapPartitions
函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭 代器对整个分区的元素进行操作。
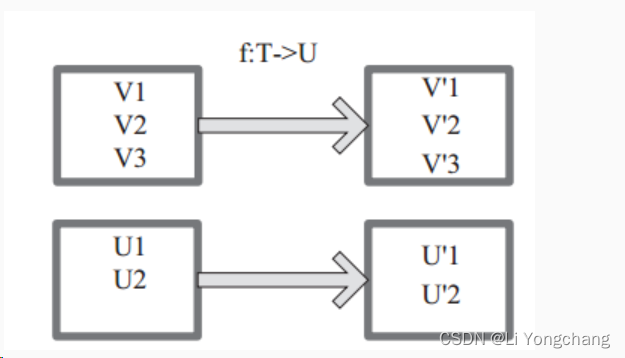
图中每个方框表示一个
RDD
分区,左侧的分区经过自定义函数
f:T->U
映射为右侧的新
RDD
分区。
mapPartitions 与 map
map
:遍历算子,可以遍历
RDD
中每一个元素,遍历的单位是每条记录。
mapPartitions
:遍历算子,可以改变
RDD
格式,会提高
RDD
并行度,遍历单位是
Partition
,也就是在遍历之前它会将一个
Partition
的数据加载到内存中。
那么问题来了,用上面的两个算子遍历一个
RDD
谁的效率高?
mapPartitions
算子效率高。
mapPartitions 案例
def f(iterator):list = []for x in iterator:list.append(x*2)return listif __name__ == "__main__":sc = SparkContext("local", "Simple App")data = [1,2,3,4,5,6]rdd = sc.parallelize(data)print(rdd.collect())partitions = rdd.mapPartitions(f)print(partitions.collect())
输出:
[1, 2, 3, 4, 5, 6][2, 4, 6, 8, 10, 12]
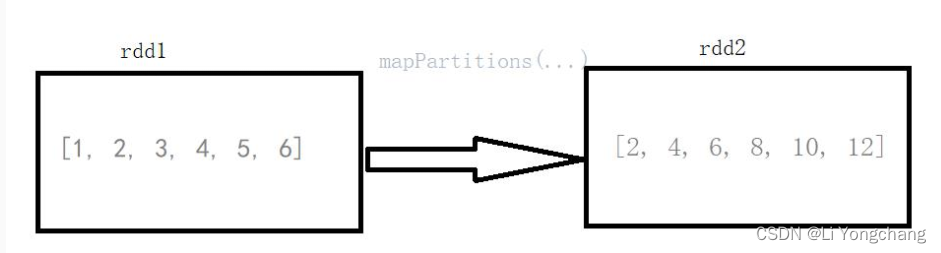
mapPartitions()
:传入的参数是
rdd
的
iterator
(元素迭代器),返回也是一个
iterator
(迭代器)。
Transformation - filter
filter
函数功能是对元素进行过滤,对每个元素应用
f
函数,返 回值为
true
的元素在
RDD
中保留,返回值为
false
的元素将被过滤掉。内部实现相当于生成。
FilteredRDD(this,sc.clean(f))
下面代码为函数的本质实现:
def filter(self, f):"""Return a new RDD containing only the elements that satisfy a predicate.>>> rdd = sc.parallelize([1, 2, 3, 4, 5])>>> rdd.filter(lambda x: x % 2 == 0).collect()[2, 4]"""def func(iterator):return filter(fail_on_stopiteration(f), iterator)return self.mapPartitions(func, True)
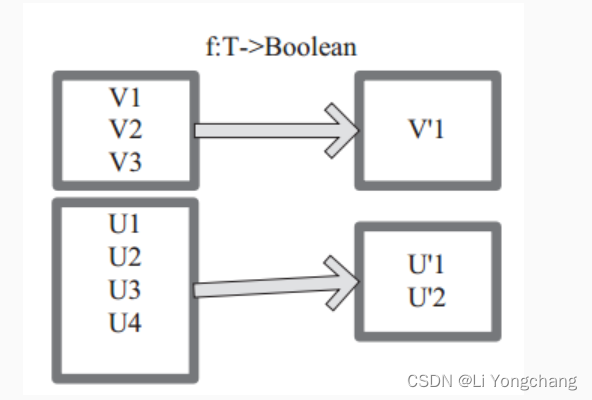
上图中每个方框代表一个
RDD
分区,
T
可以是任意的类型。通过用户自定义的过滤函数
f
,对每个数据项操作,将满足条件、返回结果为
true
的数据项保留。例如,过滤掉
V2
和
V3
保留了
V1
,为区分命名为
V’1
。
filter 案例
sc = SparkContext("local", "Simple App")data = [1,2,3,4,5,6]rdd = sc.parallelize(data)print(rdd.collect())rdd_filter = rdd.filter(lambda x: x>2)print(rdd_filter.collect())
输出:
[1, 2, 3, 4, 5, 6][3, 4, 5, 6]

说明:
rdd1( [ 1 , 2 , 3 , 4 , 5 , 6 ] )
经过
filter
算子转换成
rdd2( [ 3 ,4 , 5 , 6 ] )
。
Transformation - flatMap
flatMap
将原来
RDD
中的每个元素通过函数
f
转换为新的元素,并将生成的
RDD
中每个集合的元素合并为一个集合,内部创建:
FlatMappedRDD(this,sc.clean(f))

上图表示
RDD
的一个分区,进行
flatMap
函数操作,
flatMap
中传入的函数为
f:T->U
,
T
和
U
可以是任意的数据类型。将分区中的数据通过用户自定义函数
f
转换为新的数据。外部大方框可以认为是一个
RDD
分区,小方框代表一个集合。
V1
、
V2
、
V3
在一个集合作为
RDD
的一个数据项,可能存储为数组或其他容器,转换为
V’1
、
V’2
、
V’3
后,将原来的数组或容器结合拆散,拆散的数据形成
RDD
中的数据项。
flatMap 案例
sc = SparkContext("local", "Simple App")data = [["m"], ["a", "n"]]rdd = sc.parallelize(data)print(rdd.collect())flat_map = rdd.flatMap(lambda x: x)print(flat_map.collect())
输出:
[['m'], ['a', 'n']]['m', 'a', 'n']
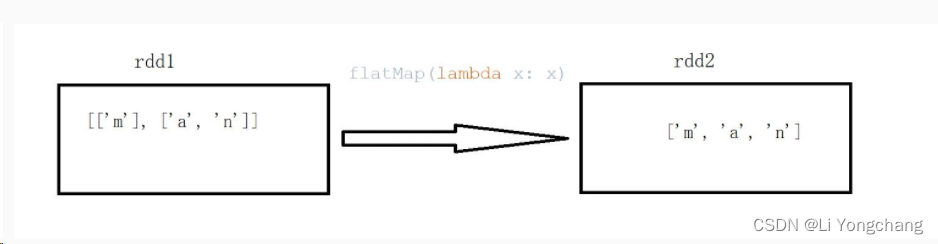
flatMap
:将两个集合转换成一个集合
Transformation - distinct
distinct
distinct
将
RDD
中的元素进行去重操作。
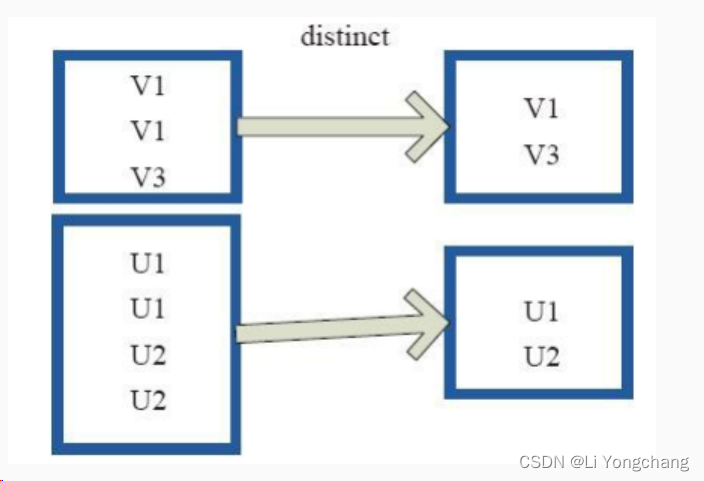
上图中的每个方框代表一个
RDD
分区,通过
distinct
函数,将数据去重。 例如,重复数据
V1
、
V1
去重后只保留一份
V1
。
distinct 案例
sc = SparkContext("local", "Simple App")data = ["python", "python", "python", "java", "java"]rdd = sc.parallelize(data)print(rdd.collect())distinct = rdd.distinct()print(distinct.collect())
输出:
['python', 'python', 'python', 'java', 'java']['python', 'java']

Transformation - sortBy
sortBy
sortBy
函数是在
org.apache.spark.rdd.RDD
类中实现的,它的实现如下:
def sortBy(self, keyfunc, ascending=True, numPartitions=None):return self.keyBy(keyfunc).sortByKey(ascending, numPartitions).values()
该函数最多可以传三个参数:
- 第一个参数是一个函数,排序规则;
- 第二个参数是
ascending,从字面的意思大家应该可以猜到,是的,这参数决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序; - 第三个参数是
numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等,即为this.partitions.size。
从
sortBy
函数的实现可以看出,第一个参数是必须传入的,而后面的两个参数可以不传入。
sortBy 案例
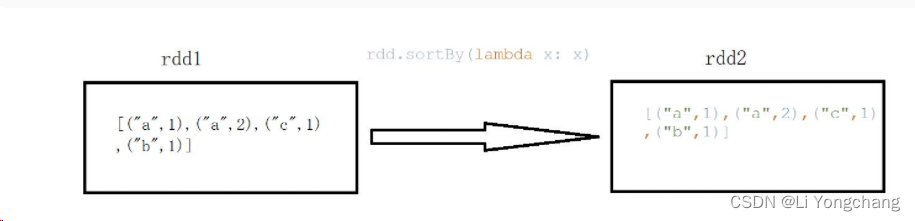
sc = SparkContext("local", "Simple App")data = [("a",1),("a",2),("c",1),("b",1)]rdd = sc.parallelize(data)by = rdd.sortBy(lambda x: x)print(by.collect())
输出:
[('a', 1), ('a', 2), ('b', 1), ('c', 1)]
Transformation - sortByKey
sortByKey
def sortByKey(self, ascending=True, numPartitions=None, keyfunc=lambda x: x):if numPartitions is None:numPartitions = self._defaultReducePartitions()memory = self._memory_limit()serializer = self._jrdd_deserializerdef sortPartition(iterator):sort = ExternalSorter(memory * 0.9, serializer).sortedreturn iter(sort(iterator, key=lambda kv: keyfunc(kv[0]), reverse=(not ascending)))if numPartitions == 1:if self.getNumPartitions() > 1:self = self.coalesce(1)return self.mapPartitions(sortPartition, True)# first compute the boundary of each part via sampling: we want to partition# the key-space into bins such that the bins have roughly the same# number of (key, value) pairs falling into themrddSize = self.count()if not rddSize:return self # empty RDDmaxSampleSize = numPartitions * 20.0 # constant from Spark's RangePartitionerf\fraction = min(maxSampleSize / max(rddSize, 1), 1.0)samples = self.sample(False, f\fraction, 1).map(lambda kv: kv[0]).collect()samples = sorted(samples, key=keyfunc)# we have numPartitions many parts but one of the them has# an implicit boundarybounds = [samples[int(len(samples) * (i + 1) / numPartitions)]for i in range(0, numPartitions - 1)]def rangePartitioner(k):p = bisect.bisect_left(bounds, keyfunc(k))if ascending:return pelse:return numPartitions - 1 - preturn self.partitionBy(numPartitions, rangePartitioner).mapPartitions(sortPartition, True)
说明:
ascending
参数是指排序(升序还是降序),默认是升序。
numPartitions
参数是重新分区,默认与上一个
RDD
保持一致。
keyfunc
参数是排序规则。
sortByKey 案例
sc = SparkContext("local", "Simple App")data = [("a",1),("a",2),("c",1),("b",1)]rdd = sc.parallelize(data)key = rdd.sortByKey()print(key.collect())
输出:
[('a', 1), ('a', 2), ('b', 1), ('c', 1)]

Transformation - mapValues
mapValues
mapValues
:针对
(Key, Value)
型数据中的
Value
进行
Map
操作,而不对
Key
进行处理。
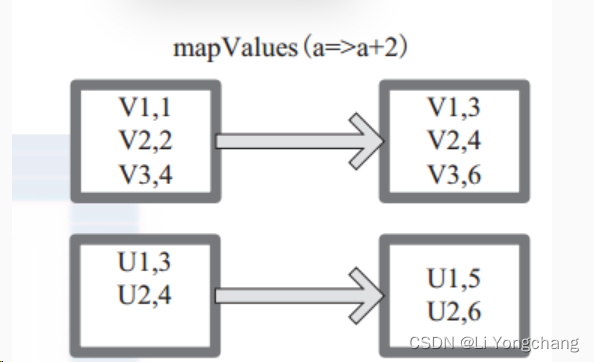
上图中的方框代表
RDD
分区。
a=>a+2
代表对
(V1,1)
这样的
Key Value
数据对,数据只对
Value
中的
1
进行加
2
操作,返回结果为
3
。
mapValues 案例
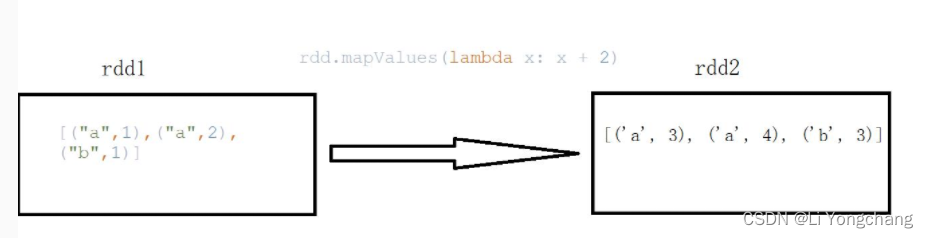
sc = SparkContext("local", "Simple App")data = [("a",1),("a",2),("b",1)]rdd = sc.parallelize(data)values = rdd.mapValues(lambda x: x + 2)print(values.collect())
输出:
[('a', 3), ('a', 4), ('b', 3)]
Transformations - reduceByKey
reduceByKey
reduceByKey
算子,只是两个值合并成一个值,比如叠加。
函数实现:
def reduceByKey(self, func, numPartitions=None, partitionFunc=portable_hash):return self.combineByKey(lambda x: x, func, func, numPartitions, partitionFunc)

上图中的方框代表
RDD
分区。通过自定义函数
(A,B) => (A + B)
,将相同
key
的数据
(V1,2)
和
(V1,1)
的
value
做加法运算,结果为
( V1,3)
。
reduceByKey 案例
sc = SparkContext("local", "Simple App")data = [("a",1),("a",2),("b",1)]rdd = sc.parallelize(data)print(rdd.reduceByKey(lambda x,y:x+y).collect())
输出:
[('a', 3), ('b', 1)]

Actions - 常用算子
count
count()
:返回
RDD
的元素个数。
示例:
sc = SparkContext("local", "Simple App")data = ["python", "python", "python", "java", "java"]rdd = sc.parallelize(data)print(rdd.count())
输出:
5
first
first()
:返回
RDD
的第一个元素(类似于
take(1)
)。
示例:
sc = SparkContext("local", "Simple App")data = ["python", "python", "python", "java", "java"]rdd = sc.parallelize(data)print(rdd.first())
输出:
python
take
take(n)
:返回一个由数据集的前
n
个元素组成的数组。
示例:
sc = SparkContext("local", "Simple App")data = ["python", "python", "python", "java", "java"]rdd = sc.parallelize(data)print(rdd.take(2))
输出:
['python', 'python']
reduce
reduce()
:通过
func
函数聚集
RDD
中的所有元素,该函数应该是可交换的和关联的,以便可以并行正确计算。
示例:
sc = SparkContext("local", "Simple App")data = [1,1,1,1]rdd = sc.parallelize(data)print(rdd.reduce(lambda x,y:x+y))
输出:
4
collect
collect()
:在驱动程序中,以数组的形式返回数据集的所有元素。
示例:
sc = SparkContext("local", "Simple App")data = [1,1,1,1]rdd = sc.parallelize(data)print(rdd.collect())
输出:
[1,1,1,1]
版权归原作者 Li Yongchang 所有, 如有侵权,请联系我们删除。