
SparkSQL 是什么
SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非 常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD。DataFrame与DataSet
DataFrame
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格,也很像pyhton中的pandas,DataFrame与RDD的主要区别在于,前者带有schema元信息(更关注于每一列的属性),即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从 API 易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API 要更加友好,门槛更低。
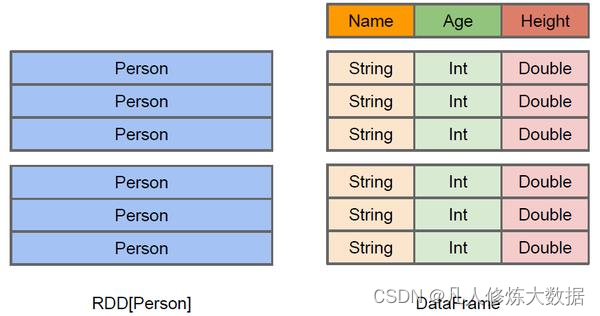
上图直观地体现了DataFrame和RDD的区别。
左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待
DataFrame也是懒执行的,但性能上比RDD要高,主要原因:优化的执行计划,即查询计划通过Spark catalyst optimiser进行优化。比如下面一个例子:


为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个
DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
DataSet
DataSet是分布式数据集合。DataSet是Spark 1.6中添加的一个新抽象,是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。DataSet也可以使用功能性的转换(操作map,flatMap,filter
等等)。
➢ DataSet是DataFrame API的一个扩展,是SparkSQL最新的数据抽象
➢ 用户友好的API风格,既具有类型安全检查也具有DataFrame的查询优化特性;
➢ 用样例类来对DataSet中定义数据的结构信息,样例类中每个属性的名称直接映射到
DataSet中的字段名称;
➢ DataSet是强类型的。比如可以有DataSet[Car],DataSet[Person]。
➢ DataFrame是DataSet的特列,DataFrame=DataSet[Row] ,所以可以通过as方法将
DataFrame转换为DataSet。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。获取数据时需要指定顺序
RDD 、 DataFrame 、 DataSet 三者的关系
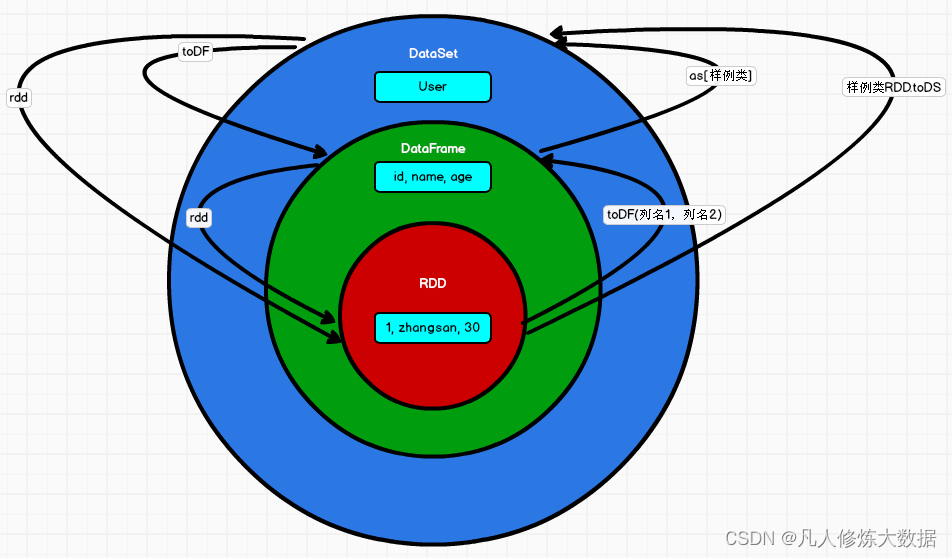
这三者是可以相互转化的
三者的共性
➢ RDD、DataFrame、DataSet全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利;
➢ 三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算;
➢ 三者有许多共同的函数,如filter,groupby等;
➢ 在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入)
➢ 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
➢ 三者都有partition的概念
➢ DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型
三者的区别
- RDD
➢ RDD一般和spark mllib同时使用
➢ RDD不支持sparksql操作 - DataFrame
➢ 与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
➢ DataFrame与DataSet一般不与 spark mllib 同时使用
DataFrame与DataSet均支持 SparkSQL 的操作,比如select,groupby之类,还能注册临时表/视窗,进行 sql 语句操作
➢ DataFrame与DataSet支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
3) DataSet
➢ Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame其实就是DataSet的一个特例 type DataFrame = Dataset[Row]
➢ DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
IDEA 开发 SparkSQL

//创建运行环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparksql")
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//执行
//DataFrame 是特定泛型的dataset
val df: DataFrame = spark.read.json("user.json")
df.show()
//DataFrame>sql
df.createOrReplaceTempView("user")
spark.sql("select * from user").show()
//DataFrame>DSL
df.select("age","username").show()
这三种展示都是同样的结果

//若涉及转换操作,需要引入转换规则
import spark.implicits._
df.select($"age"+1).as("age").show()
df.select('age+2).as("age").show()
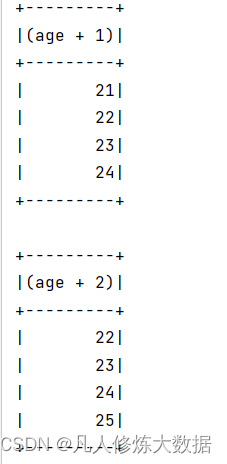
//DataSet
val seq: Seq[Int] = Seq(1, 2, 3, 4)
val ds: Dataset[Int] = seq.toDS()
ds.show()
//RDD<=>DataFrame
val rdd=spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",40)))
val df2: DataFrame = rdd.toDF("id", "name", "age")
val rowRDD: RDD[Row] = df2.rdd
//DataFrame<=>DataSet
val ds1: Dataset[User] = df2.as[User]
val df3: DataFrame = ds1.toDF()
println("------df3---------")
df3.show()
//RDD<=>DataSet
val ds3: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
println("------ds3---------")
ds3.show()
ds3.rdd
//关闭
spark.close()
}
case class User(id:BigInt,name:String,age:BigInt)

用户自定义函数
UDF
import spark.implicits._
val df: DataFrame = spark.read.json("user.json")
df.createOrReplaceTempView("user")
//自定义函数
spark.udf.register("prefixName",(name:String)=>{
"Name: "+name
})
spark.sql("select age,prefixName(username) from user").show()

UDAF
/** * 自定义聚合函数类 计算年龄品均值 */ class MyAsUDAF extends UserDefinedAggregateFunction{ //输入数据结构 override def inputSchema: StructType = { StructType( Array( StructField("age",LongType) ) ) } //缓冲区 override def bufferSchema: StructType = { StructType( Array( StructField("total", LongType), StructField("count", LongType) ) ) } //输出结果的数据类型 override def dataType: DataType = LongType override def deterministic: Boolean =true //缓冲区初始化 override def initialize(buffer: MutableAggregationBuffer): Unit = { buffer(0)=0L buffer(1)=0L } override def update(buffer: MutableAggregationBuffer, input: Row): Unit = { buffer.update(0,buffer.getLong(0)+input.getLong(0)) buffer.update(1,buffer.getLong(1)+1) } override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = { buffer1.update(0,buffer1.getLong(0)+ buffer2.getLong(0)) buffer1.update(1,buffer1.getLong(1)+ buffer2.getLong(1)) } //计算平均值 override def evaluate(buffer: Row): Any = { buffer.getLong(0)/buffer.getLong(1) }

版权归原作者 凡人修炼大数据 所有, 如有侵权,请联系我们删除。