
我们是青年,不是畸人,不是愚人,应当给自己把幸福争过来
## 1.Halo 简介
Halo是一款基于Java的开源建站工具,具有简单易用、灵活性高、插件丰富等优点。可以做博客的软件平台有很多,像大家熟知的 WordPress 、Hexo、Typecho,对于计算机专业的人来说,他们会根据自己的需求选择适合的平台,但对于小白来说Halo虽然没有功能没有老牌的博客平台那么全面,但是操作简单,博客界面也很简洁美观。
## 2.Docker 简介
Docker简介出自:通俗的解释什么是Docker,一文搞懂_docker是什么-CSDN博客
**Docker **最初是 dotCloud 公司创始人 Solomon Hykes 在法国期间发起的一个公司内部项目,它是基于dotCloud 公司多年云服务技术的一次革新,并于 2013 年 3 月以 Apache 2.0 授权协议开源,主要项目 代码在 GitHub 上进行维护。Docker 项目后来还加入了 Linux 基金会,并成立推动 开放容器联盟(OCI)。

Docker 公司起初是一家名为 dotCloud 的平台即服务(Platform-as-a-Service, PaaS)提供商。底层技术上,dotCloud 平台利用了 Linux 容器技术。为了方便创建和管理这些容器,dotCloud 开发了一套内部工具,之后被命名为“Docker”。Docker就是这样诞生的!
### 2.1 什么是 Docker
微服务虽然具备各种各样的优势,但服务的拆分通用给部署带来了很大的麻烦。
- 分布式系统中,依赖的组件非常多,不同组件之间部署时往往会产生一些冲突。
- 在数百上千台服务中重复部署,环境不一定一致,会遇到各种问题
#### 2.1.1 应用部署的环境问题
大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题:
- 依赖关系复杂,容易出现兼容性问题
- 开发、测试、生产环境有差异
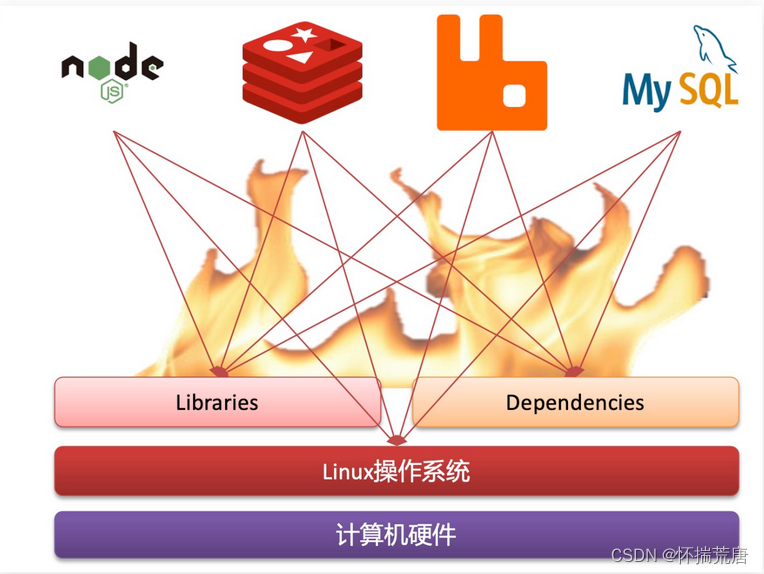
例如一个项目中,部署时需要依赖于node.js、Redis、RabbitMQ、MySQL等,这些服务部署时所需要的函数库、依赖项各不相同,甚至会有冲突。给部署带来了极大的困难。
#### 2.1.2 Docker 解决依赖兼容问题
Docker为了解决依赖的兼容问题的,采用了两个手段:
- 将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包
- 将每个应用放到一个隔离容器去运行,避免互相干扰
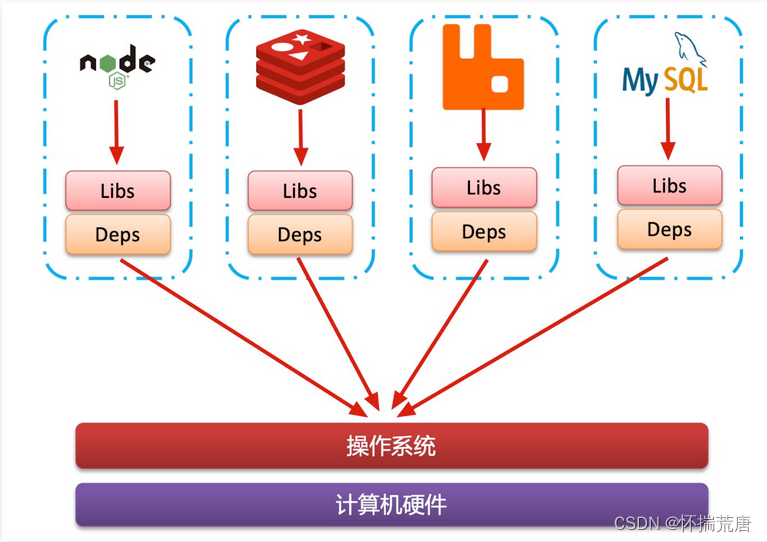
这样打包好的应用包中,既包含应用本身,也保护应用所需要的Libs、Deps,无需再操作系统上安装这些,自然就不存在不同应用之间的兼容问题了。 虽然解决了不同应用的兼容问题,但是开发、测试等环境会存在差异,操作系统版本也会有差异,怎么解决这些问题呢?
#### 2.1.3 Docker 解决操作系统差异
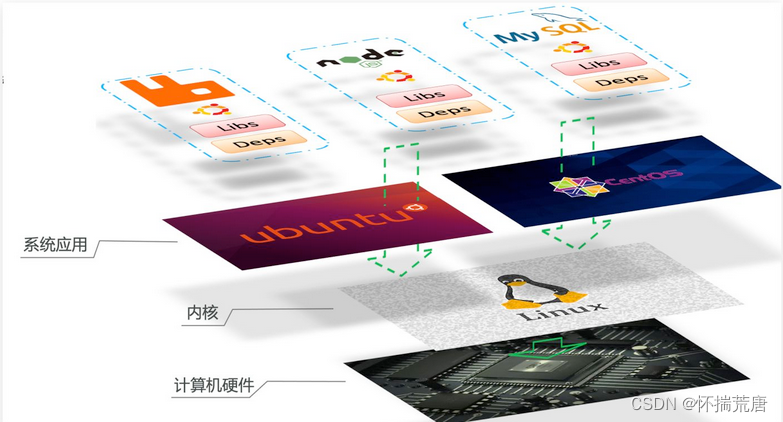
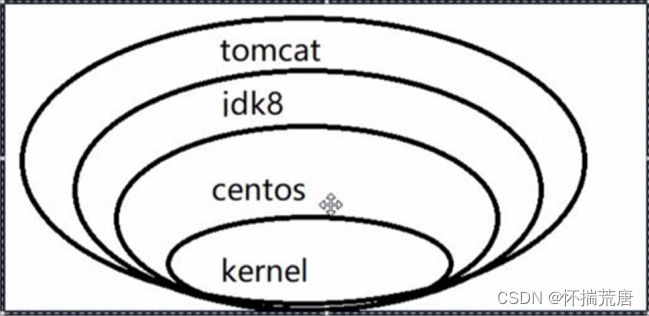
要解决不同操作系统环境差异问题,必须先了解操作系统结构。以一个Ubuntu操作系统为例,结构如下:

结构包括:
- 计算机硬件:例如CPU、内存、磁盘等
- 系统内核:所有Linux发行版的内核都是Linux,例如CentOS、Ubuntu、Fedora等。内核可以与计算机硬件交互,对外提供内核指令,用于操作计算机硬件。
- 系统应用:操作系统本身提供的应用、函数库。这些函数库是对内核指令的封装,使用更加方便。
应用于计算机交互的流程如下:
1)应用调用操作系统应用(函数库),实现各种功能
2)系统函数库是对内核指令集的封装,会调用内核指令
3)内核指令操作计算机硬件
Ubuntu和CentOSpringBoot都是基于Linux内核,无非是系统应用不同,提供的函数库有差异:

此时,如果将一个Ubuntu版本的MySQL应用安装到CentOS系统,MySQL在调用Ubuntu函数库时,会发现找不到或者不匹配,就会报错了:

Docker如何解决不同系统环境的问题?
- Docker将用户程序与所需要调用的系统(比如Ubuntu)函数库一起打包
- Docker运行到不同操作系统时,直接基于打包的函数库,借助于操作系统的Linux内核来运行
如图:
#### 2.1.4 小结--应用 Docker 缘由
Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题?
- Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker如何解决开发、测试、生产环境有差异的问题?
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术,具备下列优势:
- 可以将程序及其依赖、运行环境一起打包为一个镜像,可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动、移除都可以通过一行命令完成,方便快捷
### 2.2 Docker 和虚拟机的区别
Docker可以让一个应用在任何操作系统中非常方便的运行。而以前我们接触的虚拟机,也能在一个操作系统中,运行另外一个操作系统,保护系统中的任何应用。
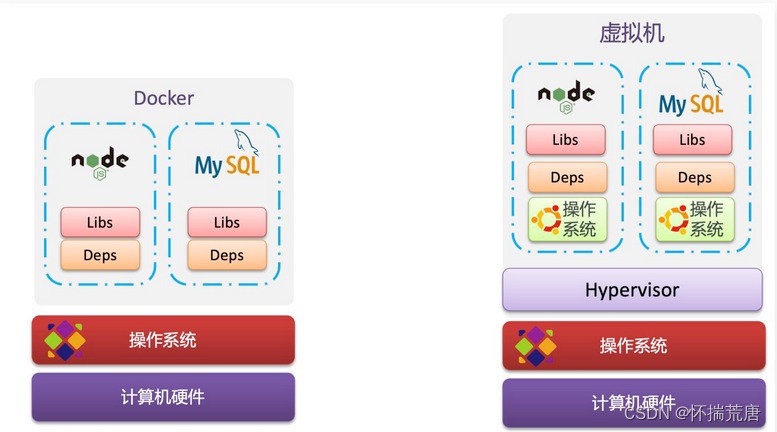
** 虚拟机(virtual machine)是在操作系统中模拟**硬件设备,然后运行另一个操作系统,比如在 Windows 系统里面运行 Ubuntu 系统,这样就可以运行任意的Ubuntu应用了。
** Docker**仅仅是封装函数库,并没有模拟完整的操作系统,如图:
二者对比:

虚拟机(VM)是将一个服务器转换为多个服务器的物理硬件的抽象,其实就是带环境安装的一种解决方案,虚拟机的缺点:**资源占用多、冗余步骤多 、启动慢。 ** 管理程序允许多个 VM 在一台机器上运行。每个虚拟机都包含一个操作系统、应用程序、必要的二进制文件和库的完整副本——占用了几十个 GB。VM 启动速度也可能很慢。 VM是一个运行在宿主机之上的完整的操作系统,VM运行自身操作系统会占用较多的CPU、内存、硬盘资源。
Docker不同于VM,只包含应用程序以及依赖库,基于 libcontainer 运行在宿主机上,并处于一个隔离的环境中,这使得Docker更加轻量高效,启动容器只需几秒钟之内完成。 由于Docker轻量、资源占用少,使得Docker可以轻易的应用到构建标准化的应用中。但Docker目前还不够完善,比如隔离效果不如VM,共享宿主机操作系统的一些基础库等;网络配置功能相对简单,主要以桥接方式为主;查看日志也不够方便灵活。
#### 2.2.1 小结
Docker和虚拟机的差异:
- docker是一个系统进程;虚拟机是在操作系统中的操作系统
- docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
### 2.3 Docker 架构
#### 2.3.1 镜像和容器
Docker中有几个重要的概念:**仓库、镜像和容器 **,它们是Docker的三大基础组件。
Docker使用客户端-服务器体系结构。Docker客户端与Docker守护进程进行通信,后者负责构建、运行和分发Docker容器。Docker客户端和守护进程可以在同一系统上运行,也可以将Docker客户端连接到远程Docker守护进程。Docker客户端和守护进程使用REST API通过UNIX套接字或网络接口进行通信。另一个Docker客户端是Docker Compose,它允许您使用由一组容器组成的应用程序。
*Docker***守护进程 **
Docker守护进程(dockerd)监听Docker API请求并管理Docker对象,如图像、容器、网络和卷。守护进程还可以与其他守护进程通信以管理Docker服务。*Docker***客户端 **
Docker客户端(Docker)是许多Docker用户与Docker交互的主要方式。当您使用诸如docker-run之类的命令时,客户端会将这些命令发送给dockerd,后者会执行这些命令。docker命令使用docker API。 Docker客户端可以与多个守护进程进行通信。*Docker***仓库 **
Docker仓库存储Docker镜像。Docker Hub是一个任何人都可以使用的公共仓库,默认情况下Docker会在DockerHub上查找映像。您甚至可以运行自己的私人仓库。 当使用docker pull或docker run命令时,docker会从您配置的注册表中提取所需的映像。当您使用docker push命令时,docker会将您的映像推送到您配置的注册表中。
镜像(Image):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
操作系统分为 **内核 **和 **用户空间**。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 **Docker ****镜像**(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:18.04 就包含了完整的一套 Ubuntu 18.04 最小系统的 root 文件系统。** Docker 镜像 是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含 **任何动态数据,其内容在构建之后也不会被改变。
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器进程做隔离,对外不可见。
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静 态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。 容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。 容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。 这种特性使得容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
仓库:
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。 一个 **Docker Registry **中可以包含多个 **仓库**(Repository);每个仓库可以包含多个 **标签**(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过**<****仓库名****>:<****标签****> **的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。
以 Ubuntu 镜像 为例,ubuntu 是仓库的名字,其内包含有不同的版本标签,如,16.04, 18.04。我们可以通过 ubuntu:16.04,或者 ubuntu:18.04 来具体指定所需哪个版本的镜像。如果忽略了标签,比如ubuntu,那将视为 ubuntu:latest。 仓库名经常以**两段式路径**形式出现,比如 jwilder/nginx-proxy,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务。
一切应用最终都是代码组成,都是硬盘中的一个个的字节形成的文件。只有运行时,才会加载到内存,形成进程。 镜像,就是把一个应用在硬盘上的文件、及其运行环境、部分系统函数库文件一起打包形成的文件包。这个文件包是只读的。 容器,就是将这些文件中编写的程序、函数加载到内存中允许,形成进程,只不过要隔离起来。因此一个镜像可以启动多次,形成多个容器进程。
通常容器提供了基于各种Linux发行版创建容器映像的方法、用于管理容器生命周期的API、用于与API交互的客户端工具、获取快照的特性、将容器实例从一个容器主机迁移到另一个容器主机等。 Linux容器是与系统其他部分隔离开的一系列进程,从另一个镜像运行,并由该镜像提供支持进程所需的全部文件。容器提供的镜像包含了应用的所有依赖项,因而在从开发到测试再到生产的整个过程中,它都具有可移植性和一致性。

例如你下载了一个QQ,如果我们将QQ在磁盘上的运行**文件**及其运行的操作系统依赖打包,形成QQ镜像。然后你可以启动多次,双开、甚至三开QQ,用不同账号达成多个聊天。
#### 2.3.2 DockerHub
开源应用程序非常多,打包这些应用往往是重复的劳动。为了避免这些重复劳动,人们就会将自己打包的应用制作镜像,例如Redis、MySQL镜像放到网络上,共享使用,就像GitHub的代码共享一样。 DockerHub:DockerHub是一个官方的Docker镜像的托管平台。这样的平台称为Docker Registry。 国内也有类似于DockerHub 的公开服务,比如 网易云镜像服务、阿里云镜像库等。我们一方面可以将自己的镜像共享到DockerHub,另一方面也可以从DockerHub拉取镜像:

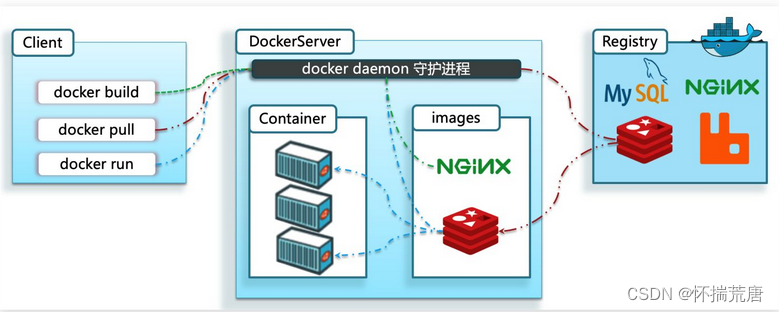
#### 2.3.3 Docker 架构
我们要使用Docker来操作镜像、容器,就必须要安装Docker。
Docker是一个CS架构的程序,由两部分组成:
- 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
- 客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令。如下图:
#### 2.3.4 小结
镜像:
将应用程序及其依赖、环境、配置打包在一起容器:
镜像运行起来就是容器,一个镜像可以运行多个容器Docker结构:
服务端:接收命令或远程请求,操作镜像或容器 客户端:发送命令或者请求到Docker服务端DockerHub:
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry1.4.安装Docker
### 2.4 LXC 容器技术介绍
#### 2.4.1 LXC 简述
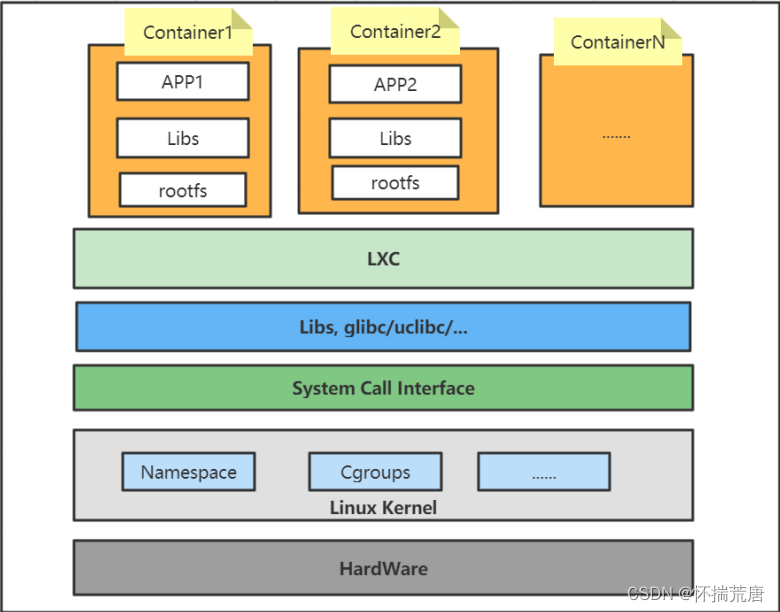
LXC是Linux Containers的简称,即Linux 容器。LXC是一种虚拟化技术,可以在操作系统层级上为应用程序提供虚拟的运行环境,内含应用程序本身的代码、所需要的操作系统kernel和依赖的库文件,这个虚拟的运行环境就是一个容器。
LXC作为Linux内核容器特性的一个用户空间接口,通过系统调用去操作各种内核功能,使得容器具有以下几个**典型特征**:**①单容器,资源可控 **
LXC在资源管控方面依赖于Linux内核特性 - Cgroups(Linux Control Groups),实现对容器中进程使用系统资源的管控和记录。常用的资源管控包括:
CPU:统计和限制CPU使用时间周期、使用率
内存:统计和限制内存使用值(process memory, kernel memory和swap)
blkio(Block IO) :限制块设备(磁盘、SSD、USB 等)的 IO 速率
**②多容器,互相隔离 **
LXC在隔离控制方面依赖于Linux内核特性 - Namespace,实现多容器之间运行环境隔离。每个容器拥有自己的namespace,可以对其他容器隐藏自身的进程空间和资源信息。
处于同一namespace下的进程才可以进行进程间通信。
PID、IPC、Network等系统资源不再是全局性的,而是属于特定的namespace,每个namespace里面的资源对其他namespace都是透明的。
#### 2.4.2 LXC 基本架构
#### 2.4.3 容器发展史
*阶段一:隔离文件——chroot*命令的诞生 **
在1979年,Unix系统引入了一个革命性的命令,它允许系统管理员将进程的根目录锁定在指定的位置,从而有效地限制了该进程访问的文件系统范围。这个命令成为了早期容器技术的基石,因为它实现了基本的文件系统隔离,确保进程不能访问其指定根目录之外的任何文件或目录。 这种隔离能力对于安全性至关重要,特别是在监控潜在的恶意活动时。通过创建一个隔离的环境,或所谓的“黑盒”,系统管理员能够更安全地运行和监控可疑的代码或程序。 因此这个以文件形式进行隔离的命令为现代容器技术奠定了一个重要的思想基础:隔离。后续的很多演变也都是基于“隔离”进行变化。
*阶段二:隔离访问——namespace*名称空间 **
在2002年,Linux社区迎来了一个重要的里程碑:引入了Linux名称空间(namespace)功能。 名称空间是一种轻量级的虚拟化技术,它允许不同的进程拥有自己的独立视图,包括文件系统、进程ID (PID)、用户ID(UID)、网络接口等关键系统资源。 因此每个进程都在一个独立的环境中运行,这意味着在一个名称空间中所做的更改(例如文件系统的修改、网络配置等)不会影响到其他名称空间。这种隔离不仅提高了系统的安全性,因为它限制了进程可能造成的潜在影响,也使得多个应用能够在同一个物理服务器上同时运行,而互不干扰。 在容器化的上下文中,名称空间提供了实现容器隔离的关键技术。因为每个容器实际上就是一组不同的名称空间和一些其他资源(如下文提到的cgroups)的集合。
*阶段三:隔离资源——cgroups*控制组特性 **
Cgroups(控制组)是Linux内核的一个特性,最初由Google工程师Paul Menage和Rohit Seth在2006年提出。 它通过将进程分组,并对这些分组进行资源控制和隔离,从而允许系统管理员精确地控制和限制进程组使用的资源量,如CPU时间、系统内存、网络带宽或磁盘I/O等。通过这种方式,能够有效避免一个进程出现问题把同机器上的其他进程的资源耗尽或占用, 成为了实现资源隔离和保证系统稳定性的强大工具。 因此Linux的cgroups是现代容器技术中不可或缺的一部分,它提供核心的资源隔离和限制的底层实现原理。
阶段四:封装系统——LXC虚拟化**(Linux Containers) **
LXC是linux发布的系统级虚拟化功能。它允许用户在同一宿主机上运行多个隔离的Linux系统实例。每个实例,或称为容器,都拥有自己的文件系统、网络配置和进程空间,但与传统虚拟机相比,LXC容器共享宿主机的内核,使得它们更为轻量级和高效。 LXC的理念在于封装系统,这意味着每个LXC容器都运行着完整的操作系统,包括其所有的服务和进程。缺点在于每个LXC的体积相当大,当系统内的部件需要修改,必须重写很多配置,导致维护和更新过程相对繁琐和耗时。 基于LXC的缺点,有了相应改进,才有了后面Docker容器的诞生和迅猛发展。
*阶段五:封装应用——Docker*容器 **
docker的容器化能力直接来源自lxc。后面docker的开发人员又自己用go语言开发了libcontainer避免了对lxc的强依赖。 对比于LXC, docker容器的理念在于封装应用。容器通常只包含运行单个应用所必需的最小环境,这使得它们非常轻量级和快速。当应用或其依赖需要更新时,只需修改有关部分并重新构建容器,这通常可以在几秒钟内完成。 除了轻量化以应用为中心的构建外,docker对比LXC还有以下七点优势:
跨机器的绿色部署:将所有环境依赖打包到一起,避免对机器的依赖。
自动构建:无需关注目标机器具体配置,使用任务构建工具在容器中自动构建。
多版本支持:支持git一样管理容器版本。
组件重用, 可以在基础镜像上构建专业化镜像。
共享,有公共的镜像仓库。
工具生态可以很方便扩展。
但Docker并不是没有缺点。由于它主要关注应用层,这就需要开发者和系统管理员对应用的依赖和环境有深入的了解,以确保在不同环境中一致性和安全性的维护。
*阶段六:封装集群***——kubernetes **
k8s(kubernetes)是容器编排框架, 把大型软件系统运行所依赖的集群环境也进行了另一种形式的虚拟化,令集群得以实现跨数据中心的绿色部署,实现自动扩缩。可以用一个例子来理解k8s和docker之间的关系:
Kubernetes 则相当于餐厅的经理,负责整体的流程和调度。它确保所有菜肴(容器)都能按时准备 好,并且根据顾客的需求(负载)来增减特定的菜肴数量。比如,如果一道菜特别受欢迎,Kubernetes 可以指示厨房(集群)制作更多的这道菜(即扩展容器)。如果某个炉子坏了(节点故障),它会将菜 肴分配到其他炉子上(重新调度容器)。 按工程语言描述,Kubernetes负责管理由这些容器组成的应用集合,确保它们按预期方式运行。它处理部署、替换故障容器、服务发现、负载均衡、扩展和缩减容器数量等任务。 虽然k8s最开始完全绑定依赖docker, 但通过引入容器运行时接口(Container Runtime Interface,CRI), 允许 Kubernetes 与多种容器运行时兼容,如CRI-O、containerd等, 因此Kubernetes 能够更加专注于其核心目标:集群场景下的容器编排

*阶段七:封装容器服务——基于云服务的容器化(CCE*) **
对于传统本地搭建K8S集群而言,具有以下劣势:
高成本: 自行搭建和维护Kubernetes集群需要大量的前期投资,包括硬件、网络设施等。
复杂性: 搭建和维护一个高效、稳定的k8s环境需要深厚的技术知识和经验。
维护负担: 需要持续投入人力去管理和维护硬件、软件、网络等。
缩放困难: 根据业务需求快速扩展或缩小资源可能会非常复杂和耗时。在业务初期发展阶段,纯靠经验很难快速覆盖各种缩放场景。
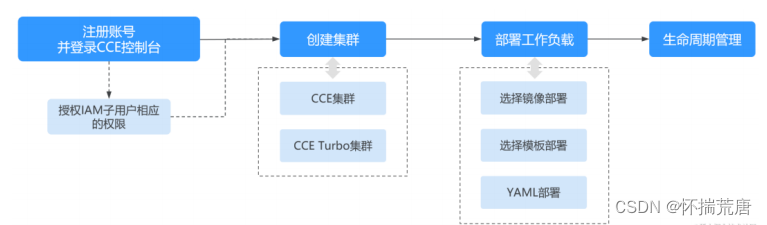
因此随着云计算的普及和成熟,容器化技术也开始步入云服务时代。这一时期,云服务提供商纷纷推出了各自的容器服务产品,如华为云的CCE(云容器引擎)服务等, 企业和开发者也越来越多地转向云平台来部署和管理容器应用,享受云计算带来的灵活性、可扩展性和成本效益。通过使用云服务提供的容器化能力,可以做到:
简化管理: 云服务提供商通常提供易于使用的管理界面和API,简化了集群的搭建、管理和扩展。
快速部署: 可以在十几分钟内就能启动和配置一个完整的k8s环境。例如通过CCE快速入门,我们可以快速熟悉容器创建的整个过程。
自动扩缩容: 云服务通常提供自动扩缩容功能,根据实际负载自动调整资源。比如CCE的弹性伸缩,可以从工作负载和节点两个维度进行伸缩。
同时我们能够见到的各种云服务也会依赖CCE云容器引擎的能力快速构建基础核心能力,例如大数据或AI等服务也可以利用CCE的高度可扩展性和弹性来处理海量数据,支持复杂的数据处理和分析任务。
### 2.5 Docker 安装
Docker从17.03版本之后分为CE(Community Edition: 社区版)和EE(Enterprise Edition: 企业版)。相对于社区版本,企业版本强调安全性,但需付费使用。这里我们使用社区版本即可。
Docker支持64位版本的CentOS 7和CentOS 8及更高版本,它要求Linux内核版本不低于3.10。 查看Linux版本的命令这里推荐两种: lsb_release -a 或 cat /etc/redhat-release 。[root@1 ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)显然,当前Linux系统为CentOS7。再查一下内核版本是否不低于3.10。
查看内核版本有三种方式:
- cat /proc/version
- uname -a
- uname -r
#### 2.5.1 Docker 自动化安装
Docker官方和国内daocloud都提供了一键安装的脚本,使得Docker的安装更加便捷。
①官方的一键安装方式: (我用了这个,很成功!)
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun②国内 daocloud一键安装命令:
curl -sSL https://get.daocloud.io/docker | sh以上两条选择任意一条自动安装即可!
#### 2.5.2 Docker 手动安装
手动安装Docker分三步:卸载、设置仓库、安装。
①卸载Docker("卸载历史版本"--可选)
检查是否安装过Docker:
rpm -qa |grep docker
若之前安装过旧版本的Docker,可以使用如下命令进行卸载:
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce
②设置源仓库
新主机上首次安装Docker Engine-Community之前,需要设置Docker仓库。此后可从仓库安装和更新Docker。 在设置仓库之前,需先安装所需的软件包。yum-utils提供了yum-config-manager,并且device mapper存储驱动程序需要device-mapper-persistent-data和lvm2。
yum install -y yum-utils device-mapper-persistent-data lvm2
执行上述命令,安装完毕即可进行仓库的设置。使用官方源地址设置命令如下:
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
通常,官方的源地址比较慢,可将上述的源地址替换为国内比较快的地址:
- 阿里云:http:**//mirrors.aliyun.com/docker-ce/linux/centos/**docker-ce.repo
- 清华大学源:https:**//mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/**docker-ce.repo
如换成阿里的地址:
yum-config-manager --add-repo https://mirrors.aliyun.com/dockerce/linux/centos/docker-ce.repo
仓库设置完毕,即可进行Docker的安装
③Docker安装
执行以下命令,安装最新版本的 Docker Engine-Community 和 containerd。
yum install -y docker-ce docker-ce-cli containerd.io
docker-ce为社区免费版本。稍等片刻,docker即可安装成功。但安装完成之后的默认是未启动的,需要进行启动操作。
如果不需要docker-ce-cli或containerd.io可直接执行如下命令:
yum install -y docker-ce
### 2.6 Docker 启动
# 启动Docker的命令
systemctl start docker
# 设置成开机自启
systemctl enable docker
**建立 ****docker ****用户组 **
默认情况下,docker 命令会使用 Unix socket与 Docker 引擎通讯。而只有 root 用户docker 组的用户才可以访问 Docker 引擎的 Unix socket。出于安全考虑,一般 Linux 系统上不会直接使用 root 用户。因此,要将需要使用 docker 的用户加入 docker 用户组。
# 建立docker用户组
sudo groupadd docker
# 将当前用户加入 docker 组
usermod -aG docker $USER
*docker***验证 **
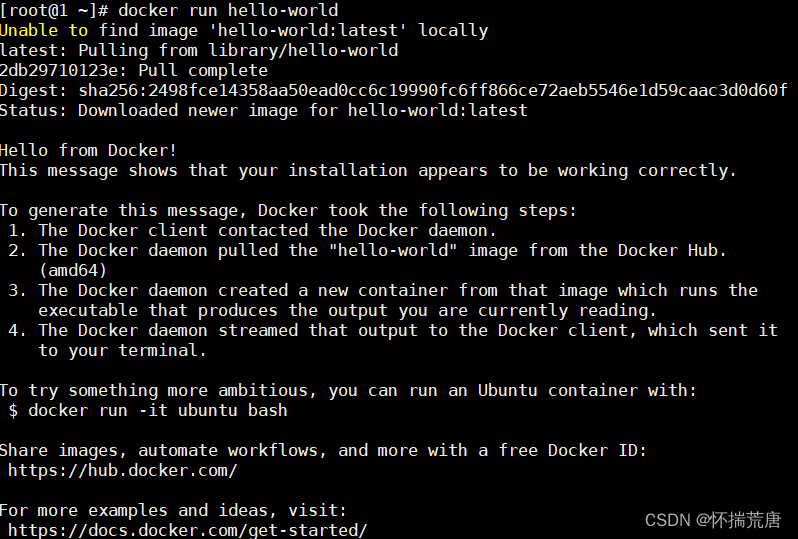
通过运行hello-world镜像来验证是否正确安装了Docker Engine-Community。
# 拉取镜像
docker pull hello-world
# 执行hello-world
docker run hello-world
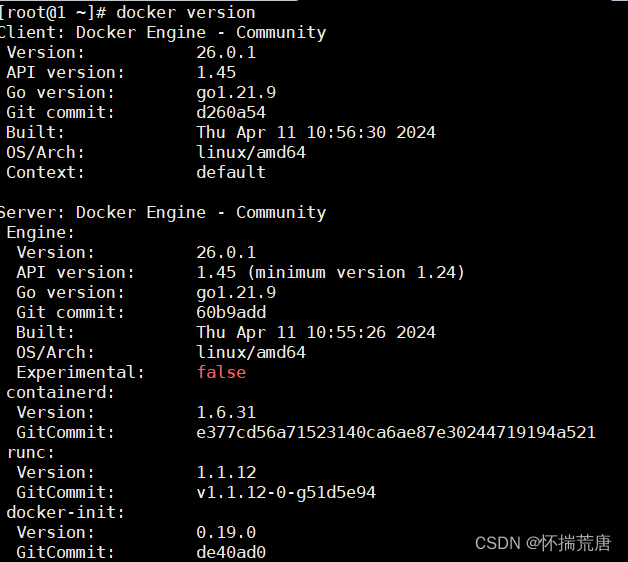
如果执行之后,控制台显示如下信息,则说明Docker安装和启动成功:
或者使用docker version验证安装是否成功(有client和service两部分表示docker安装启动都成功了)
#### 2.6.1 Docker 其他启动相关命令
除了启动Docker,一些其他启动相关的命令:
- 守护进程重启:systemctl daemon-reload
- 重启Docker服务:systemctl restart docker / service docker restart
- 关闭Docker服务:docker service docker stop / docker systemctl stop docker
#### 2.6.2 Docker 运行原理
Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上,然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。

Docker容器的实现原理就是通过Namespace命名空间实现进程隔离,UnionFilesystem联合文件系统实现文件系统隔离,ControlGroups控制组实现资源隔离。 Docker利用Linux中的核心分离机制,例如Cgroups,以及Linux的核心Namespace(命名空间)来创建独立的容器。 Docker就是利用Namespace做资源隔离,用Cgroup做资源限制,利用Union FS做容器文件系统的轻量级虚拟化技术。
#### 2.6.3 Docker 命令及故障方案
官方命令文档:https://docs.docker.com/engine/reference/commandline/search/
- 搜索仓库镜像:docker search 镜像名
- 拉取镜像:docker pull 镜像名
- 查看正在运行的容器:docker ps
- 查看所有容器:docker ps -a
- 删除容器:docker rm container_id
- 查看镜像:docker images
- 删除镜像:docker rmi image_id
- 启动(停止的)容器:docker start 容器ID
- 停止容器:docker stop 容器ID
- 重启容器:docker restart 容器ID
- 启动(新)容器:docker run -it ubuntu /bin/bash
- 进入容器: docker attach 容器ID 或 docker exec -it 容器ID /bin/bash ,推荐使用后者
##### 2.6.3.1 命令及实例
# 查看已拉取或已制作镜像
docker images
# 或docker image ls
## 结果
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
hello-world latest 9f5834b25059 14 months ago 1.84 kB
## 结果解释
REPOSITORY:表示镜像的仓库源
TAG:镜像的标签
IMAGE ID:镜像ID
CREATED:镜像创建时间
SIZE:镜像大小
**①docker search 搜索某个镜像名称(从http://hub.docker.com) **
例:
命令:
docker search tomcat
## 结果:NAME DESCRIPTION STARS OFFICIAL
AUTOMATED
tomcat Apache Tomcat is an open source implementa... 2659
[OK]
tomee Apache TomEE is an all-Apache Java EE cert... 75
[OK]
dordoka/tomcat Ubuntu 14.04, Oracle JDK 8 and Tomcat 8 ba... 53
[OK]
bitnami/tomcat Bitnami Tomcat Docker Image 31
[OK]
kubeguide/tomcat-app Tomcat image for Chapter 1 28
[OK]
也可从docker hub上下载,其命令本身就是搜索的这个仓库
**②docker pull 镜像名称[:TAG] 下载镜像 **
例:
命令:
docker pull tomcat:latest
结果:
Pulling from tomcated7bc7435c95: Pull complete......Digest:
sha256:613e0884313f0da2e3b536c0c1c1850a9df405055e78320eb24b1559b708fa3cStatus:
Downloaded newer image for tomcat:latest
#### 国内镜像加速配置
由于网络原因,国外的镜像国内通过网络下载不是很顺利,因此需要配置国内镜像加速
要编辑一个国内的文件
vim /etc/docker/daemon.json
# 内容:
{
"registry-mirrors": [
"https://sopn42m9.mirror.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com"
]
}
*配置完后重启***docker: **
systemctl daemon-reload
systemctl restart docker
③docker rmi 镜像名称[:TAG] 删除镜像
##### 2.6.3.2 容器运行命令
# 有镜像才能创建容器
# 命令框架--新建并启动容器
docker run [OPTION] IMAGE [COMMAND][ARG...]
## 命令参数
–-name=“容器新名字”: 为容器指定一个名称;
-d: 后台运行容器,并返回容器ID,也即启动守护式容器;
-i:以交互模式运行容器,通常与 -t 同时使用;
-t:为容器重新分配一个伪输入终端,通常与 -i 同时使用;
-P: 随机端口映射;将容器内部开放的网络端口随机映射到宿主机的一个端口上
-p: 指定端口映射,一个指定端口上只可以绑定一个容器,有以下四种格式
①IP:HOSTPORT:CONTAINERPORT:指定IP、指定宿主机port、指定容器port
- 适用于映射到指定地址的指定端口
例:将Docker容器的5000端口映射到指定地址127.0.0.1的8081端口上:
**# docker run -it -d -p 127.0.0.1:8081:5000 docker.io/centos:latest /bin/bash **
镜像如果本地没有,则run命令会先下载再运行容器
②IP::CONTAINERPORT:指定IP、未指定宿主机port(宿主机随机端口)、指定容器port
- 适用于映射到指定地址的任意端口
例:将Docker容器的4000端口映射到指定地址127.0.0.1的任意端口上:
**# docker run -it -d -p 127.0.0.1::4000 docker.io/centos:latest /bin/bash **
③HOSTPORT:CONTAINERPORT:未指定IP、指定宿主机port、指定容器port
- 适用于将容器指定端口指定映射到宿主机的一个端口上(映射所有接口地址)
例:将Docker容器的80端口映射到宿主机的8000端口上:
# docker run -it -d -p 8000:80 docker.io/centos:latest /bin/bash
注:以上操作默认会绑定本地所有接口上的所有地址
④指定镜像id和容器名称运行
eg:docker run -it --name mycentos 2f5f33207762
紫色是容器的指定名字,蓝色是镜像ID
# 命令框架
docker ps [OPTIONS] 列出正在运行的容器
# 命令参数
OPTIONS说明(常用):
•-a : 列出当前所有正在运行的容器+历史上运行过的
•-l : 显示最近创建的容器。
•-n:显示最近n个创建的容器。
•-q : 静默模式,只显示容器编号。
•–no-trunc : 不截断输出。
# 示例
[root@hadoop1]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a596cb0250f4 efa3cf "/bin/bash" 5 minutes ago Up 5 minutes desperate_turing
##### 2.6.3.3 容器常用操作命令
# 容器停止并退出
exit
# 容器不停止退出
Ctrl + p + q
# 启动容器
docker start 容器ID
# 重启容器
docker restart 容器ID
# 停止容器
docker stop 容器ID
# 强制停止容器
docker Kill 容器ID
# 删除已停止容器
docker rm -f 容器ID
# 启动守护式容器,不显示终端,可以通过查日志了解运行情况
docker run -d centos /bin/bash -c "while true;do echo hello zzyy;sleep2;done"
# 查看日志
docker logs -f -t --tail 倒数几条 容器ID
**查看容器内运行的进程 **
**docker top 容器ID **
查看容器内部细节
docker inspect 容器ID
进入正在运行的容器并以命令行交互
1.直接进入容器启动命令的终端,不会启动新的进程
**docker attach 容器ID **
2.是在容器中打开新的终端,并且可以启动新的进程
docker exec -it 容器ID bashShell
从容器内拷贝文件到主机上
docker cp 容器ID:容器内路径 目标主机路径
例:
容器到宿主机的copy:
docker cp 9wsw2cdwwe340d:/docker-entrypoint.sh .
宿主机copy文件到容器内:
docker cp a.sh 9wsw2cdwwe340d:/
### 2.7 联合文件系统(UnionFS)-OverlayFS
#### 2.7.1 镜像、容器和层
docker中镜像是层级结构的,即图中的 image layers ,每一层只是与它之前的层的一组差异。这些层堆叠在彼此的顶部。**当我们创建一个新容器时,会在镜像层加一个新的可写层。这一层通常被称为****“****容器****层****”****。对正在运行的容器所做的所有更改,例如写入新文件、修改现有文件和删除文件,都将写入这个薄****的可写容器层。 **
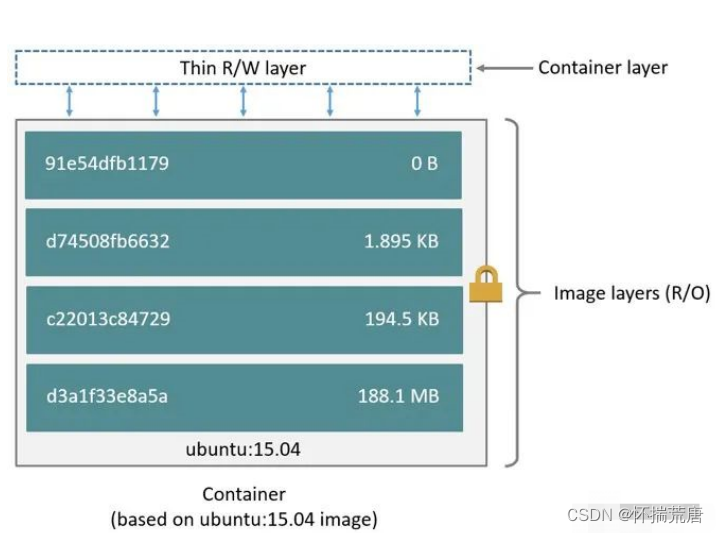
那么**一个镜像创建多个容器时是怎样的景象呢?**如下图所示,添加新数据或修改现有数据的所有写入容器都存储在此可写层中。当容器被删除时,可写层也被删除。底层镜像保持不变。因为每个容器都有自己的可写容器层,所有的变化都存储在这个容器层中,所以多个容器可以共享对同一个底层镜像的访问,同时又拥有自己的数据状态。
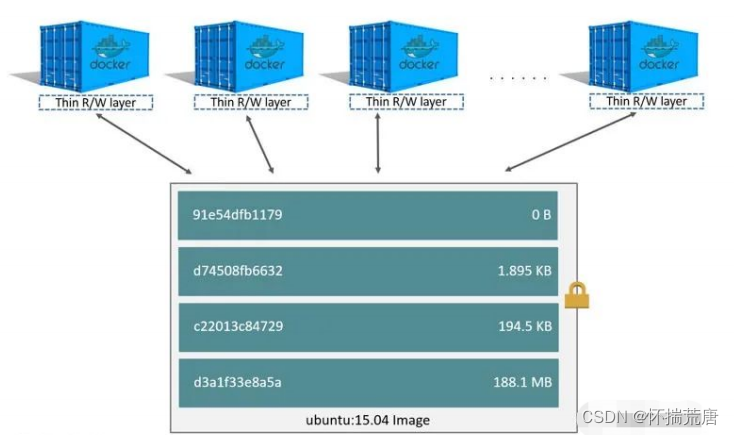
通过镜像的层级结构主要的一个优点是你可以将镜像进行共享。
为什么一个Tomcat镜像500Mb:因为它有很多层依赖,如此一来通过镜像分层可以大大减少磁盘空间占用,同时降低镜像复构建杂度。
分层最大的一个好处就是**共享资源 ** 有多个镜像都从相同的base镜像构建而来,那么宿主机只需在磁盘上保存一份base镜像; 同时内存中也只需加载一份base镜像,就可以为所有容器服务了,而且镜像的每一层都可以被共享。
#### 2.7.2 联合文件系统OverlayFS
Docker 中的镜像采用分层构建设计,每个层可以称之为 layer ,这些 layer 被存放在了 /var/lib/docker/<storage-driver>/ 目录下,这里的 storage-driver 可以有很多种如:
- AUFS
- Overlay
- FSVFS
- Brtfs
通常 ubuntu 类的系统默认采用的是 AUFS,CentOS 7.1+系列采用的是 OverlayFS而本文将介绍以OverlayFS作为存储驱动的镜像存储原理以及存储结构
##### 2.7.2.1 OverlayFS 简介
OverlayFS 是一种堆叠文件系统,它依赖并建立在其它的文件系统之上(例如 ext4fs 和 xfs 等等),并不直接参与磁盘空间结构的划分,仅仅将原来底层文件系统中不同的目录进行“合并”,然后向用户呈 现,这也就是联合挂载技术,对比于 AUFS,OverlayFS 速度更快,实现更简单。 而 Linux 内核为 Docker 提供的 OverlayFS 驱动有两种:**overlay**和**overlay2 **** **overlay2 是相对于 overlay 的一种改进,在 inode 利用率方面比 overlay 更有效。
##### 2.7.2.2 联合挂载
OverlayFS通过三个目录:**lower****目录**、**upper****目录**、以及**work****目录**实现,其中 lower 目录可以是多个,work 目录为工作基础目录,挂载后内容会被清空,且在使用过程中其内容用户不可见,最后联合挂载完成给用户呈现的统一视图称为为 merged 目录。
示例:
# 创建挂载目录/tmp/test/、及三个目录A、B、C,以及worker目录
[root@1 ~]# mkdir -p /tmp/test/ A/aa B C worker
[root@1 ~]# ls
A B C worker
[root@1 ~]# echo "from A" > A/a.txt
[root@1 ~]# echo "from B" > B/b.txt
[root@1 ~]# echo "from C" > C/c.txt
[root@1 ~]# tree .
.
|-- A
| |-- aa
| `-- a.txt
|-- B
| `-- b.txt
|-- C
| `-- c.txt
`-- worker
5 directories, 3 files
# 使用 mount 联合挂载到 /tmp/test 下
[root@1 ~]# mount -t overlay overlay -o lowerdir=A:B,upperdir=C,workdir=worker /tmp/test/
[root@1 ~]# df -Th
overlay overlay 50G 14G 34G 29% /tmp/test
然后我们再去查看 /tmp/test 目录,你会发现目录A、B、C被合并到了一起,并且相同文件名的文件会进行“覆盖”,这里覆盖并不是真正的覆盖,而是当合并时候目录中两个文件名称都相同时,merged层目录会显示离它最近层的文件。
[root@1 ~]# cd /tmp/test/
[root@1 test]# tree .
.
|-- aa
|-- a.txt
|-- b.txt
`-- c.txt
1 directory, 3 files
##### 2.7.2.3 *Docker中的overlay***驱动 **
介绍了 overlay 驱动原理以后再来看Docker 中的 overlay 存储驱动,以下是来自 docker 官网关于overlay 的工作原理图
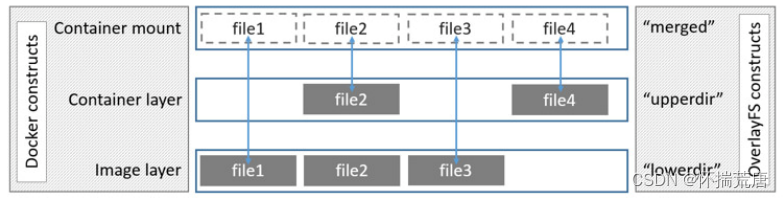
在上述图中可以看到三个层结构,即:lowerdir、uperdir、merged
l**owerdir 是只读的image layer**,其实就是rootfs,对比我们上述演示的目录A和B,我们知道image
layer可以分很多层,所以对应的lowerdir是可以有多个目录。
*upperdir 则是在lowerdir*之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容
器数据更改都发生在这里层,对比示例中的C。
**merged **目录是容器的挂载点,也就是给用户暴露的统一视角,对比示例中的 /tmp/test。而这些目录
层都保存在了 /var/lib/docker/overlay2/ 或者 /var/lib/docker/overlay/(如果使用overlay)
*①***演示 **
启动一个容器
docker run -it --name ubuntu ubuntu:latest /bin/bash
查看其 overlay 挂载点,可以发现其挂载的merged目录、lowerdir、upperdir以及workdir
mount |grep overlay

②如何工作
当容器中发生数据修改时候 overlayfs 存储驱动又是如何进行工作的?以下将阐述其读写过程:读:
如果文件在容器层(upperdir),直接读取文件;
如果文件不在容器层(upperdir),则从镜像层(lowerdir)读取;
修改:
- 首次写入:如果在upperdir中不存在,overlay和overlay2执行copy_up操作,把文件从lowerdir拷贝到upperdir,由于overlayfs是文件级别的(即使文件只有很少的一点修改,也会产生的copy_up的行为),后续对同一文件的在此写入操作将对已经复制到容器的文件的副本进行操作。这也就是常常说的写时复制(copy-on-write)
- 删除文件和目录:当文件在容器被删除时,在容器层(upperdir)创建whiteout文件,镜像层 (lowerdir)的文件是不会被删除的,因为他们是只读的,但without文件会阻止他们显示,当目录在容器内被删除时,在容器层(upperdir)一个不透明的目录,这个和上面whiteout原理一样,阻止用户继续访问,即便镜像层仍然存在。
**注意事项 **
copy_up 操作只发生在文件首次写入,以后都是只修改副本
overlayfs 只适用两层目录,相比于比 AUFS,查找搜索都更快
容器层的文件删除只是一个“障眼法”,是靠 whiteout 文件将其遮挡,image 层并没有删除,这也就是为什么使用 docker commit 提交保存的镜像会越来越大,无论在容器层怎么删除数据,image层都不会改变。
##### 2.7.2.4 overlay2镜像存储结构
从仓库 pull 一个 Ubuntu 镜像,结果显示总共拉取了4 层镜像如下:
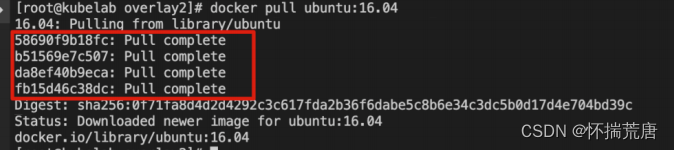
此时 4 层被存储在了/var/lib/docker/overlay2/目录下:

这里面多了一个 l 目录包含了所有层的软连接,短链接使用短名称,避免mount时候参数达到页面大小限制(演示中mount命令查看时候的短目录):

处于底层的镜像目录包含了一个diff和一个link文件,diff目录存放了当前层的镜像内容,而link文件则是与之对应的短名称:


在这之上的镜像还多了work目录和lower文件,lower 文件用于记录父层的短名称,work 目录用于联合挂载指定的工作目录。而这些目录和镜像的关系是怎么组织在的一起呢?答案是通过元数据关联。元数据分为image元数据和layer元数据。
*①image*元数据 **
镜像元数据存储在了 /var/lib/docker/image/<storage_driver>/imagedb/content/sha256/ 目录下,名称是以镜像ID命名的文件,镜像ID可通过 docker images 查看,这些文件以 json 的形式保存了该镜像的 rootfs 信息、镜像创建时间、构建历史信息、所用容器、包括启动的Entrypoint和CMD等 等。例如ubuntu镜像的id为 b6f507652425 :

查看镜像细节数据:
docker image inspect d1b55fd07600
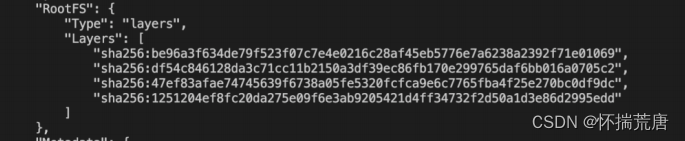
上面的 Layers 对应的的是一个镜像层,其排列也是有顺序的,从上到下依次表示镜像层的最低层到最顶层。
②layer元数据
在 docker 1.10 版本后,镜像元数据管理巨大的改变之一就是简化了镜像层的元数据,镜像层只包含一个具体的镜像层文件包。用户在 docker 宿主机上下载了某个镜像层之后,docker 会在宿主机上基于镜像层文件包和 image 元数据构建本地的 layer 元数据,包括 diff、parent、size 等。而当 docker 将在宿主机上产生的新的镜像层上传到 registry 时,与新镜像层相关的宿主机上的元数据也不会与镜像层一块打包上传。 Docker 中定义了 Layer 和 RWLayer 两种接口,分别用来定义只读层和可读写层的一些操作,又定义了roLayer 和 mountedLayer,分别实现了上述两种接口。其中,roLayer 用于描述不可改变的镜像层,mountedLayer 用于描述可读写的容器层。
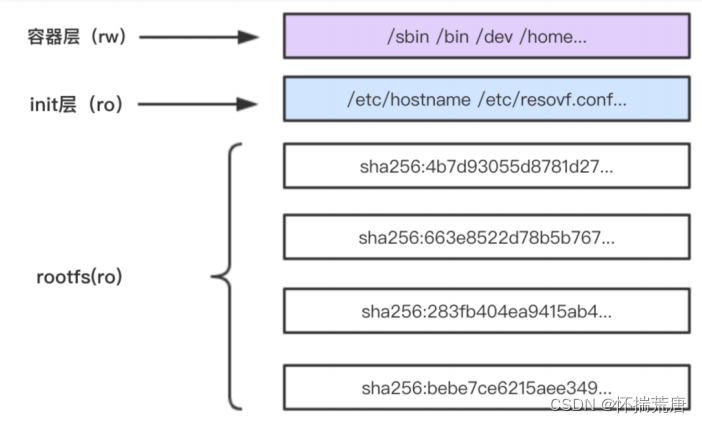
一个容器完整的层应由三个部分组成,如下图
镜像层:也称为rootfs,提供容器启动的文件系统
init层:用于修改容器中一些文件如 /etc/hostname 、 /etc/resolv.conf 等
容器层:使用联合挂载统一给用户提供的可读写目录。
##### 2.7.2.5 Docker如何使用UnionFS
如果我们浏览Docker hub,能发现大多数镜像都不是从头开始制作,而是从一些base镜像基础上创建,比如debian基础镜像。而新镜像就是从基础镜像上一层层叠加新的逻辑构成的。这种分层设计,一个优点就是资源共享。想象这样一个场景,一台宿主机上运行了100个基于debian base镜像的容器,难道每个容器里都有一份重复的debian拷贝呢?这显然不合理;借助Linux的unionFS,宿主机只需要在磁盘上保存一份base镜像,内存中也只需要加载一份,就能被所有基于这个镜像的容器共享。 当某个容器修改了基础镜像的内容,比如 /bin文件夹下的文件,这时其他容器的/bin文件夹是否会发生变化呢?根据容器镜像的写时拷贝(Copy-on-Write)技术,某个容器对基础镜像的修改会被限制在单个容器内。 容器镜像由多个镜像层组成,所有镜像层会联合在一起组成一个统一的文件系统。如果不同层中有一个相同路径的文件,比如 /text,上层的 /text 会覆盖下层的 /text,也就是说用户只能访问到上层中的文件/text。 我们将中间只读的 rootfs 的集合称为 Docker 镜像,我们在后面的部分会讲到,Docker 镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。UnionFS 使得镜像的复用、定制变得更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。

当用docker run启动这个容器时,实际上在镜像的顶部添加了一个新的可写层。这个可写层也叫容器层。
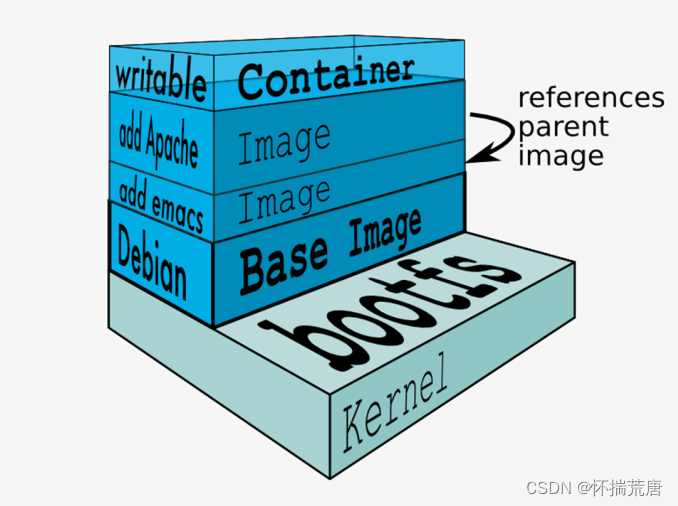
容器启动后,其内的应用所有对容器的改动,文件的增删改操作都只会发生在容器层中,对容器层下面的所有只读镜像层没有影响。
### 2.8 容器核心技术-Namespace
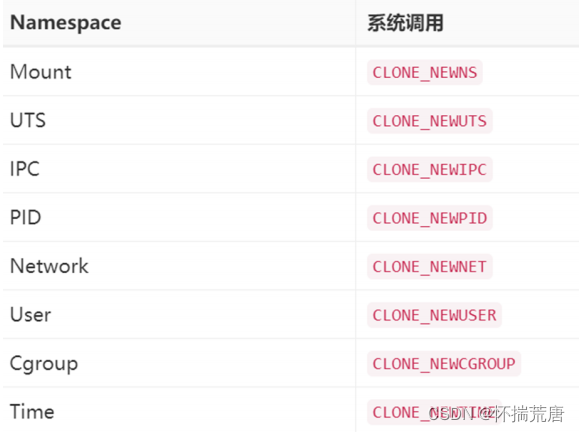
**Namespace **可以为容器提供系统资源隔离能力
举个例子:假如一个容器中的进程需要使用 root 权限,出于安全考虑,我们不可能把宿主机的 root 权限给他。但是通过 Namespace 机制,我们可以隔离宿主机与容器的真实用户资源,谎称一个普通用户就是 root,骗过这个程序。从这个角度看,Namespace *就是内核对进程说谎的机制,目前(Linux最新的稳定版本为5.6),内核可以说的*谎话有 8 种:
**①Mount Namespace **
Mount Namespace 用来隔离文件系统的挂载点,不同的 Mount namespace 拥有各自独立的挂载点信息。在 Docker 这样的容器引擎中,Mount namespace 的作用就是保证容器中看到的文件系统的视图。
**②UTS Namespace **
UTS Namespace 用来隔离系统的主机名、hostname和**NIS **域名。
**③IPC Namespace **
IPC 就是在不同进程间传递和交换信息。IPC Namespace 使得容器内的所有进程,进行的数据传输、共享数据、通知、资源共享等范围控制在所属容器内部,对宿主机和其他容器没有干扰。
**④PID Namespace **
PID namespaces用来隔离进程的 ID 空间,使得不同容器里的进程 ID 可以重复,相互不影响。
**⑤Network Namespace **
Network namespace 用来隔离网络,每个 namespace 可以有自己独立的网络栈,路由表,防火墙规则等。
**⑥User namespace **
user namespace 是例子中讲到的,控制用户 UID 和 GID 在容器内部和宿主机上的一个映射,主要用来管理权限。
**⑦Time namespace **
这个 Namespace 允许操作系统为进程设定不同的系统时间。
**⑧Cgroup Namespace **
这个 Namespace 用来限制 CGroup 根目录下不同层级目录的权限,使得 CGROUP 根目录下的子目录的进程无法影响到父目录。
感受Namespace
进入/proc/目录
cd /proc/
查看当前目录下有哪些文件或目录
ls
随便进入一个以数字(进程号)命名的目录,比如1
cd 1
查看ns(Namespace)目录下的内容
ls -al ns
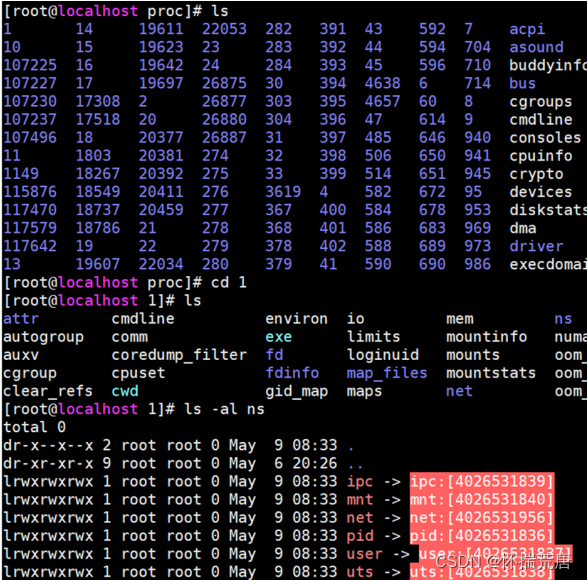
当前目录下红色的链接,就是这个进程对应的 Namespace。
有兴趣的也可以看看其他不同进程的 Namespace,比对下是否有差异。如果你找到某个进程的Namespace 与其他的不一致,就说明这个进程指定了 Namespace 隔离。
### 2.9 容器核心技术-CGroup
我们来试想这样一个场景:
一台宿主机的容器中运行了一个监控服务,但监控服务占用了宿主机全部的 CPU 和内存等资源,导致宿主机上的其他服务和容器都被卡死,无法正常运行。监控类服务不应占用大量资源,无论是什么原因引起的问题,都不应该影响宿主机的正常使用,否则容器的隔离就没有意义。Namespace 只能做到系统资源维度的隔离,无法做到硬件资源的控制。
我们需要使用一种机制 **Cgroup**,**指定容器应用最大占用多少资源**。 Linux cgroups 的全称是 Linux Control Groups,它是 Linux 内核的特性,主要作用是限制、记录和隔离进程组(process groups)使用的物理资源(CPU、Memory、IO 等)。
CGroup 是用来对进程进行资源管理的,因此 CGroup 需要考虑如何抽象这两种概念:进程和资源,同时如何组织自己的结构。CGroup 机制中有以下几个基本概念:
•task:任务,对应于系统中运行的一个实体,下文统称进程;
•subsystem:子系统,具体的资源控制器(resource class 或者 resource controller),控制某个特
定的资源使用;•cgroup:控制组,一组任务和子系统的关联关系,表示对这些任务进行怎样的资源管理策略;
•hierarchy:层级树,由一系列 CGroup 组成的树形结构。每个节点都是一个 CGroup ,CGroup 可以有多个子节点,子节点默认会继承父节点的属性。系统中可以有多个 hierarchy。
Cgroup 机制非常复杂,上面的名词了解就好,学习 Docker 暂时还不需要深入研究它。在 Linux 环境中,我们可以执行 ls -al /sys/fs/cgroup/ 查看当前系统的 Cgroup:
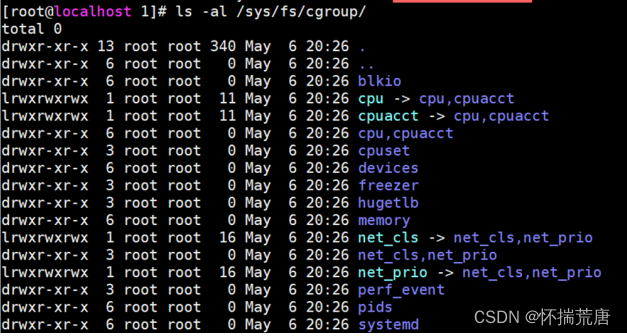
我们看到目录中有若干个子目录,除了 systemd 目录,其他的一个子目录对应一个子系统,子系统功能如下所示。

### 2.10 docker 镜像制作
镜像是容器的基础,每次执行 docker run 的时候都会指定哪个镜像作为容器运行的基础。在之前的例子中,我们所使用的都是来自于 Docker Hub 的镜像。直接使用这些镜像是可以满足一定的需求,而当这些镜像无法直接满足需求时,我们就需要定制这些镜像。
#### 2.10.1 镜像Commit
# 命令框架
docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]]
# 提交容器副本使之成为一个新的镜像
docker commit -m="提交的描述信息" -a="作者" 容器ID 要创建的目标镜像名:[标签名]
##### 2.10.1.1 镜像制作实例
镜像是多层存储,每一层是在前一层的基础上进行的修改;而容器同样也是多层存储,是在以镜像为基础层,在其基础上加一层作为容器运行时的存储层。
现在让我们以定制一个 Web 服务器为例子,来展示镜像是如何构建的
docker run --name webserver -d -p 80:80 nginx
这条命令会用 nginx 镜像启动一个容器,命名为 webserver,并且映射了 80 端口,这样我们可以用浏览器去访问这个 nginx 服务器。
直接用浏览器访问的话,我们会看到默认的 Nginx 欢迎页面。

假设我们非常不喜欢这个欢迎页面,我们希望改成欢迎 Docker 的文字,我们可以使用docker exec 命令进入容器,修改其内容。
# 进入该容器命令行
docker exec -it webserver bash
# 修改前端界面
echo '<font size=6 color=yellowgreen>Hello,Docker!Welcome Docker nginx test!</font>' > /usr/share/nginx/html/index.html
浏览器输入宿主机IP查看:

我们修改了容器的文件,也就是改动了容器的存储层。我们可以通过 docker diff 命令
宿主机终端输入:
docker diff webserver
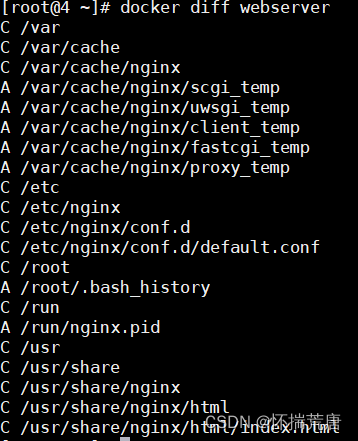
现在我们定制好了变化,我们希望能将其保存下来形成镜像。
当我们运行一个容器的时候(如果不使用卷的话),我们做的任何文件修改都会被记录于容器存储层里。而 Docker 提供了一个 docker commit 命令,可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。以后我们运行这个新镜像的时候,就会拥有原有容器最后的文件变化。
我们可以用下面的命令将容器保存为镜像:
# 宿主机命令行输入:
docker commit --author "nebula<[email protected]>" --message "修改nginx前端页面" webserver nginx:v1
其中 --author 是指定修改的作者,而 --message 则是记录本次修改的内容。这点和 git 版本控制相似,不过这里这些信息可以省略留空。
我们可以在 docker image ls 中看到这个新定制的镜像:

我们还可以用 docker history 具体查看镜像内的历史记录,如果比较 nginx:latest 的历史记录,我们会发现新增了我们刚刚提交的这一层。
docker history nginx:v1
新的镜像定制好后,我们可以来运行这个镜像。
docker run --name web2 -d -p 81:80 nginx:v1
这里我们命名为新的服务为 web2,并且映射到 81 端口。访问 http://localhost:81 看到结果,其内容应该和之前修改后的 webserver 一样。 至此,我们第一次完成了定制镜像,使用的是 docker commit 命令,手动操作给旧的镜像添加了新的一层,形成新的镜像,对镜像多层存储应该有了更直观的感觉。

**注:慎用 docker commit **
使用 docker commit 命令虽然可以比较直观的帮助理解镜像分层存储的概念,但是实际环境中并不会这样使用。 首先,如果仔细观察之前的 docker diff webserver 的结果,你会发现除了真正想要修改的/usr/share/nginx/html/index.html 文件外,由于命令的执行,还有很多文件被改动或添加了。这还仅仅是最简单的操作,如果是安装软件包、编译构建,那会有大量的无关内容被添加进来,将会导致镜像极为臃肿。
此外,使用 docker commit 意味着所有对镜像的操作都是黑箱操作,生成的镜像也被称为 **黑箱镜像**, 换句话说,就是除了制作镜像的人知道执行过什么命令、怎么生成的镜像,别人根本无从得知。而且, 即使是这个制作镜像的人,过一段时间后也无法记清具体的操作。这种黑箱镜像的维护工作是非常痛苦的。 而且,回顾之前提及的镜像所使用的分层存储的概念,除当前层外,之前的每一层都是不会发生改变的,换句话说,任何修改的结果仅仅是在当前层进行标记、添加、修改,而不会改动上一层。如果使用 docker commit 制作镜像,以及后期修改的话,每一次修改都会让镜像更加臃肿一次,所删除的上一层的东西并不会丢失,会一直如影随形的跟着这个镜像,即使根本无法访问到。这会让镜像更加臃肿
##### 2.10.1.2 docker 容器数据卷
Docker容器产生的数据,如果不通过docker commit生成新的镜像,使得数据做为镜像的一部分保存下
来,那么当容器删除后,数据自然也就没有了。为了能保存数据在docker中我们使用容器数据卷。
卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数卷,其特点为:
•数据卷可在容器之间共享或重用数据;
•卷中的更改可以直接生效;
•数据卷中的更改不会包含在镜像的更新中;
•数据卷的生命周期一直持续到没有容器使用它为止。
数据卷--直接用命令添加
将容器与宿主机之间文件绑定
docker run -it -v /宿主机目录:/容器内目录 centos /bin/bash
查看数据卷是否挂载成功:
docker inspect 容器ID

*docker***镜像的其他命令 **
**docker save imagesId -o fileName.tar.gz **
docker save命令可以将从本地镜像导出为一个压缩文件,然后复制到其他服务器执行 docker load -i fileName.tar.gz 导入使用。
### 2.11 Dockerfile
Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本
**构建步骤: **
1.编写DockerFile文件
2.docker build 创建镜像
3.docker run 运行镜像
#### 2.11.1 dockerfile 的编写规则
每条保留字指令都必须为大写字母且后面要跟随至少一个参数
指令按照顺序, 从上到下, 一条指令就是一层
#表示注释
每条指令都会创建一个新的镜像层, 并对镜像进行提交
#### 2.11.2 dockerfile 保留字指令

#### 2.11.3 执行dockerfile 流程
docker从基础镜像运行一个容器
执行一条指令并对容器修改
执行类似docker commit的操作提交一个新的镜像层
docker在基于刚提交的镜像运行一个新容器
执行dockerfile中的下一条指令直到所指令都执行完成
#### 2.11.4 常见问题
*Dockerfile中的“ COPY”和“ADD”***命令有什么区别? **
COPY :
COPY指令将从以下位置复制新文件并将其添加到容器的文件系统中:
ADD :
ADD指令将从中复制新文件并将其添加到位于path的容器的文件系统中。
•add 和 copy 都是复制文件 / 文件夹
•add 可以从网络 / 本地复制; copy 仅从本地复制, 语义更明确, 推荐使用 copy
#### 2.11.2 dockerfile 制作镜像实例
##### 2.11.2.1 示例一:封装Centos
自定义mycentos目的使镜像具备:**登录后的默认路径、****vim****编辑器、查看网络配置****ifconfig****支持。 **目标**: 练习使用WORKDIR, FROM, EVN, RUN, CMD**命令
# 准备目录
mkdir -p /docker/centos_iso/
# 编辑文件
cd /docker/centos_iso/
vim Dockerfile
## 内容
# 从centos7镜像开始制作一个新的镜像
FROM centos:centos7
# 指定镜像维护的作者和邮箱
MAINTAINER Nebula <xiaoming>@163.com
# 设置环境变量mypath
ENV MYPATH /usr/local
# 设置进入容器的默认目录是/usr/local
WORKDIR $MYPATH
#安装vim和net-tools工具
RUN yum -y install vim
RUN yum -y install net-tools
# 设置端口号是80
EXPOSE 80
# 运行命令,打印success
CMD echo $MYPATH
CMD echo "success"
# 运行命令, 进入/bin/bash
CMD /bin/bash
# 构建dockerfile,生成镜像
docker build -f Dockerfile2 -t mycentos:1.3 .
# 运行构建好的镜像
docker run -it mycentos:1.3 /bin/bash
进入容器后分别验证刚才我们定制的几个软件有没有,同时看下路径是否是设置的
##### 2.11.2.2 自定义Tomcat
Step1:首先创建文件夹存放jdk与tomcat的安装包
mkdir -p /docker/tomcat
Step2:将jdk和tomcat安装的压缩包上传至/root/下,并从其移动至/docker/tomcat/
jdk和tomcat的安装包版本分别为:
jdk-8u161-linux-x64.tar.gz 和 apache-tomcat-9.0.21.tar.gz
mv /root/jdk-8u161-linux-x64.tar.gz /docker/tomcat/
mv /root/jdk-8u161-linux-x64.tar.gz /docker/tomcat/
Step3:编辑文件
cd /docker/tomcat/
vim Dockerfile
# 内容如下:
FROM centos:centos7
MAINTAINER nebula< nebula @126.com>
#把宿主机当前上下文的a.txt拷贝到容器/usr/local/路径下
COPY a.txt /usr/local/cincontainer.txt
#把java与tomcat添加到容器中
ADD jdk-8u161-linux-x64.tar.gz /usr/local/
ADD apache-tomcat-9.0.21.tar.gz /usr/local/
#安装vim编辑器
RUN yum -y install vim
#设置工作访问时候的WORKDIR路径,登录落脚点
ENV MYPATH /usr/local
WORKDIR $MYPATH
#配置java与tomcat环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_161
ENV CLASSPATH $JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV CATALINA_HOME /usr/local/apache-tomcat-9.0.21
ENV CATALINA_BASE /usr/local/apache-tomcat-9.0.21
ENV PATH $PATH:$JAVA_HOME/bin:$CATALINA_HOME/lib:$CATALINA_HOME/bin
#容器运行时监听的端口
EXPOSE 8080
#启动时运行tomcat
# ENTRYPOINT ["/usr/local/apache-tomcat-9.0.21/bin/startup.sh" ]
# CMD ["/usr/local/apache-tomcat-9.0.21/bin/catalina.sh","run"]
CMD /usr/local/apache-tomcat-9.0.21/bin/startup.sh && tail -F /usr/local/apachetomcat-9.0.21/logs/catalina.out
# 创建文件--该文件的作用是用来使用COPY命令,便于识别copy与add命令的区别
touch a.txt
echo "This is a dockerfile test from 192.168.182.155!" > a.txt
Step4:构建镜像
docker build -f mytomcat -t mytomcat:v1.1 .
Step5:运行容器
docker run -d -p 9080:8080 --name mytomcat -v /docker/tomcat/test:/usr/local/apache-tomcat-9.0.21/webapps/test -v /docker/tomcat/logs/:/usr/local/apache-tomcat-9.0.21/logs --privileged=true mytomcat:v1.1
*注:test目录中加入war包可以挂载到容器内,容器中logs*文件中产生的日志可以同步到主机上。 **
*验证tomcat*启动结果 **
在本地输入192.168.182.155:9080. 看到tomcat启动页
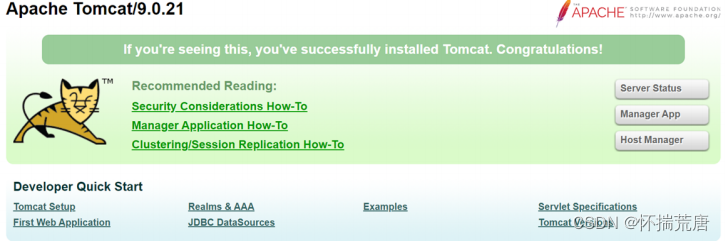
使用如下命令登录容器,然后查看我们dockerfile中copy的文件内容是否在容器中复制成功
docker exec -it 026651a4c21d /bin/bash
# 注:ID写的是"docker ps"查到的id
##### 2.11.2.3 基于 Centos7 构建 nginx 镜像
在拉取docker默认的nginx镜像后发现是debian系统,每次更新软件都非常痛苦,于是想制作一个自定义的nginx系统作为替代默认的nginx镜像 。 国内centos使用的人更多,yum源更加稳定,浪费一些空间和性能是可以接受的。
Step1:创建 Docker 文件
mkdir /docker/nginx
vim Dockerfile
# 内容如下:
#设置基本的CentOS7镜像,后续指令都以这个镜像为基础
FROM centos:centos7
#作者信息
MAINTAINER nebula
#安装依赖工具&删除默认YUM源,使用YUM源为国内163 YUM源;
RUN rpm --rebuilddb;yum install make wget tar gzip passwd openssh-server gcc pcre-devel openssl-devel net-tools vim -y
RUN rm -rf /etc/yum.repos.d/*;wget -P /etc/yum.repos.d/http://mirrors.aliyun.com/repo/Centos-7.repo
# 可换为: http://mirrors.163.com/.help/CentOS7-Base-163.repo
#配置SSHD&修改root密码为Nebula@123
RUN ssh-keygen -q -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key -N ''
RUN ssh-keygen -q -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ''
RUN ssh-keygen -q -t ed25519 -f /etc/ssh/ssh_host_ED25519_key -N ''
RUN echo 'Nebula@123' | passwd --stdin root
#Nginx官网下载Nginx最新版本软件;
RUN wget -P /tmp/ http://nginx.org/download/nginx-1.14.2.tar.gz
#解压Nginx软件包,隐藏WEB服务器版本号;
RUN cd /tmp/;tar xzf nginx-1.14.2.tar.gz;cd nginx-1.14.2;sed -i -e 's/1.14.2//g' -e 's/nginx\//WS/g' -e 's/"NGINX"/"WS"/g' src/core/nginx.h
#基于源码安装,创建配置文件;
RUN cd /tmp/nginx-1.14.2;./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module;make;make install
#启动Nginx服务进程,对外暴露22和80端口;
EXPOSE 22
EXPOSE 80
CMD /usr/local/nginx/sbin/nginx;/usr/sbin/sshd -D
Step2:生成镜像
docker build -t centos7:nginx .
Step3:创建容器
# 基于centos7:nginx镜像创建容器
docker run -itd --privileged -p 80:80 -p 2201:22 --name=mynginx centos7:nginx
# 进入容器
docker exec -it mynginx /bin/bash
也可以通过ssh 192.168.182.155宿主机IP) -p 2201实现登录,输入你在dockerfile中设置的密码
#### 2.11.3 Dockerfile 常见面试题
① Dockerfile中 RUN,CMD,ENTRYPOINT命令区别
Dockerfile中RUN,CMD和ENTRYPOINT都能够用于执行命令,下面是三者的主要用途:
•RUN命令执行命令并创建新的镜像层,通常用于安装软件包
•CMD命令设置容器启动后默认执行的命令及其参数,但CMD设置的命令能够被docker run命令后面的命令行参数替换,如果 Dockerfile 中有多个 CMD 指令,只有最后一个 CMD 有效。
•ENTRYPOINT配置容器启动时的执行命令(不会被忽略,一定会被执行,即使运行 docker run时指定了其他命令)
② Shell格式和Exec格式运行命令
我们可用两种方式指定 RUN、CMD 和 ENTRYPOINT 要运行的命令:Shell 格式和 Exec 格式:
•Shell格式: 。例如:apt-get install python3
•Exec格式: ["executable", "param1", "param2", ...]。例如: ["apt-get", "install", "python3"]
**CMD ****和 ****ENTRYPOINT ****推荐使用 ****Exec 格式,因为指令可读性更强,更容易理解。RUN **则两种格式都可以。
Run命令
RUN 指令通常用于安装应用和软件包。RUN 在当前镜像的顶部执行命令,并通过创建新的镜像层。Dockerfile 中常常包含多个 RUN 指令。下面是一个例子:
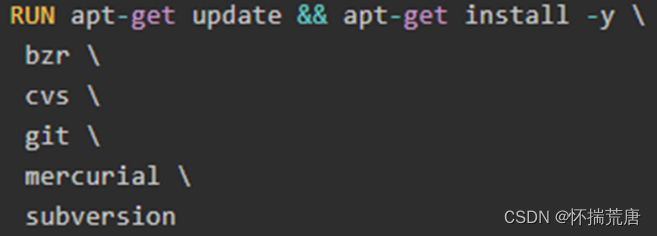
apt-get update 和 apt-get install 被放在一个 RUN 指令中执行,这样能够保证每次安装的是最新的包。如果 apt-get install 在单独的 RUN 中执行,则会使用 apt-get update 创建的镜像层,而这一层可能是很久以前缓存的。
CMD命令
CMD 指令允许用户指定容器的默认执行的命令。**此命令会在容器启动且 ****docker run **没有指定其他命令时运行。下面是一个例子:
CMD echo "Hello world"
运行容器 docker run -it [image] 将输出:
Hello world
但当后面加上一个命令,比如 docker run -it [image] /bin/bash,CMD 会被忽略掉,命令 bash 将被执行:
docker run -it [image] test
ENTRYPOINT命令
ENTRYPOINT 的 Exec 格式用于设置容器启动时要执行的命令及其参数,同时可通过CMD命令或者命令行参数提供额外的参数。ENTRYPOINT 中的参数始终会被使用,这是与CMD命令不同的一点。下面是一个例子:
ENTRYPOINT ["/bin/echo", "Hello"]
当容器通过 docker run -it [image] 启动时,输出为:
Hello
而如果通过 docker run -it [image] CloudMan 启动,则输出依旧为:
Hello
将Dockerfile修改为:
CMD echo "Hello world"
ENTRYPOINT ["/bin/echo", "Hello"]ENTRYPOINT ["/bin/echo", "Hello"]
CMD ["world"]
当容器通过 docker run -it [image] 启动时,输出为:
Hello world
而如果通过 docker run -it [image] CloudMan 启动,则输出为:
Hello CloudMan
**ENTRYPOINT 中的参数始终会被使用,而 CMD **的额外参数可以在容器启动时动态替换掉。
总结
•使用 RUN 指令安装应用和软件包,构建镜像。
•如果 Docker 镜像的用途是运行应用程序或服务,比如运行一个 MySQL,应该优先使用 Exec 格式的ENTRYPOINT 指令。CMD 可为 ENTRYPOINT 提供额外的默认参数,同时可利用 docker run 命令行替换默认参数。
•如果想为容器设置默认的启动命令,可使用 CMD 指令。用户可在 docker run 命令行中替换此默认命令。
### 2.12 Docker 编排工具
#### 2.12.1 Docker compose 和 Dockerfile区别
Dockerfile容器间通信需要--link或者桥接方式进行,而DockerCompose全自动的呀。也就是说单容器的话肯定Dockerfile了,但是多容器之间需要交互、有依赖关系,那用DockerCompose来统一管理那些零散的Dockerfile来达到自动构建部署的一体化脚本。
** 可以粗糙理解成Dockerfile是针对单容器的脚本,docker-compose是针对多Dockerfile**的自动化脚本。
#### 2.12.2 Docker compose 作用
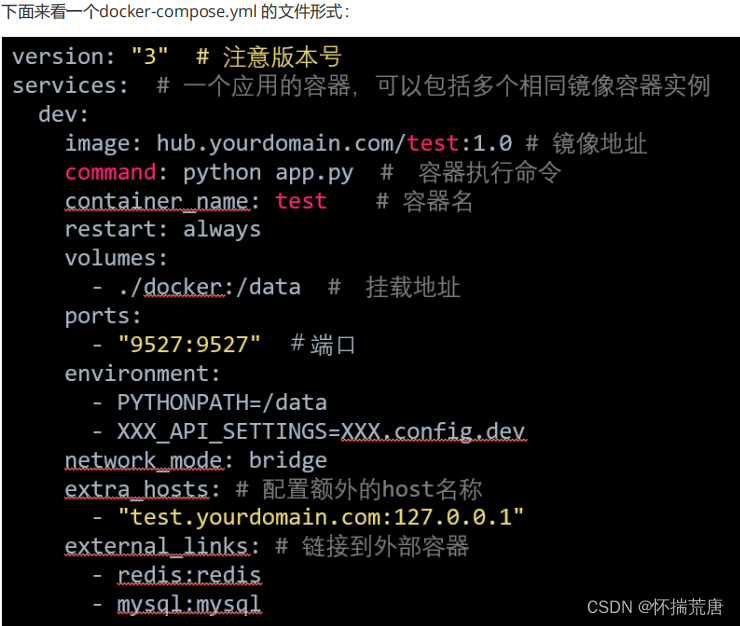
Docker Compose依赖于一个YAML配置文件,通常名为Compose.YAML。compose.yaml文件在如何定义多容器应用程序方面遵循compose规范提供的规则。这是正式Compose规范的Docker Compose实现。
#### 2.12.3 docker-compose.yml 样例
#### 2.12.4 使用Docker Compose运行容器
公共Docker注册表Docker Hub包含一个简单的Hello World镜像。现在我们已经安装了Docker Compose,让我们用这个非常简单的例子来测试它。
首先,为我们的YAML文件创建一个目录,并编辑一个yml:
mkdir /root/hello-world
cd /root/hello-world
vim docker-compose.yml
注意:Compose文件的默认路径是放置在工作目录中的compose.yaml(首选)或compose.yml。
Compose还支持docker-compose.yaml和docker-compose.yml,以实现早期版本的向后兼容性。如果这两个文件都存在,Compose更喜欢规范的compose.yaml。
将以下内容放入文件,保存文件,然后退出文本编辑器:
services:
# 这一行将用作容器名称的一部分。
my-test:
# 指定用于创建容器的镜像。该镜像将从官方Docker Hub存储库下载。
image: hello-world
仍在/root/hello-world目录中时,执行以下命令来创建容器:
docker compose up
您可以在一台计算机上运行多组Docker容器 - 只需为每个容器创建一个目录,为其目录中的每个容器创建一个docker-compose.yml文件。到目前为止,我们一直在运行docker-compose up并使用CTRL-C它来关闭它。这允许调试消息显示在终端窗口中。但这并不理想,在生产中运行时,您会希望docker-compose更像是服务。
一种简单的方法是在会话-d时添加选项up:
**docker compose up -d **
要显示您当前正在运行的Docker容器组,请使用以下命令:
**docker compose ps **
例如,以下显示hello-world-my-test-1容器已停止:

要停止应用程序组的所有正在运行的Docker容器,请在用于启动Docker组的与docker-compose.yml文件相同的目录中发出以下命令:
docker compose stop
**注意: **如果您需要更有力地关闭东西,也可以使用docker-compose kill。
在某些情况下,Docker容器会将其旧信息存储在内部卷中。如果要从头开始,可以使用该rm命令完全删除构成容器组的所有容器:
**docker compose rm **
### 2.13 Docker 网络
Docker的网络功能相对简单,没有过多复杂的配置,Docker默认使用birdge桥接方式与容器通信,启动Docker后,宿主机上会产生docker0这样一个虚拟网络接口, docker0不是一个普通的网络接口, 它是一个虚拟的以太网桥,可以为绑定到docker0上面的网络接口自动转发数据包,这样可以使容器与宿主机之间相互通信。每次Docker创建一个容器,会产生一对虚拟接口,在宿主机上执行ifconfig,会发现多了一个类似veth这样的网络接口,它会绑定到docker0上,由于所有容器都绑定到docker0上,容器之间也就可以通信。
在宿主机上执行ifconfig,会看到docker0这个网络接口, 启动一个container,再次执行ifconfig, 会有 一个类似veth的interface,每个container的缺省路由是宿主机上docker0的ip,在container中执行 netstat -r可以看到如下图所示内容
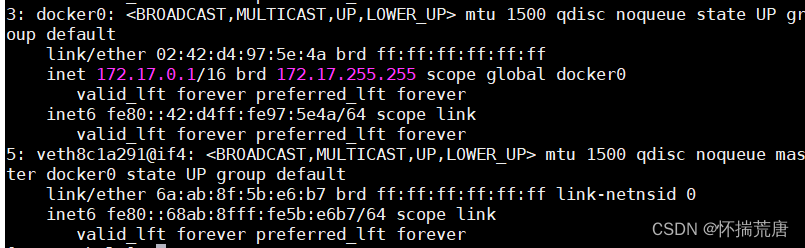

Centos8 查看路由
容器中的默认网关跟docker0的地址是一样的:
当容器退出之后,veth虚拟接口也会被销毁。
除bridge方式,Docker还支持host、container、none三种网络通信方式,使用其它通信方式,只要在Docker启动时,指定-net参数即可,比如:
docker run -i -t --net=host centos /bin/bash

** Docker网络组成简述:**
host****方式可以让容器无需创建自己的网络协议栈,而直接访问宿主机的网络接口,在容器中执行ip addr。会发现与宿主机的网络配置是一样的,host方式让容器直接使用宿主机的网络接口,传输数据的效率会更加高效,避免bridge方式带来的额外开销,但是这种方式也可以让容器访问宿主机的D-bus等网络服务,可能会带来意想不到的安全问题,应谨慎使用host方式;
container****方式可以让容器共享一个已经存在容器的网络配置;
none****方式不会对容器的网络做任务配置,需要用户自己去定制。
#### 2.13.1 docker 与 VMware 中的网络
- VMware中host网络的虚拟机采用独立的局域网,且无法与外界通信。
- VMware中bridge网络的虚拟机桥接到宿主机,配置或者获取外面局域网地址。
- VMware的NAT模式就对应于 Docker中的bridge
- docker中host网络的容器共用宿主机的接口和IP。
- docker中bridge网络的容器桥接到宿主机,有独立的局域网,通过桥接与外界通信。
#### 2.13.2 docker 网络 - bridge 模式
容器与主机、容器与容器之间是互相隔离的。同时,我们可以通过配置 docker 网络,为容器创建完全独立的网络命名空间,或者使容器共享主机或者其他容器的网络命名空间,以应对不同场景的需要。
1.bridge模式
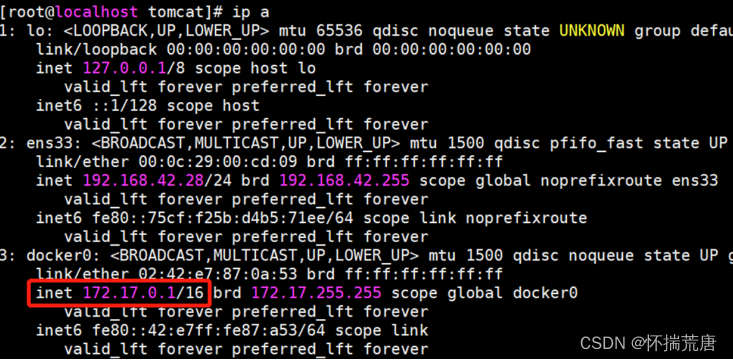
Docker 服务启动时,会自动在宿主机上创建一个 docker0 虚拟网桥 (Linux Bridge, 可以理解为一个软件虚拟出来的交换机)。它会在挂载到它的网口之间进行转发。同时 Docker 随机分配一个可用的私有 IP 地址给 docker0 接口。如果容器使用默认网络参数启动,那么它的网口也会自动分配一个与 docker0 同 网段的 IP 地址。获取 docker0 网络信息,它的地址是 172.17.0.1, 子网掩码为 255.255.0.0,如下图所示:
我们来做个测试,看看默认新建的容器是否能互相连通。
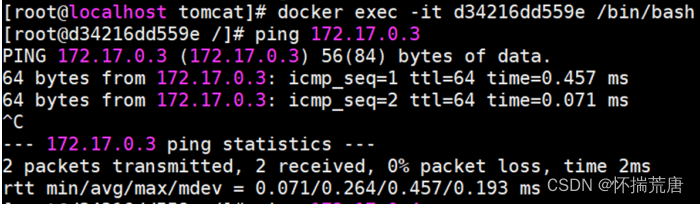
使用 centos(你本机存在的镜像,然后运行两个实例) 镜像分别运行 b0,b1 两个容器:
**docker run -d -t --name b0 centos **
**docker run -d -t --name b1 centos **
容器新建并运行成功后,查看两个容器的 IP 地址:
**# 172.17.0.2 **
docker inspect --format '{{ .NetworkSettings.IPAddress }}' b0
# 172.17.0.3
docker inspect --format '{{ .NetworkSettings.IPAddress }}' b1
# **Tips**:获取的 IP 是随机的,跟 Docker 版本与运行环境有关,以自己获取的 IP 为准,下同几个容器互相 ping 一下,证明它们的网络能连通:


1.1自定义网桥
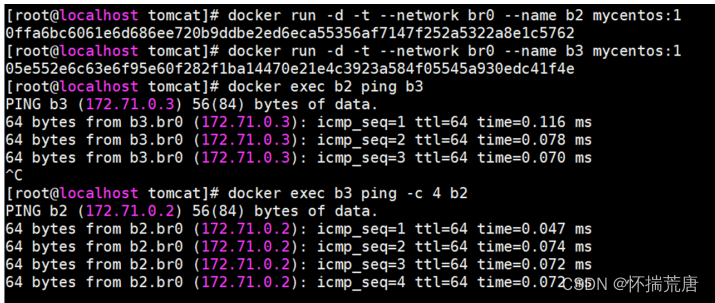
除了使用默认 docker0 做网桥,我们还可以使用 docker network 相关命令自定义网桥:这里将创建一个网桥 br0,设定网段是 172.71.0.0/24,网关为 172.71.0.1:-d 指定管理网络的驱动方式,默认为bridge # --subnet 指定子网网段 # --gateway 指定默认网关
**docker network create -d bridge --subnet '172.71.0.0/24' --gateway '172.71.0.1' br0 **
使用命令 docker network ls 查看当前的 docker 网络列表,发现新增的 br0 网桥。
接下来,我们尝试在使用这个网桥 br0 来新建运行两个容器,并测试它们的连通性。使用上次封装的centos镜像分别运行 b2,b3 两个容器:
**docker run -d -t --network br0 --name b2 mycentos:1 **
docker run -d -t --network br0 --name b3 mycentos:1
容器新建并运行成功后,分别执行下列命令,互相 ping 一下验证网络连通:
**docker exec b2 ping b3 **
**docker exec b3 ping b2 **
*ping 测试过程中,输入的并不是 IP***,而是容器名。 **
在自定义网桥中,容器名会在需要的时候自动解析到对应的** IP,也解决了容器重启可能导致 IP ****变动的问题。 **
其他 :
不再使用的容器记得删除掉,释放资源和空间
**docker rm -f b2 b3 **
删除自定义的网桥
**docker network rm br0 **

1.2端口映射访问容器
将宿主机的本地端口,与指定容器的服务端口进行映射绑定,之后访问宿主机端口时,会将请求自动转发到容器的端口上,实现外部对容器内网络服务的访问。创建名为 n0 的 nginx 容器,映射宿主机 8000 端口到它的 80 端口
**docker run -d -t -p 8000:80 --name n0 nginx **
# Tips:指定的宿主机端口必须是未被占用的端口,否则操作会失败,且生成一个无法正常启动的容器n0, 需要手动删除。
使用 docker port n0 查看 n0 的端口映射信息,显示如下:
80/tcp -> 0.0.0.0:8000
打开浏览器,地址栏输入http://localhost:8000 或 http://宿主机IP:8000,都能访问到n0的nginx 服务。
如果需要绑定多个容器端口,可以连续使用 -p 参数多次指定
docker run -d -t -p 8001:80 -p 8433:443 --name n1 nginx
如果不想主动指定宿主机端口,可以使用 -P 参数,宿主机随机使用一个可用端口与容器端口进行映射
docker run -d -t -P --name n2 nginx
如果只想使用宿主机上特定的网口与容器进行映射
docker run -d -t -p 192.168.1.13:8002:80 --name n3 nginx
# Tips:此处 192.168.1.13 指代 宿主机映射网口的 IP 地址,需要根据网口的实际 IP 更改
不再使用的容器记得删除掉,释放资源和空间
**docker rm -f n0 n1 n2 n3 **
**小结 **
使用端口映射访问容器是常用的方式之一,它配置简单,通用性强,可以跨宿主机访问,基本覆盖个人日常使用的场景,但它仍有一些缺陷。
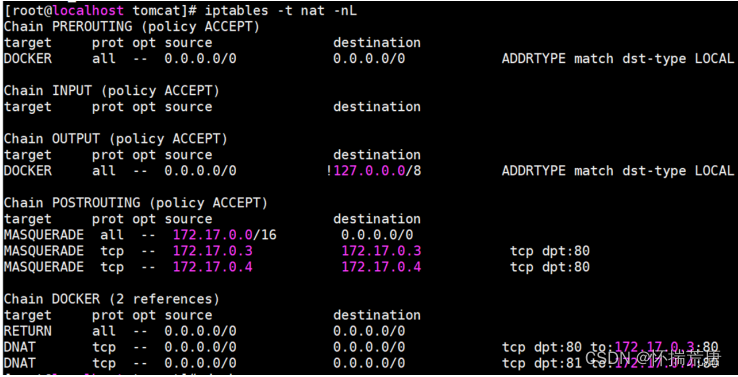
我们执行 docker ps 可能出现如下几个的 nginx 容器:
再执行 iptables -t nat -nL 查看下防火墙:
比对上面两个的输出,不难发现,这种端口转发方式的本质是通过配置 iptables 规则转发实现的,效率较低,如果容器的服务端口数量过多,需要配置较多的映射,占用大量宿主机端口,也不便于管理。

#### 2.13.3 docker 网络 - host 模式
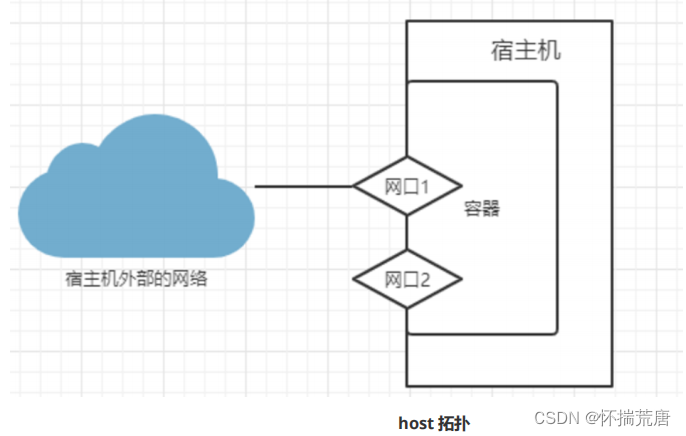
1.host模式
host 模式下启动的容器,网络不再与宿主机隔离,访问容器服务可以直接使用访问宿主机对应的网络端口,且不需要端口转发。网络拓扑图如下:
以 host 模式启动 nginx 的容器 h0:
docker run -d -t --network host --name h0 nginx
启动成功后,在浏览器输入任意的本机地址,都可以打开 nginx 的默认页面,访问宿主机 80 端口就是访问容器的 80 端口,它们是一致的。
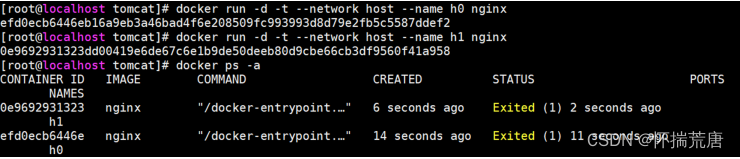
以 host 模式启动 nginx 的容器 h1:
docker run -d -t --network host --name h1 nginx
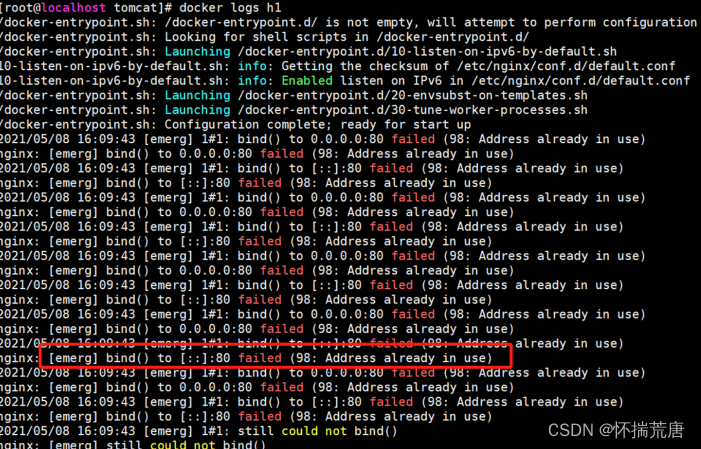
使用 docker ps -a 命令查看所有容器,发现 h1 容器没有运行:
使用 docker logs h1 查看容器 h1 的日志,发现,由于宿主机 80 端口已经被 h0 容器的服务占用,使得h1 无法获取到 此端口,导致无法正常启动。
我们在学习过程中,不再使用的容器记得删除掉,释放资源和空间
**docker rm -f h0 h1 **
**小结 **
host 模式下的容器与宿主机共享同一个网络环境,容器可以使用宿主机的网卡和外界的通信,不需要转发拆包,性能好。但 host 模式也有非常严重的缺点:容器没有隔离的网络,会与其他服务竞争宿主机的****网络,导致宿主机网络状态不可控,因此无法用在生产环境。
#### 2.13.4 docker 网络 - container 模式
1.container 模式
与 host 模式类似,container 模式可以使一个容器共享另一个已存在容器的网络,此时这两个容器共同使用同一网卡、主机名、IP 地址,容器间通讯可直接通过本地回环 lo 接口通讯。
新运行一个 centos 的容器 b1,设定它共享已存在的容器 b0 的网络:
**docker run -d -t --network container:b0 --name b1 centos **
Tips:端口转发设定以已存在的容器为准,出于安全和权限控制的角度,container 模式下运行的容器设定端口转发不生效。
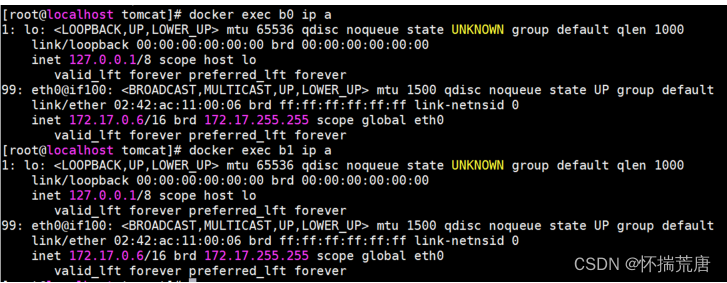
查看 b0,b1 的网络配置,验证两者的网络配置是否相同:
**docker exec b0 ip a **
docker exec b1 ip a
此时的网络拓扑图如下:
不再使用的容器记得删除掉,释放资源和空间
docker rm -f b0 b1
nginx 镜像自带的网络命令非常少,查看网络不方便,而 centos 的网络命令比较齐全,使用 container 模式,可以快速解决这个问题。我们新运行一个名为 n0 的 nginx 容器,再将它的网络共享给 centos 容器 n0-net:
**docker run -d -t --name n0 nginx **
docker run -d -t --network container:n0 --name n0-net centos
使用 n0-net 容器,执行 docker exec n0-net ip a 进行网络状态查看自身网络信息,也就是 nginx 的网络信息
执行如下命令,通过 localhost 访问 n0 的 web 服务,说明通过 container 模式下,共享的网络中的容器能够使用 lo 访问其他容器的服务。
docker exec n0-net telnet localhost 80
在交互中输入
GET /
如果上述命令返回Connection closed by foreign host. 则执行如下
不再使用的容器记得删除掉,释放资源和空间:
**docker rm -f n0 n0-net **


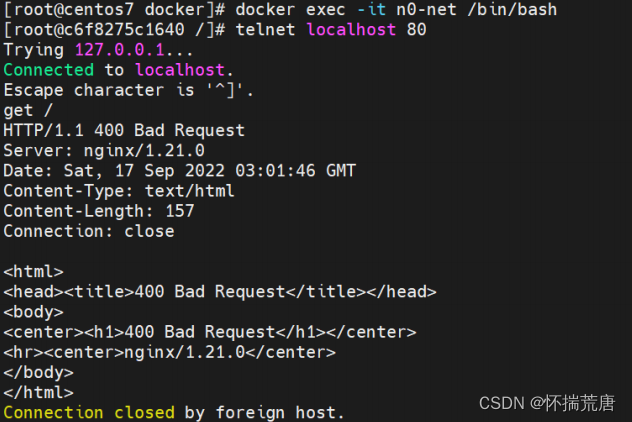
**小结 **
在 container 模式下的容器,会使用其他容器的网络命名空间,其网络隔离性会处于 bridge 桥接模式与host 模式之间:当容器共享其他容器的网络命名空间,则在容器之间不存在网络隔离;而它们又与宿主机以及其他不在此共享中的容器存在网络隔离。
#### 2.13.5 docker 网络 - none 模式
none 模式
容器有自己的网络命名空间,但不做任何配置,它与宿主机、与其他容器都不连通的。我们新建一个none 模式的 centos 镜像 b0:
**docker run -d -t --network none --name b0 centos **
使用 docker exec b0 ip a 查看它的网络状态, 验证它仅有 lo 接口,不能与容器外通信:
两个容器之间可以直连通信,但不通过主机网桥进行桥接。解决的办法是创建一对 peer 接口,分别放到两个容器中,配置成点到点链路类型即可。
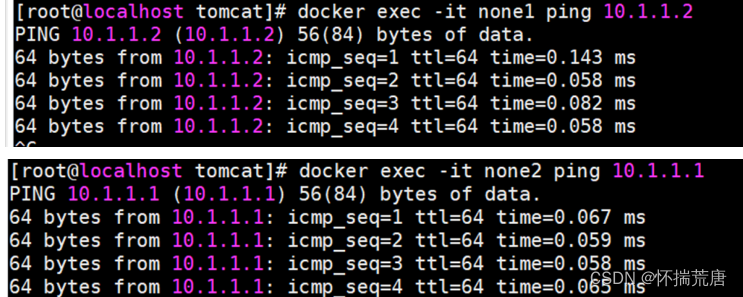
首先启动 2 个容器:
**docker run -it -d --net=none --name=none1 centos **
docker run -it -d --net=none --name=none2 centos
找到这两个容器的进程号:
16768
**docker inspect -f '{{.State.Pid}}' none1 **
16839
**docker inspect -f '{{.State.Pid}}' none2 **
然后创建网络命名空间的跟踪文件:
**mkdir -p /var/run/netns **
**ln -s /proc/16768/ns/net /var/run/netns/16768 **
ln -s /proc/16839/ns/net /var/run/netns/16839
创建一对 peer 接口,然后配置路由:
**ip link add A type veth peer name B **
**ip link set A netns 16768 **
**ip netns exec 16768 ip addr add 10.1.1.1/32 dev A **
**ip netns exec 16768 ip link set A up **
**ip netns exec 16768 ip route add 10.1.1.2/32 dev A **
**ip link set B netns 16839 **
**ip netns exec 16839 ip addr add 10.1.1.2/32 dev B **
**ip netns exec 16839 ip link set B up **
ip netns exec 16839 ip route add 10.1.1.1/32 dev B
现在这 2 个容器就可以相互 ping 通,并成功建立连接。点到点链路不需要子网和子网掩码:
测试完毕删除无用的容器:
**docker rm -f none1 none2 **
**小结 **
none 模式提供了一种空白的网络配置,方便用户排除其他干扰,用于自定义网络。

## 3. 使用Docker部署开源建站工具—Halo,并实现个人博客公网访问
① Docker部署Halo
- 本地环境操作系统:Centos7 安装 Docker--见目录2.5
- 启动 Docker
systemctl start docker
- 检查 Docker 版本
docker -v
- 检查 Docker compose 版本:确保2.0以上版本
docker compose version
- 下载 Halo 镜像:在 docker hub 下载 Halo-V2.10 版本镜像
docker pull halohub/halo:2.10
- 创建挂载目录
mkdir -p /data/halo/ && cd /data/halo/
- 创建 Halo 容器
Halo 2与1.x 版本不兼容;
此命令默认使用自带的 H2 Database 数据库,另外可以额外单独使用Mysql数据库进行连接。
docker run -it -d --name halo -p 8090:8090 -v /data/halo/./halo2:/root/.halo2 halohub/halo:2.10
- 查看 Halo 容器状态
docker ps
- 检查 Halo 容器日志
docker logs halo
- 查看本地 IP 地址
ifconfig
- 进入 Halo 初始化页面
访问地址:http://192.168.182.155:8090/console/setup
注:将IP换为自己的服务器IP地址
- 站点名称:myweb 邮箱:admin@qq.com** 用户名:admin 密码:**admin 点击初始化即可
- 登录 Halo:输入账号和密码,登录 Halo,进入到仪表盘界面
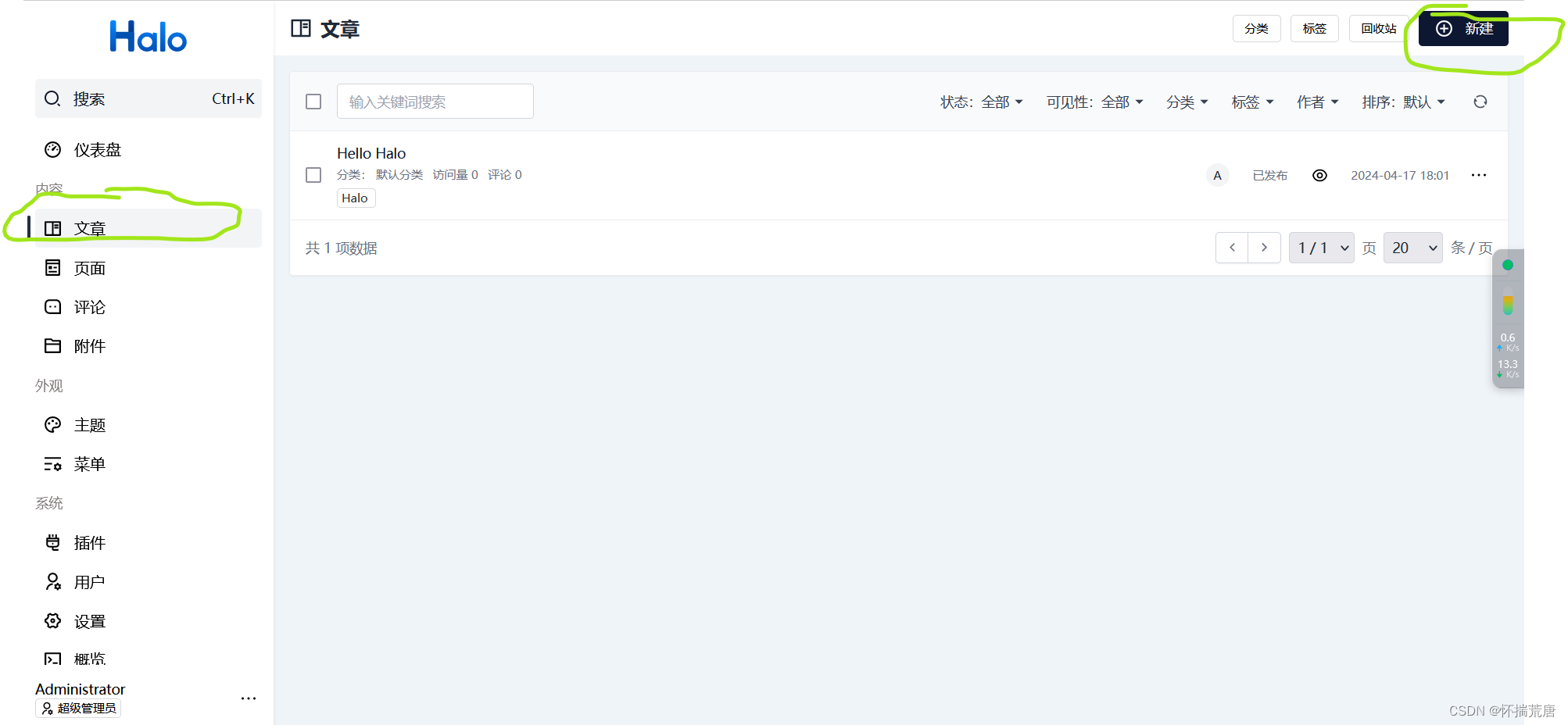
接下来举个例子我们创作一篇文章,在Halo后台管理页面,文章模块,点击“新建”
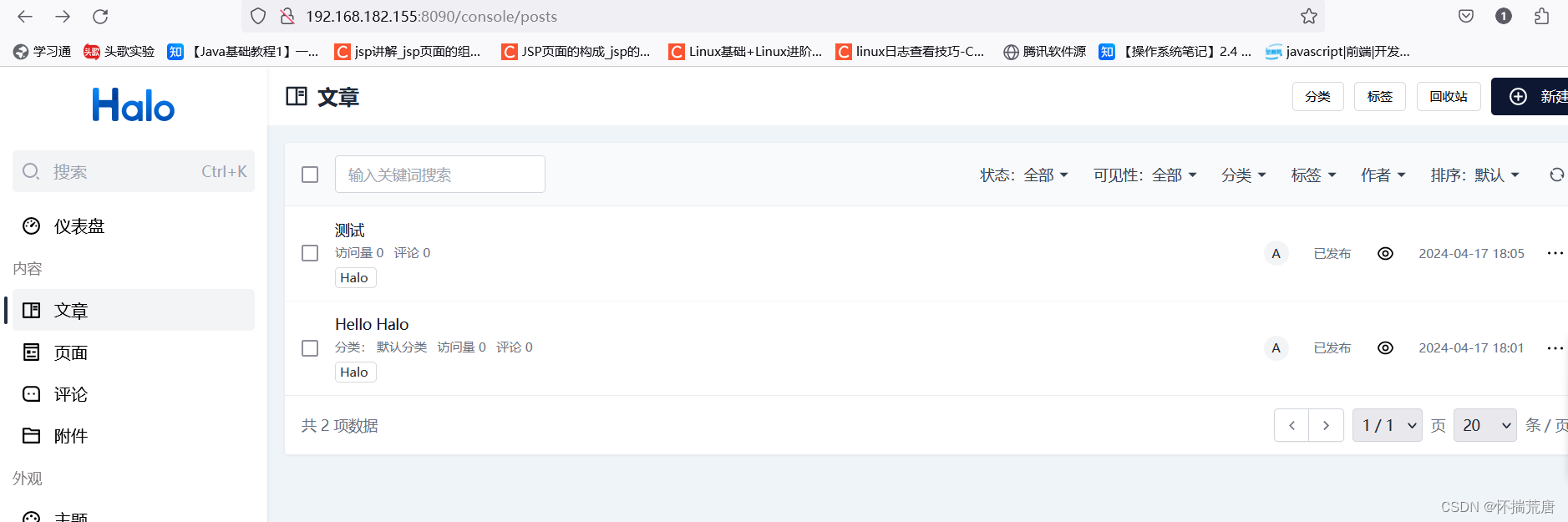
编辑完文章后,点击发布,将文章进行发布,在文章列表中即可看到发布过的文章
接下来本地浏览器访问http://192.168.182.155:8090/,本地服务器IP:8089,看到halo前台首页已经成功显示发布文章

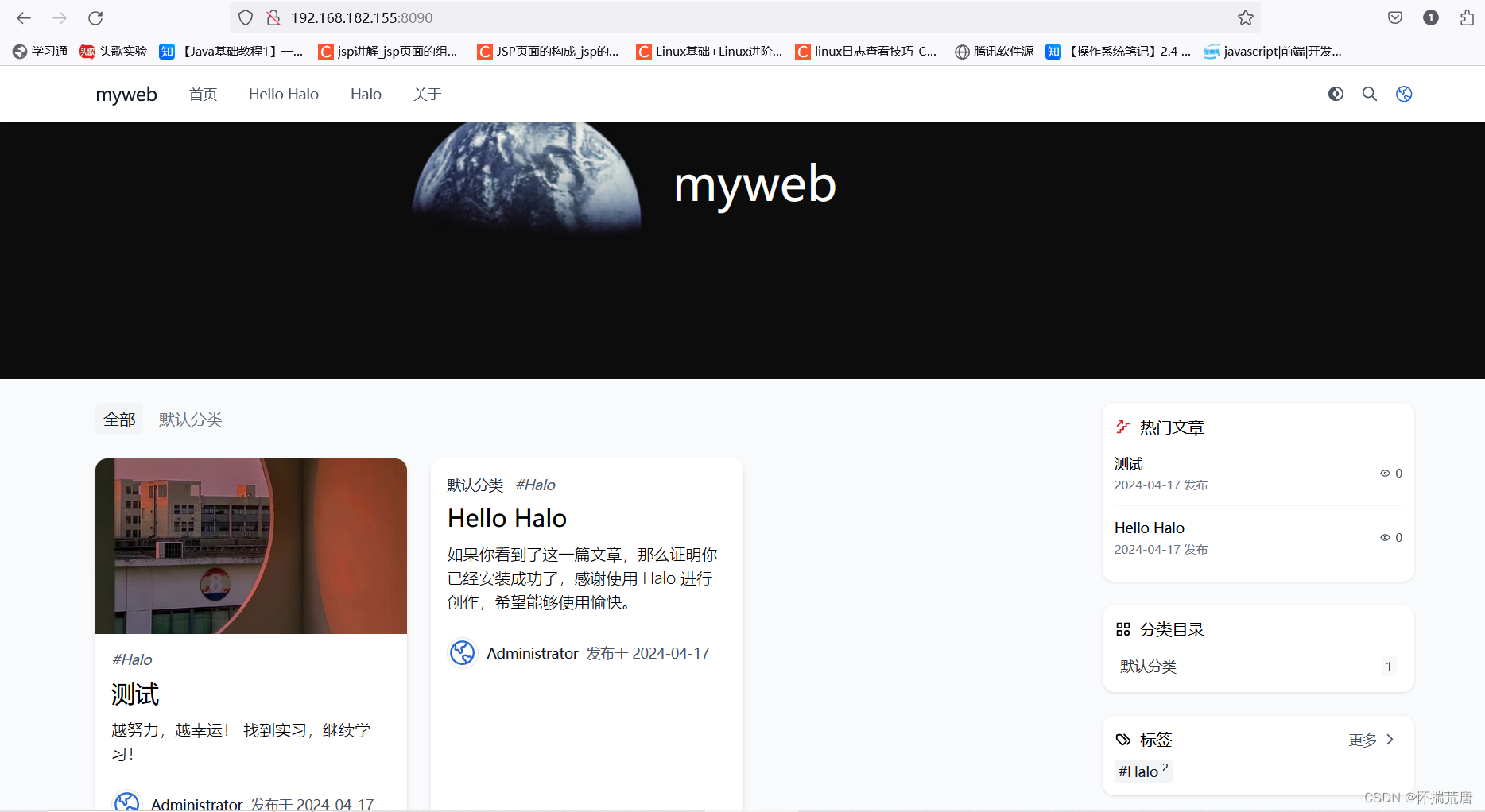
我们成功在本地部署了Halo,通过访问挂载的8089端口即可看到Halo首页界面,并创作了第一篇文章,如果我们想把创作好的个人博客发布至公网分享给身边人点击查看,那么就需要借助cpolar内网穿透工具了,接下来我们安装cpolar内网穿透工具,实现无公网环境远程访问!
② Linux安装 Cpolar
- 打开服务器防火墙
# 启动防火墙
systemctl start firewalld
# 查看防火墙状态
systemctl status firewalld
# Centos 防火墙添加端口:[单个]
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 重新载入
firewall-cmd --reload
# 查看
firewall-cmd --zone=public --list-ports
安装 cpolar 内网穿透
上面在本地Docker中成功部署了Halo,并局域网访问成功,下面我们在Linux安装Cpolar内网穿透工具,通过Cpolar 转发本地端口映射的http公网地址,我们可以很容易实现远程访问,而无需自己注册域名购买云服务器.下面是安装cpolar步骤 cpolar官网地址: https://www.cpolar.com使用一些脚本安装命令
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
向系统添加服务
systemctl enable cpolar
启动 cpolar 服务
systemctl start cpolar
注册账号:注册后直接登录即可,不用过多操作
cpolar安装成功后,在外部浏览器上访问Linux 的9200端口 即:【http://局域网ip:9200】,使用cpolar账号登录(如没有账号,可以点击下面免费注册),登录后即可看到cpolar web 配置界面,结下来在web 管理界面配置即可192.168.182.155:9200
③配置 Halo 个人博客公网地址
点击左侧仪表盘的隧道管理——创建隧道,创建一个Halo的公网http地址隧道!
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:8090 (本地访问的地址)
- 域名类型:免费选择随机域名
- 地区:选择China
点击创建
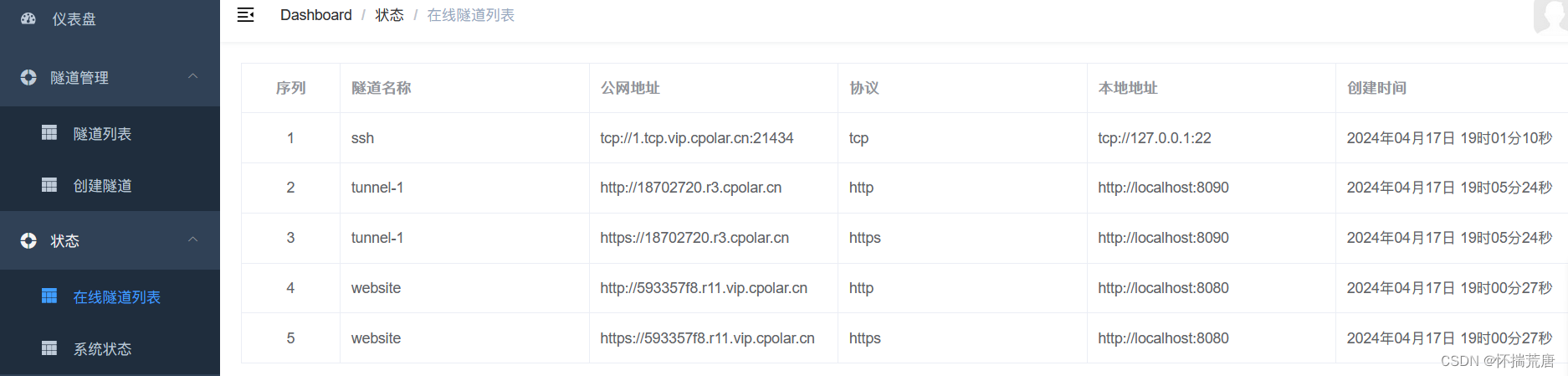
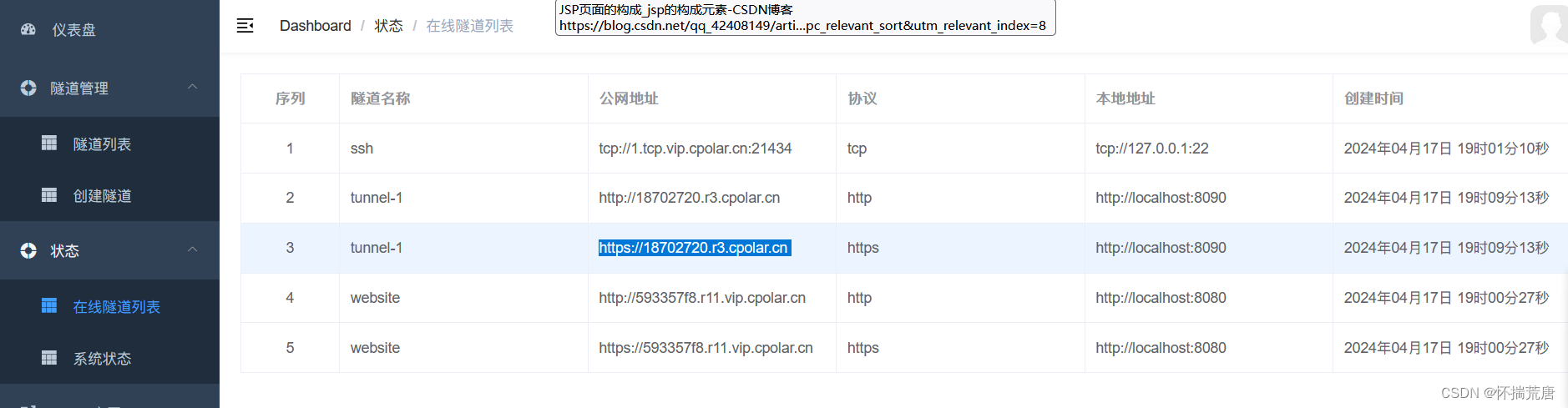
隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网访问地址,有两种访问方式,一种是http 和https
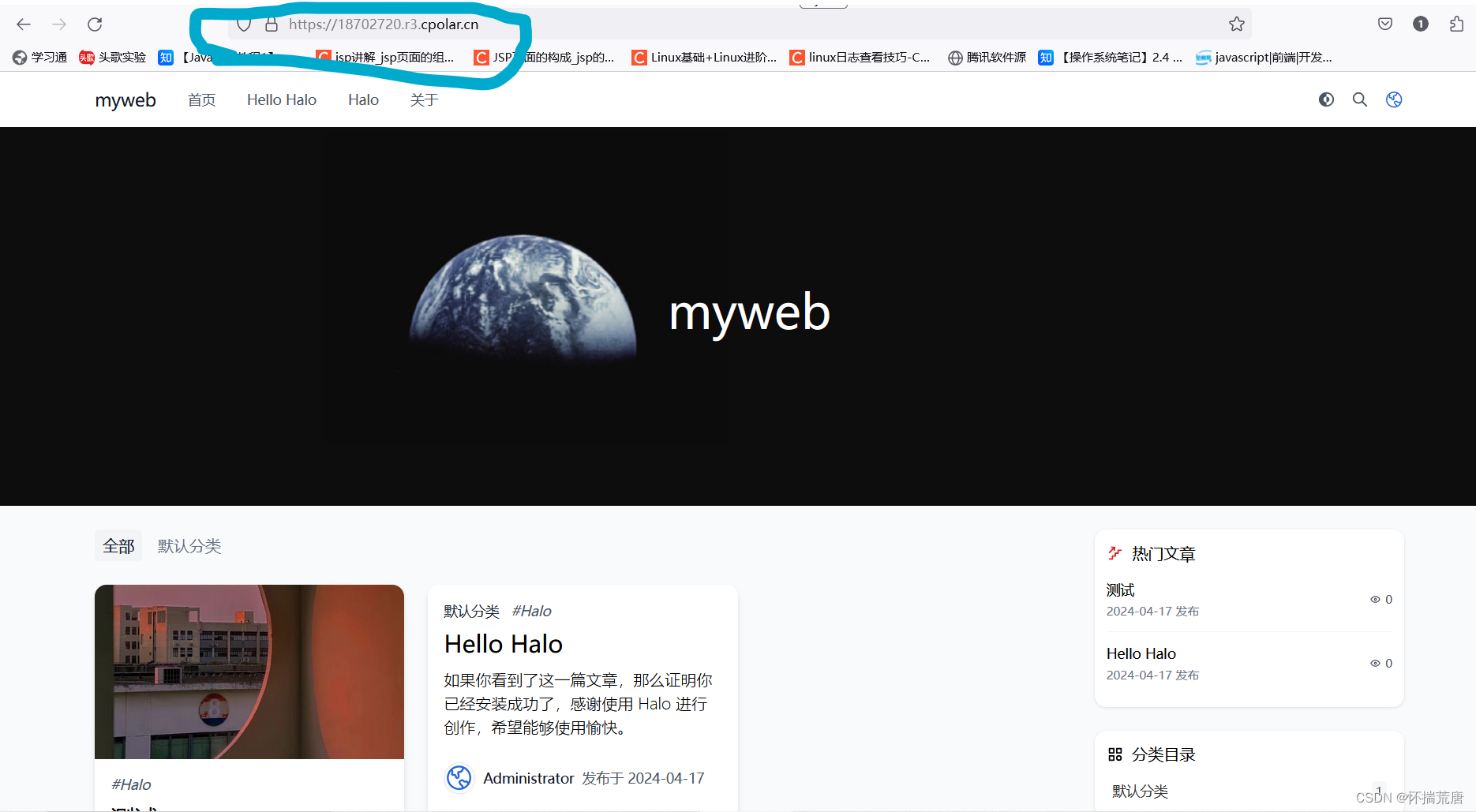
使用上面的Cpolar https公网地址,在任意设备的浏览器进行访问,即可成功看到Halo首页界面,这样一个公网地址且可以远程访问就创建好了,使用了cpolar的公网域名,无需自己购买云服务器,即可发布到公网进行远程访问!
小结:
如果我们需要把自己的个人博客长期发布至公网,分享给别人查看,由于刚才创建的是随机的地址,24小时会发生变化。另外它的网址是由随机字符生成,不容易记忆。如果想把域名变成固定的二级子域名,并且不想每次都重新创建隧道,可以选择创建一个固定的http地址来解决这个问题。

④固定 Halo 公网地址--需付费操作,练习的话到以上就结束了
我们接下来为其配置固定的HTTP端口地址,该地址不会变化,方便分享给别人长期查看你的博客,而无需每天重复修改服务器地址。注:配置固定http端口地址需要将cpolar升级到专业版套餐或以上。
登录cpolar官网,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称--https://www.cpolar.com
保留成功后复制保留成功的二级子域名的名称
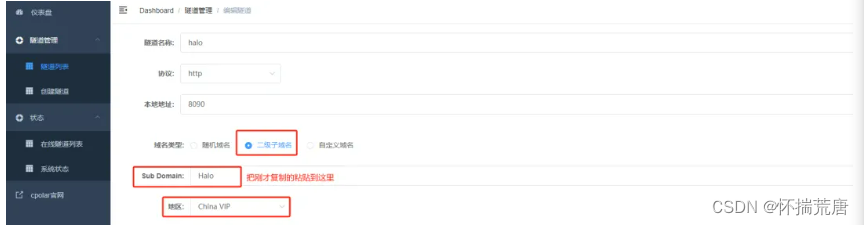
返回登录Cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击
更新(注意,点击一次更新即可,不需要重复提交)
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名
最后,我们使用固定的公网https地址访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以把个人博客分享给其他人了!


版权归原作者 怀揣荒唐 所有, 如有侵权,请联系我们删除。